Beschreiben eines Service Fabric-Clusters in Azure mithilfe des Clusterressourcen-Managers
Der Clusterressourcen-Manager ist ein Feature von Azure Service Fabric, das verschiedene Methoden zum Beschreiben eines Clusters bereitstellt:
- Fehlerdomänen
- Upgradedomänen
- Knoteneigenschaften
- Knotenkapazitäten
Zur Laufzeit nutzt der Clusterressourcen-Manager diese Informationen, um die Hochverfügbarkeit der Dienste sicherzustellen, die im Cluster ausgeführt werden. Beim Erzwingen dieser wichtigen Regeln wird auch versucht, den Ressourcenverbrauch innerhalb des Clusters zu optimieren.
Fehlerdomänen
Eine Fehlerdomäne ist ein beliebiger Bereich mit einem koordinierten Ausfall. Ein einzelner Computer ist eine Fehlerdomäne. Diese kann aus vielen unterschiedlichen Gründen ausfallen, z. B. infolge eines Stromausfalls oder aufgrund von Laufwerkfehlern oder fehlerhafter NIC-Firmware.
In einer Fehlerdomäne befinden sich alle Computer, die mit demselben Ethernetswitch verbunden sind. Außerdem gehören dieser Domäne Computer an, die über eine gemeinsame Stromversorgung besitzen oder sich an einem Standort befinden.
Da sich Hardwarefehler üblicherweise überschneiden, sind Fehlerdomänen hierarchisch aufgebaut. In Service Fabric sind sie als URIs dargestellt.
Fehlerdomänen müssen unbedingt richtig eingerichtet werden, da Service Fabric diese Informationen nutzt, um Dienste sicher zu platzieren. In Service Fabric soll eine Platzierung von Diensten vermieden werden, bei der der Ausfall einer Fehlerdomäne (aufgrund des Ausfalls einer Komponente) dazu führt, dass ein Dienst nicht mehr verfügbar ist.
In der Azure-Umgebung nutzt Service Fabric die von der Umgebung bereitgestellten Fehlerdomäneninformationen, um die Knoten im Cluster in Ihrem Auftrag richtig zu konfigurieren. Für eigenständige Service Fabric-Instanzen werden Fehlerdomänen zum Zeitpunkt der Clustereinrichtung definiert.
Warnung
Die Fehlerdomäneninformationen für Service Fabric müssen korrekt sein. Angenommen, die Knoten Ihres Service Fabric-Clusters werden auf zehn VMs ausgeführt, die auf fünf physischen Hosts betrieben werden. In diesem Fall gibt es trotz der zehn VMs lediglich fünf verschiedene Fehlerdomänen (der obersten Ebene). Die gemeinsame Verwendung eines physischen Hosts bewirkt, dass VMs dieselbe Stammfehlerdomäne gemeinsam nutzen, da die VMs bei einem Ausfall ihres physischen Hosts koordiniert ausfallen.
In Service Fabric ist nicht vorgesehen, dass sich Fehlerdomänen eines Knotens ändern. Dies liegt daran, dass andere Mechanismen, mit denen die Hochverfügbarkeit von VMs sichergestellt wird (etwa im Fall von Hochverfügbarkeits-VMs), zu Konflikten mit Service Fabric führen könnten. Bei diesen Mechanismen wird eine transparente Migration von VMs zwischen Hosts eingesetzt. Der ausgeführte Code wird dabei in der VM weder neu konfiguriert noch benachrichtigt. Derartige Mechanismen werden deswegen nicht als Grundlage für Umgebungen unterstützt, in denen Service Fabric-Cluster betrieben werden.
Service Fabric sollte die einzige eingesetzte Hochverfügbarkeitstechnologie sein. Mechanismen wie die Livemigration von VMs und SANs sind nicht erforderlich. Wenn diese in Verbindung mit Service Fabric verwendet werden, verringern sie die Verfügbarkeit und Zuverlässigkeit einer Anwendung. Der Grund dafür ist, dass sie zu zusätzlicher Komplexität führen, zentrale Fehlerquellen hinzufügen und Zuverlässigkeits- sowie Verfügbarkeitsstrategien nutzen, die mit denen von Service Fabric kollidieren.
In der Grafik unten sind alle Entitäten farbig markiert, die die Struktur von Fehlerdomänen beeinflussen, und alle unterschiedlichen Fehlerdomänen aufgeführt, die sich ergeben. Dieses Beispiel enthält Datencenter („DC“), Racks („R“) und Blades („B“). Wenn jedes Blade mehrere virtuelle Computer enthält, kann die Fehlerdomänenhierarchie eine weitere Ebene umfassen.
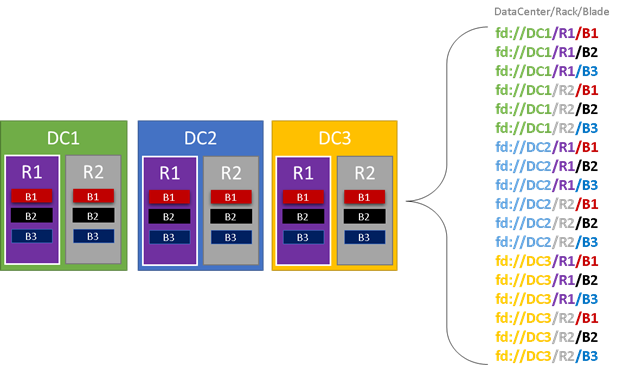
Zur Laufzeit berücksichtigt der Clusterressourcen-Manager von Service Fabric die Fehlerdomänen im Cluster und plant Layouts. Die zustandsbehafteten Replikate oder zustandslosen Instanzen für einen Dienst werden so verteilt, dass sie sich in separaten Fehlerdomänen befinden. Das Verteilen des Diensts in mehreren Fehlerdomänen stellt sicher, dass seine Verfügbarkeit nicht beeinträchtigt wird, wenn eine Fehlerdomäne auf einer beliebigen Ebene der Hierarchie ausfällt.
Für den Clusterressourcen-Manager spielt es keine Rolle, wie viele Ebenen die Hierarchie der Fehlerdomäne umfasst. Es wird aber versucht, sicherzustellen, dass sich der Ausfall eines Teils der Hierarchie nicht auf die darin ausgeführten Dienste auswirkt.
Es empfiehlt sich, dass jede Ebene der Fehlerdomänenhierarchie die gleiche Anzahl von Knoten enthält. Wenn die Struktur der Fehlerdomänen in Ihrem Cluster nicht ausgeglichen ist, ist es für den Clusterressourcen-Manager schwieriger, die beste Zuordnung für die Dienste zu ermitteln. Fehlerdomänenlayouts mit ungleichmäßiger Verteilung haben zur Folge, dass sich der Ausfall bestimmter Domänen stärker auf die Verfügbarkeit von Diensten auswirkt als der anderer Domänen. So kommt es für den Clusterressourcen-Manager zu einem Konflikt zwischen zwei Zielen:
- Die Computer in der stark ausgelasteten Domäne sollen einerseits genutzt werden, indem Dienste darin platziert werden.
- Andererseits sollen die Dienste so in anderen Domänen platziert werden, dass der Ausfall einer Domäne nicht zu Problemen führt.
Wie sehen nicht ausgeglichene Domänen aus? Im folgenden Diagramm werden zwei verschiedene Clusterlayouts abgebildet. Im ersten Beispiel werden die Knoten gleichmäßig auf die Fehlerdomänen verteilt. Im zweiten Beispiel verfügt eine Fehlerdomäne über mehr Knoten als die anderen Fehlerdomänen.
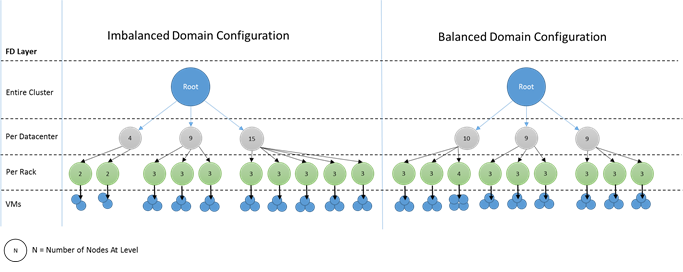
In Azure wird die Zuordnung eines Knotens zu einer bestimmten Fehlerdomäne automatisch vorgenommen. Je nach der Anzahl der Knoten, die Sie bereitstellen, kann es aber dennoch dazu kommen, dass einige Fehlerdomänen mehr Knoten als andere enthalten.
Angenommen, Sie verfügen über fünf Fehlerdomänen im Cluster, stellen für einen Knotentyp (NodeType) aber sieben Knoten bereit. In diesem Fall verfügen die ersten beiden Fehlerdomänen über eine größere Anzahl von Knoten. Das Problem verschlimmert sich, wenn Sie damit fortfahren, mehr NodeType-Instanzen mit nur wenigen Instanzen bereitzustellen. Daher empfiehlt es sich, die Anzahl der Knoten in jedem Knotentyp so festzulegen, dass diese ein Vielfaches der Anzahl der Fehlerdomänen betragen.
Upgradedomänen
Upgradedomänen sind ein weiteres Feature, mit dem der Clusterressourcen-Manager von Service Fabric das Layout des Clusters nachvollziehen kann. Mit Upgradedomänen werden Knotengruppen definiert, für die gleichzeitig Upgrades durchgeführt werden. Mithilfe von Upgradedomänen kann der Clusterressourcen-Manager Verwaltungsvorgänge wie Upgrades nachvollziehen und orchestrieren.
Upgradedomänen sind mit Fehlerdomänen vergleichbar. Es gibt jedoch einige wichtige Unterschiede. Zunächst werden Fehlerdomänen durch Bereiche von koordinierten Hardwarefehlern definiert. Upgradedomänen hingegen werden per Richtlinie definiert. Die Anzahl dieser Domänen wird nicht von der Umgebung, sondern von Ihnen vorgegeben. Sie können genauso viele Upgradedomänen wie Knoten besitzen. Ein weiterer Unterschied zwischen Fehlerdomänen und Upgradedomänen besteht darin, dass Upgradedomänen nicht hierarchisch angeordnet sind. Stattdessen ähneln sie mehr einem einfachen Tag.
Das folgende Diagramm zeigt drei Upgradedomänen, die auf drei Fehlerdomänen verteilt sind. Außerdem ist eine mögliche Platzierung für drei unterschiedliche Replikate eines zustandsbehafteten Diensts dargestellt, die jeweils in unterschiedlichen Fehler- und Upgradedomänen angeordnet werden. Bei dieser Platzierung ist selbst bei einem Ausfall einer Fehlerdomäne während eines Dienstupgrades eine Kopie des Codes und der Daten vorhanden.
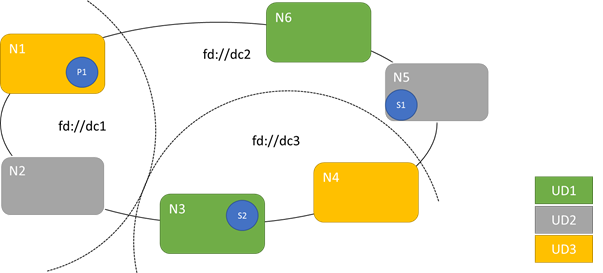
Die Verwendung einer größeren Anzahl von Upgradedomänen hat Vor- und Nachteile. Mit einer größeren Anzahl von Upgradedomänen wird jeder Schritt des Upgrades präziser und wirkt sich daher auf eine kleinere Anzahl von Knoten oder Diensten aus. Da weniger Dienste auf einmal verschoben werden müssen, sind weniger Systemänderungen erforderlich. Dies bewirkt meist eine Verbesserung der Zuverlässigkeit, da ein kleinerer Bereich des Diensts von Problemen betroffen ist, die während des Upgrades auftreten. Eine höhere Anzahl von Upgradedomänen bedeutet auch, dass Sie einen geringeren verfügbaren Puffer auf anderen Knoten vorhalten müssen, um die Auswirkungen des Upgrades verarbeiten zu können.
Wenn Sie beispielsweise über fünf Upgradedomänen verfügen, verarbeiten die Knoten jeder Domäne ca. 20 % des Datenverkehrs. Wenn Sie diese Upgradedomäne für ein Upgrade außer Betrieb nehmen müssen, muss diese Last üblicherweise verlagert werden können. Da Sie über vier verbleibende Upgradedomänen verfügen, muss jede von ihnen ca. 25 % des Gesamtdatenverkehrs aufnehmen können. Eine höhere Anzahl von Upgradedomänen bedeutet, dass Sie einen kleineren Puffer auf den Knoten im Cluster benötigen.
Angenommen, Sie verfügen nun über zehn Upgradedomänen. In diesem Fall muss jede Upgradedomäne nur etwa zehn Prozent des Gesamtdatenverkehrs verarbeiten. Wenn ein Upgrade den Cluster nach und nach durchläuft, benötigt jede Domäne nur Kapazitäten für ca. 11 % des Gesamtdatenverkehrs. Eine größere Anzahl von Upgradedomänen ermöglicht Ihnen den Betrieb Ihrer Knoten mit höherer Auslastung, da weniger Reservekapazität erforderlich ist. Dasselbe gilt für Fehlerdomänen.
Der Nachteil bei der Verwendung vieler Upgradedomänen ist, dass Upgrades oft länger dauern. Service Fabric wartet nach der Fertigstellung einer Upgradedomäne einen kurzen Zeitraum und führt Überprüfungen durch, bevor mit dem Upgrade der nächsten Domäne begonnen wird. Diese Verzögerungen ermöglichen es, etwaige durch das Upgrade bewirkte Probleme zu erkennen, bevor mit dem Upgradevorgang fortgefahren wird. Dieser Kompromiss ist akzeptabel, da dadurch verhindert wird, dass sich negative Änderungen jeweils auf einen zu großen Teil des Diensts auswirken.
Wenn zu wenige Upgradedomänen vorhanden sind, hat dies viele negative Auswirkungen. Da eine Upgradedomäne während eines Upgrades nicht verwendet werden kann, ist ein Großteil der Gesamtkapazität in diesem Zeitraum nicht verfügbar. Wenn Sie beispielsweise nur drei Upgradedomänen besitzen, nehmen Sie jeweils etwa ein Drittel der Dienst- oder Clustergesamtkapazität außer Betrieb. Es ist nicht wünschenswert, dass so ein großer Teil Ihres Diensts auf einmal nicht betriebsbereit ist, da im restlichen Cluster genügend Kapazität für die Verarbeitung der Workload vorhanden sein muss. Eine Verwaltung eines solchen Puffers bedeutet, dass die betreffenden Knoten während des Normalbetriebs in geringerem Umfang genutzt werden können, als dies sonst der Fall wäre. Dadurch steigen die Kosten für die Ausführung des Diensts.
Es gibt keine tatsächliche Beschränkung bei der Gesamtanzahl der Fehler- oder Upgradedomänen in einer Umgebung bzw. keine Einschränkungen in Bezug auf ihre Überlappung. Es gibt jedoch allgemeine Muster:
- 1:1-Zuordnung von Fehlerdomänen und Upgradedomänen
- Eine Upgradedomäne pro Knoten (physische oder virtuelle Betriebssysteminstanz)
- Ein „Stripeset“- oder „Matrix“-Modell, bei dem die Fehler- und Upgradedomänen eine Matrix bilden, in der die Computer normalerweise entlang der Diagonalen angeordnet sind
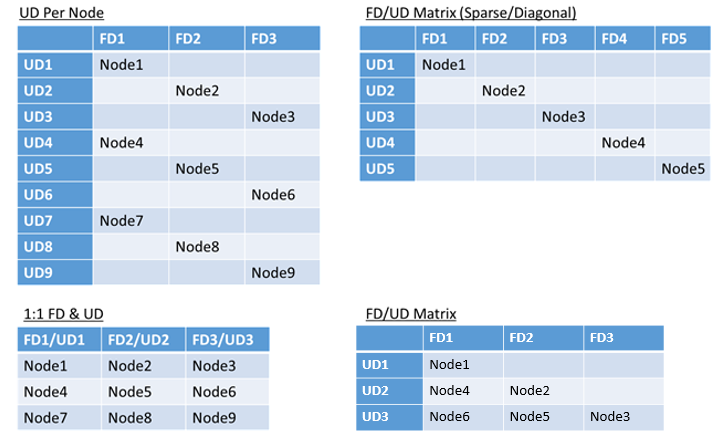
Es gibt keine allgemeingültige Empfehlung für die Auswahl des Layouts. Jede Möglichkeit hat ihre Vor- und Nachteile. Das 1FD:1U-Modell ist beispielsweise einfach einzurichten. Das Modell „Eine Upgradedomäne pro Knoten“ ist wahrscheinlich das gängigste Modell. Während eines Upgrades wird jeder Knoten unabhängig aktualisiert. Dies ähnelt früheren Situationen, in denen für kleine Gruppen von Computern manuell ein Upgrade ausgeführt wurde.
Das am häufigsten verwendete Modell ist die FD/UD-Matrix, bei der die Fehlerdomänen und Upgradedomänen eine Tabelle bilden und die Knoten am Anfang der Diagonalen angeordnet sind. Dies ist das Modell, das in Service Fabric-Clustern in Azure standardmäßig verwendet wird. Bei Clustern mit vielen Knoten entspricht das Gesamtbild anschließend einem dichten Matrixmuster.
Hinweis
In Azure gehostete Service Fabric-Cluster unterstützten keine Änderung der Standardstrategie. Nur eigenständige Cluster stellen diese Anpassungsmöglichkeit bereit.
Einschränkungen und daraus resultierendes Verhalten von Fehler- und Upgradedomänen
Standardansatz
Standardmäßig behält der Clusterressourcen-Manager die ausgewogene Verteilung der Dienste auf Fehler- und Upgradedomänen bei. Dies wird als Einschränkung simuliert. Für Fehler- und Upgradedomänen lautet diese wie folgt: „Für eine bestimmte Dienstpartition sollte sich die Anzahl der Dienstobjekte (zustandslose Dienstinstanzen oder zustandsbehaftete Dienstreplikate) zwischen Domänen auf derselben Hierarchieebene nie um mehr als eins unterscheiden.“
Nehmen wir an, dass diese Einschränkung eine „maximale Differenz“ garantiert. Die Einschränkung für die Fehler- und Upgradedomänen verhindert bestimmte Verschiebungen oder Anordnungen, die die Regel verletzen.
Angenommen, wir verwenden einen Cluster mit sechs Knoten, für die fünf Fehlerdomänen und fünf Upgradedomänen konfiguriert wurden.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N3 | ||||
| UD3 | N4 | ||||
| UD4 | N5 |
Angenommen, wir erstellen nun einen Dienst und legen für TargetReplicaSetSize (bzw. für InstanceCount im Fall eines zustandslosen Diensts) den Wert fünf fest. Die Replikate (R) werden auf den Knoten N1-N5 gespeichert. N6 wird unabhängig von der Anzahl der erstellten Dienste tatsächlich niemals verwendet. Warum ist das so? Wir betrachten den Unterschied zwischen dem aktuellen Layout und dem Fall, in dem N6 gewählt wird.
Im Folgenden sehen Sie das Layout und die Gesamtzahl der Replikate pro Fehler- und Upgradedomäne:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | 1 | ||||
| UD3 | R4 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Dieses Layout ist in Bezug auf die Knoten pro Fehler- und Upgradedomäne ausgeglichen. Zusätzlich ist es in Bezug auf die Anzahl der Replikate pro Fehler- und Upgradedomäne ausgeglichen. Jede Domäne verfügt über die gleiche Anzahl von Knoten und die gleiche Anzahl von Replikaten.
Nun sehen wir uns an, was passieren würde, wenn wir N6 anstelle von N2 verwenden würden. Wie wären die Replikate dann verteilt?
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R5 | 1 | ||||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 2 | 0 | 1 | 1 | 1 | - |
Dieses Layout verstößt gegen die Definition der „maximalen Differenz“ für die Fehlerdomäneneinschränkung. In FD0 befinden sich zwei Replikate, in FD1 hingegen gar keine. Der Unterschied zwischen FD0 und FD1 beträgt zwei und überschreitet damit die maximale Differenz von eins. Da die Einschränkung verletzt wird, lässt der Clusterressourcen-Manager diese Anordnung nicht zu.
Wenn wir N2 und N6 (anstelle von N1 und N2) auswählen, erhalten wir Folgendes:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | 0 | |||||
| UD1 | R5 | R1 | 2 | |||
| UD2 | R2 | 1 | ||||
| UD3 | R3 | 1 | ||||
| UD4 | R4 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Dieses Layout ist in Bezug auf Fehlerdomänen ausgeglichen. Allerdings verletzt es jetzt die Upgradedomäneneinschränkung, da UD0 keine Replikate aufweist, UD1 hingegen zwei. Daher ist dieses Layout ebenfalls ungültig und wird vom Clusterressourcen-Manager nicht ausgewählt.
Dieser Ansatz zur Verteilung zustandsbehafteter Replikate oder zustandsloser Instanzen bietet die bestmögliche Fehlertoleranz. Wenn eine Domäne ausfällt, fällt die kleinstmögliche Anzahl von Replikaten und Instanzen aus.
Andererseits kann dieser Ansatz zu streng sein und dem Cluster nicht die Nutzung aller Ressourcen erlauben. Bei bestimmten Clusterkonfigurationen können bestimmte Knoten nicht verwendet werden. Dies kann dazu führen, dass Service Fabric Ihre Dienste nicht platziert, was zu Warnmeldungen führt. Im vorherigen Beispiel können einige der Clusterknoten nicht verwendet werden (im Beispiel N6). Auch wenn Sie diesem Cluster Knoten hinzufügen würden (N7 bis N10), würden Replikate und Instanzen aufgrund der Fehler- und Upgradedomäneneinschränkungen nur auf N1 bis N5 platziert werden.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | N10 | |||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N9 | N5 |
Alternativer Ansatz
Der Clusterressourcen-Manager unterstützt für Fehler- und Upgradedomänen eine weitere Einschränkungsversion. Diese ermöglicht eine Platzierung und garantiert gleichzeitig ein Mindestmaß an Sicherheit. Die alternative Einschränkung kann wie folgt formuliert werden: „Für eine bestimmte Dienstpartition sollte die domänenübergreifende Replikatverteilung sicherstellen, dass die Partition keinem Quorumverlust unterliegt.“ Nehmen wir an, dass diese Einschränkung eine „Quorumsicherheit“ garantiert.
Hinweis
Für einen zustandsbehafteten Dienst definieren wir den Quorumsverlust in einer Situation, wo der überwiegende Teil der Partitionsreplikate zur gleichen Zeit außer Betrieb ist. Wenn z. B. TargetReplicaSetSize fünf beträgt, stellt eine Gruppe mit drei Replikaten das Quorum dar. Wenn TargetReplicaSetSize sechs beträgt, sind dementsprechend vier Replikate für das Quorum erforderlich. In beiden Fällen können nicht mehr als zwei Replikate zur gleichen Zeit außer Betrieb sein, damit die Partition noch ordnungsgemäß funktioniert.
Im Fall eines zustandslosen Diensts gibt es keinen Quorumverlust. Zustandslose Dienste werden auch dann weiterhin ordnungsgemäß ausgeführt, wenn mehr als die Hälfte der Instanzen gleichzeitig ausfällt. Darum konzentrieren wir uns im weiteren Verlauf des Artikels auf zustandsbehaftete Dienste.
Wir kehren zum vorherigen Beispiel zurück. Mit der „quorumsicheren“ Version der Einschränkung würden alle drei Layouts gültig sein. Selbst bei einem Ausfall von FD0 im zweiten Layout oder UD1 im dritten Layout würde die Partition noch über ein Quorum verfügen würde, und der überwiegende Teil der Replikate wäre noch funktionsfähig. Mit dieser Version der Einschränkung kann N6 fast immer genutzt werden.
Der „quorumsichere“ Ansatz bietet mehr Flexibilität als die Strategie der „maximalen Differenz“. Dies liegt daran, dass es einfacher ist, Replikatverteilungen zu finden, die in fast allen Clustertopologien gültig sind. Allerdings kann dieser Ansatz nicht die besten Fehlertoleranzeigenschaften garantieren, da manche Ausfälle schlimmer sind als andere.
Im schlimmsten Fall kann der überwiegende Teil der Replikate mit dem Ausfall einer Domäne und eines zusätzlichen Replikats verlorengehen. Sie können z. B. anstatt mit drei Ausfällen, die bei fünf Replikaten oder Instanzen für einen Quorumverlust erforderlich sind, jetzt mit nur zwei Ausfällen den überwiegenden Teil verlieren.
Adaptiver Ansatz
Da beide Ansätze Stärken und Schwächen aufweisen, wurde ein adaptiver Ansatz eingeführt, der diese beiden Strategien kombiniert.
Hinweis
Dies ist das Standardverhalten ab Version 6.2 von Service Fabric.
Der adaptive Ansatz nutzt in der Standardeinstellung die Logik der „maximalen Differenz“ und wechselt nur bei Bedarf zur „quorumsicheren“ Logik. Der Clusterressourcen-Manager ermittelt automatisch anhand der Konfiguration von Clustern und Diensten, welche Strategie erforderlich ist.
Der Clusterressourcen-Manager sollte die „quorumbasierte“ Logik für einen Dienst verwenden, wenn die folgenden beiden Bedingungen erfüllt sind:
- Der Wert von TargetReplicaSetSize muss durch die Anzahl der Fehlerdomänen und die Anzahl der Upgradedomänen teilbar sein.
- Die Anzahl der Knoten muss kleiner oder gleich der Zahl sein, die sich aus der Anzahl der Fehlerdomänen multipliziert mit der Anzahl der Upgradedomänen ergibt.
Bedenken Sie, dass der Clusterressourcen-Manager diesen Ansatz für zustandslose und zustandsbehaftete Dienste verwendet, obwohl der Quorumverlust für zustandslose Dienste nicht relevant ist.
Im Folgenden gehen wir vom vorherigen Beispiel aus, nehmen nun jedoch an, dass sich im Cluster acht Knoten befinden. Der Cluster ist immer noch mit fünf Fehlerdomänen und fünf Upgradedomänen konfiguriert. Auch der TargetReplicaSetSize-Wert für einen Dienst, der in diesem Cluster gehostet ist, beträgt nach wie vor fünf.
| FD0 | FD1 | FD2 | FD3 | FD4 | |
|---|---|---|---|---|---|
| UD0 | N1 | ||||
| UD1 | N6 | N2 | |||
| UD2 | N7 | N3 | |||
| UD3 | N8 | N4 | |||
| UD4 | N5 |
Da alle erforderlichen Bedingungen erfüllt sind, nutzt der Clusterressourcen-Manager die „quorumbasierte“ Logik bei der Verteilung des Diensts. Dies ermöglicht die Verwendung von N6 bis N8. Eine mögliche Dienstverteilung könnte in diesem Fall wie folgt aussehen:
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | R1 | 1 | ||||
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | 0 | |||||
| UD4 | R5 | 1 | ||||
| FDTotal | 2 | 1 | 1 | 0 | 1 | - |
Wenn der TargetReplicaSetSize-Wert Ihres Diensts beispielsweise auf vier verringert wird, erkennt der Clusterressourcen-Manager diese Änderung. Daraufhin wechselt er wieder zur Logik der „maximalen Differenz“, da TargetReplicaSetSize nicht mehr durch die Anzahl der Fehlerdomänen und Upgradedomänen teilbar ist. Das Ergebnis sind Replikatverschiebungen, bei denen die verbleibenden vier Replikate auf die Knoten N1 bis N5 verteilt werden. Auf diese Weise wird die Logik der „maximalen Differenz“ für Fehler- und Upgradedomänen nicht verletzt.
Wenn im vorherigen Layout der TargetReplicaSetSize-Wert fünf beträgt und N1 aus dem Cluster entfernt wird, beträgt die Anzahl der Upgradedomänen vier. Erneut beginnt der Clusterressourcen-Manager mit der Verwendung der Logik der „maximalen Differenz“, da der TargetReplicaSetSize-Wert des Diensts nicht mehr durch die Anzahl der Upgradedomänen teilbar ist. Daher muss Replikat R1 beim erneuten Erstellen auf N4 untergebracht werden, sodass die Einschränkung für die Fehler- und Upgradedomäne nicht verletzt wird.
| FD0 | FD1 | FD2 | FD3 | FD4 | UDTotal | |
|---|---|---|---|---|---|---|
| UD0 | – | – | – | – | – | – |
| UD1 | R2 | 1 | ||||
| UD2 | R3 | R4 | 2 | |||
| UD3 | R1 | 1 | ||||
| UD4 | R5 | 1 | ||||
| FDTotal | 1 | 1 | 1 | 1 | 1 | - |
Konfigurieren von Fehler- und Upgradedomänen
In Azure gehosteten Service Fabric-Bereitstellungen werden Fehler- und Upgradedomänen automatisch definiert. Service Fabric wählt die Umgebungsinformationen von Azure und verwendet sie.
Wenn Sie Ihren eigenen Cluster erstellen (oder eine bestimmte Topologie ausführen möchten, die sich in der Entwicklung befindet), können Sie die Informationen für die Fehler- und Upgradedomänen selbst angeben. Im folgenden Beispiel definieren wir einen lokalen Entwicklungscluster mit neun Knoten, der drei Datencenter (mit jeweils drei Racks) umfasst. Dieser Cluster verfügt auch über drei Upgradedomänen, die auf diese drei Datencenter verteilt sind. Im Folgenden sehen Sie eine Beispielkonfiguration, die sich in der Datei „ClusterManifest.xml“ befindet:
<Infrastructure>
<!-- IsScaleMin indicates that this cluster runs on one box/one single server -->
<WindowsServer IsScaleMin="true">
<NodeList>
<Node NodeName="Node01" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType01" FaultDomain="fd:/DC01/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node02" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType02" FaultDomain="fd:/DC01/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node03" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType03" FaultDomain="fd:/DC01/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node04" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType04" FaultDomain="fd:/DC02/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node05" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType05" FaultDomain="fd:/DC02/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node06" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType06" FaultDomain="fd:/DC02/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
<Node NodeName="Node07" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType07" FaultDomain="fd:/DC03/Rack01" UpgradeDomain="UpgradeDomain1" IsSeedNode="true" />
<Node NodeName="Node08" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType08" FaultDomain="fd:/DC03/Rack02" UpgradeDomain="UpgradeDomain2" IsSeedNode="true" />
<Node NodeName="Node09" IPAddressOrFQDN="localhost" NodeTypeRef="NodeType09" FaultDomain="fd:/DC03/Rack03" UpgradeDomain="UpgradeDomain3" IsSeedNode="true" />
</NodeList>
</WindowsServer>
</Infrastructure>
Im folgenden Beispiel wird „ClusterConfig.json“ für eigenständige Bereitstellungen verwendet:
"nodes": [
{
"nodeName": "vm1",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm2",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm3",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc1/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm4",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm5",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm6",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc2/r0",
"upgradeDomain": "UD3"
},
{
"nodeName": "vm7",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD1"
},
{
"nodeName": "vm8",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD2"
},
{
"nodeName": "vm9",
"iPAddress": "localhost",
"nodeTypeRef": "NodeType0",
"faultDomain": "fd:/dc3/r0",
"upgradeDomain": "UD3"
}
],
Hinweis
Wenn Sie über den Azure Resource Manager Cluster definieren, weist Azure Fehler- und Upgradedomänen zu. Deshalb umfasst die Definition von Knotentypen und VM-Skalierungsgruppen in Ihrer Azure Resource Manager-Vorlage keine Informationen zu Fehler- oder Upgradedomänen.
Knoteneigenschaften und Platzierungseinschränkungen
In den meisten Fällen müssen Sie sicherstellen, dass bestimmte Workloads nur auf bestimmten Knotentypen im Cluster ausgeführt werden. Beispielsweise ist es möglich, dass nur für bestimmte Workloads GPUs oder SSDs erforderlich sind.
Nahezu jede n-schichtige Architektur eignet sich als Beispiel für die Ausrichtung von Hardware auf bestimmte Workloads. Bestimmte Computer werden von der Anwendung als Front-End oder zur Bereitstellung der API verwendet und sind für die Clients oder das Internet verfügbar. Unterschiedliche Computer (häufig mit unterschiedlichen Hardwareressourcen) verarbeiten die Workload der Compute- oder Speicherebenen. Diese sind normalerweise nicht direkt für Clients oder das Internet verfügbar.
In Service Fabric wird davon ausgegangen, dass Situationen eintreten, in denen bestimmte Workloads in bestimmten Hardwarekonfigurationen ausgeführt werden müssen. Beispiel:
- Eine vorhandene n-schichtige Anwendung wurde per Lift & Shift in eine Service Fabric-Umgebung verschoben.
- Eine Workload muss aus Gründen der Leistung, Skalierbarkeit oder Sicherheitsisolation auf einer bestimmten Hardware ausgeführt werden.
- Eine Workload sollte aufgrund von Richtlinien oder des Ressourcenverbrauchs von anderen Workloads isoliert werden.
Service Fabric unterstützt diese Konfigurationen durch Tags, die Sie auf Knoten anwenden können. Diese Tags werden als Knoteneigenschaften bezeichnet. Platzierungseinschränkungen sind die Anweisungen, die an einzelne Dienste angefügt sind. Diese Anweisungen wählen Sie für mindestens eine Knoteneigenschaft aus. Platzierungseinschränkungen definieren, an welcher Stelle Dienste ausgeführt werden sollen. Die Einschränkungen sind erweiterbar. Dafür können beliebige Schlüssel-Wert-Paare verwendet werden.
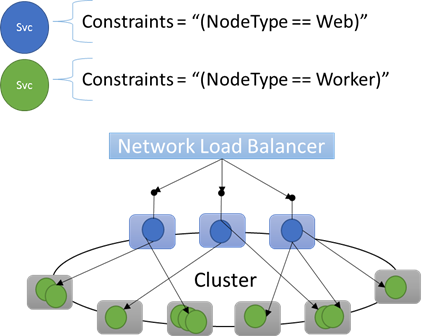
Integrierte Knoteneigenschaften
In Service Fabric werden einige Standardknoteneigenschaften definiert, die automatisch verwendet werden können, ohne vorher festgelegt werden zu müssen. Für jeden Knoten sind die Standardeigenschaften NodeType und NodeName definiert.
Sie können beispielsweise folgende Platzierungseinschränkung schreiben: "(NodeType == NodeType03)". NodeType ist eine häufig verwendete Eigenschaft. Sie ist hilfreich, da sie eindeutig dem Typ eines Computers entspricht. Jeder Computertyp wiederum entspricht einem Typ von Workload in einer herkömmlichen n-schichtigen Anwendung.
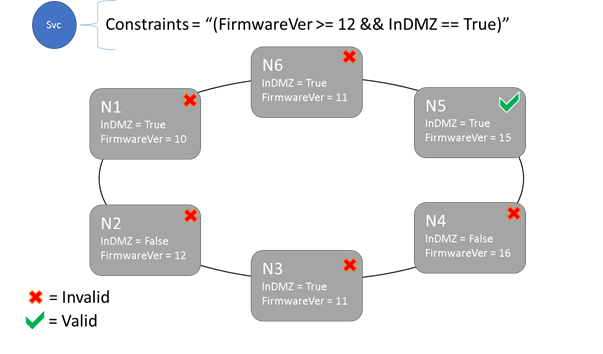
Syntax von Platzierungseinschränkungen und Knoteneigenschaften
Der Wert in der Knoteneigenschaft kann als Zeichenfolge, boolescher Wert oder als Wert des Typs „signed long“ angegeben werden. Die Anweisung im Dienst wird als Platzierungseinschränkung bezeichnet, weil damit eingeschränkt wird, wo der Dienst im Cluster ausgeführt werden kann. Bei der Einschränkung kann es sich um eine boolesche Anweisung handeln, die für die Knoteneigenschaften im Cluster ausgeführt wird. Die gültigen Selektoren in diesen booleschen Anweisungen lauten:
Bedingungsüberprüfungen zum Erstellen bestimmter Anweisungen:
-Anweisung. Syntax "equal to" (ist gleich) "==" "not equal to" (ungleich) "!=" "greater than" (größer als) ">" "greater than or equal to" (größer als oder gleich) ">=" "less than" (kleiner als) "<" "less than or equal to" (kleiner als oder gleich) "<=" Boolesche Anweisungen für Gruppierungen und logische Vorgänge:
-Anweisung. Syntax "and" (und) "&&" "or" (oder) "||" "not" (nicht) "!" "group as single statement" (Als einzelne Anweisung gruppieren) "()"
Im Folgenden sehen Sie einige Beispiele für Anweisungen von Basiseinschränkungen:
"Value >= 5""NodeColor != green""((OneProperty < 100) || ((AnotherProperty == false) && (OneProperty >= 100)))"
Nur auf Knoten, bei denen die Anweisung der Platzierungseinschränkung insgesamt als „True“ ausgewertet wird, kann ein Dienst platziert werden. Für Knoten ohne eine Eigenschaft kann keine Übereinstimmung mit einer Platzierungseinschränkung ermittelt werden, die die Eigenschaft enthält.
Angenommen, die folgenden Knoteneigenschaften für einen Knotentyp wurden in „ClusterManifest.xml“ definiert:
<NodeType Name="NodeType01">
<PlacementProperties>
<Property Name="HasSSD" Value="true"/>
<Property Name="NodeColor" Value="green"/>
<Property Name="SomeProperty" Value="5"/>
</PlacementProperties>
</NodeType>
Im folgenden Beispiel werden Knoteneigenschaften gezeigt, die sich bei eigenständigen Bereitstellungen in „ClusterConfig.json“ und bei Clustern, die in Azure gehostet sind, in „Template.json“ befinden.
Hinweis
In der Azure Resource Manager-Vorlage ist der Knotentyp üblicherweise parametrisiert. Er liegt nicht als „NodeType01“, sondern in der Form "[parameters('vmNodeType1Name')]" vor.
"nodeTypes": [
{
"name": "NodeType01",
"placementProperties": {
"HasSSD": "true",
"NodeColor": "green",
"SomeProperty": "5"
},
}
],
Sie können Dienstplatzierungseinschränkungen für einen Dienst wie folgt erstellen:
FabricClient fabricClient = new FabricClient();
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
serviceDescription.PlacementConstraints = "(HasSSD == true && SomeProperty >= 4)";
// Add other required ServiceDescription fields
//...
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceType -Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementConstraint "HasSSD == true && SomeProperty >= 4"
Wenn alle Knoten des Typs „NodeType01“ gültig sind, können Sie diesen Knotentyp auch mit der Einschränkung "(NodeType == NodeType01)" auswählen.
Platzierungseinschränkungen eines Diensts können während der Laufzeit dynamisch aktualisiert werden. Falls erforderlich, können Sie beispielsweise einen Dienst im Cluster verschieben oder Anforderungen hinzufügen und entfernen. Service Fabric stellt sicher, dass der Dienst einsatzbereit und verfügbar bleibt, selbst wenn diese Änderungen ausgeführt werden.
StatefulServiceUpdateDescription updateDescription = new StatefulServiceUpdateDescription();
updateDescription.PlacementConstraints = "NodeType == NodeType01";
await fabricClient.ServiceManager.UpdateServiceAsync(new Uri("fabric:/app/service"), updateDescription);
Update-ServiceFabricService -Stateful -ServiceName $serviceName -PlacementConstraints "NodeType == NodeType01"
Platzierungseinschränkungen werden für jede benannte Dienstinstanz angegeben. Updates ersetzen (überschreiben) immer die vorherige Angabe.
Die Clusterdefinition definiert die Eigenschaften für einen Knoten. Werden die Eigenschaften eines Knotens geändert, ist ein Upgrade der Clusterkonfiguration erforderlich. Beim Durchführen eines Upgrades für Knoteneigenschaften muss jeder betroffene Knoten neu gestartet werden, sodass seine neuen Eigenschaften gemeldet werden. Diese parallelen Upgrades werden von Service Fabric verwaltet.
Beschreiben und Verwalten von Clusterressourcen
Eine der wichtigsten Aufgaben eines Orchestrators besteht in der Verwaltung des Ressourcenverbrauchs im Cluster. Das Verwalten von Clusterressourcen kann viele verschiedene Aspekte umfassen.
Zunächst ist sicherstellen, dass die Computer nicht überlastet werden. Das heißt, es muss dafür gesorgt werden, dass auf Computern nicht mehr Dienste ausgeführt werden, als sie bewältigen können.
Zusätzlich sind Lastenausgleiche und Optimierungen erforderlich. Diese sind unverzichtbar, damit Dienste effizient ausgeführt werden. Kosteneffiziente oder leistungsabhängige Dienstangebote lassen nicht zu, dass einige Knoten stark und andere nur gering ausgelastet werden. Stark ausgelastete Knoten führen zu Ressourcenkonflikten und schlechter Leistung. Knoten mit geringer Auslastung führen zur Verschwendung von Ressourcen und zu höheren Kosten.
Service Fabric stellt Ressourcen als Metriken dar. Bei Metriken handelt es sich um alle logischen oder physischen Ressourcen, die Sie für Service Fabric beschreiben möchten. Beispiele für Metriken sind „WorkQueueDepth“ oder „MemoryInMb“. Informationen zu den physischen Ressourcen, die von Service Fabric auf Knoten verwaltet werden können, finden Sie unter Ressourcenkontrolle. Informationen zu den Standardmetriken, die vom Clusterressourcen-Manager verwendet werden, sowie zum Konfigurieren von benutzerdefinierten Metriken finden Sie in diesem Artikel.
Metriken unterscheiden sich von Platzierungseinschränkungen und Knoteneigenschaften. Knoteneigenschaften sind statische Deskriptoren der Knoten. Metriken beschreiben die Ressourcen, über die Knoten verfügen und die von Diensten genutzt werden, wenn sie auf einem Knoten ausgeführt werden. Eine Knoteneigenschaft ist beispielsweise HasSSD. Diese kann auf „true“ oder „false“ festgelegt werden. Die Menge des verfügbaren Speicherplatzes auf dieser SSD und der von Diensten verwendete Speicher kann eine Metrik wie „DriveSpaceInMb“ sein.
Der Clusterressourcen-Manager von Service Fabric kann die Namen von Metriken ebenso wenig interpretieren wie Platzierungseinschränkungen und Knoteneigenschaften. Bei Namen von Metriken handelt es sich lediglich um Zeichenfolgen. Falls die Gefahr von Mehrdeutigkeiten besteht, sollten Sie Einheiten als Teil der von Ihnen erstellten Metriknamen deklarieren.
Capacity
Wenn Sie den Lastenausgleichfür alle Ressourcen deaktivieren, kann der Clusterressourcen-Manager von Service Fabric dennoch versuchen sicherzustellen, dass kein Knoten überlastet wird. Das Verwalten von Kapazitätsüberläufen ist möglich, es sei denn, der Cluster ist zu belegt und die Workload ist größer als jeder einzelne Knoten. Die Kapazität ist eine weitere Einschränkung, anhand der der Clusterressourcen-Manager ermittelt, wie viele Ressourcen auf einem Knoten verfügbar sind. Auch die verbleibende Kapazität wird für den gesamten Cluster nachverfolgt.
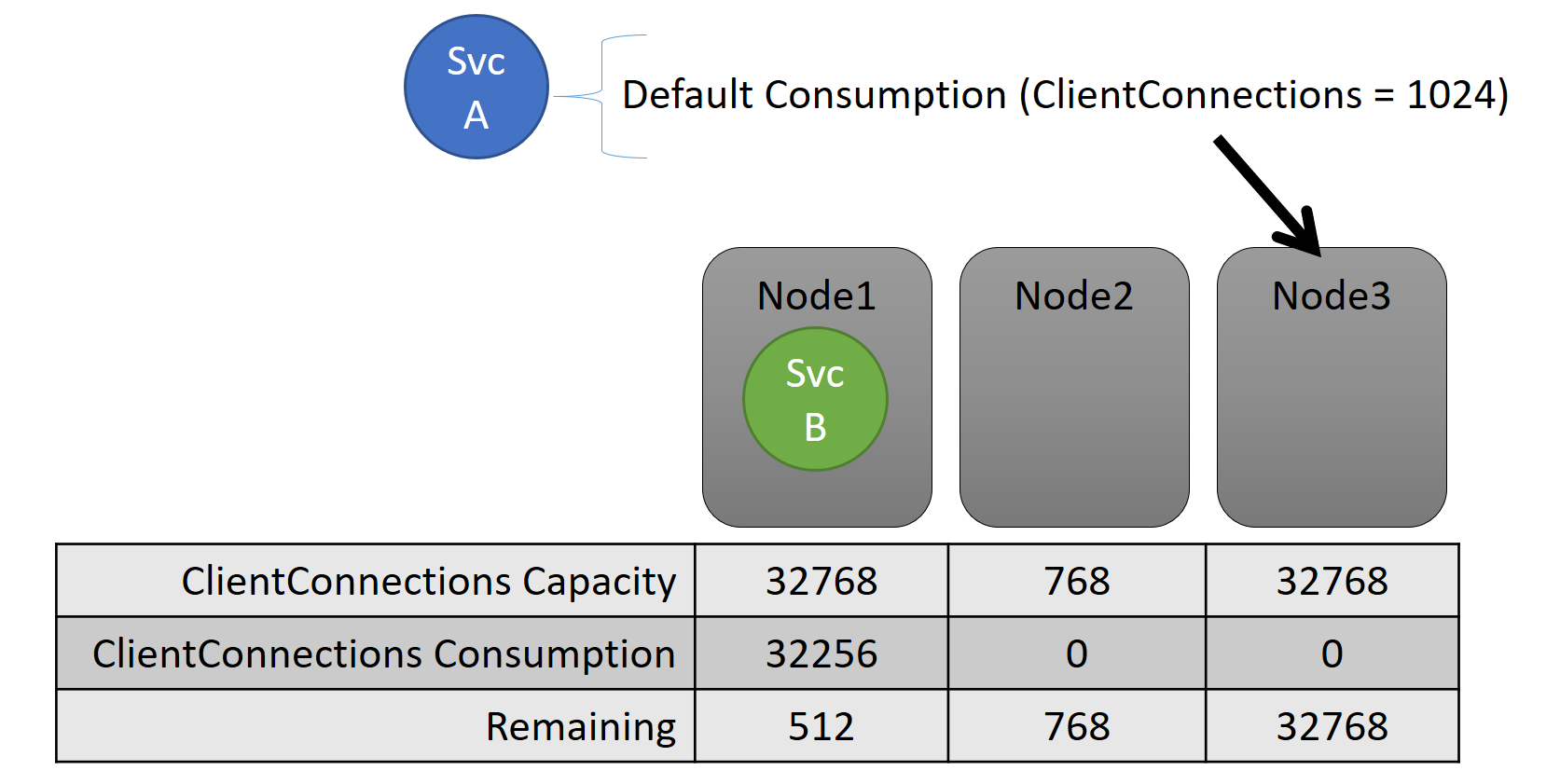
Sowohl die Kapazität als auch der Verbrauch auf Dienstebene werden als Metrik ausgedrückt. Die Metrik kann beispielsweise „ClientConnections“ lauten, und ein Knoten kann für „ClientConnections“ eine Kapazität von 32.768 Verbindungen aufweisen. Anderen Knoten können andere Grenzwerte aufweisen. Ein Dienst, der auf diesem Knoten ausgeführt wird, kann beispielsweise melden, dass aktuell 32.256 Einheiten der Metrik „ClientConnections“ genutzt werden.
Während der Laufzeit verfolgt der Clusterressourcen-Manager die verbleibende Kapazität im Cluster und auf den Knoten nach. Dazu subtrahiert er den Verbrauch jedes Diensts von der Kapazität des Knotens, auf dem der Dienst ausgeführt wird. Mit diesen Informationen kann der Clusterressourcen-Manager ermitteln, wo Replikate platziert oder wohin diese verschoben werden sollen, um die Kapazität der Knoten nicht zu überschreiten.
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
ServiceLoadMetricDescription metric = new ServiceLoadMetricDescription();
metric.Name = "ClientConnections";
metric.PrimaryDefaultLoad = 1024;
metric.SecondaryDefaultLoad = 0;
metric.Weight = ServiceLoadMetricWeight.High;
serviceDescription.Metrics.Add(metric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ClientConnections,High,1024,0)
Die festgelegten Kapazitäten finden Sie im Clustermanifest. Im Folgenden sehen Sie ein Beispiel für „ClusterManifest.xml“:
<NodeType Name="NodeType03">
<Capacities>
<Capacity Name="ClientConnections" Value="65536"/>
</Capacities>
</NodeType>
Im folgenden Beispiel werden Kapazitäten gezeigt, die sich bei eigenständigen Bereitstellungen in „ClusterConfig.json“ und bei Clustern, die in Azure gehostet sind, in „Template.json“ befinden:
"nodeTypes": [
{
"name": "NodeType03",
"capacities": {
"ClientConnections": "65536",
}
}
],
Häufig ändert sich die Last eines Diensts dynamisch. Angenommen, die Last eines Replikats, die mit der Metrik „ClientConnections“ erfasst wird, ist von 1024 auf 2048 angestiegen. Zuvor waren für den Knoten, auf dem das Replikat ausgeführt wurde, noch 512 Metrikeinheiten verfügbar. Die Platzierung dieses Replikats bzw. der Instanz ist nun ungültig, da auf dem Knoten nicht genügend Kapazitäten vorhanden sind. Daher muss der Clusterressourcen-Manager eingreifen und für den Knoten wieder die Einhaltung der Kapazitätsgrenze sicherstellen. Er verringert den Teil der Knotenlast, der seine Kapazität übersteigt, indem ein oder mehrere Replikate bzw. Instanzen von diesem Knoten auf andere Knoten verschoben werden.
Der Clusterressourcen-Manager versucht, den Aufwand für das Verschieben von Replikaten zu minimieren. Weitere Informationen finden Sie im Artikel zum Verschiebungsaufwand und im Artikel zu Strategien und Regeln für einen erneuten Ausgleich.
Clusterkapazität
Wie stellt der Clusterressourcen-Manager von Service Fabric sicher, dass der Cluster insgesamt nicht zu stark ausgelastet wird? Bei einer dynamischen Last sind die Möglichkeiten begrenzt. Dienste können unabhängig von Aktionen, die vom Clusterressourcen-Manager ausgeführt werden, Lastspitzen aufweisen. Ein Cluster, der aktuell über eine ausreichende Kapazität verfügt, kann bei stark ansteigender Nachfrage in kürzester Zeit überlastet werden.
Dieses Problem kann durch Steuermechanismen im Clusterressourcen-Manager vermieden werden. Sie können zunächst die Erstellung neuer Workloads verhindern, die eine Überlastung des Clusters verursachen.
Angenommen, Sie erstellen einen zustandslosen Dienst, der eine bestimmte Last aufweist. Der Dienst berücksichtigt die Metrik „DiskSpaceInMb“ und nutzt für jede Dienstinstanz fünf Einheiten. Sie möchten drei Instanzen des Diensts erstellen. Daher benötigen Sie 15 Einheiten von „DiskSpaceInMb“ im Cluster, um die Dienstinstanzen erstellen zu können.
Der Clusterressourcen-Manager berechnet regelmäßig die Kapazität und den Verbrauch jeder Metrik, sodass die verbleibende Kapazität im Cluster bestimmt werden kann. Falls nicht genügend Speicherplatz vorhanden ist, lehnt der Clusterressourcen-Manager den Aufruf zum Erstellen des Diensts ab.
Da die einzige Anforderung darin besteht, dass 15 Einheiten verfügbar sein müssen, können Sie den Speicher für diese auf unterschiedliche Weise belegen. Möglicherweise ist für 15 unterschiedlichen Knoten eine verbleibende Kapazitätseinheit verfügbar, oder drei verbleibende Einheiten stehen für fünf unterschiedlichen Knoten bereit. Wenn der Clusterressourcen-Manager die Anordnung so ändern kann, dass auf drei Knoten fünf Einheiten verfügbar sind, wird der Dienst platziert. Das Neuanordnen des Clusters ist im Allgemeinen möglich, es sei denn, der Cluster ist nahezu voll belegt oder die vorhandenen Dienste können aus bestimmten Gründen nicht konsolidiert werden.
Knotenpuffer und Überbuchen von Kapazität
Wenn eine Knotenkapazität für eine Metrik angegeben wird, platziert oder verschiebt der Clusterressourcen-Manager niemals Replikate auf einen Knoten, wenn die Gesamtlast die angegebene Knotenkapazität übersteigen würde. Dies kann manchmal die Platzierung neuer Replikate oder das Ersetzen ausgefallener Replikate verhindern, wenn der Cluster fast voll ausgelastet ist und ein Replikat mit einer großen Last platziert, ersetzt oder verschoben werden muss.
Um mehr Flexibilität bereitzustellen, können Sie entweder einen Knotenpuffer oder das Überbuchen von Kapazität angeben. Wenn für eine Metrik ein Knotenpuffer oder das Überbuchen von Kapazität angegeben wird, versucht der Clusterressourcen-Manager, Replikate so zu platzieren oder zu verschieben, dass die Puffer- oder Überbuchungskapazität ungenutzt bleibt, aber die Puffer- oder Überbuchungskapazität bei Bedarf für Aktionen genutzt werden kann, die die Dienstverfügbarkeit erhöhen, beispielsweise:
- Platzierung neuer Replikate oder Ersetzung fehlerhafter Replikate
- Platzierung während Upgrades
- Beheben von Verstößen gegen weiche und harte Einschränkungen
- Defragmentierung
Die Knotenpufferkapazität stellt einen reservierten Anteil der Kapazität unterhalb der angegebenen Knotenkapazität dar, und die Überbuchungskapazität stellt einen Teil der zusätzlichen Kapazität oberhalb der angegebenen Knotenkapazität dar. In beiden Fällen wird vom Clusterressourcen-Manager versucht, diese Kapazität frei zu halten.
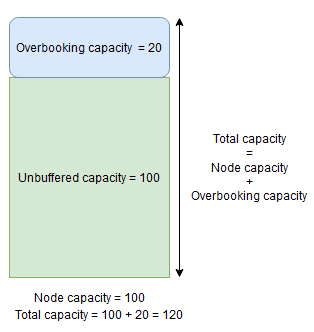
Wenn ein Knoten beispielsweise eine angegebene Kapazität für die Metrik CpuUtilization von 100 hat und der Knotenpufferprozentsatz für diese Metrik auf 20 % festgelegt ist, dann betragen die Gesamtkapazität und die ungepufferte Kapazität 100 bzw. 80, und der Clusterressourcen-Manager platziert unter normalen Umständen nicht mehr als 80 Lasteinheiten auf dem Knoten.

Der Knotenpuffer sollte verwendet werden, wenn Sie einen Teil der Knotenkapazität reservieren möchten, die nur für Aktionen verwendet wird, die die oben genannte Dienstverfügbarkeit erhöhen.
Wenn dagegen der Prozentsatz der Knotenüberbuchung verwendet und auf 20 % festgelegt wird, beträgt die Gesamtkapazität und die ungepufferte Kapazität 120 bzw. 100.
Wenn Sie zulassen möchten, dass der Clusterressourcen-Manager Replikate selbst dann auf einem Knoten platziert, wenn die gesamte Ressourcennutzung die Kapazität überschreitet, sollte die Überbuchungskapazität verwendet werden. Dies kann verwendet werden, um auf Kosten der Leistung zusätzliche Verfügbarkeit für Dienste bereitzustellen. Wenn Überbuchung verwendet wird, muss die Benutzeranwendungslogik mit weniger physischen Ressourcen funktionieren, als möglicherweise erforderlich ist.
Wenn Knotenpuffer- oder Überbuchungskapazitäten angegeben werden, werden Replikate vom Clusterressourcen-Manager weder verschoben noch platziert, wenn die Gesamtlast auf dem Zielknoten die Gesamtkapazität überschreitet (Knotenkapazität im Fall von Knotenpuffer und Knotenkapazität + Überbuchungskapazität im Fall von Überbuchung).
Die Überbuchungskapazität kann auch als unendlich angegeben werden. In diesem Fall wird vom Clusterressourcen-Manager versucht, die Gesamtlast auf dem Knoten unterhalb der angegebenen Knotenkapazität zu halten, es kann jedoch möglicherweise eine weitaus größere Auslastung auf dem Knoten platziert werden, was zu schwerwiegenden Leistungseinbußen führen kann.
Für eine Metrik kann nicht gleichzeitig ein Knotenpuffer und eine Überbuchungskapazität angegeben werden.
Im folgenden Beispiel werden Knotenpuffer- oder Überbuchungskapazitäten in ClusterManifest.xml angegeben:
<Section Name="NodeBufferPercentage">
<Parameter Name="SomeMetric" Value="0.15" />
</Section>
<Section Name="NodeOverbookingPercentage">
<Parameter Name="SomeOtherMetric" Value="0.2" />
<Parameter Name=”MetricWithInfiniteOverbooking” Value=”-1.0” />
</Section>
Im folgenden Beispiel wird gezeigt, wie Sie Knotenpuffer oder Überbuchungskapazitäten über ClusterConfig.json für eigenständige Bereitstellungen bzw. über Template.json für Cluster festlegen, die in Azure gehostet werden:
"fabricSettings": [
{
"name": "NodeBufferPercentage",
"parameters": [
{
"name": "SomeMetric",
"value": "0.15"
}
]
},
{
"name": "NodeOverbookingPercentage",
"parameters": [
{
"name": "SomeOtherMetric",
"value": "0.20"
},
{
"name": "MetricWithInfiniteOverbooking",
"value": "-1.0"
}
]
}
]
Nächste Schritte
- Weitere Informationen zur Architektur des Clusterressourcen-Managers und dem internen Informationsfluss finden Sie unter Cluster Resource Manager architecture overview (Übersicht über die Architektur des Clusterressourcen-Managers).
- Das Definieren von Defragmentierungsmetriken ist eine Möglichkeit, die Last auf Knoten zu konsolidieren, statt sie zu verteilen. Informationen zum Konfigurieren der Defragmentierung finden Sie unter Defragmentierung von Metriken und Lasten in Service Fabric.
- Starten Sie mit einer Einführung in den Clusterressourcen-Manager von Service Fabric.
- Informationen darüber, wie der Clusterressourcen-Manager die Last im Cluster verwaltet und verteilt, finden Sie unter Balancing your Service Fabric cluster (Vornehmen eines Lastausgleichs für Service Fabric-Cluster).