Consulta de Apache Hive mediante el controlador JDBC en HDInsight
Aprenda a usar el controlador JDBC desde una aplicación de Java. Para enviar consultas de Apache Hive a Apache Hadoop en Azure HDInsight. La información de este documento muestra cómo conectarse mediante programación y desde el cliente de SQuirreL SQL.
Para obtener más información sobre la interfaz JDBC de Hive, consulte HiveJDBCInterface.
Prerrequisitos
- Un clúster de Hadoop de HDInsight: Para crear uno, vea Introducción a HDInsight de Azure. Asegúrese de que el servicio HiveServer2 está en ejecución.
- Kit para desarrolladores de Java (JDK), versión 11 o posterior.
- SQL SQuirreL. SQuirreL es una aplicación de cliente JDBC.
Cadena de conexión JDBC
Las conexiones de JDBC a un clúster de HDInsight en Azure se realizan a través del puerto 443. El tráfico se protege mediante TLS/SSL. La puerta de enlace pública tras la que se encuentran los clústeres redirige el tráfico al puerto que HiveServer2 escucha. En la siguiente cadena de conexión puede verse el formato que se va a utilizar en HDInsight:
jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2
Reemplace CLUSTERNAME por el nombre del clúster de HDInsight.
Nombre de host en la cadena de conexión
El nombre de host "CLUSTERNAME.azurehdinsight.net" de la cadena de conexión es el mismo que el de la dirección URL del clúster. Puede obtenerlo en Azure Portal.
Puerto de la cadena de conexión
Solo puede usar el puerto 443 para conectarse al clúster desde algunos lugares fuera de la red virtual de Azure. HDInsight es un servicio administrado, lo que significa que todas las conexiones al clúster se administran a través de una puerta de enlace segura. No se puede conectar a HiveServer 2 directamente en los puertos 10001 o 10000. Estos puertos no tienen exposición al exterior.
Authentication
Al establecer la conexión, utilice el nombre y la contraseña de administrador del clúster de HDInsight para realizar la autenticación. En los clientes de JDBC como SQuirreL SQL, escriba el nombre y la contraseña de administrador en la configuración de cliente.
Desde una aplicación de Java, tiene que utilizar el nombre y la contraseña al establecer una conexión. Por ejemplo, el siguiente código Java abre una nueva conexión:
DriverManager.getConnection(connectionString,clusterAdmin,clusterPassword);
Conexión con el cliente SQL SQuirreL
SQL SQuirreL es un cliente JDBC que puede utilizarse para ejecutar consultas de Hive de manera remota con el clúster de HDInsight. En los pasos siguientes se da por hecho que ya ha instalado SQuirreL SQL.
Cree un directorio para que contenga determinados archivos que se van a copiar desde el clúster.
En el siguiente script, reemplace
sshuserpor el nombre de la cuenta de usuario SSH del clúster. ReemplaceCLUSTERNAMEpor el nombre del clúster de HDInsight. Desde una línea de comandos, cambie el directorio de trabajo por el que creó en el paso anterior y escriba el siguiente comando para copiar archivos desde el clúster de HDInsight:scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/log4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . -> scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hadoop-client/{hadoop-auth.jar,hadoop-common.jar,lib/reload4j-*.jar,lib/slf4j-*.jar,lib/curator-*.jar} . scp sshuser@CLUSTERNAME-ssh.azurehdinsight.net:/usr/hdp/current/hive-client/lib/{commons-codec*.jar,commons-logging-*.jar,hive-*-*.jar,httpclient-*.jar,httpcore-*.jar,libfb*.jar,libthrift-*.jar} .Inicie la aplicación SQL SQuirreL. A la izquierda de la ventana, seleccione Drivers (Controladores).

En los iconos de la parte superior del cuadro de diálogo Drivers (Controladores), seleccione el icono + para crear un controlador.
En el cuadro de diálogo Controlador agregado, agregue la siguiente información:
Propiedad Valor Nombre Hive Example URL (URL de ejemplo) jdbc:hive2://localhost:443/default;transportMode=http;ssl=true;httpPath=/hive2Extra Class Path (Ruta de acceso de clase adicional): use el botón Add (Agregar) para agregar todos los archivos .jar que se descargaron anteriormente. Class Name (Nombre de clase) org.apache.hive.jdbc.HiveDriver 
Seleccione Aceptar para guardar la configuración.
En el lado izquierdo de la ventana de SQL SQuirreL, seleccione Aliases. A continuación, seleccione el icono de + para crear un nuevo alias de conexión.
Use los siguientes valores en el cuadro de diálogo Add Alias (Agregar alias).
Propiedad Valor Nombre Hive en HDInsight Controlador Use la lista desplegable para seleccionar el controlador Hive. URL jdbc:hive2://CLUSTERNAME.azurehdinsight.net:443/default;transportMode=http;ssl=true;httpPath=/hive2. Reemplace CLUSTERNAME por el nombre del clúster de HDInsight.Nombre de usuario nombre de la cuenta de inicio de sesión del clúster de HDInsight. El valor predeterminado es admin. Contraseña contraseña para la cuenta de inicio de sesión del clúster. 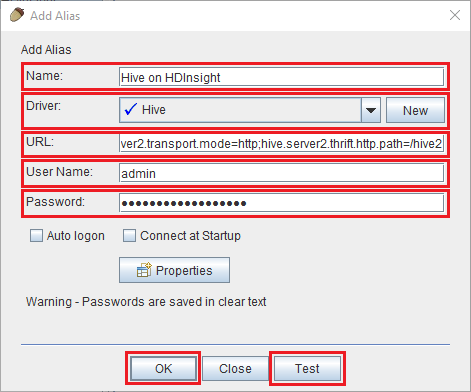
Importante
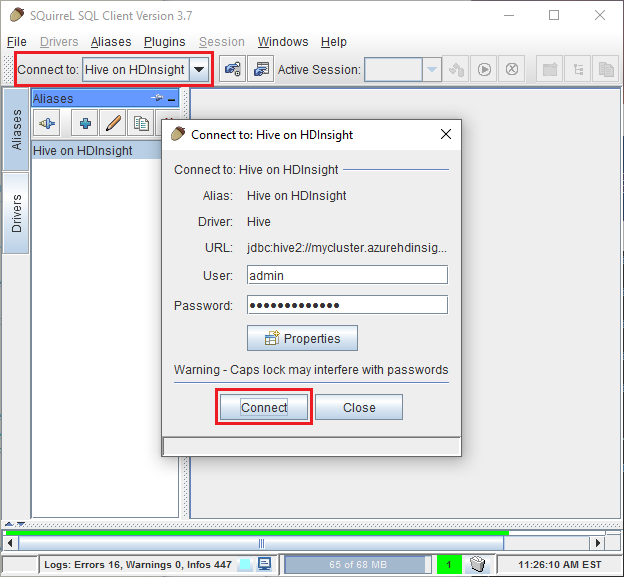
Use el botón Test (Probar) para comprobar que la conexión funciona. Cuando aparezca el cuadro de diálogo Connect to: Hive on HDInsight (Conectarse a: Hive en HDInsight), haga clic en Connect (Conectar) para realizar la prueba. Si la prueba se realiza con éxito, verá un cuadro de diálogo Connection successful (Conexión correcta). Si se produce un error, consulte Solución de problemas.
Use el botón OK (Aceptar) situado en la parte inferior del cuadro de diálogo Add Alias (Agregar alias) para guardar el alias de conexión.
En la lista desplegable Connect to (Conectar a), en la parte superior de SQL SQuirreL, seleccione Hive on HDInsight (Hive en HDInsight). Cuando se le pida, seleccione Connect (Conectar).
Una vez conectado, escriba la siguiente consulta en el cuadro de diálogo de consulta SQL y seleccione el icono Run (Ejecutar) (la persona que lo ejecuta). El área de resultados debe mostrar los resultados de la consulta.
select * from hivesampletable limit 10;
Conexión desde una aplicación de Java de ejemplo
Hay un ejemplo del uso de un cliente de Java para consultar Hive en HDInsight disponible en https://github.com/Azure-Samples/hdinsight-java-hive-jdbc. Siga las instrucciones del repositorio para crear y ejecutar el ejemplo.
Solución de problemas
Error inesperado al intentar abrir una conexión SQL
Síntomas: si se conecta a un clúster de HDInsight con la versión 3.3 o posterior, es posible que reciba un mensaje donde se indique que se produjo un error inesperado. Se iniciará el seguimiento de la pila para este error con las siguientes líneas:
java.util.concurrent.ExecutionException: java.lang.RuntimeException: java.lang.NoSuchMethodError: org.apache.commons.codec.binary.Base64.<init>(I)V
at java.util.concurrent.FutureTas...(FutureTask.java:122)
at java.util.concurrent.FutureTask.get(FutureTask.java:206)
Causa: este error lo causa un archivo commons-codec.jar de una versión anterior que está incluido en SQuirreL.
Solución: para corregir este error, siga estos pasos:
Salga de SQuirreL y vaya al directorio donde está instalado SQuirreL en el sistema, por ejemplo,
C:\Program Files\squirrel-sql-4.0.0\lib. En el directorio de SQuirreL, bajo el directoriolib, reemplace el archivo commons-codec.jar existente por el descargado desde el clúster de HDInsight.Reinicie SQuirreL. El error ya no debería ocurrir al conectarse a Hive en HDInsight.
Conexión desconectada por HDInsight
Síntomas: HDInsight desconecta inesperadamente la conexión al intentar descargar una gran cantidad de datos (por ejemplo, varios GB) mediante JDBC/ODBC.
Causa: la limitación en los nodos de puerta de enlace provoca este error. Al obtener datos de JDBC u ODBC, todos los datos deben pasar por el nodo de puerta de enlace. Sin embargo, una puerta de enlace no está diseñada para descargar una gran cantidad de datos, por lo que podría cerrar la conexión si no puede administrar el tráfico.
Solución: evite el uso del controlador JDBC u ODBC para descargar grandes cantidades de datos. En su lugar, copie los datos directamente del almacenamiento de blobs.
Pasos siguientes
Ahora que aprendió a usar JDBC para que funcione con Hive, utilice los siguientes vínculos para explorar otras formas de trabajar con Azure HDInsight.
- Visualización de datos de Apache Hive con Microsoft Power BI en Azure HDInsight.
- Visualización de datos de Interactive Query Hive con Power BI en Azure HDInsight.
- Conexión de Excel a Hadoop en Azure HDInsight con Microsoft Hive ODBC Driver.
- Conexión de Excel a Apache Hadoop con Power Query.
- Uso de Apache Hive con HDInsight
- Uso de Apache Pig con HDInsight
- Uso de trabajos de MapReduce con HDInsight