Monitor Azure Service Fabric
Dieser Artikel beschreibt Folgendes:
- Die Arten von Überwachungsdaten, die Sie für diesen Dienst sammeln können
- Möglichkeiten zum Analysieren dieser Daten.
Hinweis
Wenn Sie bereits mit diesem Dienst und/oder Azure Monitor vertraut sind und nur wissen möchten, wie Überwachungsdaten analysiert werden, lesen Sie den Abschnitt Analysieren am Ende dieses Artikels.
Wenn Sie über unternehmenskritische Anwendungen und Geschäftsprozesse verfügen, die auf Azure-Ressourcen basieren, müssen Sie diese überwachen und Warnungen für Ihr System abrufen. Der Azure Monitor-Dienst sammelt und aggregiert Metriken und Protokolle aus jeder Komponente Ihres Systems. Azure Monitor bietet Ihnen eine Übersicht über Verfügbarkeit, Leistung und Resilienz und benachrichtigt Sie über Probleme. Sie können das Azure-Portal, PowerShell, die Azure CLI, die REST-API oder Clientbibliotheken verwenden, um Überwachungsdaten einzurichten und anzuzeigen.
- Weitere Informationen zu Azure Monitor finden Sie unter Azure Monitor – Übersicht.
- Weitere Informationen zum Überwachen von Azure-Ressourcen im Allgemeinen finden Sie unter Überwachen von Azure-Ressourcen mit Azure Monitor.
Überwachung von Azure Service Fabric
Azure Service Fabric verfügt über die folgenden Ebenen, die Sie überwachen können:
- Anwendungsüberwachung: Die Anwendungen, die auf den Knoten ausgeführt werden. Sie können Anwendungen mit Application Insights-Schlüssel oder SDK, EventStore oder ASP.NET Core-Protokollierung überwachen.
- Überwachung der Plattform (bzw. des Clusters): Clientmetriken, Protokolle und Ereignisse für die Plattform- oder Clusterknoten, einschließlich Containermetriken. Die Metriken und Protokolle unterscheiden sich für Linux- oder Windows-Knoten.
- Überwachung der Infrastruktur (Leistung): Dienststatus- und Leistungsindikatoren für die Dienstinfrastruktur.
Sie können die Nutzung Ihrer Anwendungen, die Aktionen der Service Fabric-Plattform, die Ressourcenverwendung (mithilfe von Leistungsindikatoren) sowie die allgemeine Integrität Ihres Clusters nachverfolgen. Azure Monitor-Protokolle und Application Insights bieten integrierte Integration in Service Fabric.
- Informationen zu Best Practices finden Sie unter Best Practices für Überwachung und Diagnose für Azure Service Fabric.
- Ein Lernprogramm, das zeigt, wie Service Fabric-Ereignisse und Integritätsberichte angezeigt werden, die EventStore-APIs abfragen und Leistungsindikatoren überwachen, finden Sie unter Tutorial: Überwachen eines Service Fabric-Clusters in Azure.
- Informationen zum Konfigurieren von Azure Monitor-Protokollen zum Überwachen Ihrer Windows-Container, die in Service Fabric orchestriert werden, finden Sie unter Tutorial: Überwachen von Windows-Containern in Service Fabric mithilfe von Azure Monitor-Protokollen.
Service Fabric Explorer
Service Fabric Explorer, eine Desktopanwendung für Windows, macOS und Linux, ist ein Open-Source-Tool zum Untersuchen und Verwalten von Azure Service Fabric-Clustern. Jede Aktion, die mit Service Fabric Explorer ausgeführt werden kann, kann auch mithilfe von PowerShell oder einer REST-API ausgeführt werden, um die Automatisierung zu ermöglichen.
Anwendungsüberwachung
Bei der Anwendungsüberwachung wird nachverfolgt, wie die Funktionen und Komponenten Ihrer Anwendung genutzt werden. In der Regel überwachen Sie Anwendungen auf Probleme, die die Benutzer beeinträchtigen könnten. Für die Anwendungsüberwachung sind die Benutzer zuständig, die eine Anwendung und die zugehörigen Dienste entwickeln, da die Überwachung stark von der Geschäftslogik Ihrer Anwendung abhängig ist. Das Überwachen Ihrer Anwendungen kann in den folgenden Szenarien hilfreich sein:
- Wie hoch ist das Datenverkehrsaufkommen für meine Anwendung? (Müssen Sie Ihre Dienste skalieren, um Benutzeranforderungen gerecht zu werden oder einen möglichen Engpass in der Anwendung zu beheben?)
- Sind Aufrufe zwischen Diensten erfolgreich, und werden sie nachverfolgt?
- Welche Aktionen führen die Benutzer meiner Anwendung aus? (Die Erfassung von Telemetriedaten kann bei der Entwicklung zukünftiger Features und bei der Diagnose von Anwendungsfehlern hilfreich sein.)
- Treten in meiner Anwendung unbehandelte Ausnahmen auf?
- Was passiert in den Diensten, die in meinem Container ausgeführt werden?
Das Praktische an der Anwendungsüberwachung ist, dass Entwickler beliebige Tools und Frameworks verwenden können, da sie innerhalb des Kontexts Ihrer Anwendung stattfindet. Weitere Informationen zur Azure-Lösung für die Anwendungsüberwachung mit Application Insights in Azure Monitor finden Sie unter Ereignisanalyse und Visualisierung mit Application Insights.
Darüber hinaus erfahren Sie in diesem Tutorial, wie Sie diese Lösung für .NET-Anwendungen einrichten. Das Tutorial zeigt, wie Sie die richtigen Tools installieren. Außerdem erfahren Sie anhand eines Beispiels, wie Sie benutzerdefinierte Telemetrie in Ihrer Anwendung schreiben, und es wird gezeigt, wie Sie die Anwendungsdiagnose und die Telemetriedaten im Azure-Portal anzeigen.
Anwendungsprotokollierung
Die Instrumentierung Ihres Codes liefert nicht nur Erkenntnisse über Ihre Benutzer. Sie ist auch die einzige Möglichkeit, um Probleme in Ihrer Anwendung zu erkennen und zu diagnostizieren. Es ist zwar technisch möglich, einen Debugger mit einem Produktionsdienst zu verbinden, aber dies ist keine gängige Vorgehensweise. Es ist also wichtig, dass Sie über ausführliche Instrumentierungsdaten verfügen.
Bei einigen Produkten wird Ihr Code automatisch instrumentiert. Diese Lösungen können zwar auch funktionieren, eine manuelle Instrumentierung muss jedoch fast immer speziell auf Ihre Geschäftslogik zugeschnitten sein. Letztlich benötigen Sie ausreichend Informationen für das genaue Debuggen der Anwendung. Service Fabric-Anwendungen können mit einem beliebigen Protokollierungsframework instrumentiert werden. In diesem Abschnitt werden verschiedene Verfahren für die Instrumentierung Ihres Codes sowie geeignete Anwendungsfälle beschrieben.
Application Insights SDK: Die umfassende Integration von Application Insights in Service Fabric ist vorkonfiguriert. Benutzer können die KI-NuGet-Pakete von Service Fabric hinzufügen und Daten und Protokolle empfangen, die so erstellt und erfasst wurden, dass sie im Azure-Portal angezeigt werden können. Außerdem wird Benutzern das Hinzufügen ihrer eigenen Telemetriedaten empfohlen, um ihre Anwendungen zu diagnostizieren und zu debuggen, und um nachzuverfolgen, welche Dienste und Teile ihrer Anwendung am häufigsten verwendet werden. Die TelemetryClient-Klasse im SDK bietet viele Methoden zum Nachverfolgen von Telemetriedaten in Ihren Anwendungen. Weitere Informationen finden Sie unter Ereignisanalyse und Visualisierung mit Application Insights.
Sehen Sie sich im Tutorial zum Überwachen und Diagnostizieren einer .NET-Anwendung ein Beispiel zum Instrumentieren und Hinzufügen von Application Insights zu Ihrer Anwendung an.
EventSource: Wenn Sie eine Service Fabric-Lösung aus einer Vorlage in Visual Studio erstellen, wird eine von EventSource abgeleitete Klasse (ServiceEventSource oder ActorEventSource) generiert. Es wird eine Vorlage erstellt, in der Sie Ereignisse für Ihre Anwendung oder Ihren Dienst hinzufügen können. Der EventSource-Name muss eindeutig sein. Er sollte auf der Standardvorlage „MyCompany-<Projektmappe>-<Projekt>“ basieren und entsprechend umbenannt werden. Mehrere EventSource-Definitionen mit dem gleichen Namen führen zur Laufzeit zu Problemen. Jedes definierte Ereignis muss über einen eindeutigen Bezeichner verfügen. Wenn ein Bezeichner nicht eindeutig ist, tritt ein Laufzeitfehler auf. In einigen Organisationen werden Wertebereiche vorab Bezeichnern zugewiesen, um Konflikte zwischen separaten Entwicklungsteams zu vermeiden. Weitere Informationen finden Sie im Blog von Vance oder in der MSDN-Dokumentation.
ASP.NET Core-Protokollierung: Es ist wichtig, dass Sie sorgfältig planen, wie Sie Ihren Code instrumentieren. Mit dem richtigen Instrumentierungsplan können Sie ggf. verhindern, dass Ihre Codebasis destabilisiert wird und eine erneute Instrumentierung des Codes erforderlich wird. Zur Reduzierung des Risikos können Sie eine Instrumentierungsbibliothek wie Microsoft.Extensions.Logging wählen, die Teil von Microsoft ASP.NET Core ist. ASP.NET Core verfügt über eine ILogger-Schnittstelle, die Sie zusammen mit dem Anbieter Ihrer Wahl nutzen können, während gleichzeitig die Auswirkungen auf den vorhandenen Code minimiert werden. Sie können den Code in ASP.NET Core unter Windows und Linux und im vollständigen .NET Framework verwenden, damit Ihr Instrumentierungscode standardisiert ist.
Beispiele zur Verwendung dieser Vorschläge finden Sie unter Hinzufügen von Protokollierung zur Service Fabric-Anwendung.
Überwachung der Plattform (bzw. des Clusters)
Ein Benutzer hat die Kontrolle über die Telemetriedaten aus seiner Anwendung, da er den Code selbst schreibt. Aber wie verhält es sich mit den Diagnosen der Service Fabric-Plattform? Ein Ziel von Service Fabric besteht darin, für Anwendungen die Resilienz in Bezug auf Hardwarefehler sicherzustellen. Dies ist möglich, weil die Systemdienste der Plattform in der Lage sind, Infrastrukturprobleme zu erkennen und für Workloads schnell ein Failover auf andere Knoten im Cluster durchzuführen. In diesem speziellen Fall stellt sich aber die Frage, was geschieht, wenn die Systemdienste selbst Probleme haben? Oder was geschieht, wenn beim Bereitstellen oder Verschieben einer Workload Regeln für die Platzierung von Diensten verletzt werden? Service Fabric bietet Diagnosen für diese und viele andere Fälle, um sicherzustellen, dass Sie über die Aktivitäten in Ihrem Cluster informiert sind. Zu den Beispielszenarien für die Clusterüberwachung zählen unter anderem folgende:
Weitere Informationen zum Überwachen Ihrer Plattform (bzw. des Clusters) finden Sie unter Überwachen des Clusters.
Service Fabric-Ereignisse
Service Fabric bietet eine umfassende Reihe von Diagnoseereignissen sofort, auf die Sie über den EventStore oder den betriebsbereiten Ereigniskanal zugreifen können, den die Plattform verfügbar macht. Diese Service Fabric-Ereignisse stellen Aktionen dar, die von der Plattform für unterschiedliche Entitäten wie Knoten, Anwendungen, Dienste, Partitionen usw. ausgeführt wurden. In Windows- und Linux-Clustern stehen jeweils die gleichen Ereignisse zur Verfügung.
Service Fabric-Ereigniskanäle: Unter Windows stehen Service Fabric-Ereignisse von einem einzelnen ETW-Anbieter mit einer Reihe relevanter
logLevelKeywordFilters-Elemente zur Verfügung, die für die Auswahl zwischen operationalen Kanälen und Daten- und Messagingkanälen verwendet werden. Auf diese Art und Weise werden ausgehende Service Fabric-Ereignisse separiert und können nach Bedarf gefiltert werden. Unter Linux laufen alle Service Fabric-Ereignisse über LTTng und werden in eine Speicherabelle eingefügt, in der sie nach Bedarf gefiltert werden können. Diese Kanäle enthalten geordnete, strukturierte Ereignisse, mit deren Hilfe sich der Zustand des Clusters besser nachvollziehen lässt. Die Diagnose ist bei der Erstellung des Clusters standardmäßig aktiviert. Hierbei wird eine Azure Storage-Tabelle erstellt, an die die Ereignisse aus diesen Kanälen gesendet werden und aus der in Zukunft Ereignisse abgefragt werden können.EventStore ist ein Feature, das Service Fabric-Plattformereignisse im Service Fabric Explorer und programmgesteuert über die REST-API der Service Fabric-Clientbibliothek anzeigt. Sie können eine Momentaufnahmeansicht der Vorgänge in Ihrem Cluster für jeden Knoten, Dienst, Anwendung und Abfrage basierend auf dem Zeitpunkt des Ereignisses anzeigen. Die EventStore-APIs sind nur für in Azure ausgeführte Windows-Cluster verfügbar. Auf Windows-Computern sind diese Ereignisse in das „EventLog“ (Ereignisprotokoll) eingebunden, sodass Service Fabric-Ereignisse in der Ereignisanzeige angezeigt werden.
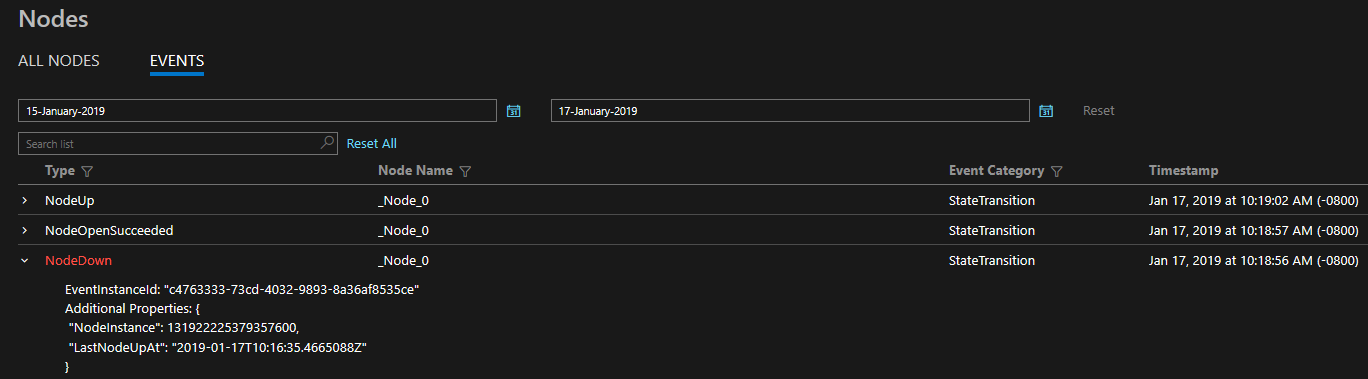
Die Diagnosen stehen bereits standardmäßig als umfassender Satz von Ereignissen zur Verfügung. Diese Service Fabric-Ereignisse stellen Aktionen dar, die von der Plattform für unterschiedliche Entitäten wie Knoten, Anwendungen, Dienste, Partitionen usw. ausgeführt wurden. Wenn im letzten der obigen Szenarien ein Knoten ausfällt, gibt die Plattform ein Ereignis vom Typ NodeDown aus, und Sie werden umgehend von Ihrem bevorzugten Überwachungstool informiert. Andere gängige Beispiele wären etwa ApplicationUpgradeRollbackStarted oder PartitionReconfigured während eines Failovers. In Windows- und Linux-Clustern stehen jeweils die gleichen Ereignisse zur Verfügung.
Die Ereignisse werden sowohl unter Windows als auch unter Linux über Standardkanäle gesendet und können von jedem Überwachungstool gelesen werden, das diese unterstützt. Die Azure Monitor-Lösung ist Azure Monitor-Protokolle. Sie können sich gerne ausführlicher über die Integration von Azure Monitor-Protokollen informieren. Diese beinhaltet ein benutzerdefiniertes Betriebsdashboard für Ihren Cluster sowie einige Beispielabfragen, die Sie als Grundlage für die Erstellung von Benachrichtigungen verwenden können. Weitere Konzepte für die Clusterüberwachung finden Sie unter Monitoring the cluster (Überwachen des Clusters).
Systemüberwachung
Die Service Fabric-Plattform umfasst ein Integritätsmodell, das erweiterbare Integritätsberichtsfunktionen für den Status von Entitäten in einem Cluster bereitstellt. Alle Knoten, Anwendungen, Dienste, Partitionen, Replikate oder Instanzen verfügen über einen kontinuierlich aktualisierbaren Integritätsstatus. Der Integritätsstatus kann entweder „OK“, „Warnung“ oder „Fehler“ lauten. Service Fabric-Ereignisse können Sie sich als Tätigkeiten vorstellen, die der Cluster für verschiedene Entitäten ausführt, und die Integrität als Eigenschaft der jeweiligen Entität. Bei jeder Änderung der Integrität einer bestimmten Entität wird auch ein Ereignis ausgegeben. Dadurch können Sie in Ihrem bevorzugten Überwachungstool Abfragen und Benachrichtigungen für Integritätsereignisse einrichten (genau wie für andere Ereignisse).
Benutzer können sogar die Integrität für Entitäten überschreiben. Wenn für Ihre Anwendung ein Upgrade ausgeführt wird und bei Validierungstests Fehler auftreten, können Sie den Service Fabric-Integritätsdienst mithilfe der Health-API darüber informieren, dass Ihre Anwendung nicht mehr fehlerfrei ist, woraufhin Service Fabric automatisch ein Rollback des Upgrades durchführt. Weitere Informationen zum Integritätsmodell finden Sie in der Einführung in die Service Fabric-Integritätsüberwachung.
Watchdogs
Ein Watchdog ist im Allgemeinen ein separater Dienst, der die Integrität und Last dienstübergreifend überwacht, Pings an Endpunkte sendet und unerwartete Integritätsereignisse im Cluster meldet. So können Fehler verhindert werden, die anhand der Leistung eines einzelnen Diensts allein nicht erkannt werden können. Watchdogs sind auch ein guter Ort zum Hosten von Code, mit dem Maßnahmen zur Problembehandlung durchgeführt werden, ohne dass eine Benutzeraktion erforderlich ist (z. B. Bereinigen von Protokolldateien im Speicher nach bestimmten Zeitintervallen). Informieren Sie sich über das FabricObserver-Projekt, wenn Sie einen vollständig implementierten Open-Source-Dienst für den SF-Watchdog benötigen, der ein benutzerfreundliches Watchdogerweiterungsmodell umfasst und sowohl in Windows- als auch in Linux-Clustern ausgeführt wird. Bei FabricObserver handelt es sich um produktionsbereite Software. Wir empfehlen, FabricObserver in Ihren Test- und Produktionsclustern bereitzustellen und zu erweitern, um Ihre Anforderungen entweder mithilfe des Plug-In-Modells oder durch Forken der Software und Schreiben Ihres eigenen integrierten Beobachters zu erfüllen. Ersteres (Plug-Ins) stellt den empfohlenen Ansatz dar.
Überwachung der Infrastruktur (Leistung)
Nachdem Sie nun mit den Diagnosen auf Anwendungs- und Plattformebene vertraut sind, stellt sich die Frage, wie Sie feststellen können, ob die Hardware wie erwartet funktioniert. Die Überwachung der zugrunde liegenden Infrastruktur ist wichtig, um einen Eindruck vom Zustand des Clusters und der Ressourcenverwendung zu erhalten. Die Messung der Systemleistung hängt je nach Workloads von zahlreichen (teilweise subjektiven) Faktoren ab. Solche Faktoren werden in der Regel mithilfe von Leistungsindikatoren gemessen. Diese Leistungsindikatoren können aus verschiedensten Quellen stammen – etwa vom Betriebssystem, aus .NET Framework oder von der Service Fabric-Plattform selbst. Sie können unter anderem zur Beantwortung folgender Fragen hilfreich sein:
- Nutze ich meine Hardware effizient? Möchten Sie Ihre CPU zu 90 Prozent auslasten oder nur zu zehn Prozent? Dies ist hilfreich, wenn Sie Ihren Cluster skalieren oder die Prozesse Ihrer Anwendung optimieren.
- Kann ich Infrastrukturprobleme proaktiv vorhersagen? Vielen Problemen geht eine plötzliche Veränderung im Leistungsverhalten (Leistungsabfall) voraus, wodurch sich Probleme mithilfe von Leistungsindikatoren (beispielsweise zu Netzwerk-E/A und CPU-Auslastung) proaktiv vorhersagen und diagnostizieren lassen.
Eine Liste der Leistungsindikatoren, die auf Infrastrukturebene erfasst werden sollten, finden Sie unter Leistungsmetriken.
Azure Monitor-Protokolle wird empfohlen, um Ereignisse auf Clusterebene zu überwachen. Nachdem Sie den Log Analytics-Agent mit Ihrem Arbeitsbereich konfiguriert haben, können Sie Folgendes erfassen:
- Leistungsmetriken wie CPU-Auslastung.
- .NET-Leistungsindikatoren wie CPU-Auslastung auf Prozessebene.
- Leistungsindikatoren für Service Fabric, z. B. die Anzahl der Ausnahmen von einem zuverlässigen Dienst.
- Containermetriken wie CPU-Auslastung.
Ressourcentypen
Azure verwendet das Konzept von Ressourcentypen und IDs, um alles in einem Abonnement zu identifizieren. Ressourcentypen sind auch Teil der Ressourcen-IDs für jede Ressource, die in Azure ausgeführt wird. Beispiel: Ein Ressourcentyp für eine VM ist Microsoft.Compute/virtualMachines. Eine Liste der Dienste und ihrer zugehörigen Ressourcentypen finden Sie unter Ressourcenanbieter.
Ähnliche organisiert Azure Monitor die Kernüberwachungsdaten in Metriken und Protokollen basierend auf Ressourcentypen, die auch als Namespaces bezeichnet werden. Für unterschiedliche Ressourcentypen stehen unterschiedliche Metriken und Protokolle zur Verfügung. Ihr Dienst ist möglicherweise mehr als einem Ressourcentyp zugeordnet.
Weitere Informationen zu den Ressourcentypen für Azure Service Fabric finden Sie unter Service Fabric-Überwachungsdatenreferenz.
Datenspeicher
For Azure Monitor:
- Metrikdaten werden in der Azure Monitor-Metrikendatenbank gespeichert.
- Protokolldaten werden im Azure Monitor-Protokollspeicher gespeichert. Log Analytics ist ein Tool im Azure-Portal zum Abfragen dieses Speichers.
- Das Azure-Aktivitätsprotokoll ist ein separater Speicher mit eigener Schnittstelle im Azure-Portal.
Optional können Sie Metrik- und Aktivitätsprotokolldaten an den Azure Monitor-Protokollspeicher weiterleiten. Anschließend können Sie Log Analytics verwenden, um die Daten abzufragen und mit anderen Protokolldaten zu korrelieren.
Viele Dienste können Diagnoseeinstellungen verwenden, um Metrik- und Protokolldaten an andere Speicherorte außerhalb von Azure Monitor zu senden. Beispiele umfassen Azure Storage, gehostete Partnersysteme und Nicht-Azure-Partnersysteme, die Event Hubs verwenden.
Detaillierte Informationen dazu, wie Azure Monitor Daten speichert, finden Sie unter Azure Monitor-Datenplattform.
Azure Monitor-Plattformmetriken
Azure Monitor stellt Plattformmetriken für viele Dienste bereit. Eine Liste aller Metriken, die für alle Ressourcen in Azure Monitor gesammelt werden können, finden Sie unter Unterstützte Metriken in Azure Monitor.
Dieser Dienst sammelt keine Plattformmetriken.
Nicht-Azure Monitor-basierte Metriken
Dieser Dienst stellt andere Metriken bereit, die nicht in der Azure Monitor-Metrikdatenbank enthalten sind.
Gastbetriebssystemmetriken
Metriken für das Gastbetriebssystem (Os), das auf Service Fabric-Clusterknoten ausgeführt wird, müssen über einen oder mehrere Agents gesammelt werden, die auf dem Gastbetriebssystem ausgeführt werden. Zu den Metriken des Gastbetriebssystems gehören Leistungszähler, die den Gast-CPU-Prozentsatz oder die Speichernutzung verfolgen, die beide häufig für die automatische Skalierung oder Alarmierung verwendet werden.
Es wird empfohlen, den Azure Monitor-Agent zu verwenden und zu konfigurieren, um Leistungsmetriken des Gastbetriebssystems über die benutzerdefinierte Metrik-API in die Azure Monitor-Metrikdatenbank zu senden. Sie können die Gastbetriebssystemmetriken mithilfe desselben Agents an Azure Monitor Logs senden. Anschließend können Sie diese Metriken und Protokolle mithilfe von Log Analytics abfragen.
Hinweis
Der Azure Monitor-Agent ersetzt die Azure-Diagnoseerweiterung und den Log Analytics-Agent für das Routing des Gastbetriebssystems. Weitere Informationen finden Sie unter Übersicht über Azure Monitor-Agents.
Azure Monitor-Ressourcenprotokolle
Ressourcenprotokolle bieten Einblicke in Vorgänge, die von einer Azure-Ressourcen ausgeführt wurden. Protokolle werden automatisch generiert, aber Sie müssen sie an Azure Monitor-Protokolle weiterleiten, um sie zu speichern oder abzufragen. Protokolle sind in Kategorien unterteilt. Ein bestimmter Namespace kann mehrere Ressourcenprotokollkategorien enthalten, die Sie sammeln können.
Dieser Dienst sammelt keine Ressourcenprotokolle, aber Sie finden Informationen zu diesen in Überwachung von Daten aus Azure-Ressourcen.
Service Fabric-Protokolle und -Ereignisse
Service Fabric kann die folgenden Protokolle erfassen:
- Für Windows-Cluster können Sie die Clusterüberwachung mit Diagnose-Agent und Azure Monitor-Protokollen einrichten.
- Für Linux-Cluster ist Azure Monitor-Protokolle ebenfalls das empfohlene Tool für die Überwachung der Azure-Plattform und -Infrastruktur. Für die Linux-Plattformdiagnose sind unterschiedliche Konfigurationen erforderlich. Weitere Informationen finden Sie unter Service Fabric Linux-Clusterereignisse in Syslog.
- Sie können den Azure Monitor-Agent so konfigurieren, dass Gastbetriebssystemprotokolle an Azure Monitor-Protokolle gesendet werden, in denen Sie sie mithilfe von Log Analytics abfragen können.
- Sie können Service Fabric-Containerprotokolle in stdout oder stderr schreiben, damit sie in Azure Monitor-Protokollen verfügbar sind.
- Sie können die Containerüberwachungslösung für Azure Monitor-Protokolle einrichten, um Containerereignisse anzuzeigen.
Weitere Protokollierungslösungen
Die beiden empfohlenen Lösungen (Azure Monitor-Protokolle und Application Insights) verfügen zwar über eine integrierte Integration in Service Fabric, aber viele Ereignisse werden über ETW-Anbieter geschrieben und können um andere Protokollierungslösungen erweitert werden. Unter Umständen kommt für Sie auch Elastic Stack (insbesondere, wenn Sie einen Cluster in einer Offlineumgebung ausführen möchten), Dynatrace oder eine andere Plattform infrage. Eine Liste der integrierten Partner finden Sie unter Azure Service Fabric Überwachungspartner.
Wichtige Aspekte für jede Plattform sind unter anderem, wie gut Sie mit der Benutzeroberfläche, den Abfragefunktionen, den verfügbaren benutzerdefinierten Visualisierungen und Dashboards sowie mit den zusätzlichen Tools zur Erweiterung der Überwachung zurechtkommen.
Azure-Aktivitätsprotokoll
Das Aktivitätsprotokoll enthält Ereignisse auf Abonnementebene, die Vorgänge für jede Azure-Ressource nachverfolgen, so wie sie von außerhalb dieser Ressource gesehen werden, z. B. das Erstellen einer neuen Ressource oder das Starten einer VM.
Sammlung: Aktivitätsprotokollereignisse werden automatisch generiert und in einem separaten Speicher für die Anzeige im Azure-Portal gesammelt.
Routing: Sie können Aktivitätsprotokolldaten an Azure Monitor-Protokolle senden, damit Sie diese zusammen mit anderen Protokolldaten analysieren können. Andere Speicherorte wie z. B. Azure Storage, Azure Event Hubs und bestimmte Microsoft-Überwachungspartner sind ebenfalls verfügbar. Weitere Informationen zum Weiterleiten von Aktivitätsprotokollen finden Sie unter Übersicht über das Azure-Aktivitätsprotokoll.
Analysieren von Überwachungsdaten
Es gibt viele Tools zum Analysieren von Überwachungsdaten.
Azure Monitor-Tools
Azure Monitor unterstützt die folgenden grundlegenden Tools:
Metriken-Explorer, ein Tool im Azure-Portal, mit dem Sie Metriken für Azure-Ressourcen anzeigen und analysieren können. Weitere Informationen finden Sie unter Analysieren von Metriken mit dem Azure Monitor-Metrik-Explorer.
Log Analytics, ein Tool im Azure-Portal, mit dem Sie Protokolldaten mithilfe der KQL-Abfragesprache abfragen und analysieren können. Weitere Informationen finden Sie unter Erste Schritte mit Protokollabfragen in Azure Monitor.
Das Aktivitätsprotokoll, das über eine Benutzeroberfläche im Azure-Portal für die Anzeige und einfache Suchvorgänge verfügt. Um ausführlichere Analysen durchzuführen, müssen Sie die Daten an Azure Monitor-Protokolle weiterleiten und komplexere Abfragen in Log Analytics ausführen.
Zu den Tools, die eine komplexere Visualisierung ermöglichen, gehören:
- Dashboards, mit denen Sie verschiedene Typen von Daten in einen einzelnen Bereich im Azure-Portal kombinieren können.
- Arbeitsmappen, anpassbare Berichte, die Sie im Azure-Portal erstellen können. Arbeitsmappen können Text, Metriken und Protokollabfragen enthalten.
- Grafana, ein Tool auf einer offenen Plattform, das für operationale Dashboards ideal ist. Sie können Grafana verwenden, um Dashboards zu erstellen, die Daten aus mehreren anderen Quellen als Azure Monitor enthalten.
- Power BI ist ein Geschäftsanalysedienst, der interaktive Visualisierungen für verschiedene Datenquellen bereitstellt. Sie können Power BI für den automatischen Import von Protokolldaten aus Azure Monitor konfigurieren, um diese Visualisierungen zu nutzen.
Eine Übersicht über allgemeine Service Fabric-Überwachungsanalyseszenarien finden Sie unter Diagnose allgemeiner Szenarien mit Service Fabric.
Exporttools für Azure Monitor
Sie können Daten aus Azure Monitor in andere Tools abrufen, indem Sie die folgenden Methoden verwenden:
Metriken: Verwenden Sie die REST-API für Metriken, um Metrikdaten aus der Azure Monitor-Metrikendatenbank zu extrahieren. Die API unterstützt Filterausdrücke, um die abgerufenen Daten zu verfeinern. Weitere Informationen finden Sie in der Referenz zur Azure Monitor-REST-API.
Protokolle: Verwenden Sie die REST-API oder die zugeordneten Clientbibliotheken.
Eine weitere Option ist der Arbeitsbereichsdatenexport.
Informationen zu den ersten Schritten mit der REST-API für Azure Monitor finden Sie in der exemplarischen Vorgehensweise für die Azure-Überwachungs-REST-API.
Kusto-Abfragen
Sie können Überwachungsdaten im Azure Monitor Logs / Log Analytics Store mithilfe der Kusto-Abfragesprache (KQL) analysieren.
Wichtig
Wenn Sie Protokolle im Menü des Diensts im Portal auswählen, wird Log Analytics geöffnet, wobei der Abfragebereich auf den aktuellen Dienst festgelegt ist. Dieser Bereich bedeutet, dass Protokollabfragen nur Daten aus diesem Ressourcentyp umfassen. Wenn Sie eine Abfrage durchführen möchten, die Daten aus anderen Azure-Diensten enthält, wählen Sie im Menü Azure Monitor die Option Protokolle aus. Ausführliche Informationen finden Sie unter Protokollabfragebereich und Zeitbereich in Azure Monitor Log Analytics.
Eine Liste häufiger Abfragen für alle Dienste finden Sie unter Log Analytics-Abfrageschnittstelle.
Beispielabfragen
Die folgenden Abfragen geben Service Fabric-Ereignisse zurück, einschließlich Aktionen auf Knoten. Weitere nützliche Abfragen finden Sie unter Service Fabric-Ereignisse.
Geben Sie in der letzten Stunde aufgezeichnete Betriebsereignisse zurück:
ServiceFabricOperationalEvent
| where TimeGenerated > ago(1h)
| join kind=leftouter ServiceFabricEvent on EventId
| project EventId, EventName, TaskName, Computer, ApplicationName, EventMessage, TimeGenerated
| sort by TimeGenerated
Zurückgeben von Integritätsberichten mit HealthState == 3 (Fehler) und Extrahieren weiterer Eigenschaften aus dem EventMessage Feld:
ServiceFabricOperationalEvent
| join kind=leftouter ServiceFabricEvent on EventId
| extend HealthStateId = extract(@"HealthState=(\S+) ", 1, EventMessage, typeof(int))
| where TaskName == 'HM' and HealthStateId == 3
| extend SourceId = extract(@"SourceId=(\S+) ", 1, EventMessage, typeof(string)),
Property = extract(@"Property=(\S+) ", 1, EventMessage, typeof(string)),
HealthState = case(HealthStateId == 0, 'Invalid', HealthStateId == 1, 'Ok', HealthStateId == 2, 'Warning', HealthStateId == 3, 'Error', 'Unknown'),
TTL = extract(@"TTL=(\S+) ", 1, EventMessage, typeof(string)),
SequenceNumber = extract(@"SequenceNumber=(\S+) ", 1, EventMessage, typeof(string)),
Description = extract(@"Description='([\S\s, ^']+)' ", 1, EventMessage, typeof(string)),
RemoveWhenExpired = extract(@"RemoveWhenExpired=(\S+) ", 1, EventMessage, typeof(bool)),
SourceUTCTimestamp = extract(@"SourceUTCTimestamp=(\S+)", 1, EventMessage, typeof(datetime)),
ApplicationName = extract(@"ApplicationName=(\S+) ", 1, EventMessage, typeof(string)),
ServiceManifest = extract(@"ServiceManifest=(\S+) ", 1, EventMessage, typeof(string)),
InstanceId = extract(@"InstanceId=(\S+) ", 1, EventMessage, typeof(string)),
ServicePackageActivationId = extract(@"ServicePackageActivationId=(\S+) ", 1, EventMessage, typeof(string)),
NodeName = extract(@"NodeName=(\S+) ", 1, EventMessage, typeof(string)),
Partition = extract(@"Partition=(\S+) ", 1, EventMessage, typeof(string)),
StatelessInstance = extract(@"StatelessInstance=(\S+) ", 1, EventMessage, typeof(string)),
StatefulReplica = extract(@"StatefulReplica=(\S+) ", 1, EventMessage, typeof(string))
Rufen Sie mit dem spezifischen Dienst und Knoten aggregierte Service Fabric-Betriebsereignisse ab:
ServiceFabricOperationalEvent
| where ApplicationName != "" and ServiceName != ""
| summarize AggregatedValue = count() by ApplicationName, ServiceName, Computer
Alerts
Azure Monitor-Warnungen informieren Sie proaktiv, wenn bestimmte Bedingungen in Ihren Überwachungsdaten auftreten. Warnungen ermöglichen Ihnen, Probleme in Ihrem System zu identifizieren und zu beheben, bevor Ihre Kunden sie bemerken. Weitere Informationen finden Sie unter Azure Monitor-Warnungen.
Es gibt viele Quellen allgemeiner Warnungen für Azure-Ressourcen. Beispiele für häufige Warnungen für Azure-Ressourcen finden Sie in den Beispielabfragen für Protokollwarnungen. Die Website Azure Monitor-Baselinewarnungen (Azure Monitor Baseline Alerts, AMBA) stellt eine halbautomatisierte Methode für die Implementierung wichtiger Metrikwarnungen der Plattform, Dashboards und Richtlinien bereit. Die Website gilt für eine fortlaufend erweiterte Teilmenge von Azure-Diensten, einschließlich aller Dienste, die Teil der Azure-Zielzone (Azure Landing Zone, ALZ) sind.
Mit dem allgemeinen Warnungsschema wird die Benutzeroberfläche für Warnungsbenachrichtigungen in Azure Monitor standardisiert. Weitere Informationen finden Sie unter Allgemeines Warnungsschema.
Warnungstypen
Sie können zu jeder Metrik oder Protokolldatenquelle der Azure Monitor-Datenplattform Warnungen erhalten. Es gibt viele verschiedene Typen von Warnungen, abhängig von den Diensten, die Sie überwachen, und den Überwachungsdaten, die Sie sammeln. Verschiedene Typen von Warnungen haben jeweils ihre Vor- und Nachteile. Weitere Informationen finden Sie unter Auswählen des richtigen Warnungsregeltyps.
In der folgenden Liste werden die Typen von Azure Monitor-Warnungen beschrieben, die Sie erstellen können:
- Metrikwarnungen bewerten Ressourcenmetriken in regelmäßigen Abständen. Metriken können Plattformmetriken, benutzerdefinierte Metriken, in Metriken konvertierte Protokolle aus Azure Monitor oder Application Insights-Metriken sein. Metrikwarnungen können auch mehrere Bedingungen und dynamische Schwellwerte anwenden.
- Protokollwarnungen ermöglichen es Benutzern, eine Log Analytics-Abfrage zum Auswerten von Ressourcenprotokollen in vordefinierten Frequenz zu verwenden.
- Aktivitätsprotokollwarnungen werden ausgelöst, wenn ein neues Aktivitätsprotokollereignis eintritt, das definierte Bedingungen erfüllt. Resource Health- und Service Health-Warnungen sind Aktivitätsprotokollwarnungen, die über die Dienst- und Ressourcenintegrität berichten.
Einige Azure-Dienste unterstützen auch intelligente Erkennungswarnungen, Prometheus-Warnungen oder empfohlene Warnungsregeln.
Einige Dienste können Sie im großen Stil überwachen, indem Sie dieselbe Metrikwarnungsregel auf mehrere Ressourcen desselben Typs anwenden, die sich in derselben Azure-Region befinden. Für jede überwachte Ressource werden einzelne Benachrichtigungen gesendet. Unterstützte Azure-Dienste und -Clouds finden Sie unter Überwachen mehrerer Ressourcen mit einer Warnungsregel.
Service Fabric-Warnungsregeln
In der folgenden Tabelle sind einige Warnungsregeln für Service Fabric aufgeführt. Diese Warnungen sind nur Beispiele. Sie können Warnungen für jeden Metrik-, Protokolleintrags- oder Aktivitätsprotokolleintrag festlegen, der im Service Fabric-Überwachungsdatenverweis oder in der Liste der Service Fabric-Ereignisse aufgeführt ist.
| Warnungstyp | Bedingung | Beschreibung |
|---|---|---|
| Knoten-Ereignis | Knoten fällt aus | ServiceFabricOperationalEvent, wobei EventID >= 25622 und EventID <= 25626. Diese Ereignis-IDs finden Sie in der Referenz zu Knotenereignissen. |
| Anwendungsereignis- | Zurücksetzung Anwendungsupgrade | ServiceFabricOperationalEvent, wobei EventID == 29623 oder EventID == 29624. Diese Ereignis-IDs finden Sie in der Referenz zu Anwendungsereignissen. |
| Ressourcenintegrität | Upgradedienst nicht erreichbar/nicht verfügbar | Cluster wechselt zum Status "UpgradeServiceUnreachable". |
Advisor-Empfehlungen
Wenn in einigen Diensten während eines Ressourcenvorgangs kritische Bedingungen oder unmittelbar bevorstehende Änderungen auftreten, wird auf der Dienstseite Übersicht im Portal eine Warnung angezeigt. Weitere Informationen und empfohlene Korrekturen für die Warnung finden Sie in Advisor-Empfehlungen unter Überwachung im linken Menü. Während des normalen Betriebs werden keine Advisor-Empfehlungen angezeigt.
Weitere Informationen zu Azure Advisor finden Sie unter Azure Advisor – Übersicht.
Empfohlene Einrichtung
Nachdem Sie nun mit den einzelnen Bereichen für die Überwachung sowie mit entsprechenden Beispielszenarien vertraut sind, finden Sie im Anschluss eine Zusammenfassung der Azure-Überwachungstools und der Einrichtungsschritte, die für die Überwachung aller oben genannten Bereiche erforderlich sind.
- Anwendungsüberwachung mit Application Insights
- Clusterüberwachung mit Diagnose-Agent und Azure Monitor-Protokollen
- Infrastrukturüberwachung mit Azure Monitor-Protokollen
Sie können auch die ARM-Beispielvorlage verwenden und anpassen, um die Bereitstellung aller erforderlichen Ressourcen und Agents zu automatisieren.
Zugehöriger Inhalt
- Eine Referenz der Metriken, Protokolle und anderer wichtiger Werte, die für Service Fabric erstellt wurden, finden Sie unter Service Fabric Überwachungsdaten.
- Allgemeine Informationen zur Überwachung von Azure-Ressourcen finden Sie unter Überwachen von Azure-Ressourcen mit Azure Monitor.
- Siehe Liste mit Service Fabric-Ereignissen.