Introduzione al monitoraggio dell'integrità di Service Fabric
Con Azure Service Fabric è stato introdotto un modello di integrità che offre funzionalità di valutazione e reporting dell'integrità dettagliate, flessibili ed estendibili. Il modello include il monitoraggio quasi in tempo reale dello stato del cluster e dei servizi in esso eseguiti. Questo consente di ottenere facilmente informazioni relative all'integrità e correggere i potenziali problemi prima che si propaghino a catena e causino un numero elevato di interruzioni. Nel modello tipico i servizi inviano report basati sulla situazione locale e le informazioni vengono aggregate per fornire una panoramica generale a livello di cluster.
I componenti di Service Fabric usano questo dettagliato modello di integrità per segnalare il proprio stato corrente ed è possibile avvalersi dello stesso meccanismo per segnalare l'integrità delle proprie applicazioni. Investendo nella creazione di report sull'integrità di alta qualità con acquisizione delle proprie condizioni personalizzate, è possibile rilevare e risolvere i problemi dell'applicazione in esecuzione con maggiore facilità.
Nota
Il sottosistema di integrità è stato introdotto per rispondere alla necessità di aggiornamenti monitorati. Service Fabric offre aggiornamenti monitorati delle applicazioni e dei cluster che garantiscono disponibilità completa, senza tempi di inattività e con un intervento minimo o addirittura nessun intervento da parte dell'utente. Per raggiungere questi obiettivi, l'aggiornamento controlla l'integrità in base ai criteri di aggiornamento configurati. Un aggiornamento può continuare solo quando l'integrità rientra nelle soglie desiderate. In caso contrario, l'aggiornamento viene sottoposto a rollback o sospeso automaticamente per consentire agli amministratori di risolvere il problema. Per altre informazioni sugli aggiornamenti delle applicazioni, vedere questo articolo.
Archivio integrità
L'archivio integrità mantiene le informazioni di integrità relative alle entità del cluster per facilitarne il recupero e la valutazione. Viene implementato come servizio con stato persistente di Service Fabric per garantire la scalabilità e una disponibilità elevata. L'archivio integrità fa parte dell'applicazione fabric:/System ed è disponibile quando il cluster è operativo.
Entità e gerarchia di integrità
Le entità di integrità sono organizzate in una gerarchia logica che acquisisce le interazioni e le dipendenze tra le diverse entità. L'archivio integrità crea automaticamente la gerarchia e le entità di integrità in base ai report ricevuti dai componenti di Service Fabric.
Le entità di integrità corrispondono alle entità di Service Fabric. Ad esempio, un'entità applicazione di integrità corrisponde a un'istanza di applicazione distribuita nel cluster, mentre un'entità nodo di integrità corrisponde a un nodo del cluster di Service Fabric. La gerarchia di integrità acquisisce le interazioni delle entità di sistema e costituisce la base per una valutazione avanzata dell'integrità. Per informazioni sui concetti chiave di Service Fabric, vedere la panoramica tecnica di Service Fabric. Per altre informazioni sull'applicazione, vedere il modello di applicazione di Service Fabric.
Le entità e la gerarchia di integrità consentono di eseguire in modo efficace la creazione di report, il debug e il monitoraggio del cluster e delle applicazioni. Il modello di integrità offre un'accurata rappresentazione granulare dell'integrità dei numerosi elementi mobili all'interno del cluster.
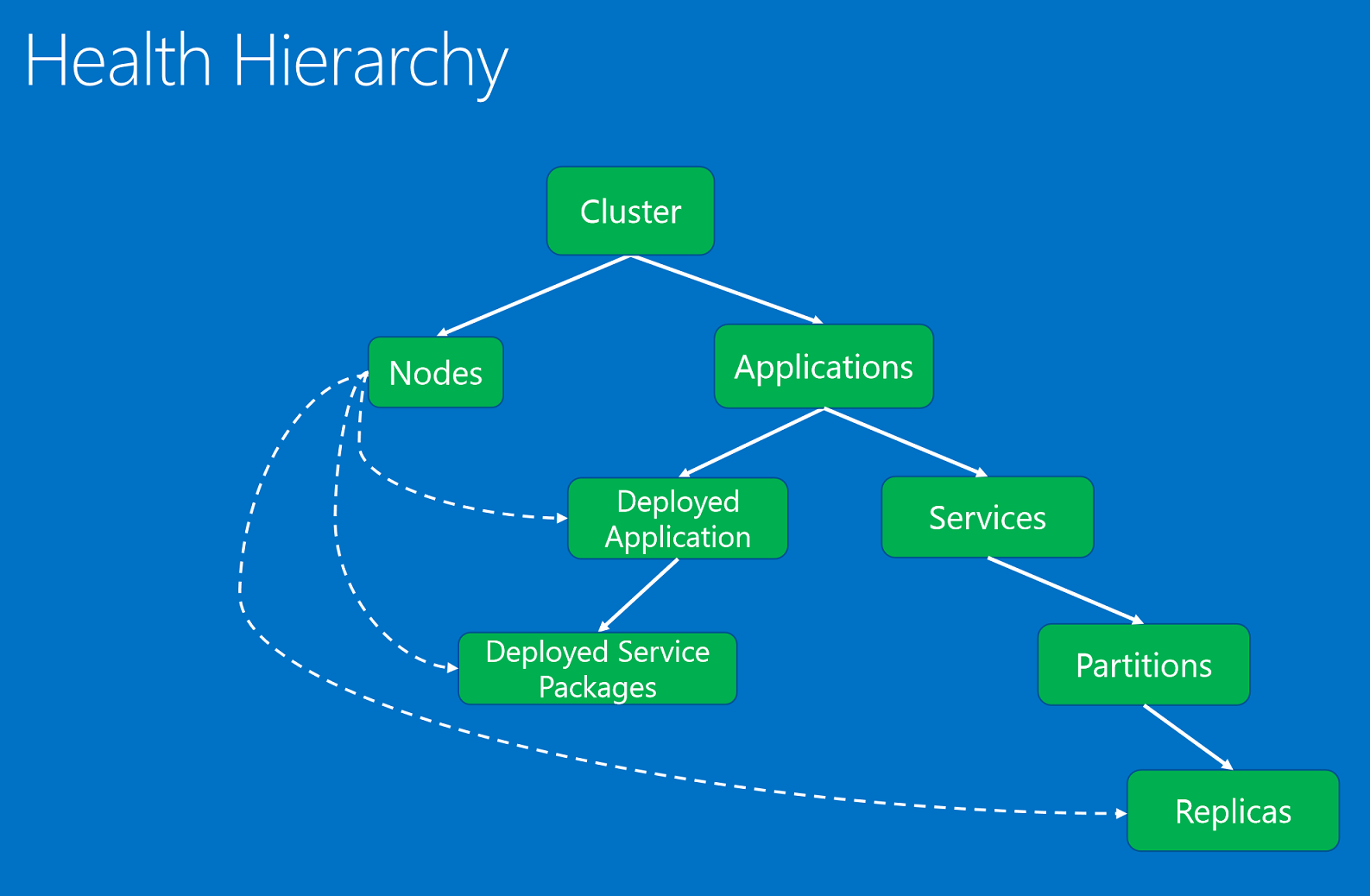 Entità di integrità, organizzate in una gerarchia basata su relazioni padre-figlio.
Entità di integrità, organizzate in una gerarchia basata su relazioni padre-figlio.
Le entità di integrità sono le seguenti:
- Cluster. Rappresenta l'integrità di un cluster di Service Fabric. I report sull'integrità del cluster illustrano le condizioni che interessano l'intero cluster. Queste condizioni interessano più entità nel cluster o il cluster stesso. In base alla condizione, il reporter non può restringere il problema a uno o più elementi figlio non integri. ad esempio lo split brain del cluster a causa di problemi di comunicazione o di partizionamento della rete.
- Node. Rappresenta l'integrità di un nodo di Service Fabric. I report sull'integrità del nodo illustrano le condizioni che influiscono sulla funzionalità del nodo. In genere influiscono su tutte le entità distribuite in esecuzione su di esso. Ad esempio, un nodo con spazio su disco non sufficiente o con problemi relativi ad altre proprietà a livello di computer, come la memoria o le connessioni, oppure la presenza di un nodo non attivo. L'entità nodo è identificata dal nome del nodo (stringa).
- Applicazione. Rappresenta l'integrità di un'istanza di applicazione in esecuzione nel cluster. I report sull'integrità dell'applicazione illustrano le condizioni che influiscono sull'integrità generale dell'applicazione e non possono essere limitati a singoli elementi figlio, servizi o applicazioni distribuite. Ad esempio, indicano l'interazione end-to-end tra diversi servizi nell'applicazione. L'entità applicazione è identificata dal nome dell'applicazione (URI).
- Servizi. Rappresenta l'integrità di un servizio in esecuzione nel cluster. I report sull'integrità del servizio illustrano le condizioni che interessano l'integrità generale del servizio. Il reporter non può restringere il problema a una partizione o una replica non integra. Ad esempio, indicano una configurazione del servizio, una porta o una condivisione file esterna, che causa problemi a tutte le partizioni. L'entità servizio è identificata dal nome del servizio (URI).
- Partizione. Rappresenta l'integrità di una partizione del servizio. I report sull'integrità della partizione illustrano le condizioni che influiscono sull'intero set di repliche. Ad esempio, indicano quando un numero di repliche è al di sotto del conteggio target o quando una partizione mostra una perdita di quorum. L'entità partizione è identificata dall'ID partizione (GUID).
- Replica. Rappresenta l'integrità di una replica di un servizio con stato o di un'istanza di un servizio senza stato. La replica è l'unità più piccola di cui i watchdog e i componenti di sistema possono segnalare la condizione per un'applicazione. Nel caso di servizi con stato, ad esempio, una replica primaria che non è in grado di replicare le operazioni nelle repliche secondarie oppure un processo di replica lento. Un'istanza senza stato può segnalare se le risorse si stanno esaurendo o se presenta problemi di connettività. L'entità replica è identificata dall'ID partizione (GUID) e dall'ID replica o dall'ID istanza (long).
- Applicazione distribuita. Rappresenta l'integrità di un' applicazione in esecuzione in un nodo. I report sull'integrità dell'applicazione distribuita illustrano le condizioni specifiche dell'applicazione nel nodo che non possono essere ricondotte ai pacchetti servizio distribuiti nello stesso nodo. Ad esempio, errori a causa dei quali non è possibile scaricare il pacchetto dell'applicazione nel nodo e problemi di configurazione delle entità di sicurezza dell'applicazione nel nodo. L'applicazione distribuita è identificata dal nome dell'applicazione (URI) e dal nome del nodo (stringa).
- Pacchetto servizio distribuito. Rappresenta l'integrità di un pacchetto servizio in esecuzione in un nodo del cluster. Illustra le condizioni specifiche di un pacchetto servizio che non influiscono sugli altri pacchetti servizio nello stesso nodo per la stessa applicazione. Ad esempio, indica che non è possibile avviare un pacchetto di codice nel pacchetto del servizio o leggere un pacchetto di configurazione. Il pacchetto del servizio distribuito è identificato dal nome dell'applicazione (URI), dal nome del nodo (stringa), dal nome del manifesto del servizio (stringa) e dall'ID di attivazione del pacchetto del servizio (stringa).
La granularità del modello di integrità facilita il rilevamento e l'eliminazione dei problemi. Ad esempio, se un servizio non risponde, è possibile segnalare che l'istanza dell'applicazione non è integra. La segnalazione a tale livello non è tuttavia l'approccio ideale, perché il problema potrebbe non riguardare tutti i servizi all'interno dell'applicazione. Il report dovrebbe essere applicato al servizio non integro oppure a una partizione figlio specifica a cui eventualmente puntano altre informazioni. I dati vengono esposti automaticamente attraverso la gerarchia e la partizione non integra sarà visibile a livello di servizio e di applicazione. Questa aggregazione di individuare e risolvere più rapidamente la causa radice del problema.
La gerarchia di integrità è costituita da relazioni padre-figlio. Un cluster è costituito da nodi e applicazioni. Le applicazioni hanno servizi e applicazioni distribuite e le applicazioni distribuite hanno pacchetti del servizio distribuiti. I servizi dispongono di partizioni e ogni partizione dispone di una o più repliche. Tra i nodi e le entità distribuite esiste una relazione speciale. Un nodo non integro in base alla segnalazione effettuata dal relativo componente di sistema autorevole (servizio Gestione failover) influisce sulle applicazioni distribuite, sui pacchetti del servizio e sulle repliche distribuite.
La gerarchia di integrità rappresenta lo stato più recente del sistema in base agli ultimi report sull'integrità, che forniscono informazioni quasi in tempo reale. I watchdog interni ed esterni possono segnalare la condizione delle stesse entità in base alla logica specifica dell'applicazione o a condizioni monitorate personalizzate. I report utente coesistono con i report di sistema.
Durante la progettazione di un servizio cloud di grandi dimensioni, pianificare un investimento per i report e gli interventi relativi all'integrità. Questo investimento iniziale semplifica il debug, il monitoraggio e la gestione del servizio.
Stati di integrità
Service Fabric usa tre stati di integrità per indicare se un'entità è integra o meno: OK, Warning ed Error. Tutti i report inviati all'archivio integrità devono specificare uno di questi stati. Come risultato della valutazione dell'integrità viene restituito uno di tali stati.
I possibili stati di integrità sono:
- OK. L'entità è integra. Non vengono segnalati problemi noti per l'entità o i relativi elementi figlio (se esistenti).
- Avviso. L'entità ha alcuni problemi, ma può comunque funzionare correttamente. Ad esempio, si verificano ritardi che però non causano ancora problemi funzionali. In alcuni casi, la condizione di avviso potrebbe risolversi automaticamente senza l'intervento esterno. In questi casi, i report sull'integrità forniscono informazioni e visibilità sulla situazione. In altri casi tale condizione può trasformarsi in un problema serio senza l'intervento dell'utente.
- Errore. L'entità non è integra. È necessario intervenire per correggere lo stato dell'entità, che non può funzionare correttamente.
- Sconosciuto. L'entità non è presente nell'archivio integrità. È possibile ottenere questo risultato dalle query distribuite che uniscono i risultati da più componenti. Ad esempio, la query per ottenere l'elenco dei nodi passa a FailoverManager, ClusterManager e HealthManager, mentre la query per ottenere l'elenco delle applicazioni passa a ClusterManager e HealthManager. Tali query uniscono i risultati provenienti da più componenti di sistema. Se un altro componente di sistema restituisce un'entità non presente nell'archivio integrità, il risultato unito ha uno stato di integrità sconosciuto. Un'entità non è nell'archivio perché non sono ancora stati elaborati i report sull'integrità o è stata eseguita la pulizia dell'entità dopo l'eliminazione.
Criteri di integrità
L'archivio integrità applica criteri di integrità per determinare se un'entità è integra in base ai relativi report e agli elementi figlio.
Nota
I criteri di integrità possono essere specificati nel manifesto del cluster, per la valutazione dell'integrità del cluster e dei nodi, o nel manifesto dell'applicazione, per la valutazione dell'applicazione e degli eventuali elementi figlio. Le richieste di valutazione dell'integrità possono anche passare criteri personalizzati, usati solo per la valutazione in questione.
Per impostazione predefinita, per la relazione gerarchica padre-figlio Service Fabric applica regole severe, in base alle quali tutti gli elementi devono essere integri. Se anche uno solo degli elementi figlio presenta un evento non integro, l'elemento padre è considerato non integro.
Criteri di integrità del cluster
I criteri di integrità del cluster vengono usati per valutare lo stato di integrità del cluster e dei nodi. e possono essere definiti nel manifesto del cluster. Se non sono definiti, vengono usati i criteri predefiniti, in base ai quali non sono tollerati errori.
I criteri di integrità del cluster includono:
ConsiderWarningAsError. Specifica se considerare i report sull'integrità di tipo Warning come errori durante la valutazione dell'integrità. Valore predefinito: false.
MaxPercentUnhealthyApplications. Specifica la percentuale massima tollerata di applicazioni che possono risultare non integre prima che per il cluster venga impostato lo stato Error.
MaxPercentUnhealthyNodes. Specifica la percentuale massima tollerata di nodi che possono risultare non integri prima che per il cluster venga impostato lo stato Error. Questa percentuale dovrà essere configurata in modo da tenere conto del fatto che in cluster di grandi dimensioni sono sempre presenti nodi inattivi o in fase di riparazione.
ApplicationTypeHealthPolicyMap. La mappa dei criteri di integrità dei tipi di applicazioni può essere usata durante la valutazione dell'integrità del cluster per descrivere i tipi di applicazioni speciali. Per impostazione predefinita, tutte le applicazioni vengono inserite in un pool e valutate con MaxPercentUnhealthyApplications. I tipi di applicazioni che devono essere trattati in modo diverso possono essere estratti dal pool globale ed essere invece valutati in base alle percentuali associate al nome del tipo di applicazione nella mappa. Ad esempio, in un cluster esistono migliaia di applicazioni di tipi diversi e alcune istanze di applicazioni di controllo di un tipo di applicazione speciale. Le applicazioni di controllo non devono mai riscontrare errori. È possibile specificare l'impostazione globale di MaxPercentUnhealthyApplications al 20% per tollerare alcuni errori, impostando però MaxPercentUnhealthyApplications su 0 per il tipo di applicazione "ControlApplicationType". In questo modo, se alcune delle numerose applicazioni non sono integre, ma si trovano al di sotto della percentuale di non integrità globale, il cluster verrà valutato come Warning. Uno stato di integrità Warning non influisce sull'aggiornamento del cluster o su altri tipi di monitoraggio attivati dallo stato di integrità Error. Una sola applicazione di controllo in errore rende tuttavia il cluster non integro attivando, a seconda della configurazione di aggiornamento, il ripristino dello stato precedente o la sospensione dell'aggiornamento. Per i tipi di applicazioni definiti nella mappa, tutte le istanze delle applicazioni vengono estratte dal pool globale di applicazioni. Vengono valutate in base al numero totale di applicazioni del tipo di applicazione, usando il valore MaxPercentUnhealthyApplications specifico della mappa. Tutte le altre applicazioni rimangono nel pool globale e vengono valutate con MaxPercentUnhealthyApplications.
L'esempio seguente è un estratto del manifesto di un cluster. Per definire le voci nella mappa dei tipi di applicazioni, anteporre "ApplicationTypeMaxPercentUnhealthyApplications-" al nome del parametro, seguito dal nome del tipo di applicazione.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="ApplicationTypeMaxPercentUnhealthyApplications-ControlApplicationType" Value="0" /> </Section> </FabricSettings>NodeTypeHealthPolicyMap. La mappa dei criteri di integrità dei tipi di nodi può essere usata durante la valutazione dell'integrità del cluster per descrivere i tipi di nodi speciali. I tipi di nodi vengono valutati in base alle percentuali associate al nome del tipo di nodo nella mappa. L'impostazione di questo valore non ha alcun effetto sul pool globale di nodi usati perMaxPercentUnhealthyNodes. Ad esempio, un cluster ha centinaia di nodi di tipi diversi e alcuni tipi di nodo che ospitano un lavoro importante. Nessun nodo in tale tipo deve essere inattivo. È possibile impostare il valoreMaxPercentUnhealthyNodesglobale sul 20% per tollerare alcuni errori per tutti i nodi, ma per il tipo di nodoSpecialNodeType, impostareMaxPercentUnhealthyNodessu 0. In questo modo, se alcuni dei numerosi nodi non sono integri, ma si trovano al di sotto della percentuale di non integrità globale, il cluster verrà valutato come se fosse nello stato di integrità Warning. Uno stato di integrità Warning non influisce sull'aggiornamento del cluster o su altri tipi di monitoraggio attivati da uno stato di integrità Error. Un solo nodo di tipoSpecialNodeTypein uno stato di integrità Error rende tuttavia il cluster non integro e attiva, a seconda della configurazione di aggiornamento, il ripristino dello stato precedente o la sospensione dell'aggiornamento. Al contrario, l'impostazione del valoreMaxPercentUnhealthyNodesglobale su 0 e l'impostazione della percentuale massima diSpecialNodeTypesu 100 per i nodi non integri con un nodo di tipoSpecialNodeTypein uno stato di errore, il cluster si troverebbe comunque in uno stato di errore perché in questo caso la restrizione globale è più rigorosa.L'esempio seguente è un estratto del manifesto di un cluster. Per definire le voci nella mappa dei tipi di nodo, anteporre al nome del parametro il prefisso "NodeTypeMaxPercentUnhealthyNodes-", seguito dal nome del tipo di nodo.
<FabricSettings> <Section Name="HealthManager/ClusterHealthPolicy"> <Parameter Name="ConsiderWarningAsError" Value="False" /> <Parameter Name="MaxPercentUnhealthyApplications" Value="20" /> <Parameter Name="MaxPercentUnhealthyNodes" Value="20" /> <Parameter Name="NodeTypeMaxPercentUnhealthyNodes-SpecialNodeType" Value="0" /> </Section> </FabricSettings>
Criteri di integrità dell'applicazione
I criteri di integrità delle applicazioni descrivono come viene eseguita la valutazione dell'aggregazione degli eventi e degli stati degli elementi figlio per le applicazioni e i relativi elementi figlio. Possono essere definiti nel manifesto delle applicazioni, ApplicationManifest.xml, nel pacchetto delle applicazioni. Se non vengono specificati criteri, Service Fabric considera l'entità come non integra se presenta un report sull'integrità o un elemento figlio con stato Warning o Error. I criteri configurabili sono i seguenti:
- ConsiderWarningAsError. Specifica se considerare i report sull'integrità di tipo Warning come errori durante la valutazione dell'integrità. Valore predefinito: false.
- MaxPercentUnhealthyDeployedApplications. Specifica la percentuale massima tollerata di applicazioni distribuite che possono risultare non integre prima che per l'applicazione venga impostato lo stato Error. Tale percentuale viene calcolata dividendo il numero delle applicazioni distribuite non integre per il numero dei nodi in cui tali applicazioni sono attualmente distribuite nel cluster. Il calcolo viene arrotondato per eccesso per tollerare un errore su un numero limitato di nodi. Percentuale predefinita: zero.
- DefaultServiceTypeHealthPolicy. Specifica i criteri di integrità predefiniti per il tipo di servizio, che sostituiscono i criteri di integrità predefiniti usati per tutti i tipi di servizi nell'applicazione.
- ServiceTypeHealthPolicyMap. Fornisce una mappa dei criteri di integrità del servizio per tipo di servizio. Questi criteri sostituiscono i criteri di integrità del tipo di servizio predefiniti per ogni tipo di servizio specificato. Se un'applicazione include un tipo di servizio gateway senza stato e un tipo di servizio motore con stato, ad esempio, è possibile configurare in modo diverso i criteri di integrità per la relativa valutazione. Specificando i criteri in base al tipo di servizio è possibile ottenere un controllo più granulare sull'integrità del servizio.
Criteri di integrità del tipo di servizio
I criteri di integrità dei tipi di servizi specificano come valutare e aggregare i servizi e i relativi elementi figlio. I criteri includono:
- MaxPercentUnhealthyPartitionsPerService. Specifica la percentuale massima tollerata di partizioni che possono risultare non integre prima che un servizio venga considerato non integro. Percentuale predefinita: zero.
- MaxPercentUnhealthyReplicasPerPartition. Specifica la percentuale massima tollerata di repliche che possono risultare non integre prima che una partizione venga considerata non integra. Percentuale predefinita: zero.
- MaxPercentUnhealthyServices. Specifica la percentuale massima tollerata di servizi che possono risultare non integri prima che l'applicazione venga considerata non integra. Percentuale predefinita: zero.
L'esempio seguente è un estratto del manifesto di un'applicazione:
<Policies>
<HealthPolicy ConsiderWarningAsError="true" MaxPercentUnhealthyDeployedApplications="20">
<DefaultServiceTypeHealthPolicy
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="10"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="FrontEndServiceType"
MaxPercentUnhealthyServices="0"
MaxPercentUnhealthyPartitionsPerService="20"
MaxPercentUnhealthyReplicasPerPartition="0"/>
<ServiceTypeHealthPolicy ServiceTypeName="BackEndServiceType"
MaxPercentUnhealthyServices="20"
MaxPercentUnhealthyPartitionsPerService="0"
MaxPercentUnhealthyReplicasPerPartition="0">
</ServiceTypeHealthPolicy>
</HealthPolicy>
</Policies>
Valutazione dell'integrità
Gli utenti e i servizi automatizzati possono valutare l'integrità di qualsiasi entità in qualsiasi momento. Per valutare l'integrità di un'entità, l'archivio integrità aggrega tutti i report sull'integrità di tale entità e valuta tutti i relativi elementi figlio (se esistenti). L'algoritmo di aggregazione dell'integrità usa criteri di integrità che specificano come valutare i report e come aggregare gli stati di integrità degli elementi figlio (se disponibili).
Aggregazione dei report sull'integrità
Per una stessa entità possono essere disponibili più report sull'integrità inviati da generatori diversi (componenti di sistema o watchdog) relativamente a proprietà diverse. L'aggregazione usa i criteri di integrità associati, in particolare il membro ConsiderWarningAsError dei criteri di integrità dell'applicazione o del cluster, che specifica come valutare i report di tipo Warning.
Lo stato di integrità aggregato viene attivato dai report sull'integrità peggiori relativi all'entità. Se è presente almeno un report sull'integrità di tipo Error, lo stato di integrità aggregato sarà Error.
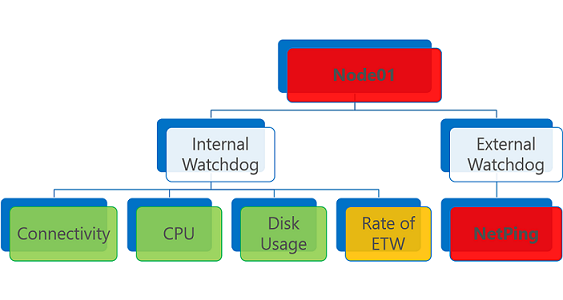
Un'entità di integrità con uno o più report sull'integrità di tipo Error viene valutata come Error. La stesso accade in caso di report sull'integrità scaduto, indipendentemente dallo stato di integrità.
Se non sono presenti report di tipo Error ma uno o più report di tipo Warning, lo stato di integrità aggregato sarà Warning o Error, a seconda del flag dei criteri ConsiderWarningAsError.
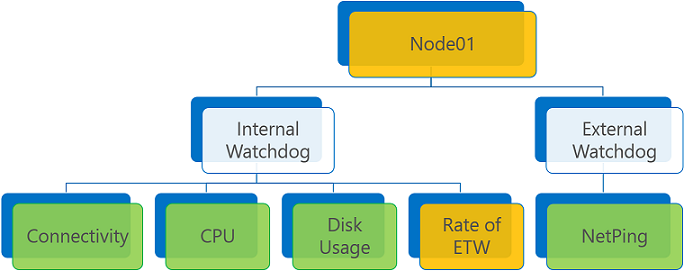
Aggregazione dei report sull'integrità con report di tipo Warning e ConsiderWarningAsError impostato su false (valore predefinito).
Aggregazione dell'integrità degli elementi figlio
Lo stato di integrità aggregato di un'entità riflette gli stati di integrità degli elementi figlio (se esistenti). Per l'algoritmo di aggregazione degli stati degli elementi figlio vengono usati i criteri di integrità applicabili in base al tipo di entità.
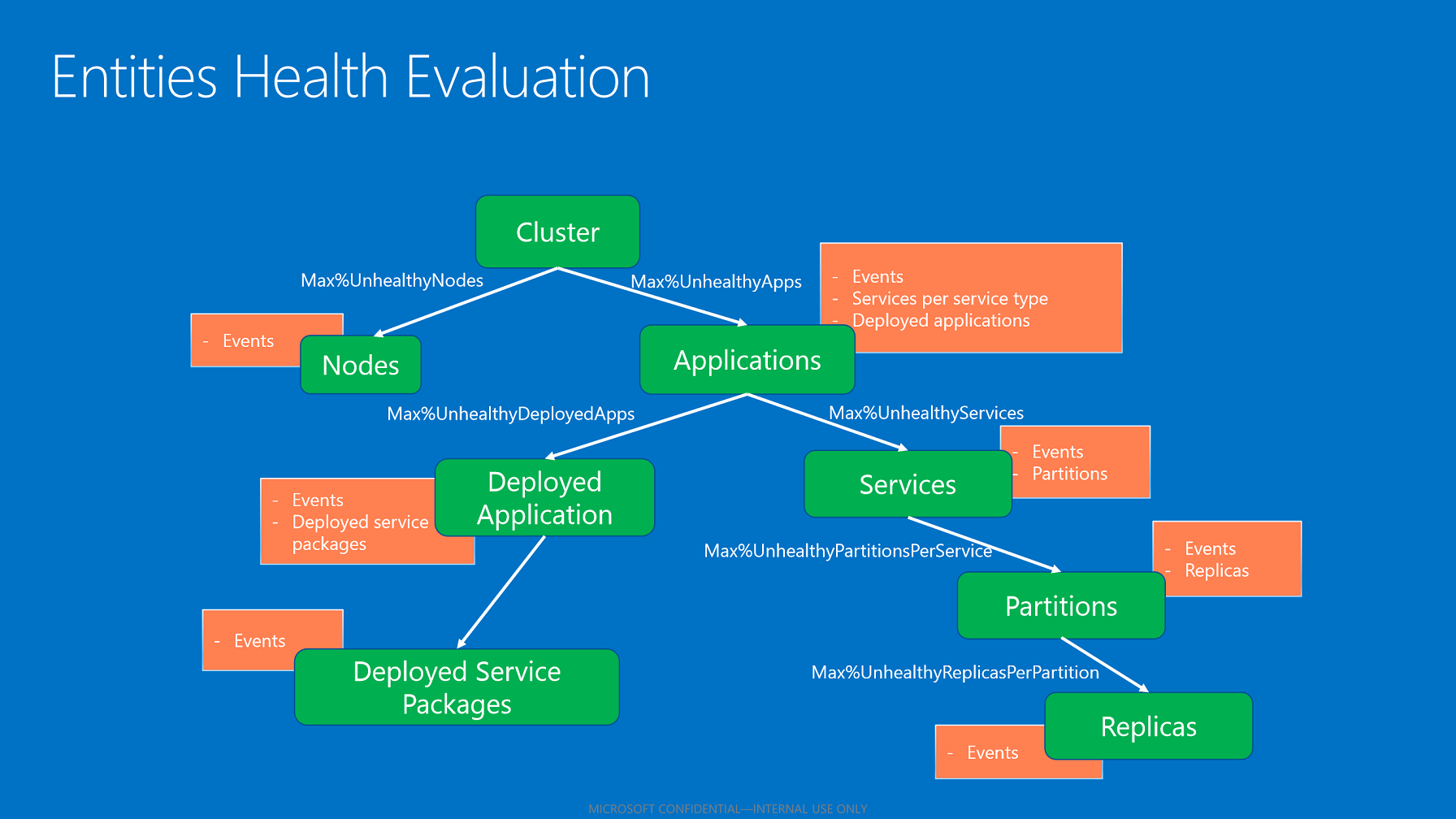
Aggregazione degli elementi figlio in base ai criteri di integrità.
Dopo aver eseguito la valutazione di tutti gli elementi figlio, l'archivio integrità ne aggrega gli stati di integrità in base alla percentuale massima configurata di elementi figlio non integri. Tale percentuale è ricavata dai criteri in base al tipo di entità e di elemento figlio.
- Se lo stato è OK per tutti gli elementi figlio, lo stato di integrità aggregato di tali elementi sarà OK.
- Se insieme a elementi figlio con stato OK sono presenti elementi figlio con stato Warning, lo stato di integrità aggregato di tali elementi sarà Warning.
- Se sono presenti elementi figlio con stato Error che non rientrano nella percentuale massima di elementi figlio non integri consentita, lo stato di integrità aggregato dell'elemento padre sarà Error.
- Se gli elementi figlio con stato Error non superano la percentuale massima di elementi figlio non integri consentita, lo stato di integrità aggregato dell'elemento padre sarà Warning.
Creazione di report sull'integrità
I componenti di sistema, le applicazioni Fabric di sistema e i watchdog interni/esterni possono generare report in relazione alle entità di Service Fabric. I generatori di report determinano localmente l'integrità delle entità monitorate in base alle condizioni sottoposte a monitoraggio. Non considerano alcuno stato globale o dato aggregato Il comportamento desiderato prevede generatori di report semplici e non organismi complessi che devono tenere conto di numerosi aspetti per decidere quali informazioni inviare.
Per inviare i dati di integrità all'archivio integrità, i generatori di report devono identificare l'entità interessata e creare un report sull'integrità. Per inviare il report, usare l'API FabricClient.HealthClient.ReportHealth, le API di integrità dei report esposte negli oggetti Partition o CodePackageActivationContext, i cmdlet di PowerShell o REST.
Report sull'integrità
I report sull'integrità per ognuna delle entità incluse nel cluster contengono le informazioni seguenti:
SourceId. Stringa che identifica in modo univoco il generatore di report per l'evento di integrità.
Entity identifier. Identifica l'entità a cui viene applicato il report. Varia in base al tipo di entità:
- Cluster. Nessuno.
- Node. Nome del nodo (stringa).
- Applicazione. Nome dell'applicazione (URI). Rappresenta il nome dell'istanza di applicazione distribuita nel cluster.
- Servizi. Nome del servizio (URI). Rappresenta il nome dell'istanza di servizio distribuita nel cluster.
- Partizione. ID della partizione (GUID). Rappresenta l'identificatore univoco della partizione.
- Replica. ID della replica del servizio con stato o ID dell'istanza del servizio senza stato (INT64).
- Applicazione distribuita. Nome dell'applicazione (URI) e nome del nodo (stringa).
- Pacchetto servizio distribuito. Nome dell'applicazione (URI), nome del nodo (stringa) e nome del manifesto del servizio (stringa).
Proprietà. Stringa (non un'enumerazione fissa) che consente al generatore di report di categorizzare l'evento di integrità per una proprietà specifica dell'entità. Ad esempio, il reporter A può segnalare l'integrità di Node01 in base alla proprietà "Storage", mentre il reporter B può segnalare l'integrità di Node01 in base alla proprietà "Connectivity". Entrambi questi report vengono considerati come eventi di integrità separati nell'archivio integrità per l'entità Node01.
Descrizione. Stringa che consente a un generatore di report di fornire informazioni dettagliate sull'evento di integrità. SourceId, Property e HealthState descrivono il report in modo esauriente. Description aggiunge informazioni leggibili sul report semplificando la comprensione del report sull'integrità da parte di amministratori e utenti.
HealthState. Enumerazione che descrive lo stato di integrità del report. I valori accettati sono OK, Warning ed Error.
TimeToLive. Intervallo di tempo che indica per quanto è valido il report sull'integrità. Insieme a RemoveWhenExpired, indica all'archivio integrità come valutare gli eventi scaduti. Per impostazione predefinita, il valore è infinito e quindi il report è sempre valido.
RemoveWhenExpired. Valore booleano. Se è impostato su true, il report sull'integrità scaduto viene rimosso automaticamente dall'archivio integrità e non incide sulla valutazione dell'integrità dell'entità. Viene usato quando il report è valido solo per un periodo di tempo specificato e non deve essere eliminato esplicitamente dal generatore di report. Viene usato anche per eliminare i report dall'archivio integrità. Ad esempio, se un watchdog viene modificato e smette di inviare report con la proprietà e l'origine precedenti. Può inviare un report con un valore TimeToLive basso e RemoveWhenExpired per cancellare qualsiasi stato precedente dall'archivio integrità. Se il valore è impostato su false, il report scaduto viene considerato come un errore nella valutazione dell'integrità. Il valore false indica all'archivio integrità che l'origine dovrebbe inviare periodicamente informazioni su questa proprietà. In caso contrario, il watchdog potrebbe avere un problema. L'integrità del watchdog viene acquisita considerando l'evento come un errore.
SequenceNumber. Numero intero positivo che deve essere sempre crescente, perché rappresenta l'ordine dei report. Viene usato dall'archivio integrità per rilevare i report non aggiornati, ricevuti in ritardo a causa di ritardi sulla rete o di altri problemi. I report vengono rifiutati se il numero di sequenza è minore o uguale all'ultimo numero applicato per la stessa entità, origine e proprietà. Se non è specificato, il numero di sequenza viene generato automaticamente. È necessario inserire il numero di sequenza solo quando si inviano report sulle transizioni di stato. In questo caso, l'origine deve ricordare i report inviati e mantenere le informazioni per recuperarle in caso di failover.
SourceId, l'identificatore dell'entità, Property e HealthState sono dati obbligatori per tutti i report sull'integrità. La stringa SourceId non può iniziare con il prefisso "System.", che è riservato ai report di sistema. Per la stessa entità è disponibile un solo report per la stessa origine e la stessa proprietà. Più report per la stessa origine e la stessa proprietà si sostituiscono l'uno all'altro sul lato del client di integrità (se sono in batch) o sul lato dell'archivio integrità. La sostituzione avviene in base al numero di sequenza, quindi i report più recenti con un numero di sequenza più alto sostituiscono quelli meno recenti.
Eventi di integrità
Internamente, l'archivio integrità mantiene eventi di integritàcontenenti tutte le informazioni provenienti dai report e metadati aggiuntivi. I metadati includono l'ora in cui un report è stato consegnato al client di integrità e l'ora in cui è stato modificato sul lato server. Gli eventi di integrità vengono restituiti dalle query sull'integrità.
I metadati aggiunti includono quanto segue:
- SourceUtcTimestamp. Ora in cui il report è stato fornito al client di integrità (UTC).
- LastModifiedUtcTimestamp. Ora in cui il report è stato modificato l'ultima volta sul lato server (UTC).
- IsExpired. Flag che indica se il report era scaduto quando la query è stata eseguita dall'archivio integrità. Un evento può risultare scaduto solo se RemoveWhenExpired è false. In caso contrario, l'evento non viene restituito dalla query e viene rimosso dall'archivio.
- LastOkTransitionAt, LastWarningTransitionAt, LastErrorTransitionAt. Ultima volta in cui si sono verificate transizioni OK/Warning/Error. Questi campi forniscono la cronologia delle transizioni degli stati di integrità per l'evento.
I campi di transizione dello stato possono essere usati per ottenere avvisi più intelligenti o informazioni "cronologiche" sull'evento di integrità. Consentono l'uso di scenari simili ai seguenti:
- Avviso quando lo stato di una proprietà è impostato su Warning/Error da più di X minuti. Controllando la condizione per un determinato periodo di tempo si evitano avvisi per condizioni temporanee. Ad esempio, se si vuole un avviso quando lo stato di integrità rimane impostato su Warning per più di 5 minuti, è possibile usare: (HealthState == Warning and Now - LastWarningTransitionTime > 5 minutes).
- Avviso solo per le condizioni cambiate negli ultimi X minuti. Se un report segnalava lo stato Error anche prima dell'ora specificata, può essere ignorato perché il problema era già stato segnalato in precedenza.
- Se una proprietà si alterna tra lo stato Warning e lo stato Error, determinare per quanto tempo è risultata non integra, ovvero non OK. Ad esempio, se si vuole un avviso quando la proprietà non risulta integra da più di 5 minuti, è possibile usare: (HealthState != Ok and Now - LastOkTransitionTime > 5 minutes).
Esempio: Report e valutazione dell'integrità dell'applicazione
L'esempio seguente invia tramite PowerShell un report sull'integrità dell'applicazione fabric:/WordCount dall'origine MyWatchdog. Il report sull'integrità contiene informazioni sulla "disponibilità" della proprietà di integrità con stato di integrità Error e TimeToLive infinito. Viene quindi eseguita una query sull'integrità dell'applicazione che restituisce Error come stato di integrità aggregato e gli eventi di integrità segnalati nell'elenco degli eventi di integrità.
PS C:\> Send-ServiceFabricApplicationHealthReport –ApplicationName fabric:/WordCount –SourceId "MyWatchdog" –HealthProperty "Availability" –HealthState Error
PS C:\> Get-ServiceFabricApplicationHealth fabric:/WordCount -ExcludeHealthStatistics
ApplicationName : fabric:/WordCount
AggregatedHealthState : Error
UnhealthyEvaluations :
Error event: SourceId='MyWatchdog', Property='Availability'.
ServiceHealthStates :
ServiceName : fabric:/WordCount/WordCountService
AggregatedHealthState : Error
ServiceName : fabric:/WordCount/WordCountWebService
AggregatedHealthState : Ok
DeployedApplicationHealthStates :
ApplicationName : fabric:/WordCount
NodeName : _Node_0
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_2
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_3
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_4
AggregatedHealthState : Ok
ApplicationName : fabric:/WordCount
NodeName : _Node_1
AggregatedHealthState : Ok
HealthEvents :
SourceId : System.CM
Property : State
HealthState : Ok
SequenceNumber : 360
SentAt : 3/22/2016 7:56:53 PM
ReceivedAt : 3/22/2016 7:56:53 PM
TTL : Infinite
Description : Application has been created.
RemoveWhenExpired : False
IsExpired : False
Transitions : Error->Ok = 3/22/2016 7:56:53 PM, LastWarning = 1/1/0001 12:00:00 AM
SourceId : MyWatchdog
Property : Availability
HealthState : Error
SequenceNumber : 131032204762818013
SentAt : 3/23/2016 3:27:56 PM
ReceivedAt : 3/23/2016 3:27:56 PM
TTL : Infinite
Description :
RemoveWhenExpired : False
IsExpired : False
Transitions : Ok->Error = 3/23/2016 3:27:56 PM, LastWarning = 1/1/0001 12:00:00 AM
Uso del modello di integrità
Il modello di integrità consente la scalabilità dei servizi cloud e della piattaforma Service Fabric sottostante perché il monitoraggio e la determinazione dell'integrità vengono distribuiti tra i diversi monitor all'interno del cluster. Altri sistemi hanno un unico servizio centralizzato a livello di cluster che analizza tutte le informazioni potenzialmente utili generate dai servizi. Questo approccio ne impedisce la scalabilità e non consente la raccolta di informazioni specifiche per identificare i problemi effettivi e potenziali risalendo alla causa principale.
Il modello di integrità viene usato in larga misura per il monitoraggio e la diagnosi, per la valutazione dell'integrità del cluster e dell'applicazione e per aggiornamenti monitorati. Altri servizi usano i dati di integrità per eseguire riparazioni automatiche, generare la cronologia dell'integrità del cluster e inviare avvisi in determinate condizioni.
Passaggi successivi
Come visualizzare i report sull'integrità di Service Fabric
Uso dei report sull'integrità del sistema per la risoluzione dei problemi
Creare report e verificare l'integrità dei servizi
Aggiungere report sull'integrità di Service Fabric personalizzati
Monitorare e diagnosticare servizi in locale
Aggiornamento di un'applicazione di infrastruttura di servizi