Eseguire il training del modello vocale professionale
Questo articolo illustra come eseguire il training di una voce neurale personalizzata tramite il portale di Speech Studio.
Importante
Il training di Sintesi vocale neurale è attualmente disponibile solo in alcune aree. Dopo aver eseguito il training del modello vocale in un'area supportata, è possibile copiarlo in una risorsa Voce in un'altra area in base alle esigenze. Per altre informazioni, vedere le note a piè di pagina nella tabella del servizio Voce.
La durata del training varia a seconda della quantità di dati usata. In media sono necessarie circa 40 ore di calcolo per eseguire il training di una voce neurale personalizzata. Gli utenti con una sottoscrizione standard (S0) possono eseguire il training di quattro voci contemporaneamente. Se si raggiunge il limite, attendere che venga completato il training di almeno un modello di voce, quindi riprovare.
Nota
Anche se il numero totale di ore richieste per metodo di training varia, lo stesso prezzo unitario si applica a ognuno di essi. Per altre informazioni, vedere i dettagli sui prezzi del training neurale personalizzato.
Scegliere un metodo di training
Dopo aver convalidato i file di dati, usarli per creare il modello vocale neurale personalizzato. Quando si crea una voce neurale personalizzata, è possibile scegliere di eseguirne il training con uno dei metodi seguenti:
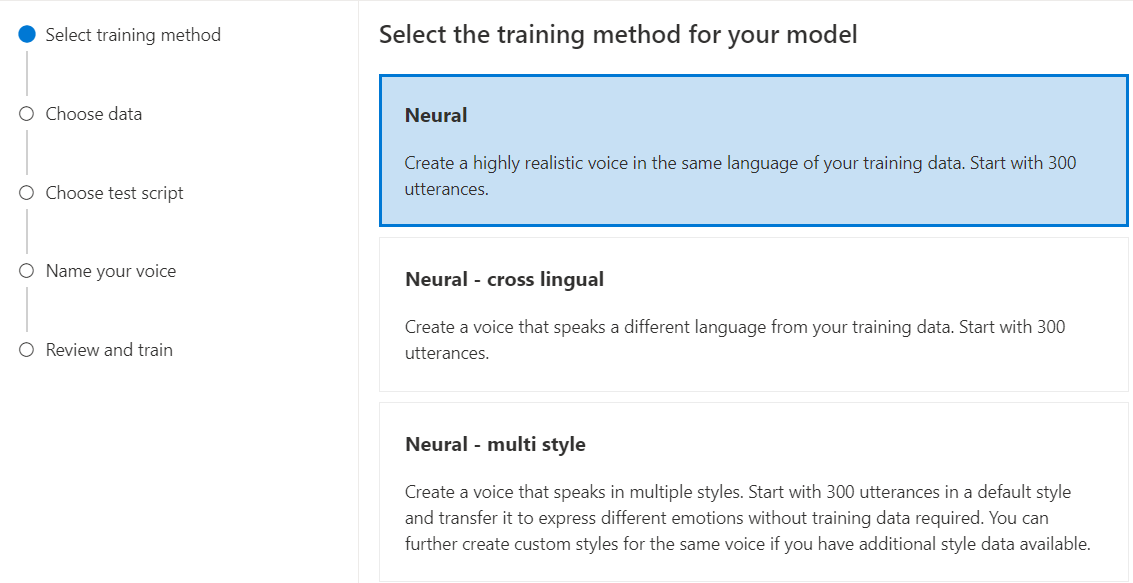
Neurale: creare una voce nella stessa lingua dei dati di training.
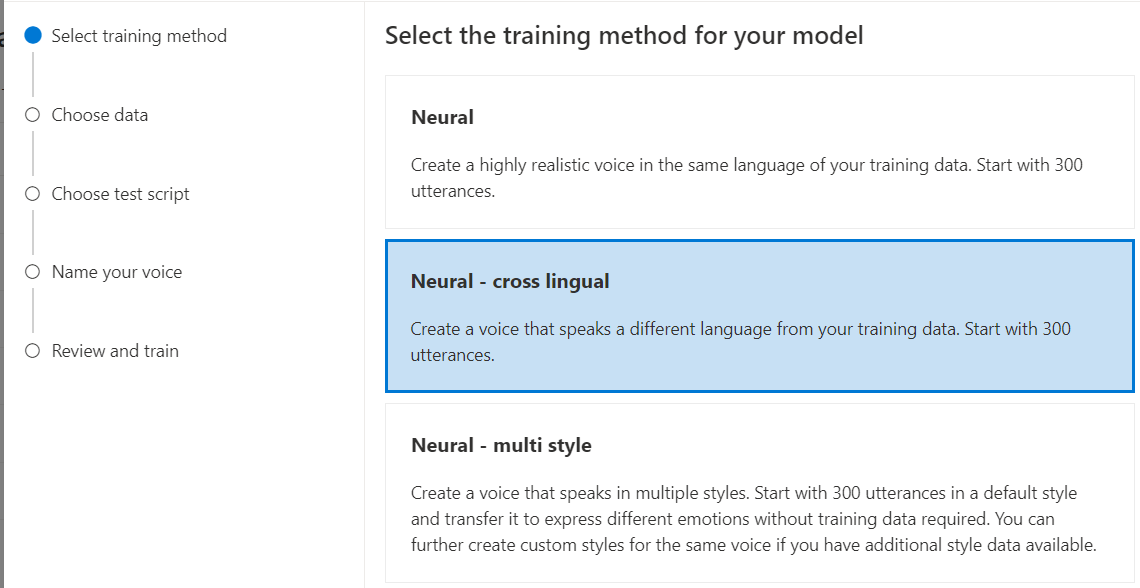
Neurale - multilingue: creare una voce che parla una lingua diversa dai dati di training. Ad esempio, con i dati di training
zh-CN, è possibile creare una voce che parlaen-US.La lingua dei dati di training e la lingua di destinazione devono essere entrambe una delle lingue supportate per il training vocale multilingue. Non è necessario preparare i dati di training nel linguaggio di destinazione, ma lo script di test deve trovarsi nella lingua di destinazione.
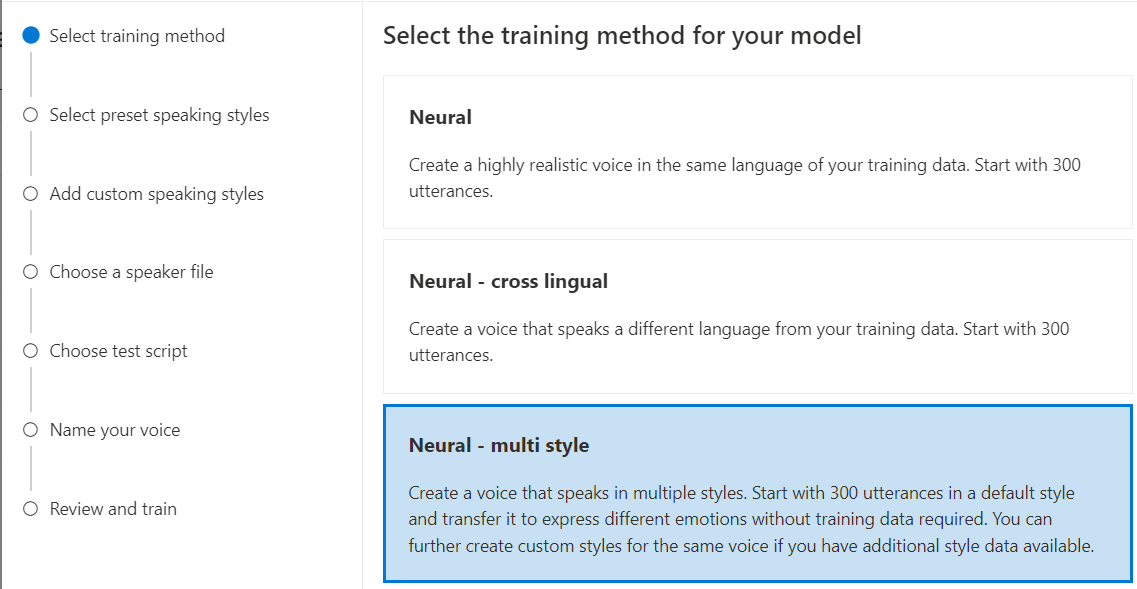
Neural - multi stile: creare una voce neurale personalizzata che parla in più stili ed emozioni, senza aggiungere nuovi dati di training. Più voci di stile sono utili per i personaggi di videogiochi, chatbot conversazionali, audiobook, lettori di contenuti e altro ancora.
Per creare una voce con più stili, è necessario preparare un set di dati di training generali, almeno 300 espressioni. Selezionare uno o più stili di destinazione predefiniti. È anche possibile creare più stili personalizzati fornendo esempi di stile, di almeno 100 espressioni per stile, come dati di training aggiuntivi per la stessa voce. Gli stili predefiniti supportati variano in base a lingue diverse. Vedere gli stili predefiniti disponibili nelle varie lingue.
Il linguaggio dei dati di training deve essere uno dei linguaggi supportati per la voce neurale personalizzata, il linguaggio multilingue o il training di più stili.
Eseguire il training del modello vocale neurale personalizzato
Per creare una voce neurale personalizzata in Speech Studio, seguire questa procedura per uno dei metodi seguenti:
Accedere a Speech Studio.
Selezionare Voce personalizzata><Nome progetto>>Eseguire il training del modello>Eseguire il training di un nuovo modello.
Selezionare Neurale come metodo di training per il modello e quindi selezionare Avanti. Per usare un metodo di training diverso, vedere Neurale - multilingue o Neural - multi stile.
Selezionare una versione della ricetta di training per il modello. La versione più recente è selezionata per impostazione predefinita. Le funzionalità supportate e il tempo di training possono variare in base alla versione. In genere, è consigliabile usare la versione più recente. In alcuni casi, è possibile scegliere una versione precedente per ridurre il tempo di training. Per altre informazioni sulla formazione bilingue e sulle differenze tra le impostazioni locali, vedere Formazione bilingue.
Nota
Le versioni del modello
V2.2021.07,V4.2021.10,V5.2022.05,V6.2022.11eV9.2023.10verranno ritirate entro il 1° ottobre 2024. I modelli vocali già creati in queste versioni ritirate non saranno interessati.Selezionare i dati da usare per il training. I nomi audio duplicati vengono rimossi dal training. Assicurarsi che i dati selezionati non contengano gli stessi nomi audio in più file .zip.
È possibile selezionare solo set di dati elaborati correttamente per il training. Se il set di training non viene visualizzato nell'elenco, controllare lo stato di elaborazione dei dati.
Selezionare un file voce con l'istruzione voice talent corrispondente all'altoparlante nei dati di training.
Selezionare Avanti.
Ogni training genera automaticamente 100 file audio di esempio per testare il modello con uno script predefinito.
Facoltativamente, è anche possibile selezionare Aggiungi script di test personale e fornire uno script di test personalizzato con un massimo di 100 espressioni per testare il modello senza costi aggiuntivi. I file audio generati sono una combinazione degli script di test automatici e degli script di test personalizzati. Per altre informazioni, vedere requisiti di script di test.
Immettere un nome per identificare il modello. Scegliere un nome con attenzione. Il nome del modello viene usato come nome vocale nella richiesta di sintesi vocale dall'SDK e dall'input SSML. Sono consentiti solo lettere, numeri e alcuni caratteri di punteggiatura. Usare nomi diversi per modelli vocali neurali diversi.
Facoltativamente, immettere la descrizione per identificare il modello. Un uso comune della descrizione consiste nel registrare i nomi dei dati usati per creare il modello.
Selezionare Avanti.
Esaminare le impostazioni e selezionare la casella per accettare le condizioni per l'utilizzo.
Selezionare Invia per avviare il training del modello.
Formazione bilingue
Se si seleziona il tipo di training Neurale, è possibile eseguire il training di una voce per parlare in più lingue. Le zh-CNimpostazioni locali , zh-HKe zh-TW supportano la formazione bilingue per la voce per parlare sia cinese che inglese. A seconda dei dati di training, la voce sintetizzata può parlare inglese con un accento nativo inglese o inglese con lo stesso accento dei dati di training.
Nota
Per consentire a una voce nelle impostazioni locali di zh-CN di parlare inglese con lo stesso accento dei dati di esempio, è necessario scegliere Chinese (Mandarin, Simplified), English bilingual durante la creazione di un progetto o specificare le impostazioni locali di zh-CN (English bilingual) per i dati del set di training tramite l'API REST.
La tabella seguente illustra le differenze tra le impostazioni locali:
| Impostazioni locali di Speech Studio | Impostazioni locali dell'API REST | Supporto bilingue |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Se i dati di esempio includono l'inglese, la voce sintetizzata parla inglese con un accento nativo inglese, anziché con lo stesso accento dei dati di esempio, indipendentemente dalla quantità di dati in inglese. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Se si vuole che la voce sintetizzata parli inglese con lo stesso accento dei dati di esempio, è consigliabile includere oltre il 10% dei dati in inglese nel set di training. In caso contrario, l'accento dell’inglese parlato potrebbe non essere ideale. |
Chinese (Cantonese, Simplified) |
zh-HK |
Se si vuole eseguire il training di una voce sintetizzata in grado di parlare inglese con lo stesso accento dei dati di esempio, assicurarsi di fornire più del 10% di dati in inglese nel set di training. In caso contrario, l'impostazione predefinita è un accento nativo inglese. La soglia del 10% viene calcolata in base ai dati accettati dopo il caricamento, non ai dati prima del caricamento. Se alcuni dati in inglese caricati vengono rifiutati a causa di difetti e non soddisfano la soglia del 10%, la voce sintetizzata per impostazione predefinita è un accento nativo inglese. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Se si vuole eseguire il training di una voce sintetizzata in grado di parlare inglese con lo stesso accento dei dati di esempio, assicurarsi di fornire più del 10% di dati in inglese nel set di training. In caso contrario, l'impostazione predefinita è un accento nativo inglese. La soglia del 10% viene calcolata in base ai dati accettati dopo il caricamento, non ai dati prima del caricamento. Se alcuni dati in inglese caricati vengono rifiutati a causa di difetti e non soddisfano la soglia del 10%, la voce sintetizzata per impostazione predefinita è un accento nativo inglese. |
Stili predefiniti disponibili in lingue diverse
La tabella seguente riepiloga i diversi stili predefiniti in base a lingue diverse.
| Modo di parlare | Lingua (impostazioni locali) |
|---|---|
| arrabbiato | Inglese (Stati Uniti) (en-US)Giapponese (Giappone) ( ja-JP) 1Cinese (mandarino, semplificato) ( zh-CN) 1 |
| calmo | Cinese (mandarino, semplificato) (zh-CN) 1 |
| chat | Cinese (mandarino, semplificato) (zh-CN) 1 |
| allegro | Inglese (Stati Uniti) (en-US)Giapponese (Giappone) ( ja-JP) 1Cinese (mandarino, semplificato) ( zh-CN) 1 |
| scontento | Cinese (mandarino, semplificato) (zh-CN) 1 |
| eccitato | Inglese (Stati Uniti) (en-US) |
| impaurito | Cinese (mandarino, semplificato) (zh-CN) 1 |
| gentile | Inglese (Stati Uniti) (en-US) |
| speranzoso | Inglese (Stati Uniti) (en-US) |
| triste | Inglese (Stati Uniti) (en-US)Giapponese (Giappone) ( ja-JP) 1Cinese (mandarino, semplificato) ( zh-CN) 1 |
| gridando | Inglese (Stati Uniti) (en-US) |
| serio | Cinese (mandarino, semplificato) (zh-CN) 1 |
| terrorizzato | Inglese (Stati Uniti) (en-US) |
| scortese | Inglese (Stati Uniti) (en-US) |
| sussurrando | Inglese (Stati Uniti) (en-US) |
1 Lo stile della voce neurale è disponibile in anteprima pubblica. Gli stili in anteprima pubblica sono disponibili solo in queste aree di servizio: Stati Uniti orientali, Europa occidentale e Asia sud-orientale.
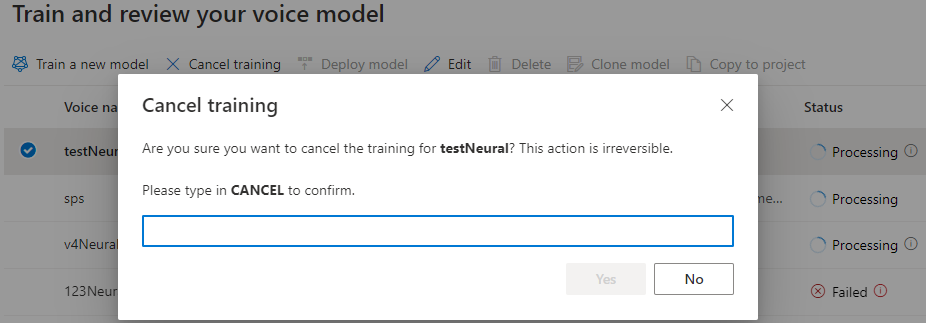
Nella tabella Esegui training del modello viene visualizzata una nuova voce corrispondente a questo modello appena creato. Lo stato riflette il processo di conversione dei dati in un modello vocale, come descritto in questa tabella:
| State | Significato |
|---|---|
| in lavorazione | Viene creato il modello vocale. |
| Completato | Il modello vocale è stato creato e può essere distribuito. |
| Non riuscito | Il modello vocale non è riuscito nel training. La causa dell'errore potrebbe essere, ad esempio, problemi di dati non visualizzati o problemi di rete. |
| Annullati | Il training per il modello vocale è stato annullato. |
Mentre lo stato del modello è In elaborazione, è possibile selezionare Annulla training per annullare il modello vocale. Non viene addebitato alcun costo per questo training annullato.
Dopo aver completato correttamente il training del modello, è possibile esaminare i dettagli del modello e Testare il modello vocale.
È possibile usare lo strumento Creazione contenuto audio in Speech Studio per creare audio e ottimizzare la voce distribuita. Se applicabile per la voce, è possibile selezionare uno di più stili.
Rinominare il modello
Per rinominare il modello compilato, selezionare Clona modello per creare un clone del modello con un nuovo nome nel progetto corrente.
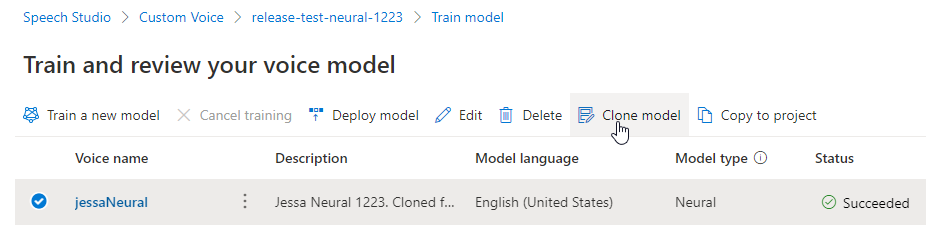
Immettere il nuovo nome nella finestra Clonare il modello vocale e quindi selezionare Invia. Il testo Neurale verrà aggiunto automaticamente come suffisso al nuovo nome del modello.
Testare il modello vocale
Dopo aver compilato correttamente il modello vocale, è possibile usare i file audio di esempio generati per testarlo prima di distribuirlo.
La qualità della voce dipende da molti fattori, ad esempio:
- Dimensioni dei dati di training.
- Qualità della registrazione.
- Accuratezza del file di trascrizione.
- La voce registrata nei dati di training corrisponde alla personalità della voce progettata per il caso d'uso previsto.
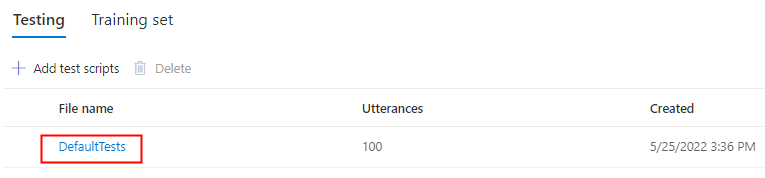
Selezionare DefaultTests in Test per ascoltare i file audio di esempio. Gli esempi di test predefiniti includono 100 file audio di esempio generati automaticamente durante il training per testare il modello. Oltre a questi 100 file audio forniti per impostazione predefinita, anche le espressioni dello script di test vengono aggiunte al set di DefaultTests. Questa aggiunta è al massimo di 100 espressioni. Non vengono addebitati costi per il test con DefaultTests.
Per caricare script di test personalizzati per testare ulteriormente il modello, selezionare Aggiungi script di test per caricare uno script di test personalizzato.
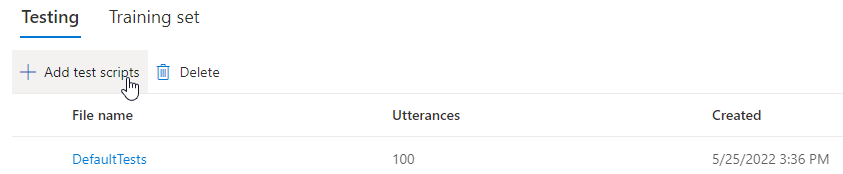
Prima di caricare lo script di test, controllare i requisiti dello script di test. Vengono addebitati i costi per i test aggiuntivi con la sintesi batch in base al numero di caratteri fatturabili. Vedere Prezzi di Riconoscimento vocale di Azure per intelligenza artificiale.
In Aggiungi script di test selezionare Cerca un file per selezionare uno script personalizzato e quindi selezionare Aggiungi per caricarlo.
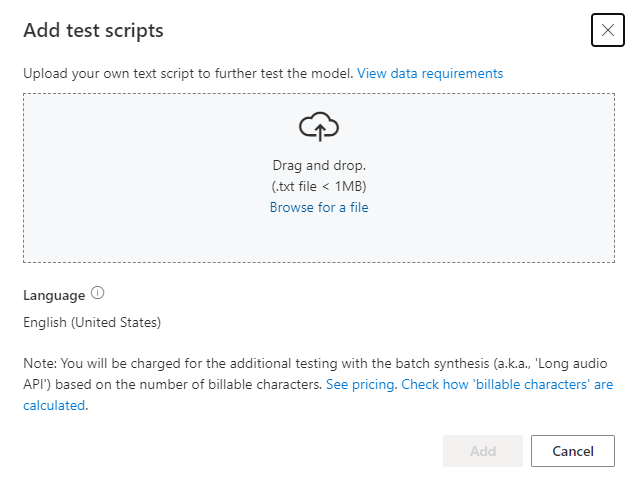
Requisiti dello script di test
Lo script di test deve essere un file di .txt minore di 1 MB. I formati di codifica supportati includono ANSI/ASCII, UTF-8, UTF-8-BOM, UTF-16-LE o UTF-16-BE.
A differenza dei file di trascrizione di training, lo script di test deve escludere l'ID dell'espressione, ovvero il nome file di ogni espressione. In caso contrario, questi ID vengono pronunciati.
Di seguito è riportato un esempio di set di espressioni in un unico file .txt:
This is the waistline, and it's falling.
We have trouble scoring.
It was Janet Maslin.
Ogni paragrafo dell'espressione restituisce un audio separato. Se si vuole combinare tutte le frasi in un unico audio, inserirle in un solo paragrafo.
Nota
I file audio generati sono una combinazione degli script di test automatici e degli script di test personalizzati.
Aggiornare la versione del motore per il modello vocale
I motori di sintesi vocale di Azure vengono aggiornati di tanto in tanto per acquisire il modello linguistico più recente che definisce la pronuncia della lingua. Dopo aver eseguito il training della voce, è possibile applicare la voce al nuovo modello linguistico eseguendo l'aggiornamento alla versione più recente del motore.
Quando è disponibile un nuovo motore, viene richiesto di aggiornare il modello di voce neurale.

Passare alla pagina dei dettagli del modello e seguire le istruzioni visualizzate per installare il motore più recente.
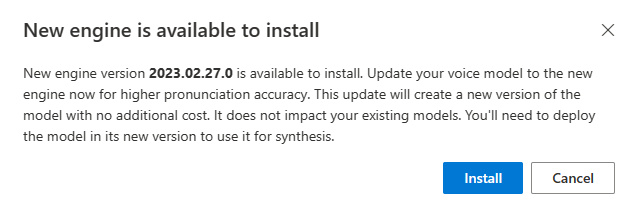
In alternativa, selezionare Installa il motore più recente in un secondo momento per aggiornare il modello alla versione più recente del motore.
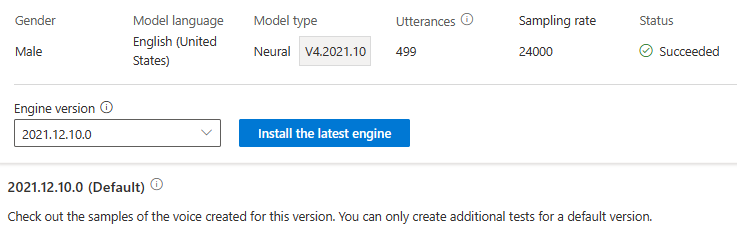
Non vengono addebitati costi per l'aggiornamento del motore. Le versioni precedenti vengono ancora mantenute.
È possibile controllare tutte le versioni del motore per il modello dall'elenco Versione motore oppure rimuoverlo se non è più necessario.
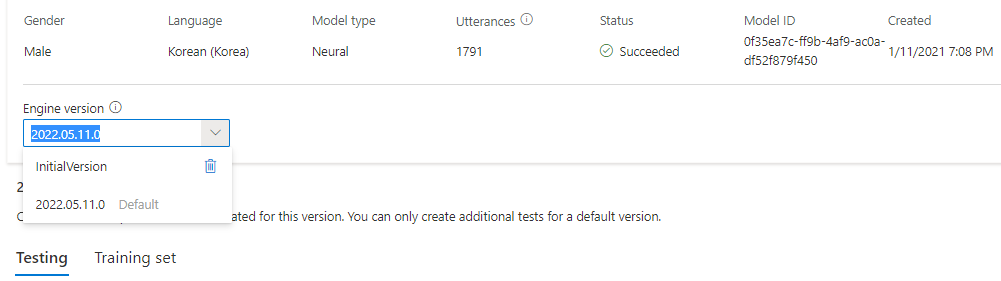
La versione aggiornata viene impostata automaticamente come predefinita. È tuttavia possibile modificare la versione predefinita selezionando una versione dall'elenco a discesa e selezionando Imposta come predefinito.
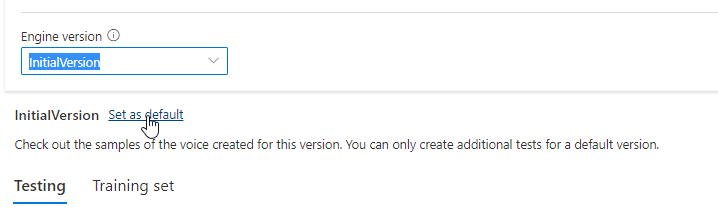

Se si vuole testare ogni versione del motore del modello vocale, è possibile selezionare una versione dall'elenco, quindi selezionare DefaultTests in Test per ascoltare i file audio di esempio. Se si vogliono caricare script di test personalizzati per testare ulteriormente la versione corrente del motore, assicurarsi prima di tutto che la versione sia impostata come predefinita, quindi seguire i passaggi descritti in Testare il modello vocale.
L'aggiornamento del motore crea una nuova versione del modello senza costi aggiuntivi. Dopo aver aggiornato la versione del motore per il modello vocale, è necessario distribuire la nuova versione per creare un nuovo endpoint. È possibile distribuire solo la versione predefinita.
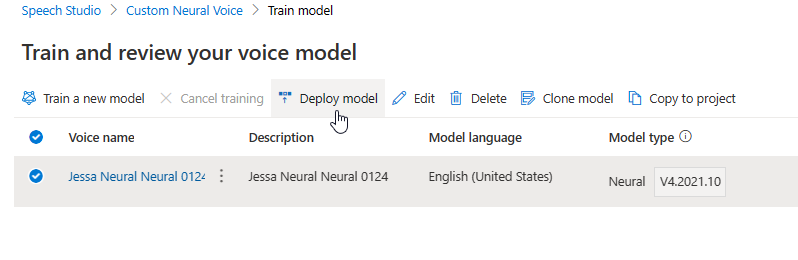
Dopo aver creato un nuovo endpoint, è necessario trasferire il traffico al nuovo endpoint nel prodotto.
Per altre informazioni sulle funzionalità e sui limiti di questa funzionalità e sulla procedura consigliata per migliorare la qualità del modello, vedere Caratteristiche e limitazioni per l'uso di voce neurale personalizzata.
Copiare il modello vocale in un altro progetto
È possibile copiare il modello vocale in un altro progetto per la stessa area o un'altra area. Ad esempio, è possibile copiare un modello di voce neurale sottoposto a training in un'area, in un progetto per un'altra area.
Nota
Il training di Sintesi vocale neurale è attualmente disponibile solo in alcune aree. È possibile copiare un modello vocale neurale da tali aree ad altre aree. Per altre informazioni, vedere le aree per la voce neurale personalizzata.
Per copiare il modello di voce neurale personalizzato in un altro progetto:
Nella scheda Esegui training modello selezionare un modello vocale da copiare e quindi selezionare Copia nel progetto.
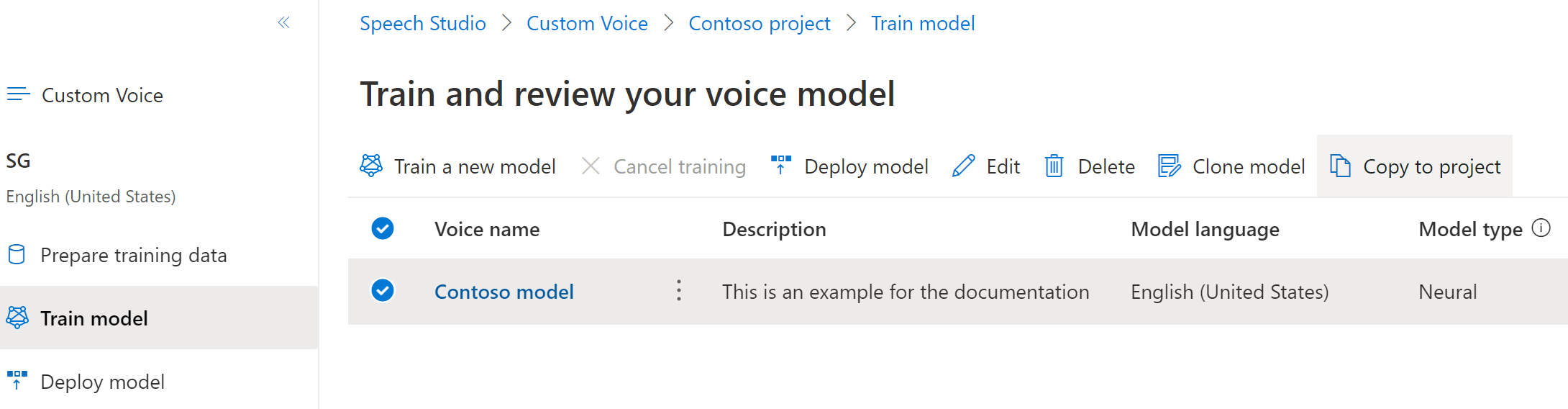
Selezionare Sottoscrizione, Area, risorsa Voce e Progetto in cui si vuole copiare il modello. È necessario disporre di una risorsa di riconoscimento vocale e di un progetto nell'area di destinazione. In caso contrario, è prima necessario crearli.
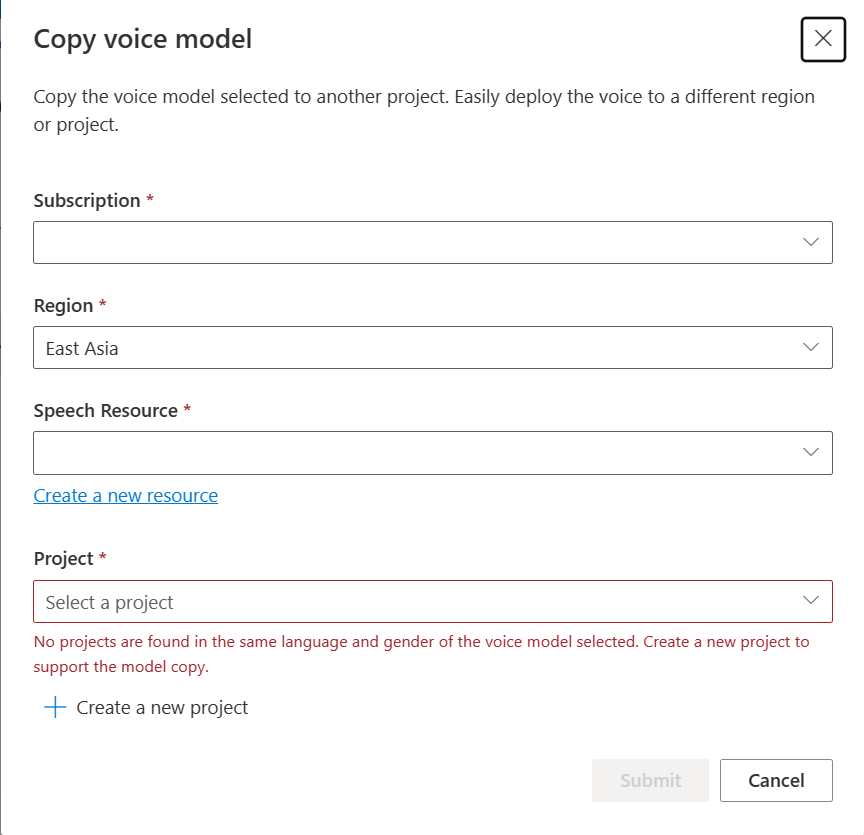
Selezionare Invia per copiare il modello.
Selezionare Visualizza modello nel messaggio di notifica per la corretta copia.
Passare al progetto in cui è stato copiato il modello per distribuire la copia del modello.
Passaggi successivi
Questo articolo illustra come eseguire il training di una voce neurale personalizzata tramite l'API vocale personalizzata.
Importante
Il training di Sintesi vocale neurale è attualmente disponibile solo in alcune aree. Dopo aver eseguito il training del modello vocale in un'area supportata, è possibile copiarlo in una risorsa Voce in un'altra area in base alle esigenze. Per altre informazioni, vedere le note a piè di pagina nella tabella del servizio Voce.
La durata del training varia a seconda della quantità di dati usata. In media sono necessarie circa 40 ore di calcolo per eseguire il training di una voce neurale personalizzata. Gli utenti con una sottoscrizione standard (S0) possono eseguire il training di quattro voci contemporaneamente. Se si raggiunge il limite, attendere che venga completato il training di almeno un modello di voce, quindi riprovare.
Nota
Anche se il numero totale di ore richieste per metodo di training varia, lo stesso prezzo unitario si applica a ognuno di essi. Per altre informazioni, vedere i dettagli sui prezzi del training neurale personalizzato.
Scegliere un metodo di training
Dopo aver convalidato i file di dati, usarli per creare il modello vocale neurale personalizzato. Quando si crea una voce neurale personalizzata, è possibile scegliere di eseguirne il training con uno dei metodi seguenti:
Neurale: creare una voce nella stessa lingua dei dati di training.
Neurale - multilingue: creare una voce che parla una lingua diversa dai dati di training. Ad esempio, con i dati di training
fr-FR, è possibile creare una voce che parlaen-US.La lingua dei dati di training e la lingua di destinazione devono essere entrambe una delle lingue supportate per il training vocale multilingue. Non è necessario preparare i dati di training nel linguaggio di destinazione, ma lo script di test deve trovarsi nella lingua di destinazione.
Neural - multi stile: creare una voce neurale personalizzata che parla in più stili ed emozioni, senza aggiungere nuovi dati di training. Più voci di stile sono utili per i personaggi di videogiochi, chatbot conversazionali, audiobook, lettori di contenuti e altro ancora.
Per creare una voce con più stili, è necessario preparare un set di dati di training generali, almeno 300 espressioni. Selezionare uno o più stili di destinazione predefiniti. È anche possibile creare più stili personalizzati fornendo esempi di stile, di almeno 100 espressioni per stile, come dati di training aggiuntivi per la stessa voce. Gli stili predefiniti supportati variano in base a lingue diverse. Vedere gli stili predefiniti disponibili nelle varie lingue.
Il linguaggio dei dati di training deve essere uno dei linguaggi supportati per la voce neurale personalizzata, il linguaggio multilingue o il training di più stili.
Creare un modello vocale
Per creare una voce neurale, usare l'operazione Models_Create dell'API vocale personalizzata. Creare il corpo della richiesta in base alle istruzioni seguenti:
- Impostare la proprietà
projectIdobbligatoria. Vedere creare un progetto. - Impostare la proprietà
consentIdobbligatoria. Vedere Aggiungere il consenso per i talenti vocali. - Impostare la proprietà
trainingSetIdobbligatoria. Vedere Creare un set di training. - Impostare la proprietà
kinddella ricetta richiesta suDefaultper il training vocale neurale. Il tipo di ricetta indica il metodo di training e non può essere modificato in un secondo momento. Per usare un metodo di training diverso, vedere Neurale - multilingue o Neural - multi stile. Per altre informazioni sulla formazione bilingue e sulle differenze tra le impostazioni locali, vedere Formazione bilingue. - Impostare la proprietà
voiceNameobbligatoria. Il nome della voce deve terminare con "Neurale" e non può essere modificato in un secondo momento. Scegliere un nome con attenzione. Il nome vocale viene usato nella richiesta di sintesi vocale dall'SDK e dall'input SSML. Sono consentiti solo lettere, numeri e alcuni caratteri di punteggiatura. Usare nomi diversi per modelli vocali neurali diversi. - Facoltativamente, impostare la proprietà
descriptionper la descrizione vocale. La descrizione vocale può essere modificata in un secondo momento.
Effettuare una richiesta HTTP PUT usando l'URI come illustrato nell'esempio Models_Create seguente.
- Sostituire
YourResourceKeycon la chiave della risorsa Voce. - Sostituire
YourResourceRegioncon l'area della risorsa Voce. - Sostituire
JessicaModelIdcon un ID modello di propria scelta. L'ID con distinzione tra maiuscole e minuscole verrà usato nell'URI del modello e non potrà essere modificato in un secondo momento.
curl -v -X PUT -H "Ocp-Apim-Subscription-Key: YourResourceKey" -H "Content-Type: application/json" -d '{
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId"
} ' "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview"
Si dovrebbe ricevere un corpo della risposta nel formato seguente:
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "NotStarted",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Formazione bilingue
Se si seleziona il tipo di training Neurale, è possibile eseguire il training di una voce per parlare in più lingue. Le zh-CNimpostazioni locali , zh-HKe zh-TW supportano la formazione bilingue per la voce per parlare sia cinese che inglese. A seconda dei dati di training, la voce sintetizzata può parlare inglese con un accento nativo inglese o inglese con lo stesso accento dei dati di training.
Nota
Per consentire a una voce nelle impostazioni locali di zh-CN di parlare inglese con lo stesso accento dei dati di esempio, è necessario scegliere Chinese (Mandarin, Simplified), English bilingual durante la creazione di un progetto o specificare le impostazioni locali di zh-CN (English bilingual) per i dati del set di training tramite l'API REST.
La tabella seguente illustra le differenze tra le impostazioni locali:
| Impostazioni locali di Speech Studio | Impostazioni locali dell'API REST | Supporto bilingue |
|---|---|---|
Chinese (Mandarin, Simplified) |
zh-CN |
Se i dati di esempio includono l'inglese, la voce sintetizzata parla inglese con un accento nativo inglese, anziché con lo stesso accento dei dati di esempio, indipendentemente dalla quantità di dati in inglese. |
Chinese (Mandarin, Simplified), English bilingual |
zh-CN (English bilingual) |
Se si vuole che la voce sintetizzata parli inglese con lo stesso accento dei dati di esempio, è consigliabile includere oltre il 10% dei dati in inglese nel set di training. In caso contrario, l'accento dell’inglese parlato potrebbe non essere ideale. |
Chinese (Cantonese, Simplified) |
zh-HK |
Se si vuole eseguire il training di una voce sintetizzata in grado di parlare inglese con lo stesso accento dei dati di esempio, assicurarsi di fornire più del 10% di dati in inglese nel set di training. In caso contrario, l'impostazione predefinita è un accento nativo inglese. La soglia del 10% viene calcolata in base ai dati accettati dopo il caricamento, non ai dati prima del caricamento. Se alcuni dati in inglese caricati vengono rifiutati a causa di difetti e non soddisfano la soglia del 10%, la voce sintetizzata per impostazione predefinita è un accento nativo inglese. |
Chinese (Taiwanese Mandarin, Traditional) |
zh-TW |
Se si vuole eseguire il training di una voce sintetizzata in grado di parlare inglese con lo stesso accento dei dati di esempio, assicurarsi di fornire più del 10% di dati in inglese nel set di training. In caso contrario, l'impostazione predefinita è un accento nativo inglese. La soglia del 10% viene calcolata in base ai dati accettati dopo il caricamento, non ai dati prima del caricamento. Se alcuni dati in inglese caricati vengono rifiutati a causa di difetti e non soddisfano la soglia del 10%, la voce sintetizzata per impostazione predefinita è un accento nativo inglese. |
Stili predefiniti disponibili in lingue diverse
La tabella seguente riepiloga i diversi stili predefiniti in base a lingue diverse.
| Modo di parlare | Lingua (impostazioni locali) |
|---|---|
| arrabbiato | Inglese (Stati Uniti) (en-US)Giapponese (Giappone) ( ja-JP) 1Cinese (mandarino, semplificato) ( zh-CN) 1 |
| calmo | Cinese (mandarino, semplificato) (zh-CN) 1 |
| chat | Cinese (mandarino, semplificato) (zh-CN) 1 |
| allegro | Inglese (Stati Uniti) (en-US)Giapponese (Giappone) ( ja-JP) 1Cinese (mandarino, semplificato) ( zh-CN) 1 |
| scontento | Cinese (mandarino, semplificato) (zh-CN) 1 |
| eccitato | Inglese (Stati Uniti) (en-US) |
| impaurito | Cinese (mandarino, semplificato) (zh-CN) 1 |
| gentile | Inglese (Stati Uniti) (en-US) |
| speranzoso | Inglese (Stati Uniti) (en-US) |
| triste | Inglese (Stati Uniti) (en-US)Giapponese (Giappone) ( ja-JP) 1Cinese (mandarino, semplificato) ( zh-CN) 1 |
| gridando | Inglese (Stati Uniti) (en-US) |
| serio | Cinese (mandarino, semplificato) (zh-CN) 1 |
| terrorizzato | Inglese (Stati Uniti) (en-US) |
| scortese | Inglese (Stati Uniti) (en-US) |
| sussurrando | Inglese (Stati Uniti) (en-US) |
1 Lo stile della voce neurale è disponibile in anteprima pubblica. Gli stili in anteprima pubblica sono disponibili solo in queste aree di servizio: Stati Uniti orientali, Europa occidentale e Asia sud-orientale.
Ottenere lo stato del training
Per ottenere lo stato del training di un modello vocale, usare l'operazione di Models_Get dell'API vocale personalizzata. Creare l’URI della richiesta in base alle istruzioni seguenti:
Effettuare una richiesta HTTP GET usando l'URI come illustrato nell'esempio di Models_Get seguente.
- Sostituire
YourResourceKeycon la chiave della risorsa Voce. - Sostituire
YourResourceRegioncon l'area della risorsa Voce. - Sostituire
JessicaModelIdse è stato specificato un ID modello diverso nel passaggio precedente.
curl -v -X GET "https://YourResourceRegion.api.cognitive.microsoft.com/customvoice/models/JessicaModelId?api-version=2024-02-01-preview" -H "Ocp-Apim-Subscription-Key: YourResourceKey"
Si dovrebbe ricevere un corpo della risposta nel formato seguente.
Nota
La ricetta kind e altre proprietà dipendono dalla modalità di training della voce. In questo esempio, il tipo di ricetta è Default per il training vocale neurale.
{
"id": "JessicaModelId",
"voiceName": "JessicaNeural",
"description": "Jessica voice",
"recipe": {
"kind": "Default",
"version": "V7.2023.03"
},
"projectId": "ProjectId",
"consentId": "JessicaConsentId",
"trainingSetId": "JessicaTrainingSetId",
"locale": "en-US",
"engineVersion": "2023.07.04.0",
"status": "Succeeded",
"createdDateTime": "2023-04-01T05:30:00.000Z",
"lastActionDateTime": "2023-04-02T10:15:30.000Z"
}
Potrebbe essere necessario attendere alcuni minuti prima del completamento del training. Alla fine lo stato cambierà in Succeeded o Failed.