Installieren und Aktivieren der Datenduplizierung
In diesem Thema wird erläutert, wie Sie Datendeduplizierung installieren, Workloads für die Deduplizierung bestimmen und die Datendeduplizierung auf bestimmten Volumes aktivieren.
Hinweis
Wenn Sie die Datendeduplizierung in einem Failovercluster ausführen möchten, muss für jeden Knoten im Cluster die Serverrolle „Datendeduplizierung“ installiert sein.
Installieren der Datendeduplizierung
Wichtig
KB4025334 enthält eine Zusammenfassung von Fehlerbehebungen für die Datendeduplizierung einschließlich wichtiger Zuverlässigkeitskorrekturen, und es wird dringend empfohlen, diese bei Verwendung der Datendeduplizierung mit Windows Server 2016 zu installieren.
So installieren Sie die Datendeduplizierung mithilfe des Server-Managers
- Wählen Sie im Assistenten zum Hinzufügen von Rollen und Features Serverrollen aus, und wählen sie dann Datendeduplizierung aus.
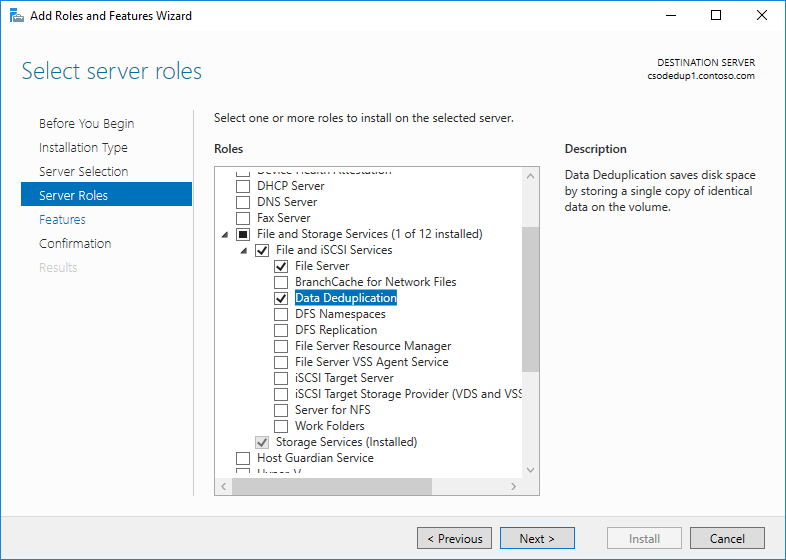
- Klicken Sie auf Weiter , bis die Schaltfläche Installieren aktiviert wird, und klicken Sie dann auf Installieren.
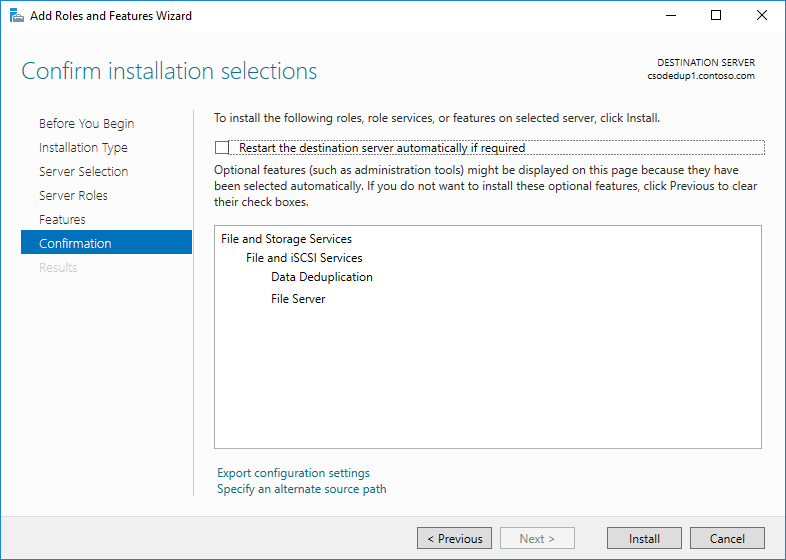
Installieren der Datendeduplizierung mithilfe von PowerShell
Um die Datendeduplizierung zu installieren, führen Sie den folgenden PowerShell-Befehl als Administrator aus: Install-WindowsFeature -Name FS-Data-Deduplication
So installieren Sie die Datendeduplizierung
Installieren Sie auf einem Server mit Windows Server 2016 oder von einem Windows-PC mit installierten Remoteserver-Verwaltungstools (Remote Server Administration Tools, RSAT) die Datendeduplizierung mit einem expliziten Verweis auf den Servernamen (ersetzen Sie „MyServer“ durch den tatsächlichen Namen der Serverinstanz):
Install-WindowsFeature -ComputerName <MyServer> -Name FS-Data-Deduplicationoder
Stellen Sie mithilfe von PowerShell-Remoting eine Remoteverbindung mit der Serverinstanz her, und installieren Sie die Datendeduplizierung, indem Sie DISM verwenden:
Enter-PSSession -ComputerName MyServer dism /online /enable-feature /featurename:dedup-core /all
Aktivieren der Datendeduplizierung
Bestimmen, welche Workloads für die Deduplizierung in Frage kommen
Datendeduplizierung kann ein effektives Instrument zum Minimieren der Kosten für die Datennutzung einer Serveranwendung sein, indem der Speicherplatz reduziert wird, der von redundanten Daten belegt wird. Vor der Aktivierung der Deduplizierung ist es wichtig, dass Sie die Merkmale Ihrer Workload verstehen, um sicherzustellen, dass Ihr Speicher Ihnen die maximale Leistung bietet. Zwei Arten von Workloads müssen berücksichtigt werden:
- Empfohlene Workloads, die nachweislich sowohl Datasets enthalten, die umfassend von der Datendeduplizierung profitieren, als auch Ressourcennutzungsmuster aufweisen, die mit dem Nachbearbeitungsmodell der Datendeduplizierung kompatibel sind. Es wird empfohlen, dass Sie für die folgenden Workloads stets die Datendeduplizierung aktivieren:
- Allgemeine Dateiserver mit Freigaben(General purpose file servers, GPFS) wie Teamfreigaben, Basisordner von Benutzern, Arbeitsordnern und Freigaben für die Softwareentwicklung
- VDI-Server (virtuelle Desktopinfrastruktur)
- Virtualisierte Sicherungsprogramme wie Microsoft Data Protection Manager (DPM)
- Workloads, die ggf. von der Deduplizierung profitieren, aber nicht immer gute Kandidaten für die Deduplizierung sind Die folgenden Workloads sind z.B. gut für die Deduplizierung geeignet, jedoch sollen Sie zunächst die Vorteile der Deduplizierung evaluieren:
- Allgemeine Hyper-V-Hosts
- SQL-Server
- Branchenspezifische Server
Auswerten von Workloads für die Datendeduplizierung
Wichtig
Bei Ausführen einer empfohlenen Workload können Sie diesen Abschnitt überspringen und für Ihre Workload Aktivieren der Datendeduplizierung aufrufen.
Um zu bestimmen, ob sich eine Workload gut für die Deduplizierung eignet, beantworten Sie die folgenden Fragen. Wenn Sie sich bei einer Workload nicht sicher sind, erwägen Sie eine Pilotbereitstellung der Datendeduplizierung für ein Testdataset Ihrer Workload, um das Ergebnis zu prüfen.
Weist das Dataset meiner Workload genügend Duplizierung auf, um vom Aktivieren der Deduplizierung zu profitieren? Überprüfen Sie vor dem Aktivieren der Datendeduplizierung für eine Workload, wie viele Duplikate das Dataset Ihrer Workload aufweist. Nutzen Sie dazu das Tool für die Auswertung der Einsparungen durch Datendeduplizierung (DDPEval). Nach Installation der Datendeduplizierung finden Sie dieses Tool unter
C:\Windows\System32\DDPEval.exe. DDPEval kann das Optimierungspotenzial für direkt angeschlossene Volumes (so z.B. lokale Laufwerke oder freigegebene Clustervolumes) sowie zugeordnete und nicht zugeordnete Netzwerkfreigaben einschätzen.Bei Ausführen von „DDPEval.exe“ wird eine Ausgabe ähnlich der folgenden zurückgegeben:
Data Deduplication Savings Evaluation Tool Copyright 2011-2012 Microsoft Corporation. All Rights Reserved. Evaluated folder: E:\Test Processed files: 34 Processed files size: 12.03MB Optimized files size: 4.02MB Space savings: 8.01MB Space savings percent: 66 Optimized files size (no compression): 11.47MB Space savings (no compression): 571.53KB Space savings percent (no compression): 4 Files with duplication: 2 Files excluded by policy: 20 Files excluded by error: 0Wie sehen die E/A-Muster des Datasets meiner Workload aus? Welche Leistung erziele ich für meine Workload? Die Datendeduplizierung optimiert die Daten im Rahmen eines regelmäßigen Auftrags, anstatt sie zu optimieren, wenn eine Datei auf einen Datenträger geschrieben wird. Deshalb ist es zunächst wichtig, dass die erwarteten Lesemuster einer Workload auf dem deduplizierten Volume untersucht werden. Da bei der Datendeduplizierung Dateiinhalte in den Blockspeicher verschoben werden und versucht wird, den Blockspeicher so umfassend wie möglich dateibezogen zu organisieren, liefern Lesevorgänge die beste Leistung, wenn sie entsprechend sequenziellen Bereichen einer Datei angewendet werden.
Datenbankähnliche Workloads weisen zumeist eher Lesemuster nach dem Zufallsprinzip als sequenzielle Lesemuster auf, da Datenbanken in der Regel nicht gewährleisten, dass das Datenbanklayout für alle möglicherweise ausgeführten Abfragen optimal ist. Da sich die Abschnitte des Blockspeichers auf dem gesamten Volume befinden können, kann es beim Zugriff auf Datenbereiche im Blockspeicher für Datenbankabfragen zu zusätzlicher Latenz kommen. Hochleistungsworkloads sind besonders empfindlich für diese zusätzliche Latenz, andere datenbankähnliche Workloads jedoch möglicherweise nicht.
Hinweis
Diese Aspekte gelten in erster Linie für Speicherworkloads auf Volumes, die aus herkömmlichen rotierenden Speichermedien (also Festplattenlaufwerken bzw. HDDs) bestehen. Die gesamte Flashspeicherinfrastruktur (Solid State Disk-Laufwerke bzw. SSDs) ist von zufälligen E/A-Mustern weniger betroffen, da bei Flash-Speichermedien die Zugriffszeit auf alle Speicherorte im Datenträger gleich lang ist. Daher sorgt eine Deduplizierung nicht für denselben Umfang von Latenz bei Lesevorgängen in den Datasets einer Workload, die vollständig auf Flashmedien gespeichert sind, wie bei herkömmlichen rotierenden Speichermedien.
Wie hoch ist der Ressourcenbedarf meiner Workload auf dem Server? Da bei der Datendeduplizierung ein Nachbearbeitungsmodell zum Einsatz kommt, sind für die Datendeduplizierung regelmäßig genügend Systemressourcen erforderlich, um die Optimierung und andere Aufträge auszuführen. Dies bedeutet, dass Workloads mit Leerlaufzeit, z.B. abends oder am Wochenende, sich besonders für die Deduplizierung eignen, was bei rund um die Uhr ausgeführten Workloads ggf. nicht der Fall ist. Workloads ohne Leerlaufzeiten können sich dennoch gut für eine Deduplizierung eignen, wenn sie keinen hohen Ressourcenbedarf auf dem Server haben.
Aktivieren der Datendeduplizierung
Sie müssen vor dem Aktivieren der Datendeduplizierung den Verwendungstyp wählen, der Ihrer Workload am ehesten entspricht. Für die Datendeduplizierung gibt es drei Verwendungstypen.
- Standard – speziell für allgemeine Dateiserver optimiert
- Hyper-V – speziell für VDI-Server optimiert
- Sicherung – speziell für virtualisierte Sicherungsprogramme wie Microsoft Data Protection Manager (DPM) optimiert
Aktivieren der Datendeduplizierung mithilfe von Server-Manager
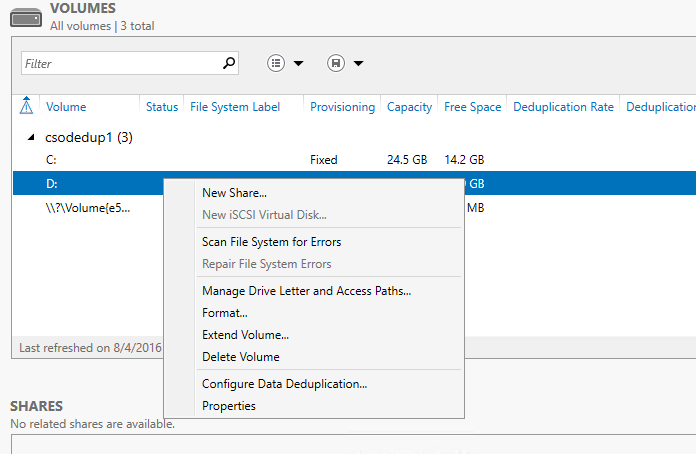
- Wählen Sie Datei- und Speicherdienste im Server-Manager aus.
- Wählen Sie Volumes im Menü Datei- und Speicherdienste aus.
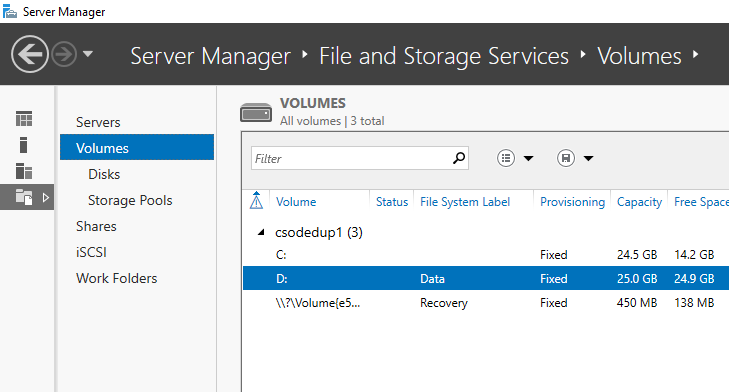
- Klicken Sie mit der rechten Maustaste auf das gewünschte Volume, und wählen Sie Datendeduplizierung konfigurieren aus.
- Wählen Sie im Dropdownfeld den gewünschten Verwendungstyp aus, und klicken Sie auf OK.
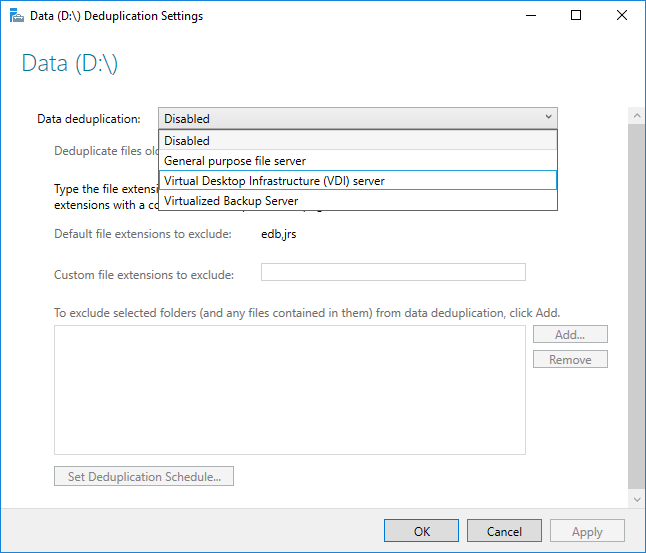
- Wenn Sie eine empfohlene Workload ausführen, sind Sie fertig. Sehen Sie sich für andere Workloads die weiteren Aspekte an.
Hinweis
Weitere Informationen zum Ausschließen von Dateinamenerweiterungen oder Ordnern und Auswählen des Zeitplans für die Deduplizierung, einschließlich Gründen, finden Sie unter Konfigurieren der Datendeduplizierung.
Aktivieren der Datendeduplizierung mit PowerShell
Führen Sie im Kontext eines Administrators den folgenden PowerShell-Befehl aus:
Enable-DedupVolume -Volume <Volume-Path> -UsageType <Selected-Usage-Type>Wenn Sie eine empfohlene Workload ausführen, sind Sie fertig. Sehen Sie sich für andere Workloads die weiteren Aspekte an.
Hinweis
Die PowerShell-Cmdlets für die Datendeduplizierung, einschließlich Enable-DedupVolume, können durch Anhängen des -CimSession-Parameters an eine CIM-Sitzung remote ausgeführt werden. Dies ist besonders nützlich für die Remoteausführung der PowerShell-Cmdlets für die Datendeduplizierung für eine Serverinstanz. Zum Erstellen einer neuen CIM-Sitzung führen Sie New-CimSession aus.
Andere Aspekte
Wichtig
Wenn Sie eine empfohlene Workload ausführen, können Sie diesen Abschnitt überspringen.
- Die Verwendungstypen für die Datendeduplizierung arbeiten mit sinnvollen Standardwerten für empfohlene Workloads, bieten aber auch einen guten Ausgangspunkt für alle Workloads. Für andere Workloads als die empfohlenen lassen sich die erweiterten Einstellungen für die Datendeduplizierung ändern, um die Deduplizierungsleistung zu verbessern.
- Wenn Ihre Workload einen hohen Ressourcenbedarf auf Ihrem Server hat, müssen die Datendeduplizierungsaufträge während der erwarteten Leerlaufzeiten für die jeweilige Workload ausgeführt werden. Dies ist besonders wichtig bei der Ausführung der Deduplizierung auf einem hyperkonvergenten Host, da die Ausführung der Datendeduplizierung während der Geschäftszeiten VMs beeinträchtigen kann.
- Wenn Ihre Workload keinen hohen Ressourcenbedarf hat oder es wichtiger ist, Optimierungsaufträge auszuführen anstatt Workloadanforderungen zu erfüllen, können Sie den Arbeitsspeicher, die CPU-Leistung und Priorität der Datendeduplizierungsaufträge anpassen.
Häufig gestellte Fragen (FAQ)
Ich möchte die Datendeduplizierung auf das Dataset für Workload X anwenden. Wird dies unterstützt? Abgesehen von Workloads, die bekanntermaßen nicht mit der Datendeduplizierung zusammenarbeiten, unterstützen wir die Datenintegrität der Datendeduplizierung für alle Workloads. Empfohlene Workloads werden auch hinsichtlich Leistung von Microsoft unterstützt. Die Leistung anderer Workloads hängt erheblich davon ab, was diese auf dem Server ausführen. Sie müssen bestimmen, welche Leistungsbeeinträchtigungen die Datendeduplizierung auf Ihre Workload ausübt, und ob dies für diese Workload zulässig ist.
Was sind die Anforderungen an die Volumegröße für deduplizierte Volumes? Unter Windows Server 2012 und Windows Server 2012 R2 musste die Größe von Volumes sorgfältig geplant werden, um sicherzustellen, dass die Datendeduplizierung mit den Änderungsumfang auf dem Datenträger zurechtkam. Dies bedeutete in der Regel, dass die durchschnittliche maximale Größe eines deduplizierten Volumes bei einer Workload mit hohem Änderungsumfang 1-2 TB und die absolute maximale empfohlene Größe 10 TB betrug. Unter Windows Server 2016 gelten diese Einschränkungen nicht mehr. Weitere Informationen finden Sie unter Neuigkeiten bei der Datendeduplizierung.
Muss ich für empfohlene Workloads den Zeitplan oder andere Reprofilierungseinstellungen ändern? Nein, die bereitgestellten Verwendungstypen sind so ausgelegt, dass für empfohlene Workloads sinnvolle Standardwerte vorgegeben sind.
Welche Arbeitsspeicheranforderungen gelten für die Datendeduplizierung?
Für den Minimalfall sollten für die Datendeduplizierung 300 MB + 50 MB für jedes TB logischer Daten vorgesehen werden. Wenn Sie beispielsweise ein 10-TB-Volume optimieren, benötigen Sie für die Deduplizierung mindestens 800 MB Arbeitsspeicher (300 MB + 50 MB * 10 = 300 MB + 500 MB = 800 MB). Während die Datendeduplizierung ein Volume mit diesem niedrigen Umfang an Arbeitsspeicher optimieren kann, werden Datendeduplizierungsaufträge durch solch einschränkte Ressourcen verlangsamt.
Im optimalen Fall sollte die Datendeduplizierung über 1 GB Arbeitsspeicher pro 1 TB logischer Daten verfügen. Wenn Sie beispielsweise ein 10-TB-Volume optimieren, benötigen Sie im Optimalfall für die Deduplizierung mindestens 10 GB Arbeitsspeicher (1 GB * 10). Dieses Verhältnis stellt die maximale Leistung für Datendeduplizierungsaufträge sicher.
Welche Speicherplatzanforderungen gelten für die Datendeduplizierung? Unter Windows Server 2016 unterstützt die Datendeduplizierung Volumegrößen bis zu 64 TB. Weitere Informationen finden Sie unter Neuigkeiten bei der Datendeduplizierung.