Limiti e domande frequenti per l’integrazione Git con le cartelle Git di Databricks
Le cartelle Git di Databricks e l'integrazione Git hanno limiti specificati nelle sezioni seguenti. Per informazioni generali, vedere Limiti di Databricks.
Passare a:
- Limiti relativi a file e repository
- Tipi di asset supportati nelle cartelle Git
- Domande frequenti: Configurazione della cartella Git
Limiti relativi a file e repository
Azure Databricks non applica un limite alle dimensioni di un repository. Tuttavia:
- I rami di lavoro sono limitati a 1 gigabyte (GB).
- I file di dimensioni superiori a 10 MB non possono essere visualizzati nell'interfaccia utente di Azure Databricks.
- I singoli file di area di lavoro sono soggetti a un limite di dimensioni separato. Per altre informazioni, vedere Limitazioni.
Databricks consiglia di usare un repository:
- Il numero totale di tutti gli asset e i file di area di lavoro non superano 20.000.
Per qualsiasi operazione Git, l'utilizzo memoria è limitato a 2 GB e le scritture su disco sono limitate a 4 GB. Poiché il limite è per operazione, si verifica un errore se si tenta di clonare un repository Git con dimensioni correnti di 5 GB. Tuttavia, se si clona un repository Git con dimensioni pari a 3 GB in un'operazione e quindi si aggiungono 2 GB in un secondo momento, l'operazione pull successiva avrà esito positivo.
Se il repository supera questi limiti, potrebbe essere visualizzato un messaggio di errore. È anche possibile che venga visualizzato un errore di timeout quando si clona il repository, ma l'operazione potrebbe essere completata in background.
Per usare il repository più grande dei limiti di dimensioni, provare a eseguire il checkout di tipo sparse.
Se è necessario scrivere file temporanei che non si desidera mantenere dopo l'arresto del cluster, scrivere i file temporanei in $TEMPDIR per evitare di superare i limiti delle dimensioni dei rami e restituisce prestazioni migliori rispetto alla scrittura nella directory di lavoro corrente (CWD) se CWD si trova nel file system dell'area di lavoro. Per altre informazioni, vedere Dove scrivere file temporanei in Azure Databricks?.
Numero massimo di cartelle Git per area di lavoro
È possibile avere un massimo di 2.000 cartelle Git per area di lavoro. Se ne servono di più, contattare il supporto tecnico di Databricks.
Ripristino di file eliminati da cartelle Git nell'area di lavoro
Le azioni dell'area di lavoro nelle cartelle Git variano in base alla recuperabilità dei file. Alcune azioni consentono il ripristino tramite la cartella Cestino , mentre altre non lo sono. I file di cui è stato eseguito il commit e il push in precedenza in un ramo remoto possono essere ripristinati usando la cronologia del commit Git per il repository Git remoto. Questa tabella descrive il comportamento e la recuperabilità di ogni azione:
| Azione | Il file è recuperabile? |
|---|---|
| Eliminare un file con il browser dell'area di lavoro | Sì, dalla cartella Cestino |
| Rimuovere un nuovo file con la finestra di dialogo della cartella Git | Sì, dalla cartella Cestino |
| Rimuovere un file modificato con la finestra di dialogo della cartella Git | No, il file non è più disponibile |
reset (hard) per le modifiche di file di cui non è stato eseguito il commit |
No, le modifiche ai file non sono più disponibili |
reset (hard) per i file di cui non è stato eseguito il commit, appena creati |
No, le modifiche ai file non sono più disponibili |
| Cambiare rami con la finestra di dialogo della cartella Git | Sì, dal repository Git remoto |
| Altre operazioni Git (commit e push e così via) dalla finestra di dialogo della cartella Git | Sì, dal repository Git remoto |
PATCH operazioni di aggiornamento dall'API /repos/id Repos |
Sì, dal repository Git remoto |
I file eliminati da una cartella Git tramite operazioni Git dall'interfaccia utente dell'area di lavoro possono essere recuperati dalla cronologia remota dei rami usando la riga di comando Git (o altri strumenti Git) se tali file sono stati precedentemente sottoposti a commit e inseriti nel repository remoto. Le azioni dell'area di lavoro variano in base alla recuperabilità dei file. Alcune azioni consentono il recupero tramite il cestino, mentre altre no. I file di cui è stato eseguito il commit e il push in precedenza in un ramo remoto possono essere ripristinati tramite la cronologia dei commit Git. La tabella seguente illustra il comportamento e la recuperabilità di ogni azione:
Supporto tecnico Monorepo
Databricks consiglia di non creare cartelle Git supportate da monorepos, in cui un monorepo è un repository Git di grandi dimensioni con migliaia di file in molti progetti.
Tipi di asset supportati nelle cartelle Git
Solo alcuni tipi di asset di Azure Databricks sono supportati dalle cartelle Git. Un tipo di asset supportato può essere serializzato, controllato dalla versione e sottoposto a push nel repository Git di backup.
Attualmente, i tipi di asset supportati sono:
| Tipo di asset | Dettagli |
|---|---|
| file | I file sono dati serializzati e possono includere qualsiasi elemento, dalle librerie ai file binari al codice alle immagini. Per altre informazioni, vedere Che cosa sono i file dell'area di lavoro? |
| Notebook | I notebook sono in particolare i formati di file del notebook supportati da Databricks. I notebook sono considerati un tipo di asset di Azure Databricks separato dai file perché non vengono serializzati. Le cartelle Git determinano un notebook in base all'estensione di file (ad esempio .ipynb) o alle estensioni di file combinate con un marcatore speciale nel contenuto del file (ad esempio, un # Databricks notebook source commento all'inizio dei file di .py origine). |
| Cartella | Una cartella è una struttura specifica di Azure Databricks che rappresenta informazioni serializzate su un raggruppamento logico di file in Git. Come previsto, l'utente esegue questa operazione come "cartella" quando visualizza una cartella Git di Azure Databricks o accede a questa cartella con l'interfaccia della riga di comando di Azure Databricks. |
I tipi di asset di Azure Databricks attualmente non supportati nelle cartelle Git includono quanto segue:
- Query DBSQL
- Avvisi
- Dashboard (inclusi i dashboard legacy)
- Esperimenti
- Spazi genie
Quando si lavora con gli asset in Git, osservare le limitazioni seguenti nella denominazione dei file:
- Una cartella non può contenere un notebook con lo stesso nome di un altro notebook, file o cartella nello stesso repository Git, anche se l'estensione del file è diversa. Per i notebook in formato di origine, l'estensione è
.pyper Python,.scalaper Scala,.sqlper SQL e.rper R. Per i notebook in formato IPYNB, l'estensione è.ipynb. Ad esempio, non è possibile usare un notebook in formato di origine denominatotest1.pye un notebook IPYNB denominatotest1nella stessa cartella Git perché il file del notebook Python in formato di origine (test1.py) verrà serializzato cometest1e si verificherà un conflitto. - Il carattere
/non è supportato nei nomi di file. Ad esempio, non è possibile avere un file denominatoi/o.pynella cartella Git.
Se si tenta di eseguire operazioni Git su file con nomi con questi modelli, verrà visualizzato il messaggio "Errore durante il recupero dello stato git". Se questo errore viene visualizzato in modo imprevisto, esaminare i nomi file degli asset nel repository Git. Se si trovano file con nomi con questi modelli in conflitto, rinominarli e ritentare l'operazione.
Nota
È possibile spostare gli asset non supportati esistenti in una cartella Git, ma non è possibile eseguire il commit delle modifiche apportate a tali asset nel repository. Non è possibile creare nuovi asset non supportati in una cartella Git.
Formati di notebook
Databricks considera due tipi di formati di notebook specifici di Databricks di alto livello: "source" e "ipynb". Quando un utente esegue il commit di un notebook nel formato "source", la piattaforma Azure Databricks esegue il commit di un file flat con un suffisso di lingua, ad esempio .py, .sql.scala, o .r. Un notebook in formato "source" contiene solo il codice sorgente e non contiene output come le visualizzazioni e le visualizzazioni delle tabelle che sono i risultati dell'esecuzione del notebook.
Il formato "ipynb", tuttavia, include output associati e tali artefatti vengono automaticamente inseriti nel repository Git che esegue il backup della cartella Git durante il push del .ipynb notebook che li ha generati. Se si desidera eseguire il commit degli output insieme al codice, usare il formato del notebook "ipynb" e configurare la configurazione per consentire a un utente di eseguire il commit di eventuali output generati. Di conseguenza, "ipynb" supporta anche un'esperienza di visualizzazione migliore in Databricks per i notebook inseriti in repository Git remoti tramite cartelle Git.
| Formato origine notebook | Dettagli |
|---|---|
| source | Può essere qualsiasi file di codice con un suffisso di file standard che segnala il linguaggio di codice, ad esempio .py, .scala.r e .sql. I notebook "source" vengono considerati come file di testo e non includeranno alcun output associato quando viene eseguito il commit in un repository Git. |
| ipynb | I file "ipynb" terminano con .ipynb e possono, se configurati, eseguire il push degli output (ad esempio le visualizzazioni) dalla cartella Git di Databricks al repository Git di backup. Un .ipnynb notebook può contenere codice in qualsiasi linguaggio supportato dai notebook di Databricks (nonostante la py parte di .ipynb). |
Se si vuole eseguire il push degli output nel repository dopo l'esecuzione di un notebook, usare un .ipynb notebook (Jupyter). Se si vuole solo eseguire il notebook e gestirlo in Git, usare un formato di "origine" come .py.
Per altre informazioni sui formati di notebook supportati, vedere Esportare e importare notebook di Databricks.
Nota
Che cosa sono gli "output"?
Gli output sono i risultati dell'esecuzione di un notebook nella piattaforma Databricks, incluse le visualizzazioni e le visualizzazioni delle tabelle.
Ricerca per categorie indicare quale formato usa un notebook, diverso dall'estensione di file?
Nella parte superiore di un notebook gestito da Databricks è in genere presente un commento a riga singola che indica il formato. Ad esempio, per un .py notebook di "origine", verrà visualizzata una riga simile alla seguente:
# Databricks notebook source
Per .ipynb i file, il suffisso di file viene usato per indicare che è il formato del notebook "ipynb".
Notebook IPYNB nelle cartelle Git di Databricks
Il supporto per i notebook di Jupyter (.ipynb file) è disponibile nelle cartelle Git. È possibile clonare i repository con .ipynb notebook, usarli in Azure Databricks e quindi eseguirne il commit e il push come .ipynb notebook. I metadati, ad esempio il dashboard del notebook, vengono mantenuti. Gli amministratori possono controllare se è possibile eseguire o meno il commit degli output.
Consenti commit dell'output del .ipynb notebook
Per impostazione predefinita, l'impostazione di amministrazione per le cartelle Git non consente .ipynb il commit dell'output del notebook. Gli amministratori dell'area di lavoro possono modificare questa impostazione:
Passare a Impostazioni amministratore Impostazioni > area di lavoro.
In Cartelle Git Consenti alle cartelle > Git di esportare gli output IPYNB selezionare Consenti: gli output IPYNB possono essere attivati o disattivati.

Importante
Quando vengono inclusi gli output, le configurazioni di visualizzazione e dashboard vengono mantenute con il formato di file con estensione ipynb.
Controllare i commit degli artefatti dell'output del notebook IPYNB
Quando si esegue il commit di un .ipynb file, Databricks crea un file di configurazione che consente di controllare la modalità di commit degli output: .databricks/commit_outputs.
Se si dispone di un
.ipynbfile di notebook ma non di un file di configurazione nel repository, aprire il modale Stato Git.Nella finestra di dialogo di notifica fare clic su Crea commit_outputs file.
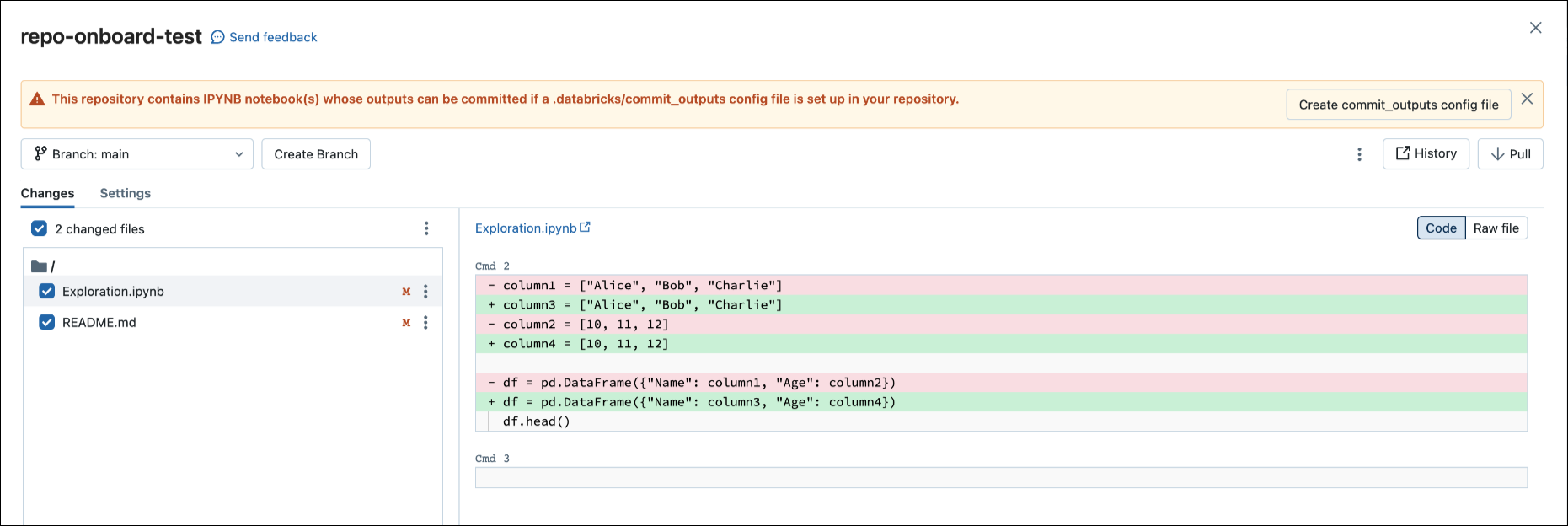
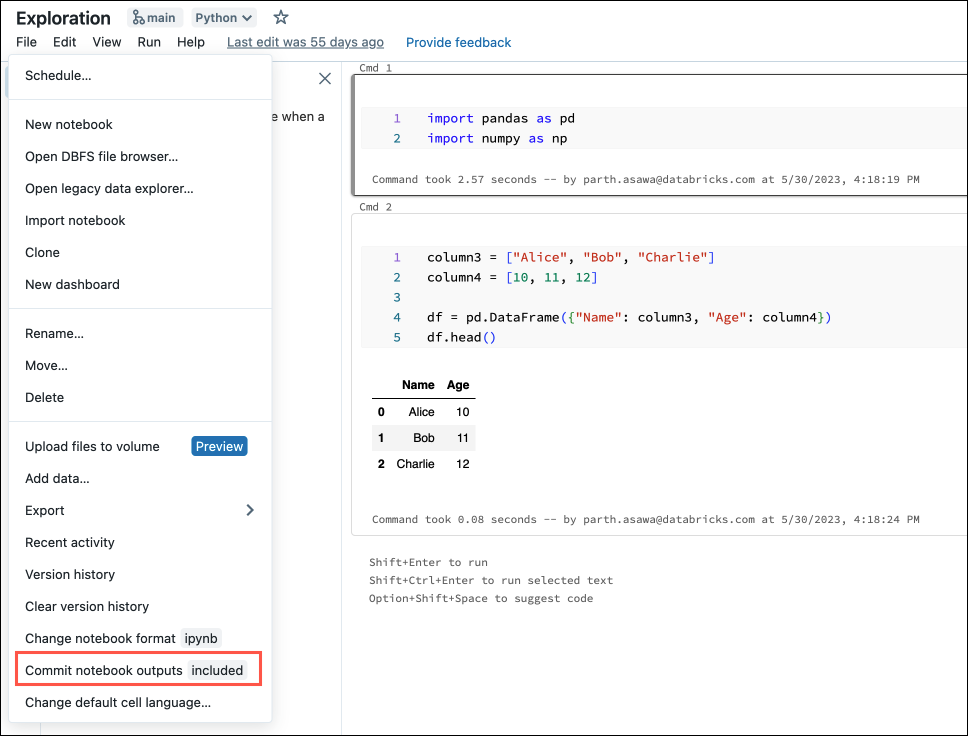
È anche possibile generare file di configurazione dal menu File . Il menu File include un controllo che consente di aggiornare automaticamente il file di configurazione per specificare l'inclusione o l'esclusione degli output per un notebook specifico.
Nel menu File selezionare Commit notebooks outputs (Esegui commit degli output dei notebook).
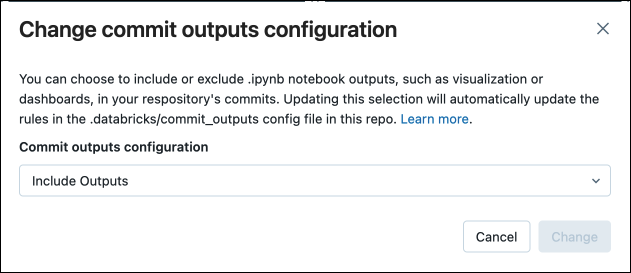
Nella finestra di dialogo confermare la scelta di eseguire il commit degli output del notebook.
Convertire un notebook di origine in IPYNB
È possibile convertire un notebook di origine esistente in una cartella Git in un notebook IPYNB tramite l'interfaccia utente di Azure Databricks.
Aprire un notebook di origine nell'area di lavoro.
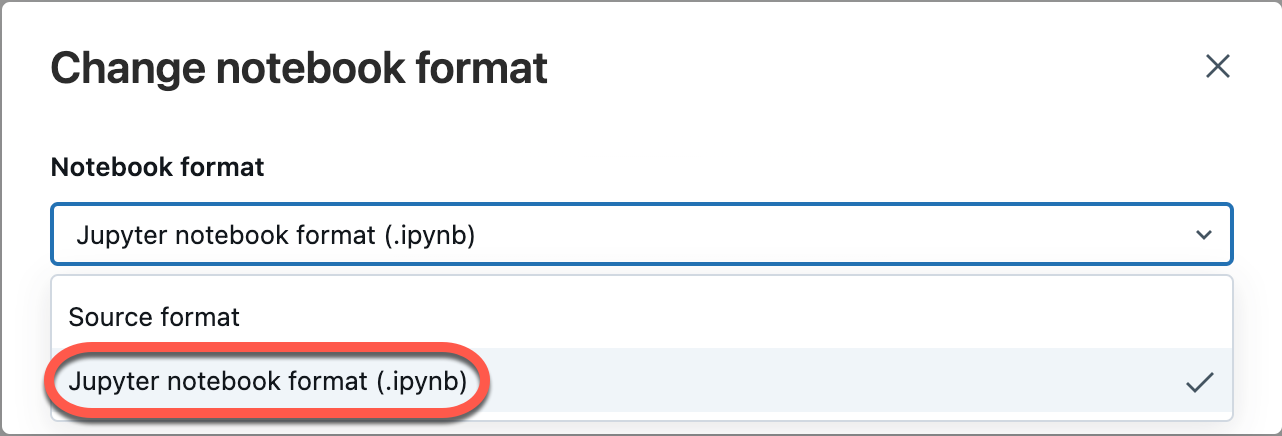
Selezionare File dal menu dell'area di lavoro e quindi selezionare Cambia formato notebook [origine]. Se il notebook è già in formato IPYNB, [source] sarà [ipynb] nell'elemento di menu.
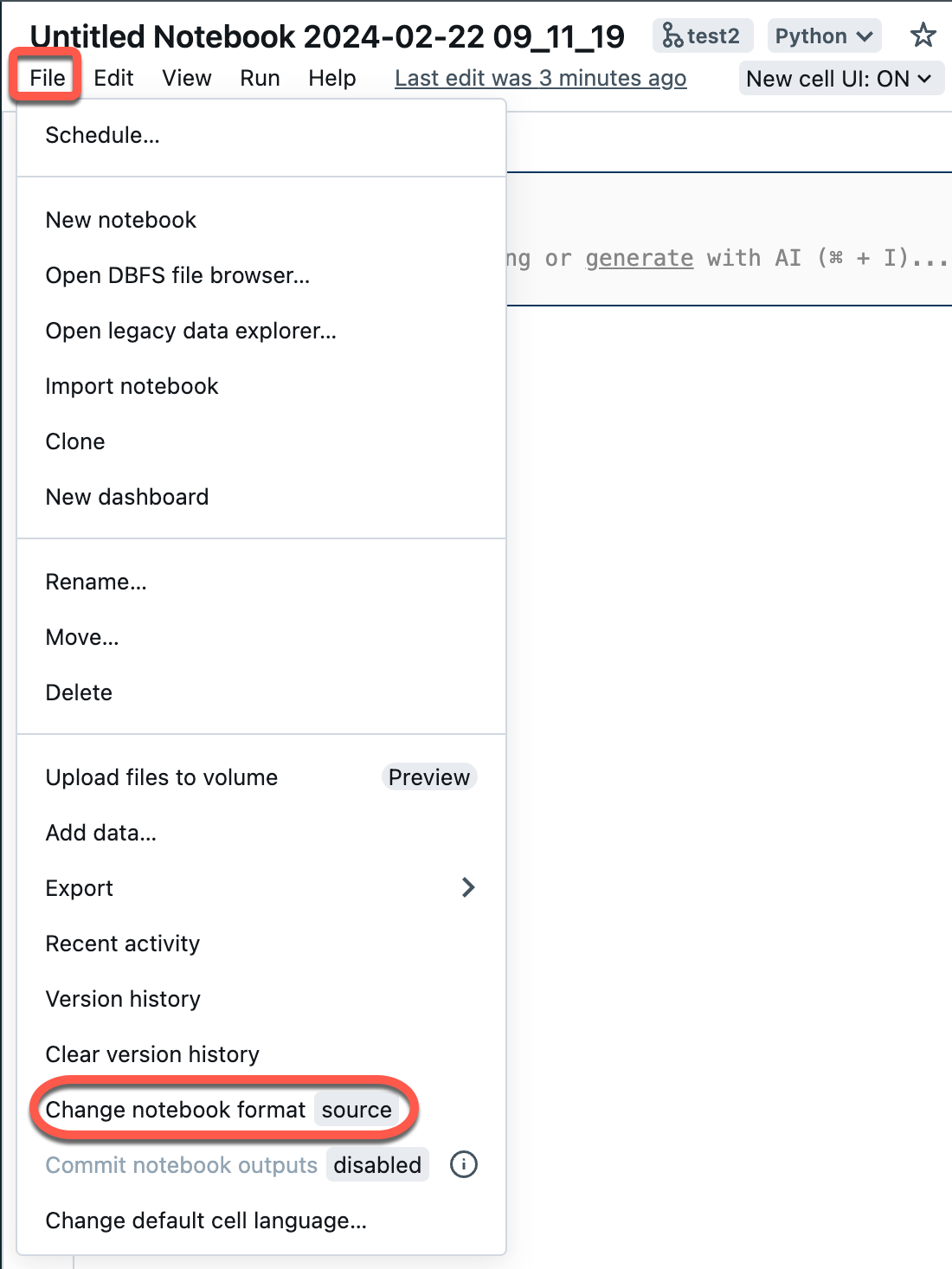
Nella finestra di dialogo modale selezionare "Formato notebook jupyter (.ipynb)" e fare clic su Cambia.
È anche possibile:
- Creare nuovi
.ipynbnotebook. - Visualizzare le differenze come differenze di codice (modifiche del codice nelle celle) o differenze non elaborate (le modifiche al codice vengono presentate come sintassi JSON, che include output del notebook come metadati).
Per altre informazioni sui tipi di notebook supportati in Azure Databricks, vedere Esportare e importare notebook di Databricks.
Domande frequenti: Configurazione della cartella Git
Dove è archiviato il contenuto del repository di Azure Databricks?
Il contenuto di un repository viene clonato temporaneamente su disco nel piano di controllo. I file di notebook di Azure Databricks vengono archiviati nel database del piano di controllo esattamente come i notebook nell'area di lavoro principale. I file non notebook vengono archiviati su disco per un massimo di 30 giorni.
Le cartelle Git supportano server Git locali o self-hosted?
Le cartelle Git di Databricks supportano GitHub Enterprise, Bitbucket Server, Azure DevOps Server e GitLab autogestito, se il server ha l’accesso a internet. Per altre informazioni sull'integrazione di cartelle Git con un server Git locale, vedere Git Proxy Server per le cartelle Git.
Per eseguire l'integrazione con un server Bitbucket, GitHub Enterprise Server o un'istanza di sottoscrizione self-managed di GitLab senza accesso a Internet, contattare il team dell'account di Azure Databricks.
Quali tipi di risorse di Databricks sono supportati dalle cartelle Git?
Per informazioni dettagliate sui tipi di asset supportati, vedere Tipi di asset supportati nelle cartelle Git.
Le cartelle Git supportano i file.gitignore?
Sì. Se si aggiunge un file al repository e non si vuole che venga rilevato da Git, creare un file .gitignore o usarne uno clonato dal repository remoto e aggiungere il nome del file, inclusa l'estensione.
.gitignore funziona solo per i file non già monitorati da Git. Se si aggiunge un file già rilevato da Git a un file .gitignore, il file viene ancora rilevato da Git.
È possibile creare cartelle di primo livello che non siano cartelle utente?
Sì, gli amministratori possono creare cartelle di primo livello a una singola profondità. Le cartelle Git non supportano livelli di cartella aggiuntivi.
Le cartelle Git supportano i moduli secondari Git?
No. È possibile clonare un repository che contiene moduli secondari Git, ma il modulo secondario non viene clonato.
Azure Data Factory supporta le cartelle Git?
Sì.
Gestione fonti
Perché i dashboard del notebook scompaiono quando si esegue il pull o il checkout di un ramo diverso?
Questa è attualmente una limitazione perché i file di origine del notebook di Azure Databricks non archiviano le informazioni della dashboard del notebook.
Se si desidera mantenere le dashboard nel repository Git, modificare il formato del notebook in .ipynb (formato notebook di Jupyter). Per impostazione predefinita, .ipynb supporta le definizioni di dashboard e visualizzazione. Se si desidera mantenere i dati del grafico (punti dati), è necessario eseguire il commit del notebook con output.
Per informazioni sul commit .ipynb degli output del notebook, vedere Consenti il commit .ipynb dell'output del notebook.
Le cartelle Git supportano l'unione dei rami?
Sì. È anche possibile creare una richiesta pull e unire tramite il provider Git.
È possibile eliminare un ramo da un repository di Azure Databricks?
No. Per eliminare un ramo, è necessario lavorare nel provider Git.
Se un catalogo è installato in un cluster e un catalogo con lo stesso nome viene incluso in una cartella all'interno di un repository, quale catalogo viene importato?
Viene importato il catalogo nel repository. Per altre informazioni sulla precedenza del catalogo in Python, vedere Precedenza catalogo Python.
È possibile eseguire il pull della versione più recente di un repository da Git prima di eseguire un lavoro senza basarsi su uno strumento di orchestrazione esterno?
No. In genere è possibile integrarlo come pre-commit nel server Git in modo che ogni push in un ramo (main/prod) aggiorni il repository Production.
È possibile esportare un repository?
È possibile esportare notebook, cartelle o un intero repository. Non è possibile esportare file non notebook. Se si esporta un intero repository, i file non del notebook non sono inclusi. Per esportare, usare il workspace export comando nelDatabricks CLI o usare l'API dell'area di lavoro.
Sicurezza, autenticazione e token
Problema con un criterio di accesso condizionale (CAP) per Microsoft Entra ID
Quando si tenta di clonare un repository, è possibile che venga visualizzato un messaggio di errore "accesso negato" quando:
- Azure Databricks è configurato per l'uso di Azure DevOps con l'autenticazione Microsoft Entra ID.
- Hai abilitato un criterio di accesso condizionale in Azure DevOps e un criterio di accesso condizionale di Microsoft Entra ID.
Per risolvere questo problema, aggiungere un'esclusione ai criteri di accesso condizionale (CAP) per l'indirizzo IP o agli utenti di Azure Databricks.
Per altre informazioni, vedere Criteri di accesso condizionale.
Elenco autorizzati con token di Azure AD
Se si usa Azure Active Directory (AAD) per l'autenticazione con Azure DevOps, l'elenco autorizzati predefinito limita gli URL Git a:
dev.azure.comvisualstudio.com
Per altre informazioni, vedere Elenco autorizzati che limitano l'utilizzo del repository remoto.
Il contenuto delle cartelle Git di Azure Databricks è crittografato?
Il contenuto delle cartelle Git di Azure Databricks viene crittografato da Azure Databricks usando una chiave predefinita. La crittografia che usa chiavi gestite dal cliente non è supportata tranne quando si crittografano le credenziali Git.
Come e dove vengono archiviati i token GitHub in Azure Databricks? Chi avrebbe accesso da Azure Databricks?
- I token di autenticazione vengono archiviati nel piano di controllo di Azure Databricks e un dipendente di Azure Databricks può accedere solo tramite credenziali temporanee controllate.
- Azure Databricks registra la creazione e l'eliminazione di questi token, ma non il relativo utilizzo. Azure Databricks tiene traccia delle operazioni Git che possono essere usate per controllare l'utilizzo dei token dall'applicazione Azure Databricks.
- GitHub enterprise controlla l'utilizzo dei token. Altri servizi Git potrebbero anche avere il controllo del server Git.
Le cartelle Git supportano la firma GPG dei commit?
No.
Le cartelle Git supportano SSH?
No, solo HTTPS.
Errore durante la connessione di Azure Databricks a un repository Di Azure DevOps in una tenancy diversa
Quando si tenta di connettersi a DevOps in una tenancy separata, è possibile che venga visualizzato il messaggio Unable to parse credentials from Azure Active Directory account. Se il progetto Azure DevOps si trova in una tenancy di Microsoft Entra ID diversa da Azure Databricks, è necessario usare un token di accesso da Azure DevOps. Vedere Connettersi a un repository di Azure DevOps usando un token DevOps.
CI/CD e MLOps
Le modifiche in ingresso cancellano lo stato del notebook
Le operazioni Git che modificano il codice sorgente del notebook comportano la perdita dello stato del notebook, inclusi output delle celle, commenti, cronologia versioni e widget. Ad esempio, git pull può modificare il codice sorgente di un notebook. In questo caso, le cartelle Git di Databricks devono sovrascrivere il notebook esistente per importare le modifiche. git commit e push o la creazione di un nuovo ramo non influiscono sul codice sorgente del notebook, quindi lo stato del notebook viene mantenuto in queste operazioni.
Importante
Gli esperimenti MLflow non funzionano nelle cartelle Git con DBR 14.x o versioni precedenti.
È possibile creare un esperimento MLflow in un repository?
Esistono due tipi di esperimenti MLflow: area di lavoro e notebook. Per altre informazioni sui due tipi di esperimenti MLflow, vedere Organizzare le esecuzioni di training con esperimenti MLflow.
Nelle cartelle Git è possibile chiamare mlflow.set_experiment("/path/to/experiment") per un esperimento MLflow di entrambi i tipi e registrarli, ma tale esperimento e le esecuzioni associate non verranno controllate nel controllo del codice sorgente.
Esperimenti MLflow dell'area di lavoro
Non è possibile creare esperimenti MLflow dell'area di lavoro in una cartella Git di Databricks (cartella Git). Se più utenti usano cartelle Git separate per collaborare allo stesso codice ML, il log MLflow viene eseguito in un esperimento MLflow creato in una normale cartella dell'area di lavoro.
Esperimenti MLflow notebook
È possibile creare esperimenti di notebook in una cartella Git di Databricks. Se si archivia il notebook nel controllo del codice sorgente come file .ipynb, è possibile registrare le esecuzioni di MLflow in un esperimento MLflow creato e associato automaticamente. Per altre informazioni, vedere Creazione di esperimenti di notebook.
Evitare la perdita di dati negli esperimenti MLflow
Gli esperimenti MLflow del notebook creati con Lavori Databricks con codice sorgente in un repository remoto vengono archiviati in una posizione di archiviazione temporanea. Questi esperimenti vengono mantenuti inizialmente dopo l'esecuzione del flusso di lavoro, ma sono a rischio di eliminazione in un secondo momento durante la rimozione pianificata dei file nell'archiviazione temporanea. Databricks consiglia di usare esperimenti MLflow dell'area di lavoro con Lavori e origini Git remote.
Avviso
Ogni volta che si passa a un ramo che non contiene il notebook, si rischia di perdere i dati dell'esperimento MLflow associati. Questa perdita diventa definitiva se non si esegue l’accesso al ramo precedente entro 30 giorni.
Per recuperare i dati dell'esperimento mancanti prima dei 30 giorni, rinominare nuovamente il notebook con il nome originale, aprire il notebook, fare clic sull'icona "esperimento" nel riquadro laterale a destra (che chiama in modo efficace anche l'API mlflow.get_experiment_by_name() ) e sarà possibile visualizzare l'esperimento e le esecuzioni ripristinate. Dopo 30 giorni, tutti gli esperimenti MLflow orfani verranno eliminati per soddisfare i criteri di conformità GDPR.
Per evitare questa situazione, Databricks consiglia di evitare di rinominare completamente i notebook nei repository oppure, se si rinomina un notebook, fare clic sull'icona "esperimento" nel riquadro laterale a destra immediatamente dopo la rinomina di un notebook.
Cosa accade se un lavoro notebook è in esecuzione in un'area di lavoro mentre è in corso un'operazione Git?
In qualsiasi momento, mentre è in corso un'operazione Git, alcuni notebook nel repository potrebbero essere stati aggiornati mentre altri non lo sono. Ciò può causare un comportamento imprevedibile.
Supponi, ad esempio, che notebook A chiami notebook Z usando un %run comando. Se un lavoro in esecuzione durante un'operazione Git avvia la versione più recente di notebook A, ma notebook Z non è ancora stato aggiornato, il %run comando nel notebook A potrebbe avviare la versione precedente di notebook Z.
Durante l'operazione Git, gli stati del notebook non sono prevedibili e il lavoro potrebbe non riuscire o eseguire notebook A e notebook Z da commit diversi.
Per evitare questa situazione, usare invece lavori basati su Git (dove l'origine è un operatore Git e non un percorso dell'area di lavoro). Per altre informazioni, vedere Usare Git con i lavori.
Risorse
Per altre informazioni sui file dell'area di lavoro di Databricks, vedere Che cosa sono i file di area di lavoro?.