dcount() (Aggregationsfunktion)
Gilt für: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Berechnet eine Schätzung der Anzahl unterschiedlicher Werte, die von einem skalaren Ausdruck in der Zusammenfassungsgruppe übernommen werden.
Nullwerte werden ignoriert und nicht in die Berechnung berücksichtigt.
Hinweis
Die dcount()-Aggregationsfunktion ist hauptsächlich zum Schätzen der Kardinalität großer Sätze nützlich. Es handelt sich um eine Genauigkeit für die Leistung und kann ein Ergebnis zurückgeben, das zwischen Ausführungen variiert. Die Reihenfolge der Eingaben hat möglicherweise Auswirkungen auf die Ausgabe.
Syntax
dcount(Ausdruck[, Genauigkeit])
Erfahren Sie mehr über Syntaxkonventionen.
Parameter
| Name | Type | Erforderlich | Beschreibung |
|---|---|---|---|
| expr | string |
✔️ | Die Eingabe, deren unterschiedliche Werte gezählt werden sollen. |
| Genauigkeit | int |
Der Wert, der die angeforderte Schätzungsgenauigkeit definiert. Der Standardwert ist 1. Siehe Schätzungsgenauigkeit für unterstützte Werte. |
Gibt zurück
Gibt eine Schätzung der Anzahl der unterschiedlichen Werte des Ausdrucks in der Gruppe zurück.
Beispiel
In diesem Beispiel wird gezeigt, wie viele Arten von Sturmereignissen in jedem Zustand aufgetreten sind.
StormEvents
| summarize DifferentEvents=dcount(EventType) by State
| order by DifferentEvents
Die angezeigte Ergebnistabelle enthält nur die ersten 10 Zeilen.
| Staat | DifferentEvents |
|---|---|
| TEXAS | 27 |
| CALIFORNIA | 26 |
| PENNSYLVANIA | 25 |
| GEORGIA | 24 |
| ILLINOIS | 23 |
| MARYLAND | 23 |
| NORTH CAROLINA | 23 |
| MICHIGAN | 22 |
| FLORIDA | 22 |
| OREGON | 21 |
| KANSAS | 21 |
| ... | ... |
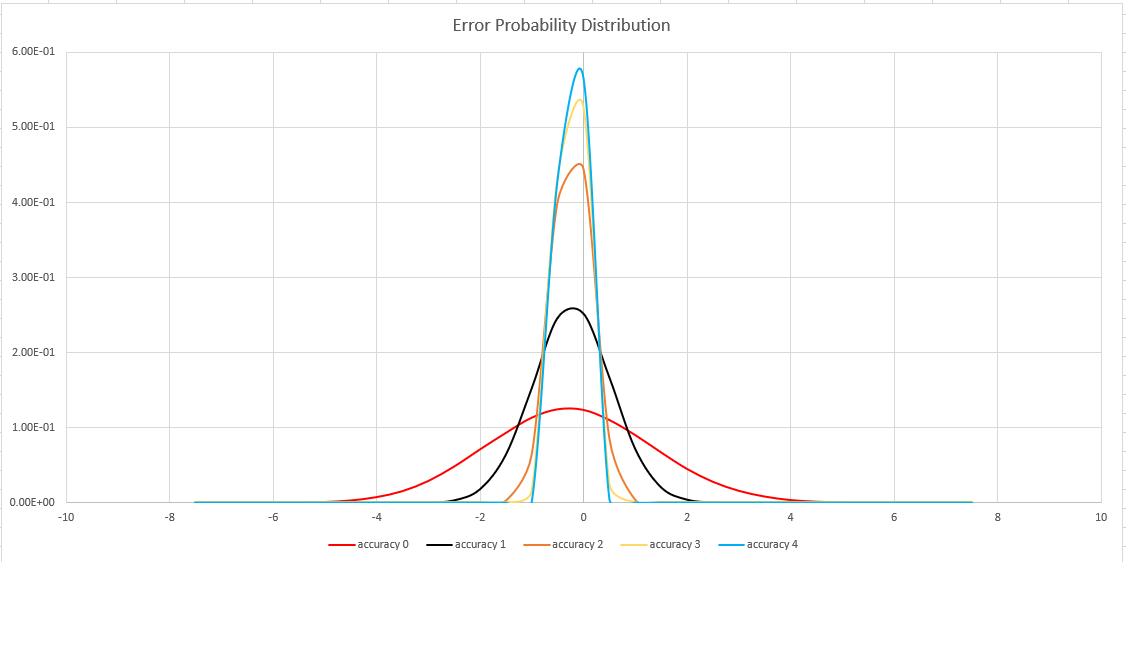
Schätzgenauigkeit
Diese Funktion verwendet eine Variante des HyperLogLog (HLL)-Algorithmus, der eine stochastische Schätzung der Set-Kardinalität durchführt. Der Algorithmus stellt einen „Knopf“ bereit, über den Genauigkeit und Ausführungszeit pro Arbeitsspeichergröße ausgeglichen werden können:
| Genauigkeit | Fehler (%) | Entry count |
|---|---|---|
| 0 | 1.6 | 212 |
| 1 | 0,8 | 214 |
| 2 | 0,4 | 216 |
| 3 | 0.28 | 217 |
| 4 | 0.2 | 218 |
Hinweis
Die Spalte „entry count“ ist die Anzahl von 1-Byte-Leistungsindikatoren in der HLL-Implementierung.
Der Algorithmus enthält einige Vorkehrungen für eine perfekte Anzahl (null Fehler), wenn die festgelegte Kardinalität klein genug ist:
- Wenn die Genauigkeitsgrad
1ist, werden 1.000 Werte zurückgegeben. - Wenn die Genauigkeitsgrad
2ist, werden 8.000 Werte zurückgegeben.
Die Fehlerbindung ist probabilistisch und keine theoretische Grenze. Der Wert ist die Standardabweichung der Fehlerverteilung (Sigma), und 99,7 % der Schätzungen weisen einen relativen Fehler von unter 3 x Sigma auf.
Die folgende Abbildung zeigt die Wahrscheinlichkeitsverteilungsfunktion des relativen Schätzfehlers in Prozent für alle unterstützten Genauigkeitseinstellungen: