Hinzufügen von Bewertungsprofilen für maximale Suchscores
Mithilfe von Bewertungsprofilen können Sie die Rangfolge übereinstimmender Dokumente anhand von Kriterien verbessern. In diesem Artikel erfahren Sie, wie Sie ein Bewertungsprofil angeben und zuweisen, das eine Suchbewertung basierend auf von Ihnen angegebenen Parametern erhöht.
Sie können Bewertungsprofile für die Stichwortsuche, die Vektorsuche und die Hybridsuche verwenden. Bewertungsprofile gelten jedoch nur für Felder ohne Vektoren. Stellen Sie daher sicher, dass Ihr Index Text- oder numerische Felder enthält, die in einem Bewertungsprofil verwendet werden können. Die Unterstützung des Bewertungsprofils für die Vektor- und Hybridsuche ist in 2024-05-01-preview und 2024-07-01 REST-APIs sowie in Azure SDK-Paketen verfügbar, die auf diese Versionen abzielen.
Wichtige Punkte zu Bewertungsprofilen
Bewertungsprofilparameter sind entweder:
Gewichtete Felder, bei denen eine Übereinstimmung in einem bestimmten Zeichenfolgenfeld gefunden wird. Sie könnten z. B. bevorzugen, dass Übereinstimmungen in einem Feld „summary“ relevanter sind als die gleiche Übereinstimmung, die in das „Inhalte“-Feld gefunden wurde.
Funktionen für numerische Daten, einschließlich Daten, Bereiche und geografische Koordinaten. Es gibt auch eine Tag-Funktion, die auf einem Feld arbeitet und eine beliebige Sammlung von Zeichenfolgen bereitstellt. Sie können diesen Ansatz gegenüber gewichteten Feldern wählen, wenn Sie eine Bewertung basierend darauf erhöhen möchten, ob eine Übereinstimmung in einem Feld für Tags gefunden wird.
Sie können mehrere Profile erstellen und dann die Abfragelogik ändern, um das jeweils zu verwendende Profil auszuwählen.
Sie können in einem Index bis zu 100 Bewertungsprofile verwenden (siehe Diensteinschränkungen), aber Sie können in einer Abfrage jeweils nur ein Profil angeben.
Sie können Semantischer Sortierer mit Bewertungsprofilen verwenden. Wenn mehrere Bewertungs- oder Relevanzfeatures eine Rolle spielen, ist die semantische Rangfolge der letzte Schritt. Dies wird unter Funktionsweise der Suchbewertung in der Azure KI-Suche veranschaulicht.
Hinweis
Sind Sie noch nicht mit Relevanzkonzepten vertraut? Besuchen Sie Relevanz und Bewertung in Azure KI-Suche für den Hintergrund. Sie können sich dieses Video-Segment auf YouTube ansehen, um Profile mit Ergebnissen über BM25-Rankings zu bewerten.
Bewertungsprofildefinition
Ein Bewertungsprofil ist ein benanntes Objekt, das in einem Indexschema definiert ist. Ein Bewertungsprofil kann aus gewichteten Feldern, Funktionen und Parametern bestehen.
Die folgende Definition zeigt ein einfaches Profil namens „geo“. Dieses Beispiel gewichtet Ergebnisse höher, die den Suchbegriff im Feld „hotelName“ enthalten. Darüber hinaus verwendet es die distance-Funktion, um Ergebnisse zu bevorzugen, die sich im Umkreis von zehn Kilometern um den aktuellen Standort befinden. Wenn nach dem Begriff „inn“ gesucht wird und „inn“ Teil des Hotelnamens ist, werden die Dokumente in den Suchergebnissen weiter oben angezeigt, die Hotels in einem Umkreis von 10 km des aktuellen Standorts mit „inn“ im Namen enthalten.
"scoringProfiles": [
{
"name":"geo",
"text": {
"weights": {
"hotelName": 5
}
},
"functions": [
{
"type": "distance",
"boost": 5,
"fieldName": "location",
"interpolation": "logarithmic",
"distance": {
"referencePointParameter": "currentLocation",
"boostingDistance": 10
}
}
]
}
]
Für die Verwendung dieses Bewertungsprofils wird Ihre Abfrage so formuliert, dass der scoringProfile-Parameter in der Anforderung angegeben wird. Wenn Sie die REST-API verwenden, werden Abfragen über GET- und POST-Anforderungen angegeben. Im folgenden Beispiel hat „currentLocation“ als Trennzeichen einen einzelnen Gedankenstrich (-). Gefolgt von Längen- und Breitengradkoordinaten, wobei Längengrad ein negativer Wert ist.
GET /indexes/hotels/docs?search+inn&scoringProfile=geo&scoringParameter=currentLocation--122.123,44.77233&api-version=2024-07-01
Beachten Sie die Syntaxunterschiede bei Verwenden von POST. In POST ist scoringParameters plural und ein Array.
POST /indexes/hotels/docs&api-version=2024-07-01
{
"search": "inn",
"scoringProfile": "geo",
"scoringParameters": ["currentLocation--122.123,44.77233"]
}
Diese Abfrage sucht nach dem Begriff "inn" und übergibt den aktuellen Standort. Beachten Sie, dass diese Abfrage weitere Parameter enthält, z. B. scoringParameter. Abfrageparameter, einschließlich „scoringParameter“, werden unter Durchsuchen von Dokumenten (REST-API) beschrieben.
Weitere Szenarien finden Sie im Erweiterten Beispiel für die Vektor- und Hybridsuche und im Erweiterten Beispiel für die Stichwortsuche.
Funktionsweise der Suchbewertung in der Azure KI-Suche
Bewertungsprofile ergänzen den Standardbewertungsalgorithmus, indem die Bewertungsergebnisse erhöht werden, die den Kriterien des Profils entsprechen. Bewertungsfunktionen gelten für Folgendes:
- Textsuche (Stichwortsuche)
- Reine Vektorabfragen
- Hybridabfragen, bei denen Text- und Vektorunterabfragen parallel ausgeführt werden
Bei eigenständigen Textabfragen identifizieren Bewertungsprofile die maximal 1.000 Übereinstimmungen in einer BM25-bewerteten Suche, und die 50 besten werden in Ergebnissen zurückgegeben.
Bei reinen Vektoren wird nur eine Vektorabfrage durchgeführt, aber wenn die k übereinstimmenden Dokumente alphanumerische Felder enthalten, die von einem Bewertungsprofil verarbeitet werden können, wird ein Bewertungsprofil angewendet. Das Bewertungsprofil überarbeitet das Resultset, indem Dokumente, die Kriterien aus dem Profil erfüllen, einen höheren Wert erhalten.
Bei Textabfragen in einer Hybridabfrage identifizieren Bewertungsprofile die maximal 1.000 Übereinstimmungen in einer BM25-bewerteten Suche. Nachdem diese 1.000 Ergebnisse identifiziert wurden, werden sie jedoch in ihrer ursprünglichen BM25-Reihenfolge wiederhergestellt, sodass sie zusammen mit Vektorenergebnissen in der finalen RRF-Reihenfolge (Reziproke Rangfolgefunktion) neu bewertet werden können, wobei das Bewertungsprofil, das in der Abbildung als finale Anpassung zur Dokumentsteigerung (final document boosting adjustment) bezeichnet wird, auf die zusammengeführten Ergebnisse angewendet wird – zusammen mit Vektorgewichtung und semantischer Rangfolge als letzter Schritt.
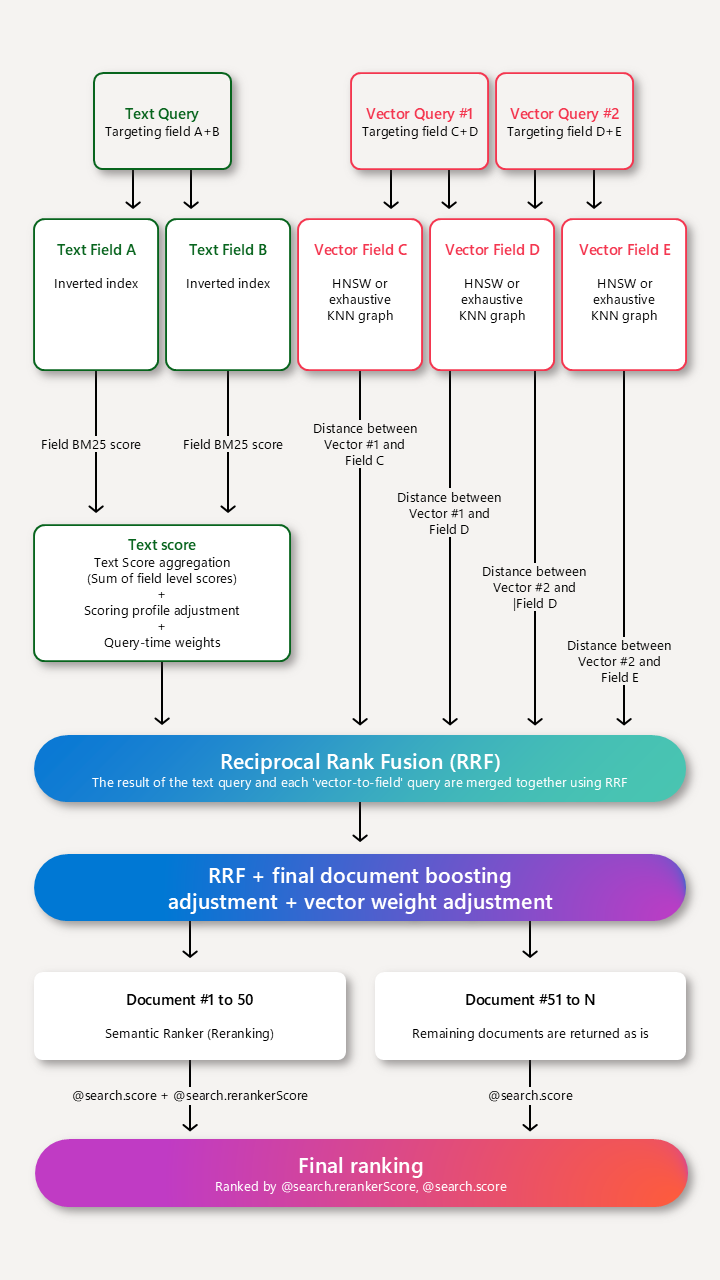
Hinzufügen eines Bewertungsprofils zu einem Suchindex
Beginnen Sie mit einer Indexdefinition. Sie können Bewertungsprofile für einen bestehenden Index hinzufügen und aktualisieren, ohne diesen neu erstellen zu müssen. Verwenden Sie eine Create or Update Index-Anforderung (Index erstellen oder aktualisieren), um Ihre Überarbeitung zu veröffentlichen.
Fügen Sie die in diesem Artikel bereitgestellte Vorlage ein.
Geben Sie einen Namen an, der den Benennungskonventionen entspricht.
Geben Sie die Relevanzkriterien an. Ein einzelnes Profil kann textgewichtete Felder, Funktionen oder beides enthalten.
Sie sollten iterativ mit einem Dataset arbeiten, das Ihnen hilft, die Effektivität eines bestimmten Profils nachzuweisen oder zu widerlegen.
Bewertungsprofile können wie im folgenden Screenshot gezeigt im Azure-Portal oder programmgesteuert über REST-APIs oder über Azure SDKs definiert werden, z. B. über die ScoringProfile-Klasse im Azure SDK für .NET.

Verwenden von textgewichteten Feldern
Verwenden Sie textgewichtete Felder, wenn der Feldkontext wichtig ist und Abfragen searchable-Zeichenfolgenfelder enthalten. Wenn eine Abfrage z. B. den Begriff "flughafen" enthält, sollten "flughafen" im Beschreibungsfeld eine höhere Gewichtung haben als im Feld „HotelName“.
Gewichtete Felder sind Name-Wert-Paare und bestehen aus einem searchable Feld und einer positiven Zahl, die als Multiplikator verwendet wird. Wenn der ursprüngliche Feldscore von HotelName 3 lautet, entspricht der höher gewichtete Score dieses Felds 6, was zu einem höheren Gesamtscore des übergeordneten Dokuments beiträgt.
"scoringProfiles": [
{
"name": "boostSearchTerms",
"text": {
"weights": {
"HotelName": 2,
"Description": 5
}
}
}
]
Verwenden von Funktionen
Verwenden Sie Funktionen, wenn einfache relative Gewichtungen nicht ausreichen oder sich nicht anwenden lassen. Dies ist z. B. bei „distance“ und „freshness“ der Fall, da es sich hier um Berechnungen für numerische Daten handelt. Sie können pro Bewertungsprofil mehrere Funktionen angeben. Weitere Informationen zu den in Azure AI Search verwendeten EDM-Datentypen finden Sie unter Unterstützte Datentypen.
| Funktion | Beschreibung | Anwendungsfälle |
|---|---|---|
| distance | Höhere Gewichtung auf Basis der Nähe oder des geografischen Standorts. Diese Funktion kann nur mit Edm.GeographyPoint -Feldern verwendet werden. |
Verwenden Sie diese Option für Szenarien für „In meiner Nähe suchen“. |
| freshness | Erhöht um Werte in einem datetime-Feld (Edm.DateTimeOffset). Legen Sie boostDuration fest, um einen Wert anzugeben, der einen Zeitbereich darstellt, über den die Verstärkung erfolgt. |
Verwenden Sie diesen Vorgang, wenn Sie eine Verstärkung nach neueren oder älteren Datumsangaben ausführen möchten. Elemente wie z. B. Kalenderereignisse können mit in der Zukunft liegenden Daten so eingestuft werden, dass Ereignisse mit geringerem Abstand zur Gegenwart höher als Ereignisse eingestuft werden, die weiter in der Zukunft liegen. Ein Ende des Bereichs ist auf die aktuelle Uhrzeit festgelegt. Um eine Reihe von Zeiten in der Vergangenheit zu erhöhen, verwenden Sie eine positive BoostDuration. Wenn Sie einen Bereich von zukünftigen Zeitpunkten höher gewichten möchten, verwenden Sie einen negativen Wert für boostingDuration. |
| magnitude | Ändern Sie Rangfolgen basierend auf dem Wertebereich für ein numerisches Feld. Der Wert muss vom Typ „Integer“ oder „Gleitkomma“ sein. Für Sternbewertungen von 1 bis 4 wäre dies die 1. Für Gewinnspannen von über 50 % wäre dies die 50. Diese Funktion kann nur mit Edm.Double- und Edm.Int-Feldern verwendet werden. Für die magnitude-Funktion können Sie den Bereich umkehren, wenn Sie das umgekehrte Muster anwenden möchten (z. B. um preiswerteren Artikeln eine höhere Relevanz als teureren zuzuweisen). Legen Sie bei einer Preisspanne zwischen 100 € und 1 € boostingRangeStart auf 100 und boostingRangeEnd auf 1 fest, um preiswertere Artikeln zu fördern. |
Verwenden Sie diese Option, wenn Sie durch Gewinnspanne, Bewertungen, Clickthrough-Anzahl, Anzahl der Downloads, höchsten Preis, niedrigsten Preis oder eine Anzahl von Downloads steigern möchten. Wenn zwei Elemente relevant sind, wird das Element mit der höheren Bewertung zuerst angezeigt. |
| tag | Höhere Gewichtung auf Basis von Tags, die sowohl für Suchdokumente als auch für Abfragezeichenfolgen gebräuchlich sind. Tags werden als tagsParameter bereitgestellt. Diese Funktion kann nur mit Suchfeldern vom Typ Edm.String und Collection(Edm.String) verwendet werden. |
Verwenden Sie diese Funktion, wenn Sie Tagfelder haben. Wenn ein Tag in der Liste selbst eine durch Trennzeichen getrennte Liste ist, können Sie eine Textnormalisierungsfunktion in diesem Feld verwenden, um die Trennzeichen zur Abfragezeit zu entfernen (das Trennzeichen wird einem Leerzeichen zugeordnet). Damit wird die Liste vereinfacht und enthält alle Begriffe in einer einzigen, langen Zeichenfolge mit Trennzeichen. |
Regeln für die Verwendung von Funktionen
- Funktionen können nur auf Felder angewendet werden, die als
filterableattribuiert sind. - Der Funktionstyp ("freshness", "magnitude", "distance", "tag") muss in Kleinbuchstaben angegeben werden.
- Funktionen dürfen keine NULL-Werte oder leeren Werte enthalten.
- Funktionen können nur ein einzelnes Feld pro Funktionsdefinition aufweisen. Um „magnitude“ zweimal im selben Profil zu verwenden, stellen Sie zwei Definitionen für jedes Feld bereit.
Vorlage
In diesem Abschnitt wird die Syntax und die Vorlage für die Bewertungsprofile veranschaulicht. Eine Beschreibung der Eigenschaften finden Sie in der REST-API-Referenz.
"scoringProfiles": [
{
"name": "name of scoring profile",
"text": (optional, only applies to searchable fields) {
"weights": {
"searchable_field_name": relative_weight_value (positive #'s),
...
}
},
"functions": (optional) [
{
"type": "magnitude | freshness | distance | tag",
"boost": # (positive number used as multiplier for raw score != 1),
"fieldName": "(...)",
"interpolation": "constant | linear (default) | quadratic | logarithmic",
"magnitude": {
"boostingRangeStart": #,
"boostingRangeEnd": #,
"constantBoostBeyondRange": true | false (default)
}
// ( - or -)
"freshness": {
"boostingDuration": "..." (value representing timespan over which boosting occurs)
}
// ( - or -)
"distance": {
"referencePointParameter": "...", (parameter to be passed in queries to use as reference location)
"boostingDistance": # (the distance in kilometers from the reference location where the boosting range ends)
}
// ( - or -)
"tag": {
"tagsParameter": "..."(parameter to be passed in queries to specify a list of tags to compare against target field)
}
}
],
"functionAggregation": (optional, applies only when functions are specified) "sum (default) | average | minimum | maximum | firstMatching"
}
],
"defaultScoringProfile": (optional) "...",
Festlegen von Interpolationen
Interpolationen legen die Form der für die Bewertung verwendete Steigung fest. Da Bewertung von hoch zu niedrig verläuft, nimmt die Steigung immer ab, die Interpolation bestimmt jedoch die Kurve des Gefälles. Die folgenden Interpolationen können verwendet werden:
| Interpolation | Beschreibung |
|---|---|
linear |
Bei Elementen, die sich innerhalb des maximalen und minimalen Bereichs befinden, wird die Verstärkung in einer ständig abnehmenden Menge angewendet. "Linear" ist die Standardinterpolation für ein Bewertungsprofil. |
constant |
Für Elemente, die sich innerhalb des Anfangs- und Endbereichs befinden, wird eine konstante Verstärkung auf die Rangfolgeergebnisse angewendet. |
quadratic |
Im Vergleich zur linearen Interpolation, die eine konstant abnehmende Verstärkung aufweist, erfolgt die Abnahme bei „Quadratic“ anfänglich mit geringerer Geschwindigkeit, während zum Bereichsende hin die Abnahme in viel größeren Schritten erfolgt. Diese Interpolationsoption ist in Bewertungsfunktionen für Tags nicht zulässig. |
logarithmic |
Im Vergleich zur linearen Interpolation, die eine konstant abnehmende Verstärkung aufweist, erfolgt die Abnahme bei „Logarithmic“ anfänglich mit höherer Geschwindigkeit, während zum Bereichsende hin die Abnahme in viel kleineren Schritten erfolgt. Diese Interpolationsoption ist in Bewertungsfunktionen für Tags nicht zulässig. |

Festlegen von „boostDuration“ für die Aktualitätsfunktion
boostingDuration ist ein Attribut der Funktion freshness. Sie können damit eine Ablaufdauer festlegen, nach der die Verstärkung für ein bestimmtes Dokument beendet wird. Um beispielsweise eine Produktlinie oder Marke für einen zehntägigen Werbezeitraum zu verstärken, können Sie den zehntägigen Zeitraum für diese Dokumente z. B. als "P10D" angeben.
boostingDuration muss als XSD-Wert "dayTimeDuration" formatiert sein (eine eingeschränkte Teilmenge eines ISO 8601-Zeitdauerwerts). Das Muster hierfür lautet: „P[nD][T[nH][nM][nS]]“.
Die folgende Tabelle enthält einige Beispiele.
| Duration | boostingDuration |
|---|---|
| 1 Tag | "P1D" |
| 2 Tage und 12 Stunden | "P2DT12H" |
| 15 Minuten | "PT15M" |
| 30 Tage, 5 Stunden, 10 Minuten und 6,334 Sekunden | "P30DT5H10M6.334S" |
Weitere Beispiele finden Sie unter XML-Schema: Datentypen (W3.org-Website).
Erweitertes Beispiel für die Vektor- und Hybridsuche
In diesem Blogbeitrag und in diesem Notizbuch finden Sie eine Demonstration der Verwendung von Bewertungsprofilen und Dokumentsteigerungen in Vektor- und generativen KI-Szenarien.
Erweitertes Beispiel für die Stichwortsuche
Im folgenden Beispiel wird das Schema eines Indexes mit zwei Bewertungsprofilen (boostGenre, newAndHighlyRated) gezeigt. Jede Abfrage für diesen Index, die eines der Profile als Abfrageparameter enthält, verwendet das Profil zum Bewerten des Resultsets.
Das Profil boostGenre verwendet gewichtete Textfelder und fördert Übereinstimmungen, die in den Feldern „albumTitle“, „genre“ und „interpretName“ gefunden werden. Die Felder werden jeweils um den Faktor 1,5, 5 und 2 höher gewichtet. Warum wird "genre" so viel stärker als die anderen Felder erhöht? Wird die Suche in relativ homogenen Daten durchgeführt (wie bei „genre“ in musicstoreindex), ist bei den relativen Gewichtungen möglicherweise eine größere Varianz erforderlich. In musicstoreindex ist „rock“ z. B. sowohl als „genre“ als auch in identisch formulierten Genrebeschreibungen aufgeführt. Wenn "genre" schwerer wiegen soll als die Genrebeschreibung, dann benötigt das Feld "genre" eine viel höhere relative Gewichtung.
{
"name": "musicstoreindex",
"fields": [
{ "name": "key", "type": "Edm.String", "key": true },
{ "name": "albumTitle", "type": "Edm.String" },
{ "name": "albumUrl", "type": "Edm.String", "filterable": false },
{ "name": "genre", "type": "Edm.String" },
{ "name": "genreDescription", "type": "Edm.String", "filterable": false },
{ "name": "artistName", "type": "Edm.String" },
{ "name": "orderableOnline", "type": "Edm.Boolean" },
{ "name": "rating", "type": "Edm.Int32" },
{ "name": "tags", "type": "Collection(Edm.String)" },
{ "name": "price", "type": "Edm.Double", "filterable": false },
{ "name": "margin", "type": "Edm.Int32", "retrievable": false },
{ "name": "inventory", "type": "Edm.Int32" },
{ "name": "lastUpdated", "type": "Edm.DateTimeOffset" }
],
"scoringProfiles": [
{
"name": "boostGenre",
"text": {
"weights": {
"albumTitle": 1.5,
"genre": 5,
"artistName": 2
}
}
},
{
"name": "newAndHighlyRated",
"functions": [
{
"type": "freshness",
"fieldName": "lastUpdated",
"boost": 10,
"interpolation": "quadratic",
"freshness": {
"boostingDuration": "P365D"
}
},
{
"type": "magnitude",
"fieldName": "rating",
"boost": 10,
"interpolation": "linear",
"magnitude": {
"boostingRangeStart": 1,
"boostingRangeEnd": 5,
"constantBoostBeyondRange": false
}
}
]
}
],
"suggesters": [
{
"name": "sg",
"searchMode": "analyzingInfixMatching",
"sourceFields": [ "albumTitle", "artistName" ]
}
]
}