Usare dati di riferimento da un database SQL per un processo di Analisi di flusso di Azure
Analisi di flusso di Azure supporta il database SQL di Azure come origine di input per i dati di riferimento. È possibile usare i dati contenuti in un database SQL come dati di riferimento per un processo di Analisi di flusso nel portale di Azure e in Visual Studio con gli strumenti di Analisi di flusso. Questo articolo illustra come fare con entrambi i metodi.
Portale di Azure
Seguire questa procedura per aggiungere il database SQL di Azure come origine di input di riferimento tramite il portale di Azure:
Prerequisiti del portale
Creare un processo di Analisi di flusso.
Creare un account di archiviazione che verrà usato dal processo di Analisi di flusso.
Importante
Analisi di flusso di Azure mantiene gli snapshot all'interno di questo account di archiviazione. Quando si configurano i criteri di conservazione, è fondamentale assicurarsi che l'intervallo di tempo scelto includa effettivamente la durata di ripristino desiderata per il processo di Analisi di flusso.
Creare il database SQL di Azure con un set di dati da usare come dati di riferimento per il processo di Analisi di flusso.
Definire l'input dei dati di riferimento del database SQL
Nel processo di Analisi di flusso selezionare Input sotto Topologia processo. Fare clic su Aggiungi input di riferimento e scegliere Database SQL.
Compilare le configurazioni di input di Analisi di flusso. Scegliere il nome del database, il nome del server, il nome utente e la password. Se si vuole che l'input dei dati di riferimento venga aggiornato periodicamente, scegliere "Attivato" per specificare la frequenza di aggiornamento in GG:HH:MM. Se sono presenti set di dati di grandi dimensioni con una frequenza di aggiornamento breve. La query Delta consente di tenere traccia delle modifiche all'interno dei dati di riferimento recuperando tutte le righe in database SQL inserite o eliminate entro un'ora di inizio, @deltaStartTimee un'ora @deltaEndTimedi fine.
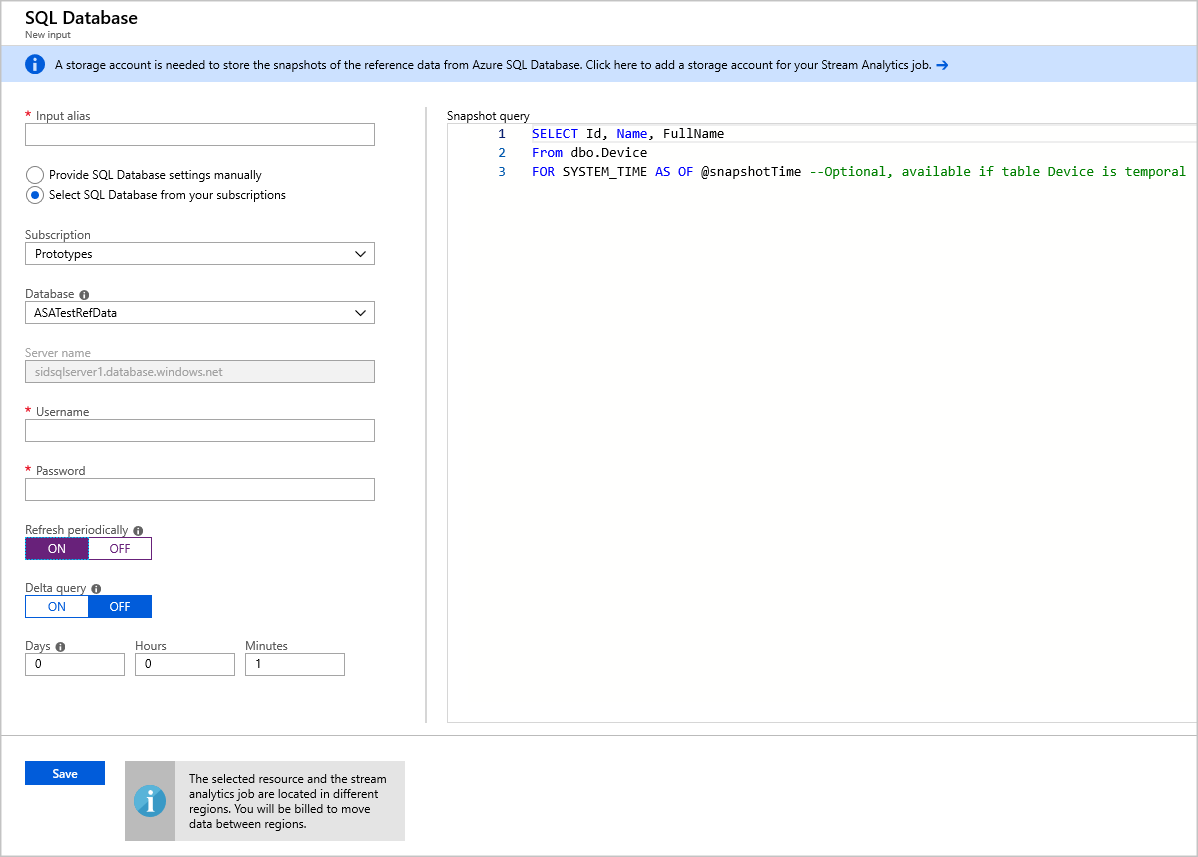
- Testare la query snapshot nell'editor di query SQL. Per altre informazioni, vedere Usare l'editor di query SQL del portale di Azure per connettersi ed eseguire query sui dati
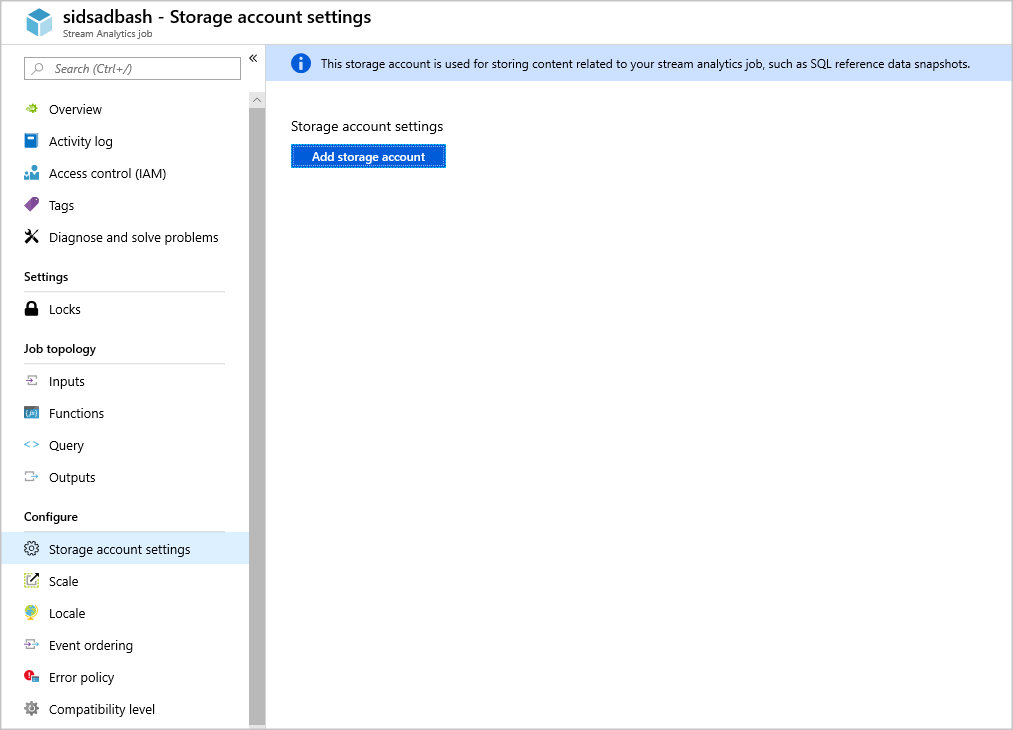
Specificare l'account di archiviazione nella configurazione del processo
Passare a Impostazioni account di archiviazione sotto Configura e selezionare Aggiungi account di archiviazione.
Avviare il processo
Dopo aver configurato gli altri input, output e query, è possibile avviare il processo di Analisi di flusso.
Strumenti per Visual Studio
Seguire questa procedura per aggiungere il database SQL di Azure come origine di input di riferimento tramite Visual Studio:
Prerequisiti di Visual Studio
Installare gli strumenti di Analisi di flusso per Visual Studio. Sono supportate le versioni seguenti di Visual Studio:
- Visual Studio 2015
- Visual Studio 2019
Acquisire familiarità con l'argomento di avvio rapido sugli strumenti di Analisi di flusso per Visual Studio.
Creare un account di archiviazione.
Importante
Analisi di flusso di Azure mantiene gli snapshot all'interno di questo account di archiviazione. Quando si configurano i criteri di conservazione, è fondamentale assicurarsi che l'intervallo di tempo scelto includa effettivamente la durata di ripristino desiderata per il processo di Analisi di flusso.
Creare una tabella del database SQL
Usare SQL Server Management Studio per creare una tabella in cui archiviare i dati di riferimento. Per informazioni dettagliate, vedere Progettare la prima database SQL di Azure usando SSMS.
La tabella di esempio usata nell'esempio seguente è stata creata dall'istruzione seguente:
create table chemicals(Id Bigint,Name Nvarchar(max),FullName Nvarchar(max));
Scegliere la sottoscrizione in uso
In Visual Studio dal menu Visualizza scegliere Esplora server.
Fare clic con il pulsante destro del mouse su Azure, selezionare Connessione alla sottoscrizione di Microsoft Azure e quindi accedere con l'account di Azure.
Creare un progetto di Analisi di flusso
Selezionare File > Nuovo progetto.
Nell'elenco dei modelli a sinistra selezionare Analisi di flusso e quindi Applicazione Analisi di flusso di Azure.
Inserire i valori appropriati per il progetto in Nome, Percorso e Nome soluzione e scegliere OK.

Definire l'input dei dati di riferimento del database SQL
Creare un nuovo input.

Fare doppio clic su Input.json in Esplora soluzioni.
Compilare Stream Analytics Input Configuration (Configurazione input Analisi di flusso). Scegliere nome del database, nome del server, tipo di aggiornamento e frequenza di aggiornamento. Specificare la frequenza di aggiornamento nel formato
DD:HH:MM.
Se si sceglie "Execute only once"(Esegui una sola volta) o "Execute periodically" (Esegui periodicamente), un file SQL CodeBehind denominato [Alias di input].snapshot.sql viene generato nel progetto sotto il nodo del file Input.json.

Se si sceglie "Refresh Periodically with Delta" (Aggiorna periodicamente con delta), verranno generati due file SQL CodeBehind: [Alias di Input].snapshot.sql e [Alias di Input].delta.sql.
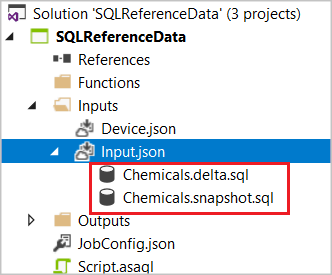
Aprire il file SQL nell'editor e scrivere la query SQL.
Se si usa Visual Studio 2019 ed è installato SQL Server Data Tools, è possibile testare la query facendo clic su Esegui. Verrà visualizzata una finestra della procedura guidata che consente di connettersi a database SQL e il risultato della query verrà visualizzato nella finestra in basso.
Specificare l'account di archiviazione
Aprire JobConfig.json per specificare l'account di archiviazione in cui archiviare gli snapshot di riferimento SQL.

Testare in locale e distribuire in Azure
Prima di distribuire il processo in Azure, è possibile testare la logica di query in locale con dati di input live. Per altre informazioni su questa funzionalità, vedere Testare i dati live in locale usando gli strumenti di Analisi di flusso di Azure per Visual Studio (anteprima). Dopo aver completato i test, fare clic su Invia ad Azure. Per informazioni su come avviare, il processo vedere l'argomento di avvio rapido Creare un processo di Analisi di flusso con gli strumenti di Analisi di flusso di Azure per Visual Studio.
Query delta
Quando si usa la query delta, è consigliabile usare le tabelle temporali nel database SQL di Azure.
Creare una tabella temporale nel database SQL di Azure.
CREATE TABLE DeviceTemporal ( [DeviceId] int NOT NULL PRIMARY KEY CLUSTERED , [GroupDeviceId] nvarchar(100) NOT NULL , [Description] nvarchar(100) NOT NULL , [ValidFrom] datetime2 (0) GENERATED ALWAYS AS ROW START , [ValidTo] datetime2 (0) GENERATED ALWAYS AS ROW END , PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo) ) WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.DeviceHistory)); -- DeviceHistory table will be used in Delta queryCreare la query snapshot.
Usare il parametro @snapshotTime per indicare al runtime di Analisi di flusso di ottenere il set di dati di riferimento da database SQL tabella temporale valida al momento del sistema. Se non si specifica questo parametro si rischia di ottenere un set di dati di riferimento di base non accurato, a causa degli sfasamenti di orario. Di seguito è riportata una query snapshot completa di esempio:
SELECT DeviceId, GroupDeviceId, [Description] FROM dbo.DeviceTemporal FOR SYSTEM_TIME AS OF @snapshotTimeCreare la query delta.
Questa query recupera tutte le righe in database SQL inserite o eliminate entro un'ora di inizio, @deltaStartTime e un'ora di fine @deltaEndTime. La query delta deve restituire le stesse colonne della query snapshot, nonché la colonna operation. Questa colonna definisce se la riga viene inserita o eliminata tra @deltaStartTime e @deltaEndTime. Le righe risultanti vengono contrassegnate con 1 se i record sono stati inseriti, con 2 se sono stati eliminati. La query deve anche aggiungere filigrana dal lato SQL Server per assicurarsi che tutti gli aggiornamenti nel periodo delta vengano acquisiti in modo appropriato. L'uso di una query delta senza filigrana può causare un set di dati di riferimento non corretto.
Per i record aggiornati, la tabella temporale registra un'operazione di inserimento ed eliminazione. Il runtime di Analisi di flusso applicherà quindi i risultati della query delta allo snapshot precedente per mantenere aggiornati i dati di riferimento. Un esempio di query delta è illustrato di seguito:
SELECT DeviceId, GroupDeviceId, Description, ValidFrom as _watermark_, 1 as _operation_ FROM dbo.DeviceTemporal WHERE ValidFrom BETWEEN @deltaStartTime AND @deltaEndTime -- records inserted UNION SELECT DeviceId, GroupDeviceId, Description, ValidTo as _watermark_, 2 as _operation_ FROM dbo.DeviceHistory -- table we created in step 1 WHERE ValidTo BETWEEN @deltaStartTime AND @deltaEndTime -- record deletedSi noti che il runtime di Analisi di flusso può eseguire periodicamente la query snapshot oltre alla query delta per archiviare i checkpoint.
Importante
Quando si usano query delta dei dati di riferimento, non apportare aggiornamenti identici alla tabella dei dati di riferimento temporale più volte. Ciò potrebbe causare la produzione di risultati non corretti. Di seguito è riportato un esempio che può causare la generazione di risultati non corretti dei dati di riferimento:
UPDATE myTable SET VALUE=2 WHERE ID = 1; UPDATE myTable SET VALUE=2 WHERE ID = 1;Esempio corretto:
UPDATE myTable SET VALUE = 2 WHERE ID = 1 and not exists (select * from myTable where ID = 1 and value = 2);In questo modo non vengono eseguiti aggiornamenti duplicati.
Testare la query
È importante verificare che la query restituisca il set di dati previsto che verrà usato dal processo di analisi di flusso come dati di riferimento. Per testare la query, passare a Input nella sezione Topologia processo nel portale. È quindi possibile selezionare Dati di esempio nell'input di riferimento del database SQL. Quando l'esempio diventa disponibile, è possibile scaricare il file e verificare se i dati restituiti sono quelli previsti. Se si vuole ottimizzare le iterazioni di sviluppo e test, è consigliabile usare gli Strumenti di Analisi di flusso per Visual Studio. È anche possibile usare qualsiasi altro strumento di preferenza per assicurarsi prima che la query restituisca i risultati corretti dal database SQL di Azure e quindi usarla nel processo di analisi di flusso.
Testare la query con Visual Studio Code
Installare gli strumenti di Analisi di flusso di Azure e SQL Server (mssql) in Visual Studio Code e configurare il progetto ASA. Per altre informazioni, vedere Avvio rapido: Creare un processo di Analisi di flusso di Azure in Visual Studio Code e l'esercitazione sull'estensione SQL Server (mssql).
Configurare l'input dei dati di riferimento SQL.

Selezionare l'icona di SQL Server e fare clic su Aggiungi connessione.
Immettere le informazioni di connessione.

Fare clic con il pulsante destro del mouse su SQL di riferimento e scegliere Esegui query.
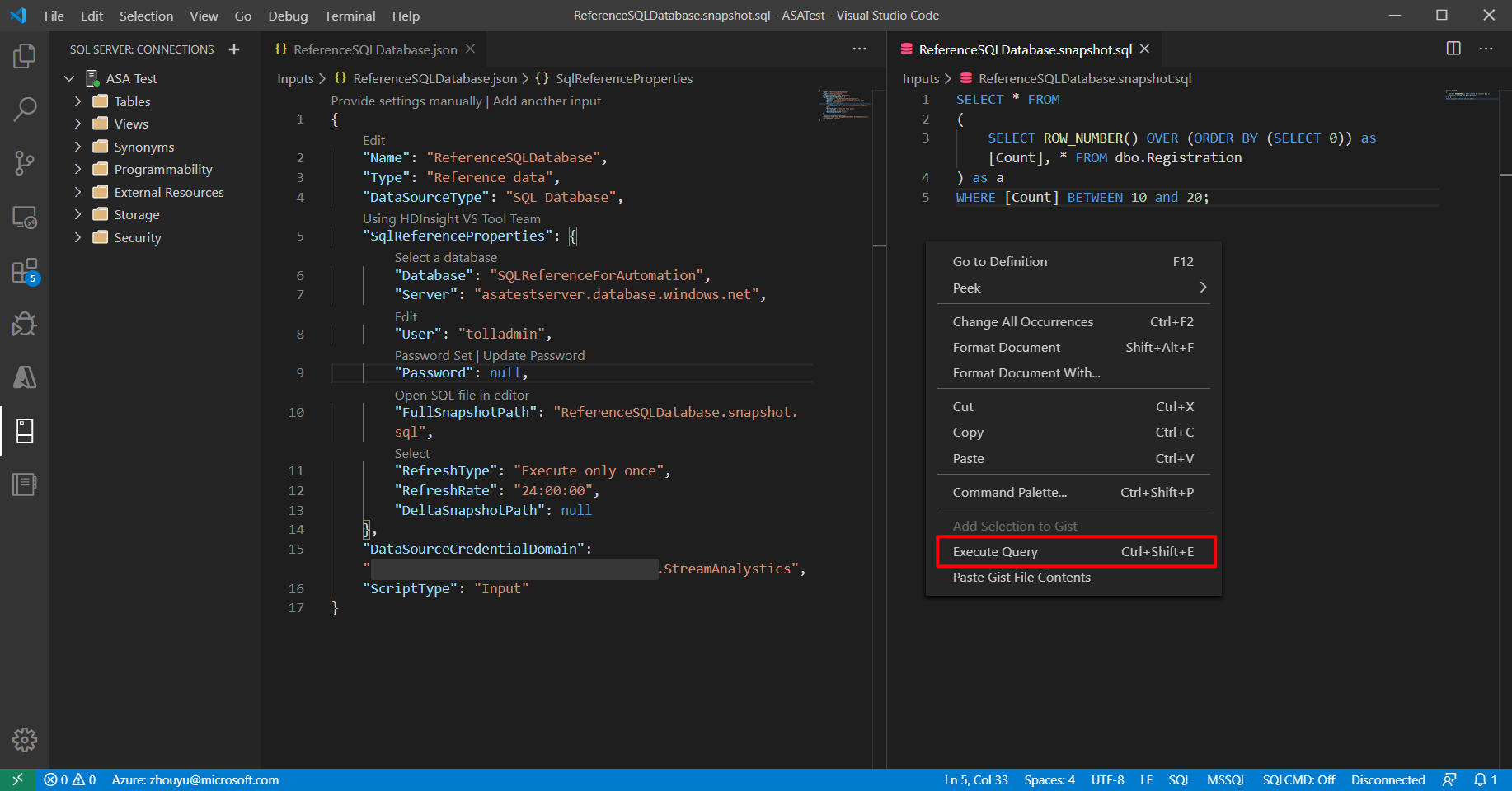
Scegliere la connessione.
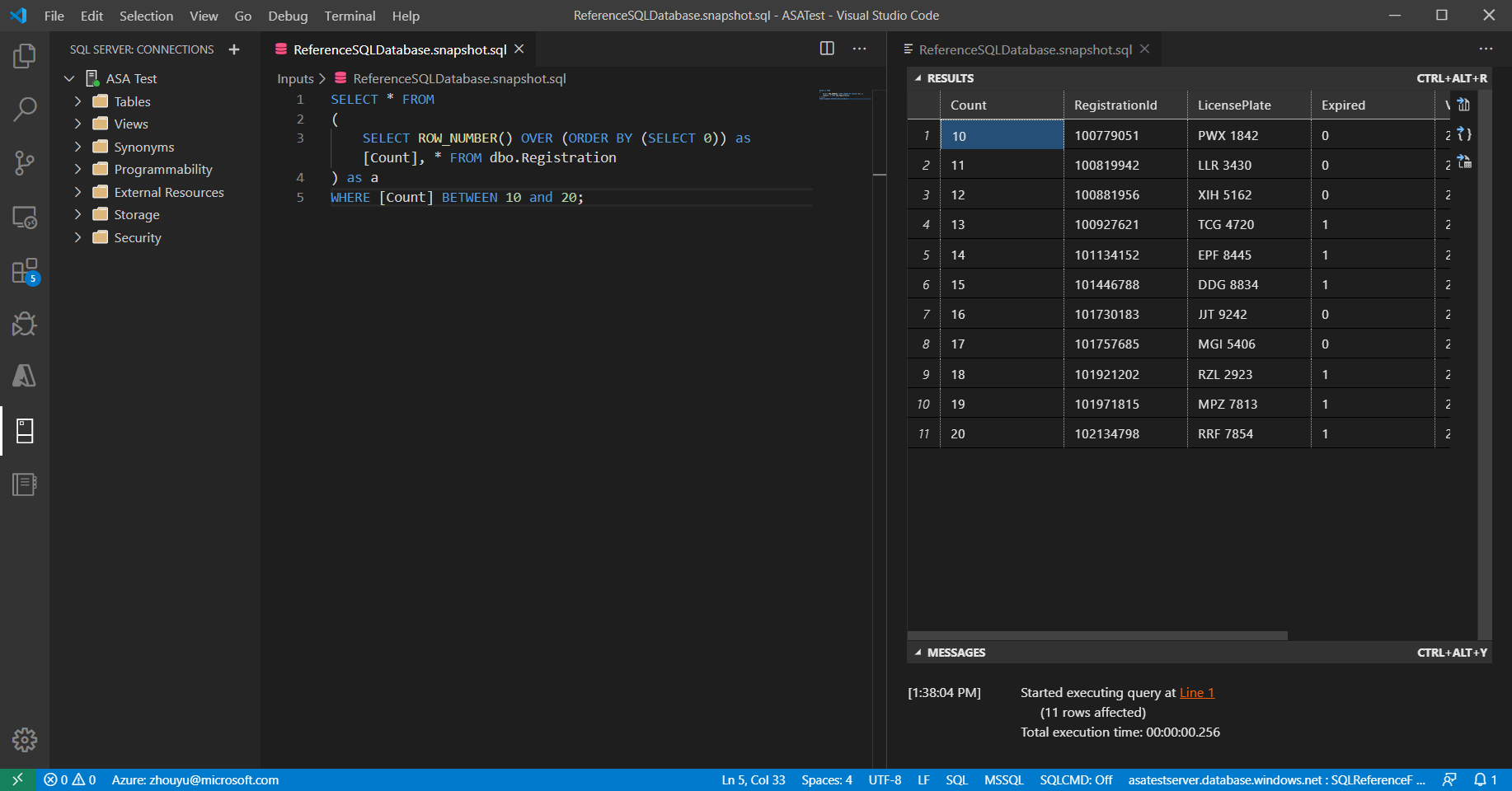
Esaminare e verificare il risultato della query.
Domande frequenti
Vengono addebitati costi aggiuntivi usando un input dei dati di riferimento SQL in Analisi di flusso di Azure?
Non sono previsti costi per unità di streaming aggiuntivi nel processo di Analisi di flusso. Tuttavia, il processo di Analisi di flusso deve avere un account di archiviazione di Azure associato. Il processo di Analisi di flusso esegue una query sul database SQL (all'avvio del processo e nell'intervallo di aggiornamento) per recuperare il set di dati di riferimento e archivia lo snapshot nell'account di archiviazione. Per l'archiviazione di questi snapshot verranno addebitati costi aggiuntivi, descritti in dettaglio nella pagina dei prezzi per l'account di archiviazione di Azure.
Come si capisce se lo snapshot dei dati di riferimento viene interrogato dal database SQL e usato nel processo di Analisi di flusso di Azure?
Esistono due metriche filtrate in base al nome logico (in Metriche portale di Azure) che è possibile usare per monitorare l'integrità dell'input dei dati di riferimento database SQL.
- InputEvents: questa metrica misura il numero di record caricati dal set di dati di riferimento database SQL.
- InputEventBytes: questa metrica misura le dimensioni dello snapshot dei dati di riferimento caricato in memoria del processo di Analisi di flusso.
La combinazione di entrambe queste metriche può essere usata per dedurre se il processo esegue query database SQL per recuperare il set di dati di riferimento e quindi caricarlo in memoria.
È necessario un tipo particolare di database SQL di Azure?
Analisi di flusso di Azure funziona con qualsiasi tipo di database SQL di Azure. Tuttavia, è importante comprendere che la frequenza di aggiornamento impostata per l'input dei dati di riferimento potrebbe incidere sul carico di query. Per usare l'opzione della query delta, è consigliabile usare le tabelle temporali nel database SQL di Azure.
Perché Analisi di flusso di Azure archivia gli snapshot nell'account di archiviazione di Azure?
Analisi di flusso garantisce un'elaborazione di eventi di tipo exactly-once e il recapito degli eventi almeno una volta. Nei casi in cui problemi temporanei incidano sul processo, per ripristinare lo stato è necessaria una breve riproduzione. Per abilitare la riproduzione è necessario aver archiviato questi snapshot in un account di archiviazione di Azure. Per altre informazioni sulla riproduzione dei checkpoint, vedere Concetti di checkpoint e riproduzione nei processi di Analisi di flusso di Azure.
Passaggi successivi
- Informazioni sugli output di Analisi di flusso di Azure
- Output di Analisi di flusso di Azure nel database SQL di Azure
- Aumentare le prestazioni della velocità effettiva per il database SQL di Azure da Analisi di flusso di Azure
- Usare le identità gestite per accedere al database SQL di Azure o ad Azure Synapse Analytics da un processo di Analisi di flusso di Azure
- Aggiornare o unire record in database SQL di Azure con Funzioni di Azure
- Avvio rapido: creare un processo di Analisi di flusso di Azure tramite il portale di Azure