Tutorial: Konfigurieren der gespiegelten Microsoft Fabric-Datenbank für Azure Cosmos DB (Vorschau)
In diesem Tutorial konfigurieren Sie eine gespiegelte Fabric-Datenbank aus einem vorhandenen Azure Cosmos DB for NoSQL-Konto.
Durch die inkrementelle Spiegelung werden Azure Cosmos DB-Daten in Fabric OneLake in Quasi-Echtzeit repliziert, ohne sich auf die Leistung von Transaktionsworkloads oder die Nutzung von Anforderungseinheiten (Request Units, RUs) auszuwirken. Sie können Power BI-Berichte direkt auf den Daten in OneLake erstellen, indem Sie den DirectLake-Modus verwenden. Sie können Ad-hoc-Abfragen in SQL oder Spark ausführen, Datenmodelle mithilfe von Notebooks erstellen und integrierte Copilot und erweiterte KI-Funktionen in Fabric nutzen, um die Daten zu analysieren.
Wichtig
Die Spiegelung für Azure Cosmos DB befindet sich derzeit in der Vorschau. Produktionsworkloads werden in der Vorschauversion nicht unterstützt. Derzeit werden nur Azure Cosmos DB for NoSQL-Konten unterstützt.
Voraussetzungen
- Ein vorhandenes Azure Cosmos DB for NoSQL-Konto.
- Wenn Sie kein Azure-Abonnement besitzen, testen Sie Azure Cosmos DB for NoSQL kostenlos.
- Wenn Sie über ein Azure-Abonnement verfügen, erstellen Sie einen neuen Azure Cosmos DB for NoSQL-Cluster.
- Eine vorhandene Fabric-Kapazität. Wenn Sie noch keine Kapazität haben, starten Sie einen Fabric-Test. Die Spiegelung ist in manchen Fabric-Regionen möglicherweise nicht verfügbar. Weitere Informationen finden Sie unter Unterstützte Regionen.
Tipp
Es wird empfohlen, während der öffentlichen Vorschau eine Test- oder Entwicklungskopie Ihrer bestehenden Azure Cosmos DB-Daten zu verwenden, die schnell aus einem Backup wiederhergestellt werden kann.
Konfigurieren Ihres Azure Cosmos DB-Kontos
Stellen Sie zunächst sicher, dass das Azure Cosmos DB-Quellkonto ordnungsgemäß für die Verwendung mit der Fabric Spiegelung konfiguriert ist.
Navigieren Sie im Azure-Portal zu Ihrem Azure Cosmos DB-Konto.
Stellen Sie sicher, dass die fortlaufende Sicherung aktiviert ist. Falls nicht aktiviert, folgen Sie der Anleitung unter Migrieren eines bestehenden Azure Cosmos DB-Kontos auf fortlaufende Sicherung, um die fortlaufende Sicherung zu aktivieren. Dieses Feature ist in manchen Szenarien möglicherweise nicht verfügbar. Weitere Informationen finden Sie unter Datenbank- und Kontobeschränkungen.
Stellen Sie sicher, dass die Netzwerkoptionen für alle Netzwerke auf Öffentlicher Netzwerkzugang eingestellt sind. Falls nicht, folgen Sie der Anleitung unter Netzwerkzugriff auf ein Azure Cosmos DB-Konto konfigurieren.
Eine gespiegelte Datenbank erstellen
Erstellen Sie nun eine gespiegelte Datenbank, die das Ziel der replizierten Daten ist. Weitere Informationen finden Sie unter Was Sie von der Spiegelung erwarten können.
Navigieren Sie zur Startseite des Fabric-Portals.
Öffnen Sie einen bestehenden Arbeitsbereich oder erstellen Sie einen neuen Arbeitsbereich.
Wählen Sie im Navigationsmenü Erstellen.
Wählen Sie Erstellen, suchen Sie den Abschnitt Data Warehouse und wählen Sie dann Gespiegelte Azure Cosmos DB (Vorschau).
Geben Sie einen Namen für die gespiegelte Datenbank ein und wählen Sie dann Erstellen.
Eine Verbindung mit der Quelldatenbank herstellen
Als nächstes verbinden Sie die Quelldatenbank mit der gespiegelten Datenbank.
Wählen Sie im Abschnitt Neue Verbindung die Option Azure Cosmos DB for NoSQL.
Geben Sie die Anmeldeinformationen für das Azure Cosmos DB for NoSQL-Konto an, einschließlich dieser Elemente:
Wert Azure Cosmos DB-Endpunkt URL-Endpunkt für das Quellkonto. Verbindungsname Eindeutiger Name für die Verbindung. Authentifizierungsart Wählen Sie Kontoschlüssel. Kontoschlüssel Lese-/Schreibzugriffsschlüssel für das Quellkonto. 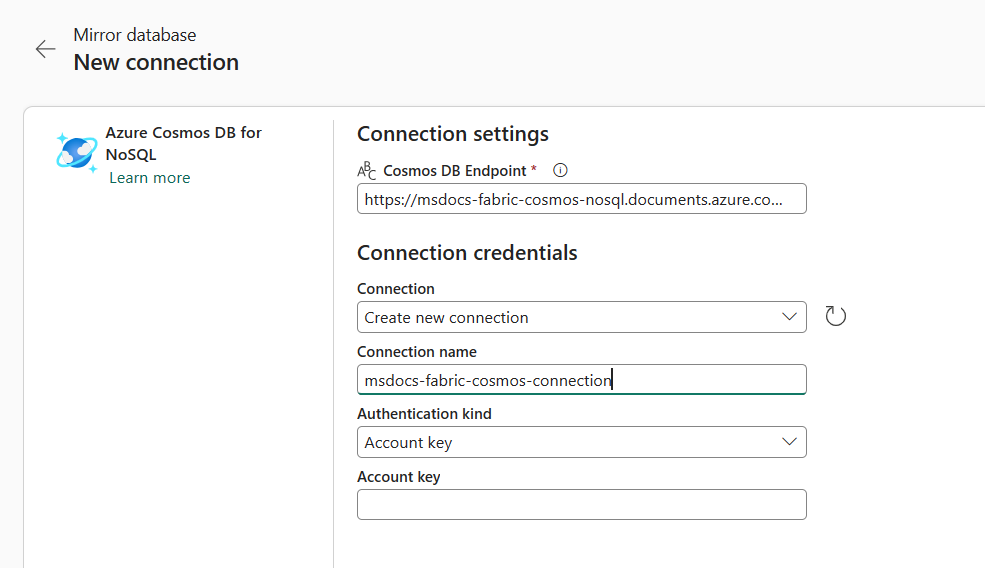
Wählen Sie Verbinden. Wählen Sie dann eine Datenbank zur Spiegelung aus.
Hinweis
Alle Container in der Datenbank werden gespiegelt.

Starten des Spiegelungsprozesses
Wählen Sie Datenbank spiegeln aus. Die Spiegelung beginnt jetzt.
Warten Sie zwei bis fünf Minuten. Wählen Sie dann Replikation überwachen, um den Status der Replikationsaktion zu sehen.
Nach ein paar Minuten sollte sich der Status auf Ausführen ändern, was bedeutet, dass die Container synchronisiert werden.
Tipp
Wenn Sie die Container und den entsprechenden Replikationsstatus nicht finden können, warten Sie ein paar Sekunden und aktualisieren Sie dann den Bereich. In seltenen Fällen erhalten Sie möglicherweise vorübergehende Fehlermeldungen. Sie können sie getrost ignorieren und mit der Aktualisierung fortfahren.
Wenn die Spiegelung das anfängliche Kopieren der Container abgeschlossen hat, erscheint ein Datum in der Spalte Letzte Aktualisierung. Wenn die Daten erfolgreich repliziert wurden, enthält die Spalte Ergebniszeilen die Anzahl der replizierten Elemente.
Fabric-Spiegelung überwachen
Jetzt, wo Ihre Daten in Betrieb sind, stehen Ihnen verschiedene Analyseszenarien für alle Fabric zur Verfügung.
Sobald die Fabric-Spiegelung konfiguriert ist, werden Sie automatisch zum Bereich Replikationsstatus geleitet.
Hier überwachen Sie den aktuellen Stand der Replikation. Weitere Informationen und Details zu den Replikationszuständen finden Sie unter Überwachen der Replikation von gespiegelten Datenbanken in Fabric.
Abfrage der Quelldatenbank von Fabric
Verwenden Sie das Fabric-Portal, um die Daten zu erkunden, die bereits in Ihrem Azure Cosmos DB-Konto vorhanden sind, indem Sie Ihre Cosmos DB-Quelldatenbank abfragen.
Navigieren zur gespiegelten Datenbank im Fabric-Portal.
Wählen Sie Ansicht und dann Quelldatenbank aus. Diese Aktion öffnet den Azure Cosmos DB-Datenexplorer mit einer schreibgeschützten Ansicht der Quelldatenbank.
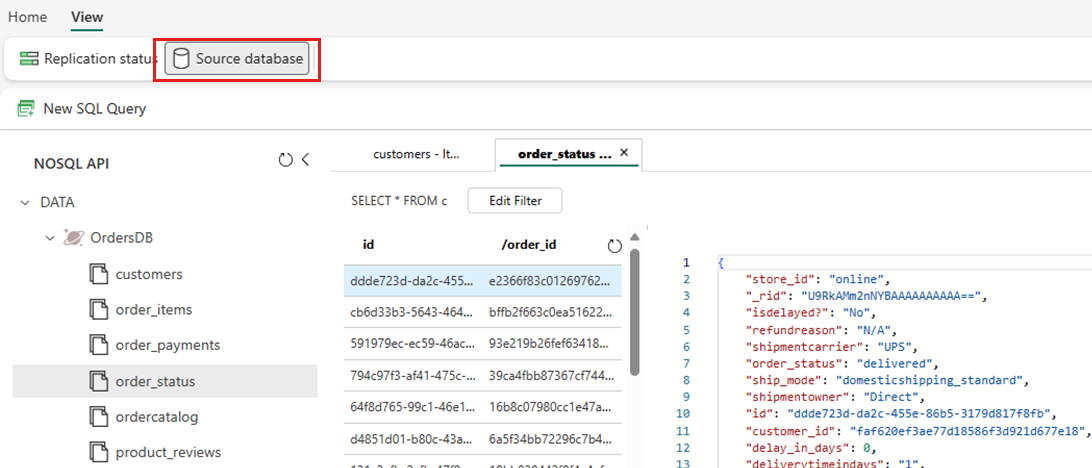
Markieren Sie einen Container, öffnen Sie dann das Kontextmenü und wählen Sie Neue SQL-Abfrage.
Führen Sie eine Abfrage aus. Zählen Sie mit
SELECT COUNT(1) FROM containerzum Beispiel die Anzahl der Gegenstände im Behälter.Hinweis
Alle Lesevorgänge in der Quelldatenbank werden an Azure weitergeleitet und verbrauchen Anforderungseinheiten (Request Units, RUs), die dem Konto zugewiesen sind.

Analysieren Sie die gespiegelte Zieldatenbank
Verwenden Sie nun T-SQL, um Ihre NoSQL-Daten abzufragen, die nun in Fabric OneLake gespeichert sind.
Navigieren zur gespiegelten Datenbank im Fabric-Portal.
Wechseln Sie von Gespiegelte Azure Cosmos DB zum SQL-Analytics-Endpunkt.

Jeder Container in der Quelldatenbank sollte im SQL-Analytics-Endpunkt als Warehouse-Tabelle dargestellt werden.
Wählen Sie eine beliebige Tabelle, öffnen Sie das Kontextmenü, wählen Sie Neue SQL-Abfrage und wählen Sie schließlich Top 100 auswählen.
Die Abfrage wird ausgeführt und liefert 100 Datensätze in der ausgewählten Tabelle.
Öffnen Sie das Kontextmenü für dieselbe Tabelle und wählen Sie Neue SQL-Abfrage. Schreiben Sie eine Beispielabfrage, die Aggregate wie
SUM,COUNT,MINoderMAXenthalten. Verbinden Sie mehrere Tabellen im Warehouse, um die Abfrage über mehrere Container hinweg auszuführen.Hinweis
Diese Abfrage würde zum Beispiel über mehrere Container hinweg ausgeführt werden:
SELECT d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type], sum(o.[price]) as price, sum(o.[freight_value]) freight_value FROM [dbo].[products] p INNER JOIN [dbo].[OrdersDB_order_payments] p on o.[order_id] = p.[order_id] INNER JOIN [dbo].[OrdersDB_order_status] t ON o.[order_id] = t.[order_id] INNER JOIN [dbo].[OrdersDB_customers] c on t.[customer_id] = c.[customer_id] INNER JOIN [dbo].[OrdersDB_productdirectory] d ON o.product_id = d.product_id INNER JOIN [dbo].[OrdersDB_sellers] s on o.seller_id = s.seller_id GROUP BY d.[product_category_name], t.[order_status], c.[customer_country], s.[seller_state], p.[payment_type]In diesem Beispiel wird der Name Ihrer Tabelle und Ihrer Spalten vorausgesetzt. Verwenden Sie beim Schreiben Ihrer SQL-Abfrage Ihre eigene Tabelle und Spalten.
Wählen Sie die Abfrage aus und wählen Sie dann Als Ansicht speichern. Geben Sie der Ansicht einen eindeutigen Namen. Sie können diese Ansicht jederzeit über das Fabric-Portal aufrufen.
Kehren Sie zurück zur gespiegelten Datenbank im Fabric-Portal.
Wählen Sie Neue visuelle Abfrage. Verwenden Sie den Abfrage-Editor, um komplexe Abfragen zu erstellen.
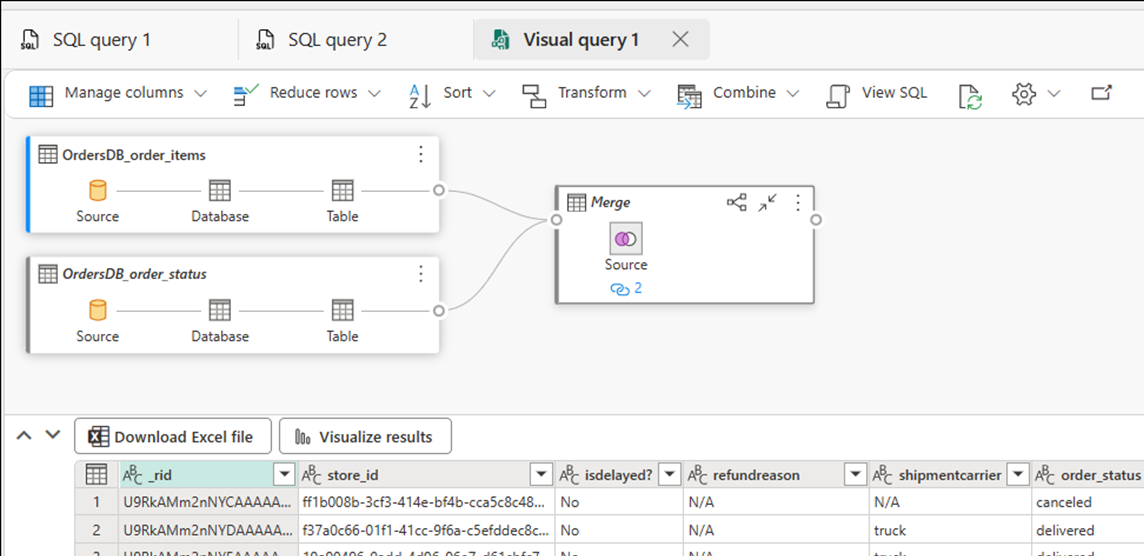


Erstellen von BI-Berichten für die SQL-Abfragen oder Sichten
- Wählen Sie die Abfrage oder Ansicht aus und wählen Sie dann Diese Daten durchsuchen (Vorschau) aus. Mit dieser Aktion wird die Abfrage in Power BI direkt mit Direct Lake auf gespiegelten OneLake-Daten untersucht.
- Bearbeiten Sie die Diagramme nach Bedarf, und speichern Sie den Bericht.
Tipp
Sie können optional auch Copilot oder andere Erweiterungen verwenden, um Dashboards und Berichte ohne weitere Datenbewegungen zu erstellen.
Weitere Beispiele
Erfahren Sie mehr darüber, wie Sie auf gespiegelte Azure Cosmos DB-Daten in Fabric zugreifen und diese abfragen können:
- Vorgehensweise: Abfragen von gespiegelten Datenbanken in Microsoft Fabric von Azure Cosmos DB (Vorschau)
- Informationen zum Zugriff auf gespiegelte Azure Cosmos DB-Daten in Lakehouse und Notebooks von Microsoft Fabric (Vorschau)
- Vorgehensweise: Verknüpfen von gespiegelten Azure Cosmos DB-Daten mit anderen gespiegelten Datenbanken in Microsoft Fabric (Vorschau)