Come migliorare il modello di Visione personalizzata
In questa guida si apprenderà come migliorare la qualità del modello di Visione personalizzata. La qualità del classificatore o del rilevatore di oggetti dipende dalla quantità, qualità e varietà dei dati con etichetta che sono forniti e dal bilanciamento del set di dati a livello generale. Un modello valido ha un set di dati di training bilanciato rappresentativo di ciò che viene inviato. Il processo di creazione di un modello di questo tipo è iterativo; è comune effettuare alcuni cicli di training per raggiungere i risultati previsti.
Di seguito è riportato un modello generale che consente di eseguire il training di un modello più accurato:
- Primo ciclo di training
- Aggiungere altre immagini e bilanciare i dati; ripetere il training
- Aggiungere immagini con sfondi, illuminazione, dimensioni degli oggetti, angolazioni e stili diversi; ripetere il training
- Usare nuove immagini per testare la stima
- Modificare i dati di training esistenti in base ai risultati della stima
Impedire l'overfitting
A volte un modello impara a eseguire stime basate su caratteristiche arbitrarie che le immagini hanno in comune. Ad esempio, se si sta creando un classificatore per mele e agrumi e si sono usate immagini di mele in mano e di agrumi su piatti bianchi, il classificatore potrebbe dare importanza non dovuta a mani e piatti bianchi anziché a mele e agrumi.
Per risolvere il problema, fornire immagini con diverse angolazioni, sfondi, dimensioni degli oggetti, gruppi e altre variazioni. Le sezioni seguenti espandono su questi concetti.
Verificare la quantità di dati
Il numero di immagini di training è il fattore più importante per il set di dati. È consigliabile usare come punto di partenza almeno 50 immagini per etichetta. Con un numero inferiore di immagini, c'è un rischio maggiore di overfitting e, sebbene i numeri di prestazione possano suggerire una buona qualità, il modello potrebbe avere difficoltà con i dati del mondo reale.
Garantire il bilanciamento dei dati
È anche importante valutare le quantità relative dei dati di training. Ad esempio, l'uso di 500 immagini per un'etichetta e di 50 immagini per un'altra etichetta rende sbilanciato un set di dati di training. In questo modo il modello risulta più accurato nella stima di un'etichetta rispetto a un'altra. È possibile ottenere risultati migliori se si mantiene un rapporto di almeno 1:2 tra l'etichetta con il minor numero di immagini e l'etichetta con il maggior numero di immagini. Ad esempio, se l'etichetta con più immagini contiene 500 immagini, l'etichetta con il numero inferiore di immagini dovrebbe disporre per il training di almeno 250 immagini.
Assicurarsi che l'ampia gamma di dati
Assicurarsi di usare immagini rappresentative di ciò che verrà inviato al classificatore durante l'uso normale. In caso contrario, un modello potrebbe apprendere come eseguire stime in base alle caratteristiche arbitrarie che le immagini hanno in comune. Ad esempio, se si sta creando un classificatore per mele e agrumi e si sono usate immagini di mele in mano e di agrumi su piatti bianchi, il classificatore potrebbe dare importanza non dovuta a mani e piatti bianchi anziché a mele e agrumi.

Per risolvere questo problema, includere un'ampia gamma di immagini per garantire che il modello possa generalizzare al meglio. Di seguito sono illustrati alcuni modi in cui è possibile diversificare il set di training:
Sfondo: specificare le immagini dell'oggetto davanti a diversi colori di sfondo. Le foto in contesti naturali sono migliori delle foto con sfondi neutri in quanto forniscono informazioni aggiuntive al classificatore.

Illuminazione: fornire immagini con diversi tipi di illuminazione, ad esempio eseguite con flash, con un'esposizione alta e così via, soprattutto se le immagini usate per la stima hanno illuminazioni diverse. È inoltre utile usare immagini con saturazione, tonalità e luminosità variabili.

Dimensioni dell'oggetto: fornire immagini in cui gli oggetti variano per dimensione e numero (ad esempio, la foto di un casco di banane e il primo piano di una banana singola). Le diverse dimensioni consentono una migliore generalizzazione da parte del classificatore.

Angolazione: fornire immagini scattate con diverse angolazioni. In alternativa, se tutte le foto devono essere eseguite con telecamere fisse, ad esempio telecamere di sorveglianza, assicurarsi di assegnare un'etichetta diversa a ciascuna degli oggetti che ricorrono regolarmente per evitare l'overfitting nell'interpretazione di oggetti non correlati, ad esempio lampioni, come funzionalità chiave.

Stile: specificare le immagini di stili diversi della stessa classe (ad esempio, diverse varietà degli stessi frutti). Tuttavia, se si dispone di oggetti con stili drasticamente diversi (ad esempio, un'immagine di Mickey Mouse rispetto a un topo vero), è consigliabile etichettarle come classi separate in modo da rappresentare meglio le caratteristiche distinte.

Usare immagini negative (solo classificatori)
Se si usa un classificatore di immagini, potrebbe essere necessario aggiungere campioni negativi per rendere il classificatore più accurato. Gli esempi negativi sono immagini che non corrispondono a nessun altro tag. Quando si caricano queste immagini, applicarvi la speciale etichetta Negative (Negativa).
I rilevatori di oggetti gestiscono automaticamente campioni negativi, perché qualsiasi area dell'immagine al di fuori dei rettangoli di selezione disegnati viene considerata negativa.
Nota
Il servizio Visione personalizzata supporta alcune operazioni di gestione automatica delle immagine negative. Se, ad esempio, si sta creando un classificatore di uva e banane e per la stima si invia l'immagine di una scarpa, il classificatore deve segnare un punteggio per quell'immagine più vicino possibile allo 0%, sia per l'uva che per le banane.
D'altra parte, nei casi in cui le immagini negative sono soltanto una variazione delle immagini usate nel training, è probabile che il modello classificherà le immagini negative come una classe con etichetta a causa delle molte analogie. Se, ad esempio, si ha un classificatore di arance e di pompelmi e si invia un'immagine di una clementina, è possibile che la clementina sia classificata come un'arancia perché molte sue caratteristiche sono simili a quelle delle arance. Se le immagini negative sono di questa natura, è consigliabile creare uno o più tag aggiuntivi (ad esempio Altro) ed etichettare le immagini negative con questo tag durante il training per consentire al modello di distinguere meglio tra queste classi.
Gestire l'occlusione e il troncamento (solo rilevatori di oggetti)
Se si desidera che il rilevatore di oggetti rilevi oggetti troncati (oggetti parzialmente ritagliati dall'immagine) od occlusi (oggetti parzialmente bloccati da altri oggetti nell'immagine), sarà necessario includere immagini di training che coprono tali casi.
Nota
Il problema di oggetti che vengono occlusi da altri oggetti non deve essere confuso con La soglia di sovrapposizione, un parametro di valutazione delle prestazioni del modello. Il dispositivo di scorrimento Sovrapponi soglia nel sito Web di Visione personalizzata verifica quanto un rettangolo di selezione stimato debba sovrapporsi con il vero rettangolo di selezione per essere considerato corretto.
Usare immagini di stima per ulteriori training
Quando si usa o si testa il modello tramite l'invio di immagini per l'endpoint di stima, il servizio Visione personalizzata archivia le immagini. È quindi possibile usarle per migliorare il modello.
Per visualizzare le immagini inviate al modello aprire la pagina Web di Visione personalizzata, andare al progetto e selezionare la scheda Predictions (Stime). La visualizzazione predefinita mostra le immagini dall'iterazione corrente. È possibile usare il menu a discesa Iteration (Iterazione) per visualizzare le immagini inviate durante le iterazioni precedenti.
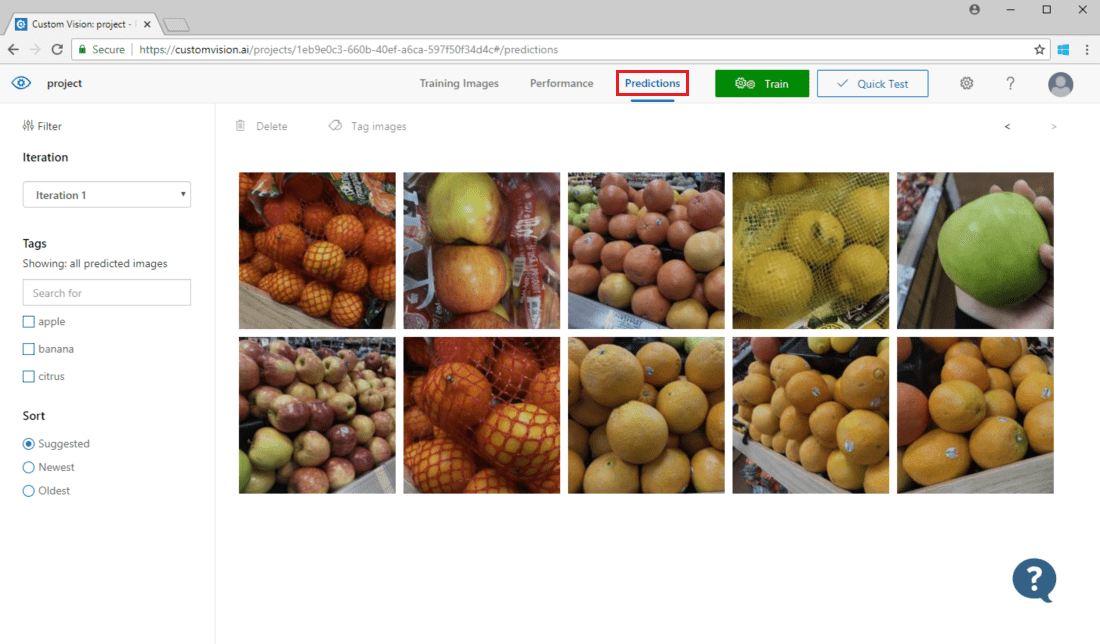
Passare il mouse su un'immagine per visualizzare i tag previsti dal modello. Le immagini vengono ordinate in modo che vengano elencate in alto quelle che possono apportare il maggior numero di miglioramenti al modello. Per usare un metodo di ordinamento diverso, effettuare una selezione all'interno della sezione Sort (Ordinamento).
Per aggiungere un'immagine ai dati di training esistenti, scegliere l'immagine, impostare i tag corretti e quindi selezionare Salva e chiudi. L'immagine viene rimossa da Predictions e aggiunta al set di immagini di training. È possibile visualizzarla selezionando la scheda Training Images (Immagini di training).
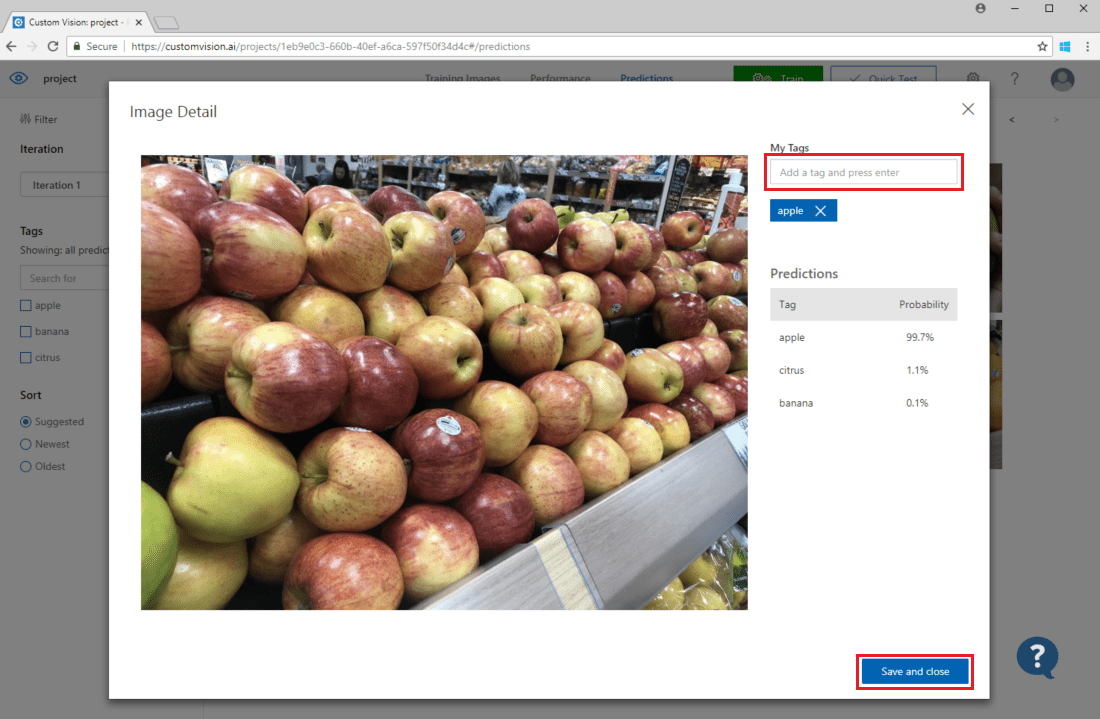
Usare quindi il pulsante Train (Eseguire il training) per ripetere il training del modello.
Controllare visivamente le stime
Per esaminare le stime delle immagini, passare alla scheda Training Images (Immagini di training), selezionare l'iterazione di training precedenti nel menu a discesa Iteration (Iterazione) e selezionare uno o più tag nella sezione Tags (Tag). La visualizzazione dovrebbe ora mostrare una casella rossa intorno a ciascuna delle immagini per le quali il modello non è riuscito a prevedere correttamente l'etichetta data.
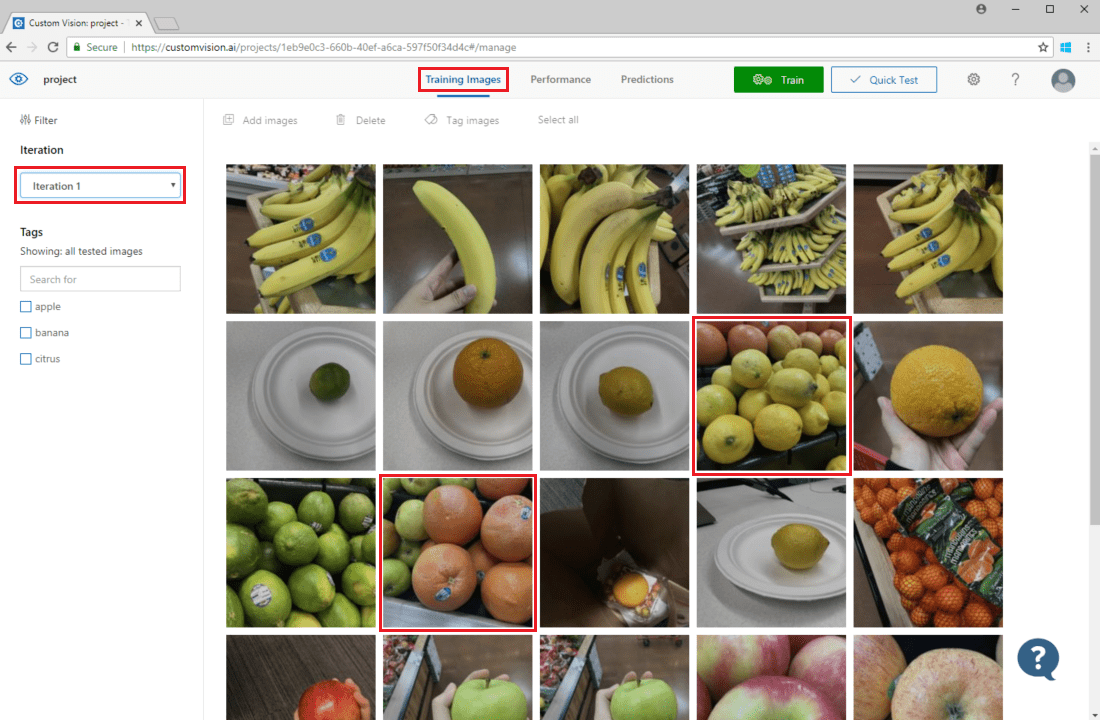
A volte un'ispezione visiva può identificare modelli che è possibile correggere aggiungendo più dati di training o modificando quelli esistenti. Un classificatore di mele rispetto a lime potrebbe ad esempio etichettare erroneamente tutte le mele verdi come lime. È perciò possibile risolvere il problema aggiungendo e fornendo dati di training che contengono immagini con tag di mele verdi.
Passaggio successivo
In questa guida, si sono apprese varie tecniche per rendere più preciso il modello di classificazione di immagini personalizzate o quello di rilevamento degli oggetti. Successivamente, altre informazioni su come eseguire il test delle immagini a livello di codice inviandole all'API delle stime.