Montones (tablas sin índices clúster)
Se aplica a: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Un montón es una tabla que no tiene un índice clúster. En las tablas almacenadas, se pueden crear uno o varios índices no clúster como un montón. Los datos se almacenan en el montón sin especificar un orden. Normalmente, los datos se almacenan inicialmente en el orden en que se insertan las filas. Sin embargo, el Motor de base de datos puede mover datos en el montón para almacenar las filas de forma eficaz. En los resultados de la consulta, no se puede predecir el orden de los datos. Para garantizar el orden de las filas que se devuelven de un montón, debe usar la cláusula ORDER BY. Para especificar un orden lógico permanente con el fin de almacenar las filas, cree un índice agrupado en la tabla, de modo que la tabla no sea un montón.
Nota:
A veces, hay buenos motivos para dejar una tabla como montón en lugar de crear un índice clúster, pero para usar los montones de forma eficaz se requieren conocimientos avanzados. La mayoría de las tablas deben tener un índice clúster cuidadosamente elegido a menos que exista un buen motivo para dejar la tabla como un montón.
Cuándo se usa un montón
Un montón es idóneo para las tablas que se truncan y se vuelven a cargar con frecuencia. El motor de base de datos optimiza el espacio en un montón rellenando el espacio disponible más antiguo.
Tenga en cuenta lo siguiente.
- La ubicación del espacio libre en un montón puede ser costosa, especialmente si se han producido muchas eliminaciones o actualizaciones.
- Los índices agrupados ofrecen un rendimiento estable para las tablas que no se truncan con frecuencia.
En el caso de las tablas que se truncan o vuelven a crear periódicamente, como tablas temporales o de almacenamiento provisional, el uso de un montón suele ser más eficaz.
La elección entre usar un montón y un índice agrupado puede afectar significativamente al rendimiento y la eficacia de la base de datos.
Cuando una tabla se almacena como montón, las filas individuales se identifican mediante una referencia a un identificador de fila (RID) de 8 bytes formado por el número de archivo, el número de páginas de datos y la ranura de la página (FileID:PageID:SlotID). El identificador de fila es una estructura pequeña y eficaz.
Los montones se pueden usar como tablas de almacenamiento provisional para operaciones de inserción de gran tamaño y sin ordenar. Dado que los datos se insertan sin aplicar un orden estricto, la operación de inserción suele ser más rápida que la inserción equivalente en un índice agrupado. Si los datos del montón se leen y procesan en un destino final, puede ser útil crear un índice no agrupado estrecho que abarque el predicado de búsqueda que usa la consulta.
Nota:
Los datos se recuperan de un montón en orden de páginas de datos, pero no necesariamente en el orden en el que se han insertado.
A veces, los profesionales de datos también usan montones cuando el acceso a los datos se realiza siempre a través de índices no agrupados y el RID es menor que una clave de índice agrupado.
Si una tabla es un montón y no tiene ningún índice agrupado, debe leerse la tabla completa (recorrido de tabla) cuando se busca una fila. SQL Server no puede buscar un RID directamente en el montón. Este comportamiento puede ser aceptable si la tabla es pequeña.
Cuándo no se usa un montón
No use un montón cuando los datos se devuelvan con frecuencia ordenados. Un índice clúster en la columna de ordenación podría impedir la operación de ordenación.
No use un montón cuando los datos se agrupan juntos a menudo. Los datos deben estar ordenados antes de que se agrupen y un índice clúster en la columna de ordenación podría impedir la operación de ordenación.
No use un montón cuando a menudo se consulten rangos de datos de la tabla. Un índice clúster en la columna de rango impedirá que se ordene el montón completo.
No use un montón cuando no haya índices no clúster y la tabla sea grande. La única aplicación para este diseño es devolver todo el contenido de la tabla sin ningún orden especificado. En un montón, el Motor de base de datos lee todas las filas para buscar cualquier fila.
No use un montón si los datos se actualizan con frecuencia. Si actualiza un registro y la actualización usa más espacio en las páginas de datos del que se usa actualmente, el registro tiene que moverse a una página de datos que tenga suficiente espacio libre. Esto crea un registro reenviado que apunta a la nueva ubicación de los datos y hay que escribir el puntero de reenvío en la página que contenía los datos anteriormente para indicar la nueva ubicación física. Esto introduce una fragmentación en el montón. Cuando el Motor de base de datos examina un montón, sigue estos punteros. Esta acción limita el rendimiento de lectura anticipada y puede incurrir en E/S adicionales, lo que reduce el rendimiento del examen.
Administración de montones
Para crear un montón, cree una tabla sin un índice clúster. Si la tabla ya tiene un índice clúster, quite el índice clúster para convertir de nuevo la tabla en un montón.
Para quitar un montón, cree un índice clúster en el montón.
Para volver a crear un montón a fin de recuperar el espacio desaprovechado:
- Cree un índice agrupado en el montón y, después, quítelo.
- Use el comando
ALTER TABLE ... REBUILDpara volver a crear el montón.
Advertencia
Para crear o quitar índices clúster, es necesario volver a escribir toda la tabla. Si la tabla tiene índices no clúster, todos los índices no clúster deberán volver a crearse cada vez que cambie el índice clúster. Por tanto, al convertir un montón en una estructura de índice agrupado o viceversa, puede necesitarse mucho tiempo y gran cantidad de espacio para reordenar los datos en tempdb.
Identificación de montones
La siguiente consulta devuelve la lista de montones de la base de datos actual. La lista incluye lo siguiente:
- Nombres de tabla
- Nombres de esquema
- Número de filas
- Tamaño de tabla en KB
- Tamaño del índice en KB
- Espacio sin usar
- Columna para identificar un montón
SELECT t.name AS 'Your TableName',
s.name AS 'Your SchemaName',
p.rows AS 'Number of Rows in Your Table',
SUM(a.total_pages) * 8 AS 'Total Space of Your Table (KB)',
SUM(a.used_pages) * 8 AS 'Used Space of Your Table (KB)',
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS 'Unused Space of Your Table (KB)',
CASE
WHEN i.index_id = 0
THEN 'Yes'
ELSE 'No'
END AS 'Is Your Table a Heap?'
FROM sys.tables t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id
INNER JOIN sys.partitions p
ON i.object_id = p.object_id
AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a
ON p.partition_id = a.container_id
LEFT JOIN sys.schemas s
ON t.schema_id = s.schema_id
WHERE i.index_id <= 1 -- 0 for Heap, 1 for Clustered Index
GROUP BY t.name,
s.name,
i.index_id,
p.rows
ORDER BY 'Your TableName';
Estructuras de montón
Un montón es una tabla que no tiene un índice clúster. Los montones tienen una fila en sys.partitions, con index_id = 0 para cada partición que usa el montón. De forma predeterminada, un montón contiene una sola partición. Cuando un montón tiene varias particiones, cada partición incluye una estructure de montón que contiene los datos de esa partición específica. Por ejemplo, si un montón tiene cuatro particiones, existirán cuatro estructuras de montón, una en cada partición.
Dependiendo de los tipos de datos incluidos en el montón, cada estructura de montón tendrá una o más unidades de asignación para almacenar y administrar los datos de una partición específica. Como mínimo, cada montón dispondrá de una unidad de asignación IN_ROW_DATA por partición. El montón también dispondrá de una unidad de asignación LOB_DATA por partición si contiene columnas de objeto grande (LOB). También tendrá una unidad de asignación ROW_OVERFLOW_DATA por partición si contiene columnas de longitud variable que superen el límite de tamaño de fila de 8060 bytes.
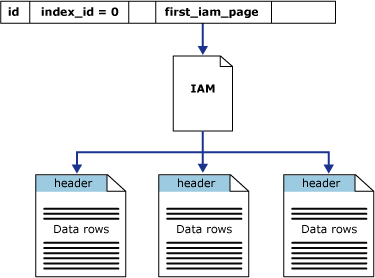
La columna first_iam_page en los puntos de vista del sistema sys.system_internals_allocation_units para la primera página IAM de la cadena de páginas IAM que administra el espacio asignado al montón en una partición específica. SQL Server usa las páginas IAM para desplazarse por el montón. Las páginas de datos y las filas que se encuentran en ellas no están en ningún orden concreto y no están vinculadas. La única conexión lógica entre las páginas de datos es la información registrada en las páginas IAM.
Importante
La vista del sistema sys.system_internals_allocation_units solo puede utilizarla internamente SQL Server. La compatibilidad con versiones posteriores no está garantizada.
Los recorridos de tablas o las lecturas secuenciales de un montón se hacen recorriendo las páginas IAM para buscar las extensiones que almacenan las páginas de dicho montón. Como la IAM representa las extensiones en el mismo orden en el que se encuentran en los archivos de datos, ello significa que los recorridos secuenciales de un montón recorren secuencialmente cada archivo. Utilizar las páginas IAM para establecer la secuencia de recorrido también significa que las filas del montón no se devuelven normalmente en el orden en que se introdujeron.
La siguiente ilustración muestra cómo el motor de la base de datos de SQL Server usa las páginas IAM para recuperar las filas de datos en un solo montón de partición.
Contenido relacionado
CREATE INDEX (Transact-SQL)
DROP INDEX (Transact-SQL)
Índices agrupados y no agrupados descritos