Actualisation incrémentielle et données en temps réel pour les modèles sémantiques
L’actualisation incrémentielle et les données en temps réel pour les modèles sémantiques dans Power BI offrent des moyens efficaces de gérer les données dynamiques et d’améliorer les performances d’actualisation des modèles. En automatisant la création et la gestion des partitions, l’actualisation incrémentielle réduit la quantité de données qui doivent être actualisées et permet l’inclusion de données en temps réel. Cet article explique comment configurer et utiliser les fonctionnalités d’actualisation incrémentielle dans Power BI pour capturer des données qui se déplacent rapidement et améliorer les performances.
L’actualisation incrémentielle étend les opérations d’actualisation planifiées en fournissant une création et une gestion de partition automatisées pour les tables de modèle sémantique qui chargent fréquemment des données nouvelles et mises à jour. Pour la plupart des modèles sémantiques, une ou plusieurs tables contiennent des données de transaction qui changent souvent et peuvent croître de manière exponentielle, comme une table de faits dans un schéma de base de données relationnelle ou en étoile. Une stratégie d’actualisation incrémentielle pour partitionner la table, actualisant uniquement les partitions importées les plus récemment et en utilisant éventuellement une autre partition DirectQuery pour les données en temps réel, peut réduire de manière significative la quantité de données qui doivent être actualisées. Dans le même temps, cette stratégie garantit que les dernières modifications apportées à la source de données sont incluses dans les résultats de la requête.
Avec l’actualisation incrémentielle et les données en temps réel :
- Moins de cycles d’actualisation pour les données qui changent rapidement sont nécessaires. Le mode DirectQuery récupère les dernières mises à jour de données au fur et à mesure que les requêtes sont traitées sans exiger une cadence d’actualisation élevée.
- Les actualisations sont plus rapides. Seules les données les plus récentes qui ont changé ont besoin d’être actualisées.
- Les actualisations sont plus fiables. Des connexions de longue durée à des sources de données volatiles ne sont pas nécessaires. Les requêtes aux données sources s’exécutent plus rapidement, ce qui réduit le risque potentiel d’interférence entre les problèmes réseau.
- La consommation des ressources est réduite. Comme il y a moins de données à actualiser, la consommation globale de mémoire et d’autres ressources diminue dans les systèmes Power BI et de source de données.
- Les modèles sémantiques volumineux sont activés. Les modèles sémantiques comportant potentiellement des milliards de lignes peuvent croître sans qu’il soit nécessaire d’actualiser entièrement l’ensemble du modèle avec chaque opération d’actualisation.
- La configuration est facile. Les stratégies d’actualisation incrémentielle sont définies dans Power BI Desktop avec seulement quelques tâches. Lorsque Power BI Desktop publie le rapport, le service applique automatiquement ces stratégies à chaque actualisation.
Quand vous publiez un modèle Power BI Desktop sur le service, chaque table du nouveau modèle a une partition unique. Cette partition unique contient toutes les lignes de cette table. Si la table est volumineuse, par exemple avec des dizaines de millions de lignes ou plus, l’actualisation de cette table peut prendre beaucoup de temps et consommer une quantité excessive de ressources.
Avec l’actualisation incrémentielle, le service partitionne et sépare dynamiquement les données qui doivent être actualisées fréquemment à partir des données qui peuvent être actualisées moins fréquemment. Les données de la table sont filtrées à l’aide des paramètres de date/heure de Power Query avec les noms réservés qui respectent la casse RangeStart et RangeEnd. Lors de la configuration de l’actualisation incrémentielle dans Power BI Desktop, ces paramètres sont utilisés pour filtrer uniquement une petite période de données qui sont chargées dans le modèle. Lorsque Power BI Desktop publie le rapport sur le service Power BI, lors de la première opération d’actualisation, le service crée des partitions d’actualisation incrémentielle et d’historique, et éventuellement une partition DirectQuery en temps réel basée sur les paramètres de stratégie d’actualisation incrémentielle. Le service remplace ensuite les valeurs de paramètres pour filtrer et interroger les données pour chaque partition en fonction des valeurs de date/d’heure pour chaque ligne.
Avec chaque actualisation suivante, les filtres de requête retournent uniquement les lignes de la période d’actualisation définies dynamiquement par les paramètres. Les lignes avec une date/heure comprise dans la période d’actualisation sont actualisées. Les lignes dont la date/l’heure n’est plus comprise dans la période d’actualisation deviennent partie intégrante de la période historique, qui n’est pas actualisée. Si une partition DirectQuery en temps réel est incluse dans la stratégie d’actualisation incrémentielle, son filtre est également mis à jour pour qu’elle récupère toutes les modifications qui surviennent après la période d’actualisation. Les périodes d’actualisation et historiques sont restaurées par progression. À mesure que de nouvelles partitions d’actualisation incrémentielle sont créées, les partitions d’actualisation ne sont plus dans la période d’actualisation et deviennent des partitions historiques. Au fil du temps, les partitions historiques deviennent moins granulaires, car elles sont fusionnées ensemble. Quand une partition historique n’est plus dans la période historique définie par la stratégie, elle est entièrement supprimée du modèle. Ce comportement est appelé modèle de fenêtre dynamique.
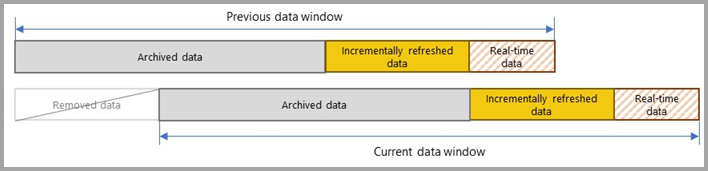
La beauté de l’actualisation incrémentielle est que le service gère tout cela pour vous en fonction des stratégies d’actualisation incrémentielle que vous définissez. En fait, le processus et les partitions créés à partir de ce dernier ne sont même pas visibles dans le service. Dans la plupart des cas, une stratégie d’actualisation incrémentielle bien définie suffit pour améliorer considérablement les performances d’actualisation des modèles. Toutefois, la partition DirectQuery en temps réel est uniquement prise en charge pour les modèles dans les capacités Premium. Power BI Premium permet également des scénarios de partition et d’actualisation plus avancés via le point de terminaison XML for Analysis (XMLA).
Configuration requise
Les sections suivantes décrivent les plans et les sources de données pris en charge.
Plans pris en charge
L’actualisation incrémentielle est prise en charge pour les modèles Power BI Premium, Premium par utilisateur, Power BI Pro et Power BI Embedded.
L’obtention des données les plus récentes en temps réel avec DirectQuery est prise en charge uniquement pour les modèles Power BI Premium, Premium par utilisateur et Power BI Embedded.
Sources de données prises en charge
L’actualisation incrémentielle et les données en temps réel fonctionnent mieux pour les sources de données relationnelles structurées, comme SQL Database et Azure Synapse, mais peuvent également fonctionner pour d’autres sources de données. Dans tous les cas, votre source de données doit prendre en charge les éléments suivants :
Filtrage de date : la source de données doit prendre en charge un mécanisme permettant de filtrer les données par date. Pour une source relationnelle, il s’agit généralement d’une colonne de type de données date/heure ou Integer sur la table cible. Les paramètres RangeStart et RangeEnd, qui doivent être de type de données date/heure, filtrent les données de la table en fonction de la colonne de date. Pour les colonnes de date de clés de substitution de type entier sous la forme de yyyymmdd, vous pouvez créer une fonction qui convertit la valeur de date/heure dans les paramètres RangeStart et RangeEnd pour qu’elle corresponde aux clés de substitution de type entier de la colonne de date. Pour plus d’informations, consultez Configurer l’actualisation incrémentielle et les données en temps réel – Convertir DateHeure en type Integer.
Pour les autres sources de données, les paramètres RangeStart et RangeEnd doivent être passés à la source de données d’une manière qui active le filtrage. Pour les sources de données basées sur des fichiers où les fichiers et dossiers sont organisés par date, les paramètres RangeStart et RangeEnd peuvent être utilisés pour filtrer les fichiers et dossiers afin de sélectionner les fichiers à charger. Pour les sources de données web, les paramètres RangeStart et RangeEnd peuvent être intégrés dans la requête HTTP. Par exemple, la requête suivante peut être utilisée pour l’actualisation incrémentielle des traces à partir d’une instance AppInsights :
let
strRangeStart = DateTime.ToText(RangeStart,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
strRangeEnd = DateTime.ToText(RangeEnd,[Format="yyyy-MM-dd'T'HH:mm:ss'Z'", Culture="en-US"]),
Source = Json.Document(Web.Contents("https://api.applicationinsights.io/v1/apps/<app-guid>/query",
[Query=[#"query"="traces
| where timestamp >= datetime(" & strRangeStart &")
| where timestamp < datetime("& strRangeEnd &")
",#"x-ms-app"="AAPBI",#"prefer"="ai.response-thinning=true"],Timeout=#duration(0,0,4,0)])),
TypeMap = #table(
{ "AnalyticsTypes", "Type" },
{
{ "string", Text.Type },
{ "int", Int32.Type },
{ "long", Int64.Type },
{ "real", Double.Type },
{ "timespan", Duration.Type },
{ "datetime", DateTimeZone.Type },
{ "bool", Logical.Type },
{ "guid", Text.Type },
{ "dynamic", Text.Type }
}),
DataTable = Source[tables]{0},
Columns = Table.FromRecords(DataTable[columns]),
ColumnsWithType = Table.Join(Columns, {"type"}, TypeMap , {"AnalyticsTypes"}),
Rows = Table.FromRows(DataTable[rows], Columns[name]),
Table = Table.TransformColumnTypes(Rows, Table.ToList(ColumnsWithType, (c) => { c{0}, c{3}}))
in
Table
Lorsque l’actualisation incrémentielle est configurée, une expression Power Query qui comprend un filtre de date/heure basé sur les paramètres RangeStart et RangeEnd est exécutée sur la source de données. Si le filtre est spécifié dans une étape de requête après la requête source initiale, il est important que le pliage de requête combine l’étape de requête initiale avec les étapes qui référencent les paramètres RangeStart et RangeEnd. Par exemple, dans l’expression de requête suivante, le Table.SelectRows se plie, car il suit immédiatement l’étape Sql.Database et SQL Server prend en charge le pliage :
let
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(Data, each [OrderDateKey] >= Int32.From(DateTime.ToText(RangeStart,[Format="yyyyMMdd"]))),
#"Filtered Rows1" = Table.SelectRows(#"Filtered Rows", each [OrderDateKey] < Int32.From(DateTime.ToText(RangeEnd,[Format="yyyyMMdd"])))
in
#"Filtered Rows1"
Il n’est pas nécessaire que la requête finale prenne en charge le pliage. Par exemple, dans l’expression suivante, nous utilisons une NativeQuery non pliable, mais nous intégrons les paramètres RangeStart et RangeEnd directement dans SQL :
let
Query = "select * from dbo.FactInternetSales where OrderDateKey >= '"& Text.From(Int32.From( DateTime.ToText(RangeStart,"yyyyMMdd") )) &"' and OrderDateKey < '"& Text.From(Int32.From( DateTime.ToText(RangeEnd,"yyyyMMdd") )) &"' ",
Source = Sql.Database("dwdev02","AdventureWorksDW2017"),
Data = Value.NativeQuery(Source, Query, null, [EnableFolding=false])
in
Data
Cependant, si la stratégie d’actualisation incrémentielle comprend l’obtention de données en temps réel avec DirectQuery, les transformations non-repliées ne peuvent pas être utilisées. S’il s’agit d’une stratégie de mode Importation pure sans données en temps réel, le moteur d’application web hybride peut compenser et appliquer le filtre localement, ce qui nécessite la récupération de toutes les lignes de la table à partir de la source de données. Cela peut entraîner un ralentissement de l’actualisation incrémentielle, et le processus peut manquer de ressources dans le service Power BI ou dans une passerelle de données locale, ce qui a pour effet de nuire à l’objectif de l’actualisation incrémentielle.
Comme la prise en charge du repli de requête est différente selon les types de sources de données, une vérification doit être effectuée pour s’assurer que la logique de filtre est incluse dans les requêtes exécutées sur la source de données. Dans la plupart des cas, Power BI Desktop tente d’effectuer cette vérification pour vous lors de la définition de la stratégie d’actualisation incrémentielle. Pour les sources de données basées sur SQL, telles que SQL Database, Azure Synapse, Oracle et Teradata, cette vérification est fiable. Cependant, les autres sources de données peuvent ne pas être en mesure d’effectuer la vérification sans suivi des requêtes. Si Power BI Desktop ne parvient pas à confirmer les requêtes, un avertissement s’affiche dans la boîte de dialogue Configuration de la stratégie d’actualisation incrémentielle.
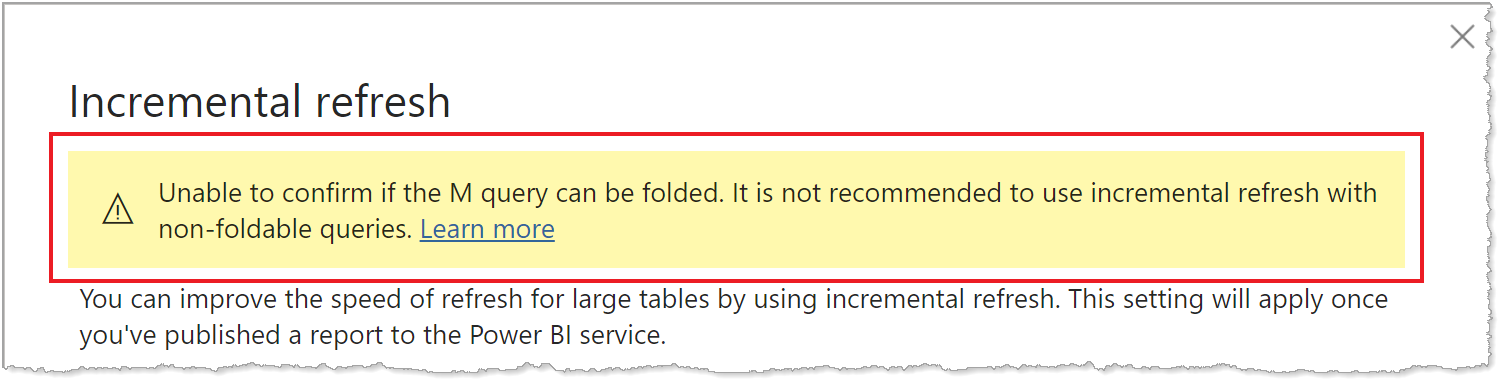
Si vous voyez cet avertissement et que vous souhaitez vérifier que le repli de requête nécessaire se produit, utilisez la fonctionnalité Power Query Diagnostics ou les requêtes de suivi à l’aide d’un outil pris en charge par la source de données, comme SQL Profiler. Si le repli de requête ne se produit pas, vérifiez que la logique de filtre est incluse dans la requête transmise à la source de données. Si ce n’est pas le cas, il est probable que la requête inclue une transformation qui empêche le repli.
Avant de configurer votre solution d’actualisation incrémentielle, veillez à lire et à comprendre soigneusement les articles Guide sur le pliage de requête dans Power BI Desktop et Repli de requête Power Query. Ces articles peuvent vous aider à déterminer si votre source de données et vos requêtes prennent en charge le repli des requêtes.
Source de données unique
Lorsque vous configurez l’actualisation incrémentielle et des données en temps réel avec Power BI Desktop ou configurez une solution avancée à l’aide du langage TMSL (Tabular Model Scripting Language) ou TOM (Tabular Object Model) par le biais du point de terminaison XMLA, toutes les partitions (importation et DirectQuery) doivent interroger les données à partir d’une source unique.
Autre types de sources de données
En utilisant des fonctions de requête et une logique de requête plus personnalisées, l’actualisation incrémentielle peut être utilisée avec d’autres types de sources de données si des filtres basés sur RangeStart et RangeEnd peuvent être passés dans une requête unique, comme avec des sources de données telles que des fichiers de classeur Excel stockés dans un dossier, des fichiers dans SharePoint et des flux RSS. Gardez à l’esprit qu’il s’agit de scénarios avancés qui nécessitent davantage de personnalisation et de test à ce qui est décrit ici. Veillez à consulter la section Communauté plus loin dans cet article pour obtenir des suggestions sur la façon dont vous pouvez trouver plus d’informations sur l’utilisation de l’actualisation incrémentielle pour des scénarios uniques.
Limites de temps
Indépendamment de l’actualisation incrémentielle, les modèles Power BI Pro ont une limite de temps d’actualisation de deux heures et ne prennent pas en charge l’obtention de données en temps réel avec DirectQuery. Pour les modèles d’une capacité Premium, la limite de temps est de cinq heures. Les opérations d’actualisation utilisent beaucoup de ressources de traitement et de mémoire. Une opération d’actualisation complète peut utiliser jusqu’à deux fois la quantité de mémoire requise par le modèle uniquement parce que le service conserve un instantané du modèle en mémoire jusqu’à la fin de l’opération d’actualisation. Les opérations d’actualisation peuvent également utiliser beaucoup de ressources de traitement, et par conséquent consommer une quantité importante de ressources processeur disponibles. Les opérations d’actualisation doivent également reposer sur des connexions volatiles aux sources de données et la capacité de ces systèmes de source de données à retourner rapidement le résultat de la requête. La limite de temps est un dispositif de protection permettant de limiter la surconsommation des ressources disponibles.
Notes
Avec les capacités Premium, les opérations d’actualisation effectuées via le point de terminaison XMLA n’ont pas de limite de temps. Pour en savoir plus, consultez Actualisation incrémentielle avancée avec le point de terminaison XMLA.
Étant donné que l’actualisation incrémentielle optimise les opérations d’actualisation au niveau de la partition dans le modèle, la consommation des ressources peut être considérablement réduite. En même temps, même avec l’actualisation incrémentielle, sauf si elles passent par le point de terminaison XMLA, les opérations d’actualisation sont liées par ces deux mêmes limites de deux et cinq heures. Une stratégie d’actualisation incrémentielle efficace réduit non seulement la quantité de données traitées avec une opération d’actualisation, mais aussi la quantité de données historiques inutiles stockées dans votre modèle.
Les requêtes peuvent également être limitées par une limite de temps par défaut pour la source de données. La plupart des sources de données relationnelles permettent de remplacer les limites de temps dans l’expression Power Query M. Par exemple, l’expression suivante utilise la fonction d’accès aux données de SQL Server pour définir CommandTimeout sur deux heures. Chaque période définie par les plages de la stratégie soumet une requête qui respecte le paramètre de délai d’expiration de la commande :
let
Source = Sql.Database("myserver.database.windows.net", "AdventureWorks", [CommandTimeout=#duration(0, 2, 0, 0)]),
dbo_Fact = Source{[Schema="dbo",Item="FactInternetSales"]}[Data],
#"Filtered Rows" = Table.SelectRows(dbo_Fact, each [OrderDate] >= RangeStart and [OrderDate] < RangeEnd)
in
#"Filtered Rows"
Pour les modèles très volumineux dans les capacités Premium qui contiennent probablement des milliards de lignes, l’opération d’actualisation initiale peut être amorcée. L’amorçage permet au service de créer des objets de table et de partition pour le modèle, mais pas de charger et de traiter les données dans l’une des partitions. En utilisant SQL Server Management Studio, vous pouvez définir des partitions à traiter individuellement, séquentiellement ou en parallèle, pour réduire à la fois la quantité de données retournées dans une requête unique et également contourner la limite de cinq heures. Pour plus d’informations, consultez Actualisation incrémentielle avancée - Empêcher les délais d’attente lors de l’actualisation complète initiale.
Date et heure actuelles
Par défaut, la date et l’heure actuelles sont déterminées en fonction du temps universel coordonné (UTC) au moment de l’actualisation. Pour les actualisations à la demande et planifiées, vous pouvez configurer un autre fuseau horaire sous « Actualisation » qui sera pris en compte pour déterminer la date et l’heure actuelles. Par exemple, une actualisation à 20:00, heure du Pacifique (États-Unis et Canada) avec un fuseau horaire configuré, détermine la date et l’heure actuelles en fonction de l’heure du Pacifique et non de l’heure UTC, qui correspondrait au jour suivant.
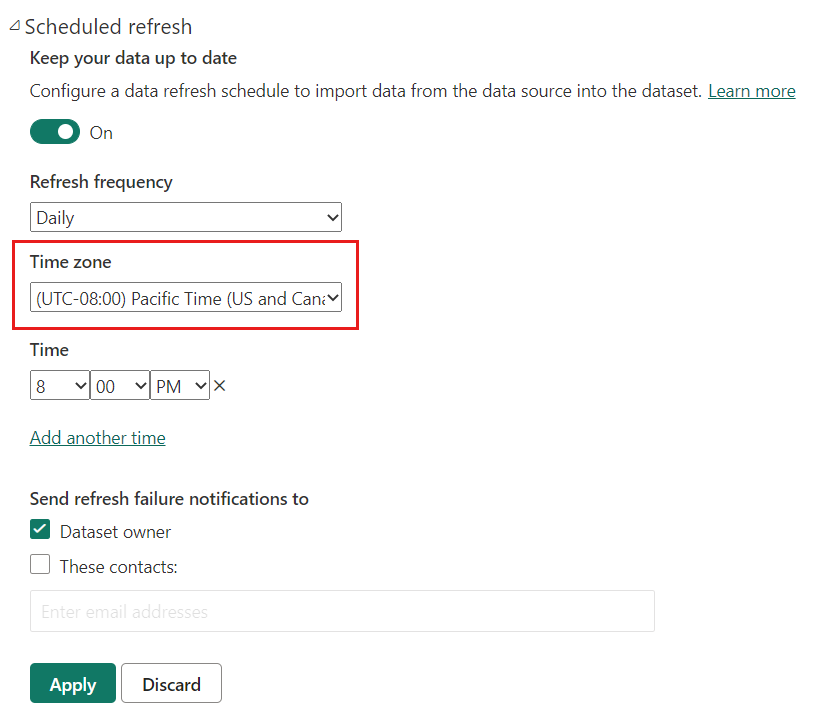
Les opérations d’actualisation non appelées par le biais du service Power BI, telles que la commande d’actualisation XMLA TMSL ou l’API d’actualisation améliorée, ne tiennent pas compte du fuseau horaire d’actualisation planifiée configuré, et utilisent l’heure UTC par défaut.
Configurer l’actualisation incrémentielle et les données en temps réel
Cette section décrit les concepts importants de la configuration de l’actualisation incrémentielle et des données en temps réel. Lorsque vous êtes prêt à obtenir des instructions pas à pas détaillées, consultez Configurer l’actualisation incrémentielle et les données en temps réel.
La configuration de l’actualisation incrémentielle s’effectue dans Power BI Desktop. Pour la plupart des modèles, seules quelques tâches sont requises. Toutefois, gardez à l'esprit les points suivants :
- Après la publication sur le service Power BI, vous ne pouvez pas publier à nouveau le même modèle à partir de Power BI Desktop. La republication entraîne la suppression des partitions et des données existantes déjà présentes dans le modèle. Si vous publiez sur une capacité Premium, les modifications de schéma de métadonnées ultérieures peuvent être apportées à l’aide d’outils tels qu’ALM Toolkit open source ou à l’aide du langage TMSL. Pour plus d’informations, consultez Actualisation incrémentielle avancée - Déploiement de métadonnées uniquement.
- Après la publication sur le service Power BI, vous ne pouvez plus télécharger le modèle au format de fichier .pbix pour Power BI Desktop. Comme les modèles du service peuvent croître de manière importante, il est difficile de les télécharger et de les ouvrir sur un ordinateur de bureau classique.
- Lors de l’obtention de données en temps réel avec DirectQuery, vous ne pouvez pas publier le modèle dans un espace de travail non-Premium. L’actualisation incrémentielle avec des données en temps réel est uniquement prise en charge avec Power BI Premium.
Créer des paramètres
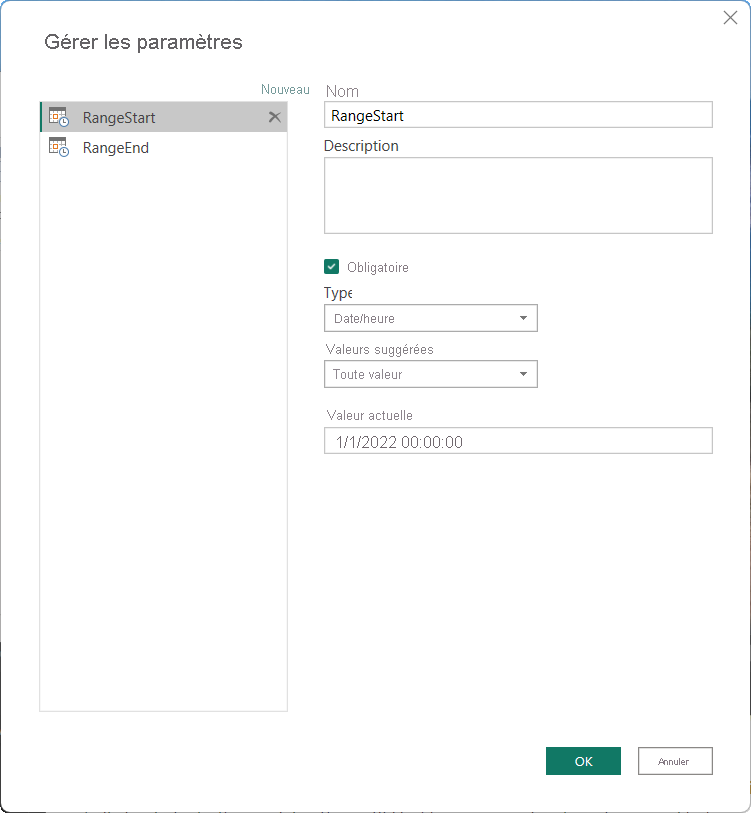
Pour configurer l’actualisation incrémentielle dans Power BI Desktop, vous créez d’abord deux paramètres de date/heure Power Query avec les noms réservés, sensibles à la casse, RangeStart et RangeEnd. Ces paramètres, définis dans la boîte de dialogue Gérer les paramètres d’Éditeur Power Query, servent initialement à filtrer les données chargées dans la table de modèle Power BI Desktop pour inclure uniquement les lignes avec une date/heure comprises dans cette période. RangeStart représente la date/heure la plus ancienne ou la première, tandis que RangeEnd représente la date/heure la plus récente ou la dernière. Une fois le modèle publié sur le service, les paramètres RangeStart et RangeEnd sont automatiquement remplacés par le service pour interroger les données définies par la période d’actualisation spécifiée dans les paramètres de stratégie d’actualisation incrémentielle.
Par exemple, la table de source de données FactInternetSales calcule la moyenne de 10 000 nouvelles lignes par jour. Pour limiter le nombre de lignes initialement chargées dans le modèle dans Power BI Desktop, spécifiez une période de deux jours entre RangeStart et RangeEnd.
Filtrer les données
Avec les paramètres RangeStart et RangeEnd définis, vous appliquez ensuite des filtres de date personnalisée à la colonne de date de votre table. Les filtres que vous appliquez sélectionnent un sous-ensemble de données qui sont chargées dans le modèle en sélectionnant Appliquer.
Avec notre exemple FactInternetSales, après avoir créé des filtres basés sur les paramètres et appliqué des étapes, deux jours de données, soit environ 20 000 lignes, sont chargées dans le modèle.
Définir une stratégie
Une fois que les filtres ont été appliqués et qu’un sous-ensemble de données a été chargé dans le modèle, vous définissez une stratégie d’actualisation incrémentielle pour la table. Une fois le modèle publié sur le service, la stratégie est utilisée par le service pour créer et gérer des partitions de table et effectuer des opérations d’actualisation. Pour définir la stratégie, vous allez utiliser la boîte de dialogue Actualisation incrémentielle et données en temps réel pour spécifier les paramètres requis et ceux facultatifs.
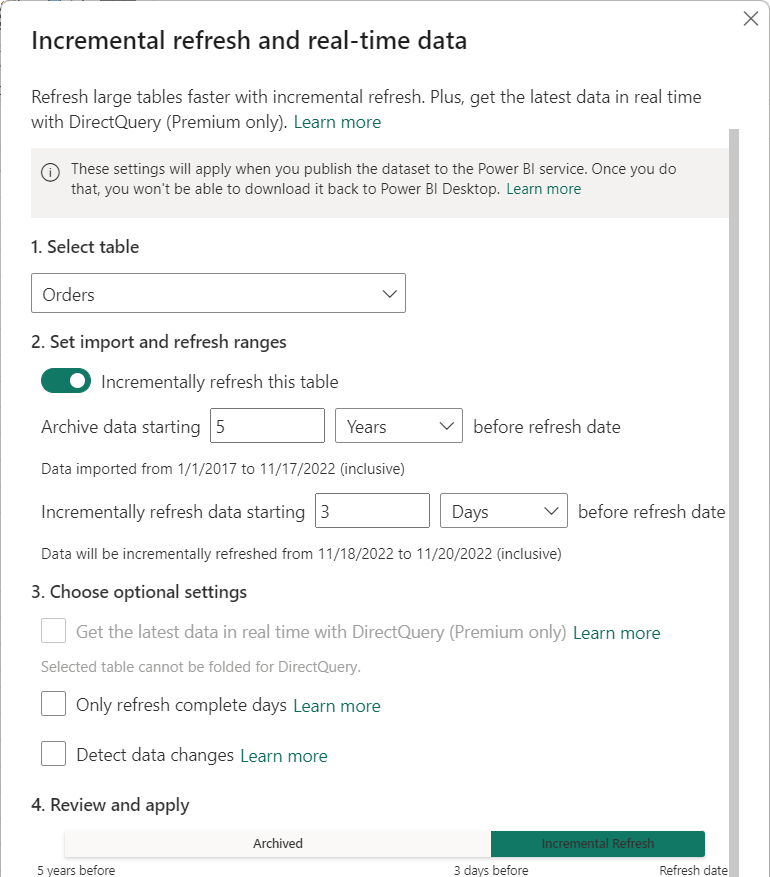
Table de charge de travail
Par défaut, la zone de liste Sélectionner la table est définie sur la table sélectionnée dans la vue Données. Activez l’actualisation incrémentielle pour la table avec le curseur. Si l’expression Power Query pour la table n’inclut pas de filtre basé sur les paramètres RangeStart et RangeEnd, le bouton bascule n’est pas disponible.
Paramètres obligatoires
Le paramètre Archiver les données avant la date d’actualisation détermine la période historique selon laquelle les lignes dont la date/heure est comprise dans cette période sont incluses dans le modèle, ainsi que les lignes de la période historique incomplète en cours et les lignes de la période d’actualisation qui s’étend jusqu’à la date et l’heure actuelles.
Par exemple, si vous spécifiez cinq ans, la table stocke les cinq dernières années entières de données historiques dans les partitions d’année. La table inclut également les lignes de l’année en cours dans les partitions trimestre, mois ou jour, jusqu’à et y compris la période d’actualisation.
Pour les modèles des capacités Premium, les partitions historiques obsolètes peuvent être actualisées de manière sélective à une granularité déterminée par ce paramètre. Pour plus d’informations, consultez Actualisation incrémentielle avancée - Partitions.
Le paramètre Archiver les données avant la date d’actualisation détermine la période d’actualisation incrémentielle selon laquelle toutes les lignes dont la date/l’heure est comprise dans cette période sont incluses dans la ou les partitions d’actualisation et actualisées à chaque opération d’actualisation.
Par exemple, si vous spécifiez une période d’actualisation de trois jours, le service remplace les paramètres RangeStart et RangeEnd à chaque opération d’actualisation afin de créer une requête pour les lignes dont la date/l’heure est comprise dans une période de trois jours, en commençant et en finissant en fonction de la date et de l’heure actuelles. Les lignes avec une date/heure au cours des trois derniers jours jusqu’à l’heure de l’opération d’actualisation actuelle sont actualisées. Avec ce type de stratégie, la table de modèle FactInternetSales figurant dans le service, qui enregistre en moyenne 10 000 nouvelles lignes par jour, devrait actualiser environ 30 000 lignes à chaque opération d’actualisation.
Spécifiez une période qui comprend uniquement le nombre minimal de lignes nécessaires pour garantir la précision des rapports. Lorsque vous définissez des stratégies pour plusieurs tables, vous devez utiliser les mêmes paramètres RangeStart et RangeEnd, même si différentes périodes de stockage et d’actualisation sont définies pour chaque table.
Paramètres facultatifs
Le paramètre Récupérer les données les plus récentes en temps réel avec DirectQuery (Premium uniquement) permet d’extraire les dernières modifications de la table sélectionnée au niveau de la source de données au-delà de la période d’actualisation incrémentielle avec DirectQuery. Toutes les lignes dont la date/heure est postérieure à la période d’actualisation incrémentielle sont incluses dans une partition DirectQuery et extraites de la source de données avec chaque requête de modèle.
Par exemple, si ce paramètre est activé, le service remplace quand même les paramètres RangeStart et RangeEnd à chaque opération d’actualisation afin de créer une requête pour les lignes dont la date/l’heure se situe après la période d’actualisation, avec le début dépendant de la date et de l’heure actuelles. Les lignes dont la date/l’heure est postérieure à l’heure de l’opération d’actualisation actuelle sont aussi incluses. Avec ce type de stratégie, la table de modèle FactInternetSales figurant dans le service inclut les dernières mises à jour de données.
Le paramètre Actualiser uniquement les jours complets permet de garantir que toutes les lignes de la journée entière sont incluses dans l’opération d’actualisation. Il est facultatif, à moins que le paramètre Récupérer les données les plus récentes en temps réel avec DirectQuery (Premium uniquement) ne soit activé. Par exemple, supposons que vous avez planifié l’actualisation à 4 h 00 chaque matin. Si de nouvelles lignes de données s’affichent dans la table de source de données pendant les quatre heures comprises entre minuit et 4 h 00, il n’est pas nécessaire d’en tenir compte. L’actualisation de certaines métriques métier, comme le nombre de barils par jour dans l’industrie du pétrole et du gaz, n’a aucun sens si elle concerne des jours partiels. Un autre exemple est l’actualisation des données d’un système financier où les données du mois précédent sont approuvées le 12e jour calendaire du mois. Vous pouvez définir une période d’actualisation d’un mois et planifier l’actualisation le 12e jour du mois. Par exemple, avec cette option sélectionnée, les données du mois de janvier sont actualisées le 12 février.
N’oubliez pas qu’à moins que l’actualisation planifiée ne soit configurée pour un fuseau horaire non UTC, les opérations d’actualisation dans le service s’exécutent en heure UTC, ce qui peut déterminer la date effective et les périodes complètes.
Le paramètre Détecter les modifications de données permet une actualisation encore plus sélective. Vous pouvez sélectionner une colonne Date/Heure pour identifier et actualiser uniquement ces jours où les données ont changé. Ce paramètre suppose que cette colonne existe dans la source de données, généralement à des fins d’audit. Cette colonne ne doit pas être la même que celle utilisée pour partitionner les données avec les paramètres RangeStart et RangeEnd. La valeur maximale de cette colonne est évaluée pour chacune des périodes définies dans la plage incrémentielle. Si elle n’a pas changé depuis la dernière actualisation, il n’est pas nécessaire d’actualiser la période, ce qui pourrait potentiellement réduire davantage les jours d’actualisation incrémentielle de trois à un.
Dans la conception actuelle, la colonne utilisée pour détecter les changements de données doit être persistante et mise en mémoire cache. Les techniques suivantes peuvent être utilisées pour réduire la cardinalité et la consommation de mémoire :
- Conservez uniquement la valeur maximale de la colonne au moment de l’actualisation, éventuellement à l’aide d’une fonction Power Query.
- Diminuez la précision à un niveau acceptable en fonction de vos exigences de fréquence d’actualisation.
- Définissez une requête personnalisée pour la détection des modifications de données à l’aide du point de terminaison XMLA et évitez de conserver entièrement la valeur de la colonne.
Dans certains cas, l’activation de l’option Détecter les changements de données peut être améliorée. Par exemple, vous pouvez vouloir éviter la persistance de la colonne de la dernière mise à jour dans le cache en mémoire, ou activer des scénarios dans lesquels la table configuration/instruction est préparée par des processus ETL (extract-transform-load) pour signaler uniquement ces partitions qui doivent être actualisées. Dans les cas de ce type, pour les capacités Premium, utilisez le langage TMSL et/ou le modèle TOM pour remplacer le comportement Détecter les changements de données. Pour plus d’informations, consultez Actualisation incrémentielle avancée - Requêtes personnalisées pour détecter les changements de données.
Publish
Après avoir configuré la stratégie d’actualisation incrémentielle, vous publiez le modèle sur le service. Une fois la publication terminée, vous pouvez effectuer l’opération d’actualisation initiale sur le modèle.
Remarque
Les modèles sémantiques avec une stratégie d’actualisation incrémentielle pour obtenir les données les plus récentes en temps réel avec DirectQuery peuvent uniquement être publiés dans un espace de travail Premium.
Pour les modèles publiés dans les espaces de travail affectés aux capacités Premium, si vous pensez que le modèle va croître au-delà de 1 Go, vous pouvez améliorer les performances de l’opération d’actualisation et vous assurer que le modèle n’atteint pas les limites de taille maximale en activant le paramètre de format de stockage du modèle sémantique volumineux avant d’effectuer la première opération d’actualisation dans le service. Pour en savoir plus, consultez Grands modèles dans Power BI Premium.
Important
Une fois que Power BI Desktop a publié le modèle dans le service, vous ne pouvez pas télécharger à nouveau ce .pbix.
Actualiser
Après publication sur le service, vous effectuez une opération d’actualisation initiale sur le modèle. Cette actualisation doit être une actualisation individuelle (manuelle) pour vous permettre de surveiller la progression. L’opération d’actualisation initiale peut prendre un certain temps. Les partitions doivent être créées, les données historiques chargées, les objets tels que les relations et les hiérarchies générés ou reconstruits, et les objets calculés recalculés.
Les opérations d’actualisation ultérieures, individuelles ou planifiées, sont beaucoup plus rapides, car seules la ou les partitions d’actualisation incrémentielles sont actualisées. D’autres opérations de traitement doivent toujours avoir lieu, comme la fusion de partitions et le recalcul, mais cela prend généralement bien moins de temps que l’actualisation initiale.
Actualisation automatique des rapports
Dans le cas des rapports qui utilisent un modèle avec une stratégie d’actualisation incrémentielle pour obtenir les données les plus récentes en temps réel avec DirectQuery, il est judicieux d’activer l’actualisation automatique des pages à un intervalle fixe ou en fonction de la détection des modifications pour que les rapports incluent les données les plus récentes sans délai. Pour plus d’informations, consultez Actualisation automatique des pages dans Power BI.
Actualisation incrémentielle avancée
Si votre modèle est sur une capacité Premium avec le point de terminaison XMLA activé, l’actualisation incrémentielle peut être étendue pour des scénarios avancés. Par exemple, vous pouvez utiliser SQL Server Management Studio pour afficher et gérer les partitions, amorcer l’opération d’actualisation initiale ou actualiser les partitions historiques obsolètes. Pour en savoir plus, consultez Actualisation incrémentielle avancée avec le point de terminaison XMLA.
Communauté
Power BI a une communauté dynamique où des MVP, des professionnels BI et des pairs partagent leur expertise dans des groupes de discussion, des vidéos, des blogs et bien plus encore. À propos des actualisations incrémentielles, consultez ces ressources :
- Communauté Power BI
- Rechercher « Actualisation incrémentielle Power BI » sur Bing
- Rechercher « Actualisation incrémentielle des fichiers » sur Bing
- Rechercher « Conserver les données existantes à l’aide de l’actualisation incrémentielle » sur Bing