Créer des règles de déploiement
Lorsque vous travaillez dans un pipeline de déploiement, les différentes phases pourraient avoir des configurations différentes. Par exemple, chaque étape peut avoir des bases de données différentes ou des paramètres de requête différents. L’étape de développement peut interroger des exemples de données de la base de données, tandis que les étapes de test et de production interrogent la base de données entière.
Lorsque vous déployez du contenu entre les phases du pipeline, vous pouvez configurer des règles de déploiement pour modifier le contenu tout en conservant certains paramètres intacts. Par exemple, vous pouvez définir une règle de modèle sémantique dans une étape de production pour qu’elle référence une base de données de production au lieu d’une base de données dans l’étape de test. La règle est définie à l’index de production, sous le modèle sémantique approprié. Une fois la règle définie, le contenu déployé du test en production hérite de la valeur telle qu’elle est définie dans la règle de déploiement. Cette règle s’applique toujours tant qu’elle est inchangée et valide.
Remarque
La nouvelle interface utilisateur du pipeline de déploiement est actuellement en préversion . Pour activer ou utiliser la nouvelle interface utilisateur, consultez Commencer à utiliser la nouvelle interface utilisateur.
Vous pouvez configurer des règles de source de données, de paramètre et des règles de lakehouse par défaut. Le tableau suivant répertorie les types d'éléments pour lesquels vous pouvez configurer des règles et le type de règle que vous pouvez configurer pour chacun.
| Article | Règle de source de données | Règle de paramètre | Règle par défaut pour lakehouse | Détails |
|---|---|---|---|---|
| Le flux de données | ✅ | ✅ | ❌ | À utiliser afin de déterminer les valeurs des sources de données ou des paramètres pour un dataflow spécifique. |
| Modèle sémantique | ✅ | ✅ | ❌ | Permet de déterminer les valeurs des sources de données ou des paramètres d’un modèle sémantique spécifique. |
| Datamart | ✅ | ✅ | ❌ | À utiliser afin de déterminer les valeurs des sources de données ou des paramètres pour un datamart données spécifique. |
| Rapport paginé | ✅ | ❌ | ❌ | Définis pour les sources de données de chaque rapport paginé. À utiliser afin de déterminer les sources de données du rapport paginé. |
| Notebook | ❌ | ❌ | ✅ | Vous pouvez les utiliser pour déterminer le lakehouse par défaut d'un notebook spécifique. |
Remarque
Les règles de source de données fonctionnent uniquement quand vous changez des sources de données du même type.
Créer une règle de déploiement
Pour créer une règle de déploiement, suivez les étapes décrites dans cette section. Après avoir créé toutes les règles de déploiement dont vous avez besoin, déployez les modèles sémantiques avec les nouvelles règles de l’étape source vers l’étape cible où les règles ont été créées. Vos règles ne sont pas appliquées tant que vous ne déployez pas les modèles sémantiques de l’étape source vers l’étape cible.
- Créer une règle de déploiement dans la nouvelle interface utilisateur
- Créer une règle de déploiement dans l’interface utilisateur d’origine
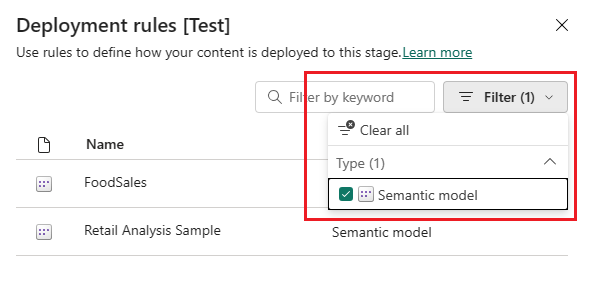
Dans la phase de pipeline pour laquelle vous souhaitez créer une règle de déploiement, sélectionnez Règles de déploiement.
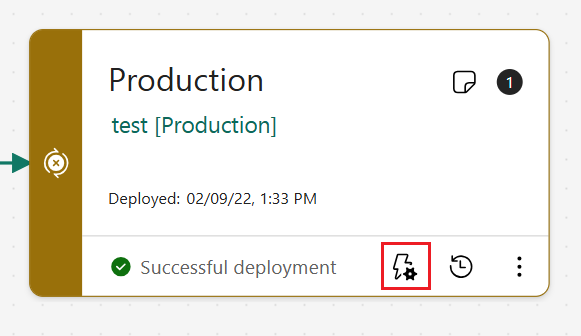
Une liste d’éléments pour laquelle vous pouvez définir des règles apparaît dans la fenêtre. Tous les éléments du pipeline ne sont pas répertoriés. Seuls les éléments d'un type pour lequel vous pouvez créer des règles sont répertoriés (flux de données, modèle sémantique, datamarts, notebooks et rapports paginés). Pour trouver l’élément pour lequel vous souhaitez définir une règle, utilisez les fonctionnalités de recherche ou de filtrage.
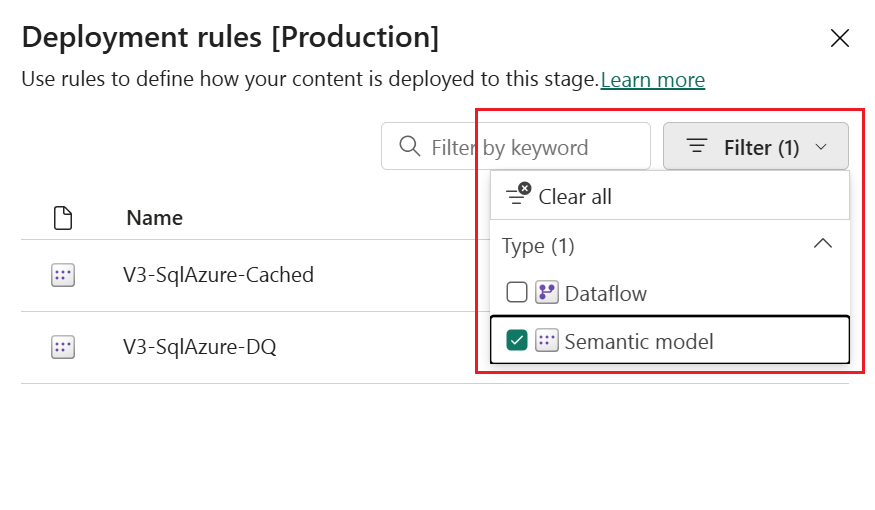
Sélectionnez l’élément pour lequel vous souhaitez créer une règle. Les types de règles que vous pouvez créer pour cet élément sont affichés. Par exemple, si vous créez une règle pour un flux de données, vous pouvez créer une règle de source de données ou une règle de paramètre. Si vous créez une règle pour un notebook, vous pouvez créer une règle de lakehouse par défaut.
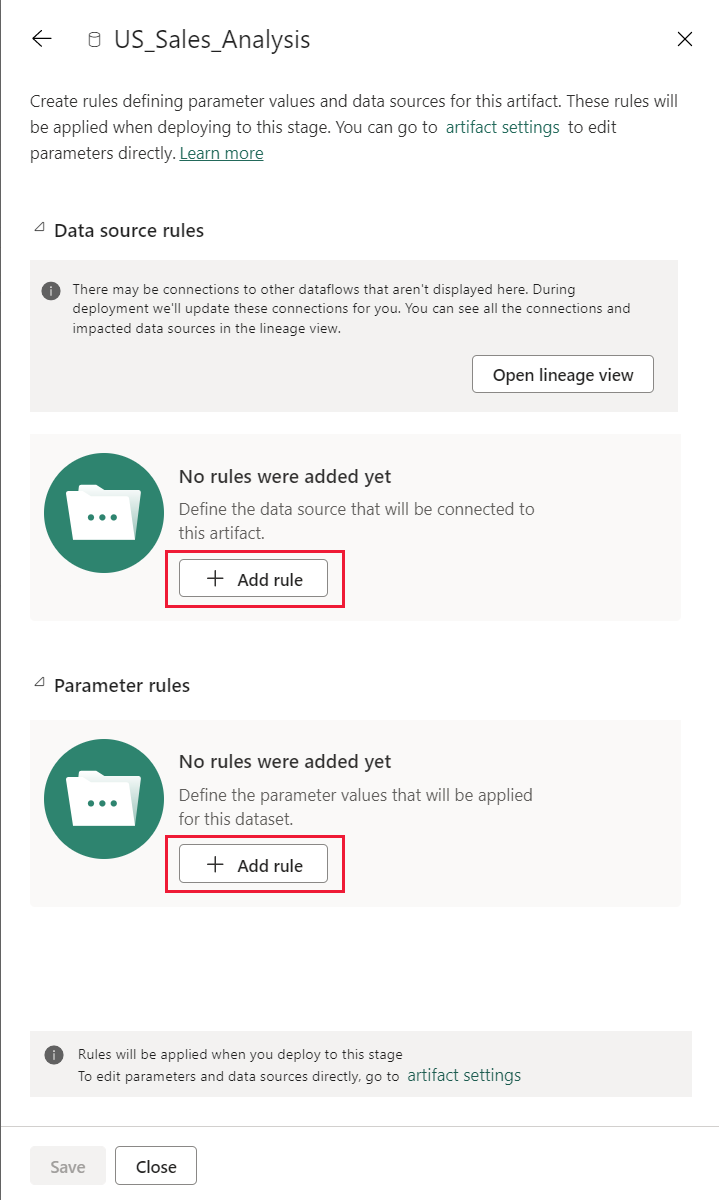
Sélectionnez le type de règle que vous souhaitez créer, développez la liste, puis sélectionnez Ajouter une règle. Il existe deux types de règles que vous pouvez créer :
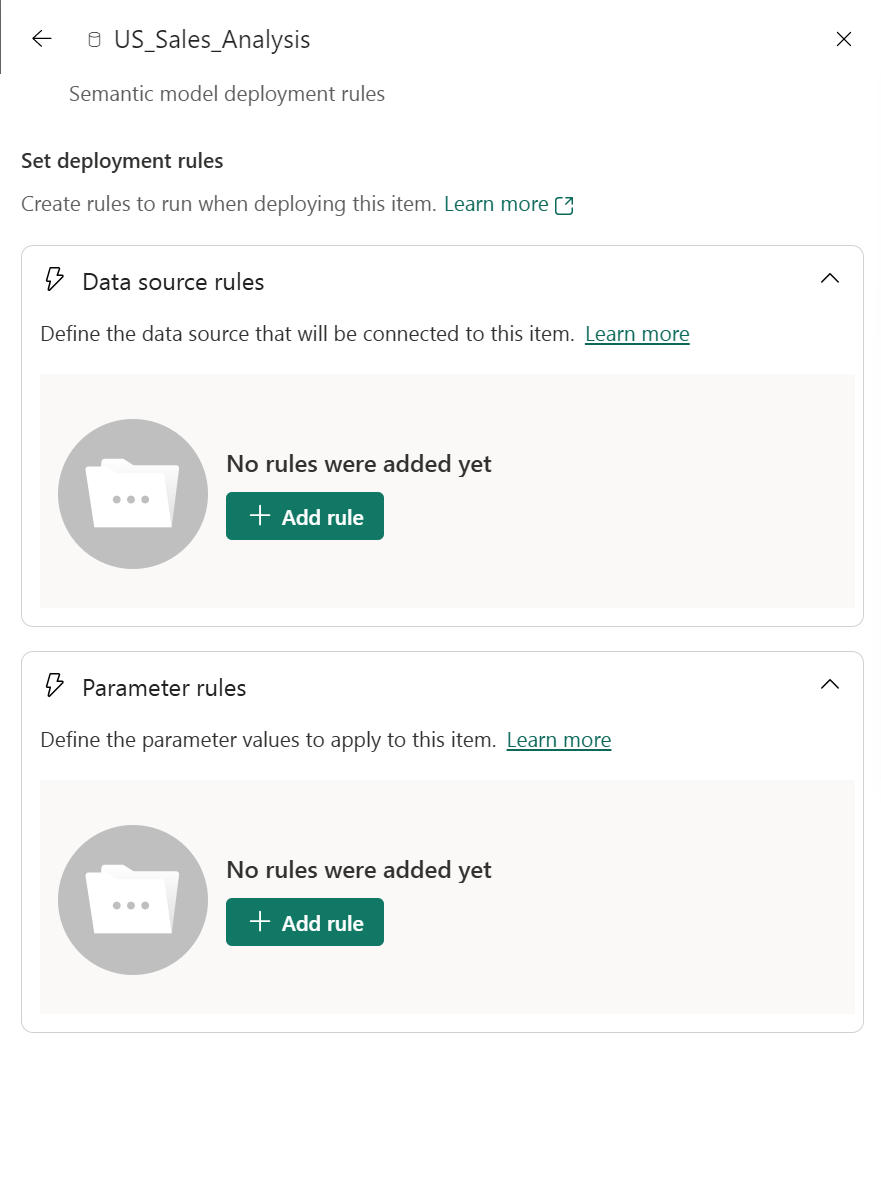
Règles de source de données
Dans la liste des sources de données, sélectionnez un nom de source de données à mettre à jour. Utilisez l’une des méthodes suivantes pour sélectionner une valeur afin de remplacer celle de l’étape source :
Sélectionnez dans une liste.
Sélectionnez Autre et ajoutez manuellement la nouvelle source de données. Vous pouvez uniquement modifier une source de données à partir du même type.
Remarque
- Les règles de source de données seront grisées si vous n'êtes pas le propriétaire de l'élément pour lequel vous créez une règle ou si votre élément ne contient aucune source de données.
- Pour les flux de données, les modèles sémantiques et les rapports paginés, la liste des sources de données provient de l’étape source du pipeline.
- Vous ne pouvez pas utiliser la même source de données dans plus d’une règle.
Règles de paramètres : sélectionnez un paramètre dans la liste des paramètres ; la valeur actuelle est affichée. Modifiez la valeur en lui affectant la valeur que vous souhaitez appliquer après chaque déploiement.
Règles de lakehouse par défaut : cette règle s’applique uniquement aux notebooks. Sélectionnez un lakehouse afin de vous connecter au notebook pour progresser vers un niveau cible et définissez-le comme valeur par défaut. Pour plus d’informations, consultez Notebook dans les pipelines de déploiement.
Sources de données prises en charge pour les règles des flux de données et des modèles sémantiques
Les règles de source de données peuvent être définies pour les sources de données suivantes :
- Azure Analysis Services (AAS)
- Azure Synapse
- SQL Server Analysis Services (SSAS)
- Azure SQL Server
- Serveur SQL
- Flux OData
- Oracle
- SapHana (mode importation uniquement ; pas en mode de requête directe)
- SharePoint
- Teradata
Pour les autres sources de données, nous vous recommandons d’utiliser des paramètres pour configurer votre source de données.
Considérations et limitations
Cette section répertorie les limitations appliquées aux règles de déploiement.
Pour créer une règle de déploiement, vous devez être le propriétaire de l'élément pour lequel vous créez une règle de déploiement.
Il est impossible de créer des règles de déploiement en phase de développement.
Lorsqu’un élément est retiré ou supprimé, ses règles sont également supprimées. Ces règles ne peuvent pas être restaurées.
Quand vous désattribuez et réattribuez un espace de travail pour rétablir les connexions, les règles de cet espace de travail sont perdues. Pour utiliser ces règles à nouveau, vous devez les reconfigurer.
Si la source de données ou le paramètre défini dans une règle est modifié ou supprimé de l'élément vers lequel il pointe dans l'étape source, la règle n'est plus valide et le déploiement échoue.
Après avoir déployé un rapport paginé avec une règle de source de données, vous ne pouvez pas ouvrir le rapport à l’aide du Générateur de rapports Power BI.
Les règles de déploiement ne prennent effet que la prochaine fois que vous effectuez un déploiement à cette étape. Toutefois, si vous créez des règles et comparez ensuite les étapes avant le déploiement, la comparaison est effectuée sur la base des règles créées, même si elles n'ont pas encore pris effet.
Les scénarios suivants ne sont pas pris en charge :
- Les règles de source de données pour les flux de données qui ont d’autres flux de données comme sources.
- Les règles de source de données pour les dossiers CDM (Common Data Model) dans un flux de données.
- Les règles de source de données pour les modèles sémantiques qui utilisent des flux de données comme source.
- La création de règles de source de données sur un modèle sémantique qui utilise une requête native et DirectQuery ensemble.
- Les règles de paramètres ne sont pas prises en charge pour les rapports paginés.
- Ajout de règles de source de données pour les modèles sémantiques et les flux de données sur les sources de données qui sont paramétrées.