Installer et activer la déduplication des données
Cette rubrique explique comment installer la déduplication des données, évaluer les charges de travail pour la déduplication et activer la déduplication des données sur des volumes spécifiques.
Notes
Si vous envisagez d’exécuter la déduplication des données dans un cluster de basculement, chaque nœud du cluster doit avoir le rôle serveur de déduplication des données installé.
Installer la déduplication des données
Important
KB4025334 contient un cumul de correctifs pour la déduplication des données, y compris des correctifs de fiabilité importants. Nous vous recommandons vivement de l’installer lorsque vous utilisez la déduplication des données avec Windows Server 2016.
Installer la déduplication des données à l’aide du Gestionnaire de serveur
- Dans l’Assistant Ajout de rôles et de fonctionnalités, sélectionnez Rôles de serveurs, puis Déduplication des données.
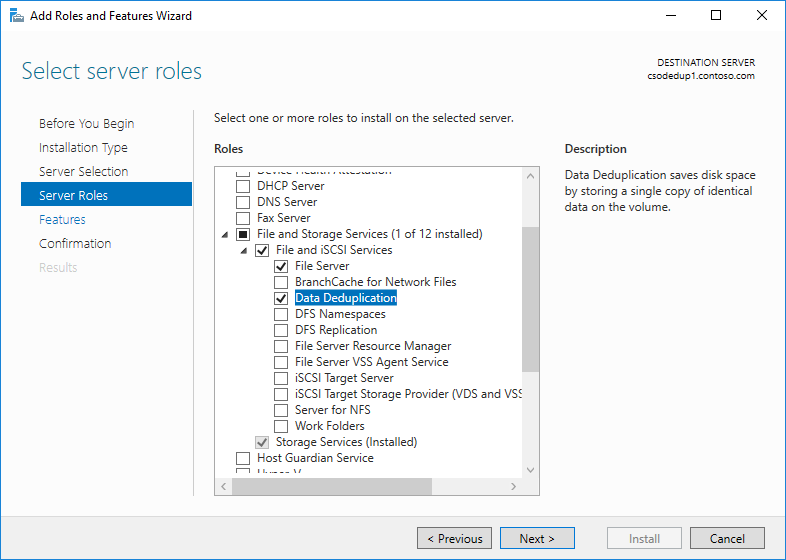
- Cliquez sur Suivant jusqu’à ce que le bouton Installer soit actif, puis cliquez sur Installer.
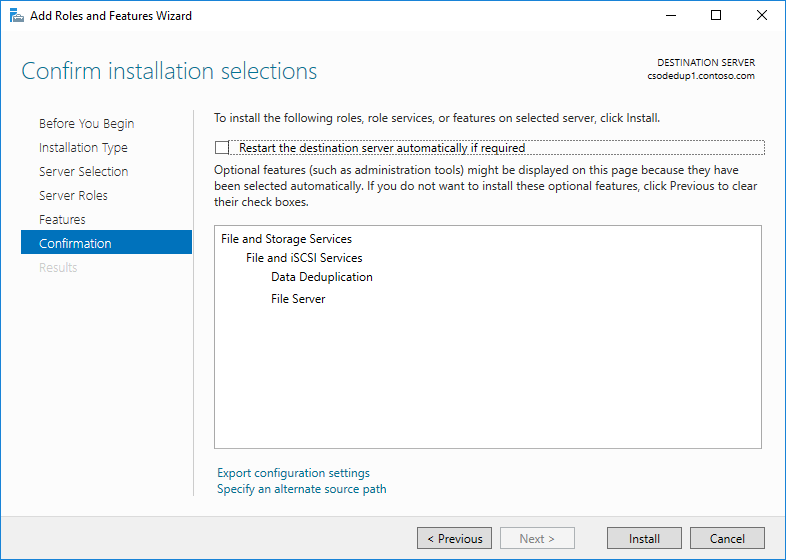
Installer la déduplication des données à l’aide de PowerShell
Pour installer la déduplication des données, exécutez la commande PowerShell suivante comme administrateur : Install-WindowsFeature -Name FS-Data-Deduplication
Pour installer la déduplication des données :
À partir d’un serveur exécutant Windows Server 2016 ou version ultérieure, ou d’un ordinateur Windows sur lequel les Outils d’administration de serveur distant sont installés, installez la déduplication des données avec une référence explicite au nom du serveur (remplacez ’MyServer’ par le nom réel de l’instance de serveur) :
Install-WindowsFeature -ComputerName <MyServer> -Name FS-Data-Deduplicationou
Connectez-vous à distance à l’instance de serveur avec la communication à distance PowerShell et la commande DISM pour installer la déduplication des données :
Enter-PSSession -ComputerName MyServer dism /online /enable-feature /featurename:dedup-core /all
Activer la déduplication des données
Identifier les charges de travail candidates à la déduplication des données
La déduplication des données peut être efficace pour réduire les coûts de consommation de données d’une application serveur en réduisant la quantité d’espace disque utilisée par les données redondantes. Avant d’activer la déduplication, il est important que vous compreniez les caractéristiques de votre charge de travail pour garantir des performances optimales hors de votre espace de stockage. Il existe deux classes de charges de travail à prendre en compte :
- Les charges de travail recommandées reconnues comme disposant des deux jeux de données qui bénéficient fortement de la déduplication et qui disposent de modèles de consommation de ressources compatibles avec le modèle de post-traitement de la déduplication des données. Nous recommandons de toujours activer la déduplication des données sur les charges de travail suivantes :
- Serveurs de fichiers à usage général traitant des partages tels que les partages d’équipe, les dossiers de base des utilisateurs, les dossiers de travail et les partages de développement de logiciels.
- Serveurs VDI (Virtual Desktop Infrastructure).
- Applications de sauvegarde virtualisée comme Microsoft Data Protection Manager (DPM).
- Charges de travail qui peuvent bénéficier de la déduplication, mais qui ne sont pas toujours de bons candidats à la déduplication. Par exemple, les charges de travail suivantes peuvent fonctionner correctement avec la déduplication, mais vous devez tout d’abord évaluer les avantages de celle-ci :
- Hôtes Hyper-V à usage général
- Serveurs SQL
- Serveurs métier
Évaluer les charges de travail pour la déduplication des données
Important
Si vous exécutez une charge de travail recommandée, vous pouvez ignorer cette section et passer à la section Activer la déduplication des données pour votre charge de travail.
Pour déterminer si une charge de travail fonctionne correctement avec la déduplication, répondez aux questions suivantes. Si vous n’êtes pas sûr d’une charge de travail, effectuez un déploiement pilote de la déduplication des données sur un jeu de données de test afin de voir comment elle se comporte.
Le jeu de données de ma charge de travail dispose-t-il d’une duplication suffisante pour tirer avantage de l’activation de la déduplication ? Avant d’activer la déduplication des données d’une charge de travail, déterminez le niveau de duplication du jeu de données de votre charge de travail à l’aide de l’outil d’évaluation des gains de la déduplication des données, appelé DDPEval. Après avoir installé la déduplication des données, cet outil est disponible à l’emplacement suivant :
C:\Windows\System32\DDPEval.exe. DDPEval peut évaluer le potentiel d’optimisation par rapport aux volumes connectés directement (notamment les lecteurs locaux ou les volumes partagés du cluster) et aux partages réseau mappés ou non mappés.L’exécution de DDPEval.exe retourne une sortie semblable à ce qui suit :
Data Deduplication Savings Evaluation Tool Copyright 2011-2012 Microsoft Corporation. All Rights Reserved. Evaluated folder: E:\Test Processed files: 34 Processed files size: 12.03MB Optimized files size: 4.02MB Space savings: 8.01MB Space savings percent: 66 Optimized files size (no compression): 11.47MB Space savings (no compression): 571.53KB Space savings percent (no compression): 4 Files with duplication: 2 Files excluded by policy: 20 Files excluded by error: 0Comment se présentent les modèles d’E/S de ma charge de travail sur son jeu de données ? Quelles sont les performances disponibles pour ma charge de travail ? La déduplication des données optimise les fichiers sous forme de tâche périodique, plutôt que lors de l’écriture du fichier sur le disque. Par conséquent, il est important d’examiner les modèles de lecture attendus d’une charge de travail pour le volume dédupliqué. Étant donné que la déduplication des données déplace le contenu des fichiers vers le magasin de blocs et tente, dans la mesure du possible, d’organiser ce magasin par fichier, les opérations de lecture donnent des résultats optimaux quand elles sont effectuées sur des plages séquentielles d’un fichier.
Les charges de travail de type base de données ont généralement plus de modèles de lecture aléatoire que de modèles de lecture séquentielle, car les bases de données ne garantissent généralement pas une disposition optimale pour toutes les requêtes qui peuvent éventuellement être exécutées. Étant donné que les sections du magasin de blocs peuvent être sur tout le volume, l’accès à des plages de données dans le magasin de blocs pour les requêtes de base de données peut entraîner une latence supplémentaire. Les charges de travail hautes performances sont particulièrement sensibles à cette latence supplémentaire. Toutefois, les autres charges de travail de type base de données ne le sont pas nécessairement.
Notes
Ces problèmes s’appliquent principalement aux charges de travail de stockage sur les volumes composés de supports de stockage de rotation traditionnels (également appelés « lecteurs de disque dur » ou « disques durs »). Toutes les infrastructures de stockage de mémoire flash (également appelées « disques SSD ») sont moins affectées par les modèles d’E/S aléatoires, car l’une des propriétés de support Flash est un temps d’accès égal pour tous les emplacements sur le disque. Par conséquent, la déduplication n’entraîne pas la même durée de latence pour les lectures dans les jeux de données d’une charge de travail stockés sur tous les supports Flash comme elle le ferait sur un support de stockage de rotation traditionnel.
Quels sont les besoins en ressources de ma charge de travail sur le serveur ? Étant donné que la déduplication des données utilise un modèle de post-traitement, elle doit régulièrement avoir assez de ressources système pour terminer son optimisation et d’autres tâches. Cela signifie que les charges de travail qui ont des temps d’inactivité, comme le soir ou le week-end, sont d’excellents candidats pour la déduplication, contrairement aux charges de travail qui s’exécutent 24h/24 et 7j/7. Les charges de travail qui n’ont pas de temps d’inactivité peuvent malgré tout constituer de bons candidats à la déduplication si la charge de travail n’a pas de forts besoins en ressources sur le serveur.
Activer la déduplication des données
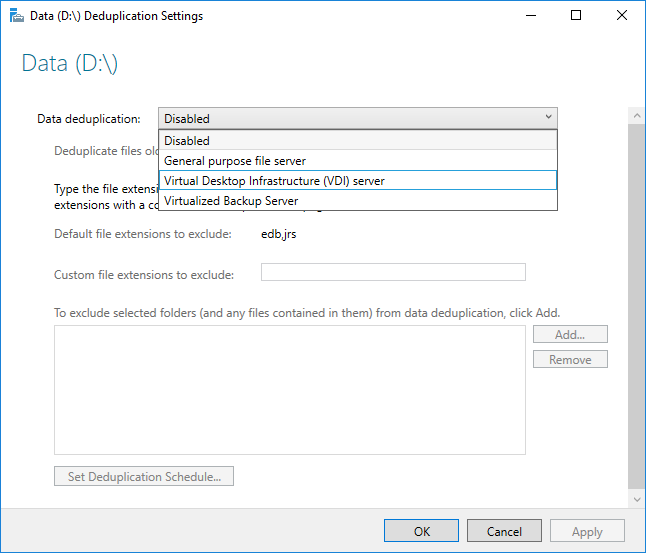
Avant d’activer la déduplication des données, vous devez choisir le Type d’utilisation qui ressemble le plus à votre charge de travail. Trois types d’utilisation sont inclus avec la déduplication des données :
- Par défaut : paramétré spécifiquement pour le serveur de fichiers à usage général
- Hyper-V - analysé spécifiquement pour les serveurs VDI
- Sauvegarde : paramétré spécifiquement pour les applications de sauvegarde virtualisée comme Microsoft DPM
Activer la déduplication des données à l’aide du Gestionnaire de serveur
- Sélectionnez Services de fichiers et de stockage dans le Gestionnaire de serveur.
- Sélectionnez Volumes dans Services de fichiers et de stockage.
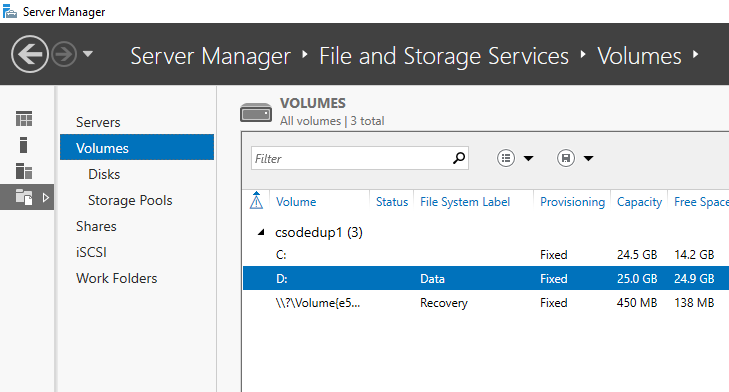
- Cliquez avec le bouton droit sur le volume de votre choix, puis sélectionnez Configurer la déduplication des données.
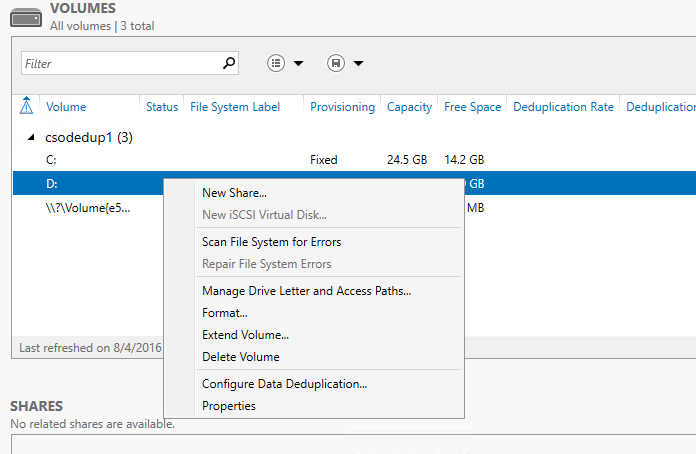
- Sélectionnez le Type d’utilisation souhaité dans la zone de liste déroulante, puis cliquez sur OK.
- Si vous exécutez une charge de travail recommandée, vous avez terminé. Pour les autres charges de travail, consultez Autres considérations.
Notes
Des informations supplémentaires sur l’exclusion d’extensions de fichiers ou de dossiers et la sélection de la planification de déduplication, notamment la raison pour laquelle vous pourriez souhaiter ces opérations, sont disponibles dans la page Configuration de la déduplication des données.
Activer la déduplication des données à l’aide de PowerShell
Avec un contexte d’administrateur, exécutez la commande PowerShell suivante :
Enable-DedupVolume -Volume <Volume-Path> -UsageType <Selected-Usage-Type>Si vous exécutez une charge de travail recommandée, vous avez terminé. Pour les autres charges de travail, consultez Autres considérations.
Notes
Les applets de commande PowerShell de la déduplication des données, notamment Enable-DedupVolume, peuvent être exécutés à distance en ajoutant le paramètre -CimSession avec une sessionCIM. Cela est particulièrement utile pour exécuter à distance les applets de commande PowerShell de la déduplication des données sur une instance de serveur. Pour créer une sessionCIM, exécutez New-CimSession.
Autres considérations
Important
Si vous exécutez une charge de travail recommandée, vous pouvez ignorer cette section.
- Les types d’utilisation de la déduplication des données donnent des valeurs par défaut sensibles pour les charges de travail recommandées, mais fournissent également un bon point de départ pour toutes les charges de travail. Pour les charges de travail autres que les charges de travail recommandées, il est possible de modifier les paramètres avancés de la déduplication des données pour améliorer les performances de la déduplication.
- Si votre charge de travail a de forts besoins en ressources sur votre serveur, les tâches de déduplication des données doivent être planifiées pour s’exécuter pendant les périodes d’inactivité attendues pour cette charge de travail. Cela est particulièrement important lors de l’exécution de la déduplication sur un hôte hyperconvergé, car l’exécution de la déduplication des données pendant les heures de travail prévues peut priver les machines virtuelles.
- Si votre charge de travail n’a pas de forts besoins en ressources, ou s’il est plus important d’effectuer les tâches d’optimisation que de traiter les demandes de charge de travail, la mémoire, le processeur et la priorité des tâches de déduplication des données peuvent être configurés.
Forum Aux Questions (FAQ)
Je souhaite exécuter la déduplication des données sur le jeu de données de la charge de travail X. Est-ce pris en charge ? En plus des charges de travail qui sont répertoriées comme ne permettant pas l’interopérabilité avec la déduplication des données, nous prenons totalement en charge l’intégrité des données de la déduplication des données avec n’importe quelle charge de travail. Les charges de travail recommandées sont également prises en charge par Microsoft pour les performances. Les performances des autres charges de travail dépendent en grande partie de ce qu’ils font sur votre serveur. Vous devez déterminer quelles conséquences en termes de performances la déduplication a sur votre charge de travail, et si cela est acceptable pour cette charge de travail.
Quels sont les critères de taille pour les volumes dédupliqués ? Dans Windows Server 2012 et Windows Server 2012 R2, la taille des volumes devait être définie avec soin pour que la déduplication des données puisse suivre l’activité des données sur le volume. Cela signifiait généralement que la taille moyenne et maximale d’un volume dédupliqué pour une charge de travail avec une forte activité était de 1 à 2 To, et que la taille recommandée maximale absolue était de 10 To. Dans Windows Server 2016, ces limitations ont été supprimées. Pour plus d’informations, consultez Nouveautés de la déduplication des données.
Est-il nécessaire de modifier la planification ou d’autres paramètres de la déduplication des données pour les charges de travail recommandées ? Non, les types d’utilisation fournis ont été créés pour fournir des valeurs par défaut raisonnables pour les charges de travail recommandées.
Quels sont les besoins en mémoire pour la déduplication des données ?
Au minimum, la déduplication des données doit disposer de 300 Mo + 50 Mo pour chaque To de données logiques. Par exemple, si vous optimisez un volume de 10 To, vous devez disposer d’au moins 800 Mo de mémoire allouée à la déduplication (300 MB + 50 MB * 10 = 300 MB + 500 MB = 800 MB). Même si la déduplication des données peut optimiser un volume avec cette faible quantité de mémoire, le fait d’avoir des ressources restreintes ralentit les tâches de déduplication des données.
Dans le meilleur des cas, la déduplication des données doit avoir 1 Go de mémoire pour chaque To de données logique. Par exemple, si vous optimisez un volume de 10 To, vous devez idéalement disposer de 10 Go de mémoire allouée à la déduplication de données (1 GB * 10). Ce rapport garantit des performances maximales pour les tâches de déduplication des données.
Quels sont les besoins en stockage pour la déduplication des données ? Dans Windows Server 2016, la déduplication des données peut prendre en charge des tailles de volume pouvant atteindre 64 To. Pour plus d’informations, consultez Nouveautés de la déduplication des données.