Eseguire la migrazione di un cluster HDInsight a una versione più recente
Per poter sfruttare le funzionalità più recenti di HDInsight, è consigliabile che i cluster HDInsight siano aggiornati regolarmente alla versione più recente. HDInsight non supporta gli aggiornamenti sul posto in cui un cluster esistente viene aggiornato a una versione più recente del componente. È necessario creare un nuovo cluster con il componente e la versione della piattaforma desiderati e quindi eseguire la migrazione delle applicazioni per usare il nuovo cluster. Seguire le linee guida seguenti per eseguire la migrazione delle versioni del cluster HDInsight.
Nota
Se si crea un cluster Hive con un contenitore di archiviazione primario, copiarlo da un cluster HDInsight esistente. Non copiare il contenuto completo. Copiare solo le cartelle dati configurate.
Il flusso di lavoro per eseguire l'aggiornamento del cluster HDInsight è il seguente.
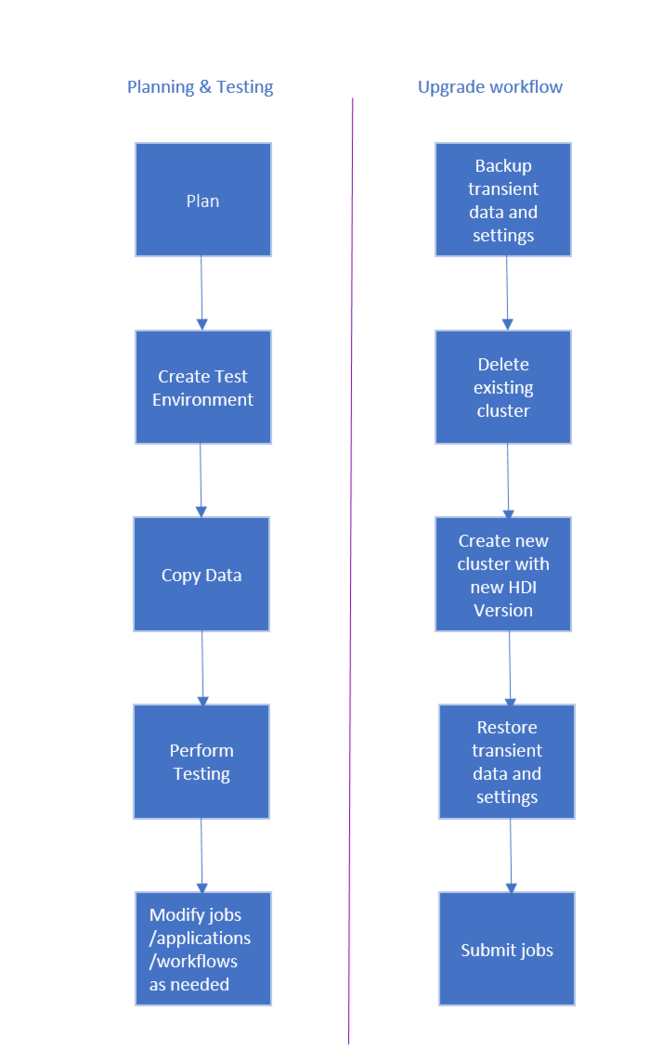
- Leggere interamente questo documento per comprendere le modifiche che potrebbero essere necessarie durante l'aggiornamento del cluster HDInsight.
- Creare un cluster come ambiente di test/controllo qualità. Per altre informazioni sulla creazione di un cluster, vedere Informazioni su come creare cluster HDInsight basati su Linux.
- Copiare processi esistenti, origini dati e sink nel nuovo ambiente.
- Eseguire il test di convalida per assicurarsi che i processi funzionino come previsto nel nuovo cluster.
Dopo aver verificato che tutto funzioni come previsto, pianificare il tempo di inattività per la migrazione. Durante questo periodo di inattività, eseguire le operazioni seguenti.
- Eseguire il backup tutti i dati temporanei archiviati localmente sui nodi del cluster, Ad esempio, se i dati sono archiviati direttamente in un nodo head.
- Eliminare il cluster esistente.
- Creare un cluster nella stessa subnet di rete virtuale con la versione più recente supportata di HDI, usando lo stesso archivio dati predefinito usato dal cluster precedente. In questo modo il nuovo cluster continuerà a lavorare con i dati di produzione esistenti.
- Importare i dati temporanei di cui è stata eseguita una copia di backup.
- Avviare processi/continuare l'elaborazione con il nuovo cluster.
I documenti seguenti forniscono indicazioni su come eseguire la migrazione di carichi di lavoro specifici:
- Eseguire la migrazione di HBase
- Eseguire la migrazione di Kafka
- Eseguire la migrazione di Hive/Interactive Query
Per altre informazioni sul backup e il ripristino del database, vedere Ripristinare un database in database SQL di Azure usando backup automatici del database.
Come accennato in precedenza, Microsoft consiglia di eseguire regolarmente la migrazione dei cluster HDInsight alla versione più recente per sfruttare le nuove funzionalità e le correzioni. Vedere l'elenco seguente dei motivi per cui è necessario eliminare e ridistribuire un cluster:
- La versione del cluster è ritirata o se si verifica un problema del cluster che verrebbe risolto con una versione più recente.
- La causa radice di un problema del cluster è determinata per correlare una macchina virtuale sottodimensionata. Visualizzare la configurazione del nodo consigliata da Microsoft.
- Un cliente apre un caso di supporto e il team tecnico Microsoft determina che il problema è già stato risolto in una versione più recente del cluster.
- Un database metastore predefinito (Ambari, Hive, Oozie, Ranger) ha raggiunto il limite di utilizzo. Microsoft chiede di ricreare il cluster usando un database di metastore personalizzato.
- La causa radice di un problema del cluster è dovuta a un'operazione non supportata. Ecco alcune delle operazioni comuni non supportate:
- Spostamento o aggiunta di un servizio in Ambari. Vedere le informazioni sui servizi cluster in Ambari, una delle azioni disponibili nel menu Azioni del servizio è Sposta [Nome servizio]. Un'altra azione è Add [Service Name]. Entrambe queste opzioni non sono supportate.
- Danneggiamento del pacchetto Python. I cluster HDInsight dipendono dagli ambienti Python predefiniti, Python 2.7 e Python 3.5. L'installazione diretta di pacchetti personalizzati in questi ambienti predefiniti predefiniti può causare modifiche impreviste alla versione della libreria e interrompere il cluster. Informazioni su come installare in modo sicuro pacchetti Python esterni personalizzati per le applicazioni Spark.
- Software di terze parti. I clienti hanno la possibilità di installare software di terze parti nei cluster HDInsight; Tuttavia, è consigliabile ricreare il cluster se interrompe la funzionalità esistente.
- Più carichi di lavoro nello stesso cluster. In HDInsight 4.0, Hive Warehouse Connector richiede cluster separati per carichi di lavoro Spark e Interactive Query. Seguire questa procedura per configurare entrambi i cluster in Azure HDInsight. Analogamente, l'integrazione di Spark con HBASE richiede due cluster diversi.
- Password personalizzata del database Ambari modificata. La password del database Ambari viene impostata durante la creazione del cluster e non esiste alcun meccanismo corrente per aggiornarlo. Se un cliente distribuisce il cluster con un database Ambari personalizzato, ha la possibilità di modificare la password del database nel database SQL. Tuttavia, non è possibile aggiornare questa password per un cluster HDInsight in esecuzione.
- Modifica dei servizi di bilanciamento del carico di HDInsight. I servizi di bilanciamento del carico HDInsight distribuiti automaticamente per L'accesso Ambari e SSH non devono essere modificati o eliminati. Se si modificano i servizi di bilanciamento del carico HDInsight e si interrompe la funzionalità del cluster, si consiglia di ridistribuire il cluster.
- Riutilizzo dei database Ranger 4.X nella versione 5.X. HDInsight 5.1 include Apache Ranger versione 2.3.0 , che è l'aggiornamento della versione principale dalla versione 1.2.0 nei cluster HDInsight 4.X. Il riutilizzo di un database Ranger di HDInsight 4.X in HDInsight 5.1 impedisce l'avvio del servizio Ranger a causa delle differenze nello schema del database. Per distribuire correttamente cluster ESP HDInsight 5.1, è necessario creare un database Ranger vuoto.