Debuggen von Apache Spark-Anwendungen in einem HDInsight-Cluster mit dem Azure-Toolkit für IntelliJ per SSH
Dieser Artikel enthält eine ausführliche Anleitung zur Verwendung der HDInsight-Tools im Azure-Toolkit für IntelliJ zum Remotedebuggen von Anwendungen in einem HDInsight-Cluster.
Voraussetzungen
Ein Apache Spark-Cluster unter HDInsight. Weitere Informationen finden Sie unter Erstellen eines Apache Spark-Clusters.
Für Windows-Benutzer: Beim Ausführen der lokalen Spark Scala-Anwendung auf einem Windows-Computer wird unter Umständen eine Ausnahme wie unter SPARK-2356 beschrieben ausgelöst. Diese Ausnahme tritt auf, weil die Datei „WinUtils.exe“ in Windows fehlt.
Um diesen Fehler zu beheben, müssen Sie Winutils.exe herunterladen und an einem Speicherort wie C:\WinUtils\bin ablegen. Fügen Sie anschließend die Umgebungsvariable HADOOP_HOME hinzu, und legen Sie den Wert der Variable auf C:\WinUtils fest.
IntelliJ IDEA (Die Community Edition ist kostenlos.).
Einen SSH-Client. Weitere Informationen finden Sie unter Herstellen einer Verbindung mit HDInsight (Hadoop) per SSH.
Erstellen einer Spark Scala-Anwendung
Starten Sie IntelliJ IDEA, und wählen Sie Create New Project (Neues Projekt erstellen) aus, um das Fenster New Project (Neues Projekt) zu öffnen.
Wählen Sie im linken Bereich Apache Spark/HDInsight aus.
Wählen Sie im Hauptfenster Spark Project with Samples (Scala) (Spark-Projekt mit Beispielen (Scala)) aus.
Wählen Sie in der Dropdownliste Build tool (Buildtool) eine der folgenden Optionen aus:
- Maven für die Unterstützung des Scala-Projekterstellungs-Assistenten
- SBT zum Verwalten von Abhängigkeiten und Erstellen für das Scala-Projekt
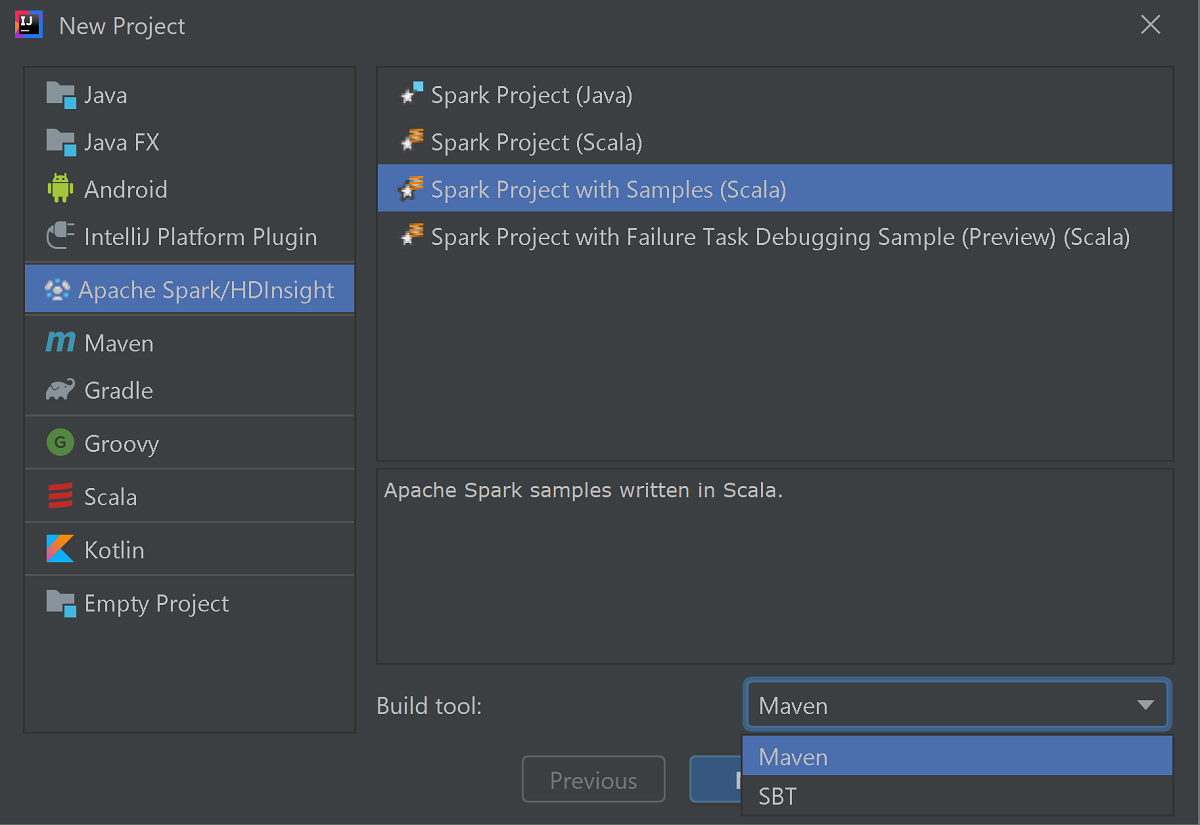
Wählen Sie Weiter aus.
Geben Sie im nächsten Fenster New Project (Neues Projekt) die folgenden Informationen an:
Eigenschaft BESCHREIBUNG Projektname Geben Sie einen Namen ein. In dieser exemplarischen Vorgehensweise wird myAppverwendet.Projektspeicherort Geben Sie den gewünschten Speicherort für Ihr Projekt ein. Project SDK (Projekt-SDK) Wenn leer, wählen Sie New... (Neu...) aus, und navigieren Sie zu Ihrem JDK. Spark-Version Der Erstellungs-Assistent integriert die passende Version für das Spark-SDK und das Scala-SDK. Wenn Sie eine ältere Spark-Clusterversion als 2.0 verwenden, wählen Sie Spark 1.x aus. Wählen Sie andernfalls Spark 2.x aus. In diesem Beispiel wird Spark 2.3.0 (Scala 2.11.8) verwendet. 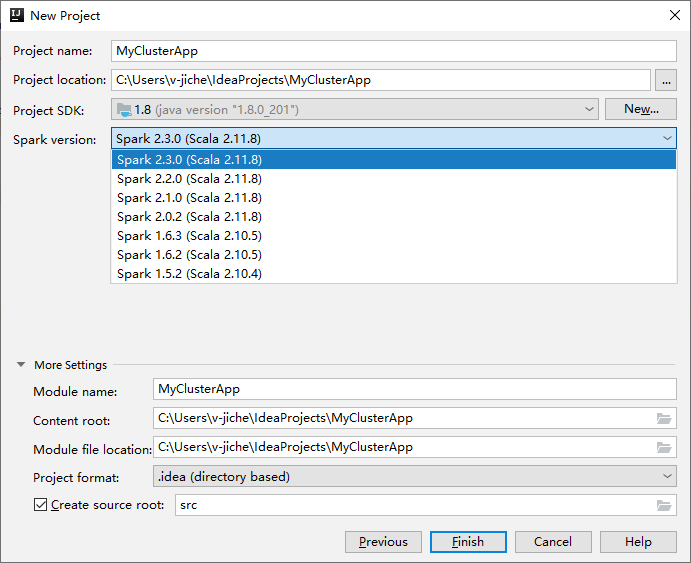
Wählen Sie Fertig stellenaus. Es kann einige Minuten dauern, bis das Projekt verfügbar ist. Verfolgen Sie den Fortschritt in der unteren rechten Ecke.
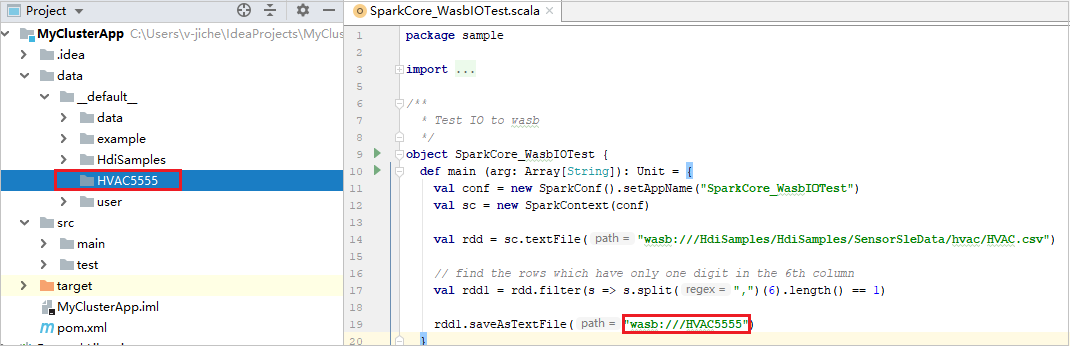
Erweitern Sie das Projekt, und navigieren Sie zu src>main>scala>sample (Beispiel). Doppelklicken Sie auf SparkCore_WasbIOTest.
Durchführen einer lokalen Ausführung
Klicken Sie im Skript SparkCore_WasblOTest mit der rechten Maustaste auf den Skript-Editor, und wählen Sie dann die Option Run 'SparkCore_WasbIOTest' („SparkCore_WasbIOTest“ ausführen) aus, um eine lokale Ausführung zu starten.
Nach Abschluss der lokalen Ausführung sehen Sie, dass die Ausgabedatei in Ihrem aktuellen Projekt-Explorer im Verzeichnis data>default gespeichert wurde.
Unsere Tools legen die Standardkonfiguration für die lokale Ausführung automatisch fest, wenn Sie die lokale Ausführung und lokales Debuggen durchführen. Öffnen Sie die Konfiguration [Spark on HDInsight] XXX ([Spark auf HDInsight] XXX). In der oberen rechten Ecke sehen Sie, dass [Spark auf HDInsight] XXX bereits unter Apache Spark on HDInsight (Apache Spark auf HDInsight) erstellt wurde. Wechseln Sie zur Registerkarte Lokal ausführen.
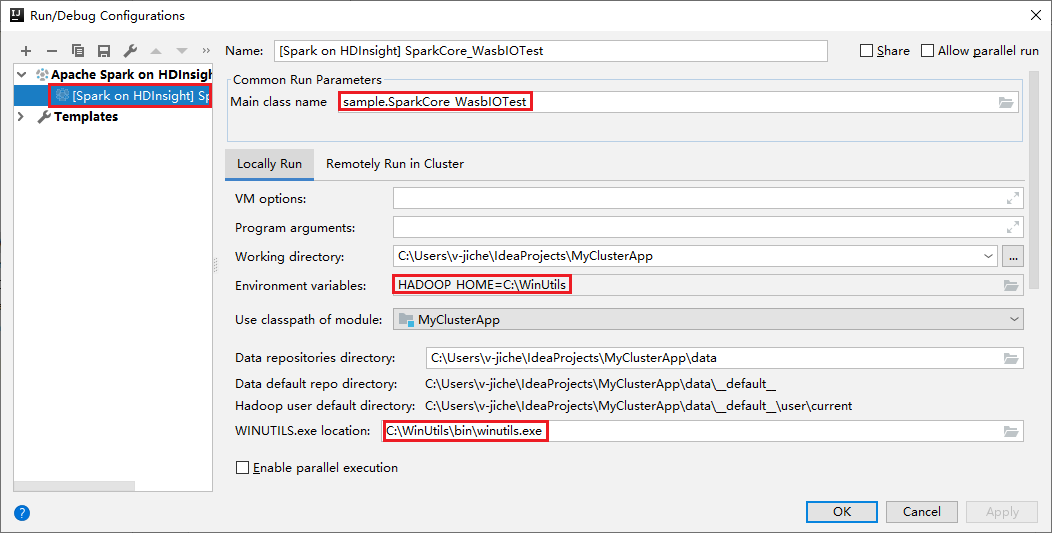
- Environment variables (Umgebungsvariablen): Wenn Sie die Systemumgebungsvariable HADOOP_HOME bereits auf C:\WinUtils festgelegt haben, kann automatisch festgestellt werden, dass eine manuelle Hinzufügung nicht erforderlich ist.
- WinUtils.exe Location (Speicherort von „WinUtils.exe“): Wenn Sie die Systemumgebungsvariable nicht festgelegt haben, können Sie den Speicherort durch Klicken auf die zugehörige Schaltfläche finden.
- Wählen Sie eine der beiden Optionen aus. Unter macOS und Linux sind diese nicht erforderlich.
Sie können die Konfiguration auch manuell vor der lokalen Ausführung und dem lokalen Debuggen festlegen. Wählen Sie im obigen Screenshot das Pluszeichen ( + ). Wählen Sie dann die Option Apache Spark auf HDInsight aus. Geben Sie Informationen für Name und Main class name (Name der Hauptklasse) für den Speichervorgang ein, und klicken Sie dann auf die Schaltfläche für die lokale Ausführung.
Durchführen eines lokalen Debuggens
Öffnen Sie das Skript SparkCore_wasbloTest, und legen Sie Breakpoints fest.
Klicken Sie mit der rechten Maustaste auf den Skript-Editor, und wählen Sie dann die Option Debug „[Spark on HDInsight]XXX“ („[Spark auf HDInsight]XXX“ debuggen), um das lokale Debuggen zu starten.
Remoteausführung
Navigieren Sie zu Ausführen>Konfigurationen bearbeiten. Über dieses Menü können Sie die Konfigurationen für das Remotedebuggen erstellen und bearbeiten.
Klicken Sie im Dialogfeld Run/Debug Configurations (Konfigurationen ausführen/debuggen) auf das Plussymbol ( + ). Wählen Sie dann die Option Apache Spark auf HDInsight aus.
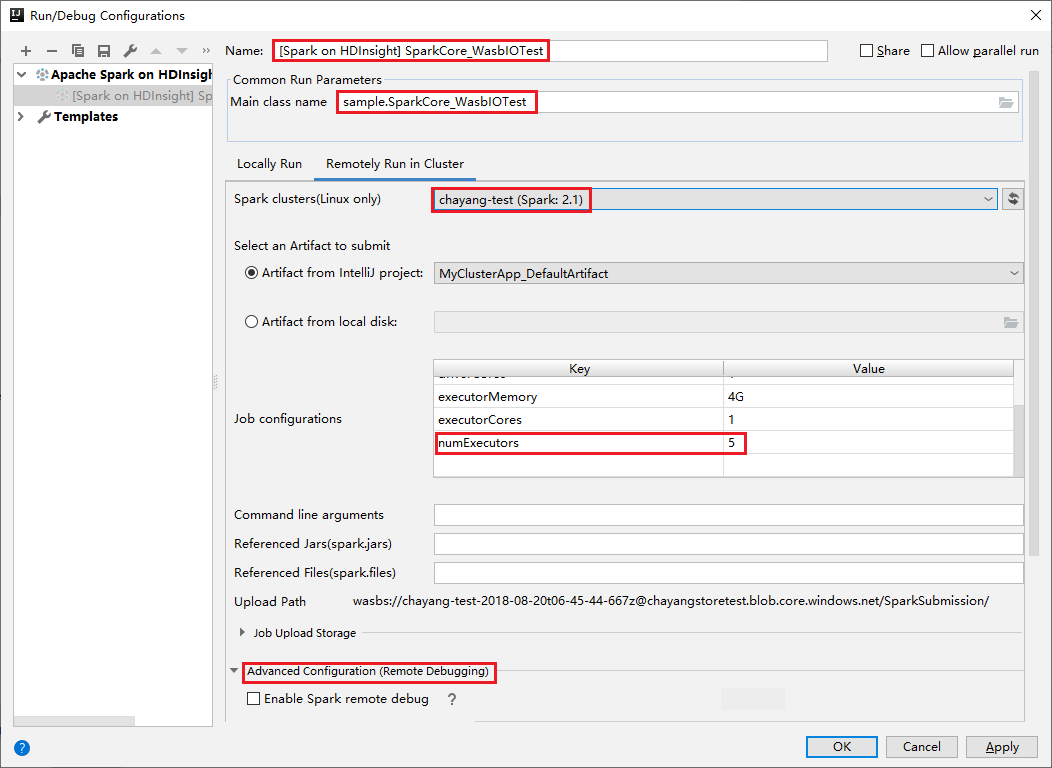
Wechseln Sie zur Registerkarte Remotely Run in Cluster (Im Cluster remote ausführen). Geben Sie Informationen für Name, Spark cluster und Main class name (Name der main-Klasse) ein. Klicken Sie dann auf Erweiterte Konfiguration (Remotedebuggen) . Unseren Tools unterstützen das Debuggen mit Executors. Die numExecutors, der Standardwert ist 5. Sie sollten ihn nicht auf einen größeren Wert als 3 festlegen.
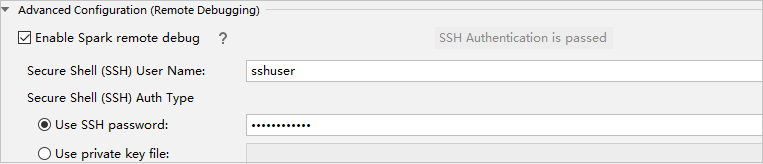
Wählen Sie im Teil Erweiterte Konfiguration (Remotedebuggen)Remotedebuggen für Spark aktivieren aus. Geben Sie den SSH-Benutzernamen und anschließend ein Kennwort ein, oder verwenden Sie eine private Schlüsseldatei. Wenn Sie das Remotedebuggen durchführen möchten, müssen Sie diesen Wert festlegen. Dies ist nicht notwendig, wenn Sie nur die Remoteausführung verwenden möchten.
Die Konfiguration wird jetzt unter dem von Ihnen angegebenen Namen gespeichert. Um die Konfigurationsdetails anzuzeigen, wählen Sie den Konfigurationsnamen aus. Um Änderungen vorzunehmen, wählen Sie Edit Configurations (Konfigurationen bearbeiten) aus.
Nachdem Sie die Konfigurationseinstellungen abgeschlossen haben, können Sie das Projekt für den Remotecluster ausführen oder das Remotedebuggen durchführen.

Klicken Sie auf die Schaltfläche Trennen, damit Die Übermittlungsprotokolle nicht im linken Bereich angezeigt werden. Die Ausführung wird jedoch auf dem Back-End fortgesetzt.
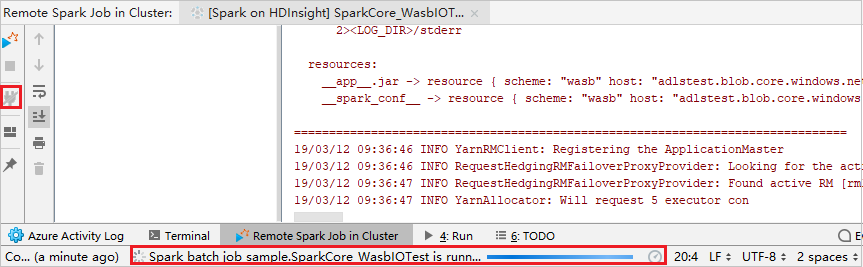
Remotedebuggen
Richten Sie Breakpoints ein, und klicken Sie dann auf das Symbol Remotedebuggen. Der Unterschied bei der Remoteübermittlung besteht darin, dass der SSH-Benutzername und das Kennwort konfiguriert werden müssen.

Wenn die Programmausführung den Breakpoint erreicht, werden eine Registerkarte Driver (Treiber) und zwei Registerkarten Executor im Bereich Debugger angezeigt. Klicken Sie auf das Symbol Resume Program (Programm fortsetzen), um die Ausführung des Codes fortzusetzen. Die Ausführung erreicht dann den nächsten Breakpoint. Sie müssen zur richtigen Executor-Registerkarte wechseln, um den Zielexecutor für das Debuggen zu finden. Sie können die Ausführungsprotokolle auf der entsprechenden Registerkarte Console (Konsole) anzeigen.
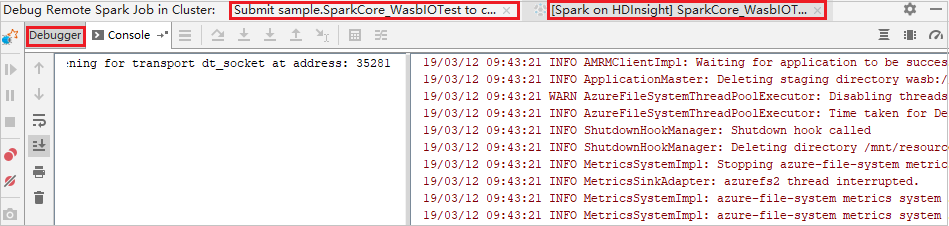
Remotedebuggen und Beheben von Fehlern
Richten Sie zwei Breakpoints ein, und klicken Sie dann auf das Symbol Debug (Debuggen), um das Remotedebuggen zu starten.
Der Code wird am ersten Breakpoint angehalten, und die Informationen zu Parametern und Variablen werden im Bereich Variables (Variablen) angezeigt.
Klicken Sie auf das Symbol Resume Program (Programm fortsetzen), um die Ausführung fortzusetzen. Der Code wird am zweiten Punkt beendet. Die Ausnahme wird wie erwartet abgefangen.
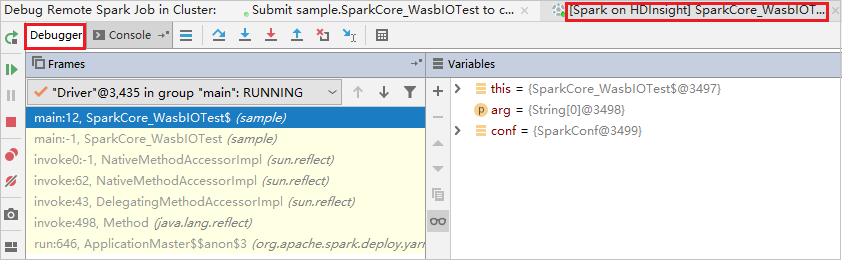
Klicken Sie erneut auf das Symbol Resume Program (Programm fortsetzen). Im Fenster HDInsight Spark Submission (HDInsight Spark-Übermittlung) wird ein Fehler bei der Auftragsausführung angezeigt.
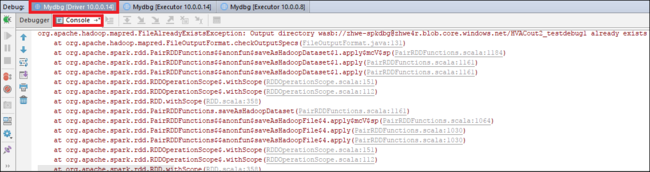
Um den Wert der Variablen mithilfe der Debugfunktion von IntelliJ dynamisch zu aktualisieren, wählen Sie erneut Debug (Debuggen) aus. Der Bereich Variables (Variablen) wird wieder angezeigt.
Klicken Sie mit der Maustaste auf die Registerkarte Debug, und wählen Sie dann Set Value (Wert festlegen) aus. Als Nächstes geben Sie einen neuen Wert für die Variable ein. Wählen Sie dann Enter (Eingabe) aus, um den Wert zu speichern.
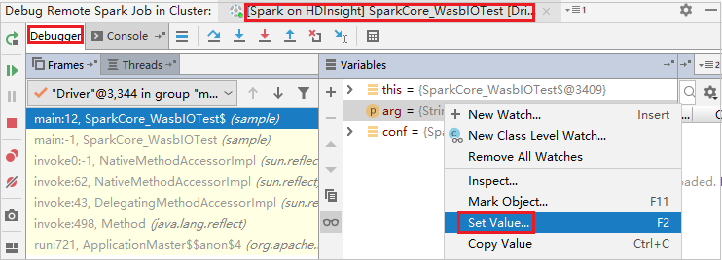
Klicken Sie auf das Symbol Resume Program (Programm fortsetzen), um die Programmausführung fortzusetzen. Dieses Mal wird keine Ausnahme abgefangen. Sie können sehen, dass das Projekt erfolgreich und ohne Ausnahmen ausgeführt wird.
Nächste Schritte
Szenarien
- Apache Spark mit BI: Durchführen interaktiver Datenanalysen mithilfe von Spark in HDInsight mit BI-Tools
- Apache Spark mit Machine Learning: Analysieren von Gebäudetemperaturen mithilfe von Spark in HDInsight und HVAC-Daten
- Apache Spark mit Machine Learning: Vorhersage von Lebensmittelkontrollergebnissen mithilfe von Spark in HDInsight
- Websiteprotokollanalyse mithilfe von Apache Spark in HDInsight
Erstellen und Ausführen von Anwendungen
- Erstellen einer eigenständigen Anwendung mit Scala
- Ausführen von Remoteaufträgen in einem Apache Spark-Cluster mithilfe von Apache Livy
Tools und Erweiterungen
- Erstellen von Apache Spark-Anwendungen für einen HDInsight-Cluster mit dem Azure-Toolkit für IntelliJ
- Verwenden des Azure-Toolkits für IntelliJ zum Remotedebuggen von Apache Spark-Anwendungen über VPN
- Verwenden der HDInsight-Tools im Azure-Toolkit für Eclipse zum Erstellen von Apache Spark-Anwendungen
- Verwenden von Apache Zeppelin Notebooks mit einem Apache Spark-Cluster unter HDInsight
- Verfügbare Kernels für Jupyter Notebooks in einem Apache Spark-Cluster für HDInsight
- Verwenden von externen Paketen mit Jupyter Notebooks
- Installieren von Jupyter Notebook auf Ihrem Computer und Herstellen einer Verbindung zum Apache Spark-Cluster in Azure HDInsight (Vorschau)