Diagnostizieren häufiger Szenarien mit Service Fabric
Dieser Artikel veranschaulicht allgemeine Szenarien, die bei Benutzern im Bereich der Überwachung und Diagnose mit Service Fabric aufgetreten sind. Die beschriebenen Szenarien beziehen sich auf alle drei Service Fabric-Ebenen: Anwendung, Cluster und Infrastruktur. Bei jeder Lösung kommen Application Insights und Azure Monitor-Protokolle sowie Azure-Überwachungstools zum Einsatz, um die einzelnen Szenarien abzuschließen. Die Schritte in den einzelnen Lösungen geben Benutzern eine Einführung in die Verwendung von Application Insights und Azure Monitor-Protokolle im Zusammenhang mit Service Fabric.
Voraussetzungen und Empfehlungen
Für die Lösungen in diesem Artikel werden die folgenden Tools verwendet. Es wird empfohlen, diese Tools vorher einzurichten und zu konfigurieren:
- Application Insights mit Service Fabric
- Aktivieren der Azure-Diagnose in Ihrem Cluster
- Einrichten eines Log Analytics-Arbeitsbereichs
- Log Analytics-Agent zum Nachverfolgen von Leistungsindikatoren
Wie kann ich nicht behandelte Ausnahmen in meiner Anwendung anzeigen?
Navigieren Sie zu Ihrer Application Insights-Ressource, mit der die Anwendung konfiguriert ist.
Wählen Sie oben links die Option Suchen aus. Wählen Sie dann im nächsten Bereich die Option „Filter“ aus.
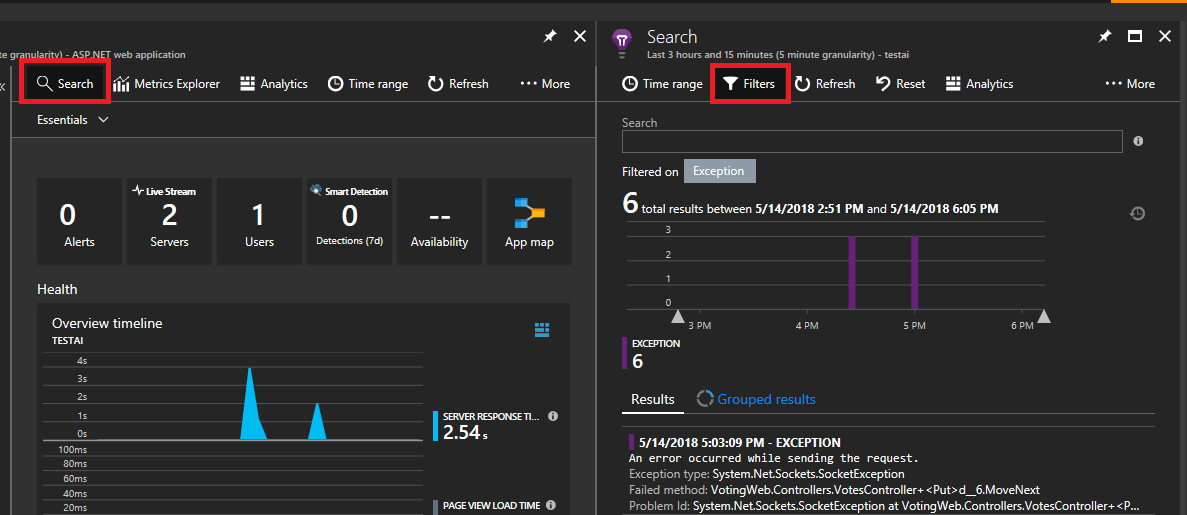
Viele Arten von Ereignissen (Ablaufverfolgungen, Anforderungen, benutzerdefinierte Ereignisse) werden angezeigt. Wählen Sie „Ausnahme“ als Filter aus.
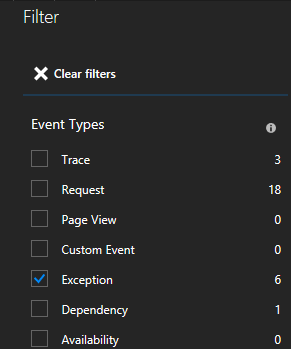
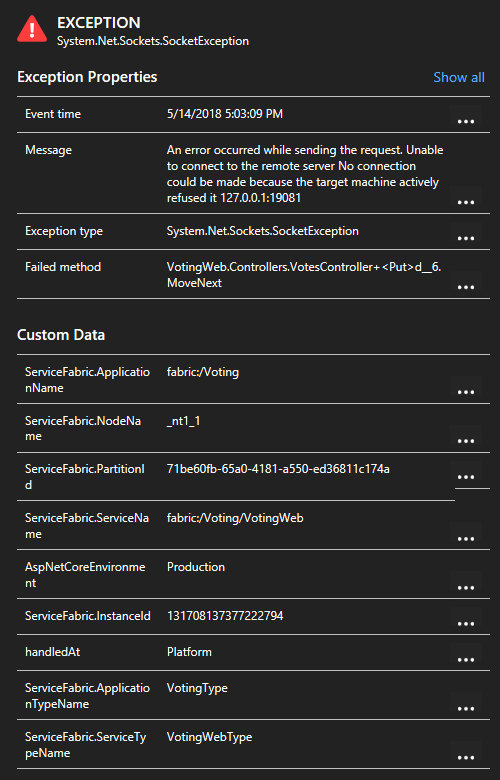
Durch Klicken auf eine Ausnahme in der Liste können Sie weitere Einzelheiten anzeigen, einschließlich des Dienstkontexts, wenn Sie das Service Fabric Application Insights-SDK verwenden.
Wie kann ich sehen, welche HTTP-Aufrufe in meinen Diensten verwendet werden?
In der gleichen Application Insights-Ressource können Sie anstatt nach „Ausnahme“ nach „Anforderungen“ filtern und alle vorgenommenen Anforderungen anzeigen.
Wenn Sie das Service Fabric Application Insights-SDK verwenden, können Sie eine visuelle Darstellung der miteinander verbundenen Dienste sowie die Anzahl der erfolgreichen und fehlgeschlagenen Anforderungen anzeigen. Wählen Sie auf der linken Seite die Option „Anwendungsübersicht“ aus.
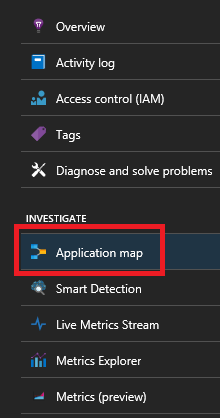

Weitere Informationen zur Anwendungsübersicht finden Sie in der Dokumentation zur Anwendungsübersicht.
Wie erstelle ich eine Warnung, wenn ein Knoten ausfällt?
Knotenereignisse werden von Ihrem Service Fabric-Cluster nachverfolgt. Navigieren Sie zur Service Fabric Analytics-Lösungsressource mit dem Namen ServiceFabric(Name_der_Ressourcengruppe) .
Wählen Sie unten auf dem Blatt „Zusammenfassung“ das Diagramm aus.

Hier finden Sie viele Diagramme und Kacheln, die verschiedene Metriken anzeigen. Wählen Sie eines der Diagramme aus. Dadurch gelangen Sie zur Protokollsuche. Hier können Sie alle Clusterereignisse oder Leistungsindikatoren abfragen.
Geben Sie die folgende Abfrage ein. Diese Ereignis-IDs finden Sie in der Referenz zu Knotenereignissen.
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626Wählen Sie oben die Option „Neue Benachrichtigungsregel“ aus. Ab jetzt erhalten Sie jedes Mal, wenn ein Ereignis basierend auf dieser Abfrage eingeht, eine Benachrichtigung mit der von Ihnen ausgewählten Kommunikationsmethode.

Wie kann ich Warnungen zu Rollbacks von Anwendungsupgrades erhalten?
Geben Sie im gleichen Fenster der Protokollsuche, das Sie zuvor verwendet haben, die folgende Abfrage nach Upgraderollbacks ein. Diese Ereignis-IDs finden Sie in der Referenz zu Anwendungsereignissen.
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624Wählen Sie oben die Option „Neue Benachrichtigungsregel“ aus. Ab jetzt erhalten Sie jedes Mal, wenn ein Ereignis basierend auf dieser Abfrage eingeht, eine Benachrichtigung.
Wie zeige ich Containermetriken an?
In derselben Ansicht mit allen Diagrammen sehen Sie einige Kacheln für die Leistung Ihrer Container. Sie benötigen den Log Analytics-Agent und die Containerüberwachungslösung, damit diese Kacheln aufgefüllt werden.
Hinweis
Um Telemetriedaten von innerhalb Ihres Containers zu instrumentieren, müssen Sie das Application Insights NuGet-Paket für Container hinzufügen.
Wie kann ich Leistungsindikatoren überwachen?
Nachdem Sie den Log Analytics-Agent dem Cluster hinzugefügt haben, müssen Sie die spezifischen Leistungsindikatoren hinzufügen, die Sie nachverfolgen möchten. Navigieren Sie im Portal zur Seite des Log Analytics-Arbeitsbereichs – von der Lösungsseite aus gesehen befindet sich die Registerkarte für den Arbeitsbereich im linken Menü.

Nachdem Sie die Seite des Arbeitsbereichs aufgerufen haben, wählen Sie im gleichen linken Menü die Option „Erweiterte Einstellungen“ aus.

Wählen Sie „Daten“ > „Windows-Leistungsindikatoren“ aus (bzw. „Daten“ > „Linux-Leistungsindikatoren“ bei Linux-Computern), um damit zu beginnen, über den Log Analytics-Agent bestimmte Leistungsindikatoren von Ihren Knoten zu sammeln. Es folgen Beispiele für das Format, in dem Leistungsindikatoren hinzugefügt werden müssen
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor TimeIn der Schnellstartanleitung werden VotingData und VotingWeb als Prozessnamen verwendet. Die Nachverfolgung dieser Leistungsindikatoren würde wie folgt aussehen:
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes
So können Sie sehen, wie Ihre Infrastruktur die Arbeitslasten verarbeitet, und anhand der Ressourcenauslastung entsprechende Benachrichtigungen festlegen. Beispiel: Sie möchten eine Benachrichtigung erhalten, wenn die Prozessorgesamtauslastung über 90 % steigt oder unter 5 % fällt. Der Name des Leistungsindikators, den Sie dafür verwenden, lautet „% Prozessorzeit“. Dazu können Sie eine Warnungsregel für die folgende Abfrage erstellen:
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
Wie kann ich die Leistung meiner Reliable Services und Reliable Actors nachverfolgen?
Um die Leistung von Reliable Services oder Reliable Actors in Ihren Anwendungen nachzuverfolgen, sollten Sie auch die Leistungsindikatoren für Service Fabric Actor, Actor-Methode, Dienst und Dienstmethode erfassen. Beispiele für zu erfassende Leistungsindikatoren für Reliable Services und Reliable Actors
Hinweis
Service Fabric-Leistungsindikatoren können derzeit nicht vom Log Analytics-Agent gesammelt werden, aber von anderen Diagnoselösungen.
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
Nutzen Sie diese Links, um die vollständige Liste der Leistungsindikatoren für Reliable Services und Reliable Actors abzurufen.
Nächste Schritte
- Suchen von häufigen Codepaket-Aktivierungsfehlern
- Richten Sie Warnungen in AI ein, um Benachrichtigungen zu Änderungen der Leistung oder Nutzung zu erhalten.
- Die intelligente Erkennung in Application Insights führt eine proaktive Analyse der an AI gesendeten Telemetriedaten aus, um Sie vor potenziellen Leistungsproblemen zu warnen.
- Erfahren Sie mehr über die Warnungen von Azure Monitor-Protokolle, die bei der Erkennung und Diagnose hilfreich sein können.
- Für lokale Cluster bietet Azure Monitor-Protokolle ein Gateway (HTTP-Weiterleitungsproxy), über das Daten an Azure Monitor-Protokolle gesendet werden können. Weitere Informationen dazu finden Sie unter Verbinden von Computern ohne Internetzugriff mit Azure Monitor-Protokolle über das Log Analytics-Gateway.
- Machen Sie sich mit den Funktionen zur Protokollsuche und -abfrage in Azure Monitor-Protokolle vertraut.
- Eine ausführlichere Übersicht über Azure Monitor-Protokolle und die zugehörigen Optionen finden Sie unter Was sind Azure Monitor-Protokolle?.