Effectuer l’apprentissage de votre modèle vocal professionnel
Dans cet article, vous allez apprendre à entraîner une voix neuronale personnalisée dans le portail Speech Studio.
Important
L’apprentissage de voix neuronale personnalisée est disponible uniquement dans certaines régions. Une fois votre modèle vocal entraîné dans une région prise en charge, vous pouvez le copier dans une ressource Speech d’une autre région, selon les besoins. Pour plus d’informations, consultez les notes de bas de page dans la table de service Speech.
La durée d’entraînement varie en fonction de la quantité de données que vous utilisez. En moyenne, 40 heures de calcul sont nécessaires pour entraîner une voix neuronale personnalisée. Ceux qui disposent d’un abonnement standard (S0) peuvent, quant à eux, en effectuer l'apprentissage de quatre voix simultanément. Si vous atteignez la limite, attendez au moins la fin de l’entraînement d’un de vos modèles vocaux, puis réessayez.
Remarque
Bien que le nombre total d’heures nécessaires par méthode d’entraînement puisse varier, le même prix unitaire s’applique à chacune d’elles. Pour plus d’informations, consultez les détails des tarifs de l’apprentissage neuronal personnalisé.
Choisir une méthode d’entraînement
Une fois vos fichiers de données validés, utilisez-les pour créer votre modèle de voix neuronale personnalisée. Quand vous créez une voix neuronale personnalisée, vous pouvez choisir de l’entraîner avec l’une des méthodes suivantes :
Neuronale : créez une voix dans la même langue que vos données d’entraînement.
Neuronal – multilingue : créez une voix qui parle une langue différente à partir de vos données d’apprentissage. Par exemple, avec des données d’entraînement
zh-CN, vous pouvez créer une voix qui parleen-US.La langue des données d’entraînement et la langue cible doivent toutes les deux correspondre à l’une des langues prises en charge pour l’entraînement vocal multilingue. Vous n’avez pas besoin de préparer les données d’entraînement dans la langue cible, mais votre script de test doit être dans la langue cible.
Neuronale - multi-style : créez une voix neuronale personnalisée ayant plusieurs styles et émotions, sans ajouter de nouvelles données d’entraînement. Les voix à styles multiples sont utiles pour les personnages de jeux vidéo, les chatbots conversationnels, les livres audio, les lecteurs de contenu, entre autres.
Pour créer une voix à style multiple, vous devez préparer un ensemble de données d’entraînement générales, au moins 300 énoncés. Sélectionnez un ou plusieurs styles d’élocution cible prédéfinis. Vous pouvez aussi créer de nombreux styles personnalisés en fournissant des exemples de style, d’au moins 100 énoncés par style, sous forme de données d’entraînement supplémentaires pour la même voix. Les styles prédéfinis pris en charge varient selon les langues. Consultez Styles prédéfinis disponibles dans différentes langues.
La langue des données d’entraînement doit être l’une des langues prises en charge pour l’entraînement multilingue ou à style multiple des voix neuronales personnalisées.
Entraîner votre modèle vocal neuronal personnalisé
Pour créer une voix neuronale personnalisée dans Speech Studio, suivez les étapes correspondant à l’une des méthodes suivantes :
Connectez-vous à Speech Studio.
Sélectionnez Custom Voice><Nom de votre projet>>Entraîner un modèle>Entraîner un nouveau modèle.
Sélectionnez Neuronale en tant que méthode d’entraînement pour votre modèle, puis sélectionnez Suivant. Pour utiliser une autre méthode d’entraînement, consultez Neuronale - multilingue ou Neuronale - multistyle.
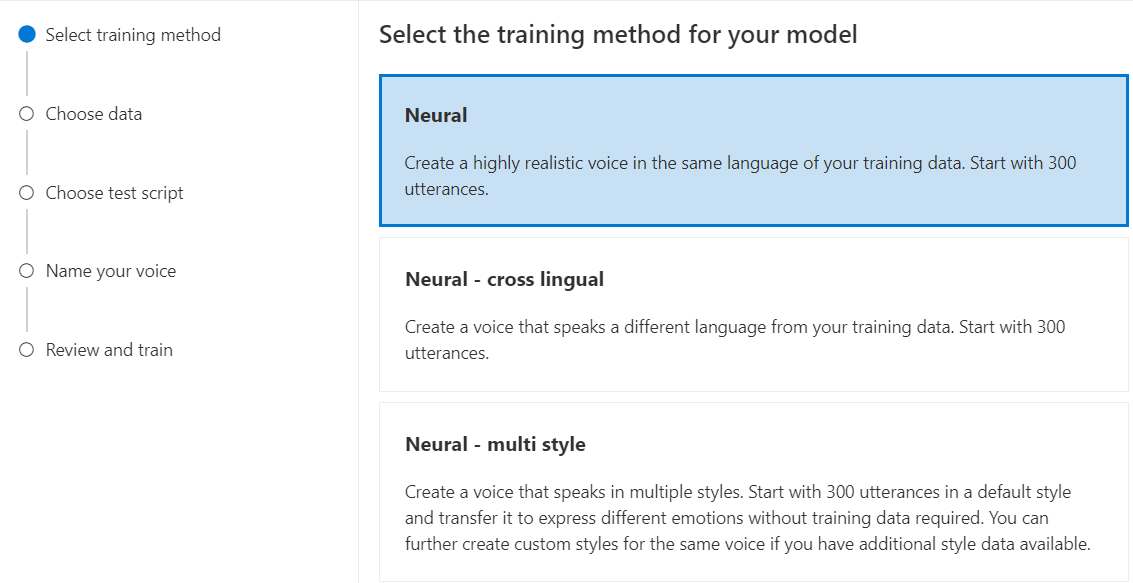
Sélectionnez une version de la recette d’entraînement pour votre modèle. La dernière version est sélectionnée par défaut. Les fonctionnalités prises en charge et la durée d’entraînement peuvent varier selon la version. Normalement, nous vous recommandons de télécharger la version la plus récente. Dans certains cas, vous pouvez choisir une version antérieure pour réduire la durée d’entraînement. Consultez Entraînement bilingue pour plus d’informations sur l’entraînement bilingue et les différences entre les paramètres régionaux.
Remarque
Les versions de modèle
V2.2021.07,V4.2021.10,V5.2022.05,V6.2022.11etV9.2023.10seront supprimées d’ici le 1er octobre 2024. Les modèles vocaux déjà créés sur ces versions supprimées ne seront pas affectés.Sélectionnez les données à utiliser pour l’entraînement. Les noms audio en double seront retirés de l’apprentissage. Vérifiez que les données que vous sélectionnez ne comportent pas les mêmes noms audio dans plusieurs fichiers .zip.
Vous pouvez sélectionner uniquement les jeux de données dont le traitement est réussi pour l’entraînement. Si vous ne voyez pas votre jeu d’entraînement dans la liste, vérifiez l’état du traitement de données.
Sélectionnez un fichier de locuteur dont la déclaration de l’artiste vocal correspond au locuteur de vos données d’entraînement.
Cliquez sur Suivant.
Chaque apprentissage génère automatiquement 100 exemples de fichiers audio pour vous aider à tester le modèle avec un script par défaut.
Si vous le souhaitez, vous pouvez également sélectionner Ajouter mon propre script de test et fournir votre propre script de test avec jusqu’à 100 énoncés pour tester le modèle sans coût supplémentaire. Les fichiers audio générés sont une combinaison de scripts de test automatiques et de scripts de test personnalisés. Pour plus d’informations, consultez les conditions relatives aux scripts de test.
Entrez un Nom pour vous aider à identifier le modèle. Choisissez un nom avec soin. Le nom du modèle est utilisé en tant que nom vocal dans votre demande de synthèse vocale par le kit SDK et l’entrée SSML. Seuls les lettres, les chiffres et quelques caractères de ponctuation sont autorisés. Utilisez un nom différent par modèle vocal neuronal.
Entrez éventuellement la Description pour identifier plus facilement le modèle. En règle générale, la description permet d’enregistrer les noms des données que vous avez utilisées pour créer le modèle.
Cliquez sur Suivant.
Passez en revue les paramètres, puis sélectionnez la case appropriée pour accepter les conditions d’utilisation.
Sélectionnez Envoyer pour commencer l’entraînement du modèle.
Entraînement bilingue
Si vous sélectionnez le type d’entraînement Neuronal, vous pouvez entraîner une voix pour qu’elle parle plusieurs langues. Les paramètres régionaux zh-CN, zh-HK et zh-TW prennent en charge l’apprentissage bilingue pour que la voix parle chinois et anglais. En fonction de vos données d’entraînement, la voix synthétisée peut parler anglais avec un accent anglais natif ou anglais avec le même accent que les données d’entraînement.
Remarque
Pour permettre à une voix avec le paramètre régional zh-CN de parler anglais avec le même accent que les échantillons de données, vous devez choisir Chinese (Mandarin, Simplified), English bilingual lors de la création d’un projet ou spécifier le paramètre régional zh-CN (English bilingual) pour les données du jeu d’entraînement via l’API REST.
Le tableau suivant présente les différences entre les paramètres régionaux :
| Paramètre régional de Speech Studio | Paramètre régional de l’API REST | Prise en charge bilingue |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Si vos échantillons de données incluent l’anglais, la voix synthétisée parle anglais avec un accent anglais natif, pas avec le même accent que les échantillons de données, quelle que soit la quantité de données en anglais. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Si vous souhaitez que la voix synthétisée parle anglais avec le même accent que les échantillons de données, nous vous recommandons d’inclure plus de 10 % de données en anglais dans votre jeu d’entraînement. Sinon, l’accent anglais risque de ne pas être idéal. |
Chinese (Cantonese, Simplified) |
zh-HK |
Si vous souhaitez entraîner une voix synthétisée capable de parler anglais avec le même accent que vos échantillons de données, veillez à fournir plus de 10 % de données en anglais dans votre jeu d’entraînement. Sinon, elle est définie par défaut avec un accent anglais natif. Le seuil de 10 % est calculé sur la base des données acceptées après avoir été chargées correctement, et non des données avant le chargement. Si certaines données en anglais qui ont été chargées sont rejetées à cause de défauts et que le seuil de 10 % n’est pas atteint, la voix synthétisée est définie par défaut avec un accent anglais natif. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Si vous souhaitez entraîner une voix synthétisée capable de parler anglais avec le même accent que vos échantillons de données, veillez à fournir plus de 10 % de données en anglais dans votre jeu d’entraînement. Sinon, elle est définie par défaut avec un accent anglais natif. Le seuil de 10 % est calculé sur la base des données acceptées après avoir été chargées correctement, et non des données avant le chargement. Si certaines données en anglais qui ont été chargées sont rejetées à cause de défauts et que le seuil de 10 % n’est pas atteint, la voix synthétisée est définie par défaut avec un accent anglais natif. |
Styles prédéfinis disponibles dans différentes langues
Le tableau suivant récapitule les différents styles prédéfinis en fonction de différentes langues.
| Style d’élocution | Langue (paramètres régionaux) |
|---|---|
| en colère | Anglais (États-Unis) (en-US)Japonais (Japon) ( ja-JP) 1Chinois (mandarin, simplifié) ( zh-CN) 1 |
| calme | Chinois (mandarin, simplifié) (zh-CN) 1 |
| chat | Chinois (mandarin, simplifié) (zh-CN) 1 |
| enjoué | Anglais (États-Unis) (en-US)Japonais (Japon) ( ja-JP) 1Chinois (mandarin, simplifié) ( zh-CN) 1 |
| mécontent | Chinois (mandarin, simplifié) (zh-CN) 1 |
| excité | Anglais (États-Unis) (en-US) |
| craintif | Chinois (mandarin, simplifié) (zh-CN) 1 |
| convivial | Anglais (États-Unis) (en-US) |
| optimiste | Anglais (États-Unis) (en-US) |
| triste | Anglais (États-Unis) (en-US)Japonais (Japon) ( ja-JP) 1Chinois (mandarin, simplifié) ( zh-CN) 1 |
| cris | Anglais (États-Unis) (en-US) |
| sérieux | Chinois (mandarin, simplifié) (zh-CN) 1 |
| terrifié | Anglais (États-Unis) (en-US) |
| peu sympathique | Anglais (États-Unis) (en-US) |
| murmure | Anglais (États-Unis) (en-US) |
1 Le style de voix neuronale est disponible en préversion publique. Les styles en préversion publique sont uniquement disponibles dans ces régions de service : USA Est, Europe Ouest et Asie Sud-Est.
Le Tableau Entraîner un modèle comporte une nouvelle entrée correspondant à ce nouveau modèle. L’état reflète le processus de conversion de vos données en modèle vocal, comme indiqué dans ce tableau :
| State | Signification |
|---|---|
| Traitement en cours | Le modèle vocal est en cours de création. |
| Opération réussie | Le modèle vocal a été créé et peut être déployé. |
| Échec | Votre modèle vocal a échoué dans l’apprentissage. La cause de l’échec peut être, par exemple, des problèmes de données non consultés ou des problèmes de réseau. |
| Opération annulée | L’apprentissage de votre modèle vocal a été annulé. |
Tant que l’état du modèle est Traitement en cours, vous pouvez sélectionner Annuler l’entraînement pour annuler votre modèle vocal. Vous n’êtes pas facturé pour cet apprentissage annulé.
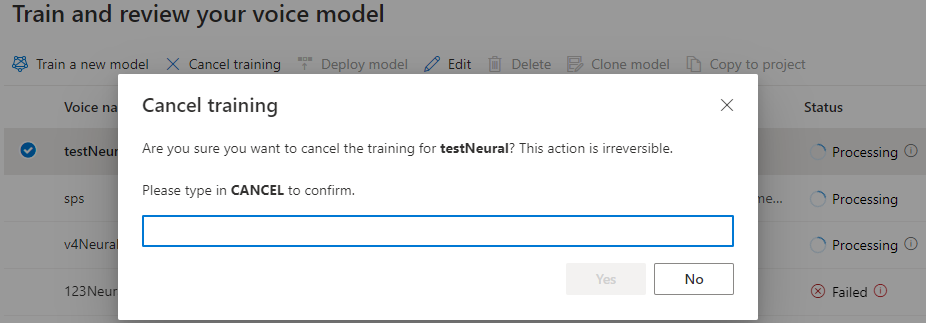
Une fois l’entraînement du modèle réussi, vous pouvez passer en revue ses détails et Tester votre modèle vocal.
Vous pouvez utiliser l’outil Création de contenu audio de Speech Studio pour créer du contenu audio et affiner la voix déployée. Si cela est applicable à votre voix, vous pouvez sélectionner un des différents styles.
Renommer votre modèle
Si vous souhaitez renommer le modèle que vous avez créé, sélectionnez Cloner le modèle pour créer un clone du modèle avec un nouveau nom dans le projet actuel.
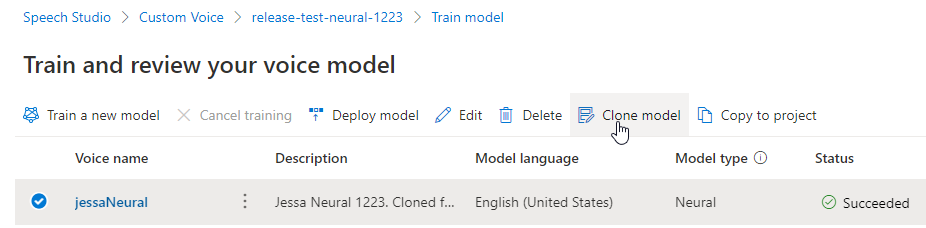
Entrez le nouveau nom dans la fenêtre Cloner le modèle vocal, puis sélectionnez Envoyer. Le texte Neural est automatiquement ajouté en tant que suffixe au nom de votre modèle.
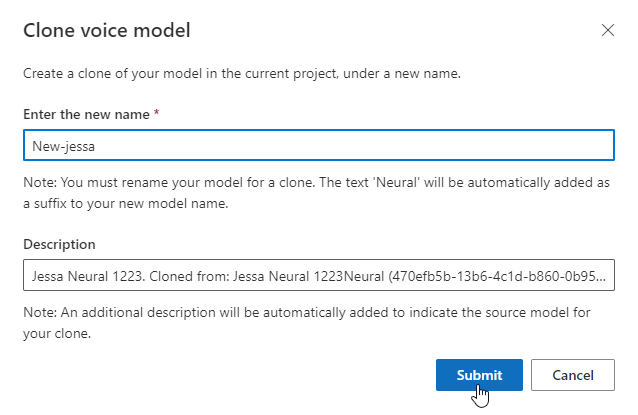
Tester un modèle vocal
Une fois votre modèle vocal créé, vous pouvez utiliser les exemples de fichiers audio pour le tester avant de le déployer.
La qualité de la voix dépend de nombreux facteurs, tels que :
- La taille des données d'entraînement.
- La qualité de l’enregistrement.
- La précision du fichier de transcription.
- L’efficacité de la voix enregistrée dans les données d’apprentissage correspond à la personnalité de la voix conçue pour le cas d’usage prévu.
Sélectionnez DefaultTests sous Test pour écouter les exemples de fichiers audio. Les exemples de test par défaut incluent 100 exemples de fichiers audio générés automatiquement pendant l’apprentissage pour vous aider à tester le modèle. En plus de ces 100 fichiers audio fournis par défaut, les énoncés de votre propre script de test sont également ajoutés à l’ensemble DefaultTests. Cet ajout est au maximum de 100 énoncés. Vous n’êtes pas facturé pour les tests avec DefaultTests.
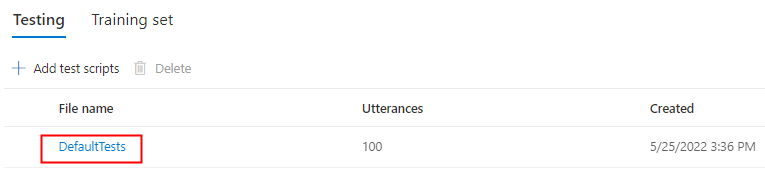
Si vous souhaitez charger vos propres scripts de test afin de tester davantage votre modèle, sélectionnez Ajouter des scripts de test pour charger votre propre script de test.
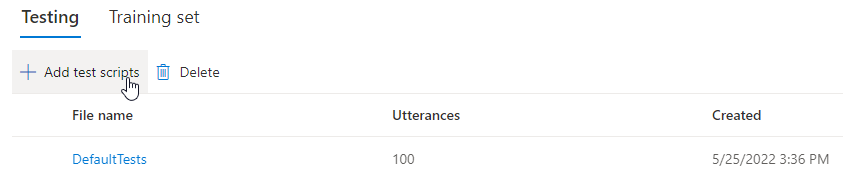
Avant de charger le script de test, vérifiez les Exigences du script de test. Vous êtes facturé pour les tests supplémentaires avec la synthèse par lots en fonction du nombre de caractères facturables. Consultez Tarification d’Azure AI Speech.
Sous Ajouter des scripts de test, sélectionnez Rechercher un fichier pour sélectionner votre propre script, puis sélectionnez Ajouter pour le charger.
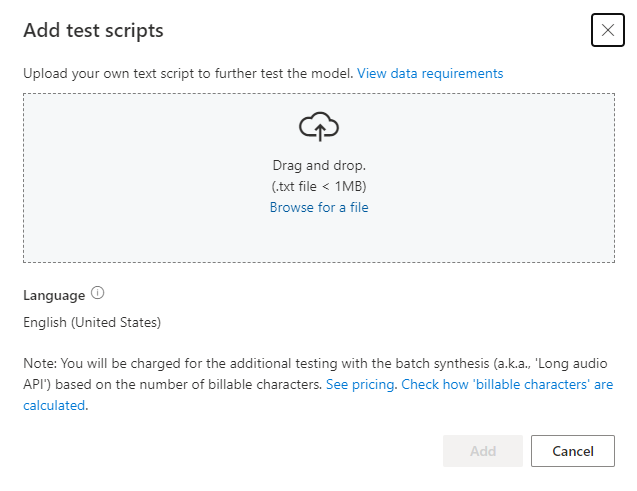
Spécifications du script de test
Le script de test doit être un fichier .txt d’une taille inférieure à 1 Mo. ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE et UTF-16-BE sont des formats d’encodage pris en charge.
Contrairement aux fichiers de transcription d’entraînement, le script de test doit exclure l’ID d’énoncé, qui est le nom de fichier de chaque énoncé. Dans le cas contraire, ces ID sont prononcés.
Voici un exemple de jeu d’énoncés dans un fichier .txt :
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Chaque paragraphe de l’énoncé produit l’objet d’un audio distinct. Si vous préférez combiner toutes les phrases dans un seul audio, incluez-les toutes dans un seul paragraphe.
Notes
Les fichiers audio générés sont une combinaison de scripts de test automatiques et de scripts de test personnalisés.
Mise à jour de la version du moteur pour votre modèle vocal
Les moteurs de synthèse vocale Azure sont mis à jour de temps à autre pour capturer le modèle linguistique le plus récent qui définit la prononciation de la langue. Une fois que vous avez entraîné votre voix, vous pouvez l’appliquer au nouveau modèle de langage en mettant à jour vers la dernière version du moteur.
Quand un nouveau moteur est disponible, vous êtes invité à mettre à jour votre modèle vocal neuronal.

Accédez à la page des détails du modèle et suivez les instructions affichées à l’écran pour installer le moteur le plus récent.
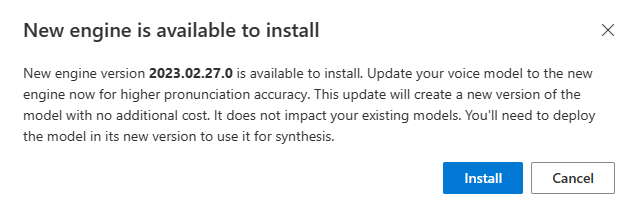
Sinon, sélectionnez Installer le moteur le plus récent plus tard pour mettre à jour votre modèle vers la dernière version du moteur.
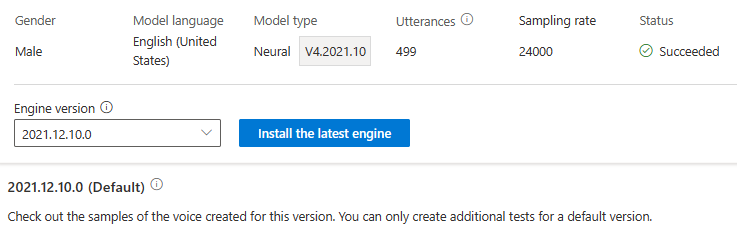
Vous n’êtes pas facturé pour la mise à jour du moteur. Les versions précédentes sont toujours conservées.
Vous pouvez vérifier toutes les versions du moteur du modèle dans la liste Version du moteur, ou en supprimer une si vous n’en avez plus besoin.
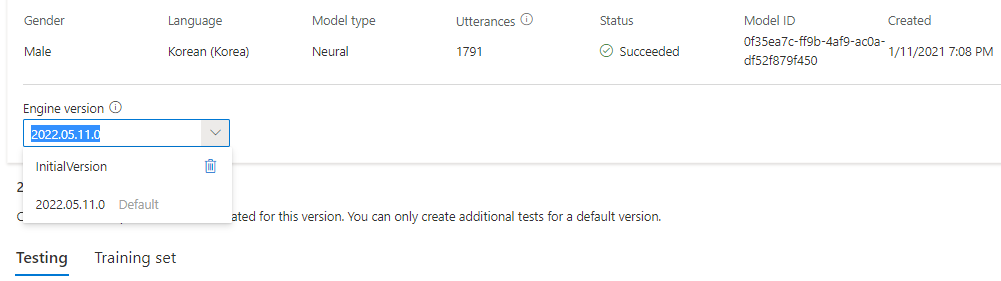
La version mise à jour est automatiquement définie comme valeur par défaut. Toutefois, vous pouvez changer la version par défaut en sélectionnant une version dans la liste déroulante, puis en sélectionnant Définir comme valeur par défaut.
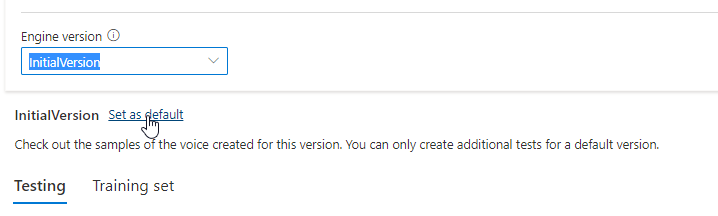

Si vous souhaitez tester chaque version de moteur de votre modèle vocal, vous pouvez sélectionner une version dans la liste, puis sélectionner DefaultTests sous Test pour écouter les exemples de fichiers audio. Si vous souhaitez charger vos propres scripts de test pour tester davantage votre version actuelle du moteur, vérifiez d’abord que la version est définie comme valeur par défaut, puis suivez les étapes dans Tester votre modèle vocal.
La mise à jour du moteur crée une nouvelle version du modèle sans coût supplémentaire. Une fois la version du moteur mise à jour pour votre modèle vocal, vous devez déployer la nouvelle version pour créer un nouveau point de terminaison. Vous ne pouvez déployer que la version par défaut.
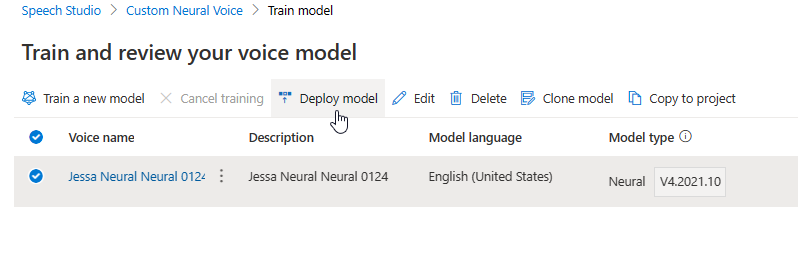
Une fois le nouveau point de terminaison créé, vous devez transférer le trafic vers le nouveau point de terminaison dans votre produit.
Pour en savoir plus sur les capacités et les limites de cette fonctionnalité, ainsi que sur les meilleures pratiques pour améliorer la qualité de votre modèle, consultez Caractéristiques et limitations de l’utilisation de la voix neuronale personnalisée.
Copier votre modèle vocal vers un autre projet
Vous pouvez copier votre modèle vocal vers un autre projet pour la même région ou une autre région. Par exemple, vous pouvez copier un modèle de voix neuronale qui a été formé dans une région vers un projet pour une autre région.
Notes
L’apprentissage de voix neuronale personnalisée est disponible uniquement dans certaines régions. Vous pouvez copier un modèle de voix neuronale à partir de ces régions vers d’autres régions. Pour plus d’informations, consultez les régions pour la voix neuronale personnalisée.
Pour copier votre modèle de voix neuronale personnalisée vers un autre projet :
Sous l’onglet Effectuer l'apprentissage du modèle, sélectionnez le modèle vocal que vous souhaitez copier, puis sélectionnez Copier dans le projet.
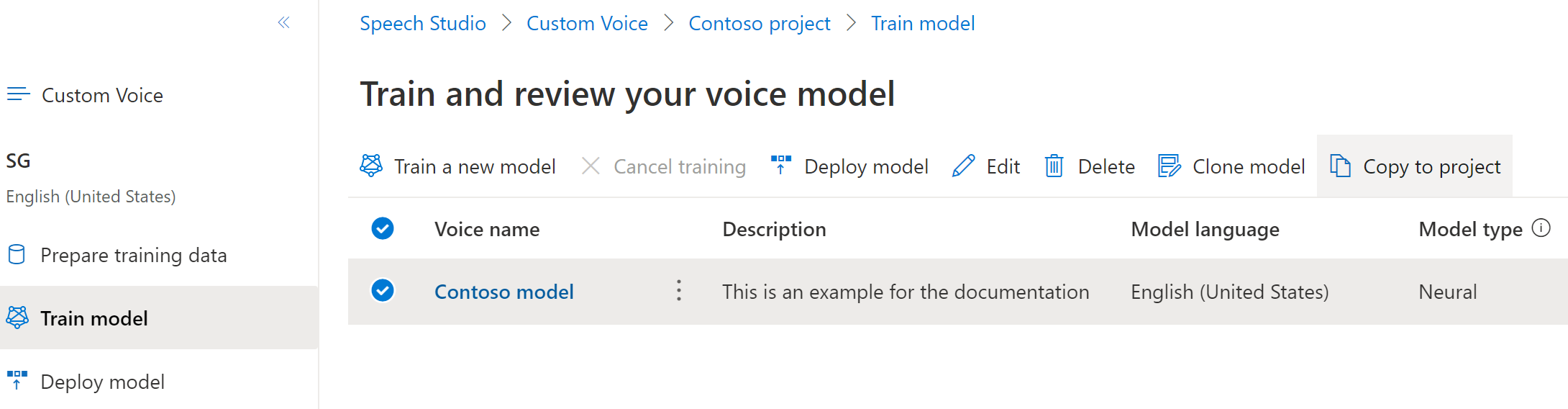
Sélectionnez Abonnement, Région, ressource Speechet Projet où vous souhaitez copier le modèle. Vous devez disposer d’une ressource Speech et d’un projet dans la région cible. Sinon, vous devez d’abord les créer.
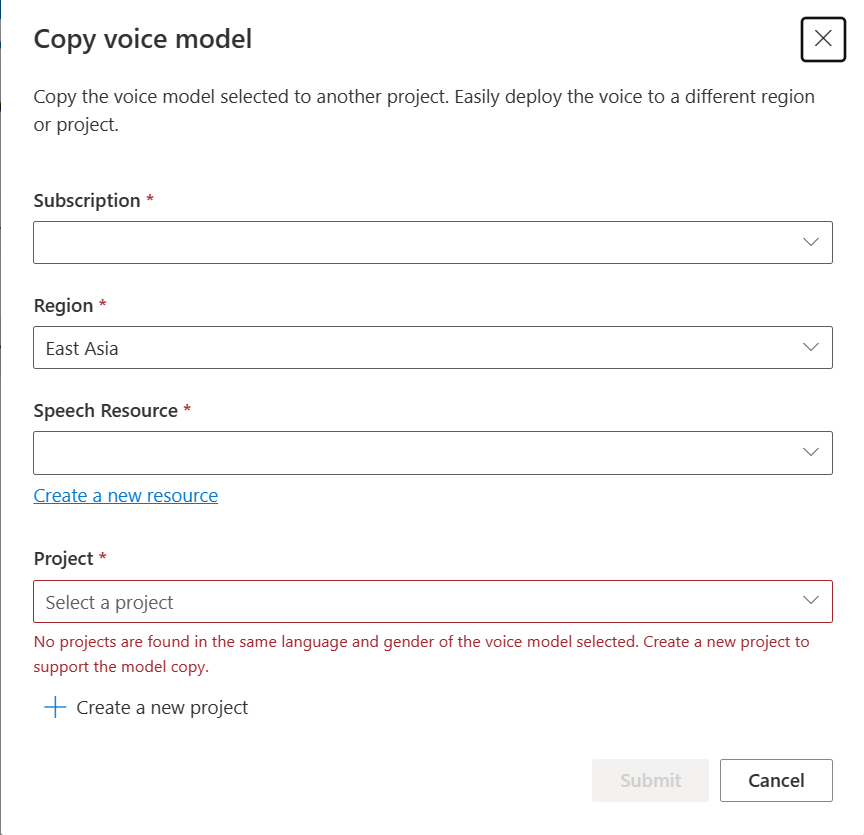
Sélectionnez Envoyer pour copier le modèle.
Sélectionnez Afficher le modèle sous le message de notification de la réussite de la copie.
Accédez au projet dans lequel vous avez copié le modèle pour déployer la copie du modèle.
Étapes suivantes
Dans cet article, vous allez apprendre à effectuer l'apprentissage d’une voix neuronale personnalisée via l’API Custom Voice.
Important
L’apprentissage de voix neuronale personnalisée est disponible uniquement dans certaines régions. Une fois votre modèle vocal entraîné dans une région prise en charge, vous pouvez le copier dans une ressource Speech d’une autre région, selon les besoins. Pour plus d’informations, consultez les notes de bas de page dans la table de service Speech.
La durée d’entraînement varie en fonction de la quantité de données que vous utilisez. En moyenne, 40 heures de calcul sont nécessaires pour entraîner une voix neuronale personnalisée. Ceux qui disposent d’un abonnement standard (S0) peuvent, quant à eux, en effectuer l'apprentissage de quatre voix simultanément. Si vous atteignez la limite, attendez au moins la fin de l’entraînement d’un de vos modèles vocaux, puis réessayez.
Remarque
Bien que le nombre total d’heures nécessaires par méthode d’entraînement puisse varier, le même prix unitaire s’applique à chacune d’elles. Pour plus d’informations, consultez les détails des tarifs de l’apprentissage neuronal personnalisé.
Choisir une méthode d’entraînement
Une fois vos fichiers de données validés, utilisez-les pour créer votre modèle de voix neuronale personnalisée. Quand vous créez une voix neuronale personnalisée, vous pouvez choisir de l’entraîner avec l’une des méthodes suivantes :
Neuronale : créez une voix dans la même langue que vos données d’entraînement.
Neuronal – multilingue : créez une voix qui parle une langue différente à partir de vos données d’apprentissage. Par exemple, avec des données d’entraînement
fr-FR, vous pouvez créer une voix qui parleen-US.La langue des données d’entraînement et la langue cible doivent toutes les deux correspondre à l’une des langues prises en charge pour l’entraînement vocal multilingue. Vous n’avez pas besoin de préparer les données d’entraînement dans la langue cible, mais votre script de test doit être dans la langue cible.
Neuronale - multi-style : créez une voix neuronale personnalisée ayant plusieurs styles et émotions, sans ajouter de nouvelles données d’entraînement. Les voix à styles multiples sont utiles pour les personnages de jeux vidéo, les chatbots conversationnels, les livres audio, les lecteurs de contenu, entre autres.
Pour créer une voix à style multiple, vous devez préparer un ensemble de données d’entraînement générales, au moins 300 énoncés. Sélectionnez un ou plusieurs styles d’élocution cible prédéfinis. Vous pouvez aussi créer de nombreux styles personnalisés en fournissant des exemples de style, d’au moins 100 énoncés par style, sous forme de données d’entraînement supplémentaires pour la même voix. Les styles prédéfinis pris en charge varient selon les langues. Consultez Styles prédéfinis disponibles dans différentes langues.
La langue des données d’apprentissage doit être l’une des langues prises en charge pour l’apprentissage multilingue ou à style multiple des voix neuronales personnalisées.
Créer un modèle vocal
Pour créer une voix neuronale, utilisez l’opération Models_Create de l’API Custom Voice. Construisez le corps de la requête conformément aux instructions suivantes :
- Définissez la propriété requise
projectId. Consultez Créer un projet. - Définissez la propriété requise
consentId. Consultez Ajouter le consentement de l’artiste vocal. - Définissez la propriété requise
trainingSetId. Consultez Créer un jeu d’apprentissage. - Définissez la propriété de recette
kindrequise surDefaultpour l’apprentissage de voix neuronale. Le type de recette indique la méthode d’apprentissage et ne peut pas être modifié ultérieurement. Pour utiliser une autre méthode d’entraînement, consultez Neuronale - multilingue ou Neuronale - multistyle. Consultez Entraînement bilingue pour plus d’informations sur l’entraînement bilingue et les différences entre les paramètres régionaux. - Définissez la propriété requise
voiceName. Le nom de la voix doit se terminer par « Neural » et ne peut pas être modifié ultérieurement. Choisissez un nom avec soin. Le nom de la voix est utilisé dans votre requête de synthèse vocale par le kit SDK et l’entrée SSML. Seuls les lettres, les chiffres et quelques caractères de ponctuation sont autorisés. Utilisez un nom différent par modèle vocal neuronal. - Si vous le souhaitez, définissez la propriété
descriptionpour la description vocale. La description vocale peut être modifiée ultérieurement.
Effectuez une requête HTTP PUT à l’aide de l’URI, comme illustré dans l’exemple Models_Create suivant.
- Remplacez
YourResourceKeypar votre clé de ressource Speech. - Remplacez
YourResourceRegionpar votre région de ressource Speech. - Remplacez
JessicaModelIdpar l’ID de modèle de votre choix. L’ID sensible à la casse est utilisé dans l’URI du modèle et ne peut pas être modifié plus tard.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview"
Vous devriez recevoir un corps de réponse au format suivant :
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Entraînement bilingue
Si vous sélectionnez le type d’entraînement Neuronal, vous pouvez entraîner une voix pour qu’elle parle plusieurs langues. Les paramètres régionaux zh-CN, zh-HK et zh-TW prennent en charge l’apprentissage bilingue pour que la voix parle chinois et anglais. En fonction de vos données d’entraînement, la voix synthétisée peut parler anglais avec un accent anglais natif ou anglais avec le même accent que les données d’entraînement.
Remarque
Pour permettre à une voix avec le paramètre régional zh-CN de parler anglais avec le même accent que les échantillons de données, vous devez choisir Chinese (Mandarin, Simplified), English bilingual lors de la création d’un projet ou spécifier le paramètre régional zh-CN (English bilingual) pour les données du jeu d’entraînement via l’API REST.
Le tableau suivant présente les différences entre les paramètres régionaux :
| Paramètre régional de Speech Studio | Paramètre régional de l’API REST | Prise en charge bilingue |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Si vos échantillons de données incluent l’anglais, la voix synthétisée parle anglais avec un accent anglais natif, pas avec le même accent que les échantillons de données, quelle que soit la quantité de données en anglais. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Si vous souhaitez que la voix synthétisée parle anglais avec le même accent que les échantillons de données, nous vous recommandons d’inclure plus de 10 % de données en anglais dans votre jeu d’entraînement. Sinon, l’accent anglais risque de ne pas être idéal. |
Chinese (Cantonese, Simplified) |
zh-HK |
Si vous souhaitez entraîner une voix synthétisée capable de parler anglais avec le même accent que vos échantillons de données, veillez à fournir plus de 10 % de données en anglais dans votre jeu d’entraînement. Sinon, elle est définie par défaut avec un accent anglais natif. Le seuil de 10 % est calculé sur la base des données acceptées après avoir été chargées correctement, et non des données avant le chargement. Si certaines données en anglais qui ont été chargées sont rejetées à cause de défauts et que le seuil de 10 % n’est pas atteint, la voix synthétisée est définie par défaut avec un accent anglais natif. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Si vous souhaitez entraîner une voix synthétisée capable de parler anglais avec le même accent que vos échantillons de données, veillez à fournir plus de 10 % de données en anglais dans votre jeu d’entraînement. Sinon, elle est définie par défaut avec un accent anglais natif. Le seuil de 10 % est calculé sur la base des données acceptées après avoir été chargées correctement, et non des données avant le chargement. Si certaines données en anglais qui ont été chargées sont rejetées à cause de défauts et que le seuil de 10 % n’est pas atteint, la voix synthétisée est définie par défaut avec un accent anglais natif. |
Styles prédéfinis disponibles dans différentes langues
Le tableau suivant récapitule les différents styles prédéfinis en fonction de différentes langues.
| Style d’élocution | Langue (paramètres régionaux) |
|---|---|
| en colère | Anglais (États-Unis) (en-US)Japonais (Japon) ( ja-JP) 1Chinois (mandarin, simplifié) ( zh-CN) 1 |
| calme | Chinois (mandarin, simplifié) (zh-CN) 1 |
| chat | Chinois (mandarin, simplifié) (zh-CN) 1 |
| enjoué | Anglais (États-Unis) (en-US)Japonais (Japon) ( ja-JP) 1Chinois (mandarin, simplifié) ( zh-CN) 1 |
| mécontent | Chinois (mandarin, simplifié) (zh-CN) 1 |
| excité | Anglais (États-Unis) (en-US) |
| craintif | Chinois (mandarin, simplifié) (zh-CN) 1 |
| convivial | Anglais (États-Unis) (en-US) |
| optimiste | Anglais (États-Unis) (en-US) |
| triste | Anglais (États-Unis) (en-US)Japonais (Japon) ( ja-JP) 1Chinois (mandarin, simplifié) ( zh-CN) 1 |
| cris | Anglais (États-Unis) (en-US) |
| sérieux | Chinois (mandarin, simplifié) (zh-CN) 1 |
| terrifié | Anglais (États-Unis) (en-US) |
| peu sympathique | Anglais (États-Unis) (en-US) |
| murmure | Anglais (États-Unis) (en-US) |
1 Le style de voix neuronale est disponible en préversion publique. Les styles en préversion publique sont uniquement disponibles dans ces régions de service : USA Est, Europe Ouest et Asie Sud-Est.
Obtenir l’état de l’entraînement
Pour obtenir l’état d’apprentissage d’un modèle vocal, utilisez l’opération Models_Get de l’API de voix personnalisée. Construisez l’URI de la requête conformément aux instructions suivantes :
Effectuez une requête HTTP GET à l’aide de l’URI, comme illustré dans l’exemple Models_Get suivant.
- Remplacez
YourResourceKeypar votre clé de ressource Speech. - Remplacez
YourResourceRegionpar votre région de ressource Speech. - Remplacez
JessicaModelIdsi vous avez spécifié un ID de modèle différent à l’étape précédente.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
Vous devriez recevoir un corps de réponse au format suivant.
Remarque
La recette kind et les autres propriétés dépendent de la façon dont vous avez effectué l’apprentissage de la voix. Dans cet exemple, le type de recette est Default pour l’apprentissage de voix neuronale.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Vous devrez peut-être attendre plusieurs minutes avant la fin de l’apprentissage. Finalement, l’état passe à Succeeded ou Failed.