Generación precisa de perfiles de llamadas de la API de Direct3D (Direct3D 9)
- La generación de perfiles con precisión de Direct3D es difícil
- Cómo generar perfiles precisos de una secuencia de representación de Direct3D
- Generación de perfiles de cambios de estado de Direct3D
- Resumen
- Apéndice
Una vez que tengas una aplicación funcional de Microsoft Direct3D y quieras mejorar su rendimiento, normalmente usas una herramienta de generación de perfiles fuera del estante o alguna técnica de medición personalizada para medir el tiempo necesario para ejecutar una o varias llamadas a la interfaz de programación de aplicaciones (API). Si lo ha hecho, pero obtiene resultados de tiempo que varían de una secuencia de representación a la siguiente, o está realizando hipótesis que no se mantienen hasta los resultados reales del experimento, la siguiente información puede ayudarle a comprender por qué.
La información que se proporciona aquí se basa en la suposición de que tiene conocimientos y experiencia con lo siguiente:
- Programación de C/C++
- Programación de la API de Direct3D
- Medición del tiempo de la API
- La tarjeta de vídeo y su controlador de software
- Posibles resultados no explicables de la experiencia de generación de perfiles anterior
La generación de perfiles con precisión de Direct3D es difícil
Un generador de perfiles informa sobre la cantidad de tiempo invertido en cada llamada API. Esto se hace para mejorar el rendimiento mediante la búsqueda y optimización de las zonas activas. Hay diferentes tipos de generadores de perfiles y técnicas de generación de perfiles.
- Un generador de perfiles de muestreo se encuentra inactivo en gran parte del tiempo, despertando a intervalos específicos para muestrear (o registrar) las funciones que se ejecutan. Devuelve el porcentaje de tiempo invertido en cada llamada. Por lo general, un generador de perfiles de muestreo no es muy invasivo para la aplicación y tiene un impacto mínimo en la sobrecarga de la aplicación.
- Un generador de perfiles de instrumentación mide el tiempo real que tarda una llamada a devolver. Requiere compilar delimitadores de inicio y detención en una aplicación. Un generador de perfiles de instrumentación es comparativamente más invasivo para una aplicación que un generador de perfiles de muestreo.
- También es posible usar una técnica de generación de perfiles personalizada con un temporizador de alto rendimiento. Esto produce resultados muy parecidos a un generador de perfiles de instrumentación.
El tipo de generador de perfiles o técnica de generación de perfiles utilizado es solo parte del desafío de generar mediciones precisas.
La generación de perfiles proporciona respuestas que le ayudan a presupuestar el rendimiento. Por ejemplo, supongamos que una llamada API calcula un promedio de mil ciclos de reloj para ejecutarse. Puede afirmar algunas conclusiones sobre el rendimiento, como las siguientes:
- Una CPU de 2 GHz (que pasa el 50 por ciento de su representación de tiempo) se limita a llamar a esta API 1 millón de veces por segundo.
- Para lograr 30 fotogramas por segundo, no puede llamar a esta API más de 33 000 veces por fotograma.
- Solo puede representar 3,3 000 objetos por fotograma (suponiendo 10 de estas llamadas API para la secuencia de representación de cada objeto).
En otras palabras, si tuviera tiempo suficiente por llamada API, podría responder a una pregunta de presupuesto, como el número de primitivos que se pueden representar de forma interactiva. Pero los números sin procesar devueltos por un generador de perfiles de instrumentación no responderán con precisión a las preguntas de presupuestación. Esto se debe a que la canalización de gráficos tiene problemas de diseño complejos, como el número de componentes que necesitan hacer trabajo, el número de procesadores que controlan cómo fluye el trabajo entre los componentes y las estrategias de optimización implementadas en tiempo de ejecución y en un controlador diseñado para que la canalización sea más eficaz.
Cada llamada API pasa por varios componentes
Cada llamada es procesada por varios componentes en su camino desde la aplicación a la tarjeta de vídeo. Por ejemplo, considere la siguiente secuencia de representación que contiene dos llamadas para dibujar un único triángulo:
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
En el diagrama conceptual siguiente se muestran los distintos componentes a través de los cuales se deben pasar las llamadas.

La aplicación invoca Direct3D que controla la escena, controla las interacciones del usuario y determina cómo se realiza la representación. Todo este trabajo se especifica en la secuencia de representación, que se envía al tiempo de ejecución mediante llamadas API de Direct3D. La secuencia de representación es prácticamente independiente del hardware (es decir, las llamadas API son independientes del hardware, pero una aplicación tiene conocimiento de las características que admite una tarjeta de vídeo).
El tiempo de ejecución convierte estas llamadas en un formato independiente del dispositivo. El tiempo de ejecución controla toda la comunicación entre la aplicación y el controlador, de modo que una aplicación se ejecute en más de una pieza de hardware compatible (según las características necesarias). Al medir una llamada de función, un generador de perfiles de instrumentación mide el tiempo dedicado a una función, así como el tiempo para que la función devuelva. Una limitación de un generador de perfiles de instrumentación es que puede no incluir el tiempo que tarda un controlador en enviar el trabajo resultante a la tarjeta de vídeo ni el tiempo para que la tarjeta de vídeo procese el trabajo. En otras palabras, un generador de perfiles de instrumentación no puede atribuir todo el trabajo asociado a cada llamada de función.
El controlador de software usa conocimientos específicos de hardware sobre la tarjeta de vídeo para convertir los comandos independientes del dispositivo en una secuencia de comandos de tarjeta de vídeo. Los controladores también pueden optimizar la secuencia de comandos que se envían a la tarjeta de vídeo, de modo que la representación en la tarjeta de vídeo se realice de forma eficaz. Estas optimizaciones pueden causar problemas de generación de perfiles porque la cantidad de trabajo realizado no es lo que parece ser (es posible que tenga que comprender las optimizaciones que deben tener en cuenta). Normalmente, el controlador devuelve el control al tiempo de ejecución antes de que la tarjeta de vídeo haya terminado de procesar todos los comandos.
La tarjeta de vídeo realiza la mayoría de la representación mediante la combinación de datos de los búferes de vértices e índices, texturas, información de estado de representación y los comandos gráficos. Cuando la tarjeta de vídeo finaliza la representación, se completa el trabajo creado a partir de la secuencia de representación.
Cada llamada API de Direct3D debe procesarse mediante cada componente (el tiempo de ejecución, el controlador y la tarjeta de vídeo) para representar cualquier cosa.
Hay más de un procesador que controla los componentes
La relación entre estos componentes es aún más compleja, ya que la aplicación, el tiempo de ejecución y el controlador están controlados por un procesador y la tarjeta de vídeo se controla mediante un procesador independiente. En el diagrama siguiente se muestran dos tipos de procesadores: una unidad de procesamiento central (CPU) y una unidad de procesamiento gráfico (GPU).
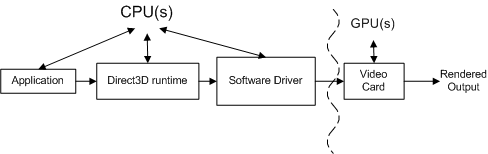
Los sistemas pc tienen al menos una CPU y una GPU, pero pueden tener más de uno de los dos o ambos. Las CPU se encuentran en la placa base y las GPU se encuentran en la placa base o en la tarjeta de vídeo. La velocidad de la CPU viene determinada por un chip de reloj en la placa base y la velocidad de la GPU viene determinada por un chip de reloj independiente. El reloj de CPU controla la velocidad del trabajo realizado por la aplicación, el tiempo de ejecución y el controlador. La aplicación envía trabajo a la GPU a través del entorno de ejecución y el controlador.
La CPU y la GPU suelen ejecutarse a diferentes velocidades, independientemente entre sí. La GPU puede responder al trabajo tan pronto como el trabajo esté disponible (suponiendo que la GPU haya terminado de procesar el trabajo anterior). El trabajo de GPU se realiza en paralelo con el trabajo de CPU como se resalta en la línea curvada de la ilustración anterior. Un generador de perfiles suele medir el rendimiento de la CPU, no la GPU. Esto dificulta la generación de perfiles, ya que las medidas realizadas por un generador de perfiles de instrumentación incluyen el tiempo de CPU, pero es posible que no incluyan el tiempo de GPU.
El propósito de la GPU es desactivar el procesamiento de la CPU a un procesador diseñado específicamente para el trabajo de gráficos. En las tarjetas de vídeo modernas, la GPU reemplaza gran parte del trabajo de transformación e iluminación en la canalización de la CPU a la GPU. Esto reduce considerablemente la carga de trabajo de CPU, lo que deja más ciclos de CPU disponibles para otro procesamiento. Para ajustar una aplicación gráfica para obtener un rendimiento máximo, debe medir el rendimiento de la CPU y la GPU, y equilibrar el trabajo entre los dos tipos de procesadores.
En este documento no se tratan temas relacionados con la medición del rendimiento de la GPU o el equilibrio del trabajo entre la CPU y la GPU. Si desea comprender mejor el rendimiento de una GPU (o una tarjeta de vídeo determinada), visite el sitio web del proveedor para buscar más información sobre el rendimiento de la GPU. En su lugar, este documento se centra en el trabajo realizado por el tiempo de ejecución y el controlador reduciendo el trabajo de GPU a una cantidad insignificante. Esto se basa, en parte, en la experiencia en la que las aplicaciones experimentan problemas de rendimiento suelen ser limitadas por la CPU.
Las optimizaciones del entorno de ejecución y del controlador pueden enmascarar las medidas de api
El tiempo de ejecución tiene una optimización del rendimiento integrada que puede sobrecargar la medición de una llamada individual. Este es un escenario de ejemplo que muestra este problema. Tenga en cuenta la siguiente secuencia de representación:
BeginScene();
...
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
...
EndScene();
Present();
Ejemplo 1: Secuencia de representación simple
Al examinar los resultados de las dos llamadas de la secuencia de representación, un generador de perfiles de instrumentación podría devolver resultados similares a estos:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 950,500
El generador de perfiles devuelve el número de ciclos de CPU necesarios para procesar el trabajo asociado a cada llamada (recuerde que la GPU no se incluye en estos números porque la GPU aún no ha empezado a trabajar en estos comandos). Dado que IDirect3DDevice9::D rawPrimitive requería casi un millón de ciclos para procesarse, podría concluir que no es muy eficaz. Sin embargo, pronto verá por qué esta conclusión es incorrecta y cómo puede generar resultados que se pueden usar para el presupuesto.
La medición de los cambios de estado requiere secuencias de representación cuidadosas
Todas las llamadas que no sean IDirect3DDevice9::D rawPrimitive, DrawIndexedPrimitive o Clear (como SetTexture, SetVertexDeclaration y SetRenderState) producen un cambio de estado. Cada cambio de estado establece el estado de canalización que controla cómo se realizará la representación.
Las optimizaciones en tiempo de ejecución o el controlador están diseñadas para acelerar la representación al reducir la cantidad de trabajo necesario. A continuación se muestran un par de optimizaciones de cambios de estado que pueden contaminar los promedios de perfil:
- Un controlador (o el tiempo de ejecución) podría guardar un cambio de estado como un estado local. Dado que el controlador podría funcionar en un algoritmo "diferido" (posponer el trabajo hasta que sea absolutamente necesario), el trabajo asociado a algunos cambios de estado podría retrasarse.
- El tiempo de ejecución (o un controlador) puede quitar los cambios de estado mediante la optimización. Un ejemplo de esto podría ser quitar un cambio de estado redundante que deshabilita la iluminación porque la iluminación se ha deshabilitado anteriormente.
No hay ninguna manera infalible de examinar una secuencia de representación y concluir qué cambios de estado establecerán un bit sucio y aplazarán el trabajo, o simplemente se quitarán mediante optimización. Incluso si podría identificar los cambios de estado optimizados en el tiempo de ejecución o el controlador de hoy en día, es probable que se actualice el tiempo de ejecución o el controlador del mañana. Tampoco sabe fácilmente cuál era el estado anterior, por lo que es difícil identificar los cambios de estado redundantes. La única manera de comprobar el costo de un cambio de estado es medir la secuencia de representación que incluye los cambios de estado.
Como puede ver, las complicaciones causadas por tener varios procesadores, comandos procesados por más de un componente y optimizaciones integradas en los componentes dificultan la generación de perfiles. En la sección siguiente, se abordarán cada uno de estos desafíos de generación de perfiles. Se mostrarán secuencias de representación de Direct3D de ejemplo, con las técnicas de medición complementarias. Con este conocimiento, podrá generar mediciones precisas y repetibles en llamadas individuales.
Cómo generar perfiles precisos de una secuencia de representación de Direct3D
Ahora que se han resaltado algunos de los desafíos de generación de perfiles, en esta sección se muestran técnicas que le ayudarán a generar medidas de perfil que se pueden usar para el presupuesto. Las medidas de generación de perfiles repetibles y precisas son posibles si comprende la relación entre los componentes controlados por la CPU y cómo evitar optimizaciones de rendimiento implementadas por el tiempo de ejecución y el controlador.
Para empezar, debe poder medir con precisión el tiempo de ejecución de una sola llamada API.
Elegir una herramienta de medición precisa como QueryPerformanceCounter
El sistema operativo Microsoft Windows incluye un temporizador de alta resolución que se puede usar para medir tiempos transcurridos de alta resolución. El valor actual de un temporizador de este tipo se puede devolver mediante QueryPerformanceCounter. Después de invocar QueryPerformanceCounter para devolver valores de inicio y detención, la diferencia entre los dos valores se puede convertir al tiempo transcurrido real (en segundos) mediante QueryPerformanceCounter.
Las ventajas de usar QueryPerformanceCounter son que está disponible en Windows y es fácil de usar. Basta con rodear las llamadas con una llamada QueryPerformanceCounter y guardar los valores de inicio y detención. Por lo tanto, en este documento se muestra cómo usar QueryPerformanceCounter para generar perfiles de tiempos de ejecución, de forma similar a la forma en que un generador de perfiles de instrumentación lo mediría. Este es un ejemplo que muestra cómo insertar QueryPerformanceCounter en el código fuente:
BeginScene();
...
// Start profiling
LARGE_INTEGER start, stop, freq;
QueryPerformanceCounter(&start);
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
QueryPerformanceCounter(&stop);
stop.QuadPart -= start.QuadPart;
QueryPerformanceFrequency(&freq);
// Stop profiling
...
EndScene();
Present();
Ejemplo 2: Implementación de generación de perfiles personalizada con QPC
start y stop son dos enteros grandes que contendrán los valores de inicio y detención devueltos por el temporizador de alto rendimiento. Observe que se llama a QueryPerformanceCounter(&start) justo antes de llamar a SetTexture y QueryPerformanceCounter(&stop) justo después de DrawPrimitive. Después de obtener el valor de detención, se llama a QueryPerformanceFrequency para devolver freq, que es la frecuencia del temporizador de alta resolución. En este ejemplo hipotético, supongamos que obtiene los siguientes resultados para iniciar, detener y freq:
| Variable local | Número de tics |
|---|---|
| start | 1792998845094 |
| stop | 1792998845102 |
| Freq | 3579545 |
Puede convertir estos valores en el número de ciclos que se tardan en ejecutar las llamadas API de la siguiente manera:
# ticks = (stop - start) = 1792998845102 - 1792998845094 = 8 ticks
# cycles = CPU speed * number of ticks / QPF
# 4568 = 2 GHz * 8 / 3,579,545
En otras palabras, se tardan unos 4568 ciclos de reloj para procesar SetTexture y DrawPrimitive en esta máquina de 2 GHz. Puede convertir estos valores en el tiempo real que tardó en ejecutar todas las llamadas como esta:
(stop - start)/ freq = elapsed time
8 ticks / 3,579,545 = 2.2E-6 seconds or between 2 and 3 microseconds.
El uso de QueryPerformanceCounter requiere que agregue medidas de inicio y detención a la secuencia de representación y use QueryPerformanceFrequency para convertir la diferencia (número de tics) al número de ciclos de CPU o al tiempo real. Identificar la técnica de medición es un buen comienzo para desarrollar una implementación de generación de perfiles personalizada. Pero antes de empezar a realizar mediciones, debe saber cómo tratar con la tarjeta de vídeo.
Centrarse en las medidas de CPU
Como se indicó anteriormente, la CPU y la GPU funcionan en paralelo para procesar el trabajo generado por las llamadas API. Una aplicación real requiere generar perfiles de ambos tipos de procesadores para averiguar si la aplicación está limitada por CPU o por GPU. Dado que el rendimiento de GPU es específico del proveedor, sería muy difícil producir resultados en este documento que cubren la variedad de tarjetas de vídeo disponibles.
En su lugar, este documento se centrará solo en la generación de perfiles del trabajo realizado por la CPU mediante una técnica personalizada para medir el tiempo de ejecución y el trabajo del controlador. El trabajo de GPU se reducirá a una cantidad insignificante, de modo que los resultados de la CPU sean más visibles. Una ventaja de este enfoque es que esta técnica produce resultados en el Apéndice que debe poder correlacionar con sus mediciones. Para reducir el trabajo requerido por la tarjeta de vídeo a un nivel insignificante, simplemente reduzca el trabajo de representación a la menor cantidad posible. Esto se puede lograr limitando las llamadas de dibujo para representar un único triángulo y se puede restringir aún más para que cada triángulo solo contenga un píxel.
La unidad de medida utilizada en este documento para medir el trabajo de CPU será el número de ciclos de reloj de CPU en lugar de tiempo real. Los ciclos de reloj de CPU tienen la ventaja de que es más portátil (para aplicaciones limitadas por CPU) que el tiempo transcurrido real entre máquinas con diferentes velocidades de CPU. Esto se puede convertir fácilmente en tiempo real si lo desea.
En este documento no se tratan temas relacionados con el equilibrio de la carga de trabajo entre la CPU y la GPU. Recuerde que el objetivo de este documento no es medir el rendimiento general de una aplicación, sino mostrar cómo medir con precisión el tiempo de ejecución y el controlador para procesar las llamadas API. Con estas medidas precisas, puede asumir la tarea de presupuestar la CPU para comprender determinados escenarios de rendimiento.
Controlar el entorno de ejecución y las optimizaciones de controladores
Con una técnica de medición identificada y una estrategia para reducir el trabajo de GPU, el siguiente paso es comprender el tiempo de ejecución y las optimizaciones de controladores que se producen al generar perfiles.
El trabajo de CPU se puede dividir en tres cubos: el trabajo de la aplicación, el trabajo en tiempo de ejecución y el trabajo del controlador. Ignore el trabajo de la aplicación, ya que esto está bajo control del programador. Desde el punto de vista de la aplicación, el tiempo de ejecución y el controlador son como cajas negras, ya que la aplicación no tiene control sobre lo que se implementa en ellos. La clave es comprender las técnicas de optimización que se pueden implementar en el entorno de ejecución y el controlador. Si no entiende estas optimizaciones, es muy fácil saltar a la conclusión incorrecta sobre la cantidad de trabajo que realiza la CPU en función de las medidas del perfil. En concreto, hay dos temas relacionados con algo denominado búfer de comandos y lo que puede hacer para ofuscar la generación de perfiles. Estos temas son:
- Optimización en tiempo de ejecución con el búfer de comandos. El búfer de comandos es una optimización en tiempo de ejecución que reduce el impacto de una transición de modo. Para controlar el tiempo de transición del modo, consulte Control del búfer de comandos.
- Negación de los efectos de tiempo del búfer de comandos. El tiempo transcurrido de una transición de modo puede tener un gran impacto en las medidas de generación de perfiles. La estrategia para esto es hacer que la secuencia de representación sea grande en comparación con la transición en modo.
Controlar el búfer de comandos
Cuando una aplicación realiza una llamada API, el tiempo de ejecución convierte la llamada API a un formato independiente del dispositivo (que llamaremos a un comando) y lo almacena en el búfer de comandos. El búfer de comandos se agrega al diagrama siguiente.
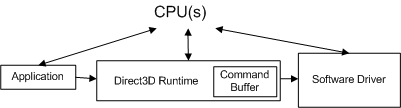
Cada vez que la aplicación realiza otra llamada API, el tiempo de ejecución repite esta secuencia y agrega otro comando al búfer de comandos. En algún momento, el tiempo de ejecución vacía el búfer (enviando los comandos al controlador). En Windows XP, al vaciar el búfer de comandos, se produce una transición de modo a medida que el sistema operativo cambia del tiempo de ejecución (que se ejecuta en modo de usuario) al controlador (que se ejecuta en modo kernel), como se muestra en el diagrama siguiente.
- modo de usuario: el modo de procesador sin privilegios que ejecuta el código de la aplicación. Las aplicaciones en modo de usuario no pueden obtener acceso a los datos del sistema, excepto a través de servicios del sistema.
- modo kernel: modo de procesador con privilegios en el que se ejecuta el código ejecutivo basado en Windows. Un controlador o subproceso que se ejecuta en modo kernel tiene acceso a toda la memoria del sistema, acceso directo al hardware y las instrucciones de CPU para realizar E/S con el hardware.
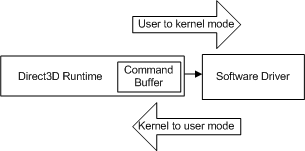
La transición se produce cada vez que la CPU cambia del modo de usuario al kernel (y viceversa) y el número de ciclos que requiere es grande en comparación con una llamada API individual. Si el tiempo de ejecución envió cada llamada API al controlador cuando se invocó, cada llamada API incurriría en el costo de una transición de modo.
En su lugar, el búfer de comandos es una optimización en tiempo de ejecución diseñada para reducir el costo efectivo de la transición del modo. El búfer de comandos pone en cola muchos comandos de controlador como preparación para una transición en modo único. Cuando el tiempo de ejecución agrega un comando al búfer de comandos, el control se devuelve a la aplicación. Un generador de perfiles no tiene forma de saber que los comandos del controlador probablemente aún no se hayan enviado al controlador. Como resultado, los números devueltos por un generador de perfiles de instrumentación fuera del estante son engañosos, ya que mide el trabajo en tiempo de ejecución, pero no el trabajo del controlador asociado.
Resultados del perfil sin una transición de modo
Con la secuencia de representación del ejemplo 2, estas son algunas medidas de tiempo típicas que ilustran la magnitud de una transición de modo. Suponiendo que las llamadas a SetTexture y DrawPrimitive no provocan una transición de modo, un generador de perfiles de instrumentación fuera del estante podría devolver resultados similares a estos:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Cada uno de estos números es la cantidad de tiempo que tarda el tiempo de ejecución en agregar estas llamadas al búfer de comandos. Puesto que no hay ninguna transición en modo, el controlador aún no ha realizado ningún trabajo. Los resultados del generador de perfiles son precisos, pero no miden todo el trabajo que la secuencia de representación hará que la CPU se realice.
Generar perfiles de resultados con una transición en modo
Ahora, examine lo que sucede en el mismo ejemplo cuando se produce una transición de modo. En esta ocasión, supongamos que SetTexture y DrawPrimitive provocan una transición de modo. Una vez más, un generador de perfiles de instrumentación fuera del estante podría devolver resultados similares a estos:
Number of cycles for SetTexture : 98
Number of cycles for DrawPrimitive : 946,900
El tiempo medido para SetTexture es aproximadamente el mismo, pero el aumento dramático en la cantidad de tiempo invertido en DrawPrimitive se debe a la transición del modo. Esto es lo que sucede:
- Supongamos que el búfer de comandos tiene espacio para un comando antes de que se inicie la secuencia de representación.
- SetTexture se convierte en un formato independiente del dispositivo y se agrega al búfer de comandos. En este escenario, esta llamada rellena el búfer de comandos.
- El tiempo de ejecución intenta agregar DrawPrimitive al búfer de comandos, pero no puede, porque está lleno. En su lugar, el tiempo de ejecución vacía el búfer de comandos. Esto provoca la transición del modo kernel. Supongamos que la transición tarda unos 5000 ciclos. Este tiempo contribuye al tiempo invertido en DrawPrimitive.
- A continuación, el controlador procesa el trabajo asociado a todos los comandos que se vaciaron del búfer de comandos. Supongamos que el tiempo del controlador para procesar los comandos que casi rellenan el búfer de comandos es de aproximadamente 935 000 ciclos. Supongamos que el trabajo del controlador asociado a SetTexture es de aproximadamente 2750 ciclos. Este tiempo contribuye al tiempo invertido en DrawPrimitive.
- Cuando el controlador finaliza su trabajo, la transición en modo de usuario devuelve el control al tiempo de ejecución. El búfer de comandos ahora está vacío. Supongamos que la transición tarda unos 5000 ciclos.
- La secuencia de representación finaliza convirtiendo DrawPrimitive y agregándola al búfer de comandos. Supongamos que esto tarda unos 900 ciclos. Este tiempo contribuye al tiempo invertido en DrawPrimitive.
Al resumir los resultados, verá lo siguiente:
DrawPrimitive = kernel-transition + driver work + user-transition + runtime work
DrawPrimitive = 5000 + 935,000 + 2750 + 5000 + 900
DrawPrimitive = 947,950
Al igual que la medida de DrawPrimitive sin la transición del modo (900 ciclos), la medición de DrawPrimitive con la transición de modo (947.950 ciclos) es precisa pero inútil en términos de trabajo presupuestado de cpu. El resultado contiene el trabajo en tiempo de ejecución correcto, el trabajo del controlador para SetTexture, el trabajo del controlador para los comandos que preceden a SetTexture y dos transiciones de modo. Sin embargo, la medida falta el trabajo del controlador DrawPrimitive .
Una transición de modo podría producirse en respuesta a cualquier llamada. Depende de lo que se encontraba anteriormente en el búfer de comandos. Debe controlar la transición del modo para comprender cuánto trabajo de CPU (tiempo de ejecución y controlador) está asociado a cada llamada. Para ello, necesita un mecanismo para controlar el búfer de comandos y el tiempo de la transición del modo.
Mecanismo de consulta
El mecanismo de consulta de Microsoft Direct3D 9 se diseñó para permitir que el tiempo de ejecución consultara la GPU para el progreso y devolver determinados datos de la GPU. Durante la generación de perfiles, si el trabajo de GPU se minimiza para que tenga un impacto insignificante en el rendimiento, puede devolver el estado de la GPU para ayudar a medir el trabajo del controlador. Después de todo, el trabajo del controlador se completa cuando la GPU ha visto los comandos del controlador. Además, el mecanismo de consulta se puede canalizar para controlar dos características de búfer de comandos que son importantes para la generación de perfiles: cuando el búfer de comandos vacía y cuánto trabajo hay en el búfer.
Esta es la misma secuencia de representación mediante el mecanismo de consulta:
// 1. Create an event query from the current device
IDirect3DQuery9* pEvent;
m_pD3DDevice->CreateQuery(D3DQUERYTYPE_EVENT, &pEvent);
// 2. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 3. Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 4. Start profiling
LARGE_INTEGER start, stop;
QueryPerformanceCounter(&start);
// 5. Invoke the API calls to be profiled.
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 1);
// 6. Add an end marker to the command buffer queue.
pEvent->Issue(D3DISSUE_END);
// 7. Force the driver to execute the commands from the command buffer.
// Empty the command buffer and wait until the GPU is idle.
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
// 8. End profiling
QueryPerformanceCounter(&stop);
Ejemplo 3: Usar una consulta para controlar el búfer de comandos
Esta es una explicación más detallada de cada una de estas líneas de código:
- Cree una consulta de eventos mediante la creación de un objeto de consulta con D3DQUERYTYPE_EVENT.
- Agregue un marcador de evento de consulta al búfer de comandos mediante una llamada a Issue(D3DISSUE_END). Este marcador indica al controlador que realice un seguimiento cuando la GPU termine de ejecutar los comandos que preceden al marcador.
- La primera llamada vacía el búfer de comandos porque al llamar a GetData con D3DGETDATA_FLUSH obliga a vaciar el búfer de comandos. Cada llamada posterior comprueba la GPU para ver cuándo termina de procesar todo el trabajo del búfer de comandos. Este bucle no devuelve S_OK hasta que la GPU está inactiva.
- Muestree la hora de inicio.
- Invoque las llamadas API que se generan perfiles.
- Agregue un segundo marcador de evento de consulta al búfer de comandos. Este marcador se usará para realizar un seguimiento de la finalización de las llamadas.
- La primera llamada vacía el búfer de comandos porque al llamar a GetData con D3DGETDATA_FLUSH obliga a vaciar el búfer de comandos. Cuando la GPU termina de procesar todo el trabajo del búfer de comandos, GetData devuelve S_OK y el bucle se cierra porque la GPU está inactiva.
- Muestree la hora de detención.
Estos son los resultados medidos con QueryPerformanceCounter y QueryPerformanceFrequency:
| Variable local | Número de tics |
|---|---|
| start | 1792998845060 |
| stop | 1792998845090 |
| Freq | 3579545 |
Convertir tics en ciclos una vez más (en una máquina de 2 GHz):
# ticks = (stop - start) = 1792998845090 - 1792998845060 = 30 ticks
# cycles = CPU speed * number of ticks / QPF
# 16,450 = 2 GHz * 30 / 3,579,545
Este es el desglose del número de ciclos por llamada:
Number of cycles for SetTexture : 100
Number of cycles for DrawPrimitive : 900
Number of cycles for Issue : 200
Number of cycles for GetData : 16,450
El mecanismo de consulta nos ha permitido controlar el tiempo de ejecución y el trabajo del controlador que se está midiendo. Para comprender cada uno de estos números, esto es lo que sucede en respuesta a cada una de las llamadas API, junto con los intervalos estimados:
La primera llamada vacía el búfer de comandos llamando a GetData con D3DGETDATA_FLUSH. Cuando la GPU termina de procesar todo el trabajo del búfer de comandos, GetData devuelve S_OK y el bucle se cierra porque la GPU está inactiva.
La secuencia de representación comienza convirtiendo SetTexture en un formato independiente del dispositivo y agregándolo al búfer de comandos. Supongamos que esto tarda unos 100 ciclos.
DrawPrimitive se convierte y se agrega al búfer de comandos. Supongamos que esto tarda unos 900 ciclos.
El problema agrega un marcador de consulta al búfer de comandos. Supongamos que esto tarda unos 200 ciclos.
GetData hace que el búfer de comandos se vacíe, lo que fuerza la transición del modo kernel. Supongamos que esto tarda unos 5000 ciclos.
A continuación, el controlador procesa el trabajo asociado a las cuatro llamadas. Supongamos que el tiempo del controlador para procesar SetTexture es de aproximadamente 2964 ciclos, DrawPrimitive es de aproximadamente 3600 ciclos, Issue es de aproximadamente 200 ciclos. Por lo tanto, el tiempo total del controlador para los cuatro comandos es de aproximadamente 6450 ciclos.
Nota
El controlador también tarda un poco en ver cuál es el estado de la GPU. Dado que el trabajo de la GPU es trivial, la GPU ya debe realizarse. GetData devolverá S_OK en función de la probabilidad de que finalice la GPU.
Cuando el controlador finaliza su trabajo, la transición en modo de usuario devuelve el control al tiempo de ejecución. El búfer de comandos ahora está vacío. Supongamos que esto tarda unos 5000 ciclos.
Los números de GetData incluyen:
GetData = kernel-transition + driver work + user-transition
GetData = 5000 + 6450 + 5000
GetData = 16,450
driver work = SetTexture + DrawPrimitive + Issue =
driver work = 2964 + 3600 + 200 = 6450 cycles
El mecanismo de consulta usado en combinación con QueryPerformanceCounter mide todo el trabajo de CPU. Esto se hace con una combinación de marcadores de consulta y comparaciones de estado de consulta. Los marcadores de consulta de inicio y detención agregados al búfer de comandos se usan para controlar cuánto trabajo hay en el búfer. Al esperar hasta que se devuelva el código de retorno correcto, la medida de inicio se realiza justo antes de que se inicie una secuencia de representación limpia y la medida de detención se realiza justo después de que el controlador haya terminado el trabajo asociado con el contenido del búfer de comandos. Esto captura eficazmente el trabajo de CPU realizado por el tiempo de ejecución, así como el controlador.
Ahora que conoce el búfer de comandos y el efecto que puede tener en la generación de perfiles, debe saber que hay otras condiciones que pueden hacer que el tiempo de ejecución vacíe el búfer de comandos. Debe watch para estos en las secuencias de representación. Algunas de estas condiciones se encuentran en respuesta a las llamadas API, otras se encuentran en respuesta a los cambios de recursos en el tiempo de ejecución. Cualquiera de las condiciones siguientes provocará una transición de modo:
- Cuando se llama a uno de los métodos de bloqueo (Lock) en un búfer de vértices, un búfer de índice o una textura (en determinadas condiciones con determinadas marcas).
- Cuando se crea un búfer de vértices o un dispositivo, un búfer de índice o una textura.
- Cuando el último lanzamiento destruye un búfer de vértices o un búfer de vértices, un búfer de índice o una textura.
- Cuando se llama a ValidateDevice .
- Cuando se llama a Present .
- Cuando el búfer de comandos se rellena.
- Cuando se llama a GetData con D3DGETDATA_FLUSH.
Tenga cuidado de watch para estas condiciones en las secuencias de representación. Cada vez que se agrega una transición de modo, se agregarán 10 000 ciclos de trabajo del controlador a las medidas de generación de perfiles. Además, el búfer de comandos no tiene un tamaño estático. El tiempo de ejecución puede cambiar el tamaño del búfer en respuesta a la cantidad de trabajo que genera la aplicación. Esta es otra optimización que depende de una secuencia de representación.
Por lo tanto, tenga cuidado de controlar las transiciones del modo durante la generación de perfiles. El mecanismo de consulta ofrece un método sólido para vaciar el búfer de comandos para que pueda controlar el tiempo de la transición del modo, así como la cantidad de trabajo que contiene el búfer. Sin embargo, incluso esta técnica se puede mejorar reduciendo el tiempo de transición del modo para que sea insignificante con respecto al resultado medido.
Hacer que la secuencia de representación sea grande en comparación con la transición del modo
En el ejemplo anterior, el conmutador en modo kernel y el conmutador en modo de usuario consumen aproximadamente 10 000 ciclos que no tienen nada que ver con el tiempo de ejecución y el trabajo del controlador. Puesto que la transición del modo está integrada en el sistema operativo, no se puede reducir a cero. Para que la transición del modo sea insignificante, la secuencia de representación debe ajustarse para que el controlador y el trabajo en tiempo de ejecución sean un orden de magnitud mayor que los conmutadores de modo. Podría intentar realizar una resta para quitar las transiciones, pero amortizar el costo en un costo de secuencia de representación mucho mayor es más confiable.
La estrategia para reducir la transición del modo hasta que se convierte en insignificante es agregar un bucle a la secuencia de representación. Por ejemplo, echemos un vistazo a los resultados de generación de perfiles si se agrega un bucle que repetirá la secuencia de representación 1500 veces:
// Initialize the array with two textures, same size, same format
IDirect3DTexture* texArray[2];
CreateQuery(D3DQUERYTYPE_EVENT, pEvent);
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
LARGE_INTEGER start, stop;
// Now start counting because the video card is ready
QueryPerformanceCounter(&start);
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
SetTexture(taxArray[i%2]);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
pEvent->Issue(D3DISSUE_END);
while(S_FALSE == pEvent->GetData( NULL, 0, D3DGETDATA_FLUSH ))
;
QueryPerformanceCounter(&stop);
Ejemplo 4: Agregar un bucle a la secuencia de representación
Estos son los resultados medidos con QueryPerformanceCounter y QueryPerformanceFrequency:
| Variable local | Número de tics |
|---|---|
| start | 1792998845000 |
| stop | 1792998847084 |
| Freq | 3579545 |
El uso de QueryPerformanceCounter mide ahora 2840 tics. La conversión de tics en ciclos es la misma que ya hemos mostrado:
# ticks = (stop - start) = 1792998847084 - 1792998845000 = 2840 ticks
# cycles = machine speed * number of ticks / QPF
# 6,900,000 = 2 GHz * 2840 / 3,579,545
En otras palabras, se tardan unos 6,9 millones de ciclos en esta máquina de 2 GHz para procesar las llamadas de 1500 en el bucle de representación. De los 6,9 millones de ciclos, la cantidad de tiempo en las transiciones de modo es de aproximadamente 10 000, por lo que ahora los resultados del perfil están casi completamente midiendo el trabajo asociado a SetTexture y DrawPrimitive.
Observe que el ejemplo de código requiere una matriz de dos texturas. Para evitar una optimización en tiempo de ejecución que quitaría SetTexture si establece el mismo puntero de textura cada vez que se llama, simplemente use una matriz de dos texturas. De este modo, cada vez que se recorre el bucle, cambia el puntero de textura y se realiza el trabajo completo asociado a SetTexture . Asegúrese de que ambas texturas tienen el mismo tamaño y formato, por lo que ningún otro estado cambiará cuando la textura lo haga.
Y ahora tiene una técnica para generar perfiles de Direct3D. Se basa en el contador de alto rendimiento (QueryPerformanceCounter) para registrar el número de tics que tarda la CPU en procesar el trabajo. El trabajo se controla cuidadosamente para que sea el tiempo de ejecución y el trabajo del controlador asociados a las llamadas API mediante el mecanismo de consulta. Una consulta proporciona dos medios de control: primero para vaciar el búfer de comandos antes de que se inicie la secuencia de representación y, en segundo lugar, devolver cuando finalice el trabajo de GPU.
Hasta ahora, este documento ha mostrado cómo generar perfiles de una secuencia de representación. Cada secuencia de representación ha sido bastante sencilla, que contiene una sola llamada DrawPrimitive y una llamada a SetTexture . Esto se hizo para centrarse en el búfer de comandos y el uso del mecanismo de consulta para controlarlo. Este es un breve resumen de cómo generar perfiles de una secuencia de representación arbitraria:
- Use un contador de alto rendimiento como QueryPerformanceCounter para medir el tiempo necesario para procesar cada llamada API. Use QueryPerformanceFrequency y la velocidad de reloj de CPU para convertirla en el número de ciclos de CPU por llamada API.
- Minimice la cantidad de trabajo de GPU mediante la representación de listas de triángulos, donde cada triángulo contiene un píxel.
- Use el mecanismo de consulta para vaciar el búfer de comandos antes de la secuencia de representación. Esto garantiza que la generación de perfiles capturará la cantidad correcta de trabajo del motor y el tiempo de ejecución asociados a la secuencia de representación.
- Controlar la cantidad de trabajo agregado al búfer de comandos con marcadores de eventos de consulta. Esta misma consulta detecta cuándo la GPU finaliza su trabajo. Dado que el trabajo de GPU es trivial, esto es prácticamente equivalente a medir cuando se completa el trabajo del controlador.
Todas estas técnicas se usan para generar perfiles de cambios de estado. Suponiendo que ha leído y comprendido cómo controlar el búfer de comandos y ha completado correctamente las medidas de línea base en DrawPrimitive, está listo para agregar cambios de estado a las secuencias de representación. Hay algunos desafíos adicionales de generación de perfiles al agregar cambios de estado a una secuencia de representación. Si piensa agregar cambios de estado a las secuencias de representación, asegúrese de continuar en la sección siguiente.
Generación de perfiles de cambios de estado de Direct3D
Direct3D usa muchos estados de representación para controlar casi todos los aspectos de la canalización. Las API que provocan cambios de estado incluyen cualquier función o método distinto de las llamadas Draw*Primitive.
Los cambios de estado son complicados porque es posible que no pueda ver el costo de un cambio de estado sin representación. Este es un resultado del algoritmo diferido que el controlador y la GPU usan para aplazar el trabajo hasta que sea absolutamente necesario realizar. En general, debe seguir estos pasos para medir un único cambio de estado:
- Perfil DrawPrimitive primero.
- Agregue un cambio de estado a la secuencia de representación y perfile la nueva secuencia.
- Resta la diferencia entre las dos secuencias para obtener el costo del cambio de estado.
Naturalmente, todo lo que ha aprendido sobre el uso del mecanismo de consulta y la colocación de la secuencia de representación en un bucle para negar el costo de la transición del modo sigue siendo aplicable.
Generación de perfiles de un cambio de estado simple
A partir de una secuencia de representación que contiene DrawPrimitive, esta es la secuencia de código para medir el costo de agregar SetTexture:
// Get the start counter value as shown in Example 4
// Initialize a texture array as shown in Example 4
IDirect3DTexture* texArray[2];
// Render sequence loop
for(int i = 0; i < 1500; i++)
{
SetTexture(0, texArray[i%2];
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
// Get the stop counter value as shown in Example 4
Ejemplo 5: Medición de una llamada API de cambio de estado
Observe que el bucle contiene dos llamadas, SetTexture y DrawPrimitive. La secuencia de representación recorre 1500 veces y genera resultados similares a estos:
| Variable local | Número de tics |
|---|---|
| start | 1792998860000 |
| stop | 1792998870260 |
| Freq | 3579545 |
La conversión de tics en ciclos vuelve a generar:
# ticks = (stop - start) = 1792998870260 - 1792998860000 = 10,260 ticks
# cycles = machine speed * number of ticks / QPF
5,775,000 = 2 GHz * 10,260 / 3,579,545
Dividir por el número de iteraciones en el bucle produce:
5,775,000 cycles / 1500 iterations = 3850 cycles for one iteration
Cada iteración del bucle contiene un cambio de estado y una llamada a draw. Restando el resultado de las hojas de la secuencia de representación DrawPrimitive :
3850 - 1100 = 2750 cycles for SetTexture
Este es el número medio de ciclos para agregar SetTexture a esta secuencia de representación. Esta misma técnica se puede aplicar a otros cambios de estado.
¿Por qué SetTexture se denomina cambio de estado simple? Dado que el estado que se establece está restringido para que la canalización realice la misma cantidad de trabajo cada vez que cambie el estado. La restricción de ambas texturas al mismo tamaño y formato garantiza la misma cantidad de trabajo para cada llamada a SetTexture .
Generación de perfiles de un cambio de estado que se debe alternar
Hay otros cambios de estado que hacen que la cantidad de trabajo realizado por la canalización de gráficos cambie para cada iteración del bucle de representación. Por ejemplo, si z-testing está habilitado, cada color de píxel actualiza un destino de representación solo después de probar el valor z del nuevo píxel con respecto al valor z del píxel existente. Si z-testing está deshabilitado, esta prueba por píxel no se realiza y la salida se escribe mucho más rápido. Habilitar o deshabilitar el estado de prueba z cambia drásticamente la cantidad de trabajo realizado (por la CPU, así como la GPU) durante la representación.
SetRenderState requiere un estado de representación determinado y un valor de estado para habilitar o deshabilitar z-testing. El valor de estado concreto se evalúa en tiempo de ejecución para determinar cuánto trabajo es necesario. Es difícil medir este cambio de estado en un bucle de representación y seguir condición previa del estado de la canalización para que cambie. La única solución es alternar el cambio de estado durante la secuencia de representación.
Por ejemplo, la técnica de generación de perfiles debe repetirse dos veces de la siguiente manera:
- Empiece por generar perfiles de la secuencia de representación DrawPrimitive . Llame a esta línea base.
- Generar perfiles de una segunda secuencia de representación que alterna el cambio de estado. El bucle de secuencia de representación contiene:
- Cambio de estado para establecer el estado en una condición "false".
- DrawPrimitive como la secuencia original.
- Cambio de estado para establecer el estado en una condición "true".
- Un segundo DrawPrimitive para forzar que se realice el segundo cambio de estado.
- Busque la diferencia entre las dos secuencias de representación. Para hacer esto:
- Multiplique la secuencia DrawPrimitive de línea base por 2 porque hay dos llamadas DrawPrimitive en la nueva secuencia.
- Resta el resultado de la nueva secuencia de la secuencia original.
- Divida el resultado en 2 para obtener el costo medio de los cambios de estado "false" y "true".
Con la técnica de bucle usada en la secuencia de representación, el costo de cambiar el estado de la canalización debe medirse alternando el estado de una condición "true" a una condición "false" y viceversa, para cada iteración de la secuencia de representación. El significado de "true" y "false" aquí no son literales, esto simplemente significa que el estado debe establecerse en condiciones opuestas. Esto hace que ambos cambios de estado se mida durante la generación de perfiles. Por supuesto, todo lo que ha aprendido sobre el uso del mecanismo de consulta y la colocación de la secuencia de representación en un bucle para negar el costo de la transición del modo todavía se aplica.
Por ejemplo, esta es la secuencia de código para medir el costo de activar o desactivar las pruebas z:
// Get the start counter value as shown in Example 4
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the "false" condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Set the pipeline state to the "true" condition
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
// Get the stop counter value as shown in Example 4
Ejemplo 5: Medición de un cambio de estado de alternancia
El bucle alterna el estado ejecutando dos llamadas a SetRenderState . La primera llamada a SetRenderState deshabilita z-testing y la segunda SetRenderState habilita z-testing. Cada SetRenderState va seguido de DrawPrimitive para que el controlador procese el trabajo asociado al cambio de estado en lugar de establecer un bit sucio en el controlador.
Estos números son razonables para esta secuencia de representación:
| Variable local | Número de tics |
|---|---|
| start | 1792998845000 |
| stop | 1792998861740 |
| Freq | 3579545 |
La conversión de tics en ciclos vuelve a generar:
# ticks = (stop - start) = 1792998861740 - 1792998845000 = 15,120 ticks
# cycles = machine speed * number of ticks / QPF
9,300,000 = 2 GHz * 16,740 / 3,579,545
Dividir por el número de iteraciones en el bucle produce:
9,300,000 cycles / 1500 iterations = 6200 cycles for one iteration
Cada iteración del bucle contiene dos cambios de estado y dos llamadas de dibujo. Restando las llamadas de dibujo (suponiendo 1100 ciclos):
6200 - 1100 - 1100 = 4000 cycles for both state changes
Este es el número medio de ciclos para ambos cambios de estado, por lo que el tiempo medio de cada cambio de estado es:
4000 / 2 = 2000 cycles for each state change
Por lo tanto, el número medio de ciclos para habilitar o deshabilitar las pruebas z es de 2000 ciclos. Cabe destacar que QueryPerformanceCounter mide la mitad del tiempo y z deshabilita la mitad del tiempo. Esta técnica mide realmente el promedio de ambos cambios de estado. En otras palabras, está midiendo el tiempo para alternar un estado. Con esta técnica, no tiene ninguna manera de saber si las horas de habilitación y deshabilitación son equivalentes, ya que ha medido el promedio de ambos. Sin embargo, se trata de un número razonable que se usa al presupuestar un estado de alternancia como una aplicación que provoca este cambio de estado solo puede hacerlo alternando este estado.
Por lo tanto, ahora puede aplicar estas técnicas y generar perfiles de todos los cambios de estado que desee, ¿verdad? No del todo. Todavía debe tener cuidado con las optimizaciones diseñadas para reducir la cantidad de trabajo que debe realizarse. Hay dos tipos de optimizaciones que debe tener en cuenta al diseñar las secuencias de representación.
Cuidado con las optimizaciones de cambios de estado
En la sección anterior se muestra cómo generar perfiles de ambos tipos de cambios de estado: un cambio de estado simple que está restringido para generar la misma cantidad de trabajo para cada iteración y un cambio de estado de alternancia que cambia drásticamente la cantidad de trabajo realizado. ¿Qué ocurre si toma la secuencia de representación anterior y agrega otro cambio de estado? Por ejemplo, en este ejemplo se toma la secuencia de representación z-enable> y se agrega una comparación z-func:
// Add a loop to the render sequence
for(int i = 0; i < 1500; i++)
{
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZFUNC, D3DCMP_NEVER);
// Precondition the pipeline state to the opposite condition
SetRenderState(D3DRS_ZENABLE, FALSE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 0)*3, 1);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZFUNC, D3DCMP_ALWAYS);
// Now set the state change you want to measure
SetRenderState(D3DRS_ZENABLE, TRUE);
// Force the state change to propagate to the GPU
DrawPrimitive(D3DPT_TRIANGLELIST, (2*i + 1)*3, 1);
}
El estado z-func establece el nivel de comparación al escribir en el búfer z (entre el valor z de un píxel actual con el valor z de un píxel en el búfer de profundidad). D3DCMP_NEVER desactiva la comparación de pruebas z mientras D3DCMP_ALWAYS establece la comparación para que se produzca cada vez que se realiza z-testing.
La generación de perfiles de cualquiera de estos cambios de estado en una secuencia de representación con DrawPrimitive genera resultados similares a estos:
| Cambio de estado único | Número medio de ciclos |
|---|---|
| solo D3DRS_ZENABLE | 2000 |
or
| Cambio de estado único | Número medio de ciclos |
|---|---|
| solo D3DRS_ZFUNC | 600 |
Sin embargo, si genera perfiles de D3DRS_ZENABLE y D3DRS_ZFUNC en la misma secuencia de representación, podría ver resultados como estos:
| Ambos cambios de estado | Número medio de ciclos |
|---|---|
| D3DRS_ZENABLE + D3DRS_ZFUNC | 2000 |
Podría esperar que el resultado sea la suma de 2000 y 600 ciclos (o 2600) porque el controlador está realizando todo el trabajo asociado con la configuración de ambos estados de representación. En su lugar, el promedio es de 2000 ciclos.
Este resultado refleja una optimización de cambios de estado implementada en tiempo de ejecución, el controlador o la GPU. En este caso, el controlador podría ver el primer SetRenderState y establecer un estado sucio que pospondría el trabajo hasta más adelante. Cuando el controlador ve el segundo SetRenderState, el mismo estado sucio podría establecerse redundantemente y el mismo trabajo se pospondría una vez más. Cuando se llama a DrawPrimitive , finalmente se procesa el trabajo asociado al estado sucio. El controlador ejecuta el trabajo una vez, lo que significa que el controlador consolida eficazmente los dos primeros cambios de estado. Del mismo modo, el controlador consolida eficazmente los cambios de estado tercero y cuarto en un solo cambio de estado cuando se llama al segundo DrawPrimitive . El resultado neto es que el controlador y la GPU procesan un único cambio de estado para cada llamada a draw.
Este es un buen ejemplo de una optimización de controladores dependientes de la secuencia. El controlador pospuso el trabajo dos veces estableciendo un estado sucio y, a continuación, realizó el trabajo una vez para borrar el estado desfasado. Este es un buen ejemplo del tipo de mejora de la eficiencia que puede tener lugar cuando el trabajo se aplaza hasta que sea absolutamente necesario.
¿Cómo sabe qué cambios de estado establecen un estado sucio internamente y, por tanto, posponer el trabajo hasta más tarde? Solo mediante la prueba de secuencias de representación (o hablando con escritores de controladores). Los controladores se actualizan y mejoran periódicamente para que la lista de optimizaciones no sea estática. Solo hay una manera de saber absolutamente cuál es el costo de un cambio de estado en una secuencia de representación determinada, en un conjunto determinado de hardware; y eso es medirlo.
Cuidado con las optimizaciones drawPrimitive
Además de las optimizaciones de cambio de estado, el tiempo de ejecución intentará optimizar el número de llamadas de dibujo que el controlador tiene que procesar. Por ejemplo, considere estas opciones de vuelta a llamadas de dibujo inversas:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 3); // Draw 3 primitives, vertices 0 - 8
DrawPrimitive(D3DPT_TRIANGLELIST, 9, 4); // Draw 4 primitives, vertices 9 - 20
Ejemplo 5a: dos llamadas de draw
Esta secuencia contiene dos llamadas de dibujo, que el tiempo de ejecución consolidará en una sola llamada equivalente a:
DrawPrimitive(D3DPT_TRIANGLELIST, 0, 7); // Draw 7 primitives, vertices 0 - 20
Ejemplo 5b: una sola llamada de dibujo concatenada
El tiempo de ejecución concatenará ambas llamadas a draw concretas en una sola llamada, lo que reduce el trabajo del controlador en un 50 por ciento, ya que el controlador ahora solo tendrá que procesar una llamada de dibujo.
En general, el tiempo de ejecución concatena dos o más llamadas drawPrimitive de back-to-back cuando:
- El tipo primitivo es una lista de triángulos (D3DPT_TRIANGLELIST).
- Cada llamada sucesiva a DrawPrimitive debe hacer referencia a vértices consecutivos dentro del búfer de vértices.
Del mismo modo, las condiciones adecuadas para concatenar dos o más llamadas de back-to-back DrawIndexedPrimitive son:
- El tipo primitivo es una lista de triángulos (D3DPT_TRIANGLELIST).
- Cada llamada sucesiva a DrawIndexedPrimitive debe hacer referencia secuencial a índices consecutivos dentro del búfer de índice.
- Cada llamada sucesiva a DrawIndexedPrimitive debe usar el mismo valor para BaseVertexIndex.
Para evitar la concatenación durante la generación de perfiles, modifique la secuencia de representación para que el tipo primitivo no sea una lista de triángulos o modifique la secuencia de representación para que no haya llamadas de dibujo de retroceso que usen vértices consecutivos (o índices). Más concretamente, el tiempo de ejecución también concatenará las llamadas draw que cumplen las dos condiciones siguientes:
- Cuando la llamada anterior es DrawPrimitive, si la siguiente llamada a draw:
- usa una lista de triángulos, AND
- especifica startVertex = anterior StartVertex + PrimitiveCount anterior * 3
- Al usar DrawIndexedPrimitive, si la siguiente llamada a draw:
- usa una lista de triángulos, AND
- especifica startIndex = previous StartIndex + previous PrimitiveCount * 3, AND
- especifica baseVertexIndex = baseVertexIndex anterior
Este es un ejemplo más sutil de concatenación de llamadas draw que es fácil de pasar por alto al generar perfiles. Supongamos que la secuencia de representación tiene este aspecto:
for(int i = 0; i < 1500; i++)
{
SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Ejemplo 5c: un cambio de estado y una llamada a Draw
El bucle recorre en iteración 1500 triángulos, estableciendo una textura y dibujando cada triángulo. Este bucle de representación toma aproximadamente 2750 ciclos para SetTexture y 1100 ciclos para DrawPrimitive , como se muestra en las secciones anteriores. Puede esperar intuitivamente que mover SetTexture fuera del bucle de representación debe reducir la cantidad de trabajo realizado por el controlador en 1500 * 2750 ciclos, que es la cantidad de trabajo asociado a llamar a SetTexture 1500 veces. El fragmento de código tendría este aspecto:
SetTexture(...); // Set the state outside the loop
for(int i = 0; i < 1500; i++)
{
// SetTexture(...);
DrawPrimitive(D3DPT_TRIANGLELIST, i*3, 1);
}
Ejemplo 5d: Ejemplo 5c con el cambio de estado fuera del bucle
Al mover SetTexture fuera del bucle de representación, se reduce la cantidad de trabajo asociado a SetTexture , ya que se llama una vez en lugar de 1500 veces. Un efecto secundario menos obvio es que el trabajo de DrawPrimitive también se reduce de 1500 llamadas a 1 llamada porque se cumplen todas las condiciones para concatenar llamadas de dibujo. Cuando se procesa la secuencia de representación, el tiempo de ejecución procesará 1500 llamadas a una sola llamada de controlador. Al mover esta línea de código, la cantidad de trabajo del controlador se ha reducido drásticamente:
total work done = runtime + driver work
Example 5c: with SetTexture in the loop:
runtime work = 1500 SetTextures + 1500 DrawPrimitives
driver work = 1500 SetTextures + 1500 DrawPrimitives
Example 5d: with SetTexture outside of the loop:
runtime work = 1 SetTexture + 1 DrawPrimitive + 1499 Concatenated DrawPrimitives
driver work = 1 SetTexture + 1 DrawPrimitive
Estos resultados son totalmente correctos, pero son muy engañosos en el contexto de la pregunta original. La optimización de llamadas draw ha provocado que la cantidad de trabajo del controlador se reduzca drásticamente. Este es un problema común al realizar la generación de perfiles personalizada. Al eliminar las llamadas de una secuencia de representación, tenga cuidado de evitar la concatenación de llamadas dibujadas. De hecho, este escenario es un ejemplo eficaz de la cantidad de mejora en el rendimiento del controlador posible por esta optimización en tiempo de ejecución.
Ahora sabe cómo medir los cambios de estado. Empiece por generar perfiles drawPrimitive. A continuación, agregue cada cambio de estado adicional a la secuencia (en algunos casos agregando una llamada y en otros casos agregando dos llamadas) y mida la diferencia entre las dos secuencias. Puede convertir los resultados en tics o ciclos o tiempo. Al igual que medir las secuencias de representación con QueryPerformanceCounter, medir los cambios de estado individuales se basa en el mecanismo de consulta para controlar el búfer de comandos y colocar los cambios de estado en un bucle para minimizar el impacto de las transiciones de modo. Esta técnica mide el costo de alternar un estado, ya que el generador de perfiles devuelve el promedio de habilitación y deshabilitación del estado.
Con esta funcionalidad, puede empezar a generar secuencias de representación arbitrarias y medir con precisión el tiempo de ejecución y el trabajo del controlador asociados. A continuación, los números se pueden usar para responder a preguntas de presupuesto como "cuántas más llamadas" se pueden realizar en la secuencia de representación, a la vez que se mantiene una velocidad de fotogramas razonable, suponiendo que los escenarios limitados por cpu.
Resumen
En este documento se muestra cómo controlar el búfer de comandos para que las llamadas individuales se puedan generar perfiles con precisión. Los números de generación de perfiles se pueden generar en tics, ciclos o tiempo absoluto. Representan la cantidad de trabajo del motor y el tiempo de ejecución asociados a cada llamada API.
Empiece por generar perfiles de una llamada Draw*Primitive en una secuencia de representación. Recuerde:
- Use QueryPerformanceCounter para medir el número de tics por llamada API. Use QueryPerformanceFrequency para convertir los resultados en ciclos o tiempo si lo desea.
- Use el mecanismo de consulta para vaciar el búfer de comandos antes de iniciarse.
- Incluya la secuencia de representación en un bucle para minimizar el impacto de la transición del modo.
- Use el mecanismo de consulta para medir cuándo la GPU ha completado su trabajo.
- Tenga cuidado con la concatenación en tiempo de ejecución que tendrá un impacto importante en la cantidad de trabajo realizado.
Esto proporciona un rendimiento de línea base para DrawPrimitive desde el que se puede usar la compilación. Para generar perfiles de un cambio de estado, siga estas sugerencias adicionales:
- Agregue el cambio de estado a un perfil de secuencia de representación conocido de la nueva secuencia. Puesto que las pruebas se realizan en un bucle, esto requiere establecer el estado dos veces en valores opuestos (como habilitar y deshabilitar por ejemplo).
- Compare la diferencia en los tiempos de ciclo entre las dos secuencias.
- Para los cambios de estado que cambian significativamente la canalización (como SetTexture), resta la diferencia entre las dos secuencias para obtener el tiempo de cambio de estado.
- Para los cambios de estado que cambian significativamente la canalización (y, por tanto, requieren alternar estados como SetRenderState), resta la diferencia entre las secuencias de representación y divida en 2. Esto generará el número medio de ciclos para cada cambio de estado.
Pero tenga cuidado con las optimizaciones que provocan resultados inesperados al generar perfiles. Las optimizaciones de cambio de estado pueden establecer estados sucios que hacen que el trabajo se aplaza. Esto puede provocar resultados de perfil que no son tan intuitivos como se esperaba. Dibujar llamadas concatenadas reducirá drásticamente el trabajo de los impulsores, lo que puede dar lugar a conclusiones erróneas. Las secuencias de representación cuidadosamente planeadas se usan para evitar que se produzcan concatenaciones de llamadas de cambio de estado y de dibujo. El truco es evitar que las optimizaciones se produzcan durante la generación de perfiles para que los números que genere sean números presupuestados razonables.
Nota
Duplicar esta estrategia de generación de perfiles en una aplicación sin el mecanismo de consulta es más difícil. Antes de Direct3D 9, la única manera predecible de vaciar el búfer de comandos es bloquear una superficie activa (como un destino de representación) para esperar hasta que la GPU esté inactiva. Esto se debe a que el bloqueo de una superficie obliga al tiempo de ejecución a vaciar el búfer de comandos en caso de que haya comandos de representación en el búfer que deben actualizar la superficie antes de que se bloquee, además de esperar a que finalice la GPU. Esta técnica es funcional, aunque es más obtrusiva que el uso del mecanismo de consulta introducido en Direct3D 9.
Apéndice
Los números de esta tabla son un intervalo de aproximaciones para la cantidad de tiempo de ejecución y el trabajo del controlador asociado a cada uno de estos cambios de estado. Las aproximaciones se basan en las mediciones reales realizadas en los conductores utilizando las técnicas que se muestran en el papel. Estos números se generaron con el entorno de ejecución de Direct3D 9 y dependen del controlador.
Las técnicas de este documento están diseñadas para medir el tiempo de ejecución y el trabajo del controlador. En general, no resulta práctico proporcionar resultados que coincidan con el rendimiento de la CPU y la GPU en cada aplicación, ya que esto requeriría una matriz exhaustiva de secuencias de representación. Además, es especialmente difícil realizar pruebas comparativas del rendimiento de la GPU porque depende en gran medida de la configuración de estado de la canalización antes de la secuencia de representación. Por ejemplo, habilitar la combinación alfa hace poco para afectar a la cantidad de trabajo de CPU necesario, pero puede tener un gran impacto en la cantidad de trabajo realizado por la GPU. Por lo tanto, las técnicas de este documento restringen el trabajo de GPU a la cantidad mínima posible limitando la cantidad de datos que se deben representar. Esto significa que los números de la tabla coincidirán más estrechamente con los resultados obtenidos de las aplicaciones que tienen un límite de CPU (en lugar de una aplicación limitada por la GPU).
Se recomienda usar las técnicas presentadas para cubrir los escenarios y configuraciones más importantes para usted. Los valores de la tabla se pueden usar para comparar con los números que se generan. Dado que cada controlador varía, la única manera de generar los números reales que verá es generar resultados de generación de perfiles mediante los escenarios.
| Llamada a la API | Número medio de ciclos |
|---|---|
| SetVertexDeclaration | 6500 - 11250 |
| SetFVF | 6400 - 11200 |
| SetVertexShader | 3000 - 12100 |
| SetPixelShader | 6300 - 7000 |
| ESPECULARENABLE | 1900 - 11200 |
| SetRenderTarget | 6000 - 6250 |
| SetPixelShaderConstant (1 constante) | 1500 - 9000 |
| NORMALIZENORMALS | 2200 - 8100 |
| LightEnable | 1300 - 9000 |
| SetStreamSource | 3700 - 5800 |
| ILUMINACIÓN | 1700 - 7500 |
| DIFFUSEMATERIALSOURCE | 900 - 8300 |
| AMBIENTMATERIALSOURCE | 900 - 8200 |
| COLORVERTEX | 800 - 7800 |
| SetLight | 2200 - 5100 |
| SetTransform | 3200 - 3750 |
| SetIndices | 900 - 5600 |
| AMBIENTE | 1150 - 4800 |
| SetTexture | 2500 - 3100 |
| SPECULARMATERIALSOURCE | 900 - 4600 |
| EMISSIVEMATERIALSOURCE | 900 - 4500 |
| SetMaterial | 1000 - 3700 |
| ZENABLE | 700 - 3900 |
| WRAP0 | 1600 - 2700 |
| MINFILTER | 1700 - 2500 |
| MAGFILTER | 1700 - 2400 |
| SetVertexShaderConstant (1 constante) | 1000 - 2700 |
| COLOROP | 1500 - 2100 |
| COLORARG2 | 1300 - 2000 |
| COLORARG1 | 1300 - 1980 |
| CULLMODE | 500 - 2570 |
| RECORTE | 500 - 2550 |
| DrawIndexedPrimitive | 1200 - 1400 |
| ADDRESSV | 1090 - 1500 |
| ADDRESSU | 1070 - 1500 |
| DrawPrimitive | 1050 - 1150 |
| SRGBTEXTURE | 150 - 1500 |
| STENCILMASK | 570 - 700 |
| STENCILZFAIL | 500 - 800 |
| STENCILREF | 550 - 700 |
| ALPHABLENDENABLE | 550 - 700 |
| STENCILFUNC | 560 - 680 |
| STENCILWRITEMASK | 520 - 700 |
| STENCILFAIL | 500 - 750 |
| ZFUNC | 510 - 700 |
| ZWRITEENABLE | 520 - 680 |
| STENCILENABLE | 540 - 650 |
| GALERÍA DE SÍMBOLOSPASS | 560 - 630 |
| SRCBLEND | 500 - 685 |
| Two_Sided_StencilMODE | 450 - 590 |
| ALPHATESTENABLE | 470 - 525 |
| ALPHAREF | 460 - 530 |
| ALPHAFUNC | 450 - 540 |
| DESTBLEND | 475 - 510 |
| COLORWRITEENABLE | 465 - 515 |
| CCW_STENCILFAIL | 340 - 560 |
| CCW_STENCILPASS | 340 - 545 |
| CCW_STENCILZFAIL | 330 - 495 |
| SCISSORTESTENABLE | 375 - 440 |
| CCW_STENCILFUNC | 250 - 480 |
| SetScissorRect | 150 - 340 |
Temas relacionados