Esercitazione: Parte 2: Valutare e distribuire un copilota basato su RAG con l'SDK del flusso di richiesta
In questa esercitazione di Azure AI Studio si usa l'SDK del prompt flow (e altre librerie) per valutare e distribuire il copilot creato in Parte 1 della serie di esercitazioni.
Questa esercitazione è la seconda parte di un'esercitazione in due parti.
In questa seconda parte si apprenderà come:
Prerequisiti
Per compilare l'applicazione copilot, è necessario completare la parte 1 della serie di esercitazioni.
È necessario disporre delle autorizzazioni necessarie per aggiungere assegnazioni di ruolo nella sottoscrizione di Azure. La concessione delle autorizzazioni per assegnazione di ruolo è consentita solo dal Proprietario delle risorse di Azure specifiche. Potrebbe essere necessario chiedere al proprietario della sottoscrizione di Azure (che può coincidere con l'amministratore IT) di fornire assistenza per l’accesso agli endpoint più avanti nell’esercitazione.
Valutare la qualità delle risposte di copilota
Ora che si sa che il copilota risponde bene alle query, inclusa la cronologia delle chat, è il momento di valutare le prestazioni in alcune metriche diverse e altri dati.
Usare l'analizzatore del flusso di richiesta con un set di dati di valutazione e la funzione di destinazione get_chat_response(), quindi valutare i risultati della valutazione.
Dopo aver eseguito una valutazione, è possibile apportare miglioramenti alla logica, ad esempio migliorare la richiesta di sistema e osservare come cambiano e migliorano le risposte copilote.
Impostare il modello di valutazione
Scegliere il modello di valutazione da usare. Può essere uguale al modello di chat distribuito in precedenza. Se si vuole un modello diverso per la valutazione, è necessario distribuirlo o specificarlo se esiste già. Ad esempio, è possibile usare gpt-35-turbo per i completamenti della chat, ma si vuole usare gpt-4 per la valutazione perché potrebbe offrire prestazioni migliori.
Aggiungere il nome del modello di valutazione nel file .env:
AZURE_OPENAI_EVALUATION_DEPLOYMENT=<your evaluation model deployment name>
Creare un set di dati di valutazione
Usare il seguente set di dati di valutazione, che contiene domande di esempio e risposte previste (verità).
Creare un file denominato eval_dataset.jsonl nella cartella rag-tutorial. Per informazioni di riferimento, vedere la struttura del codice dell'applicazione.
Incollare questo set di dati nel file:
{"chat_input": "Which tent is the most waterproof?", "truth": "The Alpine Explorer Tent has the highest rainfly waterproof rating at 3000m"} {"chat_input": "Which camping table holds the most weight?", "truth": "The Adventure Dining Table has a higher weight capacity than all of the other camping tables mentioned"} {"chat_input": "How much do the TrailWalker Hiking Shoes cost? ", "truth": "The Trailewalker Hiking Shoes are priced at $110"} {"chat_input": "What is the proper care for trailwalker hiking shoes? ", "truth": "After each use, remove any dirt or debris by brushing or wiping the shoes with a damp cloth."} {"chat_input": "What brand is for TrailMaster tent? ", "truth": "OutdoorLiving"} {"chat_input": "How do I carry the TrailMaster tent around? ", "truth": " Carry bag included for convenient storage and transportation"} {"chat_input": "What is the floor area for Floor Area? ", "truth": "80 square feet"} {"chat_input": "What is the material for TrailBlaze Hiking Pants?", "truth": "Made of high-quality nylon fabric"} {"chat_input": "What color does TrailBlaze Hiking Pants come in?", "truth": "Khaki"} {"chat_input": "Can the warrenty for TrailBlaze pants be transfered? ", "truth": "The warranty is non-transferable and applies only to the original purchaser of the TrailBlaze Hiking Pants. It is valid only when the product is purchased from an authorized retailer."} {"chat_input": "How long are the TrailBlaze pants under warrenty for? ", "truth": " The TrailBlaze Hiking Pants are backed by a 1-year limited warranty from the date of purchase."} {"chat_input": "What is the material for PowerBurner Camping Stove? ", "truth": "Stainless Steel"} {"chat_input": "Is France in Europe?", "truth": "Sorry, I can only queries related to outdoor/camping gear and equipment"}
Valutare con gli analizzatori del flusso di richiesta
Definire ora uno script di valutazione che:
- Importare la funzione
evaluatee gli analizzatori dal pacchettoevalsprompt flow. - Caricare il set di dati
.jsonldi esempio. - Generare un wrapper di funzione di destinazione intorno alla logica copilota.
- Eseguire la valutazione, che accetta la funzione di destinazione e unisce il set di dati di valutazione con le risposte del copilota.
- Generare un set di metriche assistite da GPT (pertinenza, allineamento e coerenza) per valutare la qualità delle risposte del copilota.
- Restituisce i risultati in locale e registra i risultati nel progetto cloud.
Lo script consente di esaminare i risultati in locale, eseguendo l'output dei risultati nella riga di comando e in un file JSON.
Lo script registra anche i risultati della valutazione nel progetto cloud in modo da poter confrontare le esecuzioni di valutazione nell'interfaccia utente.
Creare un file denominato evaluate.py nella cartella rag-tutorial.
Aggiungi il seguente codice. Aggiornare
dataset_patheevaluation_namein base al caso d'uso.import json import os # set environment variables before importing any other code from dotenv import load_dotenv load_dotenv() import pandas as pd from promptflow.core import AzureOpenAIModelConfiguration from promptflow.evals.evaluate import evaluate from promptflow.evals.evaluators import ( RelevanceEvaluator, GroundednessEvaluator, CoherenceEvaluator, ) # Helper methods def load_jsonl(path): with open(path, "r") as f: return [json.loads(line) for line in f.readlines()] def copilot_wrapper(*, chat_input, **kwargs): from copilot_flow.copilot import get_chat_response result = get_chat_response(chat_input) parsedResult = {"answer": str(result["reply"]), "context": str(result["context"])} return parsedResult def run_evaluation(eval_name, dataset_path): model_config = AzureOpenAIModelConfiguration( azure_deployment=os.getenv("AZURE_OPENAI_EVALUATION_DEPLOYMENT"), api_version=os.getenv("AZURE_OPENAI_API_VERSION"), azure_endpoint=os.getenv("AZURE_OPENAI_ENDPOINT"), ) # Initializing Evaluators relevance_eval = RelevanceEvaluator(model_config) groundedness_eval = GroundednessEvaluator(model_config) coherence_eval = CoherenceEvaluator(model_config) output_path = "./eval_results.jsonl" result = evaluate( target=copilot_wrapper, evaluation_name=eval_name, data=dataset_path, evaluators={ "relevance": relevance_eval, "groundedness": groundedness_eval, "coherence": coherence_eval, }, evaluator_config={ "relevance": {"question": "${data.chat_input}"}, "coherence": {"question": "${data.chat_input}"}, }, # to log evaluation to the cloud AI Studio project azure_ai_project={ "subscription_id": os.getenv("AZURE_SUBSCRIPTION_ID"), "resource_group_name": os.getenv("AZURE_RESOURCE_GROUP"), "project_name": os.getenv("AZUREAI_PROJECT_NAME"), }, ) tabular_result = pd.DataFrame(result.get("rows")) tabular_result.to_json(output_path, orient="records", lines=True) return result, tabular_result if __name__ == "__main__": eval_name = "tutorial-eval" dataset_path = "./eval_dataset.jsonl" result, tabular_result = run_evaluation( eval_name=eval_name, dataset_path=dataset_path ) from pprint import pprint pprint("-----Summarized Metrics-----") pprint(result["metrics"]) pprint("-----Tabular Result-----") pprint(tabular_result) pprint(f"View evaluation results in AI Studio: {result['studio_url']}")
La funzione principale alla fine consente di visualizzare il risultato della valutazione in locale e fornisce un collegamento ai risultati della valutazione in AI Studio.
Eseguire lo script di valutazione
Dalla console accedere all'account Azure con l'interfaccia della riga di comando di Azure:
az loginInstallare il pacchetto necessario:
pip install promptflow-evalsEseguire ora lo script di valutazione:
python evaluate.py
Per altre informazioni sull'uso dell'SDK del flusso di richiesta per la valutazione, vedere Valutare con l'SDK del flusso di richiesta.
Interpretare l'output di valutazione
Nell'output della console, per ogni domanda viene visualizzata una risposta e le metriche riepilogate in questo bel formato di tabella. È possibile che nell'output vengano visualizzate colonne diverse.
'-----Summarized Metrics-----'
{'coherence.gpt_coherence': 4.3076923076923075,
'groundedness.gpt_groundedness': 4.384615384615385,
'relevance.gpt_relevance': 4.384615384615385}
'-----Tabular Result-----'
question ... gpt_coherence
0 Which tent is the most waterproof? ... 5
1 Which camping table holds the most weight? ... 5
2 How much does TrailWalker Hiking Shoes cost? ... 5
3 What is the proper care for trailwalker hiking... ... 5
4 What brand is the TrailMaster tent? ... 1
5 How do I carry the TrailMaster tent around? ... 5
6 What is the floor area for Floor Area? ... 3
7 What is the material for TrailBlaze Hiking Pants ... 5
8 What color do the TrailBlaze Hiking Pants come ... 5
9 Can the warranty for TrailBlaze pants be trans... ... 3
10 How long are the TrailBlaze pants under warren... ... 5
11 What is the material for PowerBurner Camping S... ... 5
12 Is France in Europe? ... 1
Lo script scrive i risultati di valutazione completi in ./eval_results.jsonl.
È disponibile un collegamento nella console per visualizzare i risultati della valutazione nel progetto di Azure AI Studio.
Nota
È possibile che venga visualizzato un oggetto ERROR:asyncio:Unclosed client session, che può essere ignorato in modo sicuro e non influisce sui risultati della valutazione.
Visualizzare i risultati della valutazione in Studio AI
Al termine dell'esecuzione della valutazione, seguire il collegamento per visualizzare i risultati della valutazione nella pagina Valutazione in Azure AI Studio.
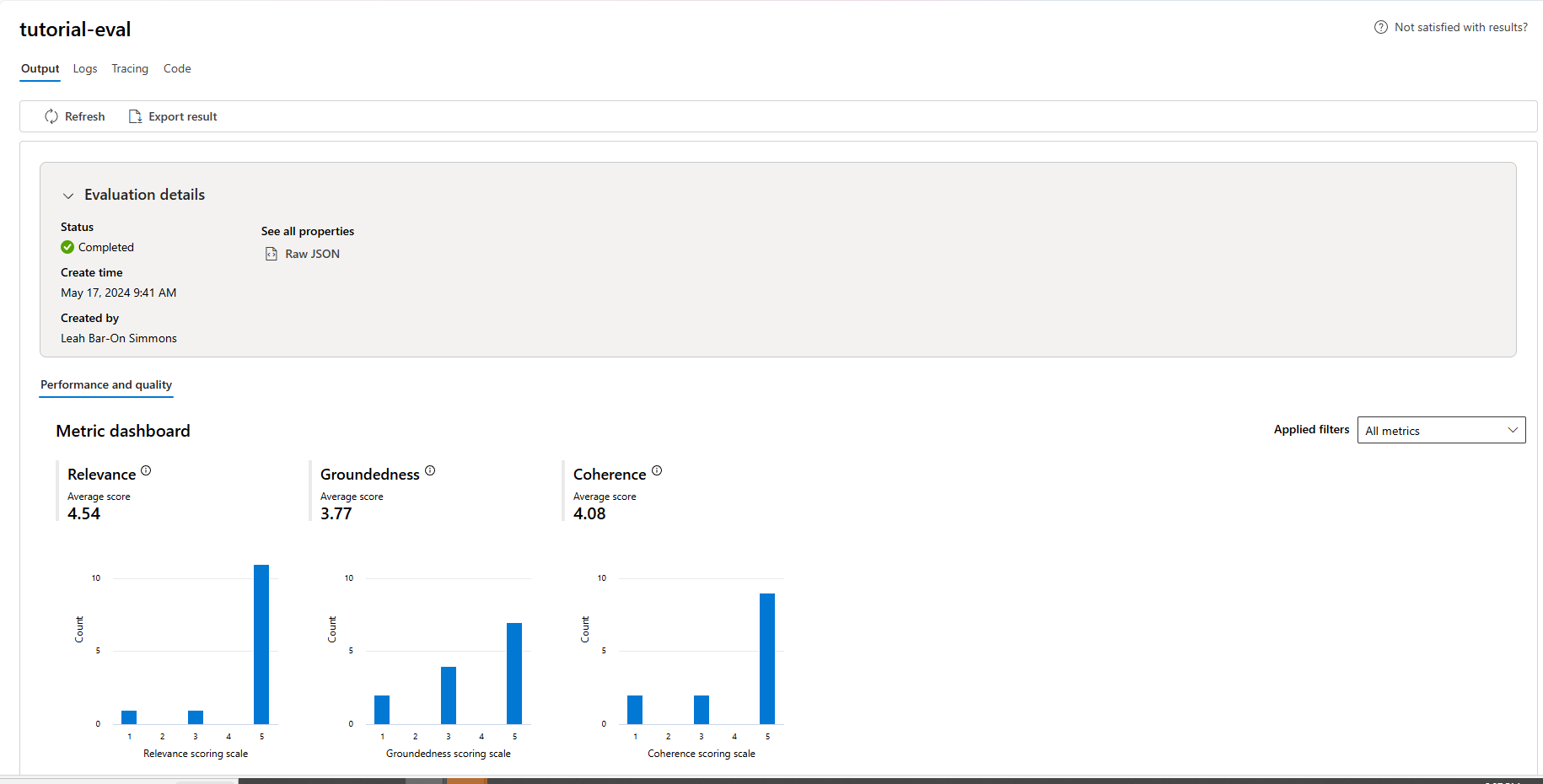
È anche possibile esaminare le singole righe e visualizzare i punteggi delle metriche per riga e visualizzare il contesto completo o i documenti recuperati. Queste metriche possono essere utili per interpretare e eseguire il debug dei risultati della valutazione.
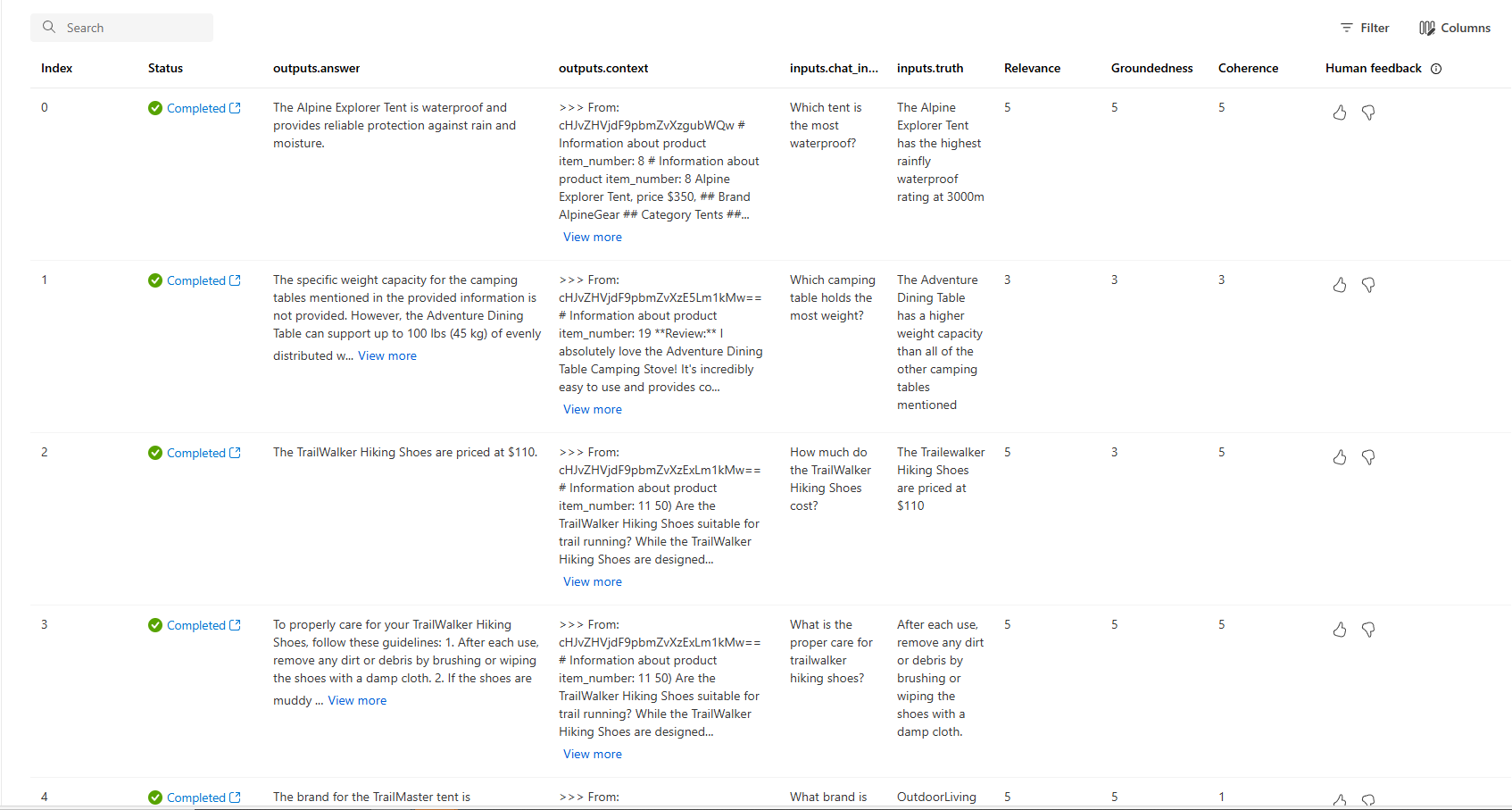
Per altre informazioni sui risultati della valutazione in AI Studio, vedere Come visualizzare i risultati della valutazione in AI Studio.
Dopo aver verificato che il copilota si comporta come previsto, si è pronti per distribuire l'applicazione.
Distribuire il copilota in Azure
A questo punto è possibile procedere e distribuire questo copilota in un endpoint gestito, in modo che possa essere utilizzato da un'applicazione esterna o da un sito Web.
Lo script di distribuzione:
- Creare un endpoint online gestito
- Definirà il flusso come modello
- Distribuirà il flusso in un ambiente gestito in tale endpoint con le variabili di ambiente
- Instraderà tutto il traffico a tale distribuzione
- Genererà l'output del collegamento per visualizzare e testare la distribuzione in Azure AI Studio
La distribuzione definisce un contesto di compilazione (Dockerfile) che si basa sull'oggetto requirement.txt specificato nella cartella del flusso e imposta anche le variabili di ambiente sull'ambiente distribuito, in modo da poter essere certi che l'applicazione copilot venga eseguita come in un ambiente di produzione come in locale.
Contesto di compilazione per la distribuzione (Dockerfile)
L'ambiente distribuito richiede un contesto di compilazione, quindi definiamo un Dockerfile per l'ambiente distribuito. Lo script di distribuzione crea un ambiente basato su questo Dockerfile. Creare questo Dockerfile nella cartella copilot_flow:
FROM mcr.microsoft.com/azureml/promptflow/promptflow-runtime:latest
COPY ./requirements.txt .
RUN pip install -r requirements.txt
Distribuire copilot in un endpoint gestito
Per distribuire l'applicazione in un endpoint gestito in Azure, creare un endpoint online, quindi creare una distribuzione in tale endpoint e quindi indirizzare tutto il traffico a tale distribuzione.
Nell'ambito della creazione della distribuzione, la cartella copilot_flow viene inserita in un pacchetto come modello e viene creato un ambiente cloud. L'endpoint viene configurato con l'autenticazione di Microsoft Entra ID. È possibile aggiornare la modalità di autenticazione desiderata nel codice o in Azure AI Studio nella pagina dei dettagli dell'endpoint.
Importante
La distribuzione dell'applicazione in un endpoint gestito in Azure ha associato costi di calcolo in base al tipo di istanza scelto. Assicurarsi di conoscere il costo associato e avere una quota per il tipo di istanza specificato. Altre informazioni sugli endpoint online.
Creare il file deploy.py nella cartella rag-tutorial. Aggiungere il codice seguente:
import os
from dotenv import load_dotenv
load_dotenv()
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
BuildContext,
)
client = MLClient(
DefaultAzureCredential(),
os.getenv("AZURE_SUBSCRIPTION_ID"),
os.getenv("AZURE_RESOURCE_GROUP"),
os.getenv("AZUREAI_PROJECT_NAME"),
)
endpoint_name = "tutorial-endpoint"
deployment_name = "tutorial-deployment"
endpoint = ManagedOnlineEndpoint(
name=endpoint_name,
properties={
"enforce_access_to_default_secret_stores": "enabled" # for secret injection support
},
auth_mode="aad_token", # using aad auth instead of key-based auth
)
# Get the directory of the current script
script_dir = os.path.dirname(os.path.abspath(__file__))
# Define the path to the directory, appending the script directory to the relative path
copilot_path = os.path.join(script_dir, "copilot_flow")
deployment = ManagedOnlineDeployment(
name=deployment_name,
endpoint_name=endpoint_name,
model=Model(
name="copilot_flow_model",
path=copilot_path, # path to promptflow folder
properties=[ # this enables the chat interface in the endpoint test tab
["azureml.promptflow.source_flow_id", "basic-chat"],
["azureml.promptflow.mode", "chat"],
["azureml.promptflow.chat_input", "chat_input"],
["azureml.promptflow.chat_output", "reply"],
],
),
environment=Environment(
build=BuildContext(
path=copilot_path,
),
inference_config={
"liveness_route": {
"path": "/health",
"port": 8080,
},
"readiness_route": {
"path": "/health",
"port": 8080,
},
"scoring_route": {
"path": "/score",
"port": 8080,
},
},
),
instance_type="Standard_DS3_v2",
instance_count=1,
environment_variables={
"PRT_CONFIG_OVERRIDE": f"deployment.subscription_id={client.subscription_id},deployment.resource_group={client.resource_group_name},deployment.workspace_name={client.workspace_name},deployment.endpoint_name={endpoint_name},deployment.deployment_name={deployment_name}",
"AZURE_OPENAI_ENDPOINT": os.getenv("AZURE_OPENAI_ENDPOINT"),
"AZURE_SEARCH_ENDPOINT": os.getenv("AZURE_SEARCH_ENDPOINT"),
"AZURE_OPENAI_API_VERSION": os.getenv("AZURE_OPENAI_API_VERSION"),
"AZURE_OPENAI_CHAT_DEPLOYMENT": os.getenv("AZURE_OPENAI_CHAT_DEPLOYMENT"),
"AZURE_OPENAI_EVALUATION_DEPLOYMENT": os.getenv(
"AZURE_OPENAI_EVALUATION_DEPLOYMENT"
),
"AZURE_OPENAI_EMBEDDING_DEPLOYMENT": os.getenv(
"AZURE_OPENAI_EMBEDDING_DEPLOYMENT"
),
"AZUREAI_SEARCH_INDEX_NAME": os.getenv("AZUREAI_SEARCH_INDEX_NAME"),
},
)
# 1. create endpoint
created_endpoint = client.begin_create_or_update(
endpoint
).result() # result() means we wait on this to complete
# 2. create deployment
created_deployment = client.begin_create_or_update(deployment).result()
# 3. update endpoint traffic for the deployment
endpoint.traffic = {deployment_name: 100} # 100% of traffic
client.begin_create_or_update(endpoint).result()
Importante
Il nome dell'endpoint e della distribuzione deve essere univoco all'interno di un'area di Azure. Se viene visualizzato un errore che indica che l'endpoint o il nome della distribuzione esiste già, provare nomi diversi.
Dettagli della distribuzione dell'output
Aggiungere le righe seguenti alla fine dello script di distribuzione per visualizzare il risultato della valutazione in locale e ottenere un collegamento allo studio:
def get_ai_studio_url_for_deploy(
client: MLClient, endpoint_name: str, deployment_name
) -> str:
studio_base_url = "https://ai.azure.com"
deployment_url = f"{studio_base_url}/projectdeployments/realtime/{endpoint_name}/{deployment_name}/detail?wsid=/subscriptions/{client.subscription_id}/resourceGroups/{client.resource_group_name}/providers/Microsoft.MachineLearningServices/workspaces/{client.workspace_name}&deploymentName={deployment_name}"
return deployment_url
print("\n ~~~Deployment details~~~")
print(f"Your online endpoint name is: {endpoint_name}")
print(f"Your deployment name is: {deployment_name}")
print("\n ~~~Test in the Azure AI Studio~~~")
print("\n Follow this link to your deployment in the Azure AI Studio:")
print(
get_ai_studio_url_for_deploy(
client=client, endpoint_name=endpoint_name, deployment_name=deployment_name
)
)
Eseguire ora lo script con:
python deploy.py
Nota
Il completamento della distribuzione può richiedere più di 10 minuti. È consigliabile seguire il passaggio successivo per assegnare l'accesso all'endpoint durante l'attesa.
Al termine della distribuzione, si ottiene un collegamento alla pagina di distribuzione di Azure AI Studio, in cui è possibile testare la distribuzione.
Verificare la distribuzione
È consigliabile testare l'applicazione in Azure AI Studio. Se si preferisce testare l'endpoint distribuito in locale, è possibile richiamarlo con codice personalizzato.
Prendere nota del nome dell'endpoint, necessario per i passaggi successivi.
Accesso agli endpoint per la risorsa OpenAI di Azure
Potrebbe essere necessario chiedere al proprietario della sottoscrizione di Azure (che può coincidere con l'amministratore IT) di fornire assistenza con questa sezione.
Mentre si attende che l'applicazione venga distribuita, l'utente o l'amministratore può assegnare l'accesso in base al ruolo all'endpoint. Questi ruoli consentono l'esecuzione dell'applicazione senza chiavi nell'ambiente distribuito, proprio come avviene in locale.
In precedenza, è stato fornito all'account un ruolo specifico per poter accedere alla risorsa usando l'autenticazione Microsoft Entra ID. Assegnare ora all'endpoint lo stesso ruolo Utente Servizi cognitivi OpenAI.
Nota
Questi passaggi sono simili al modo in cui è stato assegnato un ruolo per l'identità utente per l'uso del servizio Azure OpenAI nell'argomento di avvio rapido.
Per concedere a se stessi l'accesso alla risorsa dei Servizi di Azure AI in uso:
In Studio AI, passare al progetto e selezionare Impostazioni nel riquadro sinistro.
Nella sezione Risorse connesse selezionare il nome della connessione con tipo AIServices.
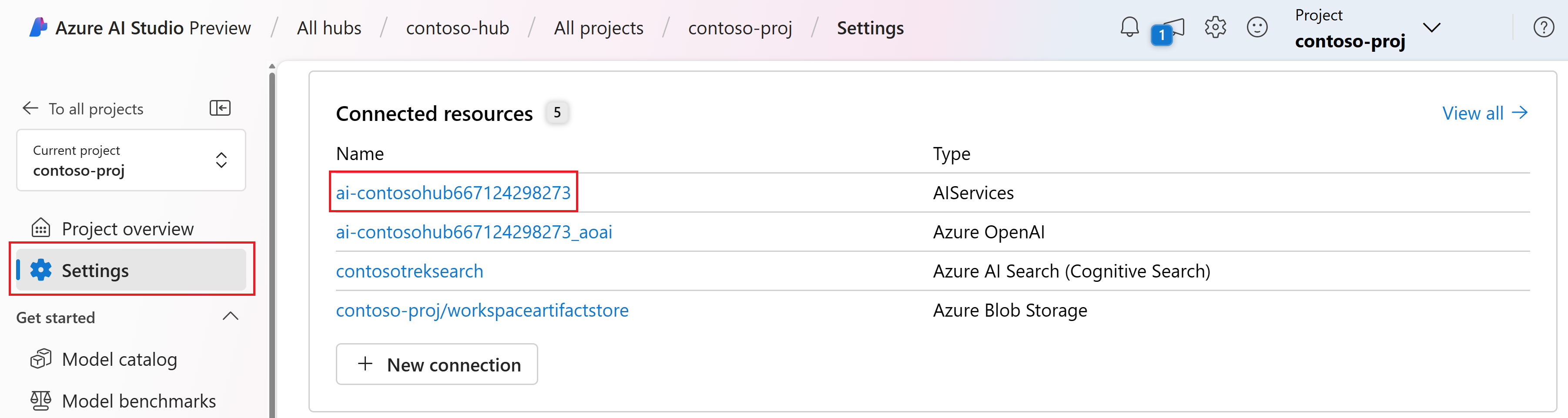
Nota
Se la connessione AIServices non viene visualizzata, al suo posto usare la connessione OpenAI di Azure.
Nella pagina dei dettagli della risorsa, selezionare il collegamento nell'intestazione Risorsa per aprire la risorsa dei Servizi IA nel portale di Azure.
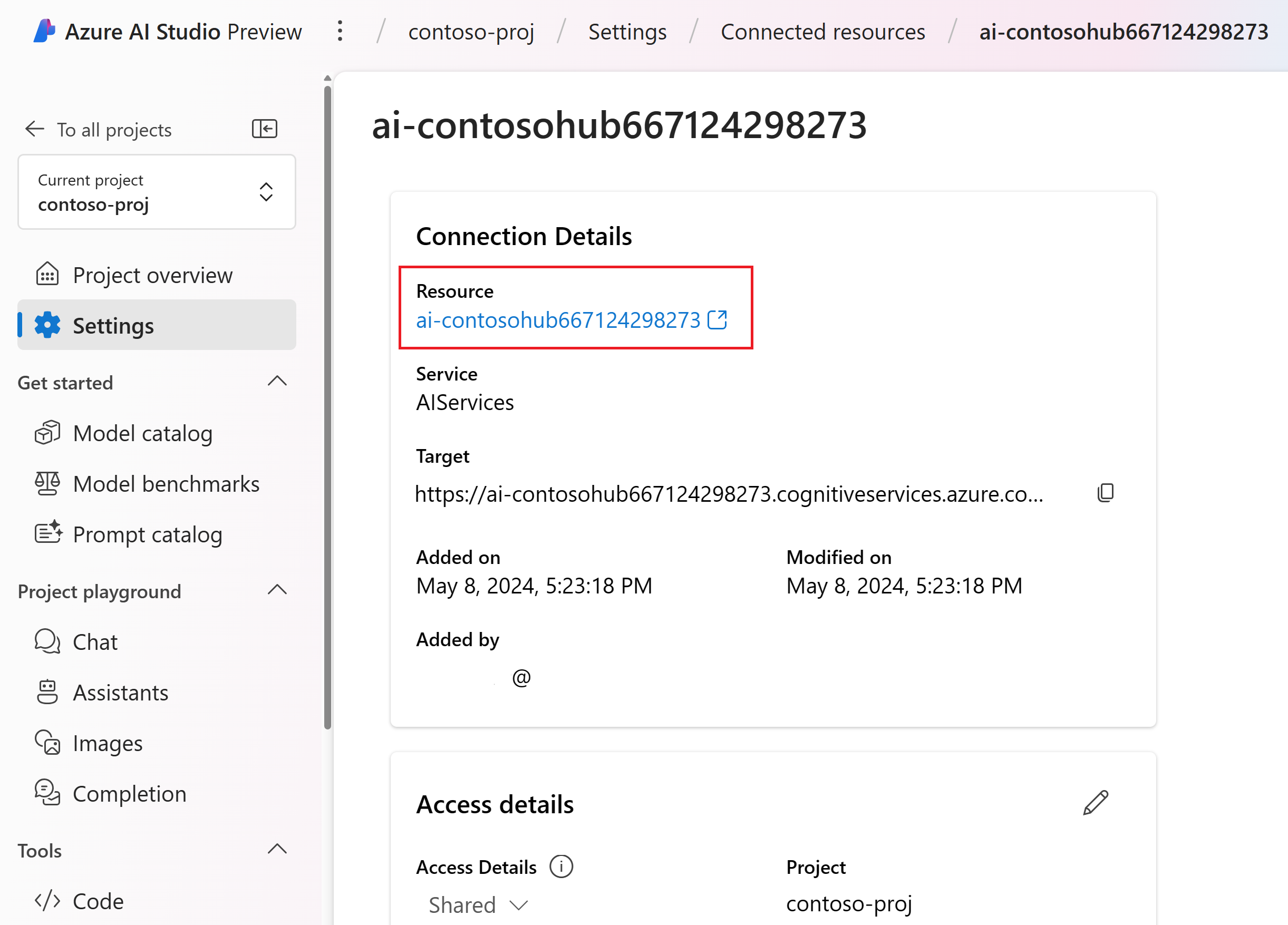
Nella pagina sinistra del portale di Azure, selezionare Controllo di accesso (IAM)> e >Aggiungi assegnazione di ruolo.
Cercare il ruolo Utente Servizi cognitivi OpenAI e selezionarlo. Quindi seleziona Avanti.
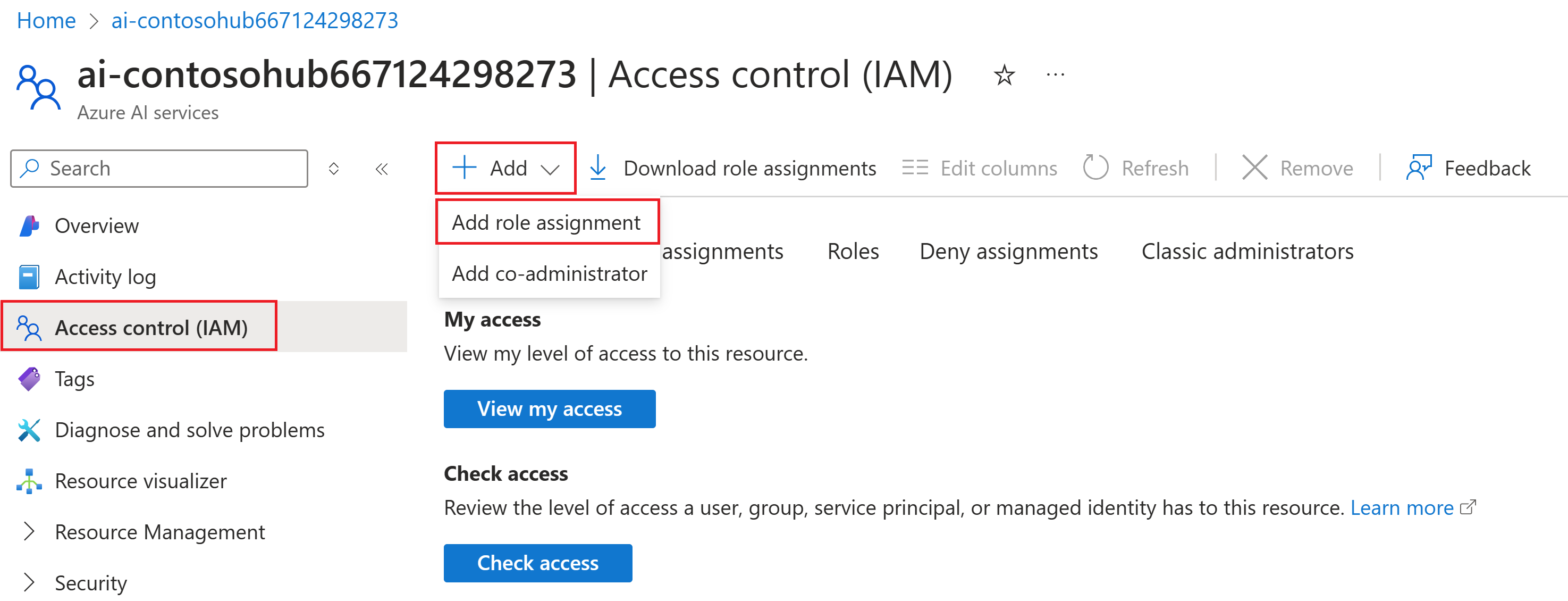
Selezionare Identità gestita. Quindi scegliere Seleziona membri.
Nel riquadro Selezionare i membri visualizzato selezionare endpoint online di Machine Learning per l'identità gestita e quindi cercare il nome dell'endpoint. Selezionare l'endpoint e quindi selezionare Seleziona.
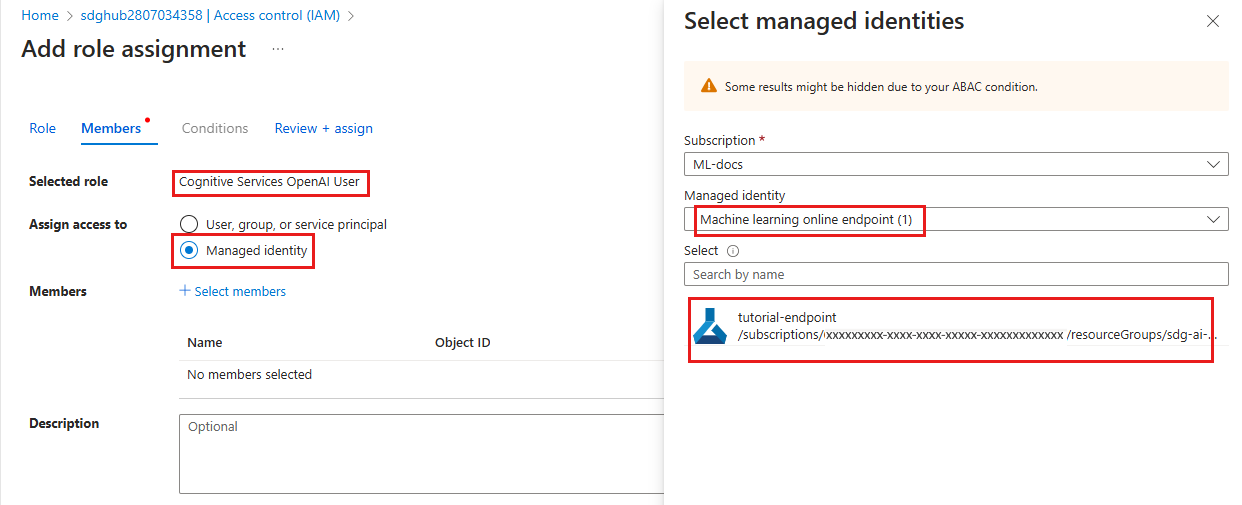
Continuare la procedura guidata e selezionare Rivedi e assegna per aggiungere l'assegnazione di ruolo.



Nota
La propagazione dell'accesso può richiedere alcuni minuti. Se viene visualizzato un errore non autorizzato durante il test nel passaggio successivo, riprovare dopo alcuni minuti.
Accesso agli endpoint per la risorsa di Ricerca di intelligenza artificiale di Azure
Potrebbe essere necessario chiedere al proprietario della sottoscrizione di Azure (che può coincidere con l'amministratore IT) di fornire assistenza con questa sezione.
Analogamente a come è stato assegnato il ruolo di Collaboratore ai dati dell'indice di ricerca al servizio Ricerca intelligenza artificiale di Azure, è necessario assegnare lo stesso ruolo per l'endpoint.
In Azure AI Studio selezionare Impostazioni e passare al servizio di ricerca di intelligenza artificiale di Azure connesso.
Selezionare il collegamento per aprire un riepilogo della risorsa. Selezionare il collegamento nella pagina di riepilogo per aprire la risorsa nel portale di Azure.
Nella pagina sinistra del portale di Azure, selezionare Controllo di accesso (IAM)> e >Aggiungi assegnazione di ruolo.
Cercare il ruolo Collaboratore dati indice di ricerca e quindi selezionarlo. Quindi seleziona Avanti.
Selezionare Identità gestita. Quindi scegliere Seleziona membri.
Nel riquadro Selezionare i membri visualizzato selezionare endpoint online di Machine Learning per l'identità gestita e quindi cercare il nome dell'endpoint. Selezionare l'endpoint e quindi selezionare Seleziona.
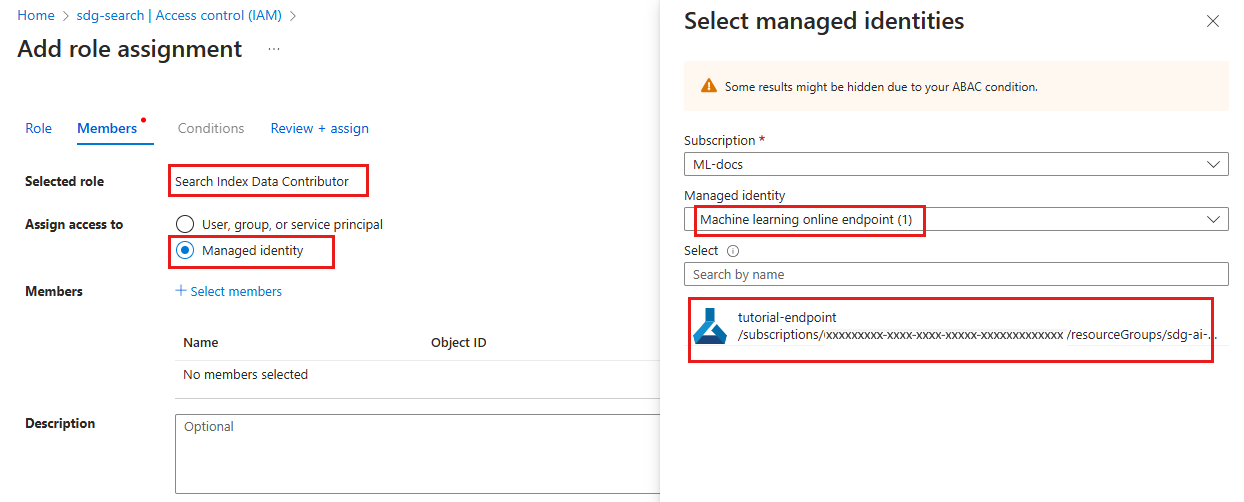
Continuare la procedura guidata e selezionare Rivedi e assegna per aggiungere l'assegnazione di ruolo.
Nota
La propagazione dell'accesso può richiedere alcuni minuti. Se viene visualizzato un errore non autorizzato durante il test nel passaggio successivo, riprovare dopo alcuni minuti.
Testare la distribuzione in AI Studio
Una volta completata la distribuzione, si ottiene un collegamento pratico alla distribuzione. Se non si usa il collegamento, passare alla scheda Distribuzioni nel progetto e selezionare la nuova distribuzione.
Selezionare la scheda Test e provare a porre una domanda nell'interfaccia della chat.
Ad esempio, digitare "Le scarpe da trekking trailwalker sono impermeabili?" e immettere.
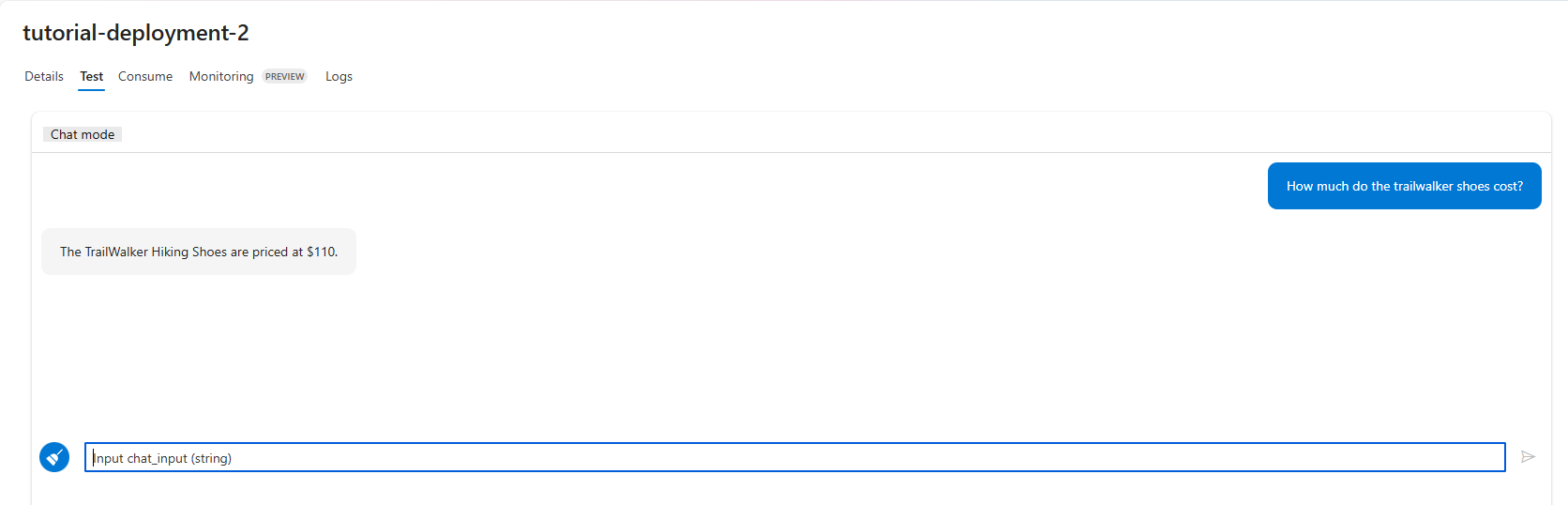
Se viene visualizzata la risposta, viene verificata la distribuzione.
Se viene visualizzato un errore, selezionare la scheda Log per ottenere altri dettagli.
Nota
Se viene visualizzato un errore non autorizzato, l'accesso all'endpoint potrebbe non essere ancora stato applicato. Riprovare dopo alcuni minuti.
Richiamare il copilot distribuito in locale
Se si preferisce verificare la distribuzione in locale, è possibile richiamarla tramite uno script Python.
Definire uno script che:
- Creare una richiesta ben formata all'URL di assegnazione dei punteggi.
- Pubblicare la richiesta e gestire la risposta.
Creare un file invoke-local.py nella cartella rag-tutorial con il codice seguente. Modificare query e endpoint_name (e altri parametri in base alle esigenze) in base al caso d'uso.
import os
from dotenv import load_dotenv
load_dotenv()
import requests
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
query = "Are the trailwalker shoes waterproof?"
endpoint_name = "tutorial-endpoint"
client = MLClient(
DefaultAzureCredential(),
os.getenv("AZURE_SUBSCRIPTION_ID"),
os.getenv("AZURE_RESOURCE_GROUP"),
os.getenv("AZUREAI_PROJECT_NAME"),
)
scoring_url = client.online_endpoints.get(endpoint_name).scoring_uri
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {client._credential.get_token('https://ml.azure.com').token}",
"Accept": "application/json",
}
response = requests.post(
scoring_url,
headers=headers,
json={"chat_input": query},
)
(print(response.json()["reply"]))
Nella console dovrebbe essere visualizzata la risposta copilota alla query.
Nota
Se viene visualizzato un errore non autorizzato, l'accesso all'endpoint potrebbe non essere ancora stato applicato. Riprovare dopo alcuni minuti.
Pulire le risorse
Per evitare di incorrere in costi di Azure superflui, è necessario eliminare le risorse create in questo avvio rapido, se non sono più richieste. Per gestire le risorse, è possibile usare il portale di Azure.
Contenuto correlato
- Altre informazioni sul prompt flow
- Per un'applicazione copilota di esempio che implementa RAG, vedere Azure-Samples/rag-data-openai-python-promptflow