Transact-SQL
A Microsoft extension to the ANSI SQL language that includes procedural programming, local variables, and various support functions.
4,656 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EFZ%3C/text%3E%3C/svg%3E)
I'm trying to use UTF-8 encoding in MSSQL 2019 but I found a weird behavior. Launching a query like
select 'me‚‚‚abcdef' COLLATE Latin1_General_100_CI_AS_SC_UTF8
on tempdb I'm getting this result:
me‚‚‚
where are the other characters? Note that the '‚' is not an ASCII comma but a Unicode 0x201a point which correspond to 0x82 Latin1 encoding (the encoding of the tempdb database).
Replying here as too long and won't fit a reply.
Thanks for the patient and effort. This does not reply entirely to my question but collecting your tests I think I can now explain my queries and the others.
So, let's start with my query and why the result
SELECT 'me‚‚‚abcdef' COLLATE Latin1_General_100_CI_AS_SC_UTF8
the server (and so the parser) receives the string as UTF-16 and parse the string 'me‚‚‚abcdef', as it's embedded in single quotes the parser "create" a VARCHAR using the encoding of the current database, in my case (tempdb just installed)
SELECT DATABASEPROPERTYEX(db_name(), 'Collation')
SQL_Latin1_General_CP1_CI_AS
so the parser converts the string to a VARCHAR(11) COLLATE SQL_Latin1_General_CP1_CI_AS column (11 are the length required), so we have basically a
CAST(N'me‚‚‚abcdef' AS VARCHAR(11)) COLLATE SQL_Latin1_General_CP1_CI_AS
now, continuing executing the initial query:
'me‚‚‚abcdef' COLLATE Latin1_General_100_CI_AS_SC_UTF8
the server tries to convert the query to another collation, using the same type (VARCHAR(11)), so doing a
CAST(<STRING> AS VARCHAR(11)) COLLATE Latin1_General_100_CI_AS_SC_UTF8
that is
CAST(CAST(N'me‚‚‚abcdef' AS VARCHAR(11)) COLLATE SQL_Latin1_General_CP1_CI_AS AS VARCHAR(11)) COLLATE Latin1_General_100_CI_AS_SC_UTF8
which returns our 'me‚‚‚' (as the commas require 3 bytes so 2+3*3 == 11)
Now, let's test this on your last query:
SELECT CONVERT (VARBINARY(MAX), '‚' COLLATE Hebrew_100_CS_AS_SC_UTF8)
should be the same as
SELECT CONVERT (VARBINARY(MAX), CAST(CAST(N'‚' AS VARCHAR(1)) COLLATE Hebrew_100_CS_AS_SC AS VARCHAR(1)) COLLATE Hebrew_100_CS_AS_SC_UTF8)
how to verify that this work? Well, let's try with the string '‚aa'
SELECT CONVERT (VARBINARY(MAX), '‚aa' COLLATE Hebrew_100_CS_AS_SC_UTF8)
converted to
SELECT CONVERT (VARBINARY(MAX), CAST(CAST(N'‚aa' AS VARCHAR(3)) COLLATE Hebrew_100_CS_AS_SC AS VARCHAR(3)) COLLATE Hebrew_100_CS_AS_SC_UTF8)
why '‚aa' ? So there's space to convert the first character to UTF-8, as the second query is doing.
Just as a last verification of my explanation this query
SELECT 'me‚王abcdef' COLLATE Latin1_General_100_CI_AS_SC_UTF8
is returning 'me‚?abcd' this confirms the double conversion and the truncation to VARCHAR(10), 10 bytes to express the source string as Latin1

You could have a try with below to get the complete output:
select cast('me‚‚‚abcdef' as VARCHAR(50)) COLLATE Latin1_General_100_CI_AS_SC_UTF8
CONVERT to VARCHAR first is a good ideas 
In general! Using UTF-8 on English characters can be extremely confusing since UTF-8 is backward compatible with ASCII which mean that it uses the same encoding for the first 128 characters. Therefore, I always recommend to test/demonstrate with other langues.
Moreover, In order to examine the behavior of on-the-fly queries you should configure the database COLLATE since the result can be totally different.
Let's create three databases for example:
CREATE DATABASE HebrewDB COLLATE Hebrew_CI_AS
CREATE DATABASE LatinDB COLLATE SQL_Latin1_General_CP1_CI_AS
CREATE DATABASE UTF8DB COLLATE Hebrew_100_CS_AS_SC_UTF8
GO
Now let's add Hebrew character and Arabic character to the above query:
-- English only: Do not really provide anything
select cast('me‚‚‚abcdef' as VARCHAR(50)) COLLATE Latin1_General_100_CI_AS_SC_UTF8
-- Adding Hebrew and Arabic
select cast(('me‚‚‚abcdef' + ',א' + ',ݰ') as VARCHAR(50)) COLLATE Latin1_General_100_CI_AS_SC_UTF8
GO
Execute the second select will return totally different result in these three databases!
use HebrewDB
select cast(('me‚‚‚abcdef' + ',א' + ',ݰ') as VARCHAR(50)) COLLATE Latin1_General_100_CI_AS_SC_UTF8
GO
USE LatinDB
select cast(('me‚‚‚abcdef' + ',א' + ',ݰ') as VARCHAR(50)) COLLATE Latin1_General_100_CI_AS_SC_UTF8
GO
USE UTF8DB
select cast(('me‚‚‚abcdef' + ',א' + ',ݰ') as VARCHAR(50)) COLLATE Latin1_General_100_CI_AS_SC_UTF8
GO
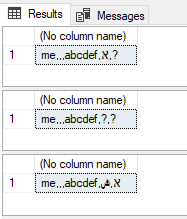
In addition, VERY IMPORTANT! Notice the differences between these queries (try to execute it in the Hebrew Database for example)
select cast(('me‚‚‚abcdef' + ',א' + ',ݰ') as VARCHAR(50)) COLLATE Latin1_General_100_CI_AS_SC_UTF8
select cast(('me‚‚‚abcdef' + ',א' + ',ݰ') COLLATE Latin1_General_100_CI_AS_SC_UTF8 as VARCHAR(50))
select cast((N'me‚‚‚abcdef' + N',א' + N',ݰ') COLLATE Latin1_General_100_CI_AS_SC_UTF8 as VARCHAR(50))
GO
For good/reliable result you should probably use the third option
----------
Good day @Frediano Ziglio
If you want to get first understanding about UTF-8 then you can check my short lecture on UTF-8 from the Microsoft Ignite 2019 (I had the honor to present this feature officially). It is only an introduction and you better search for my 90 minute lecture on the topic (there are versions in Hebrew and in English)
With that being said the link that @MelissaMa-MSFT provided is awesome and explain almost all you need to know.
Regarding your specific case, please publish a full example so we will be able to re-produce the scenario - starting from creating new database using the same COLLATE as your database, which as you can see above might be VERY important. Please explain what is the expected result and we will be able to explain the actual result :-)
Note: UTF-8 mapped the code point "0201" to "ȁ" and not to something that looks like a comma. You can use the function NCHAR and Execute 'SELECT NCHAR(0x201)` to get the result of the mapping or you can use the following link to get all the mapping of UTF-8:
I think you misread, it's 0x201a not 0x201, from your link
U+201A ‚ e2 80 9a SINGLE LOW-9 QUOTATION MARK
and
select nchar(0x201a)
is showing the right character
I think you misread, it's 0x201a not 0x201, from your link
Ops... you are right 
I missed the last char in the code point number. Thanks for the fix
It does not change anything from I said and the information I need in order to help more :-)
The original question is about why a specific query on tempdb produces a truncated result.
All responses here are changing the query. This is not answering the original question, just giving workarounds.
I installed a docker container (using a Fedora 31, I but I don't think it's important) with
docker run -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=MyStrongPassword' -p 1433:1433 -d mcr.microsoft.com/mssql/server:2019-CU6-ubuntu-16.04
(but same with 2019-latest)
Connect, switch to tempdb database (like USE tempdb) and execute a
select 'me‚‚‚abcdef' COLLATE Latin1_General_100_CI_AS_SC_UTF8
(sorry but my original post had multiple lines, I don't know why the formatting was removed).
I hope the question is more clear. Thank you for the documentation links.