Verwalten von Ressourcenverbrauch und Auslastung in Service Fabric mit Metriken
Metriken die Ressourcen, die für Ihre Dienste wichtig sind und die von den Knoten im Cluster bereitgestellt werden. Eine Metrik ist ein beliebiges Element, das Sie verwalten möchten, um die Leistung Ihrer Dienste zu verbessern oder zu steuern. Sie können beispielsweise den Arbeitsspeicherverbrauch überwachen, um festzustellen, ob Ihr Dienst überlastet ist. Eine weitere Verwendungsmöglichkeit: Sie können ermitteln, ob der Dienst an eine andere Position verschoben werden kann, bei der eine geringere Arbeitsspeicherauslastung gegeben ist, um die Leistung zu steigern.
Arbeitsspeicher, Festplatte und CPU-Auslastung sind Beispiele für Metriken. Bei diesen Metriken handelt es sich um physische Metriken, also Ressourcen, die physischen Ressourcen auf dem Knoten entsprechen und verwaltet werden müssen. In vielen Fällen handelt es sich bei Metriken aber um logische Metriken. Beispiele für logische Metriken wären „MyWorkQueueDepth“, „MessagesToProcess“ und „TotalRecords“. Logische Metriken sind in der Anwendung definiert und entsprechen indirekt einem physischen Ressourcenverbrauch. Logische Metriken werden häufig genutzt, da der Verbrauch von physischen Ressourcen für einzelne Dienste nur schwer gemessen und gemeldet werden kann. Die Komplexität der Messung und Meldung Ihrer eigenen physischen Metriken ist auch der Grund, warum in Service Fabric eine Reihe von Standardmetriken bereitgestellt werden.
Standardmetriken
Angenommen, Sie möchten damit beginnen, Ihren Dienst zu schreiben und bereitzustellen. Zu diesem Zeitpunkt ist Ihnen sein Verbrauch von physischen oder logischen Ressourcen nicht bekannt. Das ist kein Problem. Der Clusterressourcen-Manager von Service Fabric verwendet einige Standardmetriken, wenn keine anderen Metriken angegeben sind. Sie lauten wie folgt:
- PrimaryCount – Anzahl der primären Replikate auf dem Knoten
- ReplicaCount – Anzahl der insgesamt zustandsbehafteten Replikate auf dem Knoten
- Count – Anzahl aller (zustandslosen und zustandsbehafteten) Dienstobjekte auf dem Knoten
| Metrik | Auslastung für zustandslose Instanz | Zustandsbehaftete sekundäre Auslastung | Zustandsbehaftete primäre Auslastung | Weight |
|---|---|---|---|---|
| PrimaryCount | 0 | 0 | 1 | High |
| ReplicaCount | 0 | 1 | 1 | Medium |
| Anzahl | 1 | 1 | 1 | Niedrig |
Für grundlegende Workloads liefern die Standardmetriken eine hinreichende Lastverteilung im Cluster. Im folgenden Beispiel wird untersucht, was geschieht, wenn zwei Dienste erstellt und die Standardmetriken für den Ausgleich verwendet werden. Der erste Dienst ist ein zustandsbehafteter Dienst mit drei Partitionen und der Zielreplikatgruppen-Größe „3“. Der zweite Dienst ist ein zustandsloser Dienst mit einer einzelnen Partition und drei Instanzen.
Ergebnis:
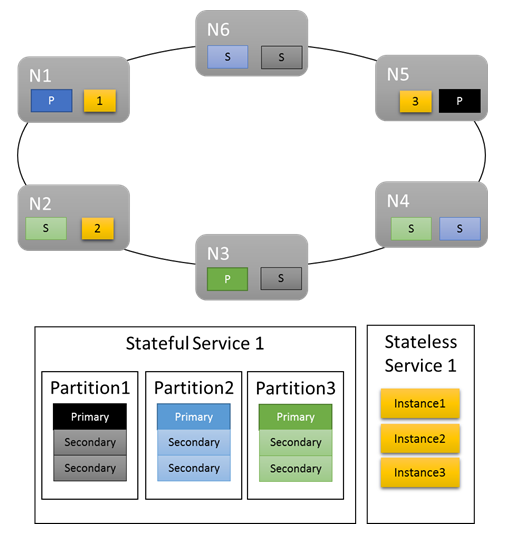
Hinweise, die Sie beachten sollten:
- Primäre Replikate für den zustandsbehafteten Dienst werden auf mehrere Knoten verteilt.
- Replikate einer Partition befinden sich auf unterschiedlichen Knoten.
- Die Gesamtanzahl primärer und sekundärer Replikate ist über den Cluster verteilt.
- Die Gesamtanzahl von Dienstobjekten ist auf den einzelnen Knoten gleichmäßig zugewiesen.
So weit, so gut.
Die Standardmetriken funktionieren hervorragend als Ausgangspunkt. Anschließend reichen die Standardmetriken jedoch nicht mehr aus. Beispiel: Wie hoch ist die Wahrscheinlichkeit, dass sich mit dem gewählten Partitionierungsschema eine absolut gleichmäßige Auslastung für alle Partitionen erreichen lässt? Wie hoch ist die Wahrscheinlichkeit, dass die Auslastung für einen bestimmten Dienst dauerhaft konstant oder auch nur zum aktuellen Zeitpunkt für mehrere Partitionen gleich ist?
Sie können den Dienst auch nur mit den Standardmetriken ausführen. Dies bedeutet jedoch im Allgemeinen nur, dass Ihre Clusterauslastung geringer und ungleichmäßiger als erwartet ist. Das liegt daran, dass die Standardmetriken nicht adaptiv sind und davon ausgegangen wird, dass alles gleichwertig ist. So tragen sowohl ein ausgelasteter als auch ein nicht ausgelasteter primärer Knoten zur Metrik „PrimaryCount“ jeweils „1“ bei. Im schlimmsten Fall kann die ausschließliche Verwendung der Standardmetriken auch zu überlasteten Knoten und damit zu Leistungseinbußen führen. Wenn Sie also Ihren Cluster optimal nutzen und Leistungsprobleme vermeiden möchten, müssen Sie auf benutzerdefinierte Metriken und dynamische Auslastungsberichte zurückgreifen.
Benutzerdefinierte Metriken
Metriken werden beim Erstellen des Diensts individuell für benannte Dienstinstanzen konfiguriert.
Jede Metrik verfügt über beschreibende Eigenschaften wie Name, Gewichtung und Standardauslastung.
- Metrikname: Der Name der Metrik. Der Metrikname ist ein eindeutiger Bezeichner für die Metrik (innerhalb des Clusters aus der Perspektive von Resource Manager).
Hinweis
Ein benutzerdefinierter Metrikname sollte keiner der Systemmetriknamen sein, z. B. servicefabric:/_CpuCores oder servicefabric:/_MemoryInMB, da dies zu nicht definierten Verhaltensweisen führen kann. Ab Service Fabric Version 9.1 wird für vorhandene Dienste mit diesen benutzerdefinierten Metriknamen eine Integritätswarnung ausgegeben, um anzugeben, dass der Metrikname falsch ist.
- Gewichtung: Die Metrikgewichtung gibt die Bedeutung der Metrik in Relation zu den anderen Metriken für diesen Dienst an.
- Standardlast: Die Standardlast wird unterschiedlich repräsentiert, je nachdem, ob der Dienst zustandslos oder zustandsbehaftet ist.
- Bei zustandslosen Diensten besitzt jede Metrik eine einzelne Eigenschaft namens „DefaultLoad“.
- Bei zustandsbehafteten Diensten definieren Sie Folgendes:
- PrimaryDefaultLoad: Die Standardmenge dieser Metrik, die der Dienst verbraucht, wenn es sich dabei um ein primäres Replikat handelt
- SecondaryDefaultLoad: Die Standardmenge dieser Metrik, die der Dienst verbraucht, wenn es sich dabei um ein sekundäres Replikat handelt
Hinweis
Wenn Sie benutzerdefinierte Metriken definieren und auch die Standardmetriken verwenden möchten, müssen Sie die Standardmetriken explizit wieder hinzufügen und ihre Gewichtungen und Werte festlegen. Dies ist erforderlich, um die Beziehung zwischen den Standardmetriken und Ihren benutzerdefinierten Metriken zu definieren. Beispielsweise haben „ConnectionCount“ und „WorkQueueDepth“ für Sie eine höhere Gewichtung als die primäre Verteilung. In der Standardeinstellung ist die Gewichtung der Metrik „PrimaryCount“ auf „Hoch“ festgelegt. Verringern Sie sie daher beim Hinzufügen der anderen Metriken auf „Mittel“, um sicherzustellen, dass diese Vorrang haben.
Definieren von Metriken für Ihren Dienst – ein Beispiel
Angenommen, Sie wünschen die folgende Konfiguration:
- Ihr Dienst meldet eine Metrik mit dem Namen „ConnectionCount“.
- Sie möchten auch die Standardmetriken verwenden.
- Sie haben im Zuge einiger Messungen ermittelt, dass für ein primäres Replikat des Diensts in der Regel 20 Einheiten von „ConnectionCount“ verbraucht werden.
- Für sekundäre Replikate fallen fünf Einheiten von „ConnectionCount“ an.
- Sie wissen, dass „ConnectionCount“ die wichtigste Metrik für die Verwaltung der Leistung dieses speziellen Diensts ist.
- Dennoch sollen primäre Replikate ausgeglichen werden. Das Ausgleichen der primären Replikate empfiehlt sich generell in jeder Situation. Dadurch werden der Ausfall von Knoten oder fehlerhafte Domänen verhindert, die auch die Mehrzahl der primären Replikate beeinträchtigen.
- In allen übrigen Aspekten sind die Standardmetriken ausreichend.
Hier sehen Sie den Code, den Sie schreiben würden, um einen Dienst mit dieser Metrikkonfiguration zu erstellen:
Code:
StatefulServiceDescription serviceDescription = new StatefulServiceDescription();
StatefulServiceLoadMetricDescription connectionMetric = new StatefulServiceLoadMetricDescription();
connectionMetric.Name = "ConnectionCount";
connectionMetric.PrimaryDefaultLoad = 20;
connectionMetric.SecondaryDefaultLoad = 5;
connectionMetric.Weight = ServiceLoadMetricWeight.High;
StatefulServiceLoadMetricDescription primaryCountMetric = new StatefulServiceLoadMetricDescription();
primaryCountMetric.Name = "PrimaryCount";
primaryCountMetric.PrimaryDefaultLoad = 1;
primaryCountMetric.SecondaryDefaultLoad = 0;
primaryCountMetric.Weight = ServiceLoadMetricWeight.Medium;
StatefulServiceLoadMetricDescription replicaCountMetric = new StatefulServiceLoadMetricDescription();
replicaCountMetric.Name = "ReplicaCount";
replicaCountMetric.PrimaryDefaultLoad = 1;
replicaCountMetric.SecondaryDefaultLoad = 1;
replicaCountMetric.Weight = ServiceLoadMetricWeight.Low;
StatefulServiceLoadMetricDescription totalCountMetric = new StatefulServiceLoadMetricDescription();
totalCountMetric.Name = "Count";
totalCountMetric.PrimaryDefaultLoad = 1;
totalCountMetric.SecondaryDefaultLoad = 1;
totalCountMetric.Weight = ServiceLoadMetricWeight.Low;
serviceDescription.Metrics.Add(connectionMetric);
serviceDescription.Metrics.Add(primaryCountMetric);
serviceDescription.Metrics.Add(replicaCountMetric);
serviceDescription.Metrics.Add(totalCountMetric);
await fabricClient.ServiceManager.CreateServiceAsync(serviceDescription);
Mit PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("ConnectionCount,High,20,5”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Hinweis
In den obigen Beispielen und den übrigen Abschnitten dieses Dokuments wird das Verwalten von Metriken für benannte Dienste erläutert. Sie können Metriken für Ihre Dienste auch auf der Ebene der Diensttypen definieren. Dazu müssen Sie sie in den Dienstmanifesten angeben. Das Definieren von Metriken auf der Typebene ist aus verschiedenen Gründen nicht zu empfehlen. Der erste Grund ist, dass Metriknamen häufig umgebungsspezifisch sind. Sofern kein fester Vertrag in Kraft ist, können Sie nicht sicher sein, dass die Metrik „Cores“ in einer Umgebung in anderen nicht „MiliCores“ oder „CoReS“ heißt. Wenn die Metriken in Ihrem Manifest definiert sind, müssen Sie für jede Umgebung neue Manifeste erstellen. Dies führt normalerweise zu einer Verbreitung von unterschiedlichen Manifesten, die sich jedoch nur geringfügig unterscheiden, was die Verwaltung erschwert.
Metrikauslastungen werden normalerweise für einzelne Instanzen benannter Dienste zugewiesen. Angenommen, Sie erstellen eine Instanz des Diensts für Kunde A, der sie in nur geringem Umfang nutzen möchte. Darüber hinaus erstellen Sie eine weitere Instanz für Kunde B, der über eine größere Workload verfügt. In einer solchen Situation möchten Sie wahrscheinlich die Standardlasten für diese Dienste optimieren. Wenn Sie Metriken und Auslastungen über Manifeste definiert haben und dieses Szenario unterstützt werden soll, werden für jeden Kunden unterschiedliche Anwendungs- und Diensttypen benötigt. Die Werte, die beim Erstellen der einzelnen Dienste festgelegt werden, setzen die im Manifest definierten Werte außer Kraft; somit können Sie auf diese Weise spezielle Standardwerte festlegen. Wenn Sie so vorgehen, entsprechen jedoch die in den Manifesten deklarierten Werte nicht den Werten, mit denen der Dienst tatsächlich ausgeführt wird. Dies kann verwirrend sein.
Zur Erinnerung: Falls Sie nur die Standardmetriken verwenden möchten, müssen Sie beim Erstellen des Diensts weder die Sammlung mit den Metriken verwenden noch sonstige Einstellungen konfigurieren. Sofern keine anderen Metriken angegeben sind, werden automatisch die Standardmetriken verwendet.
Im Folgenden betrachten wir jede dieser Einstellungen eingehender und diskutieren das Verhalten, das von ihnen beeinflusst wird.
Laden
Metriken werden definiert, um eine Auslastung darzustellen. Die Auslastung gibt an, welcher Anteil einer bestimmten Metrik von einer Dienstinstanz oder von einem Replikat auf einem bestimmten Knoten verbraucht wird. Die Auslastung kann an beinahe jedem Punkt konfiguriert werden. Beispiel:
- Die Auslastung kann beim Erstellen eines Diensts definiert werden. Diese Art der Auslastungskonfiguration wird als Standardauslastung bezeichnet.
- Die Metrikinformationen für einen Dienst, einschließlich der Standardauslastungen, können nach dem Erstellen des Diensts aktualisiert werden. Diese Metrikaktualisierung erfolgt durch Aktualisieren eines Dienst.
- Die Auslastungen für eine bestimmte Partition können auf die Standardwerte für den betreffenden Dienst zurückgesetzt werden. Diese Metrikaktualisierung wird als Zurücksetzen der Partitionsauslastung bezeichnet.
- Die Auslastung kann dynamisch während der Laufzeit für einzelne Dienstobjekte gemeldet werden. Diese Metrikaktualisierung wird als Melden der Auslastung bezeichnet.
- Die Auslastung für Replikate oder Instanzen der Partition kann auch aktualisiert werden, indem Auslastungswerte über einen Fabric-API-Aufruf gemeldet werden. Diese Metrikaktualisierung wird als Melden der Auslastung für eine Partition bezeichnet.
Alle diese Strategien können für ein und denselben Dienst während dessen Lebensdauer verfolgt werden.
Standardauslastung
Die Standardauslastung gibt den Verbrauch der Metrik an, der für die einzelnen Dienstobjekte (zustandslose Instanz oder zustandsbehaftetes Replikat) dieses Dienstes anfällt. Der Clusterressourcen-Manager verwendet diesen Wert als Auslastung des Dienstobjekts, bis er weitere Informationen erhält, beispielsweise einen dynamischen Auslastungsbericht. Für einfachere Dienste stellt die Standardauslastung eine statische Definition dar. Die Standardauslastung wird nie aktualisiert und über die gesamte Lebensdauer des Diensts verwendet. Standardauslastungen eignen sich gut für einfache Kapazitätsplanungsszenarien, in denen verschiedenen Workloads bestimmte Ressourcenmengen zugewiesen werden, die sich nicht ändern.
Hinweis
Weitere Informationen zur Kapazitätsverwaltung und zum Definieren von Kapazitäten für die Knoten im Cluster finden Sie in diesem Artikel.
Der Clusterressourcen-Manager ermöglicht für zustandsbehaftete Dienste die Angabe unterschiedlicher Standardauslastungen für seine primären und sekundären Replikate. Bei zustandslosen Diensten kann hingegen nur ein einzelner Wert angegeben werden, der für alle Instanzen gilt. Bei zustandsbehafteten Diensten unterscheidet sich die Auslastung für primäre Replikate üblicherweise von der Auslastung für sekundäre Replikate, da Replikate in jeder Rolle verschiedene Arten von Aufgaben übernehmen. So übernehmen primäre Replikate im Gegensatz zu sekundären Replikaten in der Regel sowohl Lese- als auch Schreibvorgänge sowie den Großteil der Rechenlast. Im Allgemeinen ist die Standardauslastung für ein primäres Replikat höher als die für sekundäre Replikate. Bei den Istwerten sollten Sie sich auf eigene Messungen verlassen.
Dynamische Auslastung
Nehmen wir an, Sie haben den Dienst bereits eine Zeitlang ausgeführt. Dabei haben Sie aufgrund der Überwachung Folgendes festgestellt:
- Einige Partitionen oder Instanzen eines bestimmten Diensts verbrauchen mehr Ressourcen als andere.
- Die Auslastung einiger Dienste verändert sich im Laufe der Zeit.
Diese Auslastungsschwankungen können verschiedenste Ursachen haben. So sind beispielsweise verschiedene Dienste oder Partitionen unterschiedlichen Kunden mit unterschiedlichen Anforderungen zugeordnet. Die Auslastung kann sich auch ändern, weil die Arbeitslast des Diensts im Verlauf des Tages variiert. Ungeachtet der Ursache gibt es im Allgemeinen keinen Einzelwert, den Sie als Standardwert verwenden können. Dies gilt insbesondere dann, wenn sie eine optimale Auslastung des Clusters anstreben. Jeder Wert, den Sie für die Standardauslastung festlegen, ist für einen gewissen Zeitraum unzutreffend. Bei einer falschen Standardauslastung weist der Clusterressourcen-Manager entweder zu viele oder zu wenige Ressourcen zu. Dies führt zu einer übermäßigen oder unzureichenden Auslastung von Knoten, selbst wenn der Cluster für den Clusterressourcen-Manager ausgewogen erscheint. Standardauslastungen haben einen gewissen Informationsgehalt für die anfängliche Platzierung und sind daher nicht schlecht, vermitteln in der Praxis aber kein umfassendes Bild von den Workloads. Um sich ändernde Ressourcenanforderungen genau widerzuspiegeln, ermöglicht der Clusterressourcen-Manager den einzelnen Dienstobjekten die Aktualisierung der eigenen Auslastung zur Laufzeit. Dies wird als „dynamisches Melden der Auslastung“ bezeichnet.
Mit Berichten zur dynamischen Auslastung können Replikate oder Instanzen die Zuordnung bzw. die gemeldete Auslastung von Metriken im Laufe ihrer Lebensdauer anpassen. Dienstreplikate oder -instanzen, die gerade nicht aktiv sind und nichts zu tun haben, melden in der Regel eine geringe Nutzung einer bestimmten Metrik. Aktive Replikate oder Instanzen melden eine höhere Auslastung.
Auf der Grundlage replikat- oder instanzspezifischer Berichte kann der Clusterressourcen-Manager die einzelnen Dienstobjekte im Cluster organisieren. Durch das Neuorganisieren der Dienste wird sichergestellt, dass den Diensten die benötigten Ressourcen zur Verfügung stehen. Dadurch können aktive Dienste Ressourcen von anderen Replikaten oder Instanzen abziehen, die gerade nicht aktiv sind oder weniger zu tun haben.
Innerhalb von Reliable Services sieht der Code zum dynamischen Melden der Auslastung wie folgt aus:
Code:
this.Partition.ReportLoad(new List<LoadMetric> { new LoadMetric("CurrentConnectionCount", 1234), new LoadMetric("metric1", 42) });
Ein Dienst kann Berichte zu jeder der Metriken liefern, die für ihn bei seiner Erstellung definiert wurden. Wenn ein Dienst eine Auslastung für eine Metrik meldet, dessen Verwendung für ihn nicht konfiguriert ist, wird der betreffende Bericht von Service Fabric ignoriert. Werden gleichzeitig andere Metriken gemeldet, die gültig sind, werden diese Berichte akzeptiert. Der Dienstcode kann sämtliche ihm bekannten Metriken messen und melden, und der Bediener kann die zu verwendende Metrikkonfiguration angeben, ohne den Dienstcode zu ändern.
Melden der Auslastung für eine Partition
Im vorherigen Abschnitt wird beschrieben, wie Dienstreplikate oder -instanzen selbst Auslastungen melden. Es gibt eine zusätzliche Option zum dynamischen Melden der Auslastung für die Replikate oder Instanzen einer Partition über die Service Fabric-API. Wenn Sie die Auslastung für eine Partition melden, können Sie sie für mehrere Partitionen gleichzeitig melden.
Diese Berichte werden auf die gleiche Weise wie Auslastungsberichte verwendet, die von den Replikaten oder Instanzen selbst stammen. Gemeldete Werte sind gültig, bis neue Auslastungswerte gemeldet werden, entweder durch das Replikat oder die Instanz oder durch das Melden eines neuen Auslastungswerts für eine Partition.
Mit dieser API gibt es mehrere Möglichkeiten, die Auslastung im Cluster zu aktualisieren:
- Eine zustandsbehaftete Dienstpartition kann die primäre Replikatauslastung aktualisieren.
- Durch zustandslose und zustandsbehaftete Dienste kann die Auslastung aller zugehörigen sekundären Replikate oder Instanzen aktualisiert werden.
- Durch zustandslose und zustandsbehaftete Dienste kann die Auslastung eines bestimmten Replikats oder einer bestimmten Instanz auf einem Knoten aktualisiert werden.
Es ist auch möglich, jede dieser Aktualisierungen pro Partition gleichzeitig zu kombinieren. Eine Kombination von Auslastungsaktualisierungen für eine bestimmte Partition muss über das Objekt „PartitionMetricLoadDescription“ angegeben werden. Dabei kann es sich um eine entsprechende Liste von Auslastungsaktualisierungen handeln, wie im Beispiel weiter unten zu sehen. Auslastungsaktualisierungen werden durch das Objekt „MetricLoadDescription“ dargestellt. Dieses Objekt kann einen aktuellen oder vorhergesagten Auslastungswert für eine Metrik enthalten, der mit einem Metriknamen angegeben wird.
Hinweis
Vorhergesagte Metrikauslastungswerte sind derzeit als Previewfunktion verfügbar. Sie ermöglicht es, dass vorhergesagte Auslastungswert aufseiten von Service Fabric gemeldet und verwendet werden, diese Funktion ist derzeit jedoch nicht aktiviert.
Das Aktualisieren von Auslastungen für mehrere Partitionen kann mit einem einzigen API-Aufruf durchführt werden. in diesem Fall enthält die Ausgabe eine Antwort pro Partition. Wenn die Partitionsaktualisierung aus irgendeinem Grund nicht erfolgreich angewendet wird, werden Aktualisierungen für diese Partition übersprungen, und der entsprechende Fehlercode für eine Zielpartition wird angegeben:
- PartitionNotFound: Die angegebene Partitions-ID ist nicht vorhanden.
- ReconfigurationPending: Die Partition wird zurzeit neu konfiguriert.
- InvalidForStatelessServices: Es wurde versucht, die Auslastung eines primären Replikats für eine Partition zu ändern, die zu einem zustandslosen Dienst gehört.
- ReplicaDoesNotExist: Das sekundäre Replikat oder die Instanz für einen angegebenen Knoten ist nicht vorhanden.
- InvalidOperation: Kann in zwei Fällen auftreten: Die Aktualisierung der Auslastung für eine Partition, die zur Systemanwendung gehört, oder die Aktualisierung der vorhergesagten Auslastung ist nicht aktiviert.
Wenn einige dieser Fehler zurückgegeben werden, können Sie die Eingabe für eine bestimmte Partition aktualisieren und die Aktualisierung dafür wiederholen.
Code:
Guid partitionId = Guid.Parse("53df3d7f-5471-403b-b736-bde6ad584f42");
string metricName0 = "CustomMetricName0";
List<MetricLoadDescription> newPrimaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 100)
};
string nodeName0 = "NodeName0";
List<MetricLoadDescription> newSpecificSecondaryReplicaLoads = new List<MetricLoadDescription>()
{
new MetricLoadDescription(metricName0, 200)
};
OperationResult<UpdatePartitionLoadResultList> updatePartitionLoadResults =
await this.FabricClient.UpdatePartitionLoadAsync(
new UpdatePartitionLoadQueryDescription
{
PartitionMetricLoadDescriptionList = new List<PartitionMetricLoadDescription>()
{
new PartitionMetricLoadDescription(
partitionId,
newPrimaryReplicaLoads,
new List<MetricLoadDescription>(),
new List<ReplicaMetricLoadDescription>()
{
new ReplicaMetricLoadDescription(nodeName0, newSpecificSecondaryReplicaLoads)
})
}
},
this.Timeout,
cancellationToken);
In diesem Beispiel führen Sie eine Aktualisierung der zuletzt gemeldeten Auslastung für eine Partition 53df3d7f-5471-403b-b736-bde6ad584f42 aus. Die Auslastung des primären Replikats für eine Metrik CustomMetricName0 wird mit dem Wert 100 aktualisiert. Gleichzeitig wird die Auslastung für die gleiche Metrik für ein bestimmtes sekundäres Replikat, das sich auf dem Knoten NodeName0 befindet, mit dem Wert 200 aktualisiert.
Aktualisieren der Metrikkonfiguration eines Diensts
Die dem Dienst zugeordnete Liste der Metriken und die Eigenschaften dieser Metriken können dynamisch aktualisiert werden, während der Dienst aktiv ist. Dies bietet eine gewisse Flexibilität und Experimentiermöglichkeiten. Beispiele für Situationen, in denen dies hilfreich ist:
- Deaktivieren einer Metrik mit einem fehlerhaften Bericht für einen bestimmten Dienst
- Neukonfigurieren der Gewichtungen von Metriken entsprechend dem gewünschten Verhalten
- Aktivieren einer neuen Metrik erst nach erfolgter Bereitstellung und Überprüfung des Codes durch andere Mechanismen
- Ändern der Standardauslastung für einen Dienst gemäß dem beobachteten Verhalten und Verbrauch
Die wichtigsten APIs zum Ändern der Metrikkonfiguration sind FabricClient.ServiceManagementClient.UpdateServiceAsync in C# und Update-ServiceFabricService in PowerShell. Die Informationen, die Sie in diesen APIs angeben, ersetzen sofort die vorhandenen Metrikinformationen für den Dienst.
Kombinieren von Standardauslastungswerten und dynamischen Auslastungsberichten
Für einen Dienst können sowohl Standardauslastungen als auch dynamische Auslastungen verwendet werden. Wenn ein Dienst sowohl Standardauslastungsberichte als dynamische Auslastungsberichte nutzt, fungiert die Standardauslastung als Schätzwert, bis dynamische Berichte zur Verfügung stehen. Die Standardauslastung empfiehlt sich, weil der Clusterressourcen-Manager damit über einen vorläufigen Arbeitswert verfügt. Auf der Grundlage der Standardauslastung kann der Clusterressourcen-Manager die Dienstobjekte bei deren Erstellung sinnvoll platzieren. Ohne Angabe einer Standardauslastung werden die Dienste im Endeffekt zufällig platziert. Wenn später Auslastungsberichte eingehen, erweist sich die Anfangsplatzierung häufig als falsch, und der Clusterressourcen-Manager muss Dienste verschieben.
Im Anschluss sehen wir uns anhand des vorherigen Beispiels an, was passiert, wenn wir einige benutzerdefinierte Metriken sowie dynamische Auslastungsberichte hinzufügen. In diesem Beispiel verwenden wir „MemoryInMb“ als Beispielmetrik.
Hinweis
Der Arbeitsspeicher stellt eine der Systemmetriken dar, für die Service Fabric die Ressourcensteuerung übernehmen kann, und wenn Sie selbst Berichte dazu erstellen möchten, ist dies in der Regel schwierig. Es wird nicht erwartet, dass Sie selbst Berichte zum Arbeitsspeicherverbrauch ausgeben; der Arbeitsspeicher fungiert hier nur als Anschauungspunkt, anhand dessen Sie sich mit den Fähigkeiten des Clusterressourcen-Managers vertraut machen können.
Außerdem nehmen wir an, dass der zustandsbehaftete Dienst ursprünglich mit dem folgenden Befehl erstellt wurde:
PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton –Metric @("MemoryInMb,High,21,11”,"PrimaryCount,Medium,1,0”,"ReplicaCount,Low,1,1”,"Count,Low,1,1”)
Syntax: ("Metrikname, Metrikgewichtung, Standardauslastung des primären Replikats, Standardauslastung des sekundären Replikats").
Ein mögliches Clusterlayout kann beispielsweise wie folgt aussehen:

Beachten Sie folgende Punkte:
- Sekundäre Replikate innerhalb einer Partition können jeweils über eine eigene Auslastung verfügen.
- Insgesamt machen die Metriken einen ausgeglichenen Eindruck. Für den Arbeitsspeicher liegt das Verhältnis zwischen maximaler und minimaler Auslastung bei 1,75. (Der Knoten mit der höchsten Auslastung ist N3, der Knoten mit der geringsten Auslastung ist N2, also: 28/16 = 1,75.)
Einige Punkte müssen noch erläutert werden:
- Wie wird bestimmt, ob ein Verhältnis von 1,75 gut oder nicht gut ist? Woher weiß der Clusterressourcen-Manager, ob dieses Ergebnis ausreicht oder ob noch weitere Optimierungen erforderlich sind?
- Wann wird ein Lastenausgleich durchgeführt?
- Was bedeutet es, dass „Memory“ die Gewichtung „Hoch“ erhalten hat?
Metrikgewichtungen
Es ist unverzichtbar, dass die gleichen Metriken über verschiedene Dienste hinweg nachverfolgt werden können. Mit dieser globalen Sicht kann der Clusterressourcen-Manager den Verbrauch im Cluster überwachen, knotenübergreifend ausgleichen und sicherstellen, dass die Kapazität von Knoten nicht überschritten wird. Die gleiche Metrik hat jedoch bei unterschiedlichen Diensten unter Umständen nicht den gleichen Stellenwert. Außerdem sind perfekt ausgewogene Lösungen in einem Cluster mit zahlreichen Metriken und einer Vielzahl von Diensten unter Umständen gar nicht für alle Metriken möglich. Wie soll der Clusterressourcen-Manager mit solchen Situationen umgehen?
Dank Metrikgewichtungen kann der Clusterressourcen-Manager entscheiden, wie der Cluster ausgeglichen werden soll, falls keine perfekte Lösung verfügbar ist. Auf der Grundlage von Metrikgewichtungen kann der Clusterressourcen-Manager außerdem bestimmte Dienste unterschiedlich ausgleichen. Metriken können vier unterschiedliche Gewichtungen haben: Null, Niedrig, Mittel und Hoch. Eine Metrik mit der Gewichtung „Null“ hat keine Auswirkung auf die Frage, ob ein guter Ausgleich besteht. Ihre Auslastung wird jedoch für bestimmte Aspekte der Kapazitätsverwaltung berücksichtigt. Metriken mit der Gewichtung „Null“ sind dennoch hilfreich und werden häufig bei der Überwachung von Dienstverhalten und -leistung hinzugezogen. Dieser Artikel liefert weitere Informationen zur Nutzung von Metriken für das Überwachen und Diagnostizieren Ihrer Dienste.
Der tatsächliche Nutzen von Metrikgewichtungen im Cluster besteht darin, dass der Clusterressourcen-Manager unterschiedliche Lösungen generiert. Mithilfe von Metrikgewichtungen wird dem Clusterressourcen-Manager vermittelt, dass bestimmte Metriken einen höheren Stellenwert haben als andere. Sollte keine perfekte Lösung verfügbar sein, kann der Clusterressourcen-Manager Lösungen bevorzugen, bei denen die höher gewichteten Metriken besser ausgeglichen werden. Falls ein Dienst eine bestimmte Metrik als unwichtig betrachtet, entsteht für ihn unter Umständen der Eindruck, dass die Verwendung dieser Metrik zu einer Unausgewogenheit führt. Dadurch kann bei einem anderen Dienst, bei dem dies wichtig ist, eine ausgewogene Verteilung einer bestimmten Metrik erzielt werden.
Im Anschluss sehen wir uns ein Beispiel für einige Auslastungsberichte an und beschäftigen uns damit, wie unterschiedliche Metrikgewichtungen zu unterschiedlichen Zuordnungen im Cluster führen. In diesem Beispiel sehen Sie, dass die Umstellung der relativen Metrikgewichtung bewirkt, dass der Clusterressourcen-Manager unterschiedliche Dienstanordnungen erstellt.

In diesem Beispiel gibt es vier verschiedene Dienste, die jeweils unterschiedliche Werte für zwei verschiedene Metriken („MetricA“ und „MetricB“) liefern. In einem Fall definieren alle Dienste „MetricA“ als wichtigste Metrik (Weight = High, Gewichtung = Hoch) und „MetricB“ als unwichtig (Weight = Low, Gewichtung = Niedrig). Daher platziert der Clusterressourcen-Manager die Dienste so, dass „MetricA“ im Vergleich zu „MetricB“ besser ausgeglichen ist. „Besser ausgeglichen“ bedeutet, dass „MetricA“ eine geringere Standardabweichung als „MetricB“ aufweist. Im zweiten Fall kehren wir die Metrikgewichtungen um. Daraufhin vertauscht der Clusterressourcen-Manager die Dienste A und B, um eine Zuordnung zu erzielen, bei der „MetricB“ im Vergleich zu „MetricA“ einen besseren Ausgleich aufweist.
Hinweis
Metrikgewichtungen bestimmen, auf welche Weise der Clusterressourcen-Manager einen Ausgleich vornehmen soll, nicht dass ein Ausgleich stattfinden soll. Weitere Informationen zum Ausgleichen finden Sie in diesem Artikel.
Globale Metrikgewichtungen
Angenommen „ServiceA“ definiert die Gewichtung von „MetricA“ als „High“ (Hoch), während „ServiceB“ die Gewichtung für „MetricA“ auf „Low“ (Niedrig) oder „Zero“ (Null) festlegt. Welche tatsächliche Gewichtung wird letztendlich verwendet?
Für jede Metrik werden mehrere Gewichtungen verfolgt. Die erste Gewichtung ist diejenige, die beim Erstellen des Diensts für die Metrik definiert wird. Bei der anderen Gewichtung handelt es sich um eine globale Gewichtung, die automatisch berechnet wird. Beim Bewerten von Lösungen werden vom Clusterressourcen-Manager beide Gewichtungen verwendet. Es ist unerlässlich, dass beide Gewichtungen berücksichtigt werden. Dadurch kann der Clusterressourcen-Manager jeden Dienst gemäß dessen spezifischen Prioritäten ausgleichen und zudem sicherstellen, dass die Zuordnung für den Cluster als Ganzes korrekt erfolgt.
Was würde passieren, wenn sich der Clusterressourcen-Manager nicht um die globale und lokale Ausgewogenheit kümmert? Es ist nicht schwer, global ausgewogene Lösungen zu erstellen, die jedoch eine unzureichende Ressourcenzuordnung für einzelne Dienste nach sich ziehen. Im folgenden Beispiel betrachten wir einen Dienst, der lediglich mit den Standardmetriken konfiguriert ist. Dabei wird untersucht, was geschieht, wenn lediglich die globale Ausgewogenheit berücksichtigt wird:
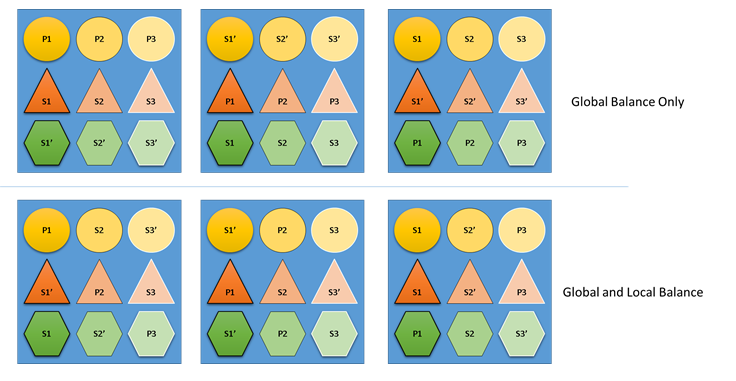
Im oberen Beispiel, das ausschließlich auf dem globalen Ausgleich basierte, ist der Cluster insgesamt tatsächlich ausgeglichen. Alle Knoten verfügen über die gleiche Anzahl von primären Replikaten sowie über die gleiche Gesamtanzahl von Replikaten. Wenn wir uns jedoch die tatsächlichen Auswirkungen dieser Zuordnung ansehen, ist das Ergebnis nicht so gut: Der Verlust eines Knotens wirkt sich unverhältnismäßig stark auf eine bestimmte Workload aus, da alle zugehörigen primären Replikate davon betroffen sind. Wenn also beispielsweise der erste Knoten ausfällt, gehen die drei primären Replikate für die drei verschiedenen Partitionen des Diensts „Circle“ verloren. Im Gegensatz dazu fällt bei den Diensten vom Typ „Dreieck“und „Sechseck“ ein Replikat in den Partitionen aus. Dies bewirkt keine Unterbrechung, und es muss lediglich das ausgefallene Replikat wiederhergestellt werden.
Im unteren Beispiel hat der Clusterressourcen-Manager die Replikate sowohl auf der Grundlage des globalen Ausgleichs als auch auf der Grundlage des dienstspezifischen Ausgleichs verteilt. Beim Berechnen der Lösungspunktzahl entfällt der Großteil der Gewichtung auf die globale Lösung und ein (konfigurierbar) Teil auf einzelne Dienste. Der globale Ausgleich für eine Metrik wird auf der Grundlage des Durchschnitts der Metrikgewichtungen für die einzelnen Dienste berechnet. Jeder Dienst wird gemäß seiner eigenen definierten Metrikgewichtungen ausgeglichen. Dadurch wird sichergestellt, dass die Dienste gemäß ihren jeweiligen Anforderungen untereinander ausgeglichen sind. Wenn nun der erste Knoten ausfällt, verteilt sich daher der Ausfall auf alle Partitionen aller Dienste. Die Auswirkungen sind also für alle gleich.
Nächste Schritte
- Weitere Informationen zum Konfigurieren von Diensten finden Sie unter Konfigurieren von Einstellungen des Clusterressourcen-Managers für Service Fabric-Dienste.
- Das Definieren von Defragmentierungsmetriken ist eine Möglichkeit, die Last auf Knoten zu konsolidieren, statt sie auszubreiten. Informationen zum Konfigurieren der Defragmentierung finden Sie in diesem Artikel
- Informationen darüber, wie der Clusterressourcen-Manager die Auslastung im Cluster verwaltet und verteilt, finden Sie im Artikel zum Lastenausgleich
- Starten Sie mit einer Einführung in den Clusterressourcen-Manager von Service Fabric
- Bewegungskosten sind eine Möglichkeit, dem Clusterressourcen-Manager mitzuteilen, dass bestimmte Dienste teurer zu bewegen sind als andere. Weitere Informationen zu Bewegungskosten finden Sie in diesem Artikel