Uso de la propagación automática para inicializar una réplica secundaria para un grupo de disponibilidad Always On
Se aplica a: ![]() SQL Server
SQL Server
En SQL Server 2012 y 2014, la única manera de inicializar una réplica secundaria en un grupo de disponibilidad AlwaysOn de SQL Server es recurriendo a los trabajos de copia de seguridad, copia y restauración. SQL Server 2016 incorpora una característica nueva para inicializar una réplica secundaria: la propagación automática. La propagación automática emplea el transporte de secuencia de registro para transmitir la copia de seguridad con VDI a la réplica secundaria de cada base de datos del grupo de disponibilidad que use los puntos de conexión configurados. Esta nueva característica se puede usar durante la creación inicial de un grupo de disponibilidad o cuando una base de datos se agrega a uno de estos grupos. La propagación automática se incluye en todas las ediciones de SQL Server que admiten grupos de disponibilidad AlwaysOn, y se puede usar tanto con los grupos de disponibilidad tradicionales como con los grupos de disponibilidad distribuidos.
Seguridad
Los permisos de seguridad varían según el tipo de réplica que se esté inicializando:
- Si es un grupo de disponibilidad tradicional, el grupo de disponibilidad en la réplica secundaria debe tener concedidos permisos, ya que está unido al grupo de disponibilidad. En Transact-SQL, use el comando
ALTER AVAILABILITY GROUP [<AGName>] GRANT CREATE ANY DATABASE. - En el caso de un grupo de disponibilidad distribuido, en el que las bases de datos de la réplica que se van a crear se encuentran en la réplica principal del segundo grupo de disponibilidad, no se requiere ningún permiso adicional, dado que ya es un elemento principal. Sin embargo, si solo hay una réplica en el segundo grupo de disponibilidad, conceda el permiso
CREATE ANY DATABASEal nombre del grupo de disponibilidad secundario o se puede producir un error en la propagación automática. - En el caso de una réplica secundaria en el segundo grupo de disponibilidad de un grupo de disponibilidad distribuido, debe usar el comando
ALTER AVAILABILITY GROUP [<2ndAGName>] GRANT CREATE ANY DATABASE. Esta réplica secundaria se propagará desde el elemento principal del segundo grupo de disponibilidad.
Impacto en el rendimiento y el registro de transacciones de la réplica principal
La propagación automática puede ser o no práctica a la hora de inicializar una réplica secundaria, según cuál sea el tamaño de la base de datos, la velocidad de red y la distancia entre las réplicas principales y las secundarias. Por ejemplo, dado:
- El tamaño de la base de datos es de 5 TB.
- La velocidad de red es de 1 Gb/s.
- La distancia entre los dos sitios es de 1000 millas.
Si está disponible el ancho de banda completo, una red de 1 GB por segundo puede proporcionar un rendimiento sostenido de 125 MB por segundo. En este ejemplo, la propagación automática podría tardar tan solo alrededor de 11 horas. En la práctica, el proceso de propagación automática es un más lento, dado que las señales de red se deterioran cuando las distancias son largas y el vínculo se comparte con otros recursos de la red. Durante la propagación, el registro de transacciones en la base de datos de la réplica principal continuará creciendo y no se podrá truncar hasta que la propagación automática de esa base de datos se complete. Cuando esto suceda, el registro de transacciones se puede truncar usando una copia de seguridad del registro de transacciones.
La propagación automática es un proceso de un único subproceso que puede asumir hasta cinco bases de datos. El subproceso único puede afectar al rendimiento, especialmente si el grupo de disponibilidad tiene más de una base de datos.
La compresión se puede usar en la propagación automática, pero está deshabilitada de forma predeterminada. Si la compresión se activa, se reducirá el ancho de banda de red y, posiblemente, el proceso se acelere, pero a cambio habrá una mayor sobrecarga del procesador. Para usar la compresión durante la propagación automática, habilite la marca de seguimiento 9567; vea Tune compression for availability group (Optimizar la compresión para los grupos de disponibilidad).
Diseño de disco
En SQL Server 2016 y versiones anteriores, la carpeta donde se creará la base de datos mediante la propagación automática ya debe existir y ser la misma que la ruta de acceso de la réplica principal.
En SQL Server 2017, Microsoft recomienda el uso de los mismos datos y la misma ruta del archivo de registro en todas las réplicas que participan en un grupo de disponibilidad, pero puede usar rutas diferentes si es necesario. Por ejemplo, en un grupo de disponibilidad multiplataforma, una instancia de SQL Server se ejecuta en Windows, mientras que la otra lo hace en Linux. Cada plataforma tiene una ruta predeterminada diferente. SQL Server 2017 admite réplicas de grupos de disponibilidad en instancias de SQL Server con rutas diferentes.
En la tabla siguiente se presentan ejemplos de diseños de disco de datos admitidos que permiten la propagación automática:
| Instancia principal Ruta de acceso de datos predeterminada |
Instancia secundaria Ruta de acceso de datos predeterminada |
Instancia principal Ubicación del archivo de origen |
Instancia secundaria Ubicación del archivo de origen |
|---|---|---|---|
| c:\data\ | /var/opt/mssql/data/ | c:\data\ | /var/opt/mssql/data/ |
| c:\data\ | /var/opt/mssql/data/ | c:\data\group1\ | /var/opt/mssql/data/group1/ |
| c:\data\ | d:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | d:\data\group1\ |
Los escenarios en los que la ubicación de la base de datos de la réplica principal y las réplicas secundarias no sea la ruta predeterminada de la instancia no se verán afectados. Los requisitos para que las rutas de archivo de las réplicas secundarias coincidan con la ruta de archivo de la réplica principal siguen siendo los mismos.
| Instancia principal Ruta de acceso de datos predeterminada |
Instancia secundaria Ruta de acceso de datos predeterminada |
Instancia principal Ubicación de archivos |
Instancia secundaria Ubicación de archivos |
|---|---|---|---|
| c:\data\ | c:\data\ | d:\group1\ | d:\group1\ |
| c:\data\ | c:\data\ | d:\data\ | d:\data\ |
| c:\data\ | c:\data\ | d:\data\group1\ | d:\data\group1\ |
Si mezcla rutas predeterminadas con rutas que no lo sean en la réplica principal y las réplicas secundarias, SQL Server 2017 no tendrá el mismo comportamiento que en versiones anteriores. En la tabla siguiente se muestra el comportamiento de SQL Server 2017.
| Instancia principal Ruta de acceso de datos predeterminada |
Instancia secundaria Ruta de acceso de datos predeterminada |
Instancia principal Ubicación de archivos |
SQL Server 2016 Instancia secundaria Ubicación de archivos |
SQL Server 2017 Instancia secundaria Ubicación de archivos |
|---|---|---|---|---|
| c:\data\ | d:\data\ | c:\data\ | c:\data\ | d:\data\ |
| c:\data\ | d:\data\ | c:\data\group1\ | c:\data\group1\ | d:\data\group1\ |
Para revertir el comportamiento de SQL Server 2016 y versión anteriores, habilite la marca de seguimiento 9571. Para obtener información sobre cómo habilitar marcas de seguimiento, consulte DBCC TRACEON (Transact-SQL).
Crear un grupo de disponibilidad con propagación automática
Puede crear un grupo de disponibilidad a través de la propagación automática con Transact-SQL o SQL Server Management Studio (SSMS, versión 17 o posterior). Para usar el Asistente para grupo de disponibilidad en SSMS, siga estas instrucciones; cuando llegue al paso 9, verá la propagación automática como la primera opción (además de ser la predeterminada).
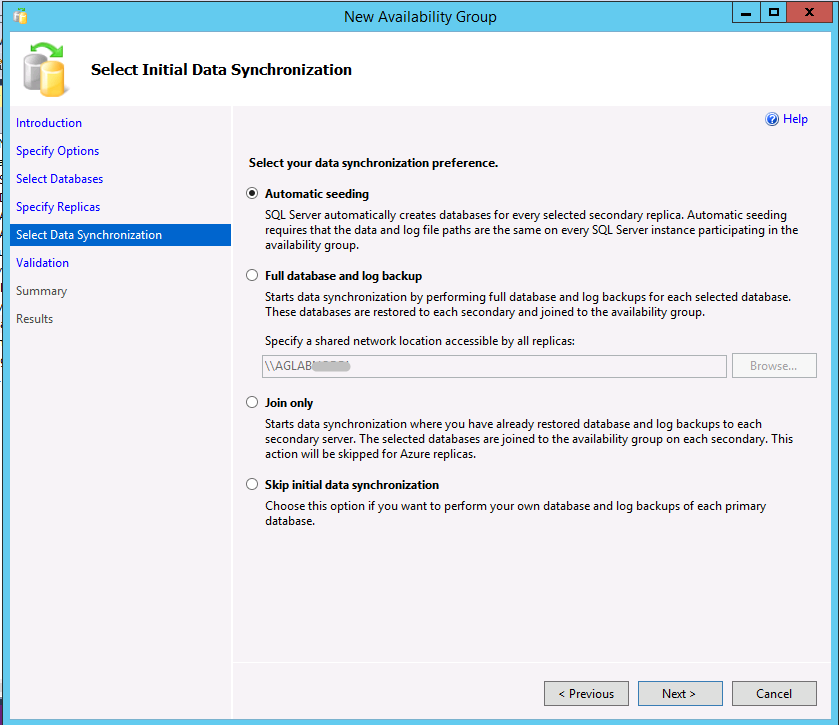
En el ejemplo siguiente se crea un grupo de disponibilidad con propagación automática mediante Transact-SQL. Vea también el tema Crear un grupo de disponibilidad (Transact-SQL). La propagación se habilita en una réplica secundaria estableciendo la opción SEEDING_MODE en AUTOMATIC. El comportamiento predeterminado es MANUAL, que es anterior al comportamiento que existía antes de SQL Server 2016 y que precisa que se haga una copia de seguridad de la base de datos en la réplica principal, una copia del archivo de copia de seguridad en la réplica secundaria y una restauración de la copia de seguridad con la opción WITH NORECOVERY.
CREATE AVAILABILITY GROUP [<AGName>]
FOR DATABASE db1
REPLICA ON N'Primary_Replica'
WITH (
ENDPOINT_URL = N'TCP://Primary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
AVAILABILITY_MODE = SYNCHRONOUS_COMMIT
),
N'Secondary_Replica' WITH (
ENDPOINT_URL = N'TCP://Secondary_Replica.Contoso.com:5022',
FAILOVER_MODE = AUTOMATIC,
SEEDING_MODE = AUTOMATIC);
GO
Establecer SEEDING_MODE en una réplica principal durante la instrucción CREATE AVAILABILITY GROUP no tiene ningún efecto, puesto que la réplica principal ya contiene la copia principal de lectura/escritura de la base de datos. SEEDING_MODE solo procede cuando otra réplica se ha convertido en principal y se le ha agregado una base de datos. El modo de propagación se puede cambiar posteriormente; vea Cambiar el modo de propagación de una réplica.
En el caso de una instancia que pasa a ser una réplica secundaria, una vez que dicha instancia se une, se agrega el siguiente mensaje en el registro de SQL Server:
La réplica de disponibilidad local para el grupo de disponibilidad "NombreGD" no tiene permiso para crear bases de datos, pero su modo
SEEDING_MODEse definió comoAUTOMATIC. UseALTER AVAILABILITY GROUP ... GRANT CREATE ANY DATABASEpara permitir la creación de bases de datos propagadas por la réplica de disponibilidad principal.
Permitir que un grupo de disponibilidad cree permisos de creación de bases de datos en réplicas secundarias
Después de la unión, conceda permiso al grupo de disponibilidad para crear bases de datos en la instancia de réplica de SQL Server. Para que la propagación automática funcione, el grupo de disponibilidad necesita permiso para crear una base de datos.
Sugerencia
Cuando el grupo de disponibilidad crea una base de datos en una réplica secundaria, establece "sa" (más específicamente, la cuenta con el sid 0x01) como el propietario de la base de datos.
Para cambiar el propietario de la base de datos después de que una réplica secundaria cree automáticamente una base de datos, use ALTER AUTHORIZATION. Consulte ALTER AUTHORIZATION (Transact-SQL).
En el ejemplo siguiente, se concede este permiso a un grupo de disponibilidad denominado NombreGD.
ALTER AVAILABILITY GROUP [<AGName>]
GRANT CREATE ANY DATABASE
GO
Si fuera necesario, establezca el propietario de la base de datos en la réplica secundaria.
Comprobar la propagación automática
Si se realiza correctamente, las bases de datos se crean automáticamente en la réplica secundaria con uno de los dos siguientes estados:
- SYNCHRONIZED, si la réplica secundaria está configurada para ser sincrónica y los datos se han sincronizado.
- SYNCHRONIZING, si la réplica secundaria está configurada con un movimiento de datos asincrónico, o bien si está configurada como sincrónica, pero aún no se ha sincronizado con la réplica principal.
Aparte de las vistas de administración dinámica descritas aquí, el inicio y la finalización de la propagación automática se pueden ver en el registro de SQL Server:

Combinar trabajos de copia de seguridad y restauración con la propagación automática
La propagación automática se puede usar de forma combinada con los trabajos tradicionales de copia de seguridad, copia y restauración. En tal caso, restaure primero la base de datos en una réplica secundaria, incluidos todos los registros de transacciones disponibles. A continuación, habilite la propagación automática al crear el grupo de disponibilidad para "detectar" la base de datos de la réplica secundaria, como si se restaurara una copia del final del registro (vea Copias del final del registro (SQL Server)).
Agregar una base de datos a un grupo de disponibilidad con propagación automática
Puede agregar una base de datos a un grupo de disponibilidad a través de la propagación automática con Transact-SQL o SQL Server Management Studio (SSMS, versión 17 o posterior).
Si la réplica secundaria usaba la propagación automática cuando se agregó al grupo de disponibilidad, no será necesario hacer nada más. Si la réplica secundaria ha usado un trabajo de copia de seguridad, copia y restauración, cambie primero el modo de propagación (consulte la sección siguiente) y, luego, al agregar la base de datos, use la instrucción GRANT; consulte Grupo de disponibilidad: agregar una base de datos.
Cambiar el modo de propagación de una réplica
El modo de propagación de una réplica se puede modificar después de crear el grupo de disponibilidad, para que la propagación automática se pueda habilitar o deshabilitar. Habilitar la propagación automática después de haber creado el grupo de disponibilidad permite agregar una base de datos al grupo de disponibilidad por medio de la propagación automática, si se creó con copia de seguridad, copia y restauración. Por ejemplo:
ALTER AVAILABILITY GROUP [AGName]
MODIFY REPLICA ON 'Replica_Name'
WITH (SEEDING_MODE = AUTOMATIC)
Para deshabilitar la propagación automática, use el valor MANUAL.
Evitar la propagación automática después de crear un grupo de disponibilidad
Si no quiere deshabilitar la propagación automática por completo en una réplica secundaria, pero sí impedir temporalmente que dicha réplica secundaria pueda crear bases de datos automáticamente, deniegue el permiso de creación de grupos de disponibilidad. Esto sucede cuando una base de datos nueva se agrega al grupo de disponibilidad, pero el grupo de disponibilidad no debe tener permisos para crear la base de datos en una réplica secundaria.
ALTER AVAILABILITY GROUP [AGName]
DENY CREATE ANY DATABASE
GO
Supervisar la propagación automática
Existen cuatro elementos con los que se puede supervisar la propagación automática y solucionar problemas al respecto:
- Registro de SQL Server, como ya hemos explicado
- Vistas de administración dinámica
- Tablas del historial de copias de seguridad
- Eventos extendidos
Vistas de administración dinámica
Hay dos vistas de administración dinámica (DMV) para la supervisión de la propagación: sys.dm_hadr_automatic_seeding y sys.dm_hadr_physical_seeding_stats.
sys.dm_hadr_automatic_seedingcontiene el estado general de la propagación automática y conserva un historial de cada vez que se ejecuta (tanto si lo hace correctamente como si no). La columnacurrent_statetendrá el valor COMPLETED o FAILED. Si el valor es FAILED, use el valor defailure_state_descpara tratar de diagnosticar el problema. Puede que sea necesario combinar esta información con lo que aparece en el registro de SQL Server para saber qué ha ido mal. Esta DMV se rellena en la réplica principal y en todas las réplicas secundarias.sys.dm_hadr_physical_seeding_statsmuestra el estado de la operación de propagación automática cuando se ejecuta. Al igual quesys.dm_hadr_automatic_seeding, este valor devuelve valores tanto para la réplica principal como las secundarias, pero no se almacena el historial. Los valores corresponden únicamente a la ejecución actual, por lo que no se conservarán. Las columnas de interés incluyenstart_time_utc,end_time_utc,estimate_time_complete_utc,total_disk_io_wait_time_ms,total_network_wait_time_ms. Si se produce un error en la operación de propagación, failure_message.
Tablas del historial de copias de seguridad
La propagación automática también agrega entradas en las tablas msdb que almacenan el historial de las copias de seguridad y las restauraciones. En la réplica secundaria que recibe la propagación automática, la columna physical_device_name de la tabla backupmediafamily contiene un GUID relativo a su valor, y la entrada correspondiente en backupset refleja el nombre de la réplica principal para nombre_servidor y nombre_equipo.
Eventos extendidos
La propagación automática agrega nuevos eventos extendidos para realizar el seguimiento de las modificaciones de estado, los errores y las estadísticas de rendimiento durante la inicialización. Por ejemplo, con el siguiente script se crea una sesión de eventos extendidos que capture eventos relacionados con la propagación automática.
CREATE EVENT SESSION [AlwaysOn_autoseed] ON SERVER
ADD EVENT sqlserver.hadr_automatic_seeding_state_transition,
ADD EVENT sqlserver.hadr_automatic_seeding_timeout,
ADD EVENT sqlserver.hadr_db_manager_seeding_request_msg,
ADD EVENT sqlserver.hadr_physical_seeding_backup_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_failure,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_forwarder_target_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_progress,
ADD EVENT sqlserver.hadr_physical_seeding_restore_state_change,
ADD EVENT sqlserver.hadr_physical_seeding_submit_callback
ADD TARGET package0.event_file(
SET filename=N'autoseed.xel',
max_file_size=(5),
max_rollover_files=(4)
)
WITH (
MAX_MEMORY=4096 KB,
EVENT_RETENTION_MODE=ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY=30 SECONDS,
MAX_EVENT_SIZE=0 KB,
MEMORY_PARTITION_MODE=NONE,
TRACK_CAUSALITY=OFF,
STARTUP_STATE=ON
)
GO
ALTER EVENT SESSION AlwaysOn_autoseed ON SERVER STATE=START
GO
En la siguiente tabla se enumeran los eventos extendidos relacionados con la propagación automática.
| Nombre | Descripción |
|---|---|
| hadr_db_manager_seeding_request_msg | Mensaje de solicitud propagación. |
| hadr_physical_seeding_backup_state_change | Cambio de estado del lado de copia de seguridad de propagación física. |
| hadr_physical_seeding_restore_state_change | Cambio de estado del lado de restauración de propagación física. |
| hadr_physical_seeding_forwarder_state_change | Cambio de estado del lado de reenviador de propagación física. |
| hadr_physical_seeding_forwarder_target_state_change | Cambio de estado del lado de destino de reenviador de propagación física. |
| hadr_physical_seeding_submit_callback | Evento de devolución de llamada del envío de propagación física. |
| hadr_physical_seeding_failure | Evento de error de propagación física. |
| hadr_physical_seeding_progress | Evento de progreso de propagación física. |
| hadr_physical_seeding_schedule_long_task_failure | Evento de error de tarea larga de programación de propagación física. |
| hadr_automatic_seeding_start | Se produce cuando se envía una operación de propagación automática. |
| hadr_automatic_seeding_state_transition | Se produce cuando cambia el estado de una operación de propagación automática. |
| hadr_automatic_seeding_success | Se produce cuando se realiza correctamente una operación de propagación automática. |
| hadr_automatic_seeding_failure | Se produce cuando se realiza una operación de propagación automática incorrectamente. |
| hadr_automatic_seeding_timeout | Se produce cuando se agota el tiempo de espera de una operación de propagación automática. |
Consulte también
ALTER AVAILABILITY GROUP (Transact-SQL)
CREATE AVAILABILITY GROUP (Transact-SQL)
Guía de solución de problemas y supervisión de grupos de disponibilidad AlwaysOn