Démarrage rapide : Créer un cluster Apache Kafka dans Azure HDInsight à l’aide du portail Azure
Apache Kafka est une plateforme de streaming open source distribuée. Elle est souvent utilisée comme broker de messages, car elle propose des fonctionnalités similaires à une file d’attente de messages de publication/abonnement.
Dans ce guide de démarrage rapide, vous allez apprendre à créer un cluster Apache Kafka à l’aide du portail Azure. Il vous expliquera également comment utiliser les utilitaires inclus pour envoyer et recevoir des messages avec Apache Kafka. Pour obtenir des explications détaillées sur les configurations disponibles, consultez Configurer des clusters dans HDInsight. Pour plus d’informations sur l’utilisation du portail pour créer des clusters, consultez Créer des clusters dans le portail.
Avertissement
La facturation des clusters HDInsight est calculée au prorata des minutes écoulées, que vous les utilisiez ou non. Veillez à supprimer votre cluster une fois que vous avez terminé de l’utiliser. Consultez Guide pratique pour supprimer un cluster HDInsight.
L’API Apache Kafka n’est accessible qu’aux ressources se trouvant dans le même réseau virtuel. Dans ce guide de démarrage rapide, vous accéderez directement au cluster suivant le protocole SSH. Pour connecter d’autres services, réseaux ou machines virtuelles à Apache Kafka, vous devez tout d’abord créer un réseau virtuel, puis créer les ressources au sein du réseau. Pour plus d’informations, consultez le document Se connecter à Apache Kafka à l’aide d’un réseau virtuel. Pour plus d’informations générales sur la planification de réseaux virtuels pour HDInsight, consultez Planifier un réseau virtuel pour Azure HDInsight.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
Un client SSH. Pour plus d’informations, consultez Se connecter à HDInsight (Apache Hadoop) à l’aide de SSH.
Créer un cluster Apache Kafka
Pour créer un cluster Apache Kafka sur HDInsight, effectuez les étapes suivantes :
Connectez-vous au portail Azure.
Dans le menu du haut, sélectionnez + Créer une ressource.
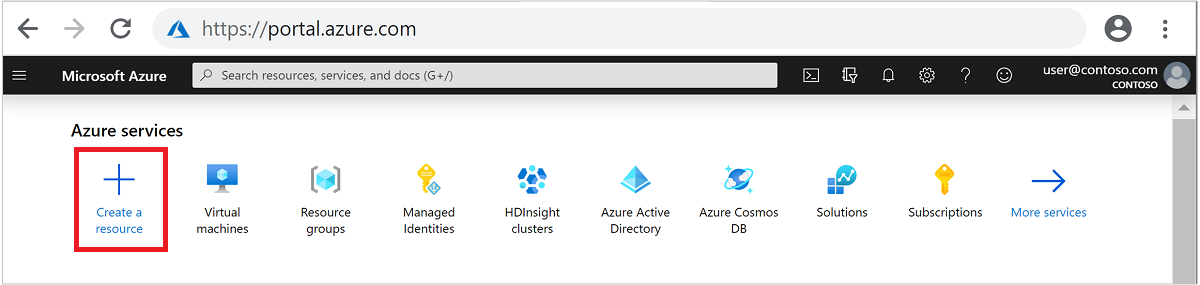
Sélectionnez Analyse>Azure HDInsight pour accéder à la page Créer un cluster HDInsight.
Sous l’onglet De base, fournissez les informations suivantes :
Propriété Description Abonnement Dans la liste déroulante, sélectionnez l’abonnement Azure utilisé pour le cluster. Resource group Sélectionnez un groupe de ressources existant ou créez-en un. Un groupe de ressources est un conteneur de composants Azure. Dans ce cas, le groupe de ressources contient le cluster HDInsight et le compte de stockage Azure dépendant. Nom du cluster Entrez un nom globalement unique. Le nom peut comporter jusqu’à 59 caractères, dont des lettres, des chiffres et des traits d’union. Le premier caractère et le dernier caractère du nom ne peuvent pas être des traits d’union. Région Dans la liste déroulante, sélectionnez une région dans laquelle le cluster est créé. Choisissez une région proche de votre emplacement pour obtenir de meilleures performances. Type de cluster Choisissez Sélectionner un type de cluster pour ouvrir une liste. Dans la liste, sélectionnez Kafka comme type de cluster. Version La version par défaut du type de cluster sera spécifiée. Sélectionnez une version dans la liste déroulante si vous souhaitez en spécifier une différente. Nom d’utilisateur et mot de passe du cluster Le nom de connexion par défaut est admin. Le mot de passe doit comporter au moins 10 caractères et inclure au moins un chiffre, une lettre majuscule, une lettre minuscule et un caractère non alphanumérique (à l’exception des caractères' ` "). Veillez à ne pas indiquer des mots de passe courants commePass@word1.Nom d’utilisateur SSH (Secure Shell) Le nom d’utilisateur par défaut est sshuser. Vous pouvez fournir un autre nom pour le nom d’utilisateur SSH.Utiliser le mot de passe de connexion au cluster pour SSH Cochez cette case pour utiliser le même mot de passe utilisateur SSH que celui fourni pour l’utilisateur de connexion au cluster. 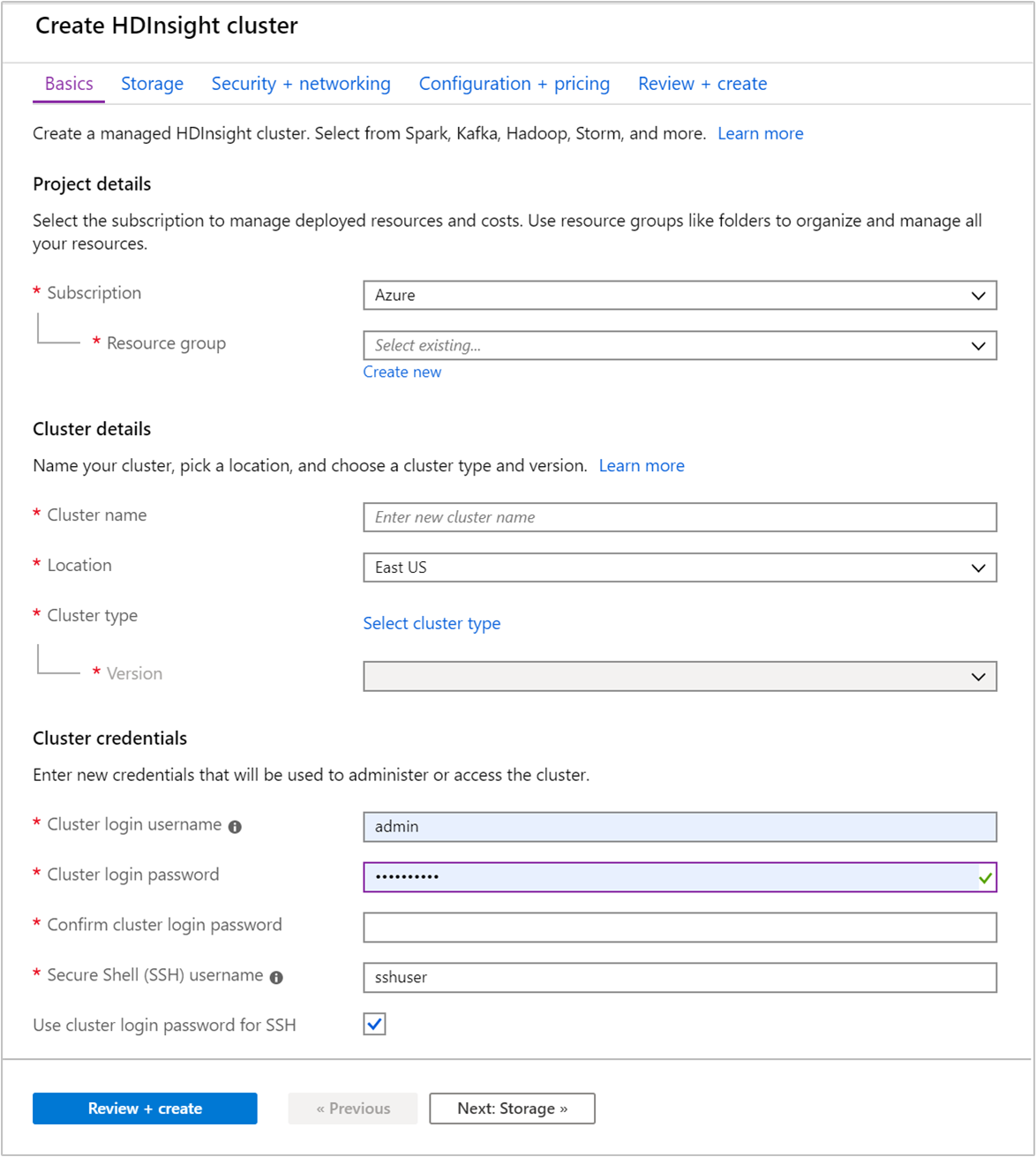
Chaque région Azure (emplacement) fournit des domaines d’erreur. Un domaine d’erreur est un regroupement logique de matériel sous-jacent dans un datacenter Azure. Chaque domaine d’erreur partage une source d’alimentation et un commutateur réseau communs. Les machines virtuelles et les disques managés mettant en œuvre les nœuds au sein d’un cluster HDInsight sont répartis dans ces domaines d’erreur. Cette architecture limite l’impact potentiel des défaillances de matériel physique.
Pour garantir la haute disponibilité des données, sélectionnez une région (emplacement) comportant trois domaines d’erreur. Pour plus d’informations sur le nombre de domaines d’erreur dans une région, consultez le document Disponibilité des machines virtuelles Linux.
Sélectionnez l’onglet Suivant : Stockage >> pour passer aux paramètres de stockage.
À partir de l’onglet Stockage, indiquez les valeurs suivantes :
Propriété Description Type de stockage principal Utilisez la valeur par défaut : Stockage Azure. Méthode de sélection Utilisez la valeur par défaut : Sélectionner dans la liste. Compte de stockage principal Utilisez la liste déroulante pour sélectionner un compte de stockage existant, ou sélectionnez Créer nouveau. Si vous créez un compte, son nom doit contenir entre 3 et 24 caractères alphanumériques minuscules. Conteneur Utilisez la valeur renseignée automatiquement. 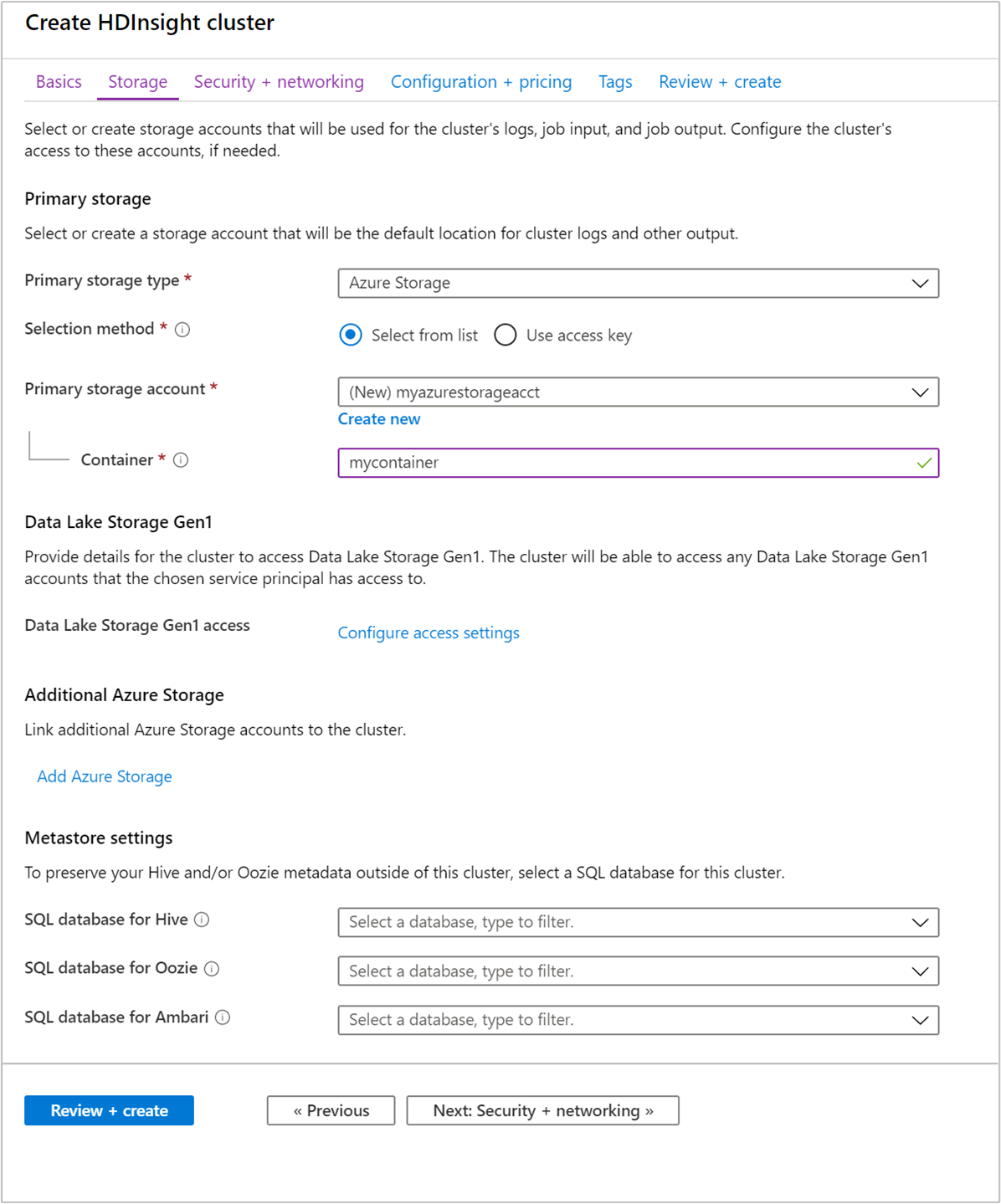
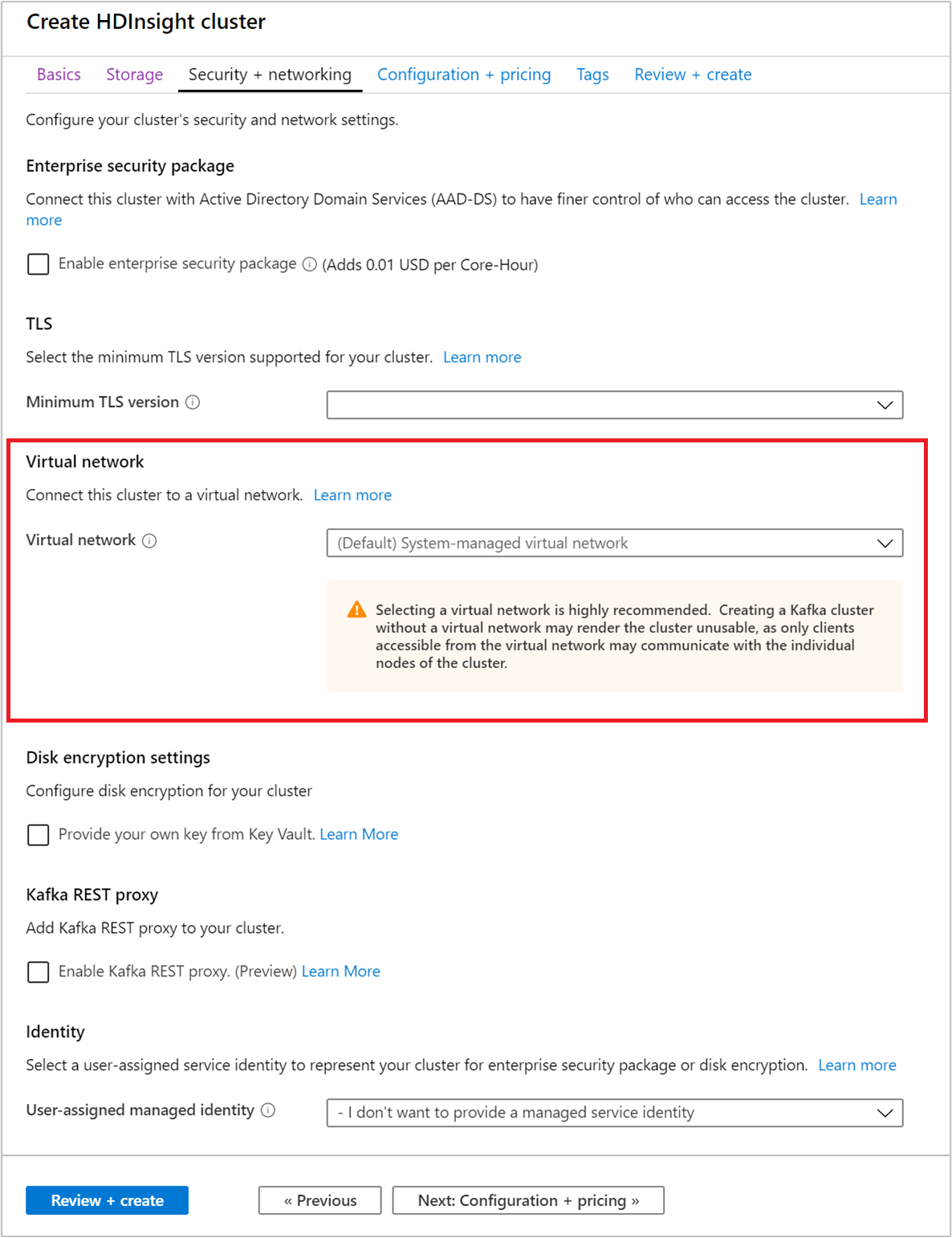
Sélectionnez l’onglet Sécurité + réseau.
Pour ce guide de démarrage rapide, laissez la valeur par défaut des paramètres de sécurité. Pour en savoir plus sur le pack Sécurité Entreprise, visitez Configurer un cluster HDInsight avec le pack Sécurité Entreprise en utilisant Microsoft Entra Domain Services. Pour savoir comment utiliser votre propre clé pour le chiffrement de disque Apache Kafka, consultez Chiffrement de disque avec les clés gérées par le client.
Si vous souhaitez connecter votre cluster à un réseau virtuel, sélectionnez un réseau virtuel à partir de la liste déroulante du Réseau virtuel.
Sélectionnez l’onglet Configuration + Tarifs.
Pour garantir la disponibilité d’Apache Kafka sur HDInsight, le nombre de nœuds de l’entrée Nœud Worker doit être supérieur ou égal à 3. La valeur par défaut est 4.
L’entrée relative aux disques standards par nœud worker configure la scalabilité d’Apache Kafka sur HDInsight. Apache Kafka sur HDInsight utilise le disque local des machines virtuelles du cluster pour stocker les données. En raison de son utilisation intensive des E/S, Apache Kafka utilise Azure Disques managés pour obtenir un débit élevé et davantage de stockage à chaque nœud. Le type de disque managé peut être soit Standard (HDD), soit Premium (SSD). Le type de disque dépend de la taille de la machine virtuelle utilisée par les nœuds de travail (brokers Apache Kafka). Les disques Premium sont utilisés automatiquement avec les machines virtuelles des séries DS et GS. Tous les autres types de machines virtuelles utilisent des disques Standard.
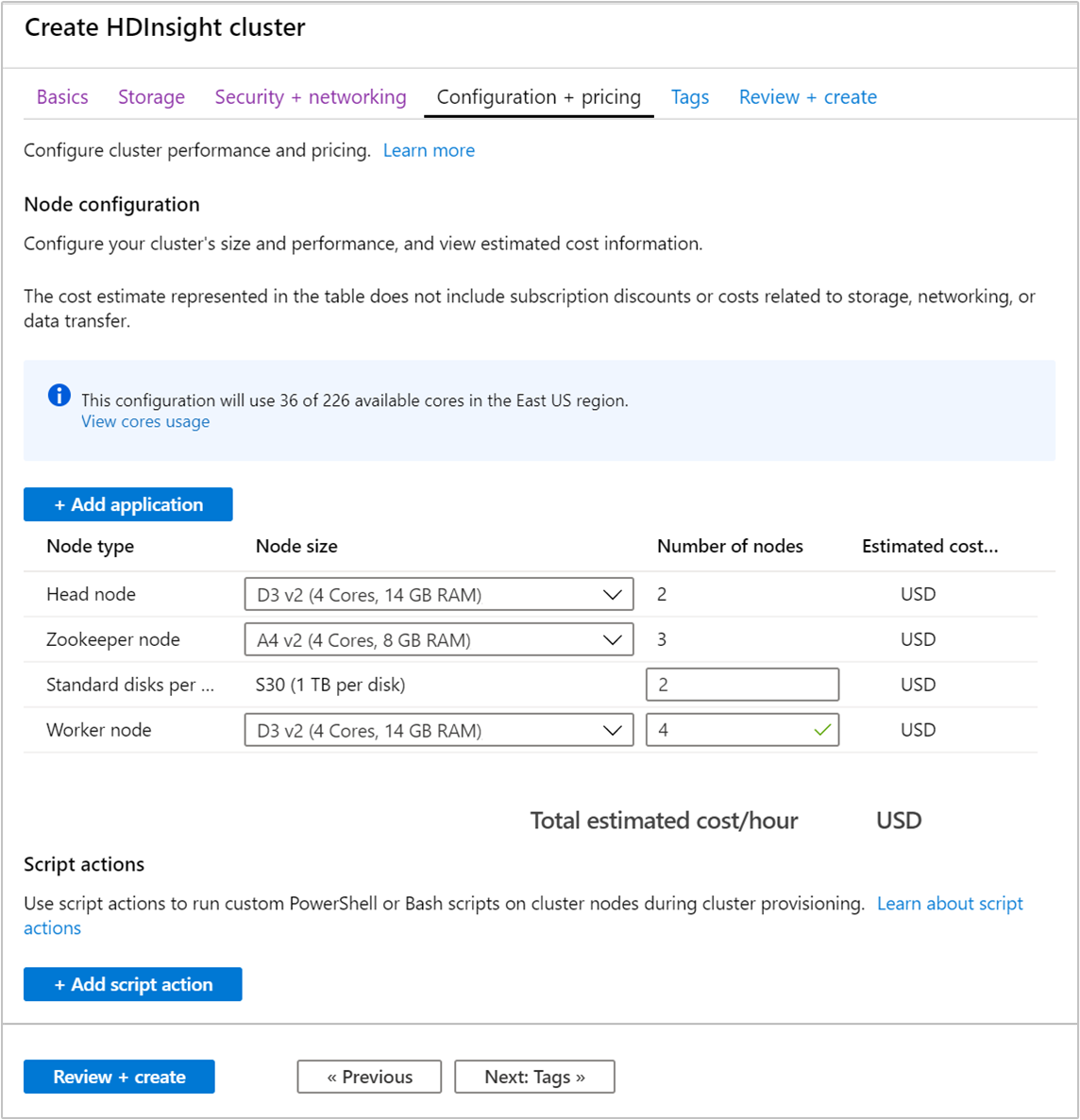
Sélectionnez l’onglet Vérifier + créer.
Passez en revue la configuration du cluster. Changez les éventuels paramètres incorrects. Enfin, sélectionnez Créer pour créer le cluster.
La création du cluster peut prendre jusqu’à 20 minutes.
Se connecter au cluster
Utilisez la commande ssh pour vous connecter à votre cluster. Modifiez la commande ci-dessous en remplaçant CLUSTERNAME par le nom de votre cluster, puis entrez la commande :
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netLorsque vous y êtes invité, entrez le mot de passe de l’utilisateur SSH.
Une fois la connexion établie, des informations de ce type s’affichent :
Authorized uses only. All activity may be monitored and reported. Welcome to Ubuntu 16.04.4 LTS (GNU/Linux 4.13.0-1011-azure x86_64) * Documentation: https://help.ubuntu.com * Management: https://landscape.canonical.com * Support: https://ubuntu.com/advantage Get cloud support with Ubuntu Advantage Cloud Guest: https://www.ubuntu.com/business/services/cloud 83 packages can be updated. 37 updates are security updates. Welcome to Apache Kafka on HDInsight. Last login: Thu Mar 29 13:25:27 2018 from 108.252.109.241
Obtenir des informations sur les hôtes Apache Zookeeper et Broker
Si vous utilisez Kafka, vous devez connaître les hôtes Apache ZooKeeper et Broker. Ces hôtes sont utilisés avec l’API Apache Kafka et la plupart des utilitaires fournis avec Kafka.
Dans cette section, vous allez obtenir les informations sur l’hôte grâce à l’API REST Apache Ambari sur le cluster.
Installez jq, un processeur JSON en ligne de commande. Il permet d’analyser des documents JSON, ce qui est utile pour analyser les informations sur l’hôte. À partir de la connexion SSH ouverte, entrez la commande suivante pour installer
jq:sudo apt -y install jqConfigurez une variable de mot de passe. Remplacez
PASSWORDpar le mot de passe de connexion du cluster, puis entrez la commande :export PASSWORD='PASSWORD'Extrayez le nom du cluster avec la bonne casse. La casse réelle du nom du cluster peut être différente de la casse attendue, suivant la façon dont le cluster a été créé. Cette commande obtient la casse réelle, puis la stocke dans une variable. Entrez la commande suivante :
export CLUSTER_NAME=$(curl -u admin:$PASSWORD -sS -G "http://headnodehost:8080/api/v1/clusters" | jq -r '.items[].Clusters.cluster_name')Notes
Si vous effectuez ce processus de l’extérieur du cluster, la procédure pour stocker le nom du cluster est différente. Récupérez le nom du cluster en minuscules à partir du portail Azure. Ensuite, remplacez le nom du cluster par
<clustername>dans la commande suivante, puis exécutez-la :export clusterName='<clustername>'.Pour définir une variable d’environnement avec les informations d’hôte Zookeeper, utilisez la commande ci-dessous. La commande récupère tous les hôtes ZooKeeper et retourne uniquement les deux premières entrées. ce qui assure une redondance au cas où l’un des hôtes serait inaccessible.
export KAFKAZKHOSTS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/ZOOKEEPER/components/ZOOKEEPER_SERVER | jq -r '["\(.host_components[].HostRoles.host_name):2181"] | join(",")' | cut -d',' -f1,2);Notes
Cette commande nécessite un accès à Ambari. Si votre cluster se trouve derrière un groupe de sécurité réseau, exécutez cette commande à partir d’un ordinateur qui peut accéder à Ambari.
Pour vérifier que la variable d’environnement est correctement définie, utilisez la commande suivante :
echo $KAFKAZKHOSTSCette commande retourne des informations semblables au texte suivant :
<zookeepername1>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181,<zookeepername2>.eahjefxxp1netdbyklgqj5y1ud.ex.internal.cloudapp.net:2181Pour définir une variable d’environnement avec les informations de l’hôte broker Apache Kafka, utilisez la commande suivante :
export KAFKABROKERS=$(curl -sS -u admin:$PASSWORD -G https://$CLUSTER_NAME.azurehdinsight.net/api/v1/clusters/$CLUSTER_NAME/services/KAFKA/components/KAFKA_BROKER | jq -r '["\(.host_components[].HostRoles.host_name):9092"] | join(",")' | cut -d',' -f1,2);Notes
Cette commande nécessite un accès à Ambari. Si votre cluster se trouve derrière un groupe de sécurité réseau, exécutez cette commande à partir d’un ordinateur qui peut accéder à Ambari.
Pour vérifier que la variable d’environnement est correctement définie, utilisez la commande suivante :
echo $KAFKABROKERSCette commande retourne des informations semblables au texte suivant :
<brokername1>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092,<brokername2>.eahjefxxp1netdbyklgqj5y1ud.cx.internal.cloudapp.net:9092
Gérer les rubriques Apache Kafka
Kafka stocke les flux de données dans des rubriques. Vous pouvez utiliser l’utilitaire kafka-topics.sh pour gérer les rubriques.
Pour créer une rubrique, utilisez la commande suivante dans la connexion SSH :
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --create --replication-factor 3 --partitions 8 --topic test --bootstrap-server $KAFKABROKERSCette commande se connecte à Broker à l’aide des informations d’hôte stockées dans
$KAFKABROKERS. Elle crée ensuite une rubrique Apache Kafka nommée test.Les données stockées dans cette rubrique sont partitionnées sur huit partitions.
Chaque partition est répliquée sur trois nœuds de travail du cluster.
Si vous avez créé le cluster dans une région Azure comportant trois domaines d’erreur, utilisez un facteur de réplication de trois. Sinon, utilisez un facteur de réplication de quatre.
Dans les régions comportant trois domaines d’erreur, un facteur de réplication de trois permet de répartir les réplicas entre les domaines d’erreur. Dans celles qui comptent deux domaines d’erreur, un facteur de réplication de quatre répartit uniformément les réplicas entre les domaines.
Pour plus d’informations sur le nombre de domaines d’erreur dans une région, consultez le document Disponibilité des machines virtuelles Linux.
Apache Kafka n’est pas informé des domaines d’erreur Azure. Lors de la création de réplicas de partitions pour les rubriques, il ne peut pas distribuer les réplicas correctement pour la haute disponibilité.
Pour garantir une haute disponibilité, utilisez l’outil de rééquilibrage de partitions d’Apache Kafka. Cet outil doit être exécuté à partir d’une connexion SSH au nœud principal du cluster Apache Kafka.
Pour garantir la haute disponibilité de vos données Apache Kafka, rééquilibrez les réplicas de partition de votre rubrique lorsque :
Vous créez une rubrique ou une partition
Vous mettez à l’échelle un cluster
Pour lister les rubriques, utilisez la commande suivante :
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --list --bootstrap-server $KAFKABROKERSCette commande liste les rubriques disponibles sur le cluster Apache Kafka.
Pour supprimer une rubrique, utilisez la commande suivante :
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh --delete --topic topicname --bootstrap-server $KAFKABROKERSCette commande supprime la rubrique nommée
topicname.Avertissement
Si vous supprimez la rubrique
testcréée précédemment, vous devrez la recréer. Elle sera utilisée ultérieurement dans ce document.
Pour plus d’informations sur les commandes disponibles avec l’utilitaire kafka-topics.sh, utilisez la commande suivante :
/usr/hdp/current/kafka-broker/bin/kafka-topics.sh
Produire et consommer des enregistrements
Kafka stocke les enregistrements dans des rubriques. Les enregistrements sont produits par des producteurs et utilisés par des consommateurs. Les producteurs et les consommateurs communiquent avec le service broker Kafka. Chacun des nœuds Worker de votre cluster HDInsight est un hôte broker Apache Kafka.
Pour stocker les enregistrements dans la rubrique test créée précédemment, puis les lire à l’aide d’un consommateur, procédez comme suit :
Pour écrire des enregistrements dans la rubrique, utilisez l’utilitaire
kafka-console-producer.shà partir de la connexion SSH :/usr/hdp/current/kafka-broker/bin/kafka-console-producer.sh --broker-list $KAFKABROKERS --topic testUne fois cette commande exécutée, vous accédez à une ligne vide.
Saisissez un message texte sur la ligne vide et appuyez sur Entrée. Entrez quelques messages de cette manière, puis utilisez Ctrl + C pour revenir à l’invite de commandes normale. Chaque ligne est envoyée en tant qu’enregistrement distinct vers la rubrique Apache Kafka.
Pour lire des enregistrements de la rubrique, utilisez l’utilitaire
kafka-console-consumer.shà partir de la connexion SSH :/usr/hdp/current/kafka-broker/bin/kafka-console-consumer.sh --bootstrap-server $KAFKABROKERS --topic test --from-beginningCette commande permet de récupérer les enregistrements à partir de la rubrique et de les afficher. L’utilisation de
--from-beginningindique au consommateur de démarrer à partir du début du flux, de manière à récupérer tous les enregistrements.Si vous utilisez une version antérieure de Kafka, remplacez
--bootstrap-server $KAFKABROKERSpar--zookeeper $KAFKAZKHOSTS.Utilisez la combinaison Ctrl + C pour arrêter le consommateur.
Vous pouvez également créer les producteurs et consommateurs par programme. Pour voir un exemple d’utilisation de cette API, consultez le document API de producteur et de consommateur Apache Kafka avec HDInsight.
Nettoyer les ressources
Pour supprimer les ressources créées par ce guide de démarrage rapide, vous pouvez supprimer le groupe de ressources. La suppression du groupe de ressources efface également le cluster HDInsight associé et d’autres ressources liées au groupe de ressources.
Pour supprimer le groupe de ressources à l’aide du portail Azure :
- Sur le portail Azure, développez le menu de gauche pour ouvrir le menu des services, et sélectionnez Groupes de ressources pour afficher la liste de vos groupes de ressources.
- Recherchez le groupe de ressources à supprimer, puis faites un clic droit sur le bouton Plus (...) se trouvant à droite de la liste.
- Sélectionnez Supprimer le groupe de ressources et confirmez.
Avertissement
La suppression d’un cluster Apache Kafka sur HDInsight entraîne la suppression de toutes les données stockées dans Kafka.