Trasformare i dati usando l'attività Spark in Azure Data Factory e Synapse Analytics
SI APPLICA A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Suggerimento
Provare Data Factory in Microsoft Fabric, una soluzione di analisi completa per le aziende. Microsoft Fabric copre tutti gli elementi, dallo spostamento dei dati all'analisi scientifica dei dati, all'analisi in tempo reale, alla business intelligence e alla creazione di report. Scopri come avviare gratuitamente una nuova versione di valutazione .
L'attività Spark in una data factory e le pipeline di Synapse eseguono un programma Spark nel proprio cluster HDInsight o su richiesta. Questo articolo si basa sull'articolo relativo alle attività di trasformazione dei dati che presenta una panoramica generale della trasformazione dei dati e le attività di trasformazione supportate. Quando si usa un servizio collegato Spark su richiesta, il servizio crea automaticamente un cluster Spark jite per elaborare i dati e quindi elimina il cluster al termine dell'elaborazione.
Aggiungere un'attività Spark a una pipeline con l'interfaccia utente
Per usare un'attività Spark in una pipeline, completare la procedura seguente:
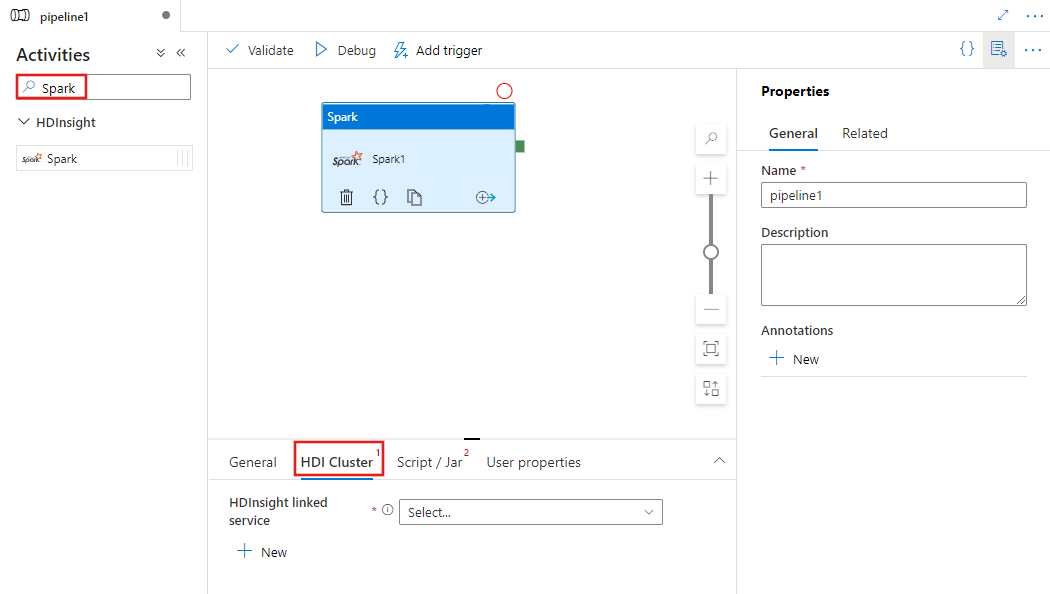
Cercare Spark nel riquadro Attività pipeline e trascinare un'attività Spark nell'area di disegno della pipeline.
Selezionare la nuova attività Spark nell'area di disegno, se non è già selezionata.
Selezionare la scheda Cluster HDI per selezionare o creare un nuovo servizio collegato in un cluster HDInsight che verrà usato per eseguire l'attività Spark.
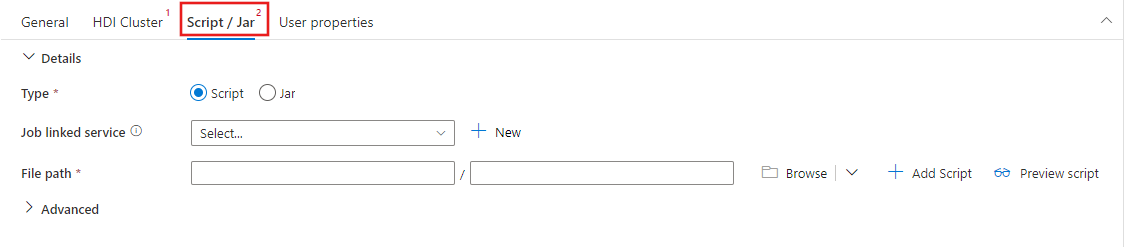
Selezionare la scheda Script/Jar per selezionare o creare un nuovo servizio collegato di processo a un account Archiviazione di Azure che ospiterà lo script. Specificare un percorso del file da eseguire. È anche possibile configurare dettagli avanzati, tra cui un utente proxy, una configurazione di debug e argomenti e parametri di configurazione spark da passare allo script.
Proprietà dell'attività Spark
Ecco la definizione JSON di esempio di un'attività Spark:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
La tabella seguente fornisce le descrizioni delle proprietà JSON usate nella definizione JSON:
| Proprietà | Descrizione | Richiesto |
|---|---|---|
| name | Nome dell'attività nella pipeline. | Sì |
| description | Testo che descrive l'attività. | No |
| Tipo | Per l'attività Spark il tipo corrisponde a HDInsightSpark. | Sì |
| linkedServiceName | Nome del servizio collegato di HDInsight Spark in cui viene eseguito il programma Spark. Per informazioni su questo servizio collegato, vedere l'articolo Servizi collegati di calcolo. | Sì |
| SparkJobLinkedService | Il servizio collegato di archiviazione di Azure che contiene il file di processo, le dipendenze e i log di Spark. Qui sono supportati solo i servizi collegati Archiviazione BLOB di Azure e ADLS Gen2. Se non si specifica un valore per questa proprietà, viene usato lo spazio di archiviazione associato al cluster HDInsight. Il valore di questa proprietà può essere solo un servizio collegato di Archiviazione di Azure. | No |
| rootPath | Contenitore BLOB di Azure e cartella che contiene il file Spark. Il nome del file distingue tra maiuscole e minuscole. Per informazioni dettagliate sulla struttura della cartella, fare riferimento alla prossima sezione, relativa alla struttura delle cartelle. | Sì |
| entryFilePath | Percorso relativo alla cartella radice del pacchetto/codice Spark. Il file di ingresso deve essere un file Python o un file JAR. | Sì |
| className | Classe principale Java/Spark dell'applicazione | No |
| arguments | Elenco di argomenti della riga di comando del programma Spark. | No |
| proxyUser | Account utente da rappresentare per eseguire il programma Spark | No |
| sparkConfig | Specificare i valori delle proprietà di configurazione di Spark elencati nell'argomento: Configurazione di SparK: proprietà dell'applicazione. | No |
| getDebugInfo | Specifica quando i file di log di Spark vengono copiati nell'archiviazione di Azure usata dal cluster HDInsight (o) specificata da sparkJobLinkedService. Valori consentiti: None, Always o Failure. Valore predefinito: None. | No |
Struttura delle cartelle
I processi Spark sono più estendibili dei processi Pig/Hive. Per i processi Spark, è possibile fornire più dipendenze, ad esempio pacchetti JAR (inseriti in Java CLASSPATH), file Python (inseriti in PYTHONPATH) e qualsiasi altro file.
Creare la struttura seguente di cartelle nell'archivio BLOB di Azure a cui fa riferimento il servizio collegato HDInsight. Caricare i file dipendenti nelle sottocartelle appropriate all'interno della cartella radice rappresentata da entryFilePath. Caricare, ad esempio, i file Python nella sottocartella pyFiles e i file jar nella sottocartella jars della cartella radice. In fase di esecuzione, il servizio prevede la struttura di cartelle seguente nell'archivio BLOB di Azure:
| Percorso | Descrizione | Richiesto | Tipo |
|---|---|---|---|
. (radice) |
Percorso radice del processo Spark nel servizio collegato di archiviazione | Sì | Cartella |
| <definito dall'utente > | Percorso che punta al file di ingresso del processo Spark | Sì | file |
| ./jars | Tutti i file in questa cartella vengono caricati e inseriti nel classpath Java del cluster | No | Cartella |
| ./pyFiles | Tutti i file in questa cartella vengono caricati e inseriti nel PYTHONPATH del cluster | No | Cartella |
| ./files | Tutti i file in questa cartella vengono caricati e inseriti nella directory di lavoro executor | No | Cartella |
| ./archives | Tutti i file in questa cartella sono decompressi | No | Cartella |
| ./logs | Cartella contenente i log del cluster Spark. | No | Cartella |
Di seguito è riportato un esempio per una risorsa di archiviazione che contiene due file di processo Spark nell'archivio BLOB di Azure a cui fa riferimento il servizio collegato HDInsight.
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
Contenuto correlato
Vedere gli articoli seguenti, che illustrano altre modalità di trasformazione dei dati: