Déploiement de points de terminaison en ligne pour l’inférence en temps réel
S’APPLIQUE À : Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Cet article décrit les points de terminaison en ligne pour l’inférence en temps réel dans Azure Machine Learning. L’inférence est le processus qui consiste à appliquer de nouvelles données d’entrée à un modèle Machine Learning pour générer des sorties. Azure Machine Learning vous permet d’effectuer une inférence en temps réel sur des données à l’aide de modèles déployés sur des points de terminaison en ligne. Bien que ces sorties soient généralement appelées prédictions, vous pouvez utiliser l’inférence pour générer des sorties pour d’autres tâches d’apprentissage automatique, telles que la classification et le clustering.
Points de terminaison en ligne
Les points de terminaison en ligne déploient des modèles sur un serveur web pouvant retourner des prédictions sous le protocole HTTP. Les points de terminaison en ligne peuvent rendre des modèles opérationnels pour l’inférence en temps réel dans les requêtes synchrones à faible latence et leur utilisation est particulièrement pertinente lorsque :
- Vous êtes soumis à des exigences de faible latence.
- Votre modèle peut répondre à la requête dans un laps de temps relativement court.
- Les entrées de votre modèle correspondent à la charge utile HTTP de la requête.
- Vous devez effectuer un scale-up du nombre de requêtes.
Pour définir un point de terminaison, vous devez spécifier :
- Le nom du point de terminaison. Ce nom doit être unique dans la région Azure. Pour connaître les autres exigences de nom, consultez Points de terminaison en ligne Azure Machine Learning et points de terminaison par lots.
- Le mode d’authentification. Vous pouvez choisir parmi le mode d’authentification par clé, par jeton Azure Machine Learning ou l’authentification basée sur les jetons Microsoft Entra pour le point de terminaison. Pour plus d’informations sur l’authentification, consultez Authentifier les clients pour les points de terminaison en ligne.
Points de terminaison en ligne managés
Les points de terminaison en ligne managés déploient vos modèles de Machine Learning de manière pratique, clé en main, et sont la méthode recommandée pour utiliser des points de terminaison en ligne Azure Machine Learning. Les points de terminaison en ligne managés fonctionnent avec des ordinateurs de processeur et GPU puissants dans Azure de manière évolutive et entièrement gérée.
Pour vous éviter une surcharge liée à la configuration et à la gestion de l’infrastructure sous-jacente, ces points de terminaison se chargent aussi de servir, de mettre à l’échelle, de sécuriser et de superviser vos modèles. Pour savoir comment définir des points de terminaison en ligne managés, consultez Définir le point de terminaison.
Points de terminaison en ligne managés et Azure Container Instances ou Azure Kubernetes Service (AKS) v1
Les points de terminaison en ligne managés sont la méthode recommandée pour utiliser des points de terminaison en ligne dans Azure Machine Learning. Le tableau suivant met en évidence les attributs clés des points de terminaison en ligne managés par rapport aux solutions Azure Container Instances et Azure Kubernetes Service (AKS) v1.
| Attributs | Points de terminaison en ligne managés (v2) | Container Instances ou AKS (v1) |
|---|---|---|
| Sécurité/isolation de réseau | Contrôle entrant/sortant facile avec bascule rapide | Réseau virtuel non pris en charge ou nécessite une configuration manuelle complexe |
| Service géré | • Approvisionnement/mise à l’échelle du calcul complètement managé • Configuration réseau pour la prévention contre l’exfiltration de données • Mise à niveau du système d’exploitation hôte, déploiement contrôlé des mises à jour sur place |
• L’évolutivité est limitée • L’utilisateur doit gérer la configuration réseau ou la mise à niveau |
| Concept de point de terminaison/déploiement | La distinction entre point de terminaison et déploiement permet d’avoir des scénarios complexes tels que le déploiement sécurisé de modèles | Aucun concept de point de terminaison |
| Diagnostics et surveillance | • Débogage de point de terminaison local possible avec Docker et Visual Studio Code • Analyse avancée des métriques et des journaux avec graphique/requête pour comparer les déploiements • Détails des coûts jusqu’au niveau du déploiement |
Pas de débogage local facile |
| Évolutivité | Mise à l’échelle élastique et automatique (non limitée par la taille de cluster par défaut) | • Container Instances n’est pas scalable • AKS (v1) prend uniquement en charge la mise à l’échelle dans le cluster et nécessite une configuration de la scalabilité |
| Préparation pour l’entreprise | Liaison privée, clés gérées par le client, Microsoft Entra ID, gestion des quotas, intégration de facturation, contrat de niveau de service (SLA) | Non pris en charge |
| Fonctionnalités ML avancées | • Collection de données de modèle • Surveillance des modèles • Modèle champion-challenger, déploiement sécurisé, mise en miroir du trafic • Extensibilité de l’IA responsable |
Non pris en charge |
Points de terminaison en ligne managés et points de terminaison en ligne Kubernetes
Si vous préférez utiliser Kubernetes pour déployer vos modèles et servir des points de terminaison, et que vous êtes à l’aise avec la gestion des exigences d’infrastructure, vous pouvez utiliser des points de terminaison en ligne Kubernetes. Ces points de terminaison vous permettent de déployer des modèles et de servir des points de terminaison en ligne avec des UC et des GPU sur votre cluster Kubernetes entièrement configuré et managé où vous voulez.
Les points de terminaison en ligne managés peuvent vous aider à simplifier votre processus de déploiement et offrent les avantages suivants par rapport aux points de terminaison en ligne Kubernetes :
Gestion automatique de l’infrastructure
- Approvisionne le calcul et héberge le modèle. Vous spécifiez simplement le type de machine virtuelle et les paramètres de mise à l’échelle.
- Met à jour automatiquement et corrige l’image du système d’exploitation hôte sous-jacent.
- Effectue une récupération de nœud en cas de défaillance du système.
Supervision et journaux
- Permet de superviser la disponibilité, les performances et le contrat SLA du modèle à l’aide de l’intégration native à Azure Monitor.
- Facilite de débogage des déploiements à l’aide des journaux et de l’intégration native à Log Analytics.

-

Notes
Les points de terminaison en ligne managés sont basés sur le calcul Azure Machine Learning. Lorsque vous utilisez un point de terminaison en ligne managé, vous payez les frais de calcul et de mise en réseau. Il n’y a pas de surcharge supplémentaire. Pour plus d’informations sur la tarification, consultez la calculatrice de prix Azure.
Si vous utilisez un réseau virtuel Azure Machine Learning pour sécuriser le trafic sortant qui vient du point de terminaison en ligne managé, vous êtes facturé pour la liaison privée Azure et pour les règles de sortie de nom de domaine complet (FQDN) utilisées par le réseau virtuel managé. Pour plus d’informations, consultez Tarification des réseaux virtuels managés.


Le tableau suivant met en évidence les principales différences entre les points de terminaison en ligne managés et les points de terminaison en ligne Kubernetes.
| Points de terminaison en ligne managés | Points de terminaison en ligne Kubernetes (AKS v2) | |
|---|---|---|
| Utilisateurs concernés | Utilisateurs qui souhaitent un déploiement de modèle managé et une expérience MLOps améliorée | Utilisateurs qui préfèrent Kubernetes et peuvent autogérer les exigences d’infrastructure |
| Approvisionnement de nœuds | Approvisionnement, mise à jour, suppression du calcul managé | Responsabilité de l’utilisateur |
| Maintenance de nœuds | Mises à jour d’images managées d’un système d’exploitation hôte et renforcement de la sécurité | Responsabilité de l’utilisateur |
| Dimensionnement du cluster (mise à l’échelle) | Mise à l’échelle automatique et manuelle managée, prise en charge de l’approvisionnement de nœuds supplémentaires | Mise à l’échelle automatique et manuelle, prise en charge de la mise à l’échelle du nombre de réplicas dans les limites fixes du cluster |
| Type de capacité de calcul | Géré par le service | Cluster Kubernetes géré par le client |
| Identité gérée | Pris en charge | Pris en charge |
| Réseau virtuel | Pris en charge via l’isolation réseau managée | Responsabilité de l’utilisateur |
| Surveillance et journalisation prêtes à l’emploi | Optimisation d’Azure Monitor et de Log Analytics, inclut des métriques clés et des tables de journaux pour les points de terminaison et les déploiements | Responsabilité de l’utilisateur |
| Journalisation avec Application Insights (héritée) | Prise en charge | Pris en charge |
| Vue des coûts | Détails au niveau du point de terminaison/du déploiement | Au niveau du cluster |
| Coûts appliqués à | Machines virtuelles affectées au déploiement | Machines virtuelles affectées au cluster |
| Trafic en miroir | Pris en charge | Non pris en charge |
| Déploiement sans code | Prise en charge de modèles MLflow et Triton | Prise en charge de modèles MLflow et Triton |
Déploiements en ligne
Un déploiement est un ensemble de ressources et de calculs nécessaires pour héberger le modèle qui effectue l’inférence. Un seul point de terminaison peut contenir plusieurs déploiements avec différentes configurations. Cette configuration permet de dissocier l’interface présentée par le point de terminaison des détails d’implémentation présents dans le déploiement. Un point de terminaison en ligne a un mécanisme de routage qui peut diriger les requêtes vers des déploiements spécifiques dans le point de terminaison.
Le diagramme suivant montre un point de terminaison en ligne qui a deux déploiements : bleu et vert. Le déploiement bleu utilise des machines virtuelles avec une référence de processeur et exécute la version 1 d’un modèle. Le déploiement vert utilise des machines virtuelles avec une référence SKU GPU et exécute la version 2 du modèle. Le point de terminaison est configuré pour acheminer 90 % du trafic entrant vers le déploiement bleu, tandis que le déploiement vert reçoit les 10 % restants.
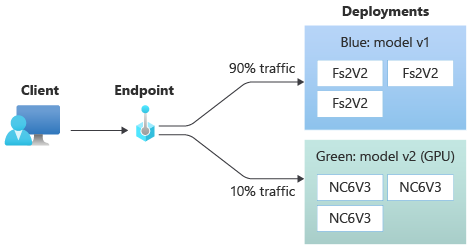
Pour déployer un modèle, vous devez disposer des éléments suivants :
Fichiers de modèle, ou nom et version d’un modèle déjà inscrit dans votre espace de travail.
Un code script de scoring, code qui exécute le modèle sur une demande d’entrée donnée.
Le script de scoring reçoit les données envoyées à un service web déployé et les passe au modèle. Le script exécute ensuite le modèle et retourne sa réponse au client. Le script de scoring est spécifique à votre modèle. Il doit comprendre les données que le modèle attend en tant qu’entrée et retourne en tant que sortie.
Un environnement pour exécuter votre modèle. L’environnement peut être une image Docker avec des dépendances Conda ou un Dockerfile.
Paramètres pour spécifier le type d’instance et capacité de mise à l’échelle.
Pour savoir comment déployer des points de terminaison en ligne à l’aide d’Azure CLI, du SDK Python, d’Azure Machine Learning studio ou d’un modèle ARM, consultez Déployer un modèle de Machine Learning à l’aide d’un point de terminaison en ligne.
Attributs clés d’un déploiement
Le tableau suivant décrit les attributs clés d’un déploiement :
| Attribut | Description |
|---|---|
| Nom | Le nom du déploiement. |
| Nom du point de terminaison | Nom du point de terminaison sous lequel créer le déploiement. |
| Modèle | Modèle à utiliser pour le déploiement. Cette valeur peut être une référence à un modèle versionné existant dans l’espace de travail ou une spécification de modèle inline. Pour plus d’informations sur le suivi et la spécification du chemin d’accès à votre modèle, consultez Spécifier le modèle à déployer pour l’utiliser dans un point de terminaison en ligne. |
| Chemin du code | Le chemin d’accès du répertoire dans l’environnement de développement local qui contient tout le code source Python pour le scoring du modèle. Vous pouvez utiliser des répertoires et des packages imbriqués. |
| Script de scoring | Le chemin relatif du fichier de scoring dans le répertoire de code source. Ce code Python doit avoir une fonction init() et une fonction run(). La fonction init() est appelée une fois le modèle créé ou mis à jour, par exemple pour mettre en cache le modèle en mémoire. La fonction run() est appelée à chaque appel du point de terminaison pour effectuer la notation et la prédiction réelles. |
| Environnement | L’environnement pour héberger le modèle et le code. Cette valeur peut être une référence à un environnement versionné existant dans l’espace de travail ou une spécification d’environnement inline. |
| Type d’instance | Taille de machine virtuelle à utiliser pour le déploiement. Pour obtenir la liste des tailles prises en charge, consultez la liste des références SKU des points de terminaison en ligne managés. |
| Nombre d’instances | Nombre d’instances à utiliser pour le déploiement. Basez la valeur sur la charge de travail que vous attendez. Pour la haute disponibilité, définissez la valeur sur au moins 3. Le système réserve un supplément de 20 % pour effectuer des mises à niveau. Pour plus d’informations, consultez allocation de quota du nombre de machines virtuelles pour les déploiements. |
Remarques pour les déploiements en ligne
Le déploiement peut référencer le modèle et l’image conteneur définis dans Environnement à tout moment, par exemple lorsque les instances de déploiement subissent des correctifs de sécurité ou d’autres opérations de récupération. Si vous utilisez un modèle inscrit ou une image conteneur dans Azure Container Registry pour le déploiement et que vous supprimez plus tard le modèle ou l’image conteneur, les déploiements qui s’appuient sur ces ressources peuvent échouer lorsque la réimagerie se produit. Si vous supprimez le modèle ou l’image conteneur, assurez-vous de recréer ou de mettre à jour les déploiements dépendants avec un autre modèle ou une autre image conteneur.
Le registre de conteneurs auquel l’environnement fait référence ne peut être privé que si l’identité du point de terminaison a l’autorisation d’y accéder via l’authentification Microsoft Entra et le contrôle d’accès en fonction du rôle (RBAC) Azure. Pour la même raison, les registres Docker privés autres que Container Registry ne sont pas pris en charge.
Microsoft corrige régulièrement les images de base pour les vulnérabilités de sécurité connues. Vous devez redéployer votre point de terminaison pour utiliser l’image corrigée. Si vous fournissez votre propre image, vous êtes chargé de la mettre à jour. Pour plus d’informations, consultez Mise à jour corrective des images.
Allocation de quota de machines virtuelles pour le déploiement
Azure Machine Learning réserve 20 % de vos ressources de calcul pour les points de terminaison en ligne managés afin d’exécuter des mises à niveau sur certaines références SKU de machine virtuelle. Si vous demandez un nombre donné d’instances pour ces références SKU de machines virtuelles dans un déploiement, vous devez disposer d’un quota de ceil(1.2 * number of instances requested for deployment) * number of cores for the VM SKU pour éviter d’obtenir une erreur. Par exemple, si vous demandez 10 instances d’une machine virtuelle Standard_DS3_v2 (qui comprend quatre cœurs) dans un déploiement, vous devez disposer d’un quota de 48 cœurs (12 instances * 4 cores) disponibles. Ce quota supplémentaire est réservé aux opérations initiées par le système, telles que les mises à niveau du système d’exploitation et la récupération de machine virtuelle, et elle n’entraîne pas de coûts, sauf si ces opérations s’exécutent.
Certaines références SKU de machine virtuelle sont exemptées d’une réservation de quota supplémentaire. Pour afficher la liste complète, consultez la liste des références SKU de points de terminaison en ligne managés. Pour afficher votre utilisation et demander des augmentations de quota, consultez Afficher votre utilisation et vos quotas dans le Portail Azure. Pour afficher votre coût d’exécution d’un point de terminaison en ligne managé, consultez Afficher les coûts d’un point de terminaison en ligne managé.
Pool de quotas partagés
Azure Machine Learning fournit un pool de quotas partagé auquel les utilisateurs de diverses régions peuvent accéder pour effectuer des tests pendant une durée limitée, en fonction de la disponibilité. Lorsque vous utilisez le studio pour déployer des modèles Llama-2, Phi, Nemotron, Mistral, Dolly et Deci-DeciLM à partir du catalogue de modèles vers un point de terminaison en ligne managé, Azure Machine Learning vous permet d’accéder à son pool de quotas partagés pendant une courte période afin de pouvoir effectuer des tests. Pour plus d’informations sur le pool de quotas partagés, consultez quota partagé Azure Machine Learning.
Pour déployer des modèles Llama-2, Phi, Nemotron, Mistral, Dolly et Deci-DeciLM à partir du catalogue de modèles avec un quota partagé, vous devez disposer d’un abonnement Contrat Entreprise. Pour plus d’informations sur l’utilisation du quota partagé pour le déploiement de points de terminaison en ligne, consultez le Guide pratique pour déployer des modèles de base à l’aide du studio.
Pour plus d’informations sur les quotas et les limites des ressources dans Azure Machine Learning, consultez Gérer et augmenter les quotas et les limites des ressources avec Azure Machine Learning.
Déploiement pour les codeurs et les non-codeurs
Azure Machine Learning prend en charge le déploiement de modèles sur des points de terminaison en ligne pour les codeurs et les non-codeurs, en fournissant des options pour les déploiements sas code, les déploiements low-code et les déploiements BYOC (Bring Your Own Container).
- Le déploiement sans code fournit une inférence prête à l’emploi pour les frameworks courants, comme scikit-learn, TensorFlow, PyTorch et Open Neural Network Exchange (ONNX) via MLflow et Triton.
- Déploiement à faible code vous permet de fournir un code minimal, ainsi que votre modèle Machine Learning pour le déploiement.
- Le déploiement BYOC vous permet d’apporter virtuellement tous les conteneurs pour exécuter votre point de terminaison en ligne. Vous pouvez utiliser toutes les fonctionnalités de la plateforme Azure Machine Learning, telles que la mise à l’échelle automatique, GitOps, le débogage et le déploiement sécurisé pour gérer vos pipelines MLOps.
Le tableau suivant met en évidence les principaux aspects des options de déploiement en ligne :
| Sans code | Faible quantité de code | BYOC | |
|---|---|---|---|
| Résumé | Utilise l’inférence prête à l’emploi des frameworks connus, tels que scikit-learn, TensorFlow, PyTorch et ONNX, via MLflow et Triton. Pour plus d’informations, consultez Déployer des modèles MLflow sur des points de terminaison en ligne. | Utilise les images organisées sécurisées et publiées des frameworks connus, avec des mises à jour toutes les deux semaines pour corriger les vulnérabilités. Vous fournissez un script de scoring et/ou des dépendances Python. Pour plus d’informations, consultez Environnements organisés Azure Machine Learning. | Vous fournissez votre pile complète via la prise en charge d’Azure Machine Learning des images personnalisées. Pour plus d’informations, consultez Utiliser un conteneur personnalisé pour déployer un modèle sur un point de terminaison en ligne. |
| Image de base personnalisée | Aucune. Les environnements organisés fournissent l’image de base pour faciliter le déploiement. | Vous pouvez utiliser une image organisée ou votre image personnalisée. | Apportez un emplacement d’image conteneur accessible comme docker.io, Container Registry ou Microsoft Artifact Registry, ou un fichier Dockerfile que vous pouvez générer/envoyer (push) avec Container Registry pour votre conteneur. |
| Dépendances personnalisées | Aucune. Les environnements organisés fournissent des dépendances pour faciliter le déploiement. | Apportez l’environnement Azure Machine Learning dans lequel le modèle s’exécute, soit une image Docker avec des dépendances Conda, soit un dockerfile. | Les dépendances personnalisées sont incluses dans l’image conteneur. |
| Code personnalisé | Aucune. Le script de scoring est généré automatiquement pour faciliter le déploiement. | Apportez votre script de scoring. | Le script de scoring est inclus dans l’image conteneur. |
Remarque
Les exécutions AutoML créent automatiquement un script de scoring et des dépendances pour les utilisateurs. Pour le déploiement sans code, vous pouvez déployer n’importe quel modèle AutoML sans créer d’autre code. Pour le déploiement low-code, vous pouvez modifier les scripts générés automatiquement en fonction des besoins de votre entreprise. Pour savoir comment déployer avec des modèles AutoML, consultez Comment déployer un modèle AutoML sur un point de terminaison en ligne.
Débogage de points de terminaison en ligne
Si possible, testez votre point de terminaison localement pour valider et déboguer votre code et votre configuration avant de déployer sur Azure. L’interface Azure CLI et le SDK Python prennent en charge les points de terminaison et les déploiements locaux, contrairement à Azure Machine Learning studio et au modèle ARM, qui ne prennent pas en charge les points de terminaison et les déploiements locaux.
Azure Machine Learning offre les moyens suivants de déboguer des points de terminaison en ligne localement et à l’aide des journaux de conteneur :
- Débogage local avec un serveur HTTP d’inférence Azure Machine Learning
- Débogage local avec un point de terminaison local
- Débogage local avec un point de terminaison local et Visual Studio Code
- Débogage avec des journaux de conteneur
Débogage local avec un serveur HTTP d’inférence Azure Machine Learning
Vous pouvez déboguer votre script de scoring localement à l’aide du serveur HTTP d’inférence Azure Machine Learning. Le serveur HTTP est un package Python qui expose votre fonction de scoring en tant que point de terminaison HTTP, et enveloppe le code et les dépendances du serveur Flask dans un seul package.
Azure Machine Learning inclut un serveur HTTP dans les images Docker prédéfinies pour l’inférence utilisé pour déployer un modèle. En utilisant le package seul, vous pouvez déployer le modèle localement pour la production, et vous pouvez aussi valider facilement votre script de scoring d’entrée dans un environnement de développement local. En cas de problème avec le script de scoring, le serveur retourne une erreur et l’emplacement où l’erreur s’est produite. Vous pouvez également utiliser Visual Studio Code pour déboguer avec le serveur HTTP d’inférence Azure Machine Learning.
Conseil
Vous pouvez utiliser le package Python du serveur HTTP d’inférence Azure Machine Learning pour déboguer votre script de scoring localement sansdu moteur Docker. Le débogage avec le serveur d’inférence vous aide à déboguer le script de scoring avant le déploiement sur des points de terminaison locaux afin de pouvoir déboguer sans être affecté par les configurations de conteneur de déploiement.
Pour obtenir plus d’informations sur le débogage avec le serveur HTTP, consultez Déboguer du script de scoring avec le serveur HTTP d’inférence Azure Machine Learning.
Débogage local avec un point de terminaison local
Pour le débogage local, vous avez besoin d’un modèle déployé dans un environnement Docker local. Vous pouvez utiliser ce déploiement local pour le test et le débogage avant le déploiement dans le cloud.
Pour déployer localement, vous devez installer et exécuter Docker Engine. Azure Machine Learning crée ensuite une image Docker locale pour imiter l’image en ligne. Azure Machine Learning génère et exécute les déploiements pour vous localement et met l’image en cache pour des itérations rapides.
Conseil
Si le moteur Docker ne se lance pas au démarrage de l’ordinateur, vous pouvez résoudre les problèmes liés au moteur Docker. Vous pouvez utiliser des outils côté client comme Docker Desktop pour déboguer les événements dans le conteneur.
Le débogage local implique généralement les étapes suivantes :
- Vérifiez d’abord que le déploiement local a réussi.
- Ensuite, appelez le point de terminaison local pour l’inférence.
- Enfin, passez en revue les journaux de sortie de l’opération de
invoke.
Les points de terminaison locaux présentent les limitations suivantes :
Aucune prise en charge des règles de trafic, de l’authentification et des paramètres de sonde.
Qu’un seul déploiement par point de terminaison peut être pris en charge.
Prise en charge des fichiers de modèle local et l’environnement avec un fichier Conda local.
Pour tester des modèles inscrits, commencez par les télécharger à l’aide de l’interface CLI ou du SDK, puis utilisez
pathdans la définition de déploiement pour faire référence au dossier parent.Pour tester des environnements inscrits, vérifiez le contexte de l’environnement dans Azure Machine Learning studio et préparez un fichier Conda local à utiliser.
Pour obtenir plus d’informations sur le débogage local, consultez Déployer et déboguer localement à l’aide d’un point de terminaison local.
Débogage local avec un point de terminaison local et Visual Studio Code (préversion)
Important
Cette fonctionnalité est actuellement disponible en préversion publique. Cette préversion est fournie sans contrat de niveau de service et n’est pas recommandée pour les charges de travail de production. Certaines fonctionnalités peuvent être limitées ou non prises en charge.
Pour plus d’informations, consultez Conditions d’Utilisation Supplémentaires relatives aux Évaluations Microsoft Azure.
Comme pour le débogage local, vous devez installer et exécuter Docker Engine, puis déployer un modèle dans l’environnement Docker local. Une fois que vous avez un déploiement local, les points de terminaison locaux Azure Machine Learning utilisent les conteneurs de développement Docker et Visual Studio Code (conteneurs de développement) pour créer et configurer un environnement de débogage local.
Avec les conteneurs de développement, vous pouvez utiliser des fonctionnalités de Visual Studio Code, telles que le débogage interactif, au sein d’un conteneur Docker. Pour plus d’informations sur le débogage interactif de points de terminaison en ligne dans Visual Studio Code, consultez Déboguer des points de terminaison en ligne localement dans Visual Studio Code.
Débogage avec des journaux de conteneur
Vous ne pouvez pas accéder directement à une machine virtuelle où un modèle se déploie, mais vous pouvez obtenir des journaux à partir des conteneurs suivants qui s’exécutent sur la machine virtuelle :
- Le journal de console serveur d’inférence contient la sortie des fonctions d’impression/de journalisation de votre code score.py de script de scoring.
- Les journaux d’initialiseur de stockage contiennent des informations sur la réussite du téléchargement des données de code et de modèle sur le conteneur. Le conteneur s’exécute avant que le conteneur du serveur d’inférence ne commence à s’exécuter.
Pour obtenir plus d’informations sur le débogage avec les journaux de conteneur, consultez Obtenir les journaux de conteneur.
Routage et mise en miroir du trafic vers les déploiements en ligne
Un seul point de terminaison en ligne peut avoir plusieurs déploiements. À mesure que le point de terminaison reçoit les requêtes de trafic entrantes, il peut router des pourcentages de trafic vers chaque déploiement, comme dans la stratégie de déploiement bleu/vert natif. Le point de terminaison peut aussi mettre en miroir ou copier le trafic d’un déploiement vers un autre, ce qu’on appelle une mise en miroir du trafic ou mise en mémoire fantôme du trafic.
Routage du trafic pour le déploiement bleu/vert
Le déploiement bleu/vert est une stratégie de déploiement qui vous permet de déployer un nouveau déploiement vert sur un petit sous-ensemble d’utilisateurs ou de requêtes avant de le déployer complètement. Le point de terminaison peut implémenter un équilibrage de charge pour allouer certains pourcentages du trafic à chaque déploiement, avec une allocation totale entre tous les déploiements qui atteint 100 %.
Conseil
Une requête peut contourner l’équilibrage de charge du trafic configuré en incluant un en-tête HTTP de azureml-model-deployment. Définissez la valeur d’en-tête sur le nom du déploiement auquel vous souhaitez que la requête soit acheminée.
L’image suivante montre les paramètres dans Azure Machine Learning studio pour l’allocation du trafic entre un déploiement bleu et vert.
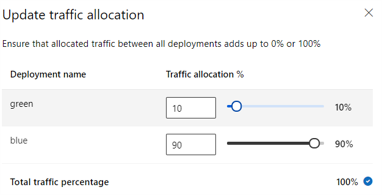
L’allocation de trafic précédente achemine 10 % du trafic vers le déploiement vert et 90 % du trafic vers le déploiement bleu, comme illustré dans l’image suivante.
Mise en miroir du trafic vers les déploiements en ligne
Le point de terminaison peut également mettre en miroir ou copier le trafic d’un déploiement vers un autre. Vous pouvez utiliser la mise en miroir du trafic, également appelée test fantôme, lorsque vous souhaitez tester un nouveau déploiement avec le trafic de production sans affecter les résultats que les clients reçoivent des déploiements existants.
Par exemple, vous pouvez implémenter un déploiement bleu/vert où 100 % du trafic est acheminé vers le bleu et 10 % est mis en miroir vers le déploiement vert. Les résultats du trafic mis en miroir vers le déploiement vert ne sont pas retournés vers clients, mais les métriques et les journaux sont enregistrés.

Pour plus d’informations sur l’utilisation de la mise en miroir de trafic, consultez Effectuer un déploiement sécurisé des nouveaux déploiements pour l’inférence en temps réel.
Plus de fonctionnalités de point de terminaison en ligne
Les sections suivantes décrivent d’autres fonctionnalités des points de terminaison en ligne Azure Machine Learning.
Authentification et chiffrement
- Authentification : clés et jetons Azure Machine Learning
- Identité managée : affectée par l’utilisateur et par le système
- SSL (Secure Socket Layer) par défaut pour l’appel de point de terminaison
Mise à l’échelle automatique
La mise à l’échelle automatique exécute automatiquement la quantité appropriée de ressources pour gérer la charge sur votre application. Les points de terminaison gérés prennent en charge la mise à l’échelle automatique via l’intégration à la fonctionnalité de mise à l’échelle automatique Azure Monitor. Vous pouvez configurer la mise à l’échelle basée sur des métriques, comme l’utilisation du processeur à >70 %, la mise à l’échelle basée sur la planification, comme les règles d’heure de pointe de l’entreprise, ou les deux.

Pour plus d’informations, consultez Mise à l’échelle automatique des points de terminaison en ligne dans Azure Machine Learning.
Isolation de réseau gérée
Quand vous déployez un modèle de Machine Learning sur un point de terminaison en ligne managé, vous pouvez sécuriser les communications avec ce point de terminaison en ligne au moyen de points de terminaison privés. Vous pouvez configurer la sécurité pour les demandes de scoring entrantes et les communications sortantes séparément.
Les communications entrantes utilisent le point de terminaison privé de l’espace de travail Azure Machine Learning, tandis que les communications sortantes utilisent des points de terminaison privés créés pour le réseau virtuel managé de l’espace de travail. Pour plus d’informations, consultez Isolement réseau avec des points de terminaison en ligne managés.
Surveillance des déploiements et des points de terminaison en ligne
Les points de terminaison Azure Machine Learning s’intègrent à Azure Monitor. L’intégration Azure Monitor vous permet d’afficher les métriques dans des graphiques, de configurer des alertes, d’interroger des tables de journal et d’utiliser Application Insights pour analyser les événements des conteneurs utilisateur. Pour plus d’informations, consultez Superviser des points de terminaison en ligne.
Injection de secrets dans les déploiements en ligne (préversion)
L’injection de secrets pour un déploiement en ligne implique de récupérer des secrets tels que des clés API à partir de magasins de secrets et de les injecter dans le conteneur utilisateur qui s’exécute à l’intérieur du déploiement. Pour fournir une consommation sécurisée des secrets pour le serveur d’inférence qui exécute votre script de scoring ou la pile d’inférence dans votre déploiement BYOC, vous pouvez utiliser des variables d’environnement pour accéder aux secrets.
Vous pouvez injecter des secrets vous-même à l’aide d’identités managées, ou utiliser la fonctionnalité d’injection de secrets. Pour plus d’informations, consultez Injection de secret dans les points de terminaison en ligne (préversion).
Contenu connexe
- Déployer et évaluer un modèle de Machine Learning à l’aide d’un point de terminaison en ligne
- Points de terminaison batch
- Sécuriser vos points de terminaison en ligne managés avec l’isolement réseau
- Déployer des modèles avec REST
- Analyser les points de terminaison en ligne
- Voir les coûts d’un point de terminaison en ligne managé Azure Machine Learning
- Gérer et augmenter les quotas et les limites de ressources avec Azure Machine Learning