Controlli di integrità
CycleCloud offre due meccanismi per controllare l'integrità delle macchine virtuali: i controlli di integrità dei nodi sono funzionalità più recenti che eseguono i controlli durante la fase di provisioning e impediscono l'aggiunta delle macchine virtuali non integre, mentre HealthCheck li esegue periodicamente dopo che la macchina virtuale ha aggiunto il cluster come nodo.
I controlli di integrità dei nodi possono rilevare l'hardware non integro prima che una macchina virtuale possa partecipare al cluster CycleCloud. La versione corrente di questa funzionalità eseguirà script di controllo integrità incorporati nelle immagini ufficiali di AzureHPC disponibili in /opt/azurehpc/test/azurehpc-health-checks/. L'origine di questi script si trova nel repository Dei controlli di integrità dei nodi di AzureHPC, ma si noti che la versione incorporata nella versione del cluster dell'immagine AzureHPC potrebbe non essere quella più recente disponibile nel repository.
La versione corrente dei controlli di integrità dei nodi supporta solo le immagini AzureHPC rilasciate dopo il 7 novembre 2023 (che contiene azurehpc-health-checks versione 2.0.6 o successiva) e le immagini personalizzate derivate da tali immagini. I controlli di integrità dei nodi non sono attualmente supportati in Windows.
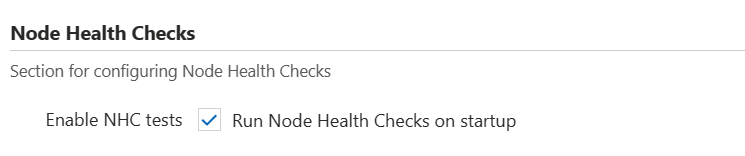
Il modulo di creazione del cluster Slurm offre una casella di controllo per abilitare i controlli di integrità dei nodi disponibili nella scheda Impostazioni avanzate . Selezionare la casella abilita i controlli di integrità dei nodi nella matrice di nodi HPC del cluster. Se si desidera abilitare i controlli di integrità dei nodi in altre matrici di nodi (o per altri tipi di cluster), è necessario usare un modello di cluster personalizzato.
I controlli di integrità dei nodi possono essere disabilitati in un cluster in esecuzione deselezionando semplicemente la casella . Non è necessario ridimensionare la matrice di nodi per rendere effettive le modifiche.
Dopo che una macchina virtuale supera i controlli di integrità, passerà alla fase di configurazione del software.
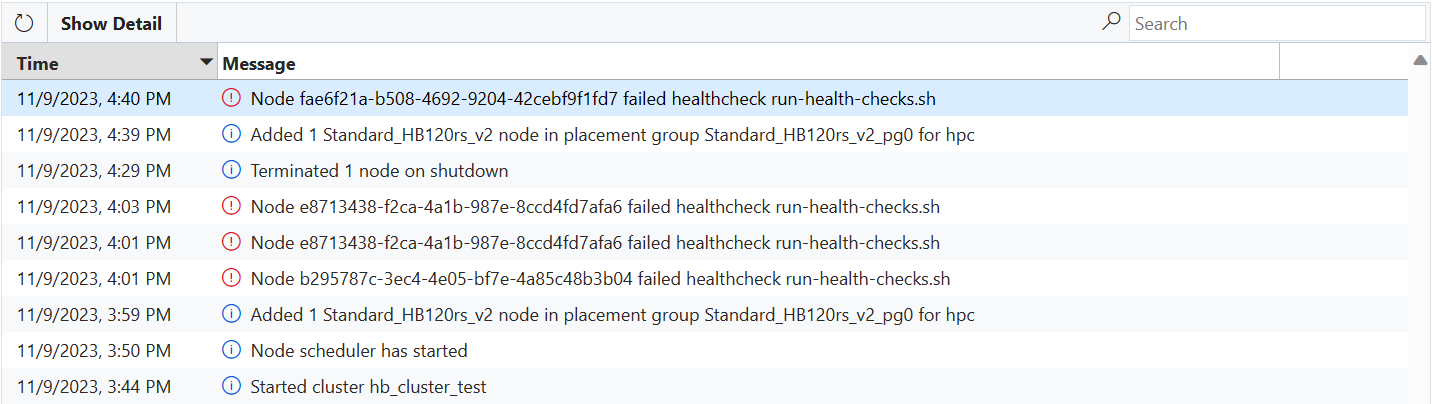
Se una macchina virtuale ha esito negativo in uno degli script di controllo integrità, verrà inviato un messaggio di errore a CycleCloud e la macchina virtuale non verrà aggiunta automaticamente al cluster.
Se la macchina virtuale viene avviata in nodeArray con over-provisioning abilitato (ad esempio, l'array di nodi hpc Slurm), la macchina virtuale deve essere sostituita automaticamente come parte dell'over-provisioning. In tal caso, non è necessaria alcuna azione e le macchine virtuali integre verranno selezionate per l'aggiunta al cluster (anche se nella pagina del cluster verrà visualizzato un messaggio di errore che indica che una o più macchine virtuali non sono riuscite).
Se la macchina virtuale viene avviata per un singolo nodo, un array di nodi con over-provisioning disabilitato (ad esempio l'array di nodi Slurm htc) o se più macchine virtuali non superano i controlli di integrità supportati dall'over-provisioning, il nodo passerà allo stato Failed e l'allocazione avrà esito negativo. CycleCloud potrebbe tentare di riprodurre l'immagine della macchina virtuale per risolvere il problema, ma se l'immagine di nuovo ha esito negativo, il nodo dovrà essere terminato e sostituito (manualmente da un amministratore o automaticamente dal ridimensionamento automatico).
Nota
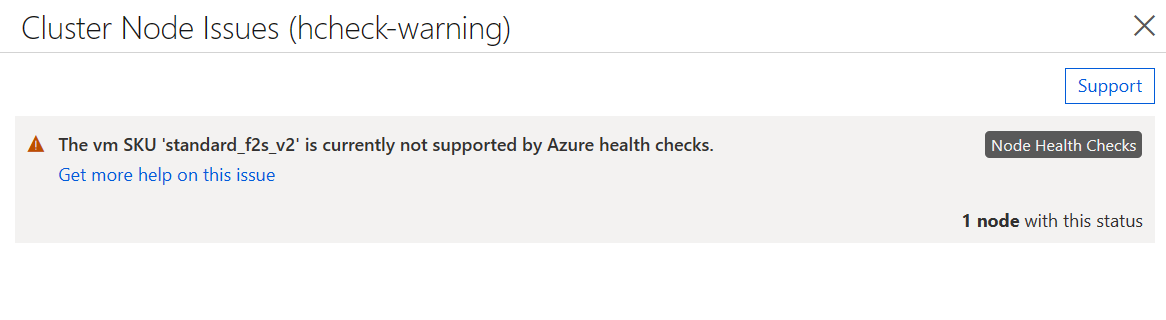
Se sono stati abilitati i controlli di integrità dei nodi, ma l'immagine della macchina virtuale non soddisfa i requisiti precedenti, tutte le macchine virtuali potranno essere unite al cluster, ma lo stato conterrà un avviso che indica che i controlli non sono supportati.
| Attributo | Type | Definizione |
|---|---|---|
| EnableNodeHealthChecks | Boolean | (Facoltativo) Abilitare i controlli di integrità dei nodi all'avvio per questo nodo o matrice di nodi |
Azure CycleCloud fornisce un meccanismo per terminare le macchine virtuali (VM) che si trovano in uno stato non integro denominato HealthCheck. Gli script definiti dal sistema e dall'utente (Python e Bash) vengono eseguiti periodicamente (5 minuti in Windows, 10 minuti in Linux) per determinare l'integrità complessiva di una macchina virtuale. HealthCheck consente agli amministratori di definire le condizioni in cui le macchine virtuali devono essere terminate senza dover monitorare e correggere manualmente.
Le macchine virtuali abilitate per CycleCloud sono dotate di due script HealthCheck predefiniti:
- Lo script converge_timeout terminerà un'istanza che non ha completato la configurazione software entro quattro ore dall'avvio. Questo periodo di timeout può essere controllato con l'impostazione
cyclecloud.keepalive.timeout(definita in secondi). - Lo script scheduled_shutdown cerca i file maker in $JETPACK_HOME/run/scheduled_shutdown che contengono una singola riga che fornisce un'ora di arresto in secondi di timestamp Unix e una seconda riga facoltativa con una spiegazione. Quando l'ora corrente è successiva al timestamp meno recente nei file, la macchina virtuale viene considerata non integra.
Gli script HealthCheck si trovano nella directory $JETPACK_HOME/config/healthcheck.d . Linux supporta sia script Python che Bash, mentre Windows supporta solo gli script Python. Lo script deve determinare l'integrità della macchina virtuale. Se la macchina virtuale risulta non integra, lo script deve uscire con lo stato 254, che indica a CycleCloud che la macchina virtuale non è integra e deve essere terminata.
Quando si è connessi a una macchina virtuale che esegue HealthCheck, è possibile impedire l'arresto della macchina virtuale eseguendo il comando jetpack keepalive. Nelle istanze di Linux è possibile specificare un intervallo di tempo in ore o forever mentre in Windows forever è l'unica opzione.
Nota
Quando una macchina virtuale è determinata come non integra, l'agente HealthCheck effettuerà una richiesta di terminare la macchina virtuale, la macchina virtuale non verrà mai arrestata localmente tramite shutdown il comando . Nel caso in cui la macchina virtuale non sia in grado di comunicare con CycleCloud, la macchina virtuale rimarrà in funzione anche se non è integra fino a quando non è possibile raggiungere CycleCloud.
Come semplice esempio verrà scritto uno script HealthCheck che garantisce che una macchina virtuale Linux non sia attiva per più di 24 ore. Questo script può essere usato per simulare le eliminazioni con priorità bassa per verificare la reazione di un flusso di lavoro a una macchina virtuale rimossa. Questo script verrà inserito in /opt/cycle/jetpack/config/healthcheck.d/healthcheck_example.sh
#!/bin/bash
# Get the uptime of the system (in seconds) and check to see if it is
# greater than 86,400 (24 hours in seconds). If it is, exit 254 to
# signal that the VM is unhealthy.
if (( $(cat /proc/uptime | awk '{print ($1 > 86400)}'))); then
exit 254
fi
Nota
Questo script può essere inserito in una macchina virtuale tramite CycleCloud Project o aggiungendolo direttamente durante la creazione di un'immagine personalizzata.