Creación de un índice en Azure AI Search
En este artículo se describen los pasos para definir un esquema para un índice de búsqueda y para insertarlo en un servicio de búsqueda. Al crearse un índice, se establece la estructura de datos física en el servicio de búsqueda. Una vez que el índice existe, cargue el índice como una tarea independiente.
Requisitos previos
Permisos de escritura como colaborador del servicio de búsqueda o clave de API de administración para la autenticación basada en claves.
Reconocimiento de los datos que desee indexar. Un índice de búsqueda se basa en el contenido externo en el que quiere realizar búsquedas. El contenido que admite búsquedas se almacena como campos en un índice. Debe tener una idea clara de los campos de origen que quiere que se puedan buscar, recuperar, filtrar, clasificar y ordenar en Búsqueda de Azure AI. Puede consultar una guía de instrucciones en la lista de comprobación del esquema.
También debe tener un campo único en los datos de origen que se puede usar como clave de documento (o identificador) en el índice.
Una ubicación de índice estable. No se admite el traslado de un índice existente a otro servicio de búsqueda de forma inmediata. Examine los requisitos de la aplicación y asegúrese de que el servicio de búsqueda existente (con su capacidad y región) cubre sus necesidades. Si está tomando una dependencia de los servicios de Azure AI o Azure OpenAI, elija una región que proporcione todos los recursos necesarios.
Por último, todos los niveles de servicio tiene límites de índice en el número de objetos que se pueden crear. Por ejemplo, si está experimentando en el nivel Gratis, solo puede tener tres índices en un momento dado. Dentro del propio índice, hay límites de vectores y límites de índice en el número de campos simples y complejos.
Claves de documento
La creación de índices de búsqueda tiene dos requisitos: un índice debe tener un nombre único en el servicio de búsqueda y debe tener una clave de documento. El atributo booleano key de un campo se puede establecer en true para indicar qué campo proporciona la clave del documento.
Una clave de documento es el identificador único de un documento de búsqueda, y un documento de búsqueda es una colección de campos que describe completamente algo. Por ejemplo, si va a indexar un conjunto de datos de películas, un documento de búsqueda contiene el título, el género y la duración de una sola película. Los nombres de las películas son únicos en este conjunto de datos, por lo que puede utilizar el nombre de la película como clave del documento.
En Búsqueda de Azure AI, una clave de documento es una cadena y debe originarse a partir de valores únicos en el origen de datos que proporcione el contenido que se va a indexar. Como regla general, los servicios de búsqueda no generan valores de clave, pero en algunos escenarios (como el indexador de tablas de Azure) sintetizan los valores existentes para crear una clave única para los documentos que se van a indexar. Otro escenario es la indexación uno a muchos para datos divididos en trozos o particiones, en cuyo caso se generan claves de documento para cada trozo.
Durante la indexación incremental, donde se indexa el contenido nuevo y el actualizado, se agregan los documentos entrantes con nuevas claves, mientras que los documentos entrantes con claves existentes se combinan o se sobrescriben, en función de si los campos de índice son nulos o se han rellenado.
Entre los puntos importantes sobre las claves de documento se incluyen:
- La longitud máxima de los valores de un campo de clave es de 1,024 caracteres.
- Se debe elegir exactamente un campo de nivel superior en cada índice como campo clave y debe ser de tipo
Edm.String. - El valor predeterminado del
keyatributo es false para los campos simples y null para los campos complejos.
Los campos clave se pueden usar para buscar documentos directamente y actualizar o eliminar documentos específicos. Los valores de los campos clave se controlan de forma que distingue mayúsculas de minúsculas al buscar o indexar documentos. Para más información, consulte GET Document (REST) y Index Documents (REST)..
Lista de comprobación de esquema
Use esta lista de comprobación como ayuda para la toma de decisiones de diseño para el índice de búsqueda.
Revise las convenciones de nomenclatura para que los nombres de índice y campo se ajusten a las reglas de nomenclatura.
Consulte los tipos de datos admitidos. El tipo de datos afectará a cómo se usa el campo. Por ejemplo, el contenido numérico se puede filtrar, pero no se puede buscar el texto completo. El tipo de datos más común es
Edm.Stringpara el texto que permite búsquedas, que se tokeniza y consulta mediante el motor de búsqueda de texto completo. El tipo de datos más común para un campo vectorial esEdm.Single, pero también puede usar otros tipos.Identifique una clave de documento. Una clave de documento es un requisito del índice. Es un campo con una sola cadena rellenado a partir de un campo de datos de origen que contiene valores únicos. Por ejemplo, si va a indexar desde Blob Storage, la ruta de acceso del almacenamiento de los metadatos se usa a menudo como clave de documento, ya que identifica de forma única cada uno de los blobs del contenedor.
Identifique los campos del origen de datos que aportan contenido que permite realizar búsquedas en el índice.
El contenido no vectorial que permite búsquedas incluye cadenas cortas o largas que se consultan mediante el motor de búsqueda de texto completo. Si el contenido es detallado (frases pequeñas o fragmentos más grandes), experimente con diferentes analizadores para ver cómo se tokeniza el texto.
El contenido vectorial que permite búsquedas puede ser imágenes o texto (en cualquier idioma) que existe como una representación matemática. Puede usar tipos de datos estrechos o compresión vectorial para reducir el tamaño de los campos vectoriales.
Atributos establecidos en campos, como
retrievableofilterable, determinan tanto los comportamientos de búsqueda como la representación física del índice en el servicio de búsqueda. Determinar cómo deben atribuirse los campos es un proceso iterativo para muchos desarrolladores. Para acelerar las iteraciones, comience con datos de ejemplo para que pueda anular y recompilar fácilmente.Identifique qué campos de origen se pueden usar como filtros. El contenido numérico y los campos de texto corto, especialmente los que tienen valores repetidos, son buenas opciones. Al trabajar con filtros, recuerde:
Los filtros se pueden usar en consultas vectoriales y no vectoriales, pero el propio filtro se aplica a los campos alfanuméricos (no vectoriales) en el índice.
Opcionalmente, los campos filtrables se pueden usar en la navegación por facetas.
Los campos filtrables se devuelven en orden arbitrario y no se someten a una puntuación de relevancia, por lo que considere la posibilidad de ordenarlos también.
En el caso de los campos vectoriales, especifique una configuración de búsqueda vectorial y los algoritmos usados para crear rutas de navegación y rellene el espacio de inserción. Para obtener más información, vea Adición de campos vectoriales.
Los campos vectoriales tienen propiedades adicionales que no tienen los campos no vectoriales, como los algoritmos que se van a usar y la compresión vectorial.
Los campos vectoriales omiten los atributos que no son útiles en los datos vectoriales, como la ordenación, el filtrado y la aplicación de facetas.
En el caso de los campos no vectoriales, determine si se debe usar el analizador predeterminado (
"analyzer": null) u otro. Los analizadores se usan para tokenizar campos de texto durante la indexación y la ejecución de consultas.En el caso de las cadenas multilingües, considere la posibilidad de usar un analizador de idioma.
Para cadenas con guiones o caracteres especiales, considere la posibilidad de analizadores especializados. Un ejemplo es el analizador por palabra clave, que trata el contenido de un campo como token único. Esto comportamiento es útil para datos como códigos postales, identificadores y algunos nombres de producto. Para más información, consulte Búsqueda de términos parciales y patrones con caracteres especiales.
Nota:
La búsqueda de texto completo se realiza mediante términos que se tokenizan durante la indexación. Si las consultas no devuelven los resultados esperados, pruebe la tokenización para comprobar que la cadena que está buscando realmente existe. Puede probar diferentes analizadores en las cadenas para ver cómo se generan los tokens para varios analizadores.
Configurar definiciones de campo
La colección de campos define la estructura de un documento de búsqueda. Todos los campos tienen un nombre, un tipo de datos y atributos.
Establecer un campo como consultable, filtrable, ordenable o facetable tiene un efecto sobre el tamaño del índice y el rendimiento de la consulta. No establezca esos atributos en campos que no están destinados a ser referenciados en expresiones de consulta.
Si no se establece que un campo sea buscable, filtrable, clasificable o facetable, no se puede hacer referencia al campo en ninguna expresión de consulta. Esto es conveniente para los campos que no se utilizan en las consultas, pero son necesarios en los resultados de búsqueda.
Las API REST tienen atribución predeterminada en función de los tipos de datos, que también usan los asistentes para importación en Azure Portal. Los SDK de Azure no tienen valores predeterminados, pero tienen subclases de campo que incorporan propiedades y comportamientos, como SearchableField para cadenas y SimpleField para primitivos.
Las atribución de campo predeterminadas para las API REST se resumen en la tabla siguiente.
| Tipo de datos | Se puede buscar | Retrievable | Filtrable | Clasificable | Ordenable | Almacenar |
|---|---|---|---|---|---|---|
Edm.String |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.String) |
✅ | ✅ | ✅ | ✅ | ❌ | ✅ |
Edm.Boolean |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.Int32, Edm.Int64, Edm.Double |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.DateTimeOffset |
❌ | ✅ | ✅ | ✅ | ✅ | ✅ |
Edm.GeographyPoint |
✅ | ✅ | ✅ | ❌ | ✅ | ✅ |
Edm.ComplexType |
✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
Collection(Edm.Single) y todos los demás tipos de campos vectoriales |
✅ | ✅ o ❌ | ❌ | ❌ | ❌ | ✅ |
Los campos de cadena también se pueden asociar opcionalmente a analizadores y mapas de sinónimos. Los campos de tipo Edm.String que son filtrables, ordenables, o facetable pueden tener como máximo 32 kilobytes de longitud. Esto se debe a que los valores de estos campos se tratan como un único término de búsqueda y la longitud máxima de un término en Azure AI Search es de 32 kilobytes. Si necesita almacenar más texto que éste en un único campo de cadena, debe establecer explícitamente filterable, ordenable y facetable false en la definición de índice.
Los campos vectoriales deben estar asociados a dimensiones y perfiles vectoriales. El valor predeterminado recuperable es true si agrega el campo vectorial mediante el Asistente para importación y vectorización en el portal; de lo contrario, es false si usa la API REST.
Los atributos de campo se describen en la tabla siguiente.
| Atributo | Description |
|---|---|
| name | Obligatorio. Establece el nombre del campo, que debe ser único dentro de la colección fields del índice o del campo primario. |
| type | Necesario. Establece el tipo de datos del campo. Los campos pueden ser simples o complejos. Los campos simples son de tipos primitivos, como Edm.String para texto o Edm.Int32 para enteros. Los campos complejos pueden tener subprocesos que son simples o complejos. Esto le permite modelar objetos y matrices de objetos, lo que a su vez le permite cargar la mayoría de las estructuras de objetos JSON en su índice. Consulte Tipos de datos admitidos para obtener la lista completa de tipos admitidos. |
| key | Necesario. Establezca este atributo en true para designar que los valores de un campo identifican de forma única documentos en el índice. Consulte Claves de documento en este artículo para obtener más información. |
| retrievable | Indica si el campo se puede devolver en un resultado de búsqueda. Establezca este atributo false en si desea usar un campo como filtro, ordenación o mecanismo de puntuación, pero no quiere que el campo sea visible para el usuario final. Este atributo debe ser true para los campos clave y debe ser null para campos complejos. Este atributo se puede cambiar en campos existentes. La configuración de recuperable en true no provoca ningún aumento en los requisitos de almacenamiento de índices. El valor predeterminado es true para campos simples y null para campos complejos. |
| searchable | Indica si el campo permite realizar búsquedas de texto completo y si se puede hacer referencia a él en las consultas de búsqueda. Esto significa que se somete a un análisis léxico, como la separación de palabras durante la indexación. Si establece un campo buscable en un valor como "día soleado", internamente se normaliza en los tokens individuales "soleado" y "día". Esto permite realizar búsquedas de texto completo de estos términos. Los campos de tipo Edm.String o Collection(Edm.String) se pueden buscar de forma predeterminada. Este atributo debe ser false para campos simples de otros tipos de datos que no son de cadena y debe ser null para campos complejos. Un campo de búsqueda consume espacio adicional en su índice, ya que Búsqueda de Azure AI procesa el contenido de esos campos y los organiza en estructuras de datos auxiliares para realizar búsquedas. Si desea ahorrar espacio en el índice y no necesita incluir un campo en las búsquedas, establecer la búsqueda en false. Consulte Funcionamiento de la búsqueda de texto completo en Azure AI Search para más información. |
| filterable | Indica si se debe hacer referencia al campo en $filter las consultas. Filterable difiere de lo que se puede buscar en la forma en que se controlan las cadenas. Los campos de tipo Edm.String o Collection(Edm.String) que son filtrables no se someten a análisis léxico, por lo que las comparaciones son solo para coincidencias exactas. Por ejemplo, si establece un campo de este tipo en f "día soleado", $filter=f eq 'sunny' no encontrará ninguna coincidencia, pero $filter=f eq 'Sunny day' lo hará. Este atributo debe ser null para campos complejos. El valor predeterminado es true para campos simples y null para campos complejos. Para reducir el tamaño del índice, establezca este atributo false en campos en los que no se filtrará. |
| sortable | Indica si se debe hacer referencia al campo en $orderby expresiones. De forma predeterminada, Azure AI Search ordena los resultados por puntuación, pero en muchas experiencias los usuarios quieren ordenar por campos de los documentos. Un campo simple sólo puede ordenarse si es de valor único (tiene un único valor en el ámbito del documento primario). Los campos de colección simples no se pueden ordenar, ya que son multivalor. Los subcampos simples de colecciones complejas también son multivalor y, por tanto, no se pueden ordenar. Esto es cierto si es un campo primario inmediato o un campo antecesor, que es la colección compleja. Los campos complejos no se pueden ordenar y el atributo ordenable debe ser null para estos campos. El valor predeterminado para ordenar es true para campos simples con valores únicos, false para campos simples con varios valores y null para campos complejos. |
| facetable | Indica si se debe hacer referencia al campo en las consultas de facetas. Suele utilizarse en una presentación de resultados de búsqueda que incluya el número de resultados por categoría (por ejemplo, busque cámaras digitales y consulte los resultados divididos por marca, por megapíxeles, por precio, etc.). Este atributo debe ser null para campos complejos. Los campos de tipo Edm.GeographyPoint o Collection(Edm.GeographyPoint) no pueden ser facetables. El valor predeterminado es true para todos los demás campos simples. Para reducir el tamaño del índice, establezca este atributo false en los campos en los que no se va a facetar. |
| analizador | Establece el analizador léxico para tokenizar cadenas durante las operaciones de indexación y consulta. Los valores válidos para esta propiedad incluyen analizadores de lenguaje, analizadores integrados, y analizadores personalizados. El valor predeterminado es standard.lucene. Este atributo sólo se puede utilizar con campos de cadena en los que se puedan realizar búsquedas, y no se puede establecer junto con searchAnalyzer o indexAnalyzer. Una vez elegido el analizador y creado el campo en el índice, no se puede cambiar para el campo. Debe ser null para campos complejos. |
| searchAnalyzer | Establezca esta propiedad junto con indexAnalyzer para especificar diferentes analizadores léxicos para la indexación y las consultas. Si usa esta propiedad, establezca analyzer en null y asegúrese de que indexAnalyzer está establecido en un valor permitido. Los valores válidos para esta propiedad incluyen analizadores integrados y analizadores personalizados. Este atributo solo se puede usar con campos que se pueden buscar. El analizador de búsqueda se puede actualizar en un campo existente, ya que solo se usa en tiempo de consulta. Debe ser null para campos complejos]. |
| indexAnalyzer | Establezca esta propiedad junto con searchAnalyzer para especificar diferentes analizadores léxicos para la indexación y las consultas. Si usa esta propiedad, establezca analyzer en null y asegúrese de que searchAnalyzer está establecido en un valor permitido. Los valores válidos para esta propiedad incluyen analizadores integrados y analizadores personalizados. Este atributo solo se puede usar con campos que se pueden buscar. Una vez elegido el analizador de índices, no se puede cambiar para el campo. Debe ser null para campos complejos. |
| synonymMaps | Lista de los nombres de los mapas de sinónimos que se van a asociar a este campo. Este atributo solo se puede usar con campos que se pueden buscar. Actualmente solo se admite un mapa de sinónimos por campo. La asignación de un mapa de sinónimos a un campo garantiza que los términos de consulta dirigidos a ese campo se expandan en el momento de la consulta utilizando las reglas del mapa de sinónimos. Este atributo se puede cambiar en campos existentes. Debe ser null o una colección vacía para campos complejos. |
| fields | Lista de subcampos si se trata de un campo de tipo Edm.ComplexType o Collection(Edm.ComplexType). Debe estar null o estar vacío para campos simples. Consulte Modelado de tipos de datos complejos en Azure AI Search para obtener más información sobre cómo y cuándo usar subcampos. |
Creación de un índice
Cuando esté listo para crear el índice, use un cliente de búsqueda que pueda enviar la solicitud. Puede usar Azure Portal o las API REST para realizar las primeras pruebas de desarrollo y de prueba de concepto; de lo contrario, es habitual usar los SDK de Azure.
Durante el desarrollo, haga planes para realizar recompilaciones con frecuencia. Como se crean estructuras físicas en el servicio, la mayoría de las modificaciones realizadas requieren anular los índices y volverlos a crear. Considere la posibilidad de trabajar con un subconjunto de los datos para asegurarse de que las recompilaciones van más rápido.
El diseño de índices a través del portal aplica ciertos requisitos y reglas de esquema para tipos de datos específicos, como no permitir funciones de búsqueda de texto completo en campos numéricos.
Inicie sesión en Azure Portal.
Compruebe si hay espacio. Los servicios de búsqueda están sujetos a un número máximo de índices, que varía según el nivel de servicio. Asegúrese de que tiene espacio para un segundo índice.
En la página Información general del servicio de búsqueda, elija cualquiera de las opciones para crear un índice de búsqueda:
- Agregar índice, un editor incrustado para especificar un esquema de índice
- Asistentes para la importación
El asistente es un flujo de trabajo de un extremo a otro que crea un indexador, un origen de datos y un índice terminado. También carga los datos. Si esto es más de lo que desea, use Agregar índice en su lugar.
En la captura de pantalla siguiente se resalta dónde aparecen las opciones Agregar índice, Importar datos e Importar y vectorizar datos en la barra de comandos.
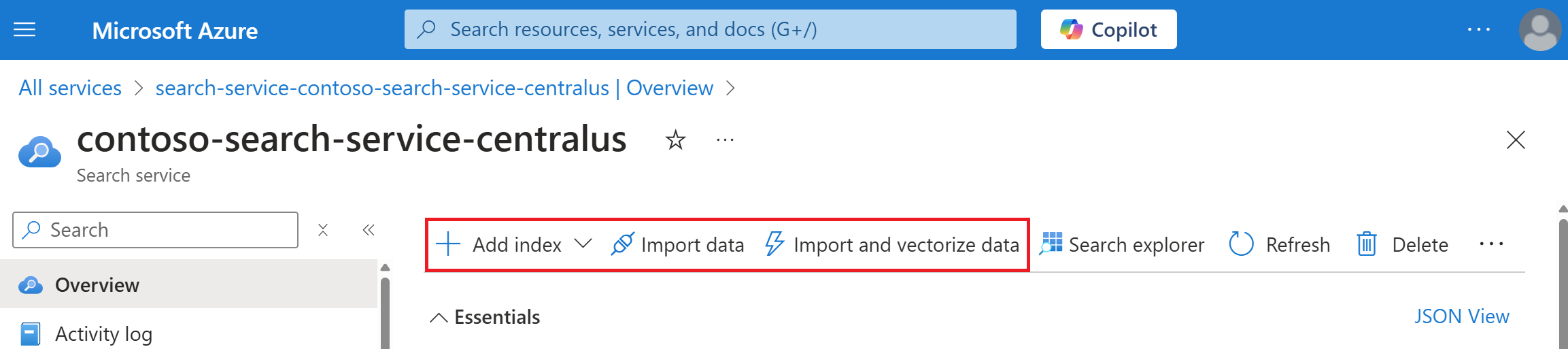
Una vez creado un índice, puede volver a encontrarlo en la página Índices desde el panel de navegación izquierdo.
Sugerencia
Después de crear un índice en el portal, puede copiar la representación JSON y agregarla al código de la aplicación.
Establecer corsOptions para las consultas entre orígenes
Los esquemas de índice incluyen una sección para establecer corsOptions. De forma predeterminada, JavaScript del lado cliente no puede llamar a ninguna API porque los exploradores impiden todas las solicitudes entre orígenes. Para permitir que se realicen consultas de origen cruzado al índice, habilite CORS (uso compartido de recursos entre orígenes) estableciendo el atributo corsOptions. Por motivos de seguridad, solamente las API de consulta admiten CORS.
"corsOptions": {
"allowedOrigins": [
"*"
],
"maxAgeInSeconds": 300
Es posible establecer para CORS las siguientes propiedades:
allowedOrigins (obligatorio): se trata de una lista de orígenes a los que se les concede acceso a su índice. El código JavaScript servido desde estos orígenes puede consultar el índice (suponiendo que el autor de la llamada proporcione una clave válida o tenga permisos). Cada origen tiene normalmente el formato
protocol://<fully-qualified-domain-name>:<port>aunque<port>se omite a menudo. Para obtener más información, consulte Uso compartido de recursos entre orígenes (Wikipedia).Si desea permitir el acceso a todos los orígenes, incluya
*como elemento único en la matriz allowedOrigins. Esta práctica no es recomendable para los servicios de búsqueda de producción, pero a menudo resulta útil para el desarrollo y la depuración.maxAgeInSeconds (opcional): los exploradores usan este valor para determinar la duración (en segundos) para almacenar en la memoria caché las respuestas preparatorias de CORS. Esto debe ser un entero no negativo. Un período de caché más largo ofrece un mejor rendimiento, pero amplía la cantidad de tiempo que requiere una directiva de CORS para surtir efecto. Si no se establece este valor, se aplica una duración predeterminada de cinco minutos.
Actualizaciones permitidas en índices existentes
Crear índice crea las estructuras de datos físicos (archivos e índices invertidos) en el servicio de búsqueda. Una vez creado el índice, la capacidad de realizar cambios mediante la opción Crear o Actualizar índice depende de si la modificación invalida esas estructuras físicas. La mayoría de los atributos de campo no se pueden cambiar una vez creado el campo en el índice.
Para minimizar la renovación en el código de aplicación, puede crear un alias de índice que actúe como referencia estable al índice de búsqueda. En lugar de actualizar el código con nombres de índice, puede actualizar un alias de índice para que apunte a versiones de índice más recientes.
Para minimizar el abandono en el proceso de diseño, en la tabla siguiente se describen qué elementos son fijos y flexibles en el esquema. El cambio de un elemento fijo requiere una recompilación del índice, mientras que los elementos flexibles se pueden cambiar en cualquier momento sin afectar a la implementación física. Para obtener más información, consulte Actualización o recompilación de un índice.
| Elemento | ¿Se puede actualizar? |
|---|---|
| Nombre | No |
| Clave | No |
| Tipos y nombres de campo | No |
| Atributos de campo (que se puedan buscar, filtrar, clasificar, ordenar) | No |
| Atributo de campo (recuperable) | Sí |
| Almacenado (se aplica a los vectores) | No |
| Analyzer | Puede agregar y modificar analizadores personalizados en el índice. Con respecto a las asignaciones de analizador en campos de cadena, solo puede modificar searchAnalyzer. Todas las demás asignaciones y modificaciones requieren una recompilación. |
| Perfiles de puntuación | Sí |
| Proveedores de sugerencias | No |
| Uso compartido de recursos entre orígenes (CORS) | Sí |
| Cifrado | Sí |
| Mapas de sinónimos | Sí |
| Configuración semántica | Sí |
Pasos siguientes
Use los vínculos siguientes para obtener información sobre las características especializadas que se pueden agregar a un índice:
- Adición de campos vectoriales y perfiles de vector
- Adición de perfiles de puntuación
- Agregar clasificación semántica
- Agregar proveedores de sugerencias
- Agregar asignaciones de sinónimos
- Adición de analizadores
- Agregar cifrado
Use estos vínculos para cargar o actualizar un índice: