Tutorial: Überwachen eines Service Fabric-Clusters in Azure
Die Überwachung und Diagnose sind wichtig für die Entwicklung und Durchführung von Tests sowie für die Bereitstellung von Workloads in beliebigen Cloudumgebungen. Dieses Tutorial ist der zweite Teil einer Reihe. Darin wird erläutert, wie Sie einen Service Fabric-Cluster mithilfe von Ereignissen, Leistungsindikatoren und Integritätsberichten überwachen und diagnostizieren. Weitere Informationen finden Sie in der Übersicht über die Clusterüberwachung und Überwachung der Infrastruktur.
In diesem Tutorial lernen Sie Folgendes:
- Anzeigen von Service Fabric-Ereignissen
- Abfragen von EventStore-APIs nach Clusterereignissen
- Überwachen der Infrastruktur/Erfassen von Leistungsindikatoren
- Anzeigen von Clusterintegritätsberichten
In dieser Tutorialserie lernen Sie Folgendes:
- Erstellen eines sicheren Windows-Clusters in Azure mithilfe einer Vorlage
- Überwachen eines Clusters
- Horizontales Herunter- oder Hochskalieren eines Clusters
- Aktualisieren der Runtime eines Clusters
- Löschen eines Clusters
Hinweis
Es wird empfohlen, das Azure Az PowerShell-Modul für die Interaktion mit Azure zu verwenden. Informationen zu den ersten Schritten finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
Voraussetzungen
Bevor Sie mit diesem Tutorial beginnen können, müssen Sie Folgendes tun:
- Wenn Sie kein Azure-Abonnement besitzen, erstellen Sie ein kostenloses Konto.
- Installieren Sie Azure PowerShell oder die Azure-Befehlszeilenschnittstelle.
- Erstellen Sie einen sicheren Windows-Cluster.
- Richten Sie eine Diagnosesammlung für den Cluster ein.
- Aktivieren Sie den EventStore-Dienst im Cluster.
- Konfigurieren Sie Azure Monitor-Protokolle und den Log Analytics-Agent für den Cluster.
Anzeigen von Service Fabric-Ereignissen mithilfe von Azure Monitor-Protokollen
Azure Monitor-Protokolle sammeln und analysieren Telemetriedaten von Anwendungen und Diensten, die in der Cloud gehostet werden. Darüber hinaus sind Analysetools verfügbar, um die Verfügbarkeit und Leistung dieser Anwendungen und Dienste maximieren zu können. Sie können Abfragen in Azure Monitor-Protokollen ausführen, um Einblicke in den Cluster zu gewinnen und Probleme zu beheben.
Wenn Sie auf die Service Fabric-Analyse-Lösung zugreifen möchten, wechseln Sie zum Azure-Portal, und wählen Sie die Ressourcengruppe aus, in der Sie die Service Fabric-Analyse-Lösung erstellt haben.
Wählen Sie die Ressource ServiceFabric(mysfomsworkspace) aus.
In der Übersicht werden Kacheln in Form eines Diagramms (Graphs) für jede der aktivierten Lösungen angezeigt, auch für Service Fabric. Wählen Sie den Graph Service Fabric aus, um mit der Service Fabric-Analyse-Lösung fortzufahren.
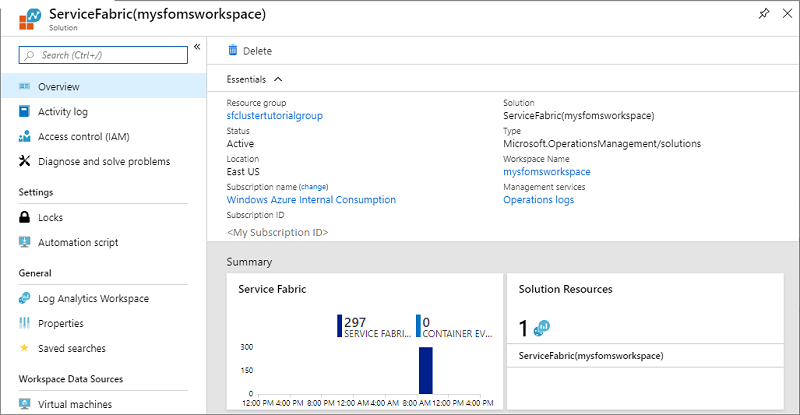
In der folgenden Abbildung ist die Startseite der Service Fabric-Analyse-Lösung dargestellt. Diese Startseite bietet eine Momentaufnahmeansicht der Vorgänge im Cluster.
Wenn Sie die Diagnose bei der Clustererstellung aktiviert haben, werden folgende Ereignisse angezeigt:
- Service Fabric-Clusterereignisse
- Ereignisse des Reliable Actors-Programmiermodells
- Ereignisse des Reliable Services-Programmiermodells
Hinweis
Zusätzlich zu den Service Fabric-Ereignissen können durch das Aktualisieren der Konfiguration der Diagnoseerweiterung detailliertere Systemereignisse erfasst werden.
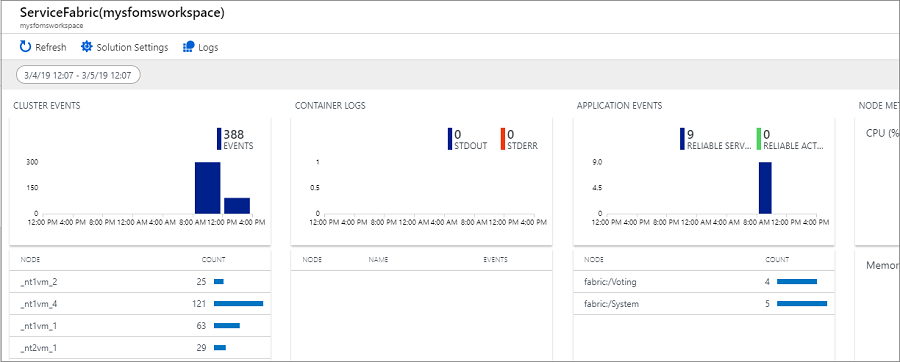
Anzeigen von Service Fabric-Ereignissen einschließlich Aktionen auf Knoten
Klicken Sie auf der Seite „Service Fabric-Analyse“ auf das Diagramm für Clusterereignisse. Daraufhin werden die Protokolle für alle erfassten Systemereignisse angezeigt. Zur Referenz: Diese stammen aus WADServiceFabricSystemEventsTable im Azure Storage-Konto. Auch die Reliable Services- und Reliable Actors-Ereignisse, die als Nächstes angezeigt werden, stammen aus diesen entsprechenden Tabellen.
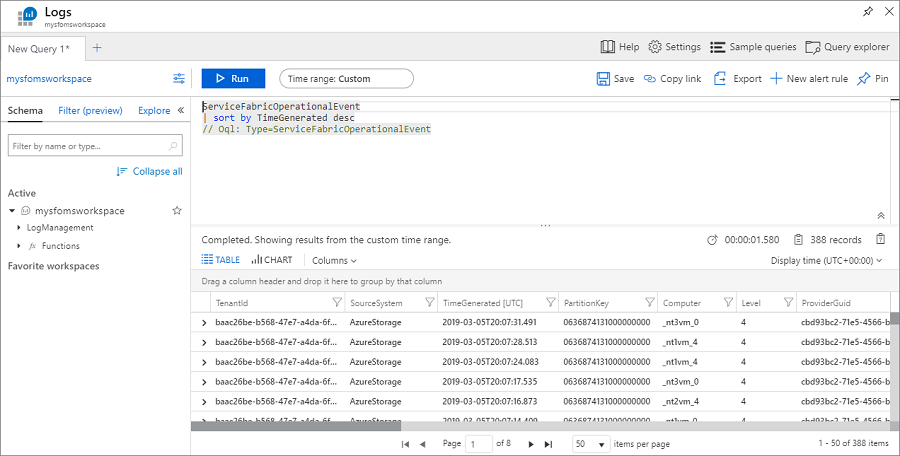
Die Abfrage verwendet die Abfragesprache Kusto, die Sie ändern können, um Ihre Suchergebnisse einzuschränken. Um beispielsweise alle Aktionen zu suchen, die im Cluster für Knoten durchgeführt wurden, können Sie die folgende Abfrage verwenden. Die unten verwendeten Ereignis-IDs finden Sie in der Referenz der Betriebskanalprotokolle.
ServiceFabricOperationalEvent
| where EventId < 25627 and EventId > 25619
Die Abfragesprache Kusto ist leistungsstark. Im Folgenden finden Sie einige weitere nützliche Abfragen.
Erstellen Sie eine ServiceFabricEvent-Nachschlagetabelle als benutzerdefinierte Funktion, indem Sie die Abfrage als Funktion mit dem Alias „ServiceFabricEvent“ speichern:
let ServiceFabricEvent = datatable(EventId: int, EventName: string)
[
...
18603, 'NodeUpOperational',
18604, 'NodeDownOperational',
...
];
ServiceFabricEvent
Geben Sie in der letzten Stunde aufgezeichnete Betriebsereignisse zurück:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Geben Sie Betriebsereignisse mit der Ereignis-ID 18604 („EventId == 18604“) und dem Ereignisnamen „NodeDownOperational“ („EventName == 'NodeDownOperational'“) zurück:
ServiceFabricOperationalEvent
| where EventId == 18604
| project EventId, EventName = 'NodeDownOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Geben Sie Betriebsereignisse mit der Ereignis-ID 18604 („EventId == 18604“) und dem Ereignisnamen „NodeUpOperational“ („EventName == 'NodeUpOperational'“) zurück:
ServiceFabricOperationalEvent
| where EventId == 18603
| project EventId, EventName = 'NodeUpOperational', TaskName, Computer, EventMessage, TimeGenerated
| sort by TimeGenerated
Geben Sie Integritätsberichte mit dem Integritätsstatus 3 (Fehler) („HealthState == 3“) zurück, und extrahieren Sie weitere Eigenschaften aus dem Feld „EventMessage“:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Geben Sie ein Zeitdiagramm von Ereignissen mit der Ereignis-ID „EventId != 17523“ zurück:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| where EventId != 17523
| summarize Count = count() by Timestamp = bin(TimeGenerated, 1h), strcat(tostring(EventId), " - ", case(EventName != "", EventName, "Unknown"))
| render timechart
Rufen Sie mit dem spezifischen Dienst und Knoten aggregierte Service Fabric-Betriebsereignisse ab:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Rendern Sie die Anzahl von Service Fabric-Ereignissen mithilfe einer ressourcenübergreifenden Abfrage nach Ereignis-ID/Ereignisname (EventId/EventName):
app('PlunkoServiceFabricCluster').traces
| where customDimensions.ProviderName == 'Microsoft-ServiceFabric'
| extend EventId = toint(customDimensions.EventId), TaskName = tostring(customDimensions.TaskName)
| where EventId != 17523
| join kind=leftouter ServiceFabricEvent on EventId
| extend EventName = case(EventName != '', EventName, 'Undocumented')
| summarize ["Event Count"]= count() by bin(timestamp, 30m), EventName = strcat(tostring(EventId), " - ", EventName)
| render timechart
Anzeigen von Service Fabric-Anwendungsereignissen
Sie können Ereignisse für die im Cluster bereitgestellten Reliable Services- und Reliable Actors-Anwendungen anzeigen. Wählen Sie auf der Seite „Service Fabric-Analyse“ den Graph für Anwendungsereignisse aus.
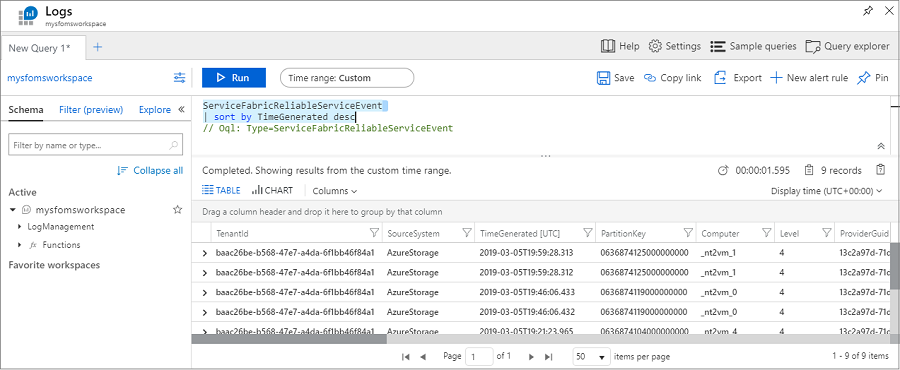
Führen Sie die folgende Abfrage aus, um Ereignisse Ihrer Reliable Services-Anwendungen anzuzeigen:
ServiceFabricReliableServiceEvent
| sort by TimeGenerated desc
Es werden unterschiedliche Ereignisse für den Start und das Ende des Diensts runasync angezeigt. Dies erfolgt normalerweise bei Bereitstellungen und Upgrades.
Sie können auch nach Ereignissen für den Reliable Service mit dem Namen „ServiceName == 'fabric:/Watchdog/WatchdogService'“ suchen:
ServiceFabricReliableServiceEvent
| where ServiceName == "fabric:/Watchdog/WatchdogService"
| project TimeGenerated, EventMessage
| order by TimeGenerated desc
Reliable Actor-Ereignisse können auf ähnliche Weise angezeigt werden:
ServiceFabricReliableActorEvent
| sort by TimeGenerated desc
Um ausführlichere Ereignisse für Reliable Actors zu konfigurieren, können Sie den scheduledTransferKeywordFilter in der Konfiguration für die Diagnoseerweiterung in der Clustervorlage ändern. Details zu den entsprechenden Werten finden Sie in der Referenz der Reliable Actors-Ereignisse.
"EtwEventSourceProviderConfiguration": [
{
"provider": "Microsoft-ServiceFabric-Actors",
"scheduledTransferKeywordFilter": "1",
"scheduledTransferPeriod": "PT5M",
"DefaultEvents": {
"eventDestination": "ServiceFabricReliableActorEventTable"
}
},
Anzeigen von Leistungsindikatoren mit Azure Monitor-Protokollen
Um Leistungsindikatoren anzuzeigen, wechseln Sie zum Azure-Portal, und navigieren Sie dann zu der Ressourcengruppe, in der Sie die Service Fabric-Analyse-Lösung erstellt haben.
Wählen Sie die Ressource ServiceFabric(mysfomsworkspace) aus, wählen Sie anschließend Log Analytics-Arbeitsbereich und dann Erweiterte Einstellungen aus.
Wählen Sie Daten und dann Windows-Leistungsindikatoren aus. Es gibt eine Liste von Standardindikatoren, die Sie aktivieren und für die Sie auch das Sammlungsintervall festlegen können. Sie können auch weitere Leistungsindikatoren hinzufügen, die erfasst werden sollen. Auf das richtige Format wird in diesem Artikel verwiesen. Wählen Sie Speichern und dann OK aus.
Schließen Sie das Blatt „Erweiterte Einstellungen“, und wählen Sie dann unter der Überschrift Allgemein die Option Zusammenfassung des Arbeitsbereichs aus. Für jede aktivierte Lösung ist eine grafische Kachel vorhanden, so auch für Service Fabric. Wählen Sie den Graph Service Fabric aus, um mit der Service Fabric-Analyse-Lösung fortzufahren.
Es sind grafische Kacheln für Betriebskanal- und Reliable Services-Ereignisse vorhanden. Die grafische Darstellung der Daten, die für die ausgewählten Leistungsindikatoren eingehen, werden unter Knotenmetriken angezeigt.
Wählen Sie den Graph Containermetrik aus, um weitere Details anzuzeigen. Sie können Leistungsindikatordaten ähnlich wie Clusterereignisse abfragen und mithilfe der Abfragesprache Kusto nach Knoten, Name des Leistungsindikators und Werten filtern.
Abfragen des EventStore-Diensts
Der EventStore-Dienst bietet eine Möglichkeit, den Zustand Ihres Clusters oder Ihrer Workloads zu einem bestimmten Zeitpunkt zu ermitteln und zu verstehen. EventStore ist ein zustandsbehafteter Service Fabric-Dienst, der Ereignisse vom Cluster verwaltet. Die Ereignisse werden über Service Fabric Explorer, REST und APIs bereitgestellt. EventStore fragt den Cluster direkt ab, um Diagnosedaten für jede Entität in Ihrem Cluster abzurufen. Eine vollständige Liste der in EventStore verfügbaren Ereignisse finden Sie unter Service Fabric-Ereignisse.
Die EventStore-APIs können mithilfe der Service Fabric-Clientbibliothek programmgesteuert abgefragt werden.
Nachfolgend finden Sie eine Beispielanforderung für alle über die Funktion „GetClusterEventListAsync“ zurückgegebenen Clusterereignisse zwischen „2018-04-03T18:00:00Z“ und „2018-04-04T18:00:00Z“.
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl, settings);
var clstrEvents = sfhttpClient.EventsStore.GetClusterEventListAsync(
"2018-04-03T18:00:00Z",
"2018-04-04T18:00:00Z")
.GetAwaiter()
.GetResult()
.ToList();
Hier ein weiteres Beispiel, das die Clusterintegrität und alle Knotenereignisse im September 2018 abfragt. Die Ergebnisse werden anschließend ausgegeben.
const int timeoutSecs = 60;
var clusterUrl = new Uri(@"http://localhost:19080"); // This example is for a Local cluster
var sfhttpClient = ServiceFabricClientFactory.Create(clusterUrl);
var clusterHealth = sfhttpClient.Cluster.GetClusterHealthAsync().GetAwaiter().GetResult();
Console.WriteLine("Cluster Health: {0}", clusterHealth.AggregatedHealthState.Value.ToString());
Console.WriteLine("Querying for node events...");
var nodesEvents = sfhttpClient.EventsStore.GetNodesEventListAsync(
"2018-09-01T00:00:00Z",
"2018-09-30T23:59:59Z",
timeoutSecs,
"NodeDown,NodeUp")
.GetAwaiter()
.GetResult()
.ToList();
Console.WriteLine("Result Count: {0}", nodesEvents.Count());
foreach (var nodeEvent in nodesEvents)
{
Console.Write("Node event happened at {0}, Node name: {1} ", nodeEvent.TimeStamp, nodeEvent.NodeName);
if (nodeEvent is NodeDownEvent)
{
var nodeDownEvent = nodeEvent as NodeDownEvent;
Console.WriteLine("(Node is down, and it was last up at {0})", nodeDownEvent.LastNodeUpAt);
}
else if (nodeEvent is NodeUpEvent)
{
var nodeUpEvent = nodeEvent as NodeUpEvent;
Console.WriteLine("(Node is up, and it was last down at {0})", nodeUpEvent.LastNodeDownAt);
}
}
Überwachen der Clusterintegrität
Mit Service Fabric wird ein Integritätsmodell eingeführt, das Integritätsentitäten enthält, für die Systemkomponenten und Watchdogs die von ihnen überwachten lokalen Bedingungen melden können. Im so genannten Integritätsspeicher werden alle Integritätsdaten zusammengefasst, um zu ermitteln, ob die Entitäten fehlerfrei sind.
Der Cluster wird automatisch mit von den Systemkomponenten gesendeten Integritätsberichten aufgefüllt. Weitere Informationen erhalten Sie unter Verwenden von Systemintegritätsberichten für die Problembehandlung.
Service Fabric macht für jeden unterstützten EntitätstypIntegritätsabfragen verfügbar. Es kann über die API (mit Methoden von FabricClient.HealthManager), mit PowerShell-Cmdlets und mit REST darauf zugegriffen werden. Mit diesen Abfragen werden vollständige Integritätsinformationen zur Entität zurückgegeben: der zusammengefasste Integritätsstatus, Integritätsereignisse der Entität, untergeordnete Integritätsstatus (falls verfügbar), Fehlerauswertungen (sofern Fehler für die Entität auftreten) und Statistiken zur Integrität untergeordneter Elemente (sofern zutreffend).
Abrufen der Clusterintegrität
Das Cmdlet Get-ServiceFabricClusterHealth gibt die Integrität der Clusterentität zurück und enthält die Integritätsstatusangaben von Anwendungen und Knoten (untergeordneten Elementen des Clusters). Stellen Sie zuerst mithilfe des Cmdlets Connect-ServiceFabricCluster eine Verbindung mit dem Cluster her.
Der Status des Clusters umfasst 11 Knoten, die Systemanwendung und „fabric:/Voting“ in der beschriebenen Konfiguration.
Im folgenden Beispiel wird die Clusterintegrität mithilfe von Standardintegritätsrichtlinien abgerufen. Die 11 Knoten werden fehlerfrei ausgeführt, aber der aggregierte Integritätsstatus des Clusters lautet „Fehler“ (Error), weil die Anwendung „fabric:/Voting“ den Status „Fehler“ (Error) aufweist. Beachten Sie, dass die Fehlerauswertungen mit Details zu den Bedingungen angezeigt werden, durch die die aggregierte Integrität ausgelöst wurde.
Get-ServiceFabricClusterHealth
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
33% (1/3) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates :
NodeName : _nt2vm_3
AggregatedHealthState : Ok
NodeName : _nt1vm_4
AggregatedHealthState : Ok
NodeName : _nt2vm_2
AggregatedHealthState : Ok
NodeName : _nt1vm_3
AggregatedHealthState : Ok
NodeName : _nt2vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_2
AggregatedHealthState : Ok
NodeName : _nt2vm_0
AggregatedHealthState : Ok
NodeName : _nt1vm_1
AggregatedHealthState : Ok
NodeName : _nt1vm_0
AggregatedHealthState : Ok
NodeName : _nt3vm_0
AggregatedHealthState : Ok
NodeName : _nt2vm_4
AggregatedHealthState : Ok
ApplicationHealthStates :
ApplicationName : fabric:/System
AggregatedHealthState : Ok
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
HealthStatistics :
Node : 11 Ok, 0 Warning, 0 Error
Replica : 4 Ok, 0 Warning, 0 Error
Partition : 2 Ok, 0 Warning, 0 Error
Service : 2 Ok, 0 Warning, 0 Error
DeployedServicePackage : 3 Ok, 1 Warning, 1 Error
DeployedApplication : 1 Ok, 1 Warning, 1 Error
Application : 0 Ok, 0 Warning, 1 Error
Im folgenden Beispiel wird die Integrität des Clusters mithilfe einer benutzerdefinierten Anwendungsrichtlinie abgerufen. Die Ergebnisse werden gefiltert, sodass nur Anwendungen und Knoten mit dem Status „Fehler“ oder „Warnung“ abgerufen werden. In diesem Beispiel werden keine Knoten zurückgegeben, da sie alle fehlerfrei sind. Nur die Anwendung „fabric:/Voting“ berücksichtigt den Anwendungsfilter. Da mit der benutzerdefinierten Richtlinie festgelegt wird, dass Warnungen für die Anwendung „fabric:/Voting“ als Fehler anzusehen sind, wird für die Anwendung der Status „Fehler“ angegeben, und daher gilt dies auch für den Cluster.
$appHealthPolicy = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicy
$appHealthPolicy.ConsiderWarningAsError = $true
$appHealthPolicyMap = New-Object -TypeName System.Fabric.Health.ApplicationHealthPolicyMap
$appUri1 = New-Object -TypeName System.Uri -ArgumentList "fabric:/Voting"
$appHealthPolicyMap.Add($appUri1, $appHealthPolicy)
Get-ServiceFabricClusterHealth -ApplicationHealthPolicyMap $appHealthPolicyMap -ApplicationsFilter "Warning,Error" -NodesFilter "Warning,Error" -ExcludeHealthStatistics
AggregatedHealthState : Error
UnhealthyEvaluations :
100% (1/1) applications are unhealthy. The evaluation tolerates 0% unhealthy applications.
Application 'fabric:/Voting' is in Error.
100% (5/5) deployed applications are unhealthy. The evaluation tolerates 0% unhealthy deployed applications.
Deployed application on node '_nt2vm_3' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '8723eb73-9b83-406b-9de3-172142ba15f3' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376195593305'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_2' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2466f2f9-d5fd-410c-a6a4-5b1e00630cca' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376486201388'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_4' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '5faa5201-eede-400a-865f-07f7f886aa32' is in Error.
'System.Hosting' reported Warning for property 'CodePackageActivation:Code:SetupEntryPoint:131959376207396204'. The evaluation treats
Warning as Error.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt2vm_0' is in Error.
100% (1/1) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '204f1783-f774-4f3a-b371-d9983afaf059' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959375885791093'.
There was an error during CodePackage activation.The service host terminated with exit code:1
Deployed application on node '_nt3vm_0' is in Error.
50% (1/2) deployed service packages are unhealthy.
Service package for manifest 'VotingWebPkg' and service package activation ID '2533ae95-2d2a-4f8b-beef-41e13e4c0081' is in Error.
'System.Hosting' reported Error for property 'CodePackageActivation:Code:SetupEntryPoint:131959376108346272'.
There was an error during CodePackage activation.The service host terminated with exit code:1
NodeHealthStates : None
ApplicationHealthStates :
ApplicationName : fabric:/Voting
AggregatedHealthState : Error
HealthEvents : None
Abrufen der Integrität von Knoten
Das Cmdlet Get-ServiceFabricNodeHealth gibt die Integrität einer Knotenentität zurück und enthält die für den Knoten gemeldeten Integritätsereignisse. Stellen Sie zuerst mithilfe des Cmdlets Connect-ServiceFabricCluster eine Verbindung mit dem Cluster her. Im folgenden Beispiel wird die Integrität eines bestimmten Knotens mithilfe von Standardintegritätsrichtlinien abgerufen:
Get-ServiceFabricNodeHealth _nt1vm_3
Im folgenden Beispiel wird die Integrität aller Knoten im Cluster abgerufen:
Get-ServiceFabricNode | Get-ServiceFabricNodeHealth | select NodeName, AggregatedHealthState | ft -AutoSize
Abrufen der Integrität von Systemdiensten
Rufen Sie die aggregierte Integrität der Systemdienste ab:
Get-ServiceFabricService -ApplicationName fabric:/System | Get-ServiceFabricServiceHealth | select ServiceName, AggregatedHealthState | ft -AutoSize
Nächste Schritte
In diesem Tutorial haben Sie Folgendes gelernt:
- Anzeigen von Service Fabric-Ereignissen
- Abfragen von EventStore-APIs nach Clusterereignissen
- Überwachen der Infrastruktur/Erfassen von Leistungsindikatoren
- Anzeigen von Clusterintegritätsberichten
Fahren Sie mit dem folgenden Tutorial fort, um zu erfahren, wie Sie einen Cluster skalieren.