Bewerten von Fehlern in Machine Learning-Modellen
Eine der größten Herausforderungen bei den derzeitigen Verfahren zum Debuggen von Modellen ist die Verwendung aggregierter Metriken zur Bewertung von Modellen anhand eines Benchmarkdatasets. Die Modellgenauigkeit ist möglicherweise nicht einheitlich für alle Untergruppen von Daten, und es könnte Eingabekohorten geben, bei denen beim Modell häufiger Fehler auftreten. Die unmittelbaren Folgen dieser Fehler sind mangelnde Zuverlässigkeit und Sicherheit, das Auftreten von Fairnessproblemen und ein genereller Vertrauensverlust in das maschinelle Lernen.

Die Fehleranalyse entfernt sich von aggregierten Genauigkeitsmetriken. Sie macht die Fehlerverteilung für Entwickler transparent und ermöglicht es ihnen, Fehler effizient zu identifizieren und zu diagnostizieren.
Die Fehleranalysekomponente des Dashboards für verantwortungsbewusste KI bietet Praktikern des maschinellen Lernens ein tieferes Verständnis der Modellfehlerverteilung und hilft ihnen, fehlerhafte Datenkohorten schnell zu identifizieren. Diese Komponente identifiziert die Datenkohorten mit einer höheren Fehlerquote im Vergleich zur allgemeinen Benchmarkfehlerrate. Sie trägt folgendermaßen zur Identifizierungsphase des Modelllebenszyklus-Workflows bei:
- Entscheidungsstruktur, die Kohorten mit hohen Fehlerraten anzeigt
- Wärmebild, das zeigt, wie sich Eingabefeatures auf die Fehlerrate in allen Kohorten auswirken
Fehlerabweichungen können auftreten, wenn das System bei bestimmten demografischen Gruppen oder selten beobachteten Eingabekohorten in den Trainingsdaten unterdurchschnittliche Leistungen erbringt.
Die Funktionen dieser Komponente stammen aus dem Fehleranalysepaket, das Modellfehlerprofile generiert.
Verwenden Sie die Fehleranalyse, wenn Sie Folgendes erreichen müssen:
- Ein tiefes Verständnis dafür gewinnen, wie Modellfehler über ein Dataset und über mehrere Eingabe- und Featuredimensionen verteilt sind
- Die aggregierten Leistungsmetriken aufschlüsseln, um automatisch fehlerhafte Kohorten zu erkennen und gezielte Maßnahmen zur Risikominderung zu ergreifen
Fehlerstruktur
Häufig sind die Fehlermuster komplex und umfassen mehr als ein oder zwei Features. Für Entwickler kann es schwierig sein, alle möglichen Kombinationen von Features zu untersuchen, um versteckte Datentaschen mit kritischen Fehlern zu entdecken.
Um den Aufwand zu verringern, unterteilt die Visualisierung der binären Struktur die Benchmarkdaten automatisch in interpretierbare Untergruppen, die unerwartet hohe oder niedrige Fehlerraten aufweisen. Mit anderen Worten: Die Struktur verwendet die Eingabefeatures, um Modellfehler und Erfolg maximal zu trennen. Für jeden Knoten, der eine Datenuntergruppe definiert, können die Benutzer die folgenden Informationen untersuchen:
- Fehlerrate: Ein Teil der Instanzen im Knoten, für die das Modell nicht korrekt ist. Dies wird durch die Intensität der roten Farbe angezeigt.
- Fehlerabdeckung: Ein Teil aller Fehler, die in den Knoten fallen. Dies wird durch die Füllrate des Knotens angezeigt.
- Datendarstellung: Die Anzahl der Instanzen in jedem Knoten der Fehlerstruktur. Dies wird durch die Stärke der eingehenden Kante zum Knoten zusammen mit der Gesamtzahl der Instanzen im Knoten angezeigt.

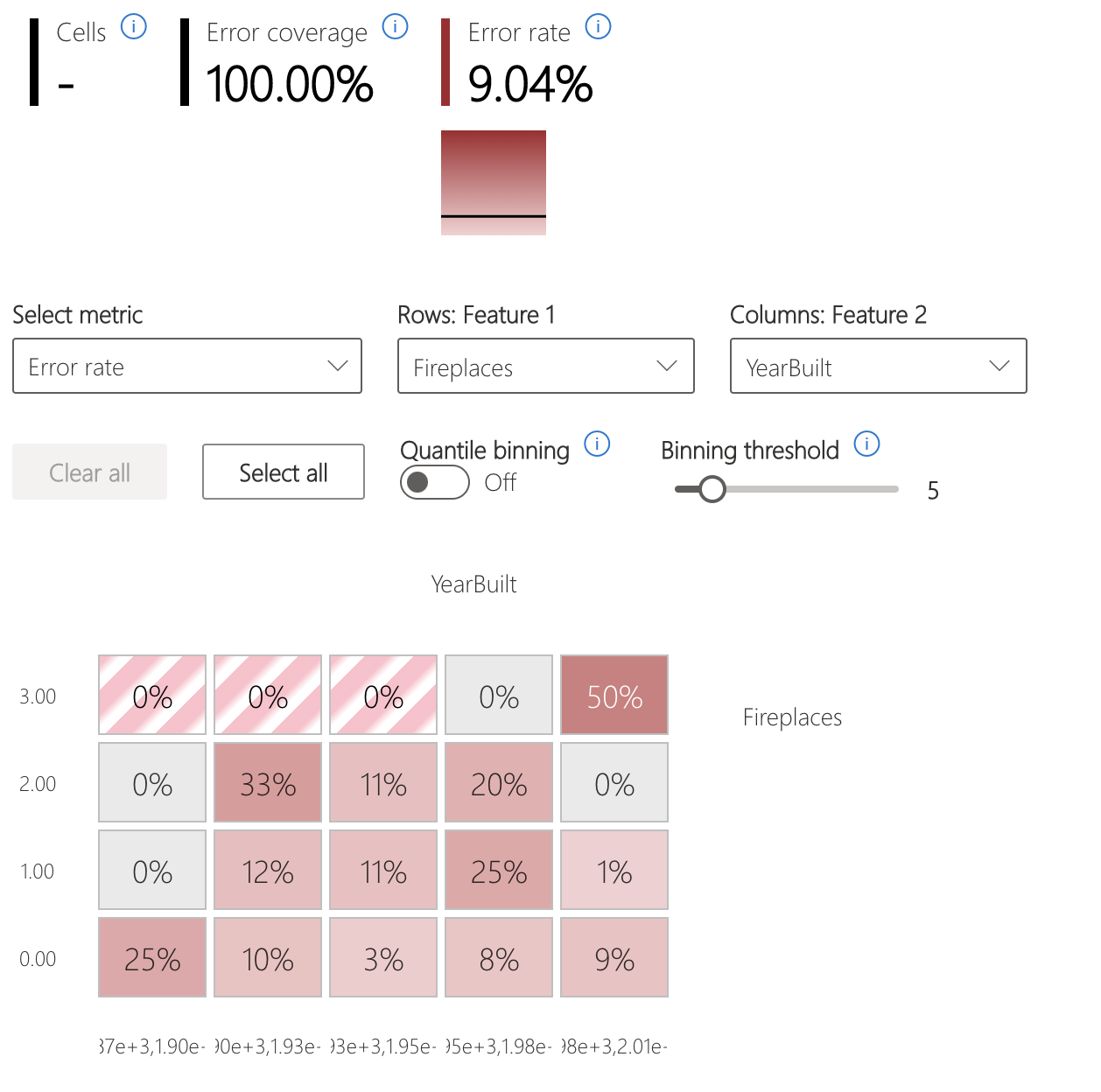
Fehlerwärmebild
Die Ansicht unterteilt die Daten auf der Grundlage eines ein- oder zweidimensionalen Rasters von Eingabefeatures. Die Benutzer können die für die Analyse interessanten Eingabefeatures auswählen.
Das Wärmebild visualisiert Zellen mit hoher Fehlerrate durch die Verwendung einer dunkleren roten Farbe, um die Aufmerksamkeit des Benutzers auf diese Regionen zu lenken. Diese Funktion ist besonders dann von Vorteil, wenn die Fehlerthemen in den verschiedenen Partitionen unterschiedlich sind, was in der Praxis häufig vorkommt. Bei dieser Sichtweise der Fehlererkennung wird die Analyse in hohem Maße von den Benutzern und ihrem Wissen oder ihren Hypothesen darüber geleitet, welche Features für das Verständnis von Fehlern am wichtigsten sein könnten.
Nächste Schritte
- Erfahren Sie, wie Sie das Dashboard für verantwortungsbewusste künstliche Intelligenz über CLI und SDK oder die Azure Machine Learning Studio-Benutzeroberfläche generieren.
- Erkunden Sie die unterstützten Fehleranalysevisualisierungen.
- Erfahren Sie, wie Sie eine Scorecard für verantwortungsvolle KI auf Grundlage der im Dashboard für verantwortungsvolle KI beobachteten Erkenntnisse generieren.