Events
Mar 31, 11 PM - Apr 2, 11 PM
The ultimate Microsoft Fabric, Power BI, SQL, and AI community-led event. March 31 to April 2, 2025.
Register todayThis browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
Applies to: ✅ Warehouse in Microsoft Fabric
This article details the strategy, considerations, and methods of migration of data warehousing in Azure Synapse Analytics dedicated SQL pools to Microsoft Fabric Warehouse.
As Microsoft introduced Microsoft Fabric, an all-in-one SaaS analytics solution for enterprises that offers a comprehensive suite of services, including Data Factory, Data Engineering, Data Warehousing, Data Science, Real-Time Intelligence, and Power BI.
This article focuses on options for schema (DDL) migration, database code (DML) migration, and data migration. Microsoft offers several options, and here we discuss each option in detail and provide guidance on which of these options you should consider for your scenario. This article uses the TPC-DS industry benchmark for illustration and performance testing. Your actual result might vary depending on many factors including type of data, data types, width of tables, data source latency, etc.
Carefully plan your migration project before you get started and ensure that your schema, code, and data are compatible with Fabric Warehouse. There are some limitations that you need to consider. Quantify the refactoring work of the incompatible items, as well as any other resources needed before the migration delivery.
Another key goal of planning is to adjust your design to ensure that your solution takes full advantage of the high query performance that Fabric Warehouse is designed to provide. Designing data warehouses for scale introduces unique design patterns, so traditional approaches aren't always the best. Review the Fabric Warehouse performance guidelines, because although some design adjustments can be made after migration, making changes earlier in the process will save you time and effort. Migration from one technology/environment to another is always a major effort.
The following diagram depicts the Migration Lifecycle listing the major pillars consisting of Assess and Evaluate, Plan and Design, Migrate, Monitor and Govern, Optimize and Modernize pillars with the associated tasks in each pillar to plan and prepare for the smooth migration.

Consider the following activities as a planning runbook for your migration from Synapse dedicated SQL pools to Fabric Warehouse.
In general, there are two types of migration scenarios, regardless of the purpose and scope of the planned migration: lift and shift as-is, or a phased approach that incorporates architectural and code changes.
In a lift and shift migration, an existing data model is migrated with minor changes to the new Fabric Warehouse. This approach minimizes risk and migration time by reducing the new work needed to realize the benefits of migration.
Lift and shift migration is a good fit for these scenarios:
In summary, this approach works well for those workloads that is optimized with your current Synapse dedicated SQL pools environment, and therefore doesn't require major changes in Fabric.
If a legacy data warehouse has evolved over a long period of time, you might need to re-engineer it to maintain the required performance levels.
You might also want to redesign the architecture to take advantage of the new engines and features available in the Fabric Workspace.
Consider the following Azure Synapse and Microsoft Fabric data warehousing differences, comparing dedicated SQL pools to the Fabric Warehouse.
When you migrate tables between different environments, typically only the raw data and the metadata physically migrate. Other database elements from the source system, such as indexes, usually aren't migrated because they might be unnecessary or implemented differently in the new environment.
Performance optimizations in the source environment, such as indexes, indicate where you might add performance optimization in a new environment, but now Fabric takes care of that automatically for you.
There are several Data Manipulation Language (DML) syntax differences to be aware of. Refer to T-SQL surface area in Microsoft Fabric. Consider also a code assessment when choosing method(s) of migration for the database code (DML).
Depending on the parity differences at the time of the migration, you might need to rewrite parts of your T-SQL DML code.
There are several data type differences in Fabric Warehouse. For more information, see Data types in Microsoft Fabric.
The following table provides the mapping of supported data types from Synapse dedicated SQL pools to Fabric Warehouse.
| Synapse dedicated SQL pools | Fabric Warehouse |
|---|---|
| money | decimal(19,4) |
| smallmoney | decimal(10,4) |
| smalldatetime | datetime2 |
| datetime | datetime2 |
| nchar | char |
| nvarchar | varchar |
| tinyint | smallint |
| binary | varbinary |
| datetimeoffset* | datetime2 |
* Datetime2 does not store the extra time zone offset information that is stored in. Since the datetimeoffset data type is not currently supported in Fabric Warehouse, the time zone offset data would need to be extracted into a separate column.
Review and identify which of these options fits your scenario, staff skill sets, and the characteristics of your data. The option(s) chosen will depend on your experience, preference, and the benefits from each of the tools. Our goal is to continue to develop migration tools that mitigate friction and manual intervention to make that migration experience seamless.
This table summarizes information for data schema (DDL), database code (DML), and data migration methods. We expand further on each scenario later in this article, linked in the Option column.
| Option Number | Option | What it does | Skill/Preference | Scenario |
|---|---|---|---|---|
| 1 | Data Factory | Schema (DDL) conversion Data extract Data ingestion |
ADF/Pipeline | Simplified all in one schema (DDL) and data migration. Recommended for dimension tables. |
| 2 | Data Factory with partition | Schema (DDL) conversion Data extract Data ingestion |
ADF/Pipeline | Using partitioning options to increase read/write parallelism providing 10x throughput vs option 1, recommended for fact tables. |
| 3 | Data Factory with accelerated code | Schema (DDL) conversion | ADF/Pipeline | Convert and migrate the schema (DDL) first, then use CETAS to extract and COPY/Data Factory to ingest data for optimal overall ingestion performance. |
| 4 | Stored procedures accelerated code | Schema (DDL) conversion Data extract Code assessment |
T-SQL | SQL user using IDE with more granular control over which tasks they want to work on. Use COPY/Data Factory to ingest data. |
| 5 | SQL Database Project extension for Azure Data Studio | Schema (DDL) conversion Data extract Code assessment |
SQL Project | SQL Database Project for deployment with the integration of option 4. Use COPY or Data Factory to ingest data. |
| 6 | CREATE EXTERNAL TABLE AS SELECT (CETAS) | Data extract | T-SQL | Cost effective and high-performance data extract into Azure Data Lake Storage (ADLS) Gen2. Use COPY/Data Factory to ingest data. |
| 7 | Migrate using dbt | Schema (DDL) conversion database code (DML) conversion |
dbt | Existing dbt users can use the dbt Fabric adapter to convert their DDL and DML. You must then migrate data using other options in this table. |
When you're deciding where to start on the Synapse dedicated SQL pool to Fabric Warehouse migration project, choose a workload area where you are able to:
Tip
Create an inventory of objects that need to be migrated, and document the migration process from start to end, so that it can be repeated for other dedicated SQL pools or workloads.
The volume of migrated data in an initial migration should be large enough to demonstrate the capabilities and benefits of the Fabric Warehouse environment, but not too large to quickly demonstrate value. A size in the 1-10 terabyte range is typical.
In this section, we discuss the options using Data Factory for the low-code/no-code persona who are familiar with Azure Data Factory and Synapse Pipeline. This drag and drop UI option provides a simple step to convert the DDL and migrate the data.
Fabric Data Factory can perform the following tasks:
This method uses Data Factory Copy assistant to connect to the source dedicated SQL pool, convert the dedicated SQL pool DDL syntax to Fabric, and copy data to Fabric Warehouse. You can select 1 or more target tables (for TPC-DS dataset there are 22 tables). It generates the ForEach to loop through the list of tables selected in the UI and spawn 22 parallel Copy Activity threads.
staticrc10 to allow a maximum of 32 queries to handle 22 queries submitted.Using the Copy Wizard to generate a ForEach provides simple UI to convert DDL and ingest the selected tables from the dedicated SQL pool to Fabric Warehouse in one step.
However, it isn't optimal with the overall throughput. The requirement to use staging, the need to parallelize read and write for the "Source to Stage" step are the major factors for the performance latency. It's recommended to use this option for dimension tables only.
To address improving the throughput to load larger fact tables using Fabric data pipeline, it's recommended to use Copy Activity for each Fact table with partition option. This provides the best performance with Copy activity.
You have the option of using the source table physical partitioning, if available. If table does not have physical partitioning, you must specify the partition column and supply min/max values to use dynamic partitioning. In the following screenshot, the data pipeline Source options are specifying a dynamic range of partitions based on the ws_sold_date_sk column.
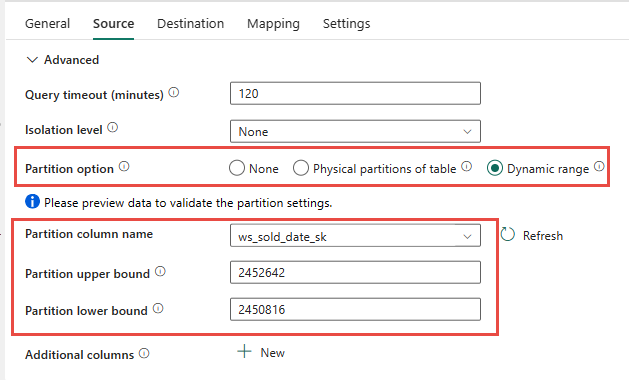
While using partition can increase the throughput with the staging phase, there are considerations to make the appropriate adjustments:
web_sales table, 163 queries were submitted to the dedicated SQL pool. At DWU6000, 128 queries were executed while 35 queries were queued.WHERE [ws_sold_date_sk] > '2451069' AND [ws_sold_date_sk] <= '2451080')
...
WHERE [ws_sold_date_sk] > '2451333' AND [ws_sold_date_sk] <= '2451344')
For fact tables, we recommended using Data Factory with partitioning option to increase throughput.
However, the increased parallelized reads require dedicated SQL pool to scale to higher DWU to allow the extract queries to be executed. Leveraging partitioning, the rate is improved 10x over no partition option. You could increase the DWU to get additional throughput via compute resources, but the dedicated SQL pool has a maximum 128 active queries allow.
Note
For more information on Synapse DWU to Fabric mapping, see Blog: Mapping Azure Synapse dedicated SQL pools to Fabric data warehouse compute.
The two previous options are great data migration options for smaller databases. But if you require higher throughput, we recommend an alternative option:
You can continue to use Data Factory to convert your schema (DDL). Using the Copy Wizard, you can select the specific table or All tables. By design, this migrates the schema and data in one step, extracting the schema without any rows, using the false condition, TOP 0 in the query statement.
The following code sample covers schema (DDL) migration with Data Factory.
You can use Fabric Data Pipelines to easily migrate over your DDL (schemas) for table objects from any source Azure SQL Database or dedicated SQL pool. This data pipeline migrates over the schema (DDL) for the source dedicated SQL pool tables to Fabric Warehouse.
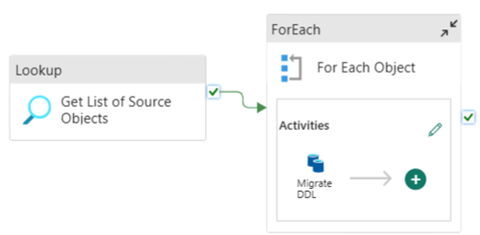
This Data Pipeline accepts a parameter SchemaName, which allows you to specify which schemas to migrate over. The dbo schema is the default.
In the Default value field, enter a comma-delimited list of table schema indicating which schemas to migrate: 'dbo','tpch' to provide two schemas, dbo and tpch.
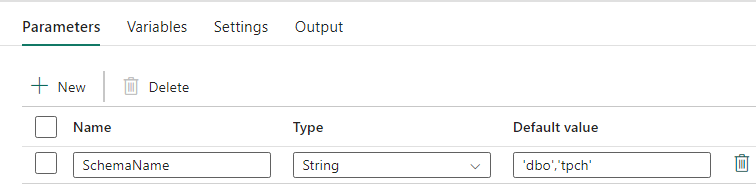
Create a Lookup Activity and set the Connection to point to your source database.
In the Settings tab:
Set Data store type to External.
Connection is your Azure Synapse dedicated SQL pool. Connection type is Azure Synapse Analytics.
Use query is set to Query.
The Query field needs to be built using a dynamic expression, allowing the parameter SchemaName to be used in a query that returns a list of target source tables. Select Query then select Add dynamic content.
This expression within the LookUp Activity generates a SQL statement to query the system views to retrieve a list of schemas and tables. References the SchemaName parameter to allow for filtering on SQL schemas. The Output of this is an Array of SQL schema and tables that will be used as input into the ForEach Activity.
Use the following code to return a list of all user tables with their schema name.
@concat('
SELECT s.name AS SchemaName,
t.name AS TableName
FROM sys.tables AS t
INNER JOIN sys.schemas AS s
ON t.type = ''U''
AND s.schema_id = t.schema_id
AND s.name in (',coalesce(pipeline().parameters.SchemaName, 'dbo'),')
')
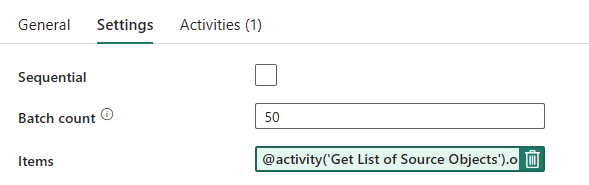
For the ForEach Loop, configure the following options in the Settings tab:
50, limiting the maximum number of concurrent iterations.@activity('Get List of Source Objects').output.value
Inside the ForEach Activity, add a Copy Activity. This method uses the Dynamic Expression Language within Data Pipelines to build a SELECT TOP 0 * FROM <TABLE> to migrate only the schema without data into a Fabric Warehouse.
In the Source tab:
@concat('SELECT TOP 0 * FROM ',item().SchemaName,'.',item().TableName)

In the Destination tab:
@item().SchemaName@item().TableName

For Sink, point to your Warehouse and reference the Source Schema and Table name.
Once you run this pipeline, you'll see your Data Warehouse populated with each table in your source, with the proper schema.
This option uses stored procedures to perform the Fabric Migration.
You can get the code samples at microsoft/fabric-migration on GitHub.com. This code is shared as open source, so feel free to contribute to collaborate and help the community.
What Migration Stored Procedures can do:
This is a great option for those who:
You can execute the specific stored procedure for the schema (DDL) conversion, data extract, or T-SQL code assessment.
For the data migration, you'll need to use either COPY INTO or Data Factory to ingest the data into Fabric Warehouse.
Microsoft Fabric Data Warehouse is supported in the SQL Database Projects extension available inside of Azure Data Studio and Visual Studio Code.
This extension is available inside Azure Data Studio and Visual Studio Code. This feature enables capabilities for source control, database testing and schema validation.
For more information on source control for warehouses in Microsoft Fabric, including Git integration and deployment pipelines, see Source Control with Warehouse.
This is a great option for those who prefer to use SQL Database Project for their deployment. This option essentially integrated the Fabric Migration Stored Procedures into the SQL Database Project to provide a seamless migration experience.
A SQL Database Project can:
For the data migration, you'll then use either COPY INTO or Data Factory to ingest the data into Fabric Warehouse.
Adding to the Azure Data Studio supportability of Microsoft Fabric, the Microsoft Fabric CAT team has provided a set of PowerShell scripts to handle the extraction, creation, and deployment of schema (DDL) and database code (DML) via a SQL Database Project. For a walkthrough of using the SQL Database project with our helpful PowerShell scripts, see microsoft/fabric-migration on GitHub.com.
For more information on SQL Database Projects, see Getting started with the SQL Database Projects extension and Build and Publish a project.
The T-SQL CREATE EXTERNAL TABLE AS SELECT (CETAS) command provides the most cost effective and optimal method to extract data from Synapse dedicated SQL pools to Azure Data Lake Storage (ADLS) Gen2.
What CETAS can do:
The advantages of this option are:
Use CETAS to extract the data to ADLS as Parquet files. Parquet files provide the advantage of efficient data storage with columnar compression that will take less bandwidth to move across the network. Furthermore, since Fabric stored the data as Delta parquet format, data ingestion will be 2.5x faster compared to text file format, since there's no conversion to the Delta format overhead during ingestion.
To increase CETAS throughput:
In this section, we discuss dbt option for those customers who are already using dbt in their current Synapse dedicated SQL pool environment.
What dbt can do:
The dbt framework generates DDL and DML (SQL scripts) on the fly with each execution. With model files expressed in SELECT statements, the DDL/DML can be translated instantly to any target platform by changing the profile (connection string) and the adapter type.
The dbt framework is code-first approach. The data must be migrated by using options listed in this document, such as CETAS or COPY/Data Factory.
The dbt adapter for Microsoft Fabric Data Warehouse allows the existing dbt projects that were targeting different platforms such as Synapse dedicated SQL pools, Snowflake, Databricks, Google Big Query, or Amazon Redshift to be migrated to a Fabric Warehouse with a simple configuration change.
To get started with a dbt project targeting Fabric Warehouse, see Tutorial: Set up dbt for Fabric Data Warehouse. This document also lists an option to move between different warehouses/platforms.
For ingestion into Fabric Warehouse, use COPY INTO or Fabric Data Factory, depending on your preference. Both methods are the recommended and best performing options, as they have equivalent performance throughput, given the prerequisite that the files are already extracted to Azure Data Lake Storage (ADLS) Gen2.
Several factors to note so that you can design your process for maximum performance:
Events
Mar 31, 11 PM - Apr 2, 11 PM
The ultimate Microsoft Fabric, Power BI, SQL, and AI community-led event. March 31 to April 2, 2025.
Register today