Tutorial: creación e implementación de un proyecto SQL
Se aplica a: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Base de datos de Azure SQL de Microsoft Fabric
Base de datos de Azure SQL de Microsoft Fabric
El ciclo de desarrollo de un proyecto de base de datos SQL permite integrar el desarrollo de bases de datos en flujos de trabajo de integración continua e implementación continua (CI/CD) conocidos como procedimiento recomendado de desarrollo. Aunque la implementación de un proyecto de base de datos SQL se puede realizar manualmente, se recomienda usar una canalización de implementación para automatizar el proceso de implementación de forma que las implementaciones en curso se ejecuten en función del desarrollo local continuo sin esfuerzo adicional.
En este artículo se describen la creación de un nuevo proyecto SQL, la adición de objetos al proyecto y la configuración de una canalización de implementación continua para crear e implementar el proyecto mediante acciones de GitHub. El tutorial es un superconjunto del contenido del artículo Introducción a los proyectos SQL. Aunque el tutorial implementa la canalización de implementación en acciones de GitHub, los mismos conceptos se aplican a Azure DevOps, GitLab y otros entornos de automatización.
En este tutorial:
- Creará un nuevo proyecto SQL
- Adición de objetos al proyecto
- Compilará el proyecto localmente
- Revisará el proyecto en el control de código fuente
- Agregará un paso de compilación del proyecto a una canalización de implementación continua
- Agregará un paso de implementación
.dacpaca una canalización de implementación continua
Si ya ha completado los pasos descritos en el artículo Introducción a los proyectos SQL, puede ir directamente al paso 4. Al final de este tutorial, el proyecto SQL compilará e implementará automáticamente los cambios en una base de datos de destino.
Requisitos previos
# install SqlPackage CLI
dotnet tool install -g Microsoft.SqlPackage
# install Microsoft.Build.Sql.Templates
dotnet new install Microsoft.Build.Sql.Templates
Asegúrese de que tiene los siguientes elementos para completar la configuración de la canalización en GitHub:
Una cuenta de GitHub en la que pueda crear un repositorio. cree una de forma gratuita.
Las acciones de GitHub están habilitadas en el repositorio.
Nota:
Para completar la implementación de un proyecto de base de datos SQL, necesita acceso a una instancia de Azure SQL o SQL Server. Puede desarrollar localmente y de forma gratuita con SQL Server Developer Edition en Windows o en contenedores.
Paso 1: Creación de un proyecto
Iniciamos nuestro proyecto mediante la creación de un nuevo proyecto de base de datos SQL antes de agregarle objetos manualmente. Hay otras maneras de crear un proyecto que permita rellenar inmediatamente el proyecto con objetos de una base de datos existente, como el uso de las herramientas de comparación de esquemas.
Selecciona Archivo, Nuevo y, a continuación, Proyecto.
En el cuadro de diálogo Nuevo proyecto, use el término SQL Server en el cuadro de búsqueda. El resultado principal debería ser Proyecto de base de datos de SQL Server.

Seleccione Siguiente para continuar con el paso siguiente. Proporcione un nombre de proyecto, que no tiene por qué coincidir con el nombre de una base de datos. Compruebe y modifique la ubicación del proyecto según sea necesario.
Seleccione Crear para crear el proyecto. El proyecto vacío se puede abrir y visualizar en el Explorador de soluciones para su edición.
Selecciona Archivo, Nuevo y, a continuación, Proyecto.
En el cuadro de diálogo Nuevo proyecto, use el término SQL Server en el cuadro de búsqueda. El resultado principal debería ser Proyecto de base de datos de SQL Server, estilo SDK (versión preliminar).

Seleccione Siguiente para continuar con el paso siguiente. Proporcione un nombre de proyecto, que no tiene por qué coincidir con el nombre de una base de datos. Compruebe y modifique la ubicación del proyecto según sea necesario.
Seleccione Crear para crear el proyecto. El proyecto vacío se puede abrir y visualizar en el Explorador de soluciones para su edición.
En la vista Proyectos de base de datos de VS Code o Azure Data Studio, seleccione el botón Nuevo proyecto.
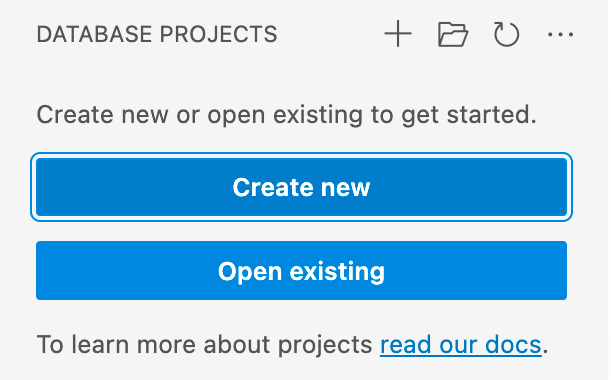
La primera consulta determina qué plantilla de proyecto se va a usar, principalmente en función de si la plataforma de destino es SQL Server o Azure SQL. Si se le pide que seleccione una versión específica de SQL, elija la versión que coincida con la de la base de datos de destino, pero si la versión de la base de datos de destino es desconocida, elija la versión más reciente, ya que el valor se puede modificar más adelante.
Escriba un nombre de proyecto en la entrada de texto que aparece, que no tiene por qué coincidir con un nombre de base de datos.
En el cuadro de diálogo “Seleccionar una carpeta” que aparece, seleccione un directorio para guardar la carpeta del proyecto, el archivo .sqlproj y el resto del contenido.
Cuando se le pregunte si desea crear un proyecto de estilo SDK (versión preliminar), seleccione Sí.
Una vez completado, el proyecto vacío se puede abrir y visualizar en la vista Proyectos de base de datos para su edición.
Con las plantillas de .NET para proyectos Microsoft.Build.Sql instalados, puede crear un nuevo proyecto de base de datos SQL desde la línea de comandos. La opción -n especifica el nombre del proyecto y la opción -tp especifica la plataforma de destino del proyecto.
Use la opción -h para ver todas las opciones disponibles.
# install Microsoft.Build.Sql.Templates
dotnet new sqlproject -n MyDatabaseProject
Paso 2: Adición de objetos al proyecto
En el Explorador de soluciones, haga clic con el botón derecho en el nodo del proyecto y seleccione Agregar y luego Tabla. Aparece el cuadro de diálogo Agregar nuevo elemento, donde puede especificar el nombre de la tabla. Seleccione Agregar para crear la tabla en el proyecto SQL.
La tabla se abre en el diseñador de tablas de Visual Studio con la plantilla de definición de tabla, donde puede agregar columnas, índices y otras propiedades de tabla. Guarde el archivo cuando haya terminado de realizar las modificaciones iniciales.
Se pueden agregar más objetos de base de datos mediante el cuadro de diálogo Agregar nuevo elemento, como vistas, procedimientos almacenados y funciones. Para acceder al cuadro de diálogo, haga clic con el botón derecho en el nodo del proyecto en Explorador de soluciones y seleccione Agregar y, a continuación, el tipo de objeto deseado. Los archivos del proyecto se pueden organizar en carpetas a través de la opción Nueva carpeta en Agregar.
En el Explorador de soluciones, haga clic con el botón derecho en el nodo del proyecto y seleccione Agregar y, a continuación, Nuevo elemento. En el cuadro de diálogo Agregar nuevo elemento, seleccione Mostrar todas las plantillas y, a continuación, Tabla. Especifique el nombre de la tabla como nombre de archivo y seleccione Agregar para crear la tabla en el proyecto de SQL.
La tabla se abre en el editor de consultas de Visual Studio con la plantilla de definición de tabla, donde puede agregar columnas, índices y otras propiedades de tabla. Guarde el archivo cuando haya terminado de realizar las modificaciones iniciales.
Se pueden agregar más objetos de base de datos mediante el cuadro de diálogo Agregar nuevo elemento, como vistas, procedimientos almacenados y funciones. Para acceder al cuadro de diálogo, haga clic con el botón derecho en el nodo del proyecto en el Explorador de soluciones y seleccione Agregar y, a continuación, el tipo de objeto deseado después de Mostrar todas las plantillas. Los archivos del proyecto se pueden organizar en carpetas a través de la opción Nueva carpeta en Agregar.
En la vista Proyectos de base de datos de VS Code o Azure Data Studio, haga clic con el botón derecho en el nodo del proyecto y seleccione Agregar tabla. En el cuadro de diálogo que aparece, especifique el nombre de la tabla.
La tabla se abre en el editor de texto con la plantilla de definición de tabla, donde puede agregar columnas, índices y otras propiedades de tabla. Guarde el archivo cuando haya terminado de realizar las modificaciones iniciales.
Se pueden agregar más objetos de base de datos a través del menú contextual del nodo del proyecto, como vistas, procedimientos almacenados y funciones. Para acceder al cuadro de diálogo, haga clic con el botón derecho sobre el nodo del proyecto en la vista Proyectos de base de datos de VS Code o Azure Data Studio y, a continuación, sobre el tipo de objeto deseado. Los archivos del proyecto se pueden organizar en carpetas a través de la opción Nueva carpeta en Agregar.
Los archivos se pueden agregar al proyecto creándolos en el directorio del proyecto o en carpetas anidadas. Se recomienda la extensión de archivo .sql y la organización por tipo de objeto o esquema y tipo de objeto.
La plantilla base de una tabla se puede usar como punto de partida para crear un nuevo objeto de tabla en el proyecto:
CREATE TABLE [dbo].[Table1]
(
[Id] INT NOT NULL PRIMARY KEY
)
Paso 3: Compilar el proyecto
El proceso de compilación valida las relaciones entre objetos y la sintaxis teniendo en cuenta la plataforma de destino especificada en el archivo de proyecto. La salida de artefacto del proceso de compilación es un archivo .dacpac, que se puede usar para implementar el proyecto en una base de datos de destino y que contiene el modelo compilado del esquema de base de datos.
En el Explorador de soluciones, haga clic con el botón derecho sobre el nodo del proyecto y seleccione Compilar.
La ventana de salida se abre automáticamente para mostrar el proceso de compilación. Si hay errores o advertencias, se muestran en la ventana de salida. En una compilación correcta, el artefacto de compilación (archivo .dacpac) se crea y su ubicación se incluye en la salida de la compilación (el valor predeterminado es bin\Debug\projectname.dacpac).
En el Explorador de soluciones, haga clic con el botón derecho sobre el nodo del proyecto y seleccione Compilar.
La ventana de salida se abre automáticamente para mostrar el proceso de compilación. Si hay errores o advertencias, se muestran en la ventana de salida. En una compilación correcta, el artefacto de compilación (archivo .dacpac) se crea y su ubicación se incluye en la salida de la compilación (el valor predeterminado es bin\Debug\projectname.dacpac).
En la vista Proyectos de base de datos de VS Code o Azure Data Studio, haga clic con el botón derecho en el nodo del proyecto y seleccione Compilar.
La ventana de salida se abre automáticamente para mostrar el proceso de compilación. Si hay errores o advertencias, se muestran en la ventana de salida. En una compilación correcta, el artefacto de compilación (archivo .dacpac) se crea y su ubicación se incluye en la salida de la compilación (el valor predeterminado es bin/Debug/projectname.dacpac).
Los proyectos de base de datos SQL se pueden compilar desde la línea de comandos mediante el comando dotnet build.
dotnet build
# optionally specify the project file
dotnet build MyDatabaseProject.sqlproj
La salida de la compilación incluye los errores o advertencias y los archivos y números de línea específicos en los que se producen. En una compilación correcta, el artefacto de compilación (archivo .dacpac) se crea y su ubicación se incluye en la salida de la compilación (el valor predeterminado es bin/Debug/projectname.dacpac).
Paso 4: revisar el proyecto en el control de código fuente
Inicializaremos nuestro proyecto como repositorio de Git y confirmaremos los archivos de proyecto en control de código fuente. Este paso es necesario para permitir que el proyecto se comparta con otros usuarios y se use en una canalización de implementación continua.
En el menú Git de Visual Studio, seleccione Crear un repositorio GIT.
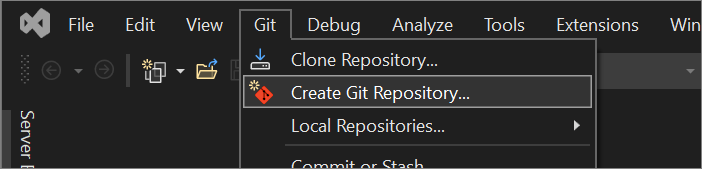
En el cuadro de diálogo Crear un repositorio GIT, en la sección Enviar cambios a un nuevo repositorio remoto, elija GitHub.
En la sección Crear un nuevo repositorio de GitHub del cuadro de diálogo Crear un repositorio GIT, escriba el nombre del repositorio que desea crear. (Si aún no ha iniciado sesión en su cuenta de GitHub, también puede hacerlo desde esta pantalla).

En Inicializar un repositorio de Git local, debería usar la opción de plantilla .gitignore para especificar los archivos no seguidos intencionadamente que quiera que Git omita. Para obtener más información sobre .gitignore, consulte Omisión de archivos. Y para obtener más información sobre las licencias, consulte Licencias de un repositorio.
Después de iniciar sesión y escribir la información del repositorio, seleccione el botón Crear y enviar los cambios para crear el repositorio y agregar la aplicación.

En el Explorador de soluciones, haga clic con el botón derecho sobre el nodo del proyecto y seleccione Publicar…
Se abre el cuadro de diálogo de publicación, donde se establece la conexión con la base de datos de destino. Si no tiene una instancia de SQL existente para la implementación, LocalDB ((localdb)\MSSQLLocalDB) se instala con Visual Studio y se puede usar para pruebas y desarrollo.
Especifique un nombre de base de datos y seleccione Publicar para implementar el proyecto en la base de datos de destino o Generar script para generar un script que se revisará antes de ejecutarse.
Puede inicializar un repositorio local y publicarlo directamente en GitHub desde VS Code o Azure Data Studio. Esta acción crea un nuevo repositorio en la cuenta de GitHub e inserta los cambios de código local en el repositorio remoto en un solo paso.
Use el botón Publicar en GitHub en la vista Control de código fuente en VS Code o Azure Data Studio. A continuación, se le pedirá que especifique un nombre y una descripción para el repositorio, así como si desea que sea público o privado.

Como alternativa, puede inicializar un repositorio local e insertarlo en GitHub siguiendo los pasos proporcionados al crear un repositorio vacío en GitHub.
Inicialice un nuevo repositorio de Git en el directorio del proyecto y confirme los archivos de proyecto en control de código fuente.
git init
git add .
git commit -m "Initial commit"
Cree un nuevo repositorio en GitHub e inserte el repositorio local en el repositorio remoto.
git remote add origin <repository-url>
git push -u origin main
Paso 5: agregar un paso de compilación del proyecto a una canalización de implementación continua
Los proyectos SQL están respaldados por una biblioteca .NET y, como resultado, los proyectos se compilan con el comando dotnet build. Este comando es un elemento básico incluso de las canalizaciones de integración continua e implementación continua (CI/CD) más básicas. El paso de compilación se puede agregar a una canalización de implementación continua que creamos en acciones de GitHub.
En la raíz del repositorio, cree un nuevo directorio con el nombre
.github/workflows. Este directorio contendrá el archivo de flujo de trabajo que define la canalización de implementación continua.En el directorio
.github/workflows, cree un nuevo archivo denominadosqlproj-sample.yml.Agregue el siguiente contenido al archivo
sqlproj-sample.ymly edite el nombre del proyecto para que coincida con el nombre y la ruta de acceso del proyecto:name: sqlproj-sample on: push: branches: [ "main" ] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - name: Setup .NET uses: actions/setup-dotnet@v4 with: dotnet-version: 8.0.x - name: Build run: dotnet build MyDatabaseProject.sqlprojConfirme el archivo de flujo de trabajo en el repositorio e inserte los cambios en el repositorio remoto.
En GitHub.com, vaya a la página principal del repositorio. Debajo del nombre del repositorio, haga clic en Acciones. En la barra lateral izquierda, seleccione el flujo de trabajo que acaba de crear. Una ejecución reciente del flujo de trabajo debe aparecer en la lista de ejecuciones de flujo de trabajo desde la que insertó el archivo de flujo de trabajo en el repositorio.
Puede encontrar más información sobre los aspectos básicos de la creación del primer flujo de trabajo de acciones de GitHub en el inicio rápido de Acciones de GitHub.
Paso 6: agregar un paso de implementación .dacpac a una canalización de implementación continua
El modelo compilado de un esquema de base de datos en un archivo .dacpac se puede implementar en una base de datos de destino mediante la herramienta de línea de comandos SqlPackage o mediante otras herramientas de implementación. El proceso de implementación determina los pasos necesarios para actualizar la base de datos de destino para que coincida con el esquema definido en .dacpac, creando o modificando objetos según sea necesario en función de los objetos que ya existen en la base de datos. Por ejemplo, para implementar un archivo .dacpac en una base de datos de destino basada en un cadena de conexión:
sqlpackage /Action:Publish /SourceFile:bin/Debug/MyDatabaseProject.dacpac /TargetConnectionString:{yourconnectionstring}

El proceso de implementación es idempotente, lo que significa que se puede ejecutar varias veces sin causar problemas. La canalización que estamos creando compilará e implementará nuestro proyecto SQL cada vez que se compruebe un cambio en la rama main de nuestro repositorio. En lugar de ejecutar el comando SqlPackage directamente en nuestra canalización de implementación, podemos usar una tarea de implementación que abstrae el comando y proporciona características adicionales, como el registro, el control de errores y la configuración de tareas. La tarea de implementación GitHub sql-action se puede agregar a una canalización de implementación continua en acciones de GitHub.
Nota:
La ejecución de una implementación desde un entorno de automatización requiere configurar la base de datos y el entorno para que la implementación pueda llegar a la base de datos y autenticarse. En Azure SQL Database o SQL Server, en una máquina virtual, esto puede requerir la configuración de una regla de firewall para permitir que el entorno de automatización se conecte a la base de datos, así como proporcionar un cadena de conexión con las credenciales necesarias. La guía se proporciona en la documentación de GitHub sql-action.
Abra el archivo
sqlproj-sample.ymlen el directorio.github/workflows.Agregue el paso siguiente al archivo
sqlproj-sample.ymldespués del paso de compilación:- name: Deploy uses: azure/sql-action@v2 with: connection-string: ${{ secrets.SQL_CONNECTION_STRING }} action: 'publish' path: 'bin/Debug/MyDatabaseProject.dacpac'Antes de confirmar los cambios, agregue un secreto al repositorio que contiene la cadena de conexión a la base de datos de destino. En el repositorio en GitHub.com, vaya a la configuración y después a Secretos. Seleccione Nuevo secreto de repositorio y agregue un secreto denominado
SQL_CONNECTION_STRINGcon el valor de la cadena de conexión a la base de datos de destino.
Confirme los cambios desde
sqlproj-sample.ymlal repositorio e inserte los cambios en el repositorio remoto.Vuelva al historial de flujo de trabajo en GitHub.com y seleccione la ejecución más reciente del flujo de trabajo. El paso de implementación debe estar visible en la lista de pasos para la ejecución del flujo de trabajo y el flujo de trabajo devuelve un código correcto.
Compruebe la implementación mediante la conexión a la base de datos de destino y compruebe que los objetos del proyecto están presentes en la base de datos.

Las implementaciones de GitHub se pueden proteger aún más mediante el establecimiento de una relación de entorno en un flujo de trabajo y la necesidad de aprobación antes de ejecutar una implementación. Puede encontrar más información sobre la protección del entorno y la protección de secretos en la documentación de Acciones de Github.