Questa architettura di riferimento mostra un'architettura di microservizi distribuita in Azure Service Fabric. Mostra una configurazione cluster di base che può essere il punto di partenza per la maggior parte delle distribuzioni.
 Un'implementazione di riferimento di questa architettura è disponibile in GitHub.
Un'implementazione di riferimento di questa architettura è disponibile in GitHub.
Architettura
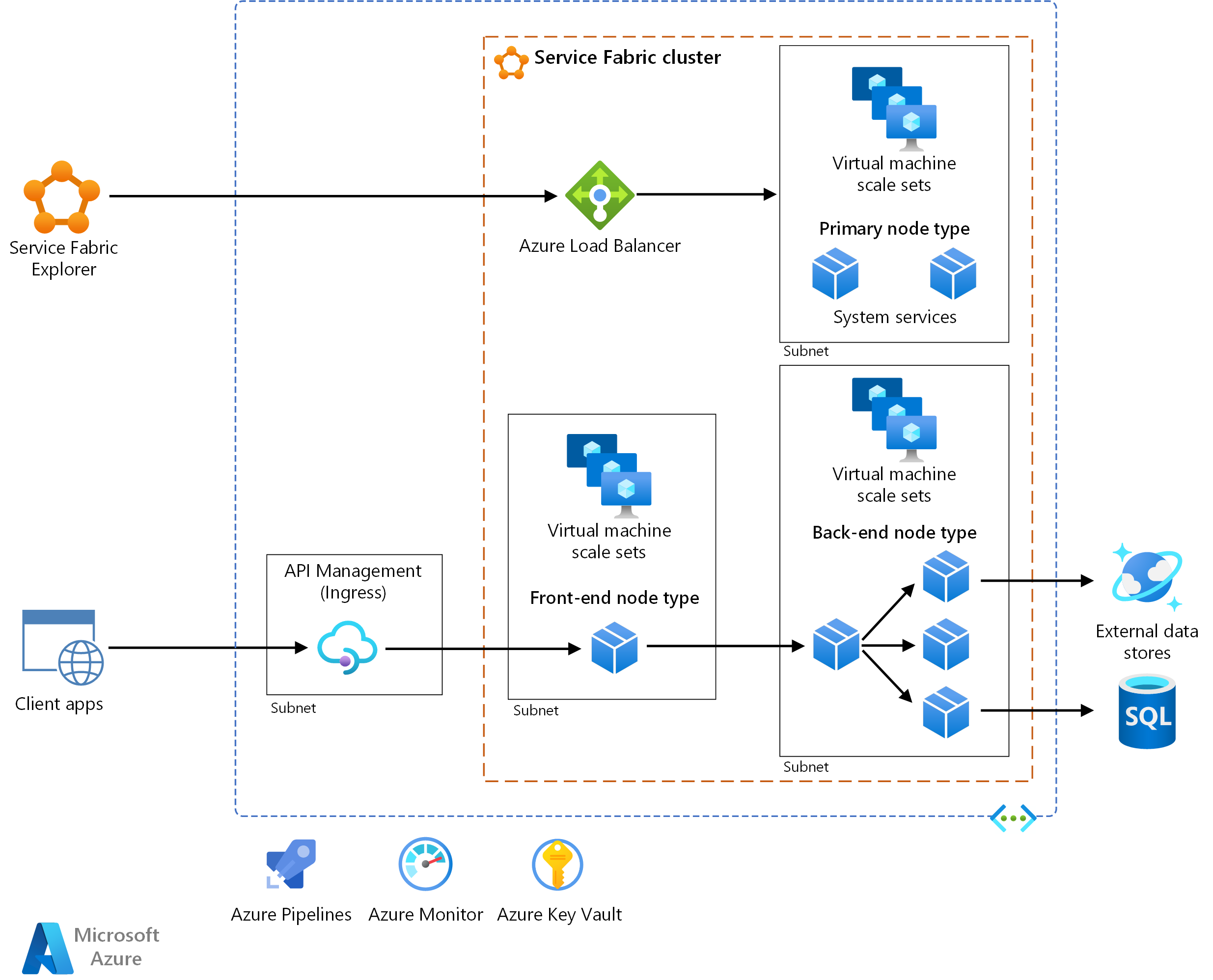
Scaricare un file di Visio di questa architettura.
Nota
Questo articolo è incentrato sul modello di programmazione Reliable Services per Service Fabric. L'uso di Service Fabric per distribuire e gestire i contenitori non rientra nell'ambito di questo articolo.
Workflow
L'architettura è costituita dai componenti seguenti. Per altri termini, vedere Panoramica della terminologia di Service Fabric.
Cluster di Service Fabric. Un cluster è un set di macchine virtuali (VM) connesso alla rete in cui si distribuiscono e gestiscono i microservizi.
Set di scalabilità di macchine virtuali. I set di scalabilità di macchine virtuali consentono di creare e gestire un gruppo di macchine virtuali identiche, con bilanciamento del carico e scalabilità automatica. Queste risorse di calcolo forniscono anche i domini di errore e di aggiornamento.
Nodi. I nodi sono le macchine virtuali che appartengono al cluster di Service Fabric.
Tipi di nodo. Un tipo di nodo rappresenta un set di scalabilità di macchine virtuali che distribuisce una raccolta di nodi. Un cluster di Service Fabric ha almeno un tipo di nodo.
In un cluster con più tipi di nodo, è necessario dichiarare il tipo di nodo primario. Il tipo di nodo primario nel cluster esegue i servizi di sistema di Service Fabric. Questi servizi offrono le funzionalità della piattaforma di Service Fabric. Il tipo di nodo primario funge anche da nodi di inizializzazione, ovvero i nodi che mantengono la disponibilità del cluster sottostante.
Configurare tipi di nodo aggiuntivi per eseguire i servizi.
Servizi. Un servizio esegue una funzione autonoma che può essere avviata ed eseguita indipendentemente da altri servizi. Le istanze dei servizi vengono distribuite ai nodi nel cluster. Esistono due varietà di servizi in Service Fabric:
- Servizio senza stato. Un servizio senza stato non mantiene lo stato all'interno del servizio. Se è necessaria la persistenza dello stato, lo stato viene scritto in e recuperato da un archivio esterno, ad esempio Azure Cosmos DB.
- Servizio con stato. Lo stato del servizio viene mantenuto all'interno del servizio stesso. La maggior parte dei servizi con stato implementa questa funzionalità tramite Reliable Collections in Service Fabric.
Service Fabric Explorer. Service Fabric Explorer è uno strumento open source per l'ispezione e la gestione dei cluster di Service Fabric.
Azure Pipelines. Azure Pipelines fa parte di Azure DevOps Services ed esegue compilazioni, test e distribuzioni automatizzate. È anche possibile usare soluzioni di integrazione continua e recapito continuo (CI/CD) di terze parti, ad esempio Jenkins.
Monitoraggio di Azure. Monitoraggio di Azure raccoglie e archivia log e metriche, tra cui le metriche della piattaforma per i servizi di Azure nella soluzione e i dati di telemetria dell'applicazione. Usare questi dati per monitorare l'applicazione, configurare avvisi e dashboard ed eseguire l'analisi delle cause principali di errore. Monitoraggio di Azure si integra con Service Fabric per raccogliere metriche da controller, nodi e contenitori, insieme ai log dei contenitori e dei nodi.
Azure Key Vault. Usare Key Vault per archiviare tutti i segreti dell'applicazione usati dai microservizi, ad esempio stringa di connessione.
Gestione API di Azure. In questa architettura, Gestione API funge da gateway API che accetta le richieste dai client e le instrada ai servizi.
Considerazioni
Queste considerazioni implementano i pilastri di Azure Well-Architected Framework, che è un set di principi guida per migliorare la qualità di un carico di lavoro.
Considerazioni relative alla progettazione
Questa architettura di riferimento è incentrata sulle architetture di microservizi. Un microservizio è un'unità di codice con controllo delle versioni ridotta e indipendente. È individuabile tramite meccanismi di individuazione dei servizi e può comunicare con altri servizi tramite le API. Ogni servizio è indipendente e deve implementare una singola funzionalità di business. Per altre informazioni su come scomporre il dominio dell'applicazione in microservizi, vedere Uso dell'analisi del dominio per modellare i microservizi.
Service Fabric offre un'infrastruttura per compilare, distribuire e aggiornare in modo efficiente i microservizi. Offre anche opzioni per la scalabilità automatica, la gestione dello stato, il monitoraggio dell'integrità e il riavvio dei servizi in caso di errore.
Service Fabric segue un modello di applicazione in cui un'applicazione è una raccolta di microservizi. L'applicazione è descritta in un file manifesto dell'applicazione. Questo file definisce i tipi di servizi contenuti dall'applicazione, insieme ai puntatori ai pacchetti di servizi indipendenti.
Il pacchetto dell'applicazione contiene in genere parametri che fungono da override per determinate impostazioni usate dai servizi. Ogni pacchetto del servizio ha un file manifesto che descrive i file fisici e le cartelle necessari per eseguire tale servizio, inclusi file binari, file di configurazione e dati di sola lettura. I servizi e le applicazioni sono indipendentemente con controllo delle versioni e aggiornabili.
Facoltativamente, il manifesto dell'applicazione può descrivere i servizi di cui viene eseguito automaticamente il provisioning quando viene creata un'istanza dell'applicazione. Questi sono denominati servizi predefiniti. In questo caso, il manifesto dell'applicazione descrive anche come creare questi servizi. Tali informazioni includono il nome del servizio, il numero di istanze, i criteri di sicurezza o di isolamento e i vincoli di posizionamento.
Nota
Evitare di usare i servizi predefiniti se si vuole controllare la durata dei servizi. I servizi predefiniti vengono creati al momento della creazione dell'applicazione e vengono eseguiti fino a quando l'applicazione è in esecuzione.
Per altre informazioni, vedere Informazioni su Service Fabric.
Modello di creazione di pacchetti da applicazione a servizio
Una rete di microservizi è che ogni servizio può essere distribuito in modo indipendente. In Service Fabric, se si raggruppano tutti i servizi in un singolo pacchetto dell'applicazione e un servizio non viene aggiornato, viene eseguito il rollback dell'intero aggiornamento dell'applicazione. Questo rollback impedisce l'aggiornamento di altri servizi.
Per questo motivo, in un'architettura di microservizi è consigliabile usare più pacchetti dell'applicazione. Inserire uno o più tipi di servizio strettamente correlati in un singolo tipo di applicazione. Ad esempio, inserire i tipi di servizio nello stesso tipo di applicazione se il team è responsabile di un set di servizi con uno di questi attributi:
- Vengono eseguiti per la stessa durata e devono essere aggiornati contemporaneamente.
- Hanno lo stesso ciclo di vita.
- Condividono risorse come dipendenze o configurazione.
Modelli di programmazione di Service Fabric
Quando si aggiunge un microservizio a un'applicazione di Service Fabric, decidere se dispone di uno stato o di dati che devono essere resi a disponibilità elevata e affidabili. In tal caso, è possibile archiviare i dati esternamente o sono i dati contenuti come parte del servizio? Scegliere un servizio senza stato se non è necessario archiviare i dati o archiviare i dati in una risorsa di archiviazione esterna. Valutare la possibilità di scegliere un servizio con stato se si applica una di queste istruzioni:
- Si desidera mantenere lo stato o i dati come parte del servizio. Ad esempio, è necessario che i dati risiedano in memoria vicino al codice.
- Non è possibile tollerare una dipendenza da un archivio esterno.
Se si vuole eseguire codice esistente in Service Fabric, è possibile eseguirlo come eseguibile guest: un eseguibile arbitrario che viene eseguito come servizio. In alternativa, è possibile creare un pacchetto dell'eseguibile in un contenitore con tutte le dipendenze necessarie per la distribuzione.
Service Fabric modella sia i contenitori che i file eseguibili guest come servizi senza stato. Per indicazioni sulla scelta di un modello, vedere Panoramica del modello di programmazione di Service Fabric.
L'utente è responsabile della gestione dell'ambiente in cui viene eseguito un eseguibile guest. Si supponga, ad esempio, che un eseguibile guest richieda Python. Se l'eseguibile non è autonomo, è necessario assicurarsi che la versione richiesta di Python sia preinstallata nell'ambiente. Service Fabric non gestisce l'ambiente. Azure offre più meccanismi per configurare l'ambiente, tra cui immagini ed estensioni di macchine virtuali personalizzate.
Per accedere a un eseguibile guest tramite un proxy inverso, assicurarsi di aver aggiunto l'attributo UriScheme all'elemento Endpoint nel manifesto del servizio dell'eseguibile guest.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" UriScheme="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Se il servizio include route aggiuntive, specificare le route nel PathSuffix valore . Il valore non deve essere preceduto o suffisso con una barra (/). Un altro modo consiste nell'aggiungere la route nel nome del servizio.
<Endpoints>
<Endpoint Name="MyGuestExeTypeEndpoint" Port="8090" Protocol="http" PathSuffix="api" Type="Input"/>
</Endpoints>
Per altre informazioni, vedi:
- Inserire un'applicazione in un pacchetto
- Creare il pacchetto e distribuire un eseguibile esistente in Service Fabric
Gateway API
Un gateway API (ingresso) si trova tra i client esterni e i microservizi. e funge da proxy inverso, indirizzando le richieste dai client ai microservizi. Può anche eseguire attività di taglio incrociato, ad esempio l'autenticazione, la terminazione SSL e la limitazione della frequenza.
È consigliabile usare Azure Gestione API per la maggior parte degli scenari, ma Traefik è un'alternativa open source più diffusa. Entrambe le opzioni tecnologiche sono integrate con Service Fabric.
Gestione API. Espone un indirizzo IP pubblico e instrada il traffico ai servizi. Viene eseguito in una subnet dedicata nella stessa rete virtuale del cluster di Service Fabric.
Gestione API possibile accedere ai servizi in un tipo di nodo esposto tramite un servizio di bilanciamento del carico con un indirizzo IP privato. Questa opzione è disponibile solo nei livelli Premium e Developer di Gestione API. Per i carichi di lavoro di produzione, usare il livello Premium. Le informazioni sui prezzi sono descritte in Gestione API prezzi.
Per altre informazioni, vedere Panoramica di Service Fabric con Azure Gestione API.
Traefik. Supporta funzionalità quali routing, traccia, log e metriche. Traefik viene eseguito come servizio senza stato nel cluster di Service Fabric. Il controllo delle versioni del servizio può essere supportato tramite il routing.
Per informazioni su come configurare Traefik per l'ingresso del servizio e come proxy inverso all'interno del cluster, vedere Provider di Azure Service Fabric nel sito Web Traefik. Per altre informazioni sull'uso di Traefik con Service Fabric, vedere il post di blog Routing intelligente in Service Fabric con Traefik.
Traefik, a differenza di Azure Gestione API, non dispone di funzionalità per risolvere la partizione di un servizio con stato (con più di una partizione) a cui viene instradata una richiesta. Per altre informazioni, vedere Aggiungere un matcher per i servizi di partizionamento.
Altre opzioni di gestione API includono app Azure gateway di comunicazione e Frontdoor di Azure. È possibile usare questi servizi in combinazione con Gestione API per eseguire attività quali routing, terminazione SSL e firewall.
Comunicazione tra i servizi
Per facilitare la comunicazione da servizio a servizio, prendere in considerazione le raccomandazioni seguenti:
Protocollo di comunicazione. In un'architettura di microservizi, i servizi devono comunicare tra loro con l'accoppiamento minimo in fase di esecuzione. Per abilitare la comunicazione indipendente dal linguaggio, HTTP è uno standard di settore con un'ampia gamma di strumenti e server HTTP disponibili in linguaggi diversi. Service Fabric supporta tutti questi strumenti e server.
Per la maggior parte dei carichi di lavoro, è consigliabile usare HTTP anziché la comunicazione remota del servizio integrata in Service Fabric.
Individuazione dei servizi. Per comunicare con altri servizi all'interno di un cluster, un servizio client deve risolvere la posizione corrente del servizio di destinazione. In Service Fabric i servizi possono spostarsi tra nodi e causare la modifica dinamica degli endpoint di servizio.
Per evitare connessioni a endpoint non aggiornati, è possibile usare il servizio di denominazione in Service Fabric per recuperare informazioni aggiornate sull'endpoint. Tuttavia, Service Fabric fornisce anche un servizio proxy inverso predefinito che astrae il servizio di denominazione. È consigliabile usare questa opzione per l'individuazione dei servizi come baseline per la maggior parte degli scenari, perché è più semplice usare e ottenere codice più semplice.
Altre opzioni per la comunicazione tra servizi includono:
- Traefik per il routing avanzato.
- DNS per scenari di compatibilità in cui un servizio prevede l'uso di DNS.
- Classe ServicePartitionClient<TCommunicationClient> , che memorizza nella cache gli endpoint di servizio. Può consentire prestazioni migliori, perché le chiamate passano direttamente tra servizi senza intermediari o protocolli personalizzati.
Scalabilità
Service Fabric supporta il ridimensionamento di queste entità cluster:
- Ridimensionamento del numero di nodi per ogni tipo di nodo
- Ridimensionamento dei servizi
Questa sezione è incentrata sulla scalabilità automatica. È possibile scegliere di ridimensionare manualmente le situazioni in cui è appropriato. Ad esempio, potrebbe essere necessario un intervento manuale per impostare il numero di istanze.
Configurazione iniziale del cluster per la scalabilità
Quando si crea un cluster di Service Fabric, effettuare il provisioning dei tipi di nodo in base alle esigenze di sicurezza e scalabilità. Ogni tipo di nodo viene mappato a un set di scalabilità di macchine virtuali e può essere ridimensionato in modo indipendente.
- Creare un tipo di nodo per ogni gruppo di servizi con requisiti di scalabilità o risorse diversi. Per iniziare, effettuare il provisioning di un tipo di nodo (che diventa il tipo di nodo primario) per i servizi di sistema di Service Fabric. Creare tipi di nodo separati per eseguire i servizi pubblici o front-end. Creare altri tipi di nodo in base alle esigenze per i servizi back-end e privati o isolati. Specificare i vincoli di posizionamento in modo che i servizi vengano distribuiti solo nei tipi di nodo previsti.
- Specificare il livello di durabilità per ogni tipo di nodo. Il livello di durabilità rappresenta la capacità di Service Fabric di influenzare gli aggiornamenti e le operazioni di manutenzione nei set di scalabilità di macchine virtuali. Per i carichi di lavoro di produzione, scegliere un livello di durabilità Silver o superiore. Per informazioni su ogni livello, vedere Caratteristiche di durabilità del cluster.
- Se si usa il livello di durabilità Bronze, alcune operazioni richiedono passaggi manuali. I tipi di nodo con il livello di durabilità Bronze richiedono passaggi aggiuntivi durante il ridimensionamento. Per altre informazioni sulle operazioni di ridimensionamento, vedere questa guida.
Ridimensionamento dei nodi
Service Fabric supporta la scalabilità automatica per scalabilità orizzontale e scalabilità orizzontale. È possibile configurare ogni tipo di nodo per la scalabilità automatica in modo indipendente.
Ogni tipo di nodo può avere un massimo di 100 nodi. Iniziare con un set di nodi più piccolo e aggiungere altri nodi a seconda del carico. Se sono necessari più di 100 nodi in un tipo di nodo, sarà necessario aggiungere altri tipi di nodo. Per informazioni dettagliate, vedere Considerazioni sulla pianificazione della capacità del cluster di Service Fabric. Un set di scalabilità di macchine virtuali non viene ridimensionato istantaneamente, quindi considerare tale fattore quando si configurano le regole di scalabilità automatica.
Per supportare il ridimensionamento automatico, configurare il tipo di nodo in modo che abbia il livello di durabilità Silver o Gold. Questa configurazione garantisce che il ridimensionamento sia ritardato fino al termine della rilocazione dei servizi da parte di Service Fabric. Assicura inoltre che i set di scalabilità di macchine virtuali informino Service Fabric che le macchine virtuali vengono rimosse, non solo temporaneamente.
Per altre informazioni sul ridimensionamento a livello di nodo o cluster, vedere Ridimensionamento dei cluster di Azure Service Fabric.
Ridimensionamento dei servizi
I servizi senza stato e con stato applicano approcci diversi alla scalabilità.
Per un servizio senza stato (scalabilità automatica):
- Usare il trigger di caricamento medio della partizione. Questo trigger determina quando il servizio viene ridimensionato o ridotto in base a un valore di soglia di carico specificato nei criteri di ridimensionamento. È anche possibile impostare la frequenza con cui viene controllato il trigger. Vedere Trigger di caricamento medio delle partizioni con scalabilità basata su istanza. Questo approccio consente di aumentare il numero di nodi disponibili.
- Impostare
InstanceCountsu -1 nel manifesto del servizio, che indica a Service Fabric di eseguire un'istanza del servizio in ogni nodo. Questo approccio consente al servizio di ridimensionare dinamicamente quando il cluster viene ridimensionato. Man mano che cambia il numero di nodi nel cluster, Service Fabric crea ed elimina automaticamente le istanze del servizio in modo che corrispondano.
Nota
In alcuni casi, potrebbe essere necessario ridimensionare manualmente il servizio. Ad esempio, se si dispone di un servizio che legge da Hub eventi di Azure, è possibile che un'istanza dedicata venga letta da ogni partizione dell'hub eventi. In questo modo, è possibile evitare l'accesso simultaneo alla partizione.
Per un servizio con stato, il ridimensionamento è controllato dal numero di partizioni, dalle dimensioni di ogni partizione e dal numero di partizioni o repliche in esecuzione in un computer:
Se si creano servizi partizionati, assicurarsi che ogni nodo ottenga repliche adeguate per la distribuzione uniforme del carico di lavoro senza causare conflitti di risorse. Se si aggiungono altri nodi, Service Fabric distribuisce i carichi di lavoro nei nuovi computer per impostazione predefinita. Ad esempio, se sono presenti 5 nodi e 10 partizioni, Service Fabric inserisce due repliche primarie in ogni nodo per impostazione predefinita. Se si aumenta il numero di istanze dei nodi, è possibile ottenere prestazioni migliori perché il lavoro viene distribuito in modo uniforme tra più risorse.
Per informazioni sugli scenari che sfruttano questa strategia, vedere Ridimensionamento in Service Fabric.
L'aggiunta o la rimozione di partizioni non è supportata correttamente. Un'altra opzione comunemente usata per ridimensionare consiste nel creare o eliminare dinamicamente servizi o intere istanze dell'applicazione. Un esempio di questo modello è descritto in Ridimensionamento creando o rimuovendo nuovi servizi denominati.
Per altre informazioni, vedi:
- Ridimensionare un cluster di Service Fabric in o in uscita usando le regole di scalabilità automatica o manualmente
- Ridimensionare un cluster di Service Fabric a livello di codice
- Aumentare il numero di istanze di un cluster di Service Fabric aggiungendo un set di scalabilità di macchine virtuali
Uso delle metriche per bilanciare il carico
A seconda del modo in cui si progetta la partizione, potrebbero essere presenti nodi con repliche che ottengono più traffico rispetto ad altri. Per evitare questa situazione, partizionare lo stato del servizio in modo che venga distribuito in tutte le partizioni. Usare lo schema di partizionamento dell'intervallo con un algoritmo hash valido. Vedere Introduzione al partizionamento.
Service Fabric usa le metriche per sapere come posizionare e bilanciare i servizi all'interno di un cluster. È possibile specificare un carico predefinito per ogni metrica associata a un servizio al momento della creazione del servizio. Service Fabric prende quindi in considerazione questo carico quando si inserisce il servizio o ogni volta che il servizio deve spostarsi (ad esempio durante gli aggiornamenti), per bilanciare i nodi nel cluster.
Il carico predefinito specificato inizialmente per un servizio non cambierà per tutta la durata del servizio. Per acquisire la modifica delle metriche per un servizio, è consigliabile monitorare il servizio e quindi segnalare il carico in modo dinamico. Questo approccio consente a Service Fabric di modificare l'allocazione in base al carico segnalato in un determinato momento. Usare il metodo IServicePartition.ReportLoad per segnalare metriche personalizzate. Per altre informazioni, vedere Caricamento dinamico.
Disponibilità
Posizionare i servizi in un tipo di nodo diverso dal tipo di nodo primario. I servizi di sistema di Service Fabric vengono sempre distribuiti nel tipo di nodo primario. Se i servizi vengono distribuiti nel tipo di nodo primario, potrebbero competere con i servizi di sistema (e interferire con) per le risorse. Se si prevede che un tipo di nodo ospiti servizi con stato, assicurarsi che siano presenti almeno cinque istanze del nodo e che si selezioni il livello di durabilità Silver o Gold.
Valutare la possibilità di vincolare le risorse dei servizi. Vedere Meccanismo di governance delle risorse.
Ecco alcune considerazioni comuni:
- Non combinare servizi regolati dalle risorse e servizi che non sono regolati dalle risorse nello stesso tipo di nodo. I servizi non regolamentati potrebbero utilizzare troppe risorse e influire sui servizi regolamentati. Specificare i vincoli di posizionamento per assicurarsi che tali tipi di servizi non vengano eseguiti nello stesso set di nodi. (Questo è un esempio di Modello di intestazione bulk.
- Specificare i core CPU e la memoria da riservare per un'istanza del servizio. Per informazioni sull'utilizzo e sulle limitazioni dei criteri di governance delle risorse, vedere Governance delle risorse.
Per evitare un singolo punto di errore (SPOF), assicurarsi che il numero di istanze o repliche di destinazione di ogni servizio sia maggiore di uno. Il numero più grande che è possibile usare come istanza del servizio o numero di repliche è uguale al numero di nodi che vincolano il servizio.
Assicurarsi che ogni servizio con stato abbia almeno due repliche secondarie attive. È consigliabile usare cinque repliche per i carichi di lavoro di produzione.
Per altre informazioni, vedere Disponibilità dei servizi di Service Fabric.
Sicurezza
La sicurezza offre garanzie contro attacchi intenzionali e l'abuso di dati e sistemi preziosi. Per altre informazioni, vedere Panoramica del pilastro della sicurezza.
Ecco alcuni punti chiave per proteggere l'applicazione in Service Fabric.
Rete virtuale
Valutare la possibilità di definire i limiti della subnet per ogni set di scalabilità di macchine virtuali per controllare il flusso di comunicazione. Ogni tipo di nodo ha un proprio set di scalabilità di macchine virtuali in una subnet all'interno della rete virtuale del cluster di Service Fabric. È possibile aggiungere gruppi di sicurezza di rete alle subnet per consentire o rifiutare il traffico di rete. Ad esempio, con i tipi di nodo front-end e back-end, è possibile aggiungere un gruppo di sicurezza di rete alla subnet back-end per accettare il traffico in ingresso solo dalla subnet front-end.
Quando si chiamano servizi di Azure esterni dal cluster, usare gli endpoint servizio di rete virtuale se il servizio di Azure lo supporta. L'uso di un endpoint di servizio protegge il servizio solo per la rete virtuale del cluster.
Ad esempio, se si usa Azure Cosmos DB per archiviare i dati, configurare l'account Azure Cosmos DB con un endpoint di servizio per consentire l'accesso solo da una subnet specifica. Vedere Accedere alle risorse di Azure Cosmos DB dalle reti virtuali.
Endpoint e comunicazione tra servizi
Non creare un cluster di Service Fabric non protetto. Se il cluster espone gli endpoint di gestione alla rete Internet pubblica, gli utenti anonimi possono connettersi. I cluster non protetti non sono supportati per l'esecuzione di carichi di lavoro di produzione. Vedere Scenari di sicurezza del cluster di Service Fabric.
Per proteggere le comunicazioni tra servizi:
- Valutare la possibilità di abilitare gli endpoint HTTPS nei servizi Web ASP.NET Core o Java.
- Stabilire una connessione sicura tra il proxy inverso e i servizi. Per informazioni dettagliate, vedere Connettersi a un servizio sicuro.
Se si usa un gateway API, è possibile eseguire l'offload dell'autenticazione nel gateway. Assicurarsi che i singoli servizi non possano essere raggiunti direttamente (senza il gateway API), a meno che non siano presenti ulteriori sicurezza per autenticare i messaggi.
Non esporre pubblicamente il proxy inverso di Service Fabric. In questo modo tutti i servizi che espongono endpoint HTTP possono essere indirizzabili dall'esterno del cluster. Ciò introduce vulnerabilità di sicurezza e potenzialmente espone informazioni aggiuntive all'esterno del cluster inutilmente. Se si vuole accedere pubblicamente a un servizio, usare un gateway API. La sezione Gateway API più avanti in questo articolo descrive alcune opzioni.
Desktop remoto è utile per la diagnostica e la risoluzione dei problemi, ma assicurarsi di chiuderlo. Lasciandola aperta si verifica un buco di sicurezza.
Segreti e certificati
Archiviare segreti, ad esempio stringa di connessione agli archivi dati, in un insieme di credenziali delle chiavi. L'insieme di credenziali delle chiavi deve trovarsi nella stessa area del set di scalabilità di macchine virtuali. Per usare un insieme di credenziali delle chiavi:
Autenticare l'accesso del servizio all'insieme di credenziali delle chiavi.
Abilitare l'identità gestita nel set di scalabilità di macchine virtuali che ospita il servizio.
Archiviare i segreti nell'insieme di credenziali delle chiavi.
Aggiungere segreti in un formato che può essere convertito in una coppia chiave/valore. Ad esempio, usare
CosmosDB--AuthKey. Quando viene compilata la configurazione, il trattino doppio (--) viene convertito in due punti (:).Accedere a tali segreti nel servizio.
Aggiungere l'URI dell'insieme di credenziali delle chiavi nel file appSettings.json . Nel servizio aggiungere il provider di configurazione che legge dall'insieme di credenziali delle chiavi, compila la configurazione e accede al segreto dalla configurazione compilata.
Di seguito è riportato un esempio in cui il servizio Flusso di lavoro archivia un segreto nell'insieme di credenziali delle chiavi nel formato CosmosDB--Database.
namespace Fabrikam.Workflow.Service
{
public class ServiceStartup
{
public static void ConfigureServices(StatelessServiceContext context, IServiceCollection services)
{
var preConfig = new ConfigurationBuilder()
…
.AddJsonFile(context, "appsettings.json");
var config = preConfig.Build();
if (config["AzureKeyVault:KeyVaultUri"] is var keyVaultUri && !string.IsNullOrWhiteSpace(keyVaultUri))
{
preConfig.AddAzureKeyVault(keyVaultUri);
config = preConfig.Build();
}
}
}
Per accedere al segreto, specificare il nome del segreto nella configurazione compilata.
if(builtConfig["CosmosDB:Database"] is var database && !string.IsNullOrEmpty(database))
{
// Use the secret.
}
Non usare i certificati client per accedere a Service Fabric Explorer. Usare invece Microsoft Entra ID. Vedere Servizi di Azure che supportano l'autenticazione di Microsoft Entra.
Non usare certificati autofirmato per la produzione.
Protezione dei dati inattivi
Se i dischi dati sono stati collegati ai set di scalabilità di macchine virtuali del cluster di Service Fabric e i servizi salvano i dati in tali dischi, è necessario crittografare i dischi. Per altre informazioni, vedere Crittografare il sistema operativo e i dischi dati collegati in un set di scalabilità di macchine virtuali con Azure PowerShell (anteprima).
Per altre informazioni sulla protezione di Service Fabric, vedere:
- Panoramica della sicurezza di Azure Service Fabric
- Procedure consigliate per la sicurezza di Azure Service Fabric
- Elenco di controllo per la sicurezza di Azure Service Fabric
Resilienza
Per eseguire il ripristino da errori e mantenere uno stato completamente funzionante, l'applicazione deve implementare determinati modelli di resilienza. Ecco alcuni modelli comuni:
- Riprova: per gestire gli errori che si prevede siano temporanei, ad esempio le risorse temporaneamente non disponibili.
- Interruttore: per risolvere gli errori che potrebbero richiedere più tempo per risolvere i problemi.
- Intestazione bulk: per isolare le risorse per ogni servizio.
Questa implementazione di riferimento usa Polly, un'opzione open source, per implementare tutti questi modelli.
Monitoraggio
Prima di esplorare le opzioni di monitoraggio, è consigliabile leggere questo articolo sulla diagnosi di scenari comuni con Service Fabric. È possibile considerare i dati di monitoraggio in questi set:
- Metriche e log dell'applicazione
- Dati sull'integrità e sugli eventi di Service Fabric
- Metriche e log dell'infrastruttura
- Metriche e log per i servizi dipendenti
Queste sono le due opzioni principali per l'analisi dei dati:
- Application Insights
- Log Analytics
È possibile usare Monitoraggio di Azure per configurare i dashboard per il monitoraggio e inviare avvisi agli operatori. Alcuni strumenti di monitoraggio di terze parti sono integrati anche con Service Fabric, ad esempio Dynatrace. Per informazioni dettagliate, vedere Partner di monitoraggio di Azure Service Fabric.
Metriche e log dell'applicazione
I dati di telemetria dell'applicazione consentono di monitorare l'integrità del servizio e identificare i problemi. Per aggiungere tracce ed eventi nel servizio:
- Usare Microsoft.Extensions.Logging se si sviluppa il servizio con ASP.NET Core. Per altri framework, usare una libreria di registrazione di propria scelta, ad esempio Serilog.
- Aggiungere la propria strumentazione usando la classe TelemetryClient nell'SDK e visualizzare i dati in Application Insights. Vedere Aggiungere strumentazione personalizzata all'applicazione.
- Registrare eventi di Traccia eventi per Windows (ETW) tramite EventSource. Questa opzione è disponibile per impostazione predefinita in una soluzione di Visual Studio Service Fabric.
Application Insights offre molti dati di telemetria predefiniti: richieste, tracce, eventi, eccezioni, metriche, dipendenze. Se il servizio espone endpoint HTTP, abilitare Application Insights chiamando il UseApplicationInsights metodo di estensione per Microsoft.AspNetCore.Hosting.IWebHostBuilder. Per informazioni sulla strumentazione del servizio per Application Insights, vedere gli articoli seguenti:
- Esercitazione: Monitorare e diagnosticare un'applicazione ASP.NET Core in Service Fabric usando Application Insights
- Application Insights per ASP.NET Core
- Application Insights .NET SDK
- Application Insights SDK per Service Fabric
Per visualizzare le tracce e i log eventi, usare Application Insights come uno dei sink per la registrazione strutturata. Configurare Application Insights con la chiave di strumentazione chiamando il AddApplicationInsights metodo di estensione. In questo esempio la chiave di strumentazione viene archiviata come segreto nell'insieme di credenziali delle chiavi.
.ConfigureLogging((hostingContext, logging) =>
{
logging.AddApplicationInsights(hostingContext.Configuration ["ApplicationInsights:InstrumentationKey"]);
})
Se il servizio non espone endpoint HTTP, è necessario scrivere un'estensione personalizzata che invia tracce ad Application Insights. Per un esempio, vedere il servizio Flusso di lavoro nell'implementazione di riferimento.
ASP.NET Servizi di base usano l'interfaccia ILogger per la registrazione delle applicazioni. Per rendere disponibili questi log applicazioni in Monitoraggio di Azure, inviare gli ILogger eventi ad Application Insights. Application Insights può aggiungere proprietà di correlazione agli ILogger eventi, utile per la visualizzazione della traccia distribuita.
Per altre informazioni, vedi:
Dati sull'integrità e sugli eventi di Service Fabric
I dati di telemetria di Service Fabric includono metriche ed eventi di integrità relativi all'operazione e alle prestazioni di un cluster di Service Fabric e alle relative entità: nodi, applicazioni, servizi, partizioni e repliche. I dati sull'integrità e sugli eventi possono provenire da:
EventStore. Questo servizio di sistema con stato raccoglie gli eventi correlati al cluster e alle relative entità. Service Fabric usa EventStore per scrivere eventi di Service Fabric per fornire informazioni sul cluster per gli aggiornamenti dello stato, la risoluzione dei problemi e il monitoraggio. EventStore può anche correlare eventi di entità diverse in un determinato momento per identificare i problemi nel cluster. Il servizio espone tali eventi tramite un'API REST.
Per informazioni su come eseguire query sulle API eventstore, vedere Eseguire query sulle API eventstore per gli eventi del cluster. È possibile visualizzare gli eventi da EventStore in Log Analytics configurando il cluster con l'estensione Diagnostica di Azure per Windows (WAD).
HealthStore. Questo servizio con stato fornisce uno snapshot dell'integrità corrente del cluster. Aggrega tutti i dati di integrità segnalati dalle entità in una gerarchia. I dati vengono visualizzati in Service Fabric Explorer. HealthStore monitora anche gli aggiornamenti delle applicazioni. È possibile usare query di integrità in PowerShell, in un'applicazione .NET o in API REST. Vedere Introduzione al monitoraggio dell'integrità di Service Fabric.
Report di integrità personalizzati. Prendere in considerazione l'implementazione di servizi watchdog interni in grado di segnalare periodicamente dati di integrità personalizzati, ad esempio gli stati difettosi dei servizi in esecuzione. È possibile leggere i report di integrità in Service Fabric Explorer.
Metriche e registri dell'infrastruttura
Le metriche dell'infrastruttura consentono di comprendere l'allocazione delle risorse nel cluster. Ecco le opzioni principali per raccogliere queste informazioni:
- WAD. Raccogliere log e metriche a livello di nodo in Windows. È possibile usare WAD configurando l'estensione vm IaaSDiagnostics in qualsiasi set di scalabilità di macchine virtuali mappato a un tipo di nodo per raccogliere gli eventi di diagnostica. Questi eventi possono includere registri eventi di Windows, contatori delle prestazioni, sistema ETW/manifesto ed eventi operativi e log personalizzati.
- Agente di Log Analytics. Configurare l'estensione macchina virtuale MicrosoftMonitoringAgent per inviare log eventi di Windows, contatori delle prestazioni e log personalizzati a Log Analytics.
Esistono alcune sovrapposizioni nei tipi di metriche raccolti tramite i meccanismi precedenti, ad esempio i contatori delle prestazioni. In caso di sovrapposizione, è consigliabile usare l'agente di Log Analytics. Poiché l'agente di Log Analytics non usa l'archiviazione di Azure, la latenza è bassa. Inoltre, i contatori delle prestazioni in IaaSDiagnostics non possono essere inseriti facilmente in Log Analytics.
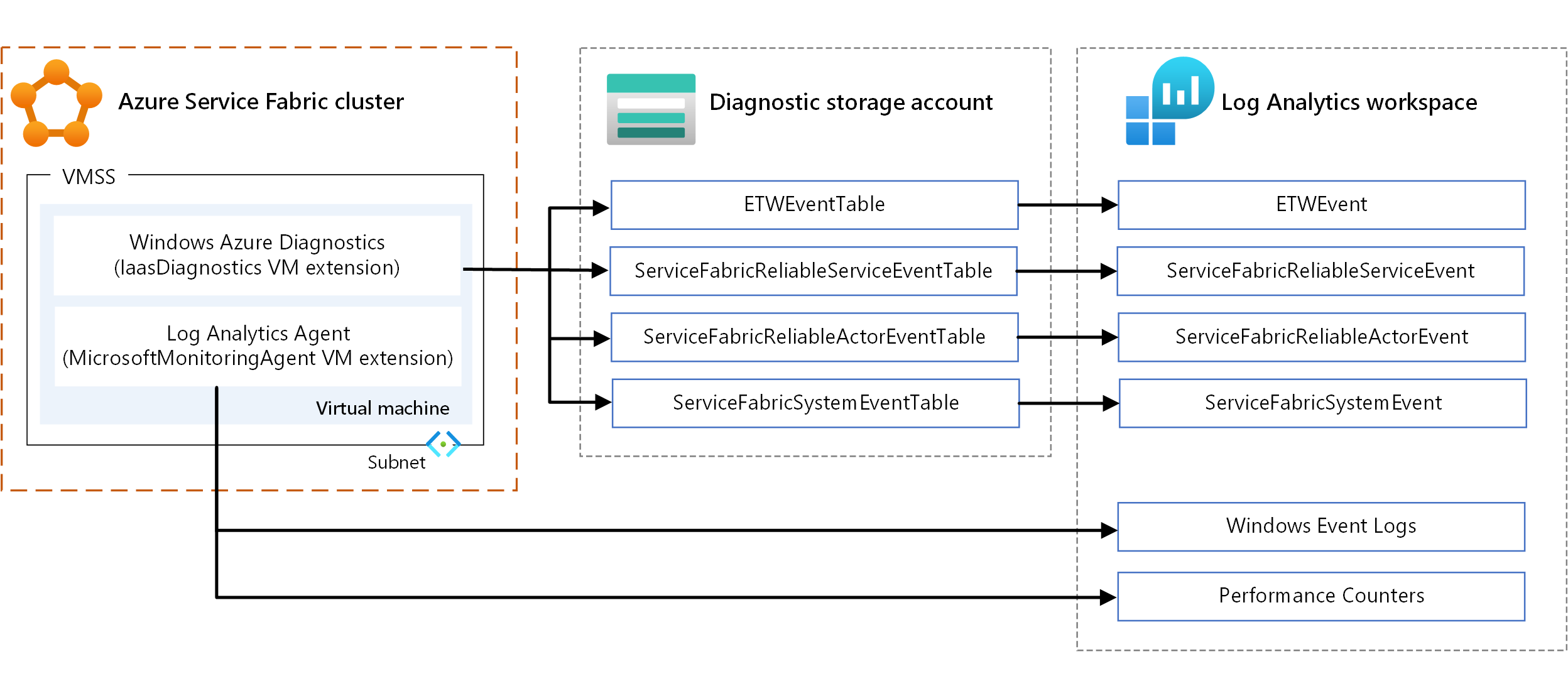
Per informazioni sull'uso delle estensioni della macchina virtuale, vedere Estensioni e funzionalità delle macchine virtuali di Azure.
Per visualizzare i dati, configurare Log Analytics per visualizzare i dati raccolti tramite WAD. Per informazioni su come configurare Log Analytics per leggere gli eventi da un account di archiviazione, vedere Configurare Log Analytics per un cluster.
È anche possibile visualizzare i log delle prestazioni e i dati di telemetria correlati a un cluster di Service Fabric, carichi di lavoro, traffico di rete, aggiornamenti in sospeso e altro ancora. Vedere Monitoraggio delle prestazioni con Log Analytics.
La soluzione Mapping dei servizi in Log Analytics fornisce informazioni sulla topologia del cluster, ovvero i processi in esecuzione in ogni nodo. Inviare i dati nell'account di archiviazione ad Application Insights. Potrebbe verificarsi un ritardo nel recupero dei dati in Application Insights. Se si vogliono visualizzare i dati in tempo reale, è consigliabile configurare Hub eventi usando sink e canali. Per altre informazioni, vedere Aggregazione e raccolta di eventi tramite WAD.
Metriche del servizio dipendente
- Mapping delle applicazioni in Application Insights fornisce la topologia dell'applicazione usando chiamate di dipendenza HTTP effettuate tra i servizi, con Application Insights SDK installato.
- Mapping dei servizi in Log Analytics fornisce informazioni sul traffico in ingresso e in uscita da e verso servizi esterni. Mapping dei servizi si integra con altre soluzioni, ad esempio aggiornamenti o sicurezza.
- I watchdog personalizzati possono segnalare condizioni di errore nei servizi esterni. Ad esempio, il servizio può fornire un report sull'integrità degli errori se non riesce ad accedere a un servizio esterno o a un'archiviazione dati (Azure Cosmos DB).
Traccia distribuita
In un'architettura di microservizi, diversi servizi spesso partecipano per completare un'attività. I dati di telemetria di ognuno di questi servizi vengono correlati tramite campi di contesto(ad esempio ID operazione e ID richiesta) in una traccia distribuita.
Usando La mappa delle applicazioni in Application Insights, è possibile creare la visualizzazione delle operazioni logiche distribuite e visualizzare l'intero grafico dei servizi dell'applicazione. È anche possibile usare la diagnostica delle transazioni in Application Insights per correlare i dati di telemetria lato server. Per altre informazioni, vedere Diagnostica delle transazioni tra componenti unificati.
È anche importante correlare le attività inviate in modo asincrono usando una coda. Per informazioni dettagliate sull'invio di dati di telemetria di correlazione in un messaggio della coda, vedere Strumentazione coda.
Per altre informazioni, vedi:
Avvisi e dashboard
Application Insights e Log Analytics supportano un linguaggio di query completo (linguaggio di query Kusto) che consente di recuperare e analizzare i dati di log. Usare le query per creare set di dati e visualizzarli nei dashboard di diagnostica.
Usare gli avvisi di Monitoraggio di Azure per notificare agli amministratori di sistema quando si verificano determinate condizioni in risorse specifiche. La notifica può essere un messaggio di posta elettronica, una funzione di Azure o un webhook, ad esempio. Per altre informazioni, vedere Avvisi in Monitoraggio di Azure.
Le regole di avviso di ricerca log consentono di definire ed eseguire una query Kusto su un'area di lavoro Log Analytics a intervalli regolari. Viene creato un avviso se il risultato della query corrisponde a una determinata condizione.
Ottimizzazione dei costi
Usare il calcolatore dei prezzi di Azure per stimare i costi. Altre considerazioni sono descritte nel pilastro dell'ottimizzazione dei costi di Microsoft Azure Well-Architected Framework.
Ecco alcuni punti da considerare per alcuni dei servizi usati in questa architettura.
Azure Service Fabric
Vengono addebitati i costi per le istanze di calcolo, l'archiviazione, le risorse di rete e gli indirizzi IP scelti durante la creazione di un cluster di Service Fabric. Sono previsti addebiti per la distribuzione per Service Fabric.
Set di scalabilità di macchine virtuali
In questa architettura i microservizi vengono distribuiti in nodi che sono set di scalabilità di macchine virtuali. Vengono addebitati i costi per le macchine virtuali di Azure distribuite come parte del cluster e delle risorse dell'infrastruttura sottostanti, ad esempio archiviazione e rete. Non sono previsti addebiti incrementali per i set di scalabilità di macchine virtuali stessi.
Gestione API di Azure
Azure Gestione API è un gateway per instradare le richieste dai client ai servizi nel cluster.
Sono disponibili diverse opzioni di prezzo. L'opzione Consumo viene addebitata in base al consumo e include un componente gateway. In base al carico di lavoro, scegliere un'opzione descritta in prezzi Gestione API.
Application Insights
È possibile usare Application Insights per raccogliere dati di telemetria per tutti i servizi e per visualizzare le tracce e i log eventi in modo strutturato. I prezzi per Application Insights sono un modello con pagamento in base al consumo basato su volume di dati inseriti e opzioni per la conservazione dei dati. Per altre informazioni, vedere Gestire l'utilizzo e i costi per Application Insights.
Monitoraggio di Azure
Per Log Analytics di Monitoraggio di Azure, vengono addebitati costi per l'inserimento e la conservazione dei dati. Per altre informazioni, vedere Prezzi di Monitoraggio di Azure.
Azure Key Vault
Si usa Azure Key Vault per archiviare la chiave di strumentazione per Application Insights come segreto. Azure offre Key Vault in due livelli di servizio. Se non sono necessarie chiavi protette dal modulo di protezione hardware, scegliere il livello Standard. Per informazioni sulle funzionalità in ogni livello, vedere Prezzi di Key Vault.
Servizi di Azure DevOps
Questa architettura di riferimento usa Azure Pipelines per la distribuzione. Il servizio Azure Pipelines consente un processo ospitato gratuitamente da Microsoft con 1.800 minuti al mese per CI/CD e un processo self-hosted con minuti illimitati al mese. Sono previsti costi aggiuntivi per i processi. Per altre informazioni, vedere Prezzi di Azure DevOps Services.
Per considerazioni su DevOps in un'architettura di microservizi, vedere CI/CD per i microservizi.
Per informazioni su come distribuire un'applicazione contenitore con CI/CD in un cluster di Service Fabric, vedere questa esercitazione.
Distribuire lo scenario
Per distribuire l'implementazione di riferimento per questa architettura, seguire la procedura descritta nel repository GitHub.
Passaggi successivi
- Training: Introduzione ad Azure Service Fabric
- Panoramica di Azure Service Fabric
- Documentazione di Gestione API
- Che cos'è Azure Pipelines?