Transform data using Spark activity in Azure Data Factory and Synapse Analytics
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Try out Data Factory in Microsoft Fabric, an all-in-one analytics solution for enterprises. Microsoft Fabric covers everything from data movement to data science, real-time analytics, business intelligence, and reporting. Learn how to start a new trial for free!
The Spark activity in a data factory and Synapse pipelines executes a Spark program on your own or on-demand HDInsight cluster. This article builds on the data transformation activities article, which presents a general overview of data transformation and the supported transformation activities. When you use an on-demand Spark linked service, the service automatically creates a Spark cluster for you just-in-time to process the data and then deletes the cluster once the processing is complete.
Add a Spark activity to a pipeline with UI
To use a Spark activity to a pipeline, complete the following steps:
Search for Spark in the pipeline Activities pane, and drag a Spark activity to the pipeline canvas.
Select the new Spark activity on the canvas if it is not already selected.
Select the HDI Cluster tab to select or create a new linked service to an HDInsight cluster that will be used to execute the Spark activity.

Select the Script / Jar tab to select or create a new job linked service to an Azure Storage account that will host your script. Specify a path to the file to be executed there. You can also configure advanced details including a proxy user, debugging configuration, and arguments and Spark configuration parameters to be passed to the script.
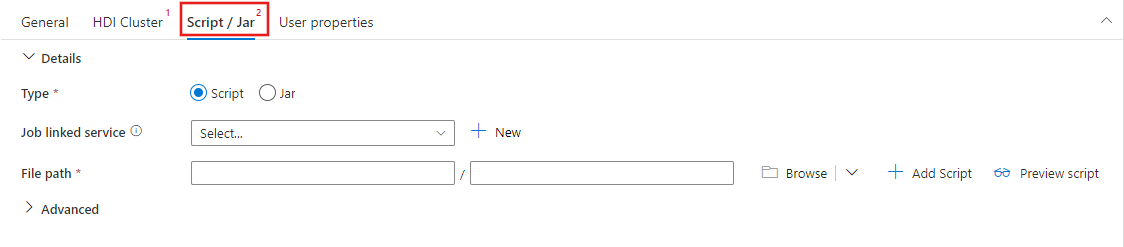
Spark activity properties
Here is the sample JSON definition of a Spark Activity:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
The following table describes the JSON properties used in the JSON definition:
| Property | Description | Required |
|---|---|---|
| name | Name of the activity in the pipeline. | Yes |
| description | Text describing what the activity does. | No |
| type | For Spark Activity, the activity type is HDInsightSpark. | Yes |
| linkedServiceName | Name of the HDInsight Spark Linked Service on which the Spark program runs. To learn about this linked service, see Compute linked services article. | Yes |
| SparkJobLinkedService | The Azure Storage linked service that holds the Spark job file, dependencies, and logs. Only Azure Blob Storage and ADLS Gen2 linked services are supported here. If you do not specify a value for this property, the storage associated with HDInsight cluster is used. The value of this property can only be an Azure Storage linked service. | No |
| rootPath | The Azure Blob container and folder that contains the Spark file. The file name is case-sensitive. Refer to folder structure section (next section) for details about the structure of this folder. | Yes |
| entryFilePath | Relative path to the root folder of the Spark code/package. The entry file must be either a Python file or a .jar file. | Yes |
| className | Application's Java/Spark main class | No |
| arguments | A list of command-line arguments to the Spark program. | No |
| proxyUser | The user account to impersonate to execute the Spark program | No |
| sparkConfig | Specify values for Spark configuration properties listed in the topic: Spark Configuration - Application properties. | No |
| getDebugInfo | Specifies when the Spark log files are copied to the Azure storage used by HDInsight cluster (or) specified by sparkJobLinkedService. Allowed values: None, Always, or Failure. Default value: None. | No |
Folder structure
Spark jobs are more extensible than Pig/Hive jobs. For Spark jobs, you can provide multiple dependencies such as jar packages (placed in the Java CLASSPATH), Python files (placed on the PYTHONPATH), and any other files.
Create the following folder structure in the Azure Blob storage referenced by the HDInsight linked service. Then, upload dependent files to the appropriate sub folders in the root folder represented by entryFilePath. For example, upload Python files to the pyFiles subfolder and jar files to the jars subfolder of the root folder. At runtime, the service expects the following folder structure in the Azure Blob storage:
| Path | Description | Required | Type |
|---|---|---|---|
. (root) |
The root path of the Spark job in the storage linked service | Yes | Folder |
| <user defined > | The path pointing to the entry file of the Spark job | Yes | File |
| ./jars | All files under this folder are uploaded and placed on the Java classpath of the cluster | No | Folder |
| ./pyFiles | All files under this folder are uploaded and placed on the PYTHONPATH of the cluster | No | Folder |
| ./files | All files under this folder are uploaded and placed on executor working directory | No | Folder |
| ./archives | All files under this folder are uncompressed | No | Folder |
| ./logs | The folder that contains logs from the Spark cluster. | No | Folder |
Here is an example for a storage containing two Spark job files in the Azure Blob Storage referenced by the HDInsight linked service.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
Related content
See the following articles that explain how to transform data in other ways: