Überwachen des virtuellen Azure-WAN
Dieser Artikel beschreibt Folgendes:
- Die Arten von Überwachungsdaten, die Sie für diesen Dienst sammeln können
- Möglichkeiten zum Analysieren dieser Daten.
Hinweis
Wenn Sie bereits mit diesem Dienst und/oder Azure Monitor vertraut sind und nur wissen möchten, wie Überwachungsdaten analysiert werden, lesen Sie den Abschnitt Analysieren am Ende dieses Artikels.
Wenn Sie über unternehmenskritische Anwendungen und Geschäftsprozesse verfügen, die auf Azure-Ressourcen basieren, müssen Sie diese überwachen und Warnungen für Ihr System abrufen. Der Azure Monitor-Dienst sammelt und aggregiert Metriken und Protokolle aus jeder Komponente Ihres Systems. Azure Monitor bietet Ihnen eine Übersicht über Verfügbarkeit, Leistung und Resilienz und benachrichtigt Sie über Probleme. Sie können das Azure-Portal, PowerShell, die Azure CLI, die REST-API oder Clientbibliotheken verwenden, um Überwachungsdaten einzurichten und anzuzeigen.
- Weitere Informationen zu Azure Monitor finden Sie unter Azure Monitor – Übersicht.
- Weitere Informationen zum Überwachen von Azure-Ressourcen im Allgemeinen finden Sie unter Überwachen von Azure-Ressourcen mit Azure Monitor.
Erkenntnisse
Einige Dienste in Azure verfügen über ein integriertes Überwachungsdashboard im Azure-Portal, das einen Ausgangspunkt für die Überwachung Ihres Diensts bietet. Diese Dashboards werden als Erkenntnisse bezeichnet, und Sie finden sie im Erkenntnishub von Azure Monitor im Azure-Portal.
Virtual WAN verwendet Netzwerkerkenntnisse, um Benutzern und Operatoren die Möglichkeit zu bieten, den Zustand und Status eines virtuellen WAN über eine automatisch ermittelte topologische Zuordnung anzuzeigen. Zustand und Status von Ressourcen werden im Diagramm überlagert, sodass Sie eine Momentaufnahmeansicht der allgemeinen Integrität der Virtual WAN-Instanz erhalten. Sie können zwischen den Ressourcen im Diagramm mittels Ein-Klick-Zugriff auf die Seiten mit der Ressourcenkonfiguration im Virtual WAN-Portal navigieren. Weitere Informationen finden Sie unter Azure Monitor-Netzwerkerkenntnisse für Virtual WAN.
Ressourcentypen
Azure verwendet das Konzept von Ressourcentypen und IDs, um alles in einem Abonnement zu identifizieren. Ressourcentypen sind auch Teil der Ressourcen-IDs für jede Ressource, die in Azure ausgeführt wird. Beispiel: Ein Ressourcentyp für eine VM ist Microsoft.Compute/virtualMachines. Eine Liste der Dienste und ihrer zugehörigen Ressourcentypen finden Sie unter Ressourcenanbieter.
Ähnliche organisiert Azure Monitor die Kernüberwachungsdaten in Metriken und Protokollen basierend auf Ressourcentypen, die auch als Namespaces bezeichnet werden. Für unterschiedliche Ressourcentypen stehen unterschiedliche Metriken und Protokolle zur Verfügung. Ihr Dienst ist möglicherweise mehr als einem Ressourcentyp zugeordnet.
Weitere Informationen zu den Ressourcentypen für Virtual WAN finden Sie in der Referenz zu den Überwachungsdaten für Azure Virtual WAN.
Datenspeicher
For Azure Monitor:
- Metrikdaten werden in der Azure Monitor-Metrikendatenbank gespeichert.
- Protokolldaten werden im Azure Monitor-Protokollspeicher gespeichert. Log Analytics ist ein Tool im Azure-Portal zum Abfragen dieses Speichers.
- Das Azure-Aktivitätsprotokoll ist ein separater Speicher mit eigener Schnittstelle im Azure-Portal.
Optional können Sie Metrik- und Aktivitätsprotokolldaten an den Azure Monitor-Protokollspeicher weiterleiten. Anschließend können Sie Log Analytics verwenden, um die Daten abzufragen und mit anderen Protokolldaten zu korrelieren.
Viele Dienste können Diagnoseeinstellungen verwenden, um Metrik- und Protokolldaten an andere Speicherorte außerhalb von Azure Monitor zu senden. Beispiele umfassen Azure Storage, gehostete Partnersysteme und Nicht-Azure-Partnersysteme, die Event Hubs verwenden.
Detaillierte Informationen dazu, wie Azure Monitor Daten speichert, finden Sie unter Azure Monitor-Datenplattform.
Azure Monitor-Plattformmetriken
Azure Monitor stellt Plattformmetriken für die meisten Dienste bereit. Diese Metriken sind:
- Einzeln für jeden Namespace definiert.
- In der Azure Monitor-Datenbank für Zeitreihenmetriken gespeichert.
- Einfach strukturiert und in der Lage, Warnmeldungen in Quasi-Echtzeit zu unterstützen.
- Verwendet zum Nachverfolgen der Leistung einer Ressource im Zeitverlauf.
Erfassung: Azure Monitor sammelt Plattformmetriken automatisch. Es ist keine Konfiguration erforderlich.
Routing: Sie können einige Plattformmetriken auch an Azure Monitor-Protokolle/Log Analytics weiterleiten, damit Sie diese mit anderen Protokolldaten abfragen können. Überprüfen Sie anhand der Einstellung DS-Export für die einzelnen Metriken, ob Sie eine Diagnoseeinstellung zum Weiterleiten der jeweiligen Metrik an Azure Monitor-Protokolle/Log Analytics verwenden können.
- Weitere Informationen finden Sie in der Diagnoseeinstellung „Metriken“.
- Informationen zum Konfigurieren von Diagnoseeinstellungen für einen Dienst finden Sie unter Erstellen von Diagnoseeinstellungen in Azure Monitor.
Eine Liste aller Metriken, die für alle Ressourcen in Azure Monitor gesammelt werden können, finden Sie unter Unterstützte Metriken in Azure Monitor.
Eine Liste der verfügbaren Metriken für Virtual WAN finden Sie in der Referenz zu den Überwachungsdaten für Azure Virtual WAN.
Sie können Metriken für virtuelles WAN mithilfe des Azure-Portals anzeigen. Führen Sie die folgenden Schritte aus, um Metriken zu suchen und anzuzeigen:
Wählen Sie Monitorgateway- aus, und dann Metriken. Sie können auch unten Metriken auswählen, um ein Dashboard der wichtigsten Metriken für Standort-zu-Standort- und Punkt-zu-Standort-VPN anzuzeigen.

Auf der Seite Metriken können Sie die Metriken anzeigen.

Um die Metriken für den virtuellen Hubrouter anzuzeigen, können Sie auf der Seite Übersicht des virtuellen Hubs die Option Metriken auswählen.




Weitere Informationen finden Sie unter Analysieren von Metriken für eine Azure-Ressource.
PowerShell-Schritte
Sie können Metriken für virtuelles WAN mithilfe von PowerShell anzeigen. Verwenden Sie für die Abfrage die folgenden PowerShell-Beispielbefehle.
$MetricInformation = Get-AzMetric -ResourceId "/subscriptions/<SubscriptionID>/resourceGroups/<ResourceGroupName>/providers/Microsoft.Network/VirtualHubs/<VirtualHubName>" -MetricName "VirtualHubDataProcessed" -TimeGrain 00:05:00 -StartTime 2022-2-20T01:00:00Z -EndTime 2022-2-20T01:30:00Z -AggregationType Sum
$MetricInformation.Data
- Ressourcen-ID. Die Ressourcen-ID Ihres virtuellen Hubs finden Sie im Azure-Portal. Navigieren Sie innerhalb von vWAN zur Seite des virtuellen Hubs, und wählen Sie unter „Essentials“ die Option JSON-Ansicht aus.
- Metrikname. Bezieht sich auf den Namen der Metrik, die Sie abfragen, in diesem Fall
VirtualHubDataProcessed. Diese Metrik zeigt alle Daten an, die der virtuelle Hubrouter in dem ausgewählten Zeitraum des Hubs verarbeitet hat. - Aggregationsintervall. Bezieht sich auf die Häufigkeit, mit der Sie die Aggregation anzeigen möchten. Im aktuellen Befehl wird eine ausgewählte aggregierte Einheit von fünf Minuten ausgegeben. Sie können 5M/15M/30M/1H/6H/12H und 1D (5, 15, 30 Minuten/1, 6, 12 Stunden und 1 Tag) auswählen.
- Startzeit und Endzeit. Diese Zeitangaben basieren auf der koordinierten Weltzeit (UTC). Achten Sie darauf, für diese Parameter UTC-Werte einzugeben. Wenn Sie diese Parameter nicht verwenden, werden standardmäßig die Daten der letzten Stunde angezeigt.
- Summenaggregationstyp: Der Aggregationstyp sum zeigt die Gesamtanzahl Bytes an, die den Router des virtuellen Hubs während eines ausgewählten Zeitraums durchlaufen haben. Wenn Sie beispielsweise die Zeitgranularität auf 5 Minuten festlegen, entspricht jeder Datenpunkt der Anzahl der in einem Fünf-Minuten-Intervall gesendeten Bytes. Um diesen Wert in GBit/s zu konvertieren, können Sie diese Zahl durch 37500000000 dividieren. Je nach Kapazität des virtuellen Hubs kann der Hubrouter zwischen 3 GBit/s und 50 GBit/s unterstützen. Die Aggregationstypen Max und Min sind derzeit nicht aussagekräftig.
Azure Monitor-Ressourcenprotokolle
Ressourcenprotokolle bieten Einblicke in Vorgänge, die von einer Azure-Ressourcen ausgeführt wurden. Protokolle werden automatisch generiert, aber Sie müssen sie an Azure Monitor-Protokolle weiterleiten, um sie zu speichern oder abzufragen. Protokolle sind in Kategorien organisiert. Ein bestimmter Namespace verfügt möglicherweise über mehrere Ressourcenprotokollkategorien.
Sammlung: Ressourcenprotokolle werden erst gesammelt und gespeichert, nachdem Sie eine Diagnoseeinstellung erstellt und die Protokolle an mindestens einen Speicherort weitergeleitet haben. Wenn Sie eine Diagnoseeinstellung erstellen, legen Sie fest, welche Kategorien von Protokollen gesammelt werden sollen. Es gibt mehrere Möglichkeiten zum Erstellen und Verwalten von Diagnoseeinstellungen, u. a. das Azure-Portal, programmgesteuert und über Azure Policy.
Routing: Der vorgeschlagene Standard besteht darin, Ressourcenprotokolle an Azure Monitor-Protokolle weiterzuleiten, damit Sie diese mit anderen Protokolldaten abfragen können. Andere Speicherorte wie z. B. Azure Storage, Azure Event Hubs und bestimmte Microsoft-Überwachungspartner sind ebenfalls verfügbar. Weitere Informationen finden Sie unter Azure-Ressourcenprotokolle und Ressourcenprotokollziele.
Ausführliche Informationen zum Sammeln, Speichern und Weiterleiten von Ressourcenprotokollen finden Sie unter Diagnoseeinstellungen in Azure Monitor.
Eine Liste aller verfügbaren Ressourcenprotokollkategorien in Azure Monitor finden Sie unter Unterstützte Ressourcenprotokolle in Azure Monitor.
Alle Ressourcenprotokolle in Azure Monitor enthalten dieselben Headerfelder, gefolgt von dienstspezifischen Feldern. Das allgemeine Schema wird in Azure Monitor-Ressourcenprotokollschema beschrieben.
Die verfügbaren Ressourcenprotokollkategorien, die zugehörigen Log Analytics-Tabellen und die Protokollschemas für Virtual WAN finden Sie in der Referenz zu den Überwachungsdaten für Azure Virtual WAN.
Schemas
Eine detaillierte Beschreibung des Schemas der obersten Ebene für Diagnoseprotokolle finden Sie unter Unterstützte Dienste, Schemas und Kategorien für Azure-Diagnoseprotokolle.
Wenn Sie Metriken über die Protokollanalyse überprüfen, enthält die Ausgabe die folgenden Spalten:
| Spalte | Type | Beschreibung |
|---|---|---|
| TimeGrain | Zeichenfolge | PT1M (Metrikwerte werden jede Minute gepusht) |
| Anzahl | real | Normalerweise gleich 2 (jedes MSEE pusht jede Minute einen einzelnen Metrikwert). |
| Minimum | real | Der Mindestwert der beiden Metrikwerte, die von den beiden MSEEs gepusht werden |
| Maximum | real | Der Höchstwert der beiden Metrikwerte, die von den beiden MSEEs gepusht werden |
| Average | real | Entspricht (Minimum + Maximum)/2 |
| Gesamt | real | Summe der beiden Metrikwerte aus beiden MSEEs (der Hauptwert, auf den sich bei der abgefragten Metrik konzentriert werden sollte) |
Erstellen einer Diagnoseeinstellung zum Anzeigen von Protokollen
Über die folgenden Schritte können Sie Diagnoseeinstellungen erstellen, bearbeiten und anzeigen:
Navigieren Sie im Portal zu Ihrer Virtual WAN-Ressource, und wählen Sie in der Gruppe Konnektivität die Option Hubs aus.

Wählen Sie auf der linken Seite in der Gruppe Konnektivität das Gateway aus, dessen Diagnoseinformationen Sie untersuchen möchten:

Wählen Sie auf der rechten Seite MonitorGateway und dann Protokolle aus.
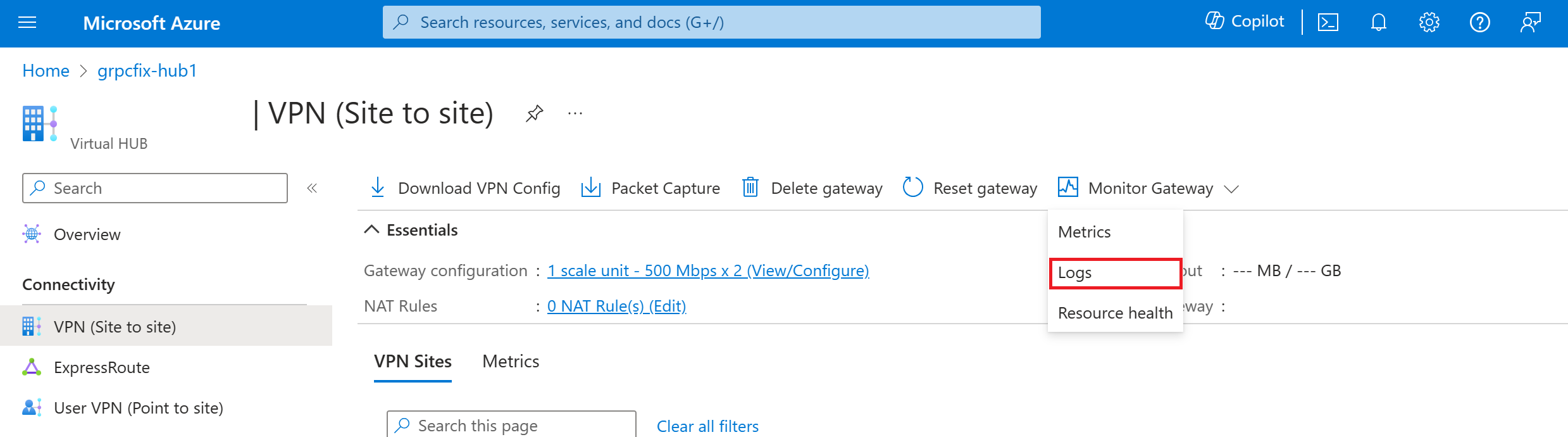
Auf dieser Seite können Sie eine neue Diagnoseeinstellung erstellen (+Diagnoseeinstellung hinzufügen) oder eine vorhandene Einstellung bearbeiten (Einstellung bearbeiten). Sie können die Diagnoseprotokolle an Log Analytics senden (wie im folgenden Beispiel gezeigt), an einen Event Hub streamen, an eine Drittanbieterlösung senden oder in einem Speicherkonto archivieren.

Nachdem Sie auf Speichern geklickt haben, sollten Protokolle innerhalb weniger Stunden in diesem Log Analytics-Arbeitsbereich erscheinen.
Um einen gesicherten Hub (mit Azure Firewall) zu überwachen, muss die Diagnose- und Protokollierungskonfiguration mittels dem Zugriff über die Registerkarte Diagnoseeinstellung erfolgen:
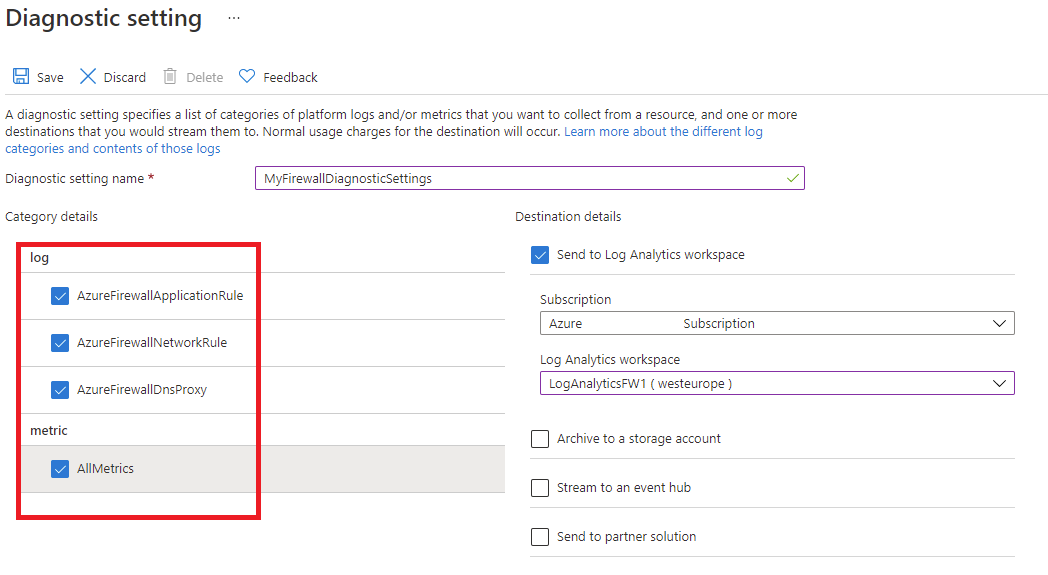





Wichtig
Ein Aktivieren dieser Einstellungen erfordert zusätzliche Azure-Dienste (Speicherkonto, Event Hub oder Log Analytics). Dadurch können sich Ihre Kosten erhöhen. Um geschätzte Kosten zu berechnen, wechseln Sie zum Azure-Preisrechner.
Überwachen des gesicherten Hubs (Azure Firewall)
Wenn Sie sich entschieden haben, den virtuellen Hub mithilfe von Azure Firewall zu schützen, finden Sie hier relevante Protokolle und Metriken: Azure Firewall-Protokolle und -Metriken.
Sie können den geschützten Hub mithilfe von Azure Firewall-Protokollen und -Metriken überwachen. Sie können aber auch Aktivitätsprotokolle verwenden, um Vorgänge für Azure Firewall-Ressourcen zu überwachen. Für jede Azure Virtual WAN-Instanz, die Sie schützen und in einen geschützten Hub konvertieren, erstellt Azure Firewall ein explizites Firewallressourcenobjekt. Das Objekt in der Ressourcengruppe, in der sich der Hub befindet.

Azure-Aktivitätsprotokoll
Das Aktivitätsprotokoll enthält Ereignisse auf Abonnementebene, die Vorgänge für jede Azure-Ressource nachverfolgen, so wie sie von außerhalb dieser Ressource gesehen werden, z. B. das Erstellen einer neuen Ressource oder das Starten einer VM.
Sammlung: Aktivitätsprotokollereignisse werden automatisch generiert und in einem separaten Speicher für die Anzeige im Azure-Portal gesammelt.
Routing: Sie können Aktivitätsprotokolldaten an Azure Monitor-Protokolle senden, damit Sie diese zusammen mit anderen Protokolldaten analysieren können. Andere Speicherorte wie z. B. Azure Storage, Azure Event Hubs und bestimmte Microsoft-Überwachungspartner sind ebenfalls verfügbar. Weitere Informationen zum Weiterleiten von Aktivitätsprotokollen finden Sie unter Übersicht über das Azure-Aktivitätsprotokoll.
Analysieren von Überwachungsdaten
Es gibt viele Tools zum Analysieren von Überwachungsdaten.
Azure Monitor-Tools
Azure Monitor unterstützt die folgenden grundlegenden Tools:
Metriken-Explorer, ein Tool im Azure-Portal, mit dem Sie Metriken für Azure-Ressourcen anzeigen und analysieren können. Weitere Informationen finden Sie unter Analysieren von Metriken mit dem Azure Monitor-Metrik-Explorer.
Log Analytics, ein Tool im Azure-Portal, mit dem Sie Protokolldaten mithilfe der KQL-Abfragesprache abfragen und analysieren können. Weitere Informationen finden Sie unter Erste Schritte mit Protokollabfragen in Azure Monitor.
Das Aktivitätsprotokoll, das über eine Benutzeroberfläche im Azure-Portal für die Anzeige und einfache Suchvorgänge verfügt. Um ausführlichere Analysen durchzuführen, müssen Sie die Daten an Azure Monitor-Protokolle weiterleiten und komplexere Abfragen in Log Analytics ausführen.
Zu den Tools, die eine komplexere Visualisierung ermöglichen, gehören:
- Dashboards, mit denen Sie verschiedene Typen von Daten in einen einzelnen Bereich im Azure-Portal kombinieren können.
- Arbeitsmappen, anpassbare Berichte, die Sie im Azure-Portal erstellen können. Arbeitsmappen können Text, Metriken und Protokollabfragen enthalten.
- Grafana, ein Tool auf einer offenen Plattform, das für operationale Dashboards ideal ist. Sie können Grafana verwenden, um Dashboards zu erstellen, die Daten aus mehreren anderen Quellen als Azure Monitor enthalten.
- Power BI ist ein Geschäftsanalysedienst, der interaktive Visualisierungen für verschiedene Datenquellen bereitstellt. Sie können Power BI für den automatischen Import von Protokolldaten aus Azure Monitor konfigurieren, um diese Visualisierungen zu nutzen.
Exporttools für Azure Monitor
Sie können Daten aus Azure Monitor in andere Tools abrufen, indem Sie die folgenden Methoden verwenden:
Metriken: Verwenden Sie die REST-API für Metriken, um Metrikdaten aus der Azure Monitor-Metrikendatenbank zu extrahieren. Die API unterstützt Filterausdrücke, um die abgerufenen Daten zu verfeinern. Weitere Informationen finden Sie in der Referenz zur Azure Monitor-REST-API.
Protokolle: Verwenden Sie die REST-API oder die zugeordneten Clientbibliotheken.
Eine weitere Option ist der Arbeitsbereichsdatenexport.
Informationen zu den ersten Schritten mit der REST-API für Azure Monitor finden Sie in der exemplarischen Vorgehensweise für die Azure-Überwachungs-REST-API.
Kusto-Abfragen
Sie können Überwachungsdaten im Azure Monitor Logs / Log Analytics Store mithilfe der Kusto-Abfragesprache (KQL) analysieren.
Wichtig
Wenn Sie Protokolle im Menü des Diensts im Portal auswählen, wird Log Analytics geöffnet, wobei der Abfragebereich auf den aktuellen Dienst festgelegt ist. Dieser Bereich bedeutet, dass Protokollabfragen nur Daten aus diesem Ressourcentyp umfassen. Wenn Sie eine Abfrage durchführen möchten, die Daten aus anderen Azure-Diensten enthält, wählen Sie im Menü Azure Monitor die Option Protokolle aus. Ausführliche Informationen finden Sie unter Protokollabfragebereich und Zeitbereich in Azure Monitor Log Analytics.
Eine Liste häufiger Abfragen für alle Dienste finden Sie unter Log Analytics-Abfrageschnittstelle.
Alerts
Azure Monitor-Warnungen informieren Sie proaktiv, wenn bestimmte Bedingungen in Ihren Überwachungsdaten auftreten. Warnungen ermöglichen Ihnen, Probleme in Ihrem System zu identifizieren und zu beheben, bevor Ihre Kunden sie bemerken. Weitere Informationen finden Sie unter Azure Monitor-Warnungen.
Es gibt viele Quellen allgemeiner Warnungen für Azure-Ressourcen. Beispiele für häufige Warnungen für Azure-Ressourcen finden Sie in den Beispielabfragen für Protokollwarnungen. Die Website Azure Monitor-Baselinewarnungen (Azure Monitor Baseline Alerts, AMBA) stellt eine halbautomatisierte Methode für die Implementierung wichtiger Metrikwarnungen der Plattform, Dashboards und Richtlinien bereit. Die Website gilt für eine fortlaufend erweiterte Teilmenge von Azure-Diensten, einschließlich aller Dienste, die Teil der Azure-Zielzone (Azure Landing Zone, ALZ) sind.
Mit dem allgemeinen Warnungsschema wird die Benutzeroberfläche für Warnungsbenachrichtigungen in Azure Monitor standardisiert. Weitere Informationen finden Sie unter Allgemeines Warnungsschema.
Warnungstypen
Sie können zu jeder Metrik oder Protokolldatenquelle der Azure Monitor-Datenplattform Warnungen erhalten. Es gibt viele verschiedene Typen von Warnungen, abhängig von den Diensten, die Sie überwachen, und den Überwachungsdaten, die Sie sammeln. Verschiedene Typen von Warnungen haben jeweils ihre Vor- und Nachteile. Weitere Informationen finden Sie unter Auswählen des richtigen Warnungsregeltyps.
In der folgenden Liste werden die Typen von Azure Monitor-Warnungen beschrieben, die Sie erstellen können:
- Metrikwarnungen bewerten Ressourcenmetriken in regelmäßigen Abständen. Metriken können Plattformmetriken, benutzerdefinierte Metriken, in Metriken konvertierte Protokolle aus Azure Monitor oder Application Insights-Metriken sein. Metrikwarnungen können auch mehrere Bedingungen und dynamische Schwellwerte anwenden.
- Protokollwarnungen ermöglichen es Benutzern, eine Log Analytics-Abfrage zum Auswerten von Ressourcenprotokollen in vordefinierten Frequenz zu verwenden.
- Aktivitätsprotokollwarnungen werden ausgelöst, wenn ein neues Aktivitätsprotokollereignis eintritt, das definierte Bedingungen erfüllt. Resource Health- und Service Health-Warnungen sind Aktivitätsprotokollwarnungen, die über die Dienst- und Ressourcenintegrität berichten.
Einige Azure-Dienste unterstützen auch intelligente Erkennungswarnungen, Prometheus-Warnungen oder empfohlene Warnungsregeln.
Einige Dienste können Sie im großen Stil überwachen, indem Sie dieselbe Metrikwarnungsregel auf mehrere Ressourcen desselben Typs anwenden, die sich in derselben Azure-Region befinden. Für jede überwachte Ressource werden einzelne Benachrichtigungen gesendet. Unterstützte Azure-Dienste und -Clouds finden Sie unter Überwachen mehrerer Ressourcen mit einer Warnungsregel.
Hinweis
Wenn Sie eine Anwendung erstellen oder ausführen, die in Ihrem Dienst ausgeführt wird, stellt Azure Monitor Application Insights möglicherweise andere Warnungstypen zur Verfügung.
Warnungsregeln für Virtual WAN
Sie können Warnungen für jede Metrik, jeden Protokolleintrag und jeden Aktivitätsprotokolleintrag festlegen, der in der Referenz zu den Überwachungsdaten für Azure Virtual WAN aufgeführt ist.
Überwachen von Azure Virtual WAN – Bewährte Methoden
Dieser Artikel enthält bewährte Methoden für die Konfiguration zur Überwachung des Virtual WAN und der verschiedenen Komponenten, die damit bereitgestellt werden können. Die in diesem Artikel vorgestellten Empfehlungen basieren hauptsächlich auf vorhandenen Azure Monitor-Metriken und Protokollen, die von Azure Virtual WAN generiert werden. Eine Liste der Metriken und Protokolle, die für Virtual WAN gesammelt werden, finden Sie in der Referenz zur Überwachung von Virtual WAN-Daten.
Die meisten Empfehlungen in diesem Artikel schlagen vor, Azure Monitor-Warnungen zu erstellen. Azure Monitor-Warnungen informieren Sie proaktiv, wenn in den Überwachungsdaten ein wichtiges Ereignis gefunden wird. Diese Informationen helfen Ihnen, die Ursache schneller zu beheben und letztendlich Ausfallzeiten zu reduzieren. Informationen zum Erstellen einer Metrikwarnung finden Sie im Tutorial: Erstellen einer Metrikwarnung für eine Azure-Ressource. Informationen zum Erstellen einer Protokollabfragewarnung finden Sie unter Tutorial: Erstellen einer Protokollabfragewarnung für eine Azure-Ressource.
Virtual WAN-Gateways
In diesem Abschnitt werden bewährte Methoden für Virtual WAN-Gateways beschrieben.
Standort-zu-Standort-VPN-Gateway
Entwurfsprüfliste – Metrikwarnungen
- Erstellen Sie eine Warnungsregel für einen Anstieg der Anzahl ausgehender und/oder eingehender gelöschter Pakete eines Tunnels.
- Erstellen Sie eine Warnungsregel, um den BGP-Peerstatus zu überwachen.
- Erstellen Sie eine Warnungsregel, um die Anzahl der angekündigten und gelernten BGP-Routen zu überwachen.
- Erstellen Sie eine Warnungsregel für die Überlastung des VPN-Gateways.
- Erstellen Sie eine Warnungsregel für die Tunnelüberlastung.
| Empfehlung | Beschreibung |
|---|---|
| Erstellen Sie eine Warnungsregel für den Anstieg der Anzahl ausgehender und/oder eingehender gelöschter Pakete eines Tunnels. | Eine Zunahme der Anzahl ausgehender und/oder eingehender gelöschter Pakete eines Tunnels kann auf ein Problem mit dem Azure VPN-Gateway oder mit dem Remote-VPN-Gerät hinweisen. Wählen Sie beim Erstellen von Warnungsregeln die Metrik Anzahl ausgehender und/oder eingehender gelöschter Pakete eines Tunnels aus. Definieren Sie einen statischen Schwellenwert, der größer als 0 ist, und den Aggregationstyp Gesamt beim Konfigurieren der Warnungslogik. Sie können die Verbindung als Ganzes überwachen oder die Warnungsregel nach Instanz und Remote-IP aufteilen, um bei Problemen mit einzelnen Tunneln benachrichtigt zu werden. Informationen zum Unterschied zwischen dem Konzept der VPN-Verbindung, des Linksund des Tunnels in Virtual WAN finden Sie in den häufig gestellten Fragen zu Virtual WAN. |
| Erstellen Sie eine Warnungsregel, um den BGP-Peerstatus zu überwachen. | Wenn Sie BGP in Ihren Site-to-Site-Verbindungen verwenden, ist es wichtig, die Integrität der BGP-Peerings zwischen den Gatewayinstanzen und den Remotegeräten zu überwachen, da wiederkehrende Fehler die Konnektivität stören können. Wählen Sie beim Erstellen der Warnungsregel die Metrik BGP-Peerstatus aus. Wählen Sie unter Verwendung eines statischen Schwellenwerts den Aggregationstyp Durchschnitt aus, und konfigurieren Sie die Warnung so, dass sie ausgelöst wird, wenn der Wert kleiner als 1 ist. Wir empfehlen, die Warnung nach Instanz und BGP-Peeradresse aufzuteilen, um Probleme mit einzelnen Peerings zu erkennen. Vermeiden Sie die Auswahl der Gatewayinstanz-IPs als BGP-Peeradresse, da diese Metrik den BGP-Status für jede mögliche Kombination überwacht, einschließlich mit der Instanz selbst (die immer 0 ist). |
| Erstellen Sie eine Warnungsregel, um die Anzahl der angekündigten und gelernten BGP-Routen zu überwachen. | Angekündigte BGP-Routen und Gelernte BGP-Routen überwachen die jeweilige Anzahl der vom VPN-Gateway gegenüber Peers angekündigten und von Peers gelernten Routen. Wenn diese Metriken unerwartet auf Null fallen, liegt dies möglicherweise daran, dass es ein Problem mit dem Gateway oder lokal gibt. Wir empfehlen, eine Warnung für beide Metriken zu konfigurieren, die ausgelöst wird, wenn ihr Wert null ist. Wählen Sie den Aggregationstyp Gesamt aus. Aufgeteilt nach Instanz, um einzelne Gatewayinstanzen zu überwachen. |
| Erstellen Sie eine Warnungsregel für die Überlastung des VPN-Gateways. | Die Anzahl der Skalierungseinheiten pro Instanz bestimmt den Aggregatdurchsatz eines VPN-Gateways. Alle Tunnel, die in derselben Gatewayinstanz enden, nutzen den Aggregatdurchsatz gemeinsam. Es ist wahrscheinlich, dass die Tunnelstabilität beeinträchtigt wird, wenn eine Instanz über einen längeren Zeitraum an ihrer Kapazitätsgrenze arbeitet. Wählen Sie Gateway Site-t-Site-Bandbreite aus, wenn Sie die Warnungsregel erstellen. Konfigurieren Sie die Warnung so, dass sie ausgelöst wird, wenn der durchschnittliche Durchsatz größer als ein Wert ist, der dem maximalen Aggregatdurchsatz beider Instanzen entspricht. Alternativ können Sie die Warnung auch nach Instanzen aufteilen und den maximalen Durchsatz pro Instanz als Referenz verwenden. Es hat sich bewährt, den Durchsatzbedarf pro Tunnel im Voraus zu ermitteln, um die geeignete Anzahl von Skalierungseinheiten zu wählen. Weitere Informationen zu den unterstützten Skalierungseinheitswerten für Site-to-Site-VPN-Gateways finden Sie in den Häufig gestellten Fragen zu Virtual WAN. |
| Erstellen Sie eine Warnungsregel für die Tunnelüberlastung. | Die Skalierungseinheiten der Gatewayinstanz, in der der Tunnel beendet wird, bestimmen den maximal zulässigen Durchsatz pro Tunnel. Möglicherweise möchten Sie benachrichtigt werden, wenn ein Tunnel gefährdet ist, seinen maximalen Durchsatz zu erreichen, da dies zu Leistungs- und Konnektivitätsproblemen führen kann. Handeln Sie proaktiv, indem Sie die Ursache der erhöhten Tunnelauslastung untersuchen oder die Skalierungseinheiten des Gateways erhöhen. Wählen Sie Tunnelbandbreite aus, wenn Sie die Warnungsregel erstellen. Teilen sie nach Instanz und Remote-IP auf, um alle einzelnen Tunnel zu überwachen, oder wählen Sie stattdessen bestimmte Tunnel aus. Konfigurieren Sie die Warnung so, dass sie ausgelöst wird, wenn der durchschnittliche Durchsatz größer als ein Wert ist, der dem maximal zulässigen Durchsatz pro Tunnel entspricht. Weitere Informationen dazu, inwiefern die Skalierungseinheiten des Gateways den maximalen Durchsatz eines Tunnels beeinflussen, finden Sie in den häufig gestellten Fragen zu Virtual WAN. |
Entwurfsprüfliste – Protokollabfragewarnungen
Um protokollbasierte Warnungen zu konfigurieren, müssen Sie zuerst eine Diagnoseeinstellung für Ihr Site-to-Site-/Point-to-Site-VPN-Gateway erstellen. In einer Diagnoseeinstellung definieren Sie, welche Protokolle und/oder Metriken Sie sammeln möchten und wie Sie diese Daten speichern möchten, die später analysiert werden sollen. Im Gegensatz zu Gatewaymetriken sind Gatewayprotokolle nicht verfügbar, wenn keine Diagnoseeinstellung konfiguriert ist. Informationen zum Erstellen einer Diagnoseeinstellung finden Sie unter Erstellen einer Diagnoseeinstellung zum Anzeigen von Protokollen.
- Erstellen sie die Warnungsregel für das Trennen der Tunnelverbindung.
- Erstellen Sie die Warnungsregel für das Trennen der BGP-Verbindung.
| Empfehlung | Beschreibung |
|---|---|
| Erstellen sie die Warnungsregel für das Trennen der Tunnelverbindung. | Verwenden Sie Tunnel-Diagnoseprotokolle, um Trennungsereignisse in Ihren Site-to-Site-Verbindungen nachzuverfolgen. Ein Trennungsereignis kann unter anderem auf einen Fehler beim Aushandeln von SAs oder eine ausbleibende Reaktion des Remote-VPN-Geräts zurückzuführen sein. Tunneldiagnoseprotokolle stellen auch den Grund für die Trennung bereit. Lesen Sie die Warnungsregel zum Trennen der Tunnelverbindung – Protokollabfrage unter dieser Tabelle, um beim Erstellen der Warnungsregel Trennungsereignisse auszuwählen. Konfigurieren Sie die Warnung so, dass sie ausgelöst wird, wenn die Anzahl der Zeilen, die sich aus der Ausführung der Abfrage ergeben, größer als 0 ist. Damit diese Warnung wirksam ist, wählen Sie die Aggregationsgranularität zwischen 1 und 5 Minuten und die Häufigkeit der Auswertung ebenfalls zwischen 1 und 5 Minuten aus. Auf diese Weise ist die Anzahl der Zeilen für ein neues Intervall erneut 0, nachdem das Aggregationsgranularitätsintervall verstrichen ist. Tipps zur Problembehandlung beim Analysieren von Tunneldiagnoseprotokollen finden Sie unter Problembehandlung beim Azure VPN-Gateway mithilfe von Diagnoseprotokollen. Verwenden Sie außerdem IKE-Diagnoseprotokolle, um Ihre Problembehandlung zu ergänzen, da diese Protokolle detaillierte IKE-spezifische Diagnosen enthalten. |
| Erstellen Sie die Warnungsregel für das Trennen der BGP-Verbindung. | Verwenden Sie Routendiagnoseprotokolle, um Routenaktualisierungen und Probleme mit BGP-Sitzungen nachzuverfolgen. Wiederholte BGP-Trennungsereignisse können die Konnektivität beeinträchtigen und Ausfallzeiten verursachen. Sehen Sie sich die Warnungsprotokollabfrage „BGP-Trennungsregel“ unter dieser Tabelle zum Auswählen von „Trennungsereignissen beim Erstellen der Warnungsregel an. Konfigurieren Sie die Warnung so, dass sie ausgelöst wird, wenn die Anzahl der Zeilen, die sich aus der Ausführung der Abfrage ergeben, größer als 0 ist. Damit diese Warnung wirksam ist, wählen Sie die Aggregationsgranularität zwischen 1 und 5 Minuten und die Häufigkeit der Auswertung ebenfalls zwischen 1 und 5 Minuten aus. Auf diese Weise ist nach dem Verstreichen des Aggregationsgranularitäts-Intervalls die Anzahl der Zeilen für ein neues Intervall erneut 0, wenn die BGP-Sitzungen wiederhergestellt werden. Weitere Informationen zu den Daten, die von Routingdiagnoseprotokollen gesammelt werden, finden Sie unter Problembehandlung beim Azure-VPN-Gateway mithilfe von Diagnoseprotokollen. |
Protokollabfragen
Warnungsregel zum Trennen einer Tunnelverbindung erstellen – Protokollabfrage: Die folgende Protokollabfrage kann zum Auswählen von Tunneltrennungsereignissen beim Erstellen der Warnungsregel verwendet werden:
AzureDiagnostics | where Category == "TunnelDiagnosticLog" | where OperationName == "TunnelDisconnected"BGP-Trennungsregelwarnung – Protokollabfrage: Die folgende Protokollabfrage kann verwendet werden, um BGP-Trennungsereignisse beim Erstellen der Warnungsregel auszuwählen:
AzureDiagnostics | where Category == "RouteDiagnosticLog" | where OperationName == "BgpDisconnectedEvent"
Point-to-Site-VPN-Gateway
Im folgenden Abschnitt wird nur die Konfiguration metrikbasierter Warnungen beschrieben. Virtual WAN-Point-to-Site-Gateways unterstützen jedoch auch Diagnoseprotokolle. Weitere Informationen zu den verfügbaren Diagnoseprotokollen für Point-to-Site-Gateways finden Sie unter Virtual WAN Point-to-Site-VPN-Gatewaydiagnose.
Entwurfsprüfliste – Metrikwarnungen
- Erstellen Sie eine Warnungsregel für die Überlastung des Gateways.
- Erstellen Sie eine Warnung wenn sich die Anzahl der P2S-Verbindungen dem Grenzwert nähert.
- Erstellen Sie eine Warnung, wenn die Anzahl der Benutzer-VPN-Routen dem Grenzwert nähert.
| Empfehlung | Beschreibung |
|---|---|
| Erstellen Sie eine Warnungsregel für die Überlastung des Gateways. | Die Anzahl der konfigurierten Skalierungseinheiten bestimmt die Bandbreite eines Point-to-Point-Gateways. Weitere Informationen zu Skalierungseinheiten für Point-to-Site-Gateways finden Sie unter Point-to-Site (User VPN). Verwenden Sie die Metrik „Gateway P2S-Bandbreite“, um die Auslastung des Gateways zu überwachen und eine Warnungsregel zu konfigurieren, die ausgelöst wird, wenn die Bandbreite des Gateways größer als ein Wert in der Nähe des Aggregatdurchsatzes ist. Wenn z. B. das Gateway mit 2 Skalierungseinheiten konfiguriert wurde, einen Aggregatdurchsatz von 1 GBit/s. In diesem Fall könnten Sie einen Schwellenwert von 950 MBit/s definieren. Verwenden Sie diese Warnung, um die Ursache der erhöhten Auslastung proaktiv zu untersuchen und die Anzahl der Skalierungseinheiten bei Bedarf zu erhöhen. Wählen Sie beim Konfigurieren der Warnungsregel den durchschnittlichen Aggregationstyp aus. |
| Warnung dafür erstellen, dass sich die Anzahl der P2S-Verbindungen dem Grenzwert nähert | Die maximale Anzahl zulässiger Point-to-Site-Verbindungen wird auch durch die Anzahl der Skalierungseinheiten bestimmt, die auf dem Gateway konfiguriert sind. Weitere Informationen zu Skalierungseinheiten für Point-to-Site-Gateways finden Sie in den häufig gestellten Fragen für Point-to-Site (Benutzer-VPN). Verwenden Sie die Metrik P2S-Verbindungsanzahl, um die Anzahl der Verbindungen zu überwachen. Wählen Sie diese Metrik aus, um eine Warnungsregel zu konfigurieren, die ausgelöst wird, wenn sich die Anzahl der Verbindungen dem maximal zulässigen Wert nähert. Beispielsweise unterstützt ein Gateway mit 1 Skalierungseinheit bis zu 500 gleichzeitige Verbindungen. In diesem Fall können Sie die Warnung so konfigurieren, dass sie ausgelöst wird, wenn die Anzahl der Verbindungen größer als 450 ist. Verwenden Sie diese Warnung, um festzustellen, ob eine Erhöhung der Anzahl der Skalierungseinheiten erforderlich ist oder nicht. Wählen Sie den Aggregationstyp Gesamt aus, wenn Sie die Warnungsregel konfigurieren. |
| Erstellen Sie eine Warnungsregel dafür, dass sich die Anzahl der Benutzer-VPN-Routen dem Grenzwert nähert. | Das verwendete Protokoll bestimmt die maximale Anzahl von Benutzer-VPN-Routen. IKEv2 weist ein Limit auf Protokollebene von 255 Routen auf, während OpenVPN ein Limit von 1.000 Routen hat. Weitere Informationen hierzu finden Sie unter VPN-Serverkonfigurationskonzepte. Möglicherweise möchten Sie benachrichtigt werden, wenn Sie kurz davor sind, die maximale Anzahl von Benutzer-VPN-Routen zu erreichen, und proaktiv reagieren möchten, um Ausfallzeiten zu vermeiden. Verwenden Sie die Anzahl der Benutzer-VPN-Routen, um dies zu überwachen und eine Warnungsregel zu konfigurieren, die ausgelöst wird, wenn die Anzahl der Routen einen Wert in der Nähe des Grenzwerts überschreitet. Wenn der Grenzwert beispielsweise bei 255 Routen liegt, könnte ein entsprechender Schwellenwert 230 sein. Wählen Sie den Aggregationstyp Gesamt aus, wenn Sie die Warnungsregel konfigurieren. |
ExpressRoute-Gateway
Der folgende Abschnitt konzentriert sich auf metrikbasierte Warnungen. Zusätzlich zu den hier beschriebenen Warnungen, die sich auf die Gatewaykomponente konzentrieren, empfehlen wir, die verfügbaren Metriken, Protokolle und Tools zum Überwachen der ExpressRoute-Verbindung zu verwenden. Weitere Informationen zur ExpressRoute-Überwachung finden Sie unter ExpressRoute-Überwachung, Metriken und Warnungen. Informationen zur Verwendung des ExpressRoute Traffic Collector-Tools finden Sie unter Konfigurieren des ExpressRoute-Traffic Collectors für ExpressRoute Direct.
Entwurfsprüfliste – Metrikwarnungen
- Erstellen Sie eine Warnungsregel für den Empfang von Bits pro Sekunde.
- Erstellen Sie eine Warnungsregel für CPU-Überlastung.
- Erstellen Sie eine Warnungsregel für Pakete pro Sekunde.
- Erstellen Sie eine Warnungsregel für die Anzahl der für Peer angekündigten Routen.
- Zählwarnungsregel für die Anzahl der vom Peer gelernten Routen.
- Erstellen Sie eine Warnungsregel für hohe Frequenz bei Routenänderungen.
| Empfehlung | Beschreibung |
|---|---|
| Erstellen Sie eine Warnungsregel für Bits, die pro Sekunde empfangen werden. | Pro Sekunde empfangene Bits überwacht die Gesamtmenge des Datenverkehrs, der vom Gateway von den MSEEs empfangen wird. Möglicherweise möchten Sie benachrichtigt werden, wenn der vom Gateway empfangene Datenverkehr Gefahr läuft, den maximalen Durchsatz zu erreichen. Dies kann zu Leistungs- und Konnektivitätsproblemen führen. Dieser Ansatz ermöglicht es Ihnen, proaktiv zu handeln, indem Sie die Ursache der erhöhten Gatewayauslastung oder das Erhöhen des maximalen zulässigen Durchsatzes des Gateways untersuchen. Wählen Sie den Aggregationstyp Durchschnitt und einen Schwellenwert-Wert in der Nähe des maximalen Durchsatzes aus, der beim Konfigurieren der Warnungsregel für das Gateway bereitgestellt wird. Darüber hinaus empfehlen wir, eine Warnung festzulegen, wenn die Anzahl der empfangenen Bits pro Sekunde nahe null ist, da es auf ein Problem mit dem Gateway oder den MSEEs hindeuten kann. Die Anzahl der bereitgestellten Skalierungseinheiten bestimmt den maximalen Durchsatz eines ExpressRoute-Gateways. Weitere Informationen zur ExpressRoute-Gatewayleistung finden Sie unter Informationen zu ExpressRoute-Verbindungen in Azure Virtual WAN. |
| Erstellen Sie eine Warnungsregel für CPU-Überlastung. | Bei der Verwendung von ExpressRoute-Gateways ist es wichtig, die CPU-Auslastung zu überwachen. Eine anhaltende hohe Auslastung kann die Leistung und Konnektivität beeinträchtigen. Verwenden Sie die Metrik CPU-Auslastung, um die Nutzung zu überwachen und eine Warnung zu erstellen, wenn die CPU-Auslastung größer als 80 % ist, sodass Sie die Grundursache untersuchen und die Anzahl der Skalierungseinheiten bei Bedarf erhöhen können. Wählen Sie beim Konfigurieren der Warnungsregel den Aggregationstyp Durchschnitt aus. Weitere Informationen zur ExpressRoute-Gatewayleistung finden Sie unter Informationen zu ExpressRoute-Verbindungen in Azure Virtual WAN. |
| Erstellen Sie eine Warnungsregel für Pakete, die pro Sekunde empfangen werden. | Pakete pro Sekunde überwacht die Anzahl der eingehenden Pakete, die das Virtual WAN ExpressRoute-Gateway durchlaufen. Möglicherweise möchten Sie benachrichtigt werden, wenn sich die Anzahl der Pakete pro Sekunde dem zulässigen Grenzwert für die Anzahl der Skalierungseinheiten, die auf dem Gateway konfiguriert sind, nähert. Wählen Sie beim Konfigurieren der Warnungsregel den Aggregationstyp „Durchschnitt“ aus. Wählen Sie einen Schwellenwert in der Nähe der maximalen Anzahl von Paketen pro Sekunde aus, die basierend auf der Anzahl der Skalierungseinheiten des Gateways zulässig sind. Weitere Informationen zur ExpressRoute-Leistung finden Sie unter Informationen zu ExpressRoute-Verbindungen in Azure Virtual WAN. Darüber hinaus empfehlen wir, eine Warnung festzulegen, wenn die Anzahl der Pakete pro Sekunde nahe null ist, da es auf ein Problem mit dem Gateway oder den MSEEs hindeuten kann. |
| Erstellen Sie eine Warnungsregel für die Anzahl der für Peer angekündigten Routen. | Die Anzahl der für Peer angekündigten Routen überwacht die Anzahl der vom ExpressRoute-Gateway an den virtuellen Hubrouter und an die Microsoft Enterprise Edge-Geräte angekündigten Routen. Wir empfehlen, dass Sie einen Filter hinzufügen, der nur die beiden BGP-Peers auswählt, die als ExpressRoute-Gerät angezeigt werden und eine Warnung erstellt, um zu ermitteln, wann sich die Anzahl der angekündigten Routen dem dokumentierten Grenzwert von 1000 nähert. Konfigurieren Sie die Warnung zum Beispiel so, dass sie ausgelöst wird, wenn die Anzahl der angekündigten Routen größer als 950 ist. Wir empfehlen außerdem, eine Warnung zu konfigurieren, wenn die Anzahl der für Microsoft Edge-Geräte angekündigten Routen gleich Null ist, um Konnektivitätsprobleme proaktiv zu erkennen. Um diese Warnungen hinzuzufügen, wählen Sie die Metrik Anzahl der für Peers angekündigten Routen und dann die Option Filter hinzufügen und anschließend die ExpressRoute-Geräte aus. |
| Erstellen Sie eine Warnungsregel für die Anzahl der vom Peer gelernten Routen. | Die Anzahl der von Peer gelernten Routen überwacht die Anzahl der Routen, die das ExpressRoute-Gateway vom virtuellen Hubrouter und vom Microsoft Enterprise Edge-Gerät gelernt hat. Wir empfehlen, dass Sie einen Filter hinzufügen, der nur die beiden BGP-Peers auswählt, die als ExpressRoute-Gerät angezeigt werden und eine Warnung erstellt, um zu ermitteln, wenn sich die Anzahl der gelernten Routen dem dokumentierten Grenzwert von 4000 für Standard SKU- und 10.000 für Premium SKU-Verbindungen nähert. Wir empfehlen außerdem, eine Warnung zu konfigurieren, wenn die Anzahl der für Microsoft Edge-Geräte angekündigten Routen gleich Null ist. Mit diesem Ansatz können Sie feststellen, wann Ihnen lokal keine Routen mehr angekündigt werden. |
| Erstellen Sie eine Warnungsregel für hohe Frequenz bei Routenänderungen. | Die Häufigkeit von Routenänderungen zeigt die Änderungshäufigkeit von Routen, die von und zu Peers gelernt und angekündigt werden, einschließlich anderer Arten von Branches wie Site-to-Site- und Point-to-Site-VPN. Diese Metrik bietet Sichtbarkeit, wenn ein neuer Branch oder mehr Verbindungen verbunden/getrennt werden. Diese Metrik ist ein nützliches Tool beim Identifizieren von Problemen mit BGP-Ankündigungen, z. B. Fluktuationen. Wir empfehlen, eine Warnung festzulegen, wenn die Umgebung statisch ist und BGP-Änderungen nicht erwartet werden. Wählen Sie einen Schwellenwert aus, der größer als 1 ist, und eine Aggregationsgranularität von 15 Minuten, um das BGP-Verhalten konsistent zu überwachen. Wenn die Umgebung dynamisch ist und BGP-Änderungen häufig erwartet werden, können Sie sich dafür entscheiden, andernfalls keine Warnung festzulegen, um falsch positive Ergebnisse zu vermeiden. Sie können diese Metrik jedoch weiterhin für die Beobachtbarkeit Ihres Netzwerks berücksichtigen. |
Virtueller Hub
Der folgende Abschnitt konzentriert sich auf metrikbasierte Warnungen für virtuelle Hubs.
Entwurfsprüfliste – Metrikwarnungen
- Erstellen einer Warnungsregel für den BGP-Peerstatus
| Empfehlung | Beschreibung |
|---|---|
| Erstellen Sie eine Warnungsregel, um den BGP-Peerstatus zu überwachen. | Wählen Sie beim Erstellen der Warnungsregel die Metrik BGP-Peerstatus aus. Wählen Sie unter Verwendung eines statischen Schwellenwerts den Aggregationstyp Durchschnitt aus, und konfigurieren Sie die Warnung so, dass sie ausgelöst wird, wenn der Wert kleiner als 1 ist. Dieser Ansatz ermöglicht es Ihnen festzustellen, wann der virtuelle Hub-Router Probleme mit der Verbindung zu den im Hub bereitgestellten ExpressRoute-, Site-to-Site VPN- und Point-to-Site VPN-Gateways hat. |
Azure Firewall
Dieser Abschnitt des Artikels konzentriert sich auf metrikbasierte Warnungen. Azure Firewall bietet eine umfassende Liste von Metriken und Protokollen für Überwachungszwecke. Zusätzlich zum Konfigurieren der Warnungen, die im folgenden Abschnitt beschrieben werden, erfahren Sie, wie die Azure Firewall-Arbeitsmappe helfen kann, Ihre Azure Firewall zu überwachen. Erkunden Sie außerdem die Vorteile der Verbindung von Azure Firewall-Protokollen mit Microsoft Sentinel mithilfe von Azure Firewall-Connector für Microsoft Sentinel.
Entwurfsprüfliste – Metrikwarnungen
- Erstellen Sie eine Warnungsregel für das Risiko der SNAT-Portausschöpfung.
- Erstellen Sie eine Warnungsregel für die Firewallüberlastung.
| Empfehlung | Beschreibung |
|---|---|
| Erstellen Sie eine Warnungsregel für das Risiko der SNAT-Portausschöpfung. | Azure Firewall bietet 2.496 SNAT-Ports pro öffentlicher IP-Adresse, die pro Back-End-VM-Skalierungsinstanz konfiguriert sind. Es ist wichtig, im Voraus die Anzahl der SNAT-Ports zu schätzen, die Ihre Organisationsanforderungen für ausgehenden Datenverkehr an das Internet erfüllen. Tun Sie dies nicht, wird das Risiko erhöht, die Anzahl der verfügbaren SNAT-Ports in der Azure Firewall zu erschöpfen, was zu Fehlern bei der ausgehenden Konnektivität führen kann. Verwenden Sie die Metrik SNAT-Portauslastung, um den Prozentsatz der aktuell verwendeten ausgehenden SNAT-Ports zu überwachen. Erstellen Sie eine Warnungsregel für diese Metrik, die ausgelöst wird, wenn dieser Prozentsatz 95 % überschreitet (z. B. aufgrund einer unvorhergesehenen Datenverkehrserhöhung), sodass Sie entsprechend reagieren können, indem Sie eine andere öffentliche IP-Adresse in der Azure Firewall konfigurieren oder stattdessen ein Azure NAT Gateway verwenden. Verwenden Sie den Aggregationstyp Maximum beim Konfigurieren der Warnungsregel. Weitere Informationen zur Interpretation der Metrik SNAT-Portauslastung finden Sie in der Übersicht über Azure Firewall-Protokolle und -Metriken. Weitere Informationen zum Skalieren von SNAT-Ports in Azure Firewall finden Sie unter Skalieren von SNAT-Ports mit Azure NAT Gateway. |
| Erstellen Sie eine Warnungsregel für die Firewallüberlastung. | Der maximale Durchsatz von Azure Firewall unterscheidet sich je nach aktivierter SKU und Features. Weitere Informationen zur Azure Firewall-Leistung finden Sie unter Azure Firewall-Leistung. Möglicherweise möchten Sie benachrichtigt werden, wenn sich Ihre Firewall dem maximalen Durchsatz nähert. Sie können die zugrunde liegende Ursache beheben, da sich diese Situation auf die Leistung der Firewall auswirken kann. Erstellen Sie eine Warnungsregel, die ausgelöst werden soll, wenn die Durchsatz-Metrik einen Wert in der Nähe des maximalen Durchsatzes der Firewall überschreitet – wenn der maximale Durchsatz 30 Gbit/s beträgt, konfigurieren Sie beispielsweise 25 Gbit/s als Schwellenwert. Die Einheit der Metrik Durchsatz ist Bits/s. Wählen Sie beim Erstellen der Warnungsregel den Aggregationstyp Durchschnitt aus. |
Resource Health-Warnungen
Sie können auch über Service Health Resource Health-Warnungen für die folgenden Ressourcen konfigurieren. Dieser Ansatz stellt sicher, dass Sie über die Verfügbarkeit Ihrer Virtual WAN-Umgebung informiert sind. Die Warnmeldungen ermöglichen es Ihnen zu ermitteln, ob Netzwerkprobleme darauf zurückzuführen sind, dass Ihre Azure-Ressourcen in einen fehlerhaften Zustand übergehen, oder auf Probleme in Ihrer lokalen Umgebung. Wir empfehlen, dass Sie Warnungen für den Fall konfigurieren, dass der Zustand einer Ressource sich verschlechtert oder sie nicht mehr verfügbar ist. Wenn der Zustand einer Ressource sich verschlechtert bzw. sie nicht mehr verfügbar ist, können Sie analysieren, ob es in letzter Zeit Spitzen im Datenverkehr, der von diesen Ressourcen verarbeitet wird, in den Routen, die für diese Ressourcen beworben werden, oder in der Anzahl der erstellten Branch/VNet-Verbindungen gibt. Weitere Informationen zu Grenzwerten, die in Virtual WAN unterstützt werden, finden Sie unter Grenzwerte von Azure Virtual WAN.
- Microsoft.Network/vpnGateways
- Microsoft.Network/expressRouteGateways
- Microsoft.Network/azureFirewalls
- Microsoft.Network/virtualHubs
- Microsoft.Network/p2sVpnGateways
Zugehöriger Inhalt
- Eine Referenz der Metriken, Protokolle und weiteren wichtigen Werte, die für Virtual WAN erstellt werden, finden Sie in der Referenz zu den Überwachungsdaten für Azure Virtual WAN.
- Allgemeine Informationen zur Überwachung von Azure-Ressourcen finden Sie unter Überwachen von Azure-Ressourcen mit Azure Monitor.