Déployer un cluster Big Data SQL Server avec un notebook Azure Data Studio
S’applique à : ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Important
Le module complémentaire Clusters Big Data Microsoft SQL Server 2019 sera mis hors service. La prise en charge de la plateforme Clusters Big Data Microsoft SQL Server 2019 se terminera le 28 février 2025. Tous les utilisateurs existants de SQL Server 2019 avec Software Assurance seront entièrement pris en charge sur la plateforme, et le logiciel continuera à être maintenu par les mises à jour cumulatives SQL Server jusqu’à ce moment-là. Pour plus d’informations, consultez le billet de blog d’annonce et les Options Big Data sur la plateforme Microsoft SQL Server.
SQL Server fournit une extension pour Azure Data Studio qui inclut des notebooks de déploiement. Un notebook de déploiement comprend la documentation et le code que vous pouvez utiliser dans Azure Data Studio pour créer un cluster Big Data SQL Server.
Implémentés à l’origine sous forme de projet open source, les notebooks ont été implémentés dans Azure Data Studio. Vous pouvez utiliser un marquage Markdown pour le texte des cellules de texte et un des noyaux disponibles pour écrire du code dans les cellules de code.
Vous pouvez utiliser des notebooks pour déployer Clusters Big Data SQL Server.
Prérequis
Les prérequis suivants sont obligatoires pour lancer également le notebook :
- Dernière version de la build Azure Data Studio Insiders installée
En plus de ce qui précède, le déploiement d’un cluster Big Data nécessite également :
Lancer le notebook
Lancez Azure Data Studio.
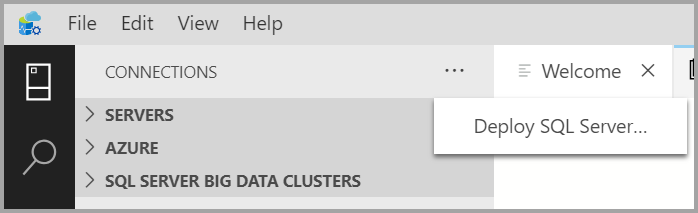
Sous l’onglet Connexions, sélectionnez le bouton de sélection ( ... ), puis sélectionnez Déployer SQL Server.
Dans les options de déploiement, sélectionnez SQL Server Big Data Cluster (Cluster Big Data SQL Server) .
À partir Deployment Target (Cible de déploiement), sous Options, sélectionnez New Azure Kubernetes Cluster (Nouveau cluster Azure Kubernetes) ou Existing Azure Kubernetes Service cluster (Cluster Azure Kubernetes Service existant).
Acceptez la déclaration de confidentialité et les termes du contrat de licence.
Cette boîte de dialogue permet également de vérifier si les outils nécessaires au type de déploiement SQL choisi existent sur l’hôte. Le bouton Sélectionner s’active uniquement en cas de réussite de la vérification des outils.
Sélectionnez le bouton Sélectionner. Cette action lance l’expérience de déploiement.
Définir le modèle de configuration de déploiement
Vous pouvez personnaliser les paramètres du profil de déploiement en suivant les instructions ci-dessous.
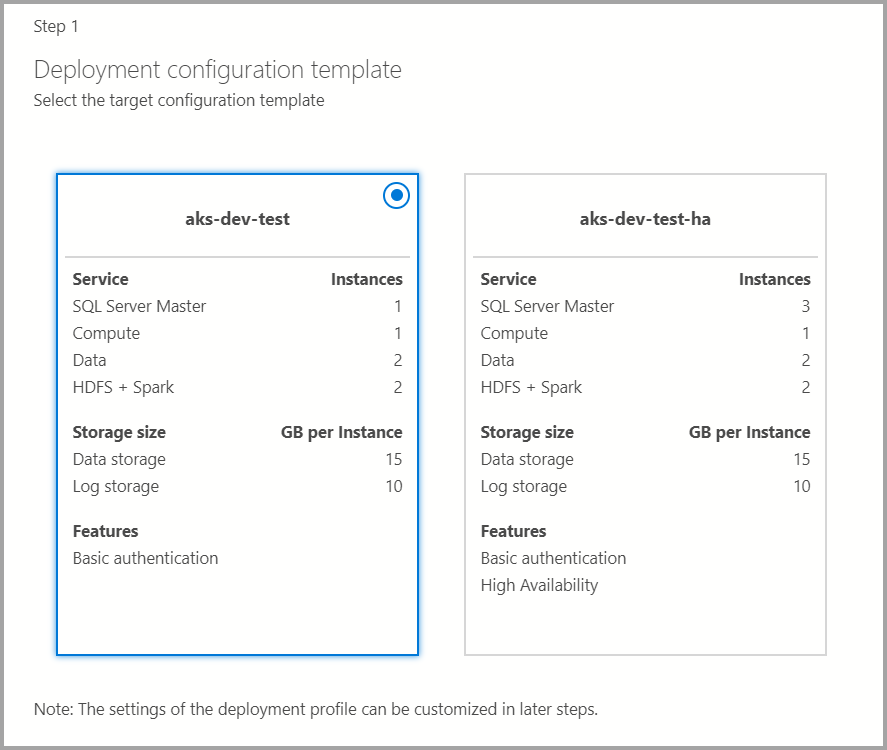
Modèle de configuration cible
Sélectionnez le modèle configuration cible parmi les modèles disponibles. Les profils disponibles sont filtrés en fonction du type de cible de déploiement choisi dans la boîte de dialogue précédente.
Paramètres Azure
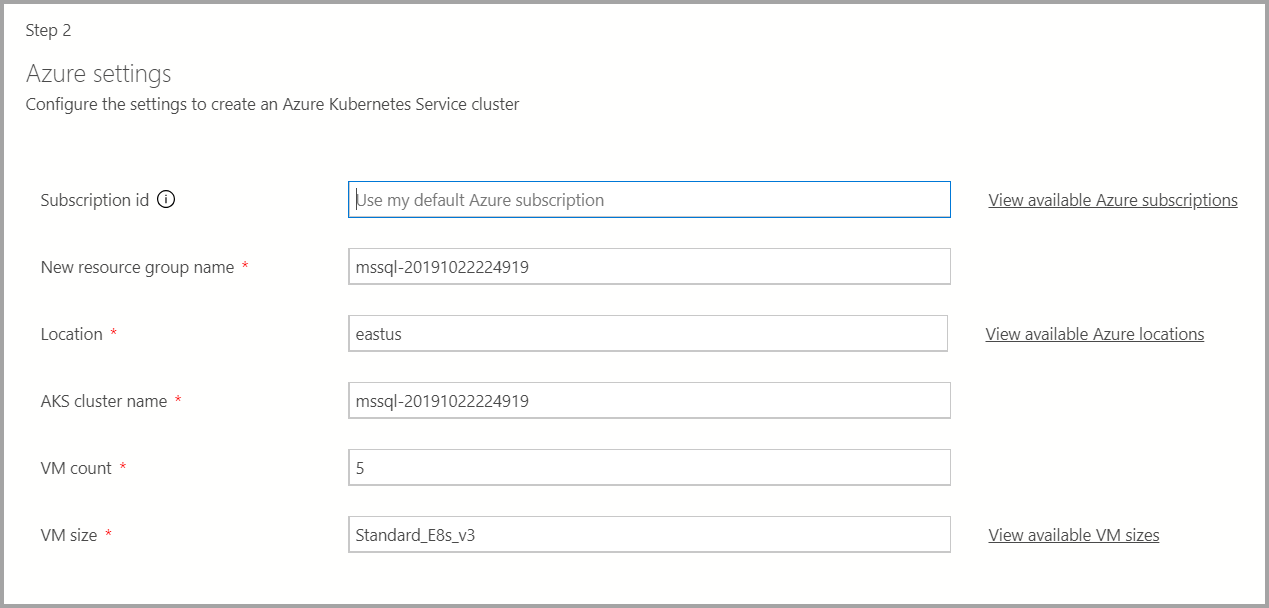
Si la cible de déploiement est une nouvelle instance Azure Kubernetes Service (AKS), des informations supplémentaires telles que l’ID d’abonnement Azure, le groupe de ressources, le nom du cluster AKS, le nombre de machines virtuelles, la taille et d’autres informations sont nécessaires pour créer le cluster AKS.
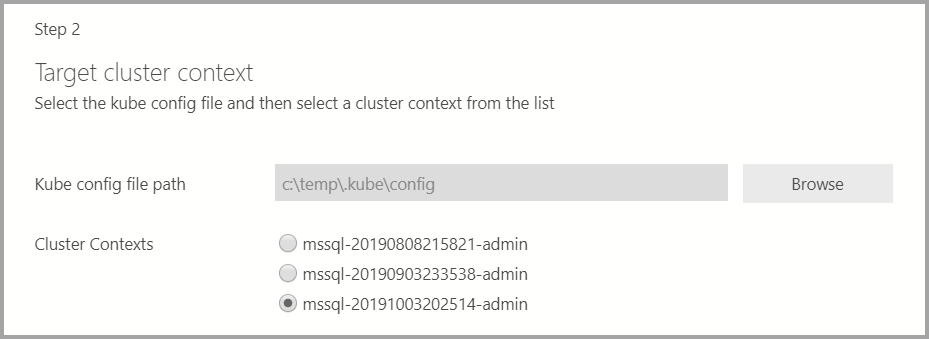
Si la cible de déploiement est un cluster Kubernetes existant, l’Assistant vous invite à entrer le chemin du fichier config kube pour importer les paramètres de cluster Kubernetes. Vérifiez que le contexte de cluster approprié est sélectionné et que vous pouvez déployer le cluster Big Data SQL Server 2019.
Paramètres de cluster, Docker et AD
Entrez le nom du cluster Big Data, un nom d’utilisateur administrateur et un mot de passe. Le même compte est utilisé pour le contrôleur et SQL Server.
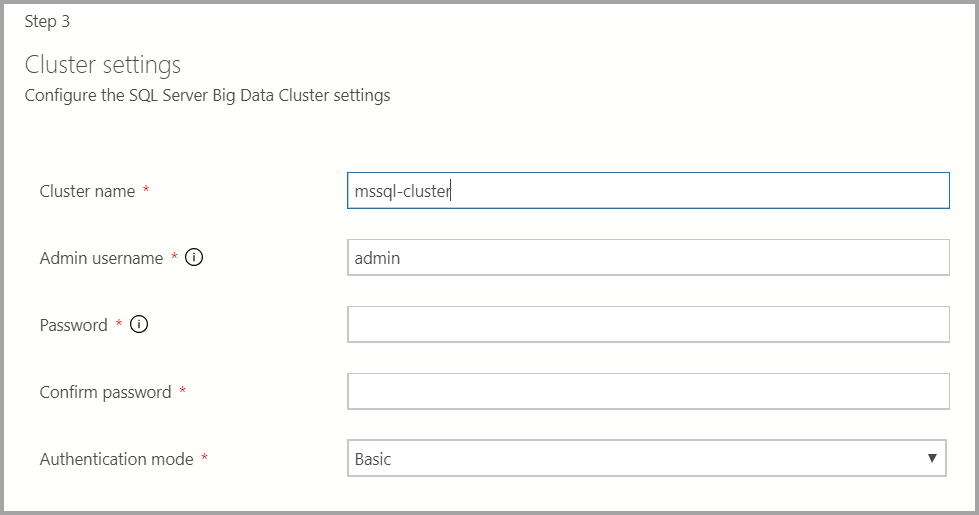
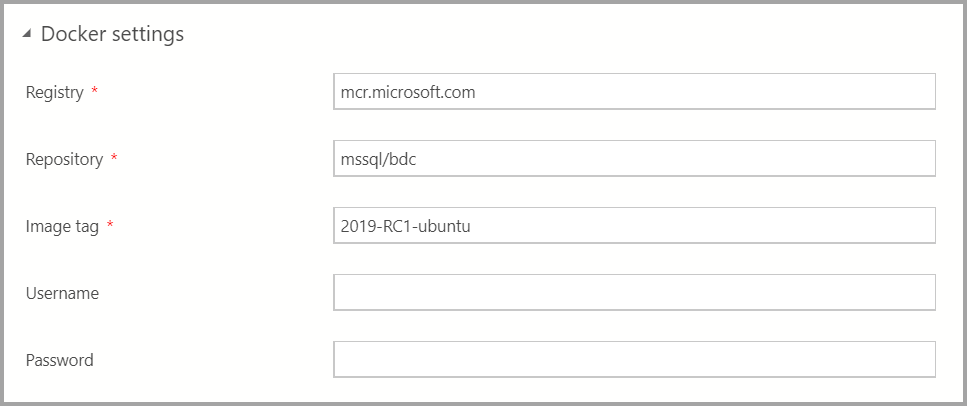
Entrez les paramètres Docker appropriés.
Important
Vérifiez que la valeur du champ de balise de l’image est la plus récente : 2019-CU13-ubuntu-20.04
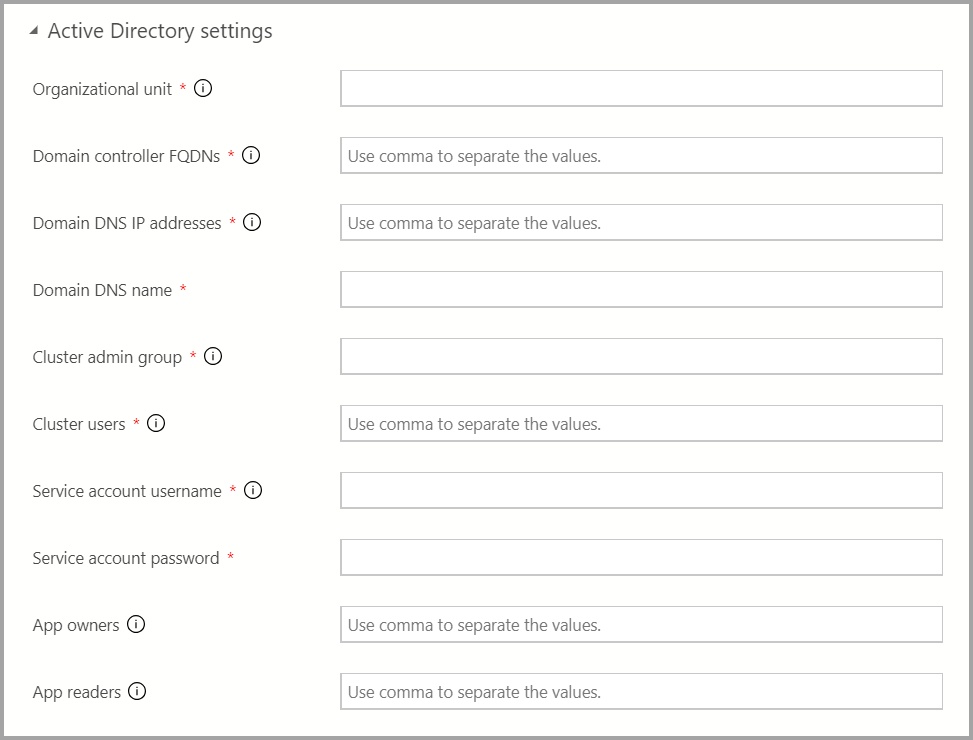
Si l’authentification AD est disponible, entrez les paramètres AD.
Paramètres de service
Cet écran contient des entrées pour divers paramètres, notamment la mise à l’échelle, les points de terminaison, le stockage et les autres paramètres de stockage avancés. Entrez les valeurs appropriées, puis sélectionnez Suivant.
Paramètres de mise à l’échelle
Entrez le nombre d’instances de chacun des composants du cluster Big Data.
Une instance de Spark peut être incluse avec HDFS. Elle est incluse dans le pool de stockage ou est seule dans le pool Spark.
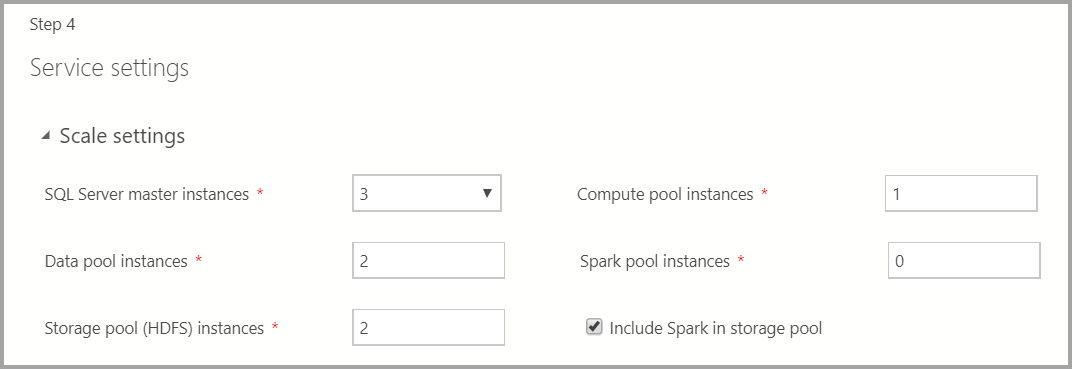
Pour plus d’informations sur chacun de ces composants, vous pouvez consulter les détails relatifs à l’instance maître, au pool de données, au pool de stockage ou au pool de calcul.
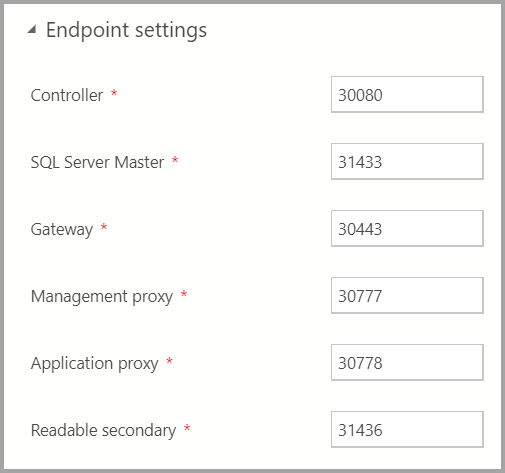
Paramètres de point de terminaison
Les points de terminaison par défaut ont été préremplis. Toutefois, vous pouvez les changer, si nécessaire.
Paramètres de stockage
Les paramètres de stockage incluent la classe de stockage et la taille des revendications pour les données et les journaux. Vous pouvez appliquer les paramètres au pool de stockage, au pool de données et au pool SQL Server Master.

Paramètres de stockage avancés
Vous pouvez ajouter des paramètres de stockage supplémentaires sous Paramètres de stockage avancés
Pool de stockage (HDFS)
Pool de données
SQL Server Master

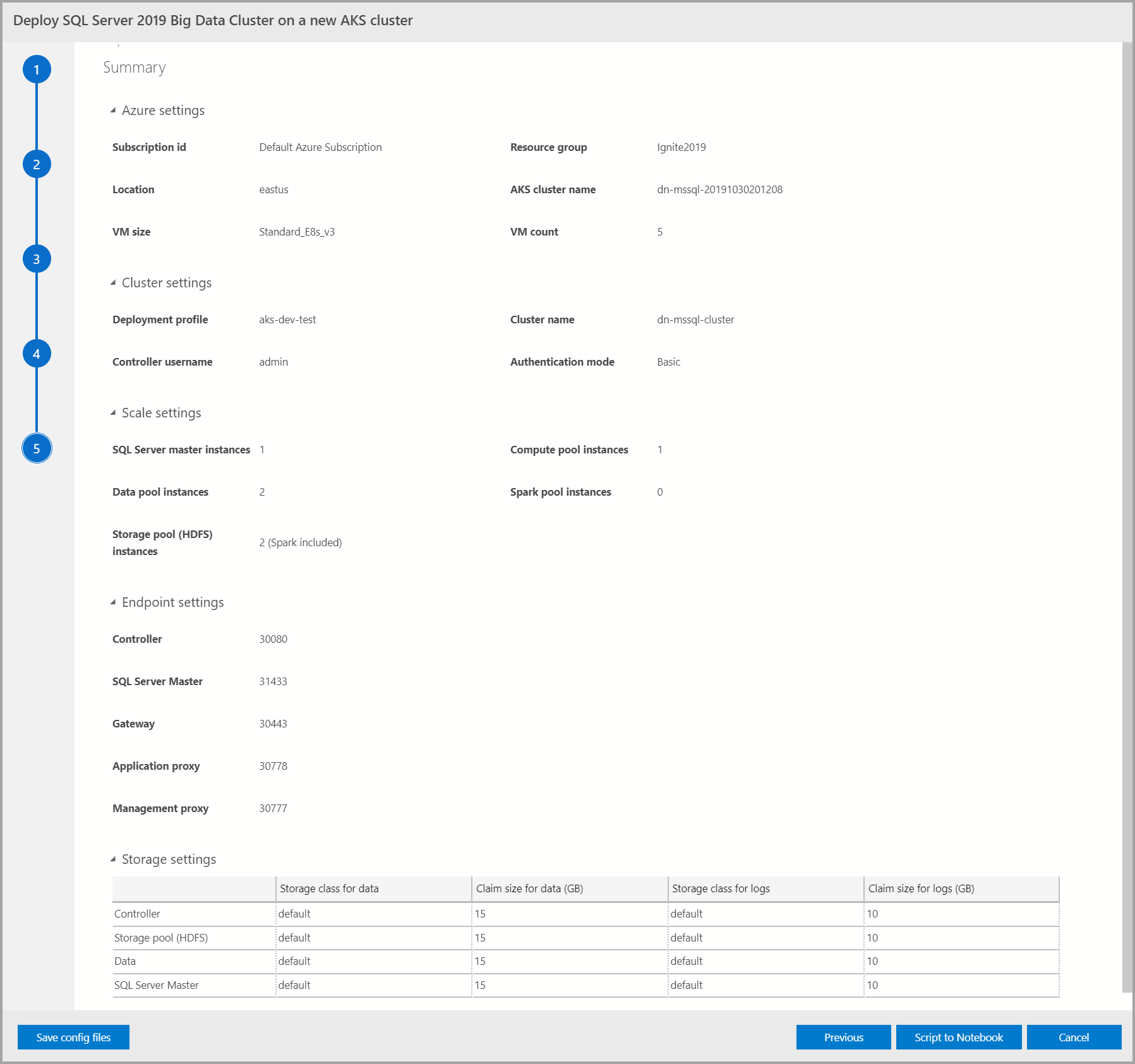
Résumé
Cet écran récapitule toutes les entrées fournies pour déployer le cluster Big Data. Vous pouvez télécharger les fichiers config via le bouton Save config files (Enregistrer les fichiers config) . Sélectionnez Script to Notebook (Script dans un notebook) pour créer un script de l’ensemble de la configuration de déploiement dans un notebook. Une fois le notebook ouvert, sélectionnez Run Cells (Exécuter les cellules) pour commencer à déployer le cluster Big Data sur la cible sélectionnée.
Étapes suivantes
Pour plus d’informations sur le déploiement, consultez Guide de déploiement pour les clusters Big Data SQL Server.