Einrichten der Notfallwiederherstellung für SQL Server
In diesem Artikel wird beschrieben, wie Sie das SQL Server-Back-End einer Anwendung schützen können. Dazu verwenden Sie eine Kombination aus SQL Server-Technologien für Geschäftskontinuität und Notfallwiederherstellung (Business Continuity and Disaster Recovery, BCDR) und Azure Site Recovery.
Bevor Sie beginnen, stellen Sie sicher, dass Sie die SQL Server-Funktionen für die Notfallwiederherstellung kennen. Diese Funktionen umfassen:
- Failoverclustering
- Always On-Verfügbarkeitsgruppen
- Datenbankspiegelung
- Protokollversand
- Aktive Georeplikation
- Autofailover-Gruppen
Kombinieren von BCDR-Technologien mit Site Recovery
Die Wahl einer BCDR-Technologie für die Wiederherstellung von SQL Server-Instanzen sollte auf Ihren Anforderungen an Recovery Time Objective (RTO) und Recovery Point Objective (RPO) basieren, wie in der folgenden Tabelle beschrieben. Kombinieren Sie Site Recovery mit dem Failovervorgang der ausgewählten Technologie, um die Wiederherstellung Ihrer gesamten Anwendung zu orchestrieren.
| Bereitstellungstyp | BCDR-Technologie | Erwartete RTO für SQL Server | Erwartete RPO für SQL Server |
|---|---|---|---|
| SQL Server auf einem virtuellen IaaS-Computer (Infrastructure-as-a-Service-VM) in Azure oder lokal. | AlwaysOn-Verfügbarkeitsgruppe | Die Zeit, die es dauert, das sekundäre Replikat zum primären zu machen. | Weil die Replikation zum sekundären Replikat asynchron ist, tritt ein gewisser Datenverlust auf. |
| SQL Server auf einer Azure-IaaS-VM oder auf einem lokalem System. | Failoverclustering (Always On-FCI) | Die Zeit, die das Failover zwischen Knoten benötigt. | Da Always On freigegebenen Speicher verwendet, ist dieselbe Ansicht der Speicherinstanz bei einem Failover verfügbar. |
| SQL Server auf einer Azure-IaaS-VM oder auf einem lokalem System. | Datenbankspiegelung (Hochleistungsmodus) | Die erforderliche Zeit, um den Dienst zu erzwingen, der den Spiegelserver als betriebsbereiten Standbyserver nutzt. | Die Replikation ist asynchron. Bei der Spiegeldatenbank kann im Vergleich zur Prinzipaldatenbank zu etwas Verzögerung auftreten. Die Verzögerung ist in der Regel gering. Sie kann jedoch sehr groß werden, wenn das System des Prinzipals oder Spiegelservers stark ausgelastet ist. Der Protokollversand kann eine Ergänzung der Datenbankspiegelung darstellen. Es ist eine günstige Alternative zur asynchronen Datenbankspiegelung. |
| SQL als Platform-as-a-Service (PaaS) in Azure. Dieser Bereitstellungstyp umfasst Einzeldatenbanken und Pools für elastische Datenbanken. |
Aktive Georeplikation | 30 Sekunden nach dem Auslösen des Failovers. Wenn das Failover für eine sekundäre Datenbank aktiviert ist, werden alle anderen sekundären Datenbanken automatisch mit der neuen primären Datenbank verknüpft. |
RPO von fünf Sekunden. Die aktive Georeplikation verwendet die Always On-Technologie von SQL Server. Sie repliziert asynchron durchgeführte Transaktionen der primären Datenbank zu einer sekundären Datenbank mithilfe der Momentaufnahmenisolation. Die sekundären Daten haben niemals partielle Transaktionen. |
| SQL als PaaS ist mit aktiver Georeplikation auf Azure konfiguriert. Dieser Bereitstellungstyp umfasst verwaltete Instanzen, Pools für elastische Datenbanken und einzelne Datenbanken. |
Autofailover-Gruppen | RTO von einer Stunde. | RPO von fünf Sekunden. Autofailover-Gruppen stellen die Gruppensemantik zusätzlich zur aktiven Georeplikation bereit. Es wird jedoch der gleiche asynchrone Replikationsmechanismus verwendet. |
| SQL Server auf einer Azure-IaaS-VM oder auf einem lokalem System. | Replikation mit Azure Site Recovery | Die RTO beträgt in der Regel weniger als 15 Minuten. Weitere Informationen finden Sie in der SLA für Site Recovery. | Eine Stunde für die Anwendungskonsistenz und fünf Minuten für die Absturzkonsistenz. Wenn Sie nach einer niedrigeren RPO suchen, verwenden Sie andere BCDR-Technologien. |
Hinweis
Wenn Sie SQL-Workloads mit Site Recovery schützen, müssen Sie einige wichtige Überlegungen anstellen:
- Site Recovery ist anwendungsunabhängig. Site Recovery kann jede Version von SQL Server schützen, die auf einem unterstützten Betriebssystem bereitgestellt wird. Weitere Informationen finden Sie in der Unterstützungsmatrix für die Notfallwiederherstellung replizierter Computer.
- Sie können Site Recovery für eine Bereitstellung unter Azure, Hyper-V, VMware oder in einer physischen Infrastruktur verwenden. Halten Sie sich an die Anweisungen am Ende des Artikels, um einen SQL Server-Cluster mit Site Recovery zu schützen.
- Stellen Sie sicher, dass die Datenänderungsrate auf dem Computer innerhalb der Site Recovery-Grenzwerte liegt. Die Änderungsrate wird in pro Sekunde geschriebenen Bytes gemessen. Bei Computern, auf denen Windows ausgeführt wird, können Sie diese Änderungsrate anzeigen, indem Sie im Task-Manager die Registerkarte Leistung auswählen. Beachten Sie die Schreibgeschwindigkeit für jeden Datenträger.
- Site Recovery unterstützt die Replikation von Failoverclusterinstanzen in direkten Speicherplätzen. Weitere Informationen finden Sie unter Replizieren von virtuellen Azure-Computern, die „Direkte Speicherplätze“ verwenden, in einer anderen Azure-Region.
Wenn Sie die SQL-Workload zu Azure migrieren, empfiehlt es sich, die Leistungsrichtlinien für SQL Server auf Azure Virtual Machines anzuwenden.
Notfallwiederherstellung einer Anwendung
Site Recovery orchestriert das Testfailover und das Failover Ihrer gesamten Anwendung mithilfe von Wiederherstellungsplänen.
Es gibt einige Voraussetzungen, um sicherzustellen, dass Ihr Wiederherstellungsplan vollständig Ihren Bedürfnissen angepasst ist. Für jede Bereitstellung einer SQL Server-Instanz ist normalerweise eine Active Directory-Bereitstellung erforderlich. Und Sie benötigen eine Verbindung für Ihre Logikschicht.
Schritt 1: Einrichten von Active Directory
Richten Sie für den ordnungsgemäßen Betrieb von SQL Server Active Directory am sekundären Wiederherstellungsstandort ein.
- Kleines Unternehmen: Sie haben eine kleine Anzahl von Anwendungen und einen einzelnen Domänencontroller für den lokalen Standort. Wenn Sie ein Failover für den gesamten Standort ausführen möchten, verwenden Sie die Site Recovery-Replikation. Dieser Dienst repliziert den Domänencontroller im sekundären Rechenzentrum oder in Azure.
- Mittleres bis großes Unternehmen: Möglicherweise müssen Sie zusätzliche Domänencontroller einrichten.
- Wenn Sie über eine hohe Anzahl von Anwendungen verfügen, eine Active Directory-Gesamtstruktur verwenden und ein anwendungs- oder workloadspezifisches Failover durchführen möchten, richten Sie einen weiteren Domänencontroller im sekundären Rechenzentrum oder in Azure ein.
- Wenn Sie für die Wiederherstellung an einem Remotestandort Always On-Verfügbarkeitsgruppen verwenden, richten Sie einen weiteren Domänencontroller am sekundären Standort oder in Azure ein. Dieser Domänencontroller wird für die wiederhergestellte SQL Server-Instanz verwendet.
Die Anweisungen in diesem Artikel setzen voraus, dass am sekundären Standort ein Domänencontroller verfügbar ist. Weitere Informationen finden Sie unter Einrichten der Notfallwiederherstellung für Active Directory und DNS.
Schritt 2: Sicherstellen der Konnektivität mit anderen Ebenen
Sobald die Datenbankebene in der Azure-Zielregion ausgeführt wird, stellen Sie sicher, dass Konnektivität mit der Anwendungs- und Webebene besteht. Führen Sie vorab die notwendigen Schritte durch, um die Konnektivität mit einem Testfailover zu überprüfen.
Die folgenden Beispiele helfen Ihnen, zu verstehen, wie Sie Anwendungen unter Konnektivitätsaspekten entwickeln können:
- Entwickeln Sie eine Anwendung für die Cloud-Notfallwiederherstellung
- Notfallwiederherstellungsstrategien für Pool für elastische Datenbanken
Schritt 3: Interoperabilität mit Always On, aktive Georeplikation und Gruppen für automatisches Failover
Die BCDR-Technologien Always On, aktive Georeplikation und Autofailover-Gruppen haben sekundäre Replikate von SQL Server-Instanzen, die in der Azure-Zielregion ausgeführt werden. Der erste Schritt für das Anwendungsfailover besteht darin, dieses Replikat als primäres Replikat anzugeben. Dieser Schritt setzt voraus, dass Sie bereits einen Domänencontroller im sekundären Rechenzentrum haben. Der Schritt mag nicht notwendig sein, wenn Sie sich für ein Autofailover entscheiden. Erst nachdem das Datenbankfailover abgeschlossen ist, sollten Sie es für Ihre Web- oder Anwendungsebenen ausführen.
Hinweis
Wenn Sie die SQL-Computer mit Site Recovery geschützt haben, müssen Sie nur eine Wiederherstellungsgruppe mit diesen Computern erstellen und ihre Failover in den Wiederherstellungsplan einfügen.
Erstellen Sie einen Wiederherstellungsplan mit Anwendungs- und Webebene auf virtuellen Computern. In den folgenden Schritten wird gezeigt, wie ein Failover der Datenbankebene hinzugefügt wird:
Importieren Sie die Skripts zum Durchführen eines Failovers für die SQL-Verfügbarkeitsgruppe sowohl auf einen mit Resource Manager erstellten virtuellen Computer als auch einen klassischen virtuellen Computer. Importieren Sie die Skripts in Ihr Azure Automation-Konto.

Fügen Sie das ASR-SQL-FailoverAG-Skript als vorausgehende Aktion der ersten Gruppe des Wiederherstellungsplans hinzu.
Befolgen Sie die im Skript verfügbaren Anweisungen, um eine Automation-Variable zu erstellen. Diese Variable gibt den Namen der Verfügbarkeitsgruppen an.
Schritt 4: Führen Sie ein Testfailover aus
Einige BCDR-Technologien wie SQL Always On unterstützten Testfailover nicht nativ. Wir empfehlen den folgenden Ansatz nur, wenn Sie ihn in solche Technologien integrieren möchten.
Richten Sie Azure Backup auf dem virtuellen Computer ein, auf dem das Replikat der Verfügbarkeitsgruppe in Azure gehostet wird.
Vor dem Auslösen des Testfailovers des Wiederherstellungsplans stellen Sie den virtuellen Computer aus der im vorherigen Schritt erstellten Sicherung wieder her.
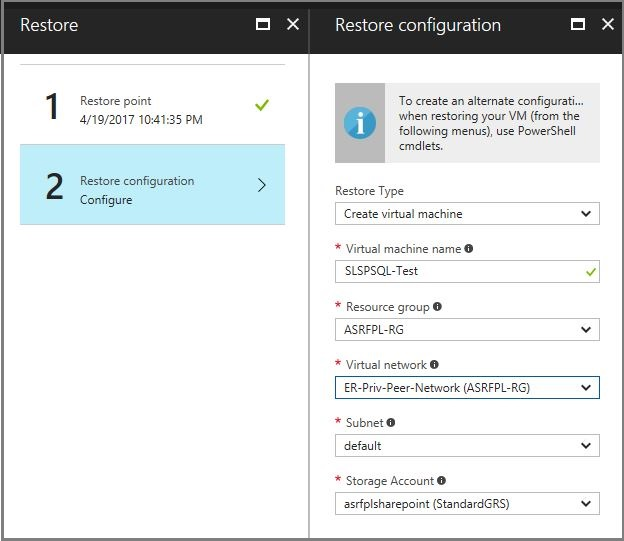
Erzwingen Sie ein Quorum auf dem virtuellen Computer, der aus einer Sicherung wiederhergestellt wurde.
Aktualisieren Sie die IP-Adresse des Listeners in eine IP-Adresse, die im Testfailovernetzwerk verfügbar ist.
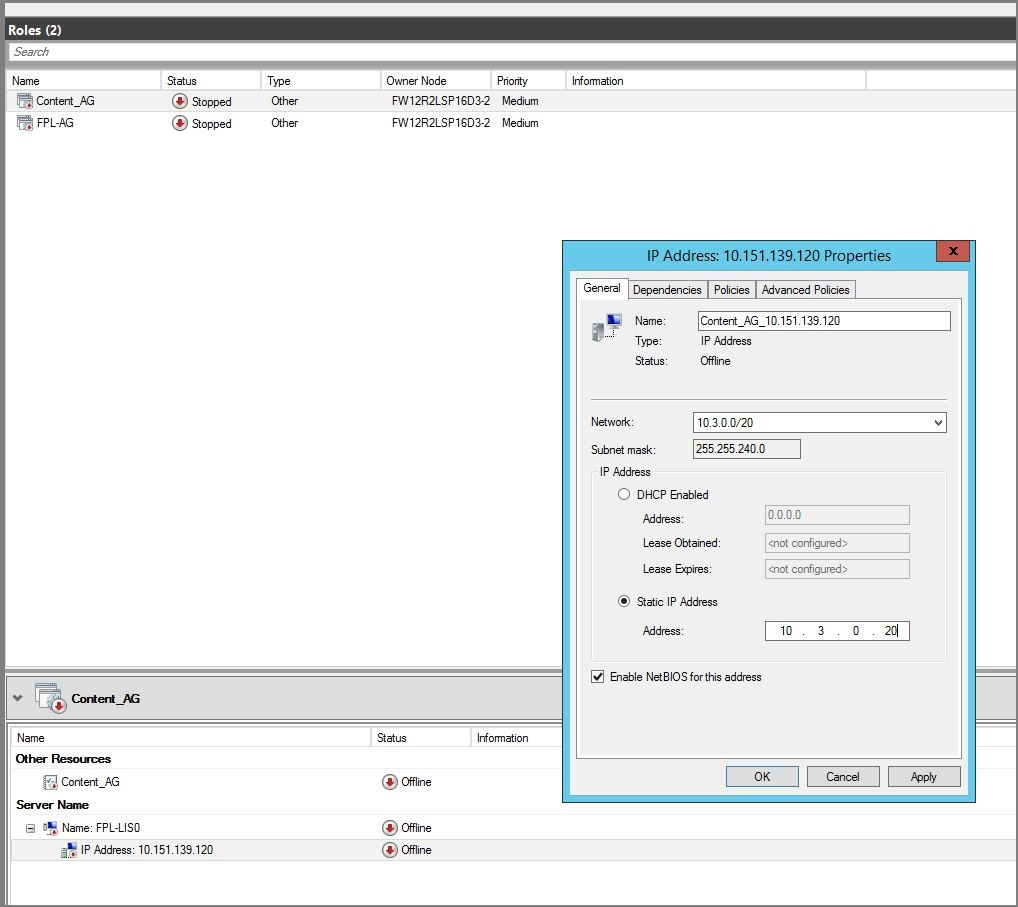
Schalten Sie den Listener online.
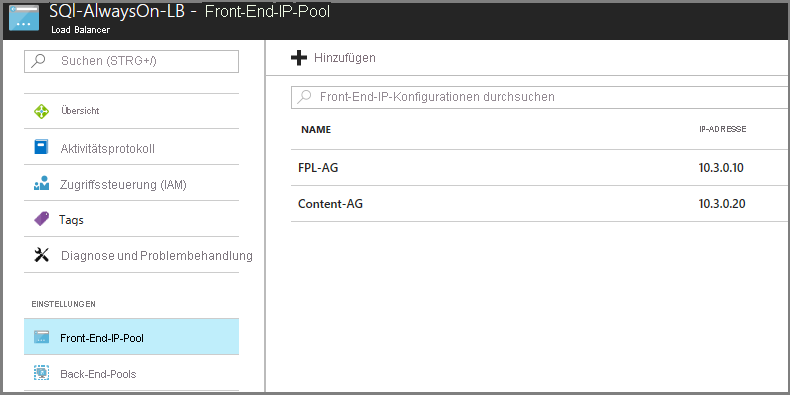
Stellen Sie sicher, dass der Lastenausgleich im Failovernetzwerk über eine IP-Adresse aus dem Front-End-IP-Adresspool verfügt, der jedem Verfügbarkeitsgruppenlistener und dem virtuellen SQL Server-Computer im Back-End-Pool entspricht.
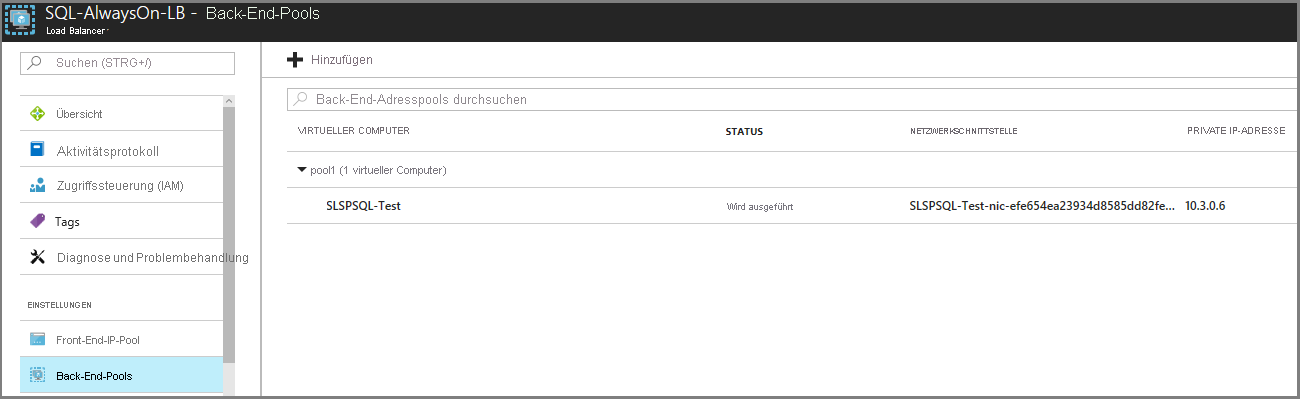
Fügen Sie in späteren Wiederherstellungsgruppen ein Failover Ihrer Anwendungsebene gefolgt von Ihrer Webeebene für diesen Wiederherstellungsplan hinzu.
Führen Sie ein Testfailover des Wiederherstellungsplans durch, um das End-to-End-Failover Ihrer Anwendung zu prüfen.
Schritte zum Failover
Nachdem Sie das Skript in Schritt 3 hinzugefügt und in Schritt 4 überprüft haben, können Sie ein Failover des Wiederherstellungsplans durchführen, den Sie in Schritt 3 erstellt haben.
Die Failoverschritte für Anwendungs- und Webebene sollten sowohl bei dem Testfailover als auch den Failover-Wiederherstellungsplänen identisch sein.
Schützen eines SQL Server-Clusters
Bei einem Cluster mit SQL Server Standard Edition oder SQL Server 2008 R2 empfiehlt es sich, SQL Server mit der Site Recovery-Replikation zu schützen.
Azure zu Azure und lokale Bereitstellung auf Azure
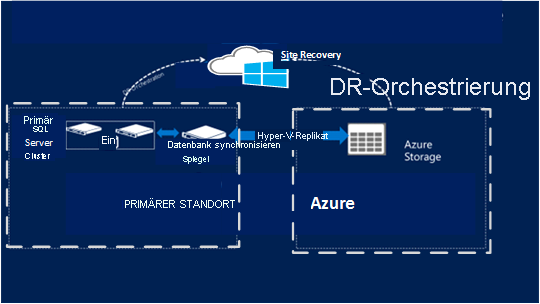
Site Recovery unterstützt bei der Replikation in einer Azure-Region keine Gastcluster. Für die SQL Server Standard Edition steht zudem keine kostengünstige Notfallwiederherstellungslösung zur Verfügung. In diesem Szenario empfiehlt es sich, den SQL Server-Cluster mit einer eigenständigen SQL Server-Instanz am primären Standort zu schützen und die Wiederherstellung am sekundären Standort vorzunehmen.
Konfigurieren Sie eine zusätzliche eigenständige SQL Server-Instanz in der primären Azure-Region oder an einem lokalen Standort.
Konfigurieren Sie diese Instanz so, dass sie als Spiegelung für die zu schützenden Datenbanken fungiert. Konfigurieren Sie die Spiegelung im Modus für hohe Sicherheit.
Konfigurieren Sie Site Recovery am primären Standort für Azure-, Hyper-V- oder VMware-VMs und physische Server.
Verwenden Sie die Site Recovery-Replikation, um die neue SQL Server-Instanz zum sekundären Standort zu replizieren. Da es sich hierbei um eine Spiegelkopie mit hoher Sicherheit handelt, wird sie mit dem primären Cluster synchronisiert. Bei der Replikation wird allerdings die Site Recovery-Replikation verwendet.
Überlegungen zum Failback
Bei SQL Server Standard-Clustern erfordert das Failback nach einem nicht geplanten Failover eine SQL Server-Sicherung und -Wiederherstellung. Dieser Vorgang wird von der Spiegelinstanz zum ursprünglichen Cluster durchgeführt, wobei die Spiegelung wiederhergestellt wird.
Häufig gestellte Fragen
Wie wird SQL Server bei der Verwendung mit Site Recovery lizenziert?
Die Site Recovery-Replikation für SQL Server wird unter dem Vorteil der Notfallwiederherstellung von Software Assurance abgedeckt. Diese Abdeckung gilt für alle Site Recovery-Szenarien: lokal für die Azure-Notfallwiederherstellung und regionsübergreifend für die Azure-IaaS-Notfallwiederherstellung. Weitere Informationen finden Sie unter Azure Site Recovery-Preise.
Unterstützt Site Recovery meine SQL Server-Version?
Site Recovery ist anwendungsunabhängig. Site Recovery kann jede Version von SQL Server schützen, die auf einem unterstützten Betriebssystem bereitgestellt wird. Weitere Informationen finden Sie in der Unterstützungsmatrix für die Notfallwiederherstellung replizierter Computer.
Funktioniert Azure Site Recovery mit SQL-Transaktionsreplikation?
Da Azure Site Recovery Kopiervorgänge auf Dateiebene durchführt, kann SQL nicht garantieren, dass die Server in einer zugeordneten SQL-Replikationstopologie zum Zeitpunkt des Azure Site Recovery-Failovers synchron sind. Dies kann dazu führen, dass der Protokollese- und/oder der Verteilungs-Agent aufgrund eines LSN-Konflikts fehlschlagen, wodurch die Replikation unterbrochen werden kann. Wenn Sie ein Failover für den Herausgeber, Verteiler oder Abonnenten in einer Replikationstopologie ausführen, müssen Sie die Replikation neu erstellen. Es wird empfohlen, das Abonnement erneut auf dem SQL Server zu initialisieren.
Nächste Schritte
- Erfahren Sie mehr über die Site Recovery-Architektur.
- Erfahren Sie für SQL Server in Azure mehr über hochverfügbare Lösungen für die Wiederherstellung in einer sekundären Azure-Region.
- Erfahren Sie für SQL-Datenbank mehr über Optionen für Geschäftskontinuität und Hochverfügbarkeit für die Wiederherstellung in sekundären Azure-Regionen.
- Erfahren Sie für SQL Server-Computer an lokalen Standorten mehr über die Hochverfügbarkeitsoptionen für die Wiederherstellung in Azure Virtual Machines.