Esercitazione: Parte 1: Creare un copilota basato su RAG con l'SDK del flusso di richiesta
In questa esercitazione di Azure AI Studio si usa l'SDK del flusso di richieste (e altre librerie) per compilare, configurare, valutare e distribuire un copilota per la società di vendita al dettaglio denominata Contoso Trek. La società di vendita al dettaglio è specializzata in attrezzatura da campeggio all'aperto e abbigliamento. Il copilota deve rispondere a domande sui prodotti e sui servizi. Ad esempio, il copilota può rispondere a domande come "quale tenda è la più impermeabile?" o "qual è il miglior sacco a pelo per il freddo?".
Questa esercitazione è la prima di un'esercitazione in due parti.
Suggerimento
Prima di iniziare questa esercitazione, assicurarsi di aver riservato il tempo necessario per completare i prerequisiti. Se non si conosce ancora Studio IA di Azure, potrebbe essere necessario definire tempo aggiuntivo per acquisire familiarità con la piattaforma.
Questa prima parte mostra come migliorare un'applicazione di chat di base aggiungendo la generazione aumentata di recupero (RAG) per definire risposte fondate nei dati personalizzati.
In questa parte si apprenderà come:
Prerequisiti
Importante
È necessario disporre delle autorizzazioni necessarie per aggiungere assegnazioni di ruolo nella sottoscrizione di Azure. La concessione delle autorizzazioni per assegnazione di ruolo è consentita solo dal Proprietario delle risorse di Azure specifiche. Potrebbe essere necessario chiedere al proprietario della sottoscrizione di Azure (che può coincidere con l'amministratore IT) di fornire assistenza per completare la sezione di assegnazione dell’accesso.
Per configurare l'ambiente, è necessario completare l'argomento di avvio rapido Creare un'app di chat personalizzata in Python usando l'SDK del flusso di richiesta.
Importante
Questa esercitazione si basa sul codice e sull'ambiente configurato nell'avvio rapido.
È necessaria una copia locale dei dati del prodotto. Il repository Azure-Samples/rag-data-openai-python-promptflow in GitHub contiene informazioni di esempio sul prodotto retail pertinenti per questo scenario di esercitazione. Scaricare i dati di un prodotto al dettaglio Contoso Trek di esempio in un file ZIP nel computer locale.
Struttura del codice dell'applicazione
Creare una cartella denominata rag-tutorial nel computer locale. Questa serie di esercitazioni illustra la creazione del contenuto di ogni file. Se si completa la serie di esercitazioni, la struttura di cartelle sarà simile alla seguente:
rag-tutorial/
│ .env
│ build_index.py
│ deploy.py
│ evaluate.py
│ eval_dataset.jsonl
| invoke-local.py
│
├───copilot_flow
│ └─── chat.prompty
| └─── copilot.py
| └─── Dockerfile
│ └─── flow.flex.yaml
│ └─── input_with_chat_history.json
│ └─── queryIntent.prompty
│ └─── requirements.txt
│
├───data
| └─── product-info/
| └─── [Your own data or sample data as described in the prerequisites.]
L'implementazione in questa esercitazione usa il flusso flessibile del flusso di richiesta, ovvero l'approccio code-first per l'implementazione dei flussi. Specificare una funzione di immissione (che verrà definita in copilot.py) e quindi usare le funzionalità di test, valutazione e traccia del flusso di richiesta per il flusso. Questo flusso si trova nel codice e non ha un DAG (Directed Acyclic Graph) o un altro componente visivo. Altre informazioni su come sviluppare un flusso flessibile nella documentazione del flusso di prompt su GitHub.
Impostare le variabili di ambiente iniziali
È disponibile una raccolta di variabili di ambiente usate nei diversi frammenti di codice. Ora li impostiamo.
È stato creato un file .env con le variabili di ambiente seguenti tramite l'argomento di avvio rapido Creare un'app di chat personalizzata in Python usando l'SDK del flusso di prompt. Se non è già stato fatto, creare un file .env nella cartella rag-tutorial con le variabili di ambiente seguenti:
AZURE_OPENAI_ENDPOINT=endpoint_value AZURE_OPENAI_DEPLOYMENT_NAME=chat_model_deployment_name AZURE_OPENAI_API_VERSION=api_versionCopiare il file .env nella cartella rag-tutorial.
Nel file .env immettere altre variabili di ambiente per l'applicazione copilot:
- AZURE_SUBSCRIPTION_ID: ID sottoscrizione di Azure
- AZURE_RESOURCE_GROUP: gruppo di risorse di Azure
- AZUREAI_PROJECT_NAME: nome del progetto di Azure AI Studio
- AZURE_OPENAI_CONNECTION_NAME: usare la stessa connessione AIServices o OpenAI di Azure usata per distribuire il modello di chat.
È possibile trovare l'ID sottoscrizione, il nome del gruppo di risorse e il nome del progetto dalla visualizzazione del progetto in AI Studio.
- In Studio AI, passare al progetto e selezionare Impostazioni nel riquadro sinistro.
- Nella sezione Dettagli progetto è possibile trovare l'ID sottoscrizione e gruppo di risorse.
- Nella sezione Impostazioni progetto è possibile trovare il nome del progetto.
A questo momento, nel file .env dovrebbero essere presenti le variabili di ambiente seguenti:
AZURE_OPENAI_ENDPOINT=endpoint_value
AZURE_OPENAI_DEPLOYMENT_NAME=chat_model_deployment_name
AZURE_OPENAI_API_VERSION=api_version
AZURE_SUBSCRIPTION_ID=<your subscription id>
AZURE_RESOURCE_GROUP=<your resource group>
AZUREAI_PROJECT_NAME=<your project name>
AZURE_OPENAI_CONNECTION_NAME=<your AIServices or Azure OpenAI connection name>
Distribuire un modello di incorporamento
Per la funzionalità Generazione aumentata di recupero (RAG), è necessario essere in grado di incorporare la query di ricerca appropriata per cercare l'indice di Azure AI Search creato.
Distribuire un modello di incorporamento OpenAI di Azure. Seguire la guida alla distribuzione dei modelli OpenAI di Azure e distribuire il modello text-embedding-ada-002. Usare la stessa connessione AIServices o Azure OpenAI usata per distribuire il modello di chat.
Aggiungere le variabili di ambiente del modello di incorporamento nel file .env. Per il valore AZURE_OPENAI_EMBEDDING_DEPLOYMENT immettere il nome del modello di incorporamento distribuito.
AZURE_OPENAI_EMBEDDING_DEPLOYMENT=embedding_model_deployment_name
Per altre informazioni sul modello di incorporamento, vedere la documentazione sugli incorporamenti in Servizio OpenAI di Azure.
Creare un indice di Azure AI Search
L'obiettivo di questa applicazione basata su RAG è quello di fondare le risposte del modello sui dati personalizzati. Si usa un indice di Ricerca intelligenza artificiale di Azure che archivia i dati vettorializzati dal modello di incorporamento. L'indice di ricerca viene utilizzato per recuperare i documenti pertinenti in base alla domanda dell'utente.
Per creare un indice di ricerca, è necessario un servizio di Ricerca intelligenza artificiale di Azure e una connessione.
Nota
La creazione di un servizio Azure AI Search e degli indici di ricerca successivi comportano costi associati. È possibile visualizzare informazioni dettagliate sui prezzi e sui piani tariffari per il servizio Ricerca intelligenza artificiale di Azure nella pagina di creazione per confermare i costi prima di creare la risorsa.
Creare un servizio di Azure AI Search
Se si ha già un servizio Ricerca intelligenza artificiale di Azure nella stessa posizione del progetto, è possibile passare alla sezione successiva.
In caso contrario, è possibile creare un servizio Ricerca intelligenza artificiale di Azure usando il portale di Azure o l'interfaccia della riga di comando di Azure (installata in precedenza per la guida introduttiva).
Importante
Usare la stessa posizione del progetto per il servizio Ricerca intelligenza artificiale di Azure. Trovare la posizione del progetto nella selezione del progetto in alto a destra di Azure AI Studio nella visualizzazione del progetto.
- Vai al portale di Azure.
- Creare un servizio ricerca di intelligenza artificiale di Azure nel portale di Azure.
- Selezionare il gruppo di risorse e i dettagli dell'istanza. In questa pagina sono disponibili informazioni dettagliate sui piani tariffari e sui piani tariffari.
- Continuare con la procedura guidata e selezionare Rivedi e assegna per creare la risorsa.
- Verificare i dettagli del servizio Ricerca intelligenza artificiale di Azure, incluso il costo stimato.
Creare una connessione ad Azure AI Search
Se nel progetto è già presente una connessione di Ricerca intelligenza artificiale di Azure, è possibile passare a configurare l'accesso per il servizio Ricerca intelligenza artificiale di Azure. Usare una connessione esistente solo se si trova nella stessa posizione del progetto.
In Azure AI Studio verificare la presenza di una risorsa connessa di ricerca di intelligenza artificiale di Azure.
- In Studio AI, passare al progetto e selezionare Impostazioni nel riquadro sinistro.
- Nella sezione Risorse connesse verificare se si dispone di una connessione di tipo Ricerca di intelligenza artificiale di Azure.
- Se si ha una connessione di Ricerca intelligenza artificiale di Azure, verificare che si trovi nella stessa posizione del progetto. In tal caso, è possibile passare direttamente a configurare l'accesso per il servizio Ricerca intelligenza artificiale di Azure.
- In caso contrario, selezionare Nuova connessione e quindi Ricerca di intelligenza artificiale di Azure.
- Trovare il servizio Ricerca intelligenza artificiale di Azure nelle opzioni e selezionare Aggiungi connessione.
- Continuare con la procedura guidata per creare la connessione. Per altre informazioni sull'aggiunta di connessioni, vedere questa guida pratica.
Configurare l'accesso per il servizio Ricerca intelligenza artificiale di Azure
È consigliabile usare Microsoft Entra ID invece di usare le chiavi API. Per usare questa autenticazione, è necessario impostare i controlli di accesso appropriati e assegnare i ruoli appropriati per il servizio Ricerca intelligenza artificiale di Azure.
Avviso
È possibile usare il controllo degli accessi in base al ruolo in locale perché è possibile eseguire az login più avanti in questa esercitazione. Tuttavia, quando si distribuisce l'app nella parte 2 dell'esercitazione, la distribuzione viene autenticata usando le chiavi API del servizio Ricerca intelligenza artificiale di Azure. Presto sarà disponibile il supporto per l'autenticazione di Microsoft Entra ID della distribuzione.
Per abilitare il controllo degli accessi in base al ruolo per il servizio Ricerca intelligenza artificiale di Azure, seguire questa procedura:
Nel servizio Ricerca intelligenza artificiale di Azure nel portale di Azure selezionare Impostazioni > Chiavi nel riquadro sinistro.
Selezionare Entrambi per assicurarsi che le chiavi API e il controllo degli accessi in base al ruolo siano entrambi abilitati per il servizio Ricerca intelligenza artificiale di Azure.
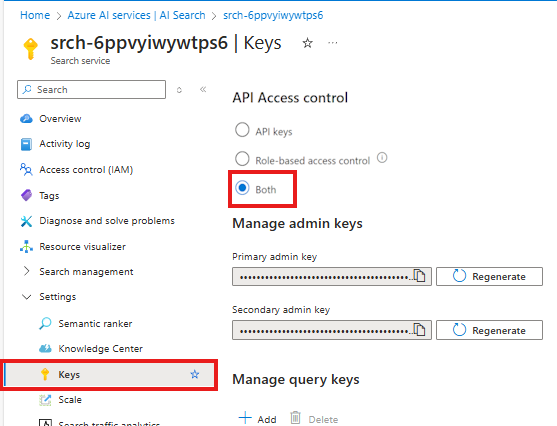
L'utente o l'amministratore deve concedere all'utente l'identità dei ruoli Collaboratore ai dati dell'indice di ricerca e Collaboratore del servizio di ricerca nel servizio Ricerca intelligenza artificiale di Azure. Questi ruoli consentono di chiamare il servizio Ricerca di intelligenza artificiale di Azure usando l'identità utente.
Nota
Questi passaggi sono simili al modo in cui è stato assegnato un ruolo per l'identità utente per l'uso del servizio Azure OpenAI nell'argomento di avvio rapido.
Nel portale di Azure seguire questa procedura per assegnare il ruolo Collaboratore ai dati dell'indice di ricerca al servizio Ricerca intelligenza artificiale di Azure:
- Selezionare il servizio Ricerca intelligenza artificiale di Azure nel portale di Azure.
- Nella pagina sinistra del portale di Azure, selezionare Controllo di accesso (IAM)> e >Aggiungi assegnazione di ruolo.
- Cercare il ruolo Collaboratore dati indice di ricerca e quindi selezionarlo. Quindi seleziona Avanti.
- Selezionare Utente, gruppo o entità servizio. Quindi scegliere Seleziona membri.
- Si apre il riquadro Seleziona membri. Qui cercare il nome dell'utente per cui si vuole aggiungere l'assegnazione di ruolo. Selezionare l'utente, quindi Seleziona.
- Continuare la procedura guidata e selezionare Rivedi e assegna per aggiungere l'assegnazione di ruolo.
Ripetere i passaggi precedenti per aggiungere il ruolo Collaboratore servizio di ricerca.
Importante
Dopo aver assegnato questi ruoli, eseguire az login nella console per assicurarsi che le modifiche vengano propagate nell'ambiente di sviluppo. In questo modo è anche possibile usare l'identità utente in locale per eseguire l'autenticazione con il servizio Ricerca di intelligenza artificiale di Azure.
Impostare le variabili di ambiente di ricerca
È necessario impostare le variabili di ambiente per il servizio Ricerca di intelligenza artificiale di Azure e la connessione nel file .env.
In Studio AI, passare al progetto e selezionare Impostazioni nel riquadro sinistro.
Nella sezione Risorse connesse selezionare il collegamento per il servizio Ricerca intelligenza artificiale di Azure creato in precedenza.
Copiare l'URL di destinazione per
<your Azure Search endpoint>.Copiare il nome nella parte superiore per
<your Azure Search connection name>.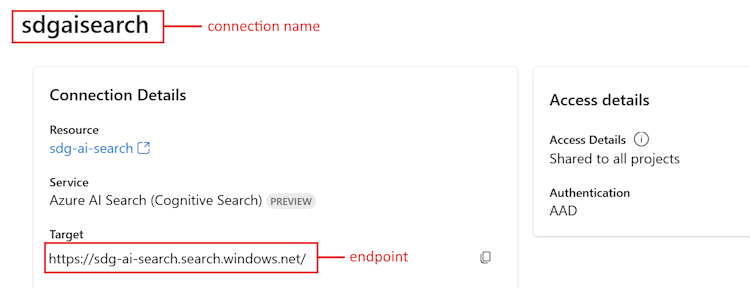
Aggiungere queste variabili di ambiente al file .env:
AZURE_SEARCH_ENDPOINT=<your Azure Search endpoint> AZURE_SEARCH_CONNECTION_NAME=<your Azure Search connection name>
Creare l'indice di ricerca
Se non è già stato creato un indice di Ricerca intelligenza artificiale di Azure, viene illustrato come crearne uno. Se si dispone già di un indice da usare, è possibile passare alla sezione impostare le variabili di ambiente di ricerca. L'indice di ricerca viene creato nel servizio Ricerca intelligenza artificiale di Azure creato o a cui si fa riferimento nel passaggio precedente.
Usare i propri dati o scaricare l'esempio Contoso Trek retail product data in un file ZIP nel computer locale. Decomprimere il file nella cartella rag-tutorial. Questi dati sono una raccolta di file markdown che rappresentano le informazioni sul prodotto. I dati sono strutturati in modo semplice da inserire in un indice di ricerca. Si compila un indice di ricerca da questi dati.
Il pacchetto RAG del flusso di prompt consente di inserire i file markdown, creare localmente un indice di ricerca e registrarlo nel progetto cloud. Installare il pacchetto RAG del flusso di richiesta:
pip install promptflow-ragAggiornare il pacchetto azure-ai-ml alla versione più recente. Eseguire il comando seguente nel terminale:
pip install azure-ai-ml -UCreare il file build_index.py nella cartella rag-tutorial.
Copiare e incollare il codice seguente nel file build_index.py.
import os from dotenv import load_dotenv load_dotenv() from azure.ai.ml import MLClient from azure.identity import DefaultAzureCredential from azure.ai.ml.entities import Index from promptflow.rag.config import ( LocalSource, AzureAISearchConfig, EmbeddingsModelConfig, ConnectionConfig, ) from promptflow.rag import build_index client = MLClient( DefaultAzureCredential(), os.getenv("AZURE_SUBSCRIPTION_ID"), os.getenv("AZURE_RESOURCE_GROUP"), os.getenv("AZUREAI_PROJECT_NAME"), ) import os # append directory of the current script to data directory script_dir = os.path.dirname(os.path.abspath(__file__)) data_directory = os.path.join(script_dir, "data/product-info/") # Check if the directory exists if os.path.exists(data_directory): files = os.listdir(data_directory) # List all files in the directory if files: print( f"Data directory '{data_directory}' exists and contains {len(files)} files." ) else: print(f"Data directory '{data_directory}' exists but is empty.") exit() else: print(f"Data directory '{data_directory}' does not exist.") exit() index_name = "tutorial-index" # your desired index name index_path = build_index( name=index_name, # name of your index vector_store="azure_ai_search", # the type of vector store - in this case it is Azure AI Search. Users can also use "azure_cognitive search" embeddings_model_config=EmbeddingsModelConfig( model_name=os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT"), deployment_name=os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT"), connection_config=ConnectionConfig( subscription_id=client.subscription_id, resource_group_name=client.resource_group_name, workspace_name=client.workspace_name, connection_name=os.getenv("AZURE_OPENAI_CONNECTION_NAME"), ), ), input_source=LocalSource(input_data=data_directory), # the location of your files index_config=AzureAISearchConfig( ai_search_index_name=index_name, # the name of the index store inside the azure ai search service ai_search_connection_config=ConnectionConfig( subscription_id=client.subscription_id, resource_group_name=client.resource_group_name, workspace_name=client.workspace_name, connection_name=os.getenv("AZURE_SEARCH_CONNECTION_NAME"), ), ), tokens_per_chunk=800, # Optional field - Maximum number of tokens per chunk token_overlap_across_chunks=0, # Optional field - Number of tokens to overlap between chunks ) # register the index so that it shows up in the cloud project client.indexes.create_or_update(Index(name=index_name, path=index_path))- Impostare la variabile
index_namesul nome dell'indice desiderato. - Se necessario, è possibile aggiornare la variabile
path_to_dataal percorso in cui sono archiviati i file di dati.
Importante
Per impostazione predefinita, l'esempio di codice prevede la struttura del codice dell'applicazione come descritto in precedenza in questa esercitazione. La cartella
datadeve essere allo stesso livello del build_index.py e la cartellaproduct-infoscaricata con i file md al suo interno.- Impostare la variabile
Dalla console eseguire il codice per compilare l'indice in locale e registrarlo nel progetto cloud:
python build_index.pyDopo l'esecuzione dello script, è possibile visualizzare l'indice appena creato nella pagina Indici del progetto di Azure AI Studio. Per altre informazioni, vedere Come compilare e usare indici vettoriali in Azure AI Studio.
Se si esegue di nuovo lo script con lo stesso nome di indice, viene creata una nuova versione dello stesso indice.
Impostare la variabile di ambiente dell'indice di ricerca
Dopo aver ottenuto il nome dell'indice da usare (creandone uno nuovo o facendo riferimento a uno esistente), aggiungerlo al file .env, come illustrato di seguito:
AZUREAI_SEARCH_INDEX_NAME=<index-name>
Sviluppare codice RAG personalizzato
Successivamente si crea codice personalizzato per aggiungere funzionalità di generazione aumentata di recupero (RAG) a un'applicazione di chat di base. Nella guida introduttiva sono stati creati file chat.py e chat.prompty. Qui si espande il codice per includere le funzionalità RAG.
Il copilota con RAG implementa la logica generale seguente:
- Generare una query di ricerca in base alla finalità della query utente e a qualsiasi cronologia delle chat
- Usare un modello di incorporamento per incorporare la query
- Recuperare i documenti pertinenti dall'indice di ricerca, data la query
- Passare il contesto pertinente al modello di completamento della chat OpenAI di Azure
- Restituire la risposta dal modello OpenAI di Azure
Logica di implementazione di Copilot
La logica di implementazione di copilot si trova nel file copilot.py. Questo file contiene la logica di base per il copilot basato su RAG.
Creare una cartella denominata copilot_flow nella cartella rag-tutorial.
Creare quindi un file denominato copilot.py nella cartella copilot_flow.
Aggiungere il codice seguente al file copilot.py:
import os from dotenv import load_dotenv load_dotenv() from promptflow.core import Prompty, AzureOpenAIModelConfiguration from promptflow.tracing import trace from openai import AzureOpenAI # <get_documents> @trace def get_documents(search_query: str, num_docs=3): from azure.identity import DefaultAzureCredential, get_bearer_token_provider from azure.search.documents import SearchClient from azure.search.documents.models import VectorizedQuery token_provider = get_bearer_token_provider( DefaultAzureCredential(), "https://cognitiveservices.azure.com/.default" ) index_name = os.getenv("AZUREAI_SEARCH_INDEX_NAME") # retrieve documents relevant to the user's question from Cognitive Search search_client = SearchClient( endpoint=os.getenv("AZURE_SEARCH_ENDPOINT"), credential=DefaultAzureCredential(), index_name=index_name, ) aoai_client = AzureOpenAI( azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), azure_ad_token_provider=token_provider, api_version=os.getenv("AZURE_OPENAI_API_VERSION"), ) # generate a vector embedding of the user's question embedding = aoai_client.embeddings.create( input=search_query, model=os.getenv("AZURE_OPENAI_EMBEDDING_DEPLOYMENT") ) embedding_to_query = embedding.data[0].embedding context = "" # use the vector embedding to do a vector search on the index vector_query = VectorizedQuery( vector=embedding_to_query, k_nearest_neighbors=num_docs, fields="contentVector" ) results = trace(search_client.search)( search_text="", vector_queries=[vector_query], select=["id", "content"] ) for result in results: context += f"\n>>> From: {result['id']}\n{result['content']}" return context # <get_documents> from promptflow.core import Prompty, AzureOpenAIModelConfiguration from pathlib import Path from typing import TypedDict class ChatResponse(TypedDict): context: dict reply: str def get_chat_response(chat_input: str, chat_history: list = []) -> ChatResponse: model_config = AzureOpenAIModelConfiguration( azure_deployment=os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT"), api_version=os.getenv("AZURE_OPENAI_API_VERSION"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), ) searchQuery = chat_input # Only extract intent if there is chat_history if len(chat_history) > 0: # extract current query intent given chat_history path_to_prompty = f"{Path(__file__).parent.absolute().as_posix()}/queryIntent.prompty" # pass absolute file path to prompty intentPrompty = Prompty.load( path_to_prompty, model={ "configuration": model_config, "parameters": { "max_tokens": 256, }, }, ) searchQuery = intentPrompty(query=chat_input, chat_history=chat_history) # retrieve relevant documents and context given chat_history and current user query (chat_input) documents = get_documents(searchQuery, 3) # send query + document context to chat completion for a response path_to_prompty = f"{Path(__file__).parent.absolute().as_posix()}/chat.prompty" chatPrompty = Prompty.load( path_to_prompty, model={ "configuration": model_config, "parameters": {"max_tokens": 256, "temperature": 0.2}, }, ) result = chatPrompty( chat_history=chat_history, chat_input=chat_input, documents=documents ) return dict(reply=result, context=documents)
Il file copilot.py contiene due funzioni chiave: get_documents() e get_chat_response().
Si noti che queste due funzioni hanno l'elemento decorator @trace, che consente di visualizzare i log di traccia del flusso di richiesta di ogni input e output di ogni chiamata di funzione. @trace è un approccio alternativo ed esteso al modo in cui l'avvio rapido ha mostrato le funzionalità di traccia.
La funzione get_documents() è il nucleo della logica RAG.
- Accetta la query di ricerca e il numero di documenti da recuperare.
- Incorpora la query di ricerca usando un modello di incorporamento.
- Esegue una query sull'indice di Ricerca di Azure per recuperare i documenti rilevanti per la query.
- Restituisce il contesto dei documenti.
La funzione get_chat_response() viene compilata dalla logica precedente nel file chat.py:
- Accetta
chat_inpute qualsiasichat_history. - Costruisce la query di ricerca in base alla finalità
chat_inputechat_history. - Chiama
get_documents()per recuperare i documenti pertinenti. - Chiama il modello di completamento della chat con il contesto per ottenere una risposta a terra alla query.
- Restituisce la risposta e il contesto. È stato impostato un dizionario tipizzato come oggetto restituito per la funzione
get_chat_response(). È possibile scegliere il modo in cui il codice restituisce la risposta più adatta al caso d'uso.
La funzione get_chat_response() usa due file Prompty per effettuare le chiamate LLM (Large Language Model) necessarie, illustrate di seguito.
Modello di richiesta per la chat
Il file chat.prompty è semplice e simile a chat.prompty nella guida introduttiva. Il prompt di sistema viene aggiornato per riflettere il prodotto e i modelli di prompt includono il contesto del documento.
Aggiungere il file chat.prompty nella directory copilot_flow. Il file rappresenta la chiamata al modello di completamento della chat, con la richiesta di sistema, la cronologia delle chat e il contesto del documento forniti.
Aggiungere questo codice al file chat.prompty:
--- name: Chat Prompt description: A prompty that uses the chat API to respond to queries grounded in relevant documents model: api: chat configuration: type: azure_openai inputs: chat_input: type: string chat_history: type: list is_chat_history: true default: [] documents: type: object --- system: You are an AI assistant helping users with queries related to outdoor outdooor/camping gear and clothing. If the question is not related to outdoor/camping gear and clothing, just say 'Sorry, I only can answer queries related to outdoor/camping gear and clothing. So, how can I help?' Don't try to make up any answers. If the question is related to outdoor/camping gear and clothing but vague, ask for clarifying questions instead of referencing documents. If the question is general, for example it uses "it" or "they", ask the user to specify what product they are asking about. Use the following pieces of context to answer the questions about outdoor/camping gear and clothing as completely, correctly, and concisely as possible. Do not add documentation reference in the response. # Documents {{documents}} {% for item in chat_history %} {{item.role}} {{item.content}} {% endfor %} user: {{chat_input}}
Modello di richiesta per la cronologia delle chat
Poiché si implementa un'applicazione basata su RAG, è necessaria una logica aggiuntiva per recuperare i documenti pertinenti non solo per la query utente corrente, ma anche tenendo conto della cronologia delle chat. Senza questa logica aggiuntiva, la chiamata LLM tiene conto della cronologia delle chat. Ma non si recupererebbero i documenti corretti per tale contesto, quindi non si otterrebbe la risposta prevista.
Ad esempio, se l'utente pone la domanda "è impermeabile?", è necessario che il sistema esamini la cronologia delle chat per determinare quale parola si riferisce e includere tale contesto nella query di ricerca da incorporare. In questo modo, recuperiamo i documenti giusti per "esso" (forse la tenda di Alpine Explorer) e il suo "costo".
Invece di passare solo la query dell'utente da incorporare, è necessario generare una nuova query di ricerca che tenga conto di qualsiasi cronologia delle chat. Viene usata un'altra Prompty (ovvero un'altra chiamata LLM) con richieste specifiche per interpretare la finalità della query utente, data la cronologia delle chat, e costruire una query di ricerca con il contesto necessario.
Creare il file queryIntent.prompty nella cartella copilot_flow.
Immettere questo codice per dettagli specifici sul formato di richiesta e sugli esempi di pochi scatti.
--- name: Chat Prompt description: A prompty that extract users query intent based on the current_query and chat_history of the conversation model: api: chat configuration: type: azure_openai inputs: query: type: string chat_history: type: list is_chat_history: true default: [] --- system: - You are an AI assistant reading a current user query and chat_history. - Given the chat_history, and current user's query, infer the user's intent expressed in the current user query. - Once you infer the intent, respond with a search query that can be used to retrieve relevant documents for the current user's query based on the intent - Be specific in what the user is asking about, but disregard parts of the chat history that are not relevant to the user's intent. Example 1: With a chat_history like below: \``` chat_history: [ { "role": "user", "content": "are the trailwalker shoes waterproof?" }, { "role": "assistant", "content": "Yes, the TrailWalker Hiking Shoes are waterproof. They are designed with a durable and waterproof construction to withstand various terrains and weather conditions." } ] \``` User query: "how much do they cost?" Intent: "The user wants to know how much the Trailwalker Hiking Shoes cost." Search query: "price of Trailwalker Hiking Shoes" Example 2: With a chat_history like below: \``` chat_history: [ { "role": "user", "content": "are the trailwalker shoes waterproof?" }, { "role": "assistant", "content": "Yes, the TrailWalker Hiking Shoes are waterproof. They are designed with a durable and waterproof construction to withstand various terrains and weather conditions." }, { "role": "user", "content": "how much do they cost?" }, { "role": "assistant", "content": "The TrailWalker Hiking Shoes are priced at $110." }, { "role": "user", "content": "do you have waterproof tents?" }, { "role": "assistant", "content": "Yes, we have waterproof tents available. Can you please provide more information about the type or size of tent you are looking for?" }, { "role": "user", "content": "which is your most waterproof tent?" }, { "role": "assistant", "content": "Our most waterproof tent is the Alpine Explorer Tent. It is designed with a waterproof material and has a rainfly with a waterproof rating of 3000mm. This tent provides reliable protection against rain and moisture." } ] \``` User query: "how much does it cost?" Intent: "the user would like to know how much the Alpine Explorer Tent costs" Search query: "price of Alpine Explorer Tent" {% for item in chat_history %} {{item.role}} {{item.content}} {% endfor %} Current user query: {{query}} Search query:
Il semplice messaggio di sistema nel file queryIntent.prompty ottiene il minimo necessario per la soluzione RAG per lavorare con la cronologia delle chat.
Configurare i pacchetti necessari
Creare il file requirements.txt nella cartella copilot_flow. Aggiungere questo contenuto:
openai
azure-identity
azure-search-documents==11.4.0
promptflow[azure]==1.11.0
promptflow-tracing==1.11.0
promptflow-tools==1.4.0
promptflow-evals==0.3.0
jinja2
aiohttp
python-dotenv
Questi sono i pacchetti necessari per l'esecuzione del flusso in locale e in un ambiente distribuito.
Usare il flusso flessibile
Come accennato in precedenza, questa implementazione usa il flusso flessibile del flusso di richiesta, ovvero l'approccio code-first per l'implementazione dei flussi. Specificare una funzione di immissione (definita in copilot.py). Per altre informazioni, vedere Sviluppare un flusso flessibile.
Questo yaml specifica la funzione di immissione, ovvero la funzione get_chat_response definita in copilot.py. Specifica anche i requisiti necessari per l'esecuzione del flusso.
Creare il file flow.flex.yaml nella cartella copilot_flow. Aggiungere questo contenuto:
entry: copilot:get_chat_response
environment:
python_requirements_txt: requirements.txt
Usare il flusso di richiesta per testare il copilota
Usare la funzionalità di test del flusso di prompt per vedere come viene eseguito il copilota come previsto sugli input di esempio. Usando il file flow.flex.yaml, è possibile usare il flusso di richiesta per eseguire il test con gli input specificati.
Eseguire il flusso usando questo comando del flusso del prompt:
pf flow test --flow ./copilot_flow --inputs chat_input="how much do the Trailwalker shoes cost?"
In alternativa, è possibile eseguire il flusso in modo interattivo con il flag --ui.
pf flow test --flow ./copilot_flow --ui
Quando si usa --ui, l'esperienza di chat di esempio interattiva apre una finestra nel browser locale.
- La prima volta che si esegue con il flag
--ui, è necessario selezionare manualmente gli input e gli output della chat dalle opzioni. La prima volta che si crea questa sessione, selezionare le impostazioni di configurazione del campo input/output chat e quindi avviare la chat. - Alla successiva esecuzione con il flag
--ui, la sessione ricorderà le impostazioni.

Al termine della sessione interattiva, immettere CTRL+C nella finestra del terminale per arrestare il server.
Testare con la cronologia delle chat
In generale, il flusso di richiesta e Prompty supportano la cronologia delle chat. Se si esegue il test con il flag --ui nel front-end servito in locale, il flusso di richiesta gestisce la cronologia delle chat. Se si esegue il test senza --ui, è possibile specificare un file di input che include la cronologia delle chat.
Poiché l'applicazione implementa RAG, è necessario aggiungere logica aggiuntiva per gestire la cronologia delle chat nel file queryIntent.prompty.
Per testare la cronologia chat, creare un file denominato input_with_chat_history.json nella cartella copilot_flow e incollare il contenuto seguente:
{
"chat_input": "how much does it cost?",
"chat_history": [
{
"role": "user",
"content": "are the trailwalker shoes waterproof?"
},
{
"role": "assistant",
"content": "Yes, the TrailWalker Hiking Shoes are waterproof. They are designed with a durable and waterproof construction to withstand various terrains and weather conditions."
},
{
"role": "user",
"content": "how much do they cost?"
},
{
"role": "assistant",
"content": "The TrailWalker Hiking Shoes are priced at $110."
},
{
"role": "user",
"content": "do you have waterproof tents?"
},
{
"role": "assistant",
"content": "Yes, we have waterproof tents available. Can you please provide more information about the type or size of tent you are looking for?"
},
{
"role": "user",
"content": "which is your most waterproof tent?"
},
{
"role": "assistant",
"content": "Our most waterproof tent is the Alpine Explorer Tent. It is designed with a waterproof material and has a rainfly with a waterproof rating of 3000mm. This tent provides reliable protection against rain and moisture."
}
]
}
Per eseguire il test con questo file, eseguire:
pf flow test --flow ./copilot_flow --inputs ./copilot_flow/input_with_chat_history.json
L'output previsto è simile al seguente: "Alpine Explorer Tent è costato $ 350".
Questo sistema è in grado di interpretare l'intento della query "quanto costa?" per sapere che tale costo si riferisce alla Tenda Alpine Explorer, che è stato il contesto più recente nella cronologia delle chat. Il sistema costruisce quindi una query di ricerca per il prezzo della Tenda di Alpine Explorer per recuperare i documenti pertinenti per il costo di Alpine Explorer Tent e si ottiene la risposta.
Se si passa alla traccia da questa esecuzione del flusso, verrà visualizzata in azione. Il collegamento tracce locali viene visualizzato nell'output della console prima del risultato dell'esecuzione del test di flusso.

Pulire le risorse
Per evitare di incorrere in costi di Azure superflui, è necessario eliminare le risorse create in questo avvio rapido, se non sono più richieste. Per gestire le risorse, è possibile usare il portale di Azure.
Ma non eliminarli ancora, se si vuole distribuire il copilota in Azure nella parte successiva di questa serie di esercitazioni.