Copiez et transformez des données dans Microsoft Fabric Lakehouse à l'aide d'Azure Data Factory ou d'Azure Synapse Analytics
S’APPLIQUE À :  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Conseil
Essayez Data Factory dans Microsoft Fabric, une solution d’analyse tout-en-un pour les entreprises. Microsoft Fabric couvre tous les aspects, du déplacement des données à la science des données, en passant par l’analyse en temps réel, l’aide à la décision et la création de rapports. Découvrez comment démarrer un nouvel essai gratuitement !
Microsoft Fabric Lakehouse est une plateforme d’architecture de données permettant de stocker, de gérer et d’analyser des données structurées et non structurées dans un emplacement unique. Pour bénéficier d’un accès fluide aux données dans l’ensemble des moteurs de calcul dans Microsoft Fabric, reportez-vous à l’article Tables Lakehouse et Delta Lake pour en savoir plus. Par défaut, les données sont écrites dans Lakehouse Table dans V-Order, et vous pouvez accéder à l’optimisation de la table Delta Lake et V-Order pour plus d’informations.
Cet article décrit comment utiliser l'activité Copy pour copier des données depuis et vers Microsoft Fabric Lakehouse et comment utiliser Data Flow pour transformer des données dans Microsoft Fabric Lakehouse. Pour en savoir plus, lisez l’article d’introduction pour Azure Data Factory ou Azure Synapse Analytics.
Fonctionnalités prises en charge
Ce connecteur Microsoft Fabric Lakehouse est pris en charge pour les fonctionnalités suivantes :
| Fonctionnalités prises en charge | IR |
|---|---|
| Activité de copie (source/récepteur) | ① ② |
| Mappage de flux de données (source/récepteur) | ① |
| Activité de recherche | ① ② |
| Activité GetMetadata | ① ② |
| Supprimer l’activité | ① ② |
① Runtime d’intégration Azure ② Runtime d’intégration auto-hébergé
Bien démarrer
Pour effectuer l’activité Copie avec un pipeline, vous pouvez vous servir de l’un des outils ou kits SDK suivants :
- L’outil Copier des données
- Le portail Azure
- Le kit SDK .NET
- Le kit SDK Python
- Azure PowerShell
- L’API REST
- Le modèle Azure Resource Manager
Créez un service lié à Microsoft Fabric Lakehouse à l’aide de l’interface utilisateur
Procédez comme suit pour créer un service lié à Microsoft Fabric Lakehouse dans l’interface utilisateur du portail Azure.
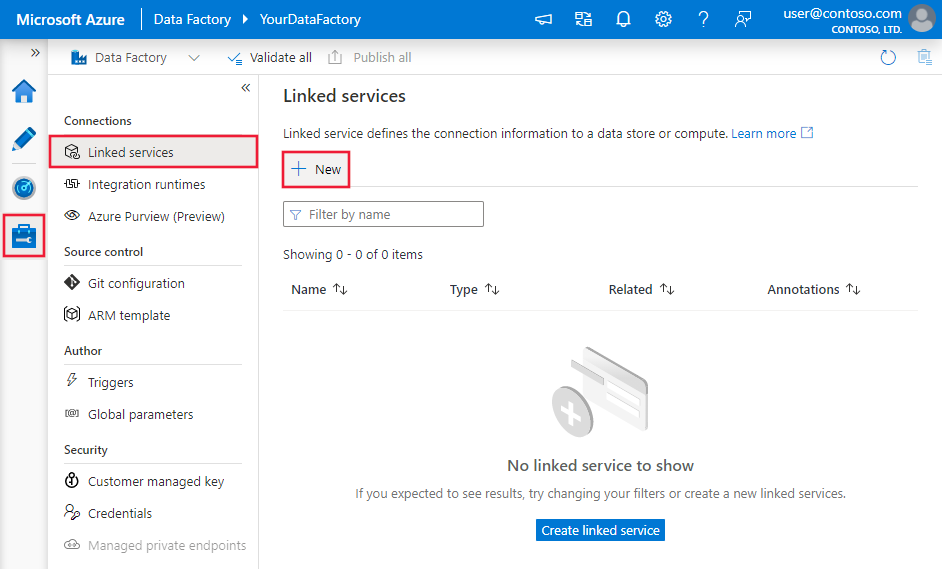
Accédez à l'onglet Gérer dans votre espace de travail Azure Data Factory ou Synapse, sélectionnez Services liés, puis sélectionnez Nouveau :
Recherchez Microsoft Fabric Lakehouse et sélectionnez le connecteur.
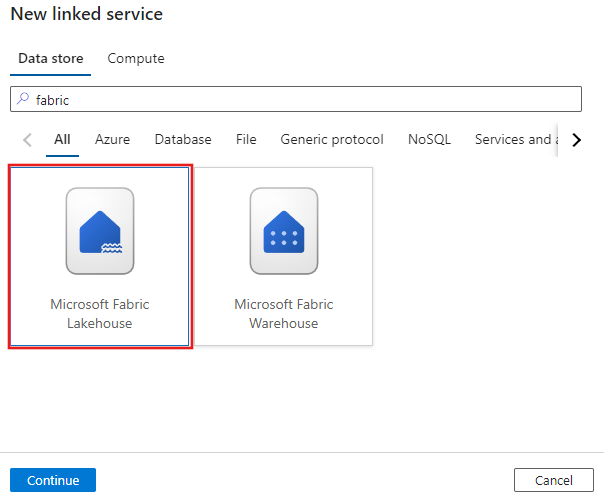
Configurez les informations du service, testez la connexion et créez le nouveau service lié.
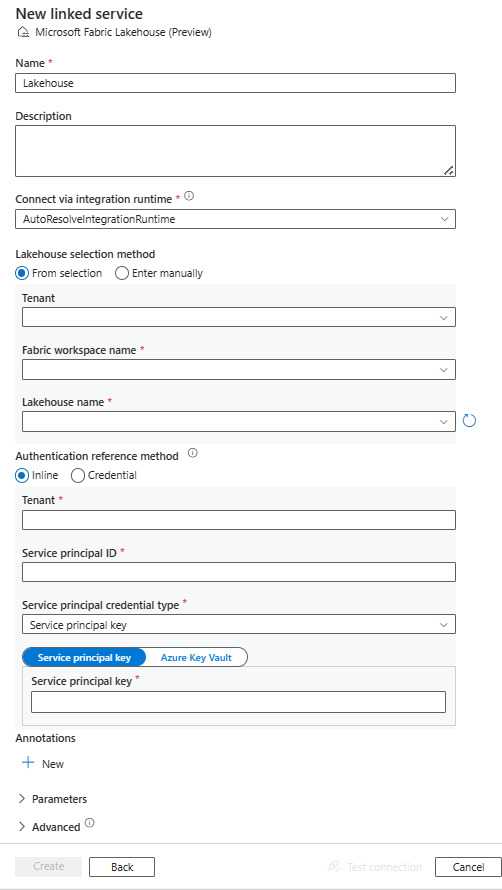
Informations de configuration des connecteurs
Les sections suivantes fournissent des détails sur les propriétés utilisées pour définir les entités Data Factory spécifiques au connecteur Microsoft Fabric Lakehouse.
Propriétés du service lié
Le connecteur Microsoft Fabric Lakehouse prend en charge les types d’authentification suivants. Consultez les sections correspondantes pour plus d’informations :
Authentification d’un principal du service
Pour l’authentification de principal de service, effectuez les étapes suivantes.
Enregistrez une application auprès de la plateforme Microsoft Identity Microsoft Identity et ajoutez une clé secrète client. Prenez ensuite note de ces valeurs, que vous utiliserez pour définir le service lié :
- ID de l'application (client), correspondant à l'ID du principal du service lié.
- Valeur de la clé secrète client, correspondant à la clé principale du service lié.
- ID client
Accordez au moins le rôle Contributeur au principal du service dans l’espace de travail Microsoft Fabric. Procédez comme suit :
Accédez à votre espace de travail Microsoft Fabric, sélectionnez Gérer l’accès dans la barre supérieure. Sélectionnez ensuite Ajouter des personnes ou des groupes.
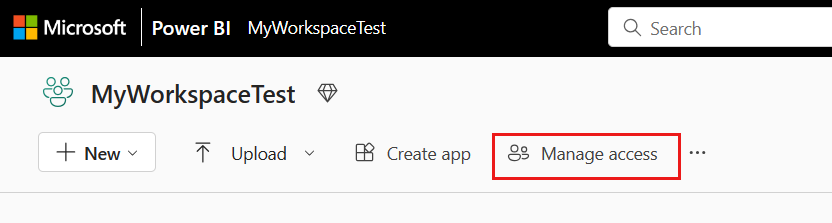
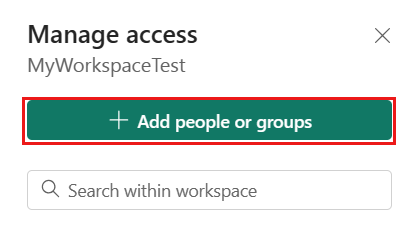
Dans le volet Ajouter des personnes, entrez le nom de votre principal de service et sélectionnez votre principal de service dans la liste déroulante.
Remarque
Le principal de service n’apparaît pas dans la liste Ajouter des personnes, sauf si les paramètres du locataire Power BI permettent aux principaux de service d’accéder aux API Fabric.
Spécifiez le rôle en tant que Contributeur ou version ultérieure (Administrateur, Membre), puis sélectionnez Ajouter.
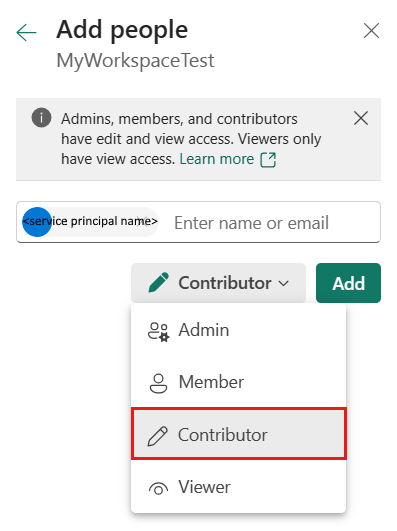
Votre principal de service s’affiche dans le volet Gérer l’accès.
Ces propriétés sont prises en charge pour le service lié :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type peut être définie sur Lakehouse. | Oui |
| workspaceId | L’ID de l’espace de travail Microsoft Fabric. | Oui |
| artifactId | L’ID d’objet Microsoft Fabric Lakehouse. | Oui |
| tenant | Spécifiez les informations de locataire (nom de domaine ou ID de locataire) dans lesquels se trouve votre application. Récupérez-les en pointant la souris dans le coin supérieur droit du Portail Azure. | Oui |
| servicePrincipalId | Spécifiez l’ID client de l’application. | Oui |
| servicePrincipalCredentialType | Type d’informations d’identification à utiliser pour l’authentification de principal du service. Les valeurs autorisées sont ServicePrincipalKey et ServicePrincipalCert. | Oui |
| servicePrincipalCredential | Informations d’identification du principal du service. En utilisant ServicePrincipalKey comme type d'informations d'identification, spécifiez la valeur de la clé secrète client de l'application. Marquez ce champ en tant que SecureString afin de le stocker en toute sécurité, ou référencez un secret stocké dans Azure Key Vault. Lorsque vous utilisez ServicePrincipalCert comme informations d’identification, référencez un certificat dans Azure Key Vault et vérifiez que le type de contenu du certificat est PKCS #12. |
Oui |
| connectVia | Le runtime d’intégration à utiliser pour se connecter à la banque de données. Vous pouvez utiliser le runtime d'intégration Azure ou un runtime d’intégration auto-hébergé si votre banque de données se trouve sur un réseau privé. À défaut de spécification, l’Azure Integration Runtime par défaut est utilisé. | Non |
Exemple : utilisation de l’authentification de la clé du principal de service
Vous pouvez également stocker la clé du principal du service dans Azure Key Vault.
{
"name": "MicrosoftFabricLakehouseLinkedService",
"properties": {
"type": "Lakehouse",
"typeProperties": {
"workspaceId": "<Microsoft Fabric workspace ID>",
"artifactId": "<Microsoft Fabric Lakehouse object ID>",
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalCredentialType": "ServicePrincipalKey",
"servicePrincipalCredential": {
"type": "SecureString",
"value": "<service principal key>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriétés du jeu de données
Le connecteur Microsoft Fabric Lakehouse prend en charge deux types de jeux de données : le jeu de données Microsoft Fabric Lakehouse Files et le jeu de données Microsoft Fabric Lakehouse Table. Pour plus d’informations, consultez les sections correspondantes.
Pour obtenir la liste complète des sections et propriétés disponibles pour la définition de jeux de données, consultez l’article sur les jeux de données.
Jeu de données Microsoft Fabric Lakehouse Files
Le connecteur Microsoft Fabric Lakehouse prend en charge les formats de fichiers suivants. Reportez-vous à chaque article pour les paramètres basés sur le format.
Les propriétés suivantes sont prises en charge sous les paramètres location du jeu de données Microsoft Fabric Lakehouse Files basé sur le format :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété de type sous location dans le jeu de données doit être définie sur LakehouseLocation. |
Oui |
| folderPath | Chemin d’accès du dossier. Si vous souhaitez utiliser un caractère générique pour filtrer les dossiers, ignorez ce paramètre et spécifiez-le dans les paramètres de la source de l’activité. | Non |
| fileName | Nom de fichier dans le chemin d’accès folderPath donné. Si vous souhaitez utiliser un caractère générique pour filtrer les fichiers, ignorez ce paramètre et spécifiez-le dans les paramètres de la source de l’activité. | Non |
Exemple :
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"location": {
"type": "LakehouseLocation",
"fileName": "<file name>",
"folderPath": "<folder name>"
},
"columnDelimiter": ",",
"compressionCodec": "gzip",
"escapeChar": "\\",
"firstRowAsHeader": true,
"quoteChar": "\""
},
"schema": [ < physical schema, optional, auto retrieved during authoring > ]
}
}
Jeu de données Microsoft Fabric Lakehouse Table
Les propriétés suivantes sont prises en charge pour le jeu de données Microsoft Fabric Lakehouse Table :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type du jeu de données doit être définie sur LakehouseTable. | Oui |
| schéma | Nom du schéma. Si elle n’est pas spécifiée, la valeur par défaut est dbo. |
Non |
| table | Nom de votre table. | Oui |
Exemple :
{
"name": "LakehouseTableDataset",
"properties": {
"type": "LakehouseTable",
"linkedServiceName": {
"referenceName": "<Microsoft Fabric Lakehouse linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"schema": "<schema_name>",
"table": "<table_name>"
},
"schema": [< physical schema, optional, retrievable during authoring >]
}
}
Propriétés de l’activité de copie
Les propriétés d’activité Copy du jeu de données Microsoft Fabric Lakehouse Files et du jeu de données Microsoft Fabric Lakehouse Table sont différentes. Pour plus d’informations, consultez les sections correspondantes.
- Microsoft Fabric Lakehouse Files dans l’activité Copy
- Microsoft Fabric Lakehouse Table dans l’activité Copy
Pour obtenir la liste complète des sections et des propriétés disponibles pour la définition des activités, consultez les articles Configurations des activités de copie et Pipelines et activités.
Microsoft Fabric Lakehouse Files dans l’activité Copy
Pour utiliser le type de jeu de données Microsoft Fabric Lakehouse Files en tant que source ou récepteur dans l’activité Copy, accédez aux sections suivantes pour connaître les configurations détaillées.
Microsoft Fabric Lakehouse Files en tant que type de source
Le connecteur Microsoft Fabric Lakehouse prend en charge les formats de fichiers suivants. Reportez-vous à chaque article pour les paramètres basés sur le format.
Plusieurs options vous permettent de copier des données à partir de Microsoft Fabric Lakehouse en utilisant le jeu de données Microsoft Fabric Lakehouse Files :
- Copier à partir du chemin d’accès spécifié dans le jeu de données.
- Filtre de caractères génériques sur le chemin d’accès du dossier ou le nom du fichier, consultez
wildcardFolderPathetwildcardFileName. - Copier les fichiers définis dans un fichier texte donné en tant que jeu de fichiers, consultez
fileListPath.
Les propriétés suivantes figurent sous les paramètres storeSettings de la source de copie basée sur le format lors de l’utilisation du jeu de données Microsoft Fabric Lakehouse Files :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété de type sous storeSettings doit être définie sur LakehouseReadSettings. |
Oui |
| Recherchez les fichiers à copier : | ||
| OPTION 1 : chemin d’accès statique |
Effectuez une copie à partir du chemin d’accès au dossier/fichier spécifié dans le jeu de données. Si vous souhaitez copier tous les fichiers d’un dossier, spécifiez en plus wildcardFileName comme *. |
|
| OPTION 2 : caractère générique - wildcardFolderPath |
Chemin d’accès du dossier avec des caractères génériques pour filtrer les dossiers sources. Les caractères génériques autorisés sont : * (correspond à zéro ou plusieurs caractères) et ? (correspond à zéro ou un caractère) ; utilisez ^ en guise d’échappement si votre nom de dossier contient effectivement ce caractère d’échappement ou générique. Consultez d’autres exemples dans les exemples de filtre de dossier et de fichier. |
Non |
| OPTION 2 : caractère générique - wildcardFileName |
Nom du fichier avec des caractères génériques situé dans le chemin d’accès folderPath/wildcardFolderPath donné pour filtrer les fichiers sources. Les caractères génériques autorisés sont : * (correspond à zéro ou plusieurs caractères) et ? (correspond à zéro ou un caractère) ; utilisez ^ en guise d’échappement si votre nom de fichier contient effectivement ce caractère d’échappement ou générique. Consultez d’autres exemples dans les exemples de filtre de dossier et de fichier. |
Oui |
| OPTION 3 : liste de fichiers - fileListPath |
Indique de copier un ensemble de fichiers donné. Pointez vers un fichier texte contenant la liste des fichiers que vous voulez copier, un fichier par ligne indiquant le chemin d’accès relatif configuré dans le jeu de données. Si vous utilisez cette option, ne spécifiez pas de nom de fichier dans le jeu de données. Pour plus d’exemples, consultez Exemples de listes de fichiers. |
Non |
| Paramètres supplémentaires : | ||
| recursive | Indique si les données sont lues de manière récursive à partir des sous-dossiers ou uniquement du dossier spécifié. Lorsque l’option « recursive » est définie sur true et que le récepteur est un magasin basé sur un fichier, un dossier vide ou un sous-dossier n’est pas copié ou créé sur le récepteur. Les valeurs autorisées sont true (par défaut) et false. Cette propriété ne s’applique pas lorsque vous configurez fileListPath. |
Non |
| deleteFilesAfterCompletion | Indique si les fichiers binaires seront supprimés du magasin source après leur déplacement vers le magasin de destination. La suppression se faisant par fichier, lorsque l’activité Copy échoue, vous constatez que certains fichiers ont déjà été copiés vers la destination et supprimés de la source, tandis que d’autres restent dans le magasin source. Cette propriété est valide uniquement dans un scénario de copie de fichiers binaires. La valeur par défaut est false. |
Non |
| modifiedDatetimeStart | Filtre de fichiers en fonction de l’attribut : Dernière modification. Les fichiers seront sélectionnés si l’heure de leur dernière modification est supérieure ou égale à modifiedDatetimeStart et inférieure à modifiedDatetimeEnd. L’heure est appliquée au fuseau horaire UTC au format « 2018-12-01T05:00:00Z ». Les propriétés peuvent être NULL, ce qui signifie qu’aucun filtre d’attribut de fichier n’est appliqué au jeu de données. Lorsque modifiedDatetimeStart a une valeur DateHeure, mais que modifiedDatetimeEnd est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est supérieur ou égal à la valeur DateHeure sont sélectionnés. Lorsque modifiedDatetimeEnd a une valeur DateHeure, mais que modifiedDatetimeStart est NULL, cela signifie que les fichiers dont l’attribut de dernière modification est inférieur à la valeur DateHeure sont sélectionnés.Cette propriété ne s’applique pas lorsque vous configurez fileListPath. |
Non |
| modifiedDatetimeEnd | Identique à ce qui précède. | Non |
| enablePartitionDiscovery | Pour les fichiers partitionnés, spécifiez s’il faut analyser les partitions à partir du chemin d’accès au fichier et les ajouter en tant que colonnes d’une autre source. Les valeurs autorisées sont false (par défaut) et true. |
Non |
| partitionRootPath | Lorsque la découverte de partition est activée, spécifiez le chemin d’accès racine absolu pour pouvoir lire les dossiers partitionnés en tant que colonnes de données. S’il n’est pas spécifié, par défaut, – Quand vous utilisez le chemin d’accès du fichier dans le jeu de données ou la liste des fichiers sur la source, le chemin racine de la partition est le chemin d’accès configuré dans le jeu de données. – Quand vous utilisez le filtre de dossiers de caractères génériques, le chemin racine de la partition est le sous-chemin avant le premier caractère générique. Par exemple, en supposant que vous configurez le chemin d’accès dans le jeu de données en tant que « root/folder/year=2020/month=08/day=27 » : – Si vous spécifiez le chemin racine de la partition en tant que « root/folder/year=2020 », l’activité de copie génère deux colonnes supplémentaires, month et day, ayant respectivement la valeur « 08 » et « 27 », en plus des colonnes contenues dans les fichiers.– Si le chemin racine de la partition n’est pas spécifié, aucune colonne supplémentaire n’est générée. |
Non |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Non |
Exemple :
"activities": [
{
"name": "CopyFromLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delimited text input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "LakehouseReadSettings",
"recursive": true,
"enablePartitionDiscovery": false
},
"formatSettings": {
"type": "DelimitedTextReadSettings"
}
},
"sink": {
"type": "<sink type>"
}
}
}
]
Microsoft Fabric Lakehouse Files en tant que type de récepteur
Le connecteur Microsoft Fabric Lakehouse prend en charge les formats de fichiers suivants. Reportez-vous à chaque article pour les paramètres basés sur le format.
Les propriétés suivantes figurent sous les paramètres storeSettings du récepteur de copie basé sur le format lors de l’utilisation du jeu de données Microsoft Fabric Lakehouse Files :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété de type sous storeSettings doit être définie sur LakehouseWriteSettings. |
Oui |
| copyBehavior | Définit le comportement de copie lorsque la source est constituée de fichiers d’une banque de données basée sur un fichier. Les valeurs autorisées sont les suivantes : - PreserveHierarchy (par défaut) : conserve la hiérarchie des fichiers dans le dossier cible. Le chemin relatif du fichier source vers le dossier source est identique au chemin relatif du fichier cible vers le dossier cible. - FlattenHierarchy : tous les fichiers du dossier source figurent dans le premier niveau du dossier cible. Les noms des fichiers cibles sont générés automatiquement. - MergeFiles : fusionne tous les fichiers du dossier source dans un seul fichier. Si le nom de fichier est spécifié, le nom de fichier fusionné est le nom spécifié. Dans le cas contraire, il s’agit d’un nom de fichier généré automatiquement. |
Non |
| blockSizeInMB | Spécifiez la taille du bloc (en Mo) qui est utilisée pour écrire des données dans Microsoft Fabric Lakehouse. En savoir plus sur les objets blobs de blocs. Les valeurs autorisées sont comprises entre 4 et 100 Mo. Par défaut, ADF détermine automatiquement la taille du bloc en fonction du type et des données de votre magasin source. Pour une copie non binaire dans Microsoft Fabric Lakehouse, la taille de bloc par défaut est de 100 Mo, ce qui permet le stockage d’environ 4,75 To de données au maximum. Cela peut ne pas être optimal si vos données ne sont pas volumineuses, en particulier si vous utilisez un runtime d’intégration auto-hébergé avec un réseau insuffisant qui entraîne l’expiration des opérations ou un problème de performances. Vous pouvez spécifier explicitement une taille de bloc, tout en veillant à ce que blockSizeInMB*50000 soit suffisamment grand pour stocker les données. Si ce n’est pas le cas, l’exécution de l’activité Copy échoue. |
Non |
| maxConcurrentConnections | La limite supérieure de connexions simultanées établies au magasin de données pendant l’exécution de l’activité. Spécifiez une valeur uniquement lorsque vous souhaitez limiter les connexions simultanées. | Non |
| metadata | Définissez des métadonnées personnalisées lors de la copie dans le récepteur. Chaque objet sous le tableau metadata représente une colonne supplémentaire. name définit le nom de clé de métadonnées et value indique la valeur des données de cette clé. Si la fonctionnalité de conservation des attributs est utilisée, les métadonnées spécifiées vont s’unir/remplacer les métadonnées du fichier source.Les valeurs de données autorisées sont : - $$LASTMODIFIED : une variable réservée indique de stocker l’heure de la dernière modification des fichiers sources. Appliquez à la source basée sur un fichier uniquement avec le format binaire.- Expression - Valeur statique |
Non |
Exemple :
"activities": [
{
"name": "CopyToLakehouseFiles",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Parquet output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "ParquetSink",
"storeSettings": {
"type": "LakehouseWriteSettings",
"copyBehavior": "PreserveHierarchy",
"metadata": [
{
"name": "testKey1",
"value": "value1"
},
{
"name": "testKey2",
"value": "value2"
}
]
},
"formatSettings": {
"type": "ParquetWriteSettings"
}
}
}
}
]
Exemples de filtres de dossier et de fichier
Cette section décrit le comportement résultant de l’utilisation de filtres de caractères génériques dans les noms de fichier et les chemins de dossier.
| folderPath | fileName | recursive | Structure du dossier source et résultat du filtrage (les fichiers en gras sont récupérés) |
|---|---|---|---|
Folder* |
(vide, utiliser la valeur par défaut) | false | DossierA Fichier1.csv File2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
Folder* |
(vide, utiliser la valeur par défaut) | true | DossierA Fichier1.csv File2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
Folder* |
*.csv |
false | DossierA Fichier1.csv Fichier2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
Folder* |
*.csv |
true | DossierA Fichier1.csv Fichier2.json Sousdossier1 File3.csv File4.json File5.csv AutreDossierB Fichier6.csv |
Exemples de liste de fichiers
Cette section décrit le comportement résultant de l’utilisation du chemin d’accès à la liste de fichiers dans la source de l’activité de copie.
En supposant que vous disposez de la structure de dossiers source suivante et que vous souhaitez copier les fichiers en gras :
| Exemple de structure source | Contenu de FileListToCopy.txt | Configuration ADF |
|---|---|---|
| filesystem DossierA Fichier1.csv Fichier2.json Sousdossier1 File3.csv File4.json File5.csv Métadonnées FileListToCopy.txt |
File1.csv Subfolder1/File3.csv Subfolder1/File5.csv |
Dans le jeu de données : - chemin d’accès du dossier : FolderADans la source de l’activité de copie : - chemin d’accès à la liste de fichiers : Metadata/FileListToCopy.txt Le chemin d’accès à la liste de fichiers pointe vers un fichier texte dans le même magasin de données qui contient la liste de fichiers que vous voulez copier, un fichier par ligne étant le chemin d’accès relatif au chemin d’accès configuré dans le jeu de données. |
Quelques exemples de valeurs recursive et copyBehavior
Cette section décrit le comportement résultant de l’opération de copie pour différentes combinaisons de valeurs recursive et copyBehavior.
| recursive | copyBehavior | Structure du dossier source | Cible obtenue |
|---|---|---|---|
| true | preserveHierarchy | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le Dossier1 cible est créé et structuré de la même manière que la source : Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
| true | flattenHierarchy | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit : Folder1 nom généré automatiquement pour Fichier1 nom généré automatiquement pour Fichier2 nom généré automatiquement pour Fichier3 nom généré automatiquement pour Fichier4 nom généré automatiquement pour Fichier5 |
| true | mergeFiles | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit : Folder1 Le contenu de Fichier1 + Fichier2 + Fichier3 + Fichier4 + Fichier5 est fusionné dans un fichier avec un nom de fichier généré automatiquement. |
| false | preserveHierarchy | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit : Folder1 Fichier1 Fichier2 Sous-dossier1, où Fichier3, Fichier4 et Fichier5 ne sont pas sélectionnés. |
| false | flattenHierarchy | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit : Folder1 nom généré automatiquement pour Fichier1 nom généré automatiquement pour Fichier2 Sous-dossier1, où Fichier3, Fichier4 et Fichier5 ne sont pas sélectionnés. |
| false | mergeFiles | Folder1 Fichier1 Fichier2 Sousdossier1 Fichier3 Fichier4 Fichier5 |
Le dossier cible Dossier1 est créé et structuré comme suit : Folder1 Le contenu de Fichier1 + Fichier2 est fusionné dans un fichier avec un nom de fichier généré automatiquement. nom généré automatiquement pour Fichier1 Sous-dossier1, où Fichier3, Fichier4 et Fichier5 ne sont pas sélectionnés. |
Microsoft Fabric Lakehouse Table dans l’activité Copy
Pour utiliser le jeu de données Microsoft Fabric Lakehouse Table en tant que source ou récepteur dans l’activité Copy, accédez aux sections suivantes pour connaître les configurations détaillées.
Microsoft Fabric Lakehouse Table en tant que type de source
Pour copier des données à partir de Microsoft Fabric Lakehouse en utilisant le jeu de données Microsoft Fabric Lakehouse Table, définissez la propriété type dans la source d’activité Copy sur LakehouseTableSource. Les propriétés suivantes sont prises en charge dans la section source de l’activité Copy :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité Copy doit être définie sur LakehouseTableSource. | Oui |
| timestampAsOf | Horodatage pour interroger un instantané plus ancien. | Non |
| versionAsOf | Version permettant d’interroger un instantané plus ancien. | Non |
Exemple :
"activities":[
{
"name": "CopyFromLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "LakehouseTableSource",
"timestampAsOf": "2023-09-23T00:00:00.000Z",
"versionAsOf": 2
},
"sink": {
"type": "<sink type>"
}
}
}
]
Microsoft Fabric Lakehouse Table en tant que type de récepteur
Pour copier des données dans Microsoft Fabric Lakehouse en utilisant le jeu de données Microsoft Fabric Lakehouse Table, définissez la propriété type dans le récepteur d’activité Copy sur LakehouseTableSink. Les propriétés suivantes sont prises en charge dans la section récepteur de l’activité Copy :
| Propriété | Description | Obligatoire |
|---|---|---|
| type | La propriété type de la source d’activité Copy doit être définie sur LakehouseTableSink. | Oui |
Remarque
Par défaut, les données sont écrites dans Lakehouse Table dans V-Order. Pour plus d'informations, consultez Optimisation de la table Delta Lake et V-Order.
Exemple :
"activities":[
{
"name": "CopyToLakehouseTable",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Microsoft Fabric Lakehouse Table output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "LakehouseTableSink",
"tableActionOption ": "Append"
}
}
}
]
Propriétés du mappage de flux de données
Lors de la transformation des données dans le flux de données de mappage, vous pouvez lire et écrire dans des fichiers ou des tables de Microsoft Fabric Lakehouse. Pour plus d’informations, consultez les sections correspondantes.
- Microsoft Fabric Lakehouse Files dans le flux de données de mappage
- Microsoft Fabric Lakehouse Table dans le flux de données de mappage
Pour plus d’informations, consultez la transformation de la source et la transformation du récepteur dans le flux de données de mappage.
Microsoft Fabric Lakehouse Files dans le flux de données de mappage
Pour utiliser le jeu de données Microsoft Fabric Lakehouse Files en tant que source ou récepteur dans le flux de données de mappage, accédez aux sections suivantes pour connaître les configurations détaillées.
Fichiers Microsoft Fabric Lakehouse en tant que type de source ou récepteur
Le connecteur Microsoft Fabric Lakehouse prend en charge les formats de fichiers suivants. Reportez-vous à chaque article pour les paramètres basés sur le format.
Pour utiliser le connecteur basé sur des fichiers Fabric Lakehouse dans le type de jeu de données inclus, vous devez choisir le bon type de jeu de données inclus pour vos données. Vous pouvez utiliser DelimitedText, Avro, JSON, ORC ou Parquet en fonction de votre format de données.
Microsoft Fabric Lakehouse Table dans le flux de données de mappage
Pour utiliser le jeu de données Microsoft Fabric Lakehouse Table en tant que source ou récepteur dans le flux de données de mappage, accédez aux sections suivantes pour connaître les configurations détaillées.
Microsoft Fabric Lakehouse Table en tant que type de source
Il n’existe aucune propriété configurable dans les options sources.
Remarque
La prise en charge de la capture des changements de données pour la source de table Lakehouse n’est pas disponible actuellement.
Microsoft Fabric Lakehouse Table en tant que type de récepteur
Les propriétés suivantes sont prises en charge dans la section récepteur de flux de données de mappage :
| Nom | Description | Obligatoire | Valeurs autorisées | Propriété du script de flux de données |
|---|---|---|---|---|
| Mettre à jour la méthode | Lorsque vous sélectionnez « Autoriser l’insertion » seul ou lorsque vous écrivez dans une nouvelle table delta, la cible reçoit toutes les lignes entrantes, quelles que soient les stratégies de ligne définies. Si vos données contiennent des lignes d’autres stratégies de ligne, elles doivent être exclues à l’aide d’une transformation de filtre précédente. Lorsque toutes les méthodes De mise à jour sont sélectionnées, une fusion est effectuée, où les lignes sont insérées/supprimées/upserted/mises à jour conformément à l’ensemble de stratégies de ligne à l’aide d’une transformation Alter Row précédente. |
Oui | true ou false |
insertable deletable upsertable updateable |
| Écriture optimisée | Obtenez un débit plus élevé pour l’opération d’écriture par le biais de l’optimisation de la lecture aléatoire interne dans les exécuteurs Spark. Il peut en résulter moins de partitions et de fichiers de plus grande taille. | non | true ou false |
optimizedWrite : true |
| Compactage automatique | Une fois qu’une opération d’écriture est terminée, Spark exécute automatiquement la commande OPTIMIZE pour réorganiser les données, ce qui entraîne davantage de partitions si nécessaire, pour une meilleure lecture des performances à l’avenir. |
non | true ou false |
autoCompact : true |
| Fusionner le schéma | Lorsque l’option Fusionner le schéma est activée, cela permet une évolution du schéma. Ainsi, toutes les colonnes présentes dans le flux entrant actuel, mais pas dans la table Delta cible, sont automatiquement ajoutées à son schéma. Cette option est prise en charge pour toutes les méthodes de mise à jour. | non | true ou false |
mergeSchema: true |
Exemple : Récepteur de Microsoft Fabric Lakehouse Table
sink(allowSchemaDrift: true,
validateSchema: false,
input(
CustomerID as string,
NameStyle as string,
Title as string,
FirstName as string,
MiddleName as string,
LastName as string,
Suffix as string,
CompanyName as string,
SalesPerson as string,
EmailAddress as string,
Phone as string,
PasswordHash as string,
PasswordSalt as string,
rowguid as string,
ModifiedDate as string
),
deletable:false,
insertable:true,
updateable:false,
upsertable:false,
optimizedWrite: true,
mergeSchema: true,
autoCompact: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CustomerTable
Pour le connecteur basé sur les tables Fabric Lakehouse dans le type de jeu de données inclus, il suffit d'utiliser Delta comme type de jeu de données. Cette action vous permet de lire et d'écrire des données à partir des tables Fabric Lakehouse.
Propriétés de l’activité Lookup
Pour en savoir plus sur les propriétés, consultez Activité Lookup.
Propriétés de l’activité GetMetadata
Pour en savoir plus sur les propriétés, consultez Activité GetMetadata.
Propriétés de l’activité Delete
Pour en savoir plus sur les propriétés, consultez Activité Delete.
Contenu connexe
Consultez les magasins de données pris en charge pour obtenir la liste des sources et magasins de données pris en charge en tant que récepteurs par l’activité de copie.