Usare le funzionalità estese del server cronologia Apache Spark per eseguire il debug e la diagnosi delle applicazioni Spark
Questo articolo illustra come usare le funzionalità estese del server cronologia Apache Spark per eseguire il debug e la diagnosi delle applicazioni Spark completate o in esecuzione. L'estensione include una scheda Dati, una scheda Grafico e una scheda Diagnosi. Nella scheda Dati è possibile controllare i dati di input e output del processo Spark. Nella scheda Grafico è possibile controllare il flusso di dati e riprodurre il grafico del processo. Nella scheda Diagnosi è possibile fare riferimento alle funzionalità Disimmetria dei dati, Asimmetria temporale ed Analisi dell'utilizzo dell'executor.
Ottenere l'accesso al server cronologia Spark
Il server cronologia Spark è l'interfaccia utente Web per le applicazioni Spark completate e in esecuzione. È possibile aprirlo dal portale di Azure o da un URL.
Aprire l'interfaccia utente Web del server cronologia Spark dal portale di Azure
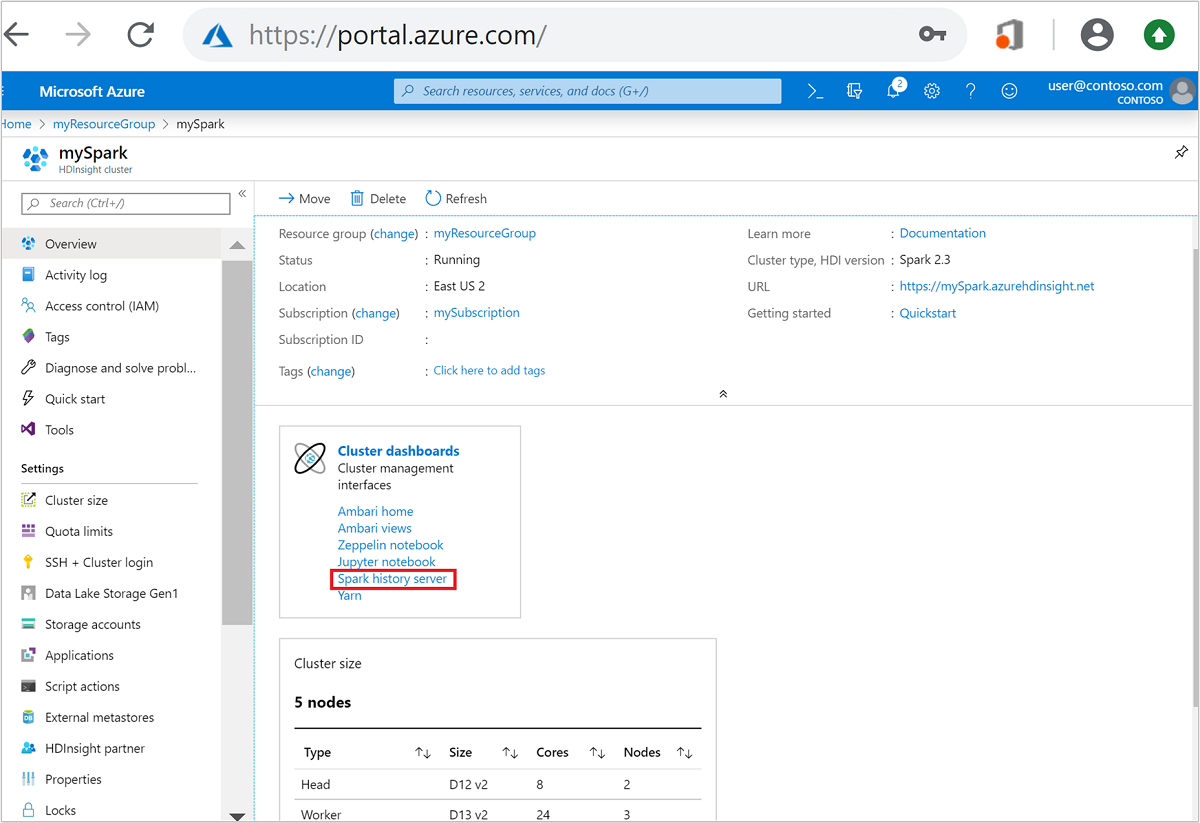
Nel portale di Azure aprire il cluster Spark. Per altre informazioni, vedere Elencare e visualizzare i cluster.
In Dashboard del cluster selezionare Server cronologia Spark. Quando richiesto, immettere le credenziali di amministratore per il cluster di Spark.
 il portale di Azure." border="true":::
il portale di Azure." border="true":::
Aprire l'interfaccia utente Web del server cronologia Spark in base all'URL
Aprire il server cronologia Spark passando a https://CLUSTERNAME.azurehdinsight.net/sparkhistory, dove CLUSTERNAME è il nome del cluster Spark.
L'interfaccia utente Web del server cronologia Spark potrebbe essere simile a questa immagine:

Usare la scheda Dati nel server cronologia Spark
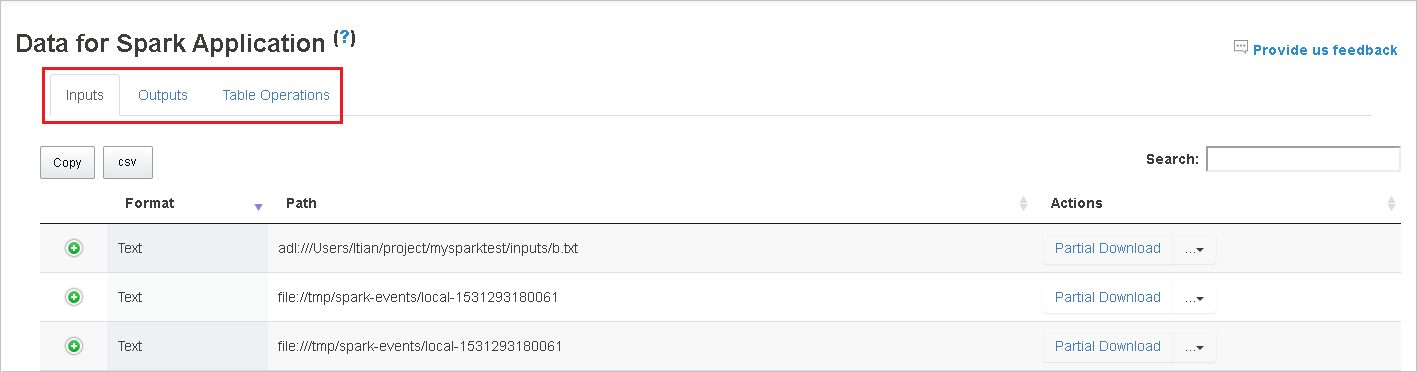
Selezionare l'ID processo e quindi selezionare Dati dal menu degli strumenti per visualizzare la visualizzazione dati.
Esaminare input, output e operazioni di tabella selezionando le singole schede.
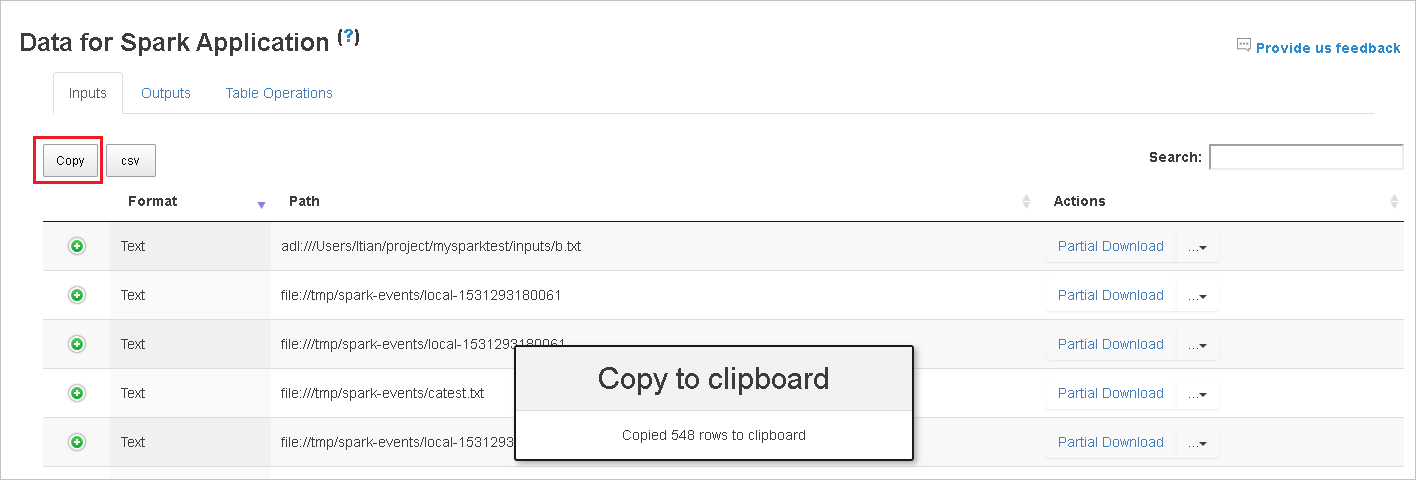
Copiare tutte le righe selezionando il pulsante Copia .
Salvare tutti i dati come . File CSV selezionando il pulsante csv .

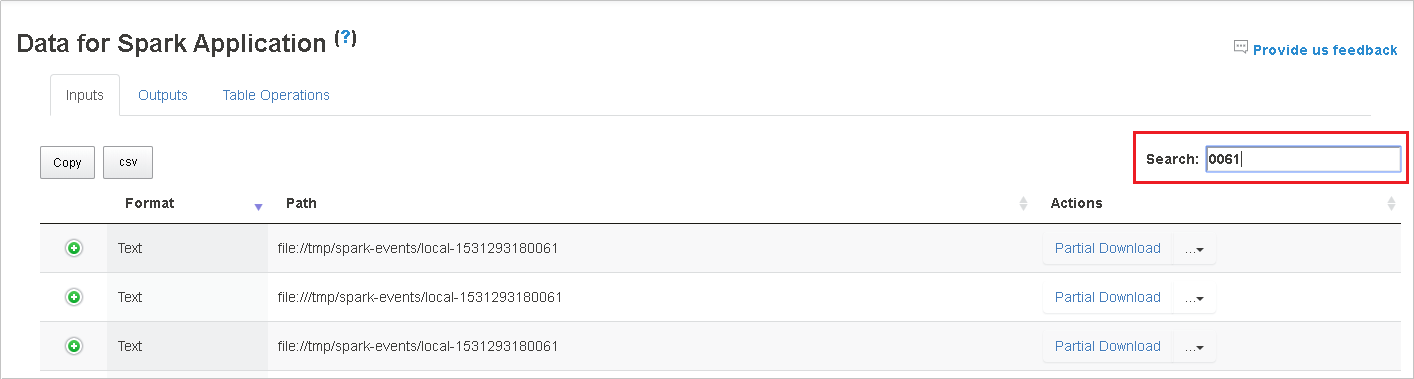
Cercare i dati immettendo parole chiave nel campo Cerca . I risultati della ricerca verranno visualizzati immediatamente.
Selezionare l'intestazione di colonna per ordinare la tabella. Selezionare il segno più per espandere una riga per visualizzare altri dettagli. Selezionare il segno meno per comprimere una riga.
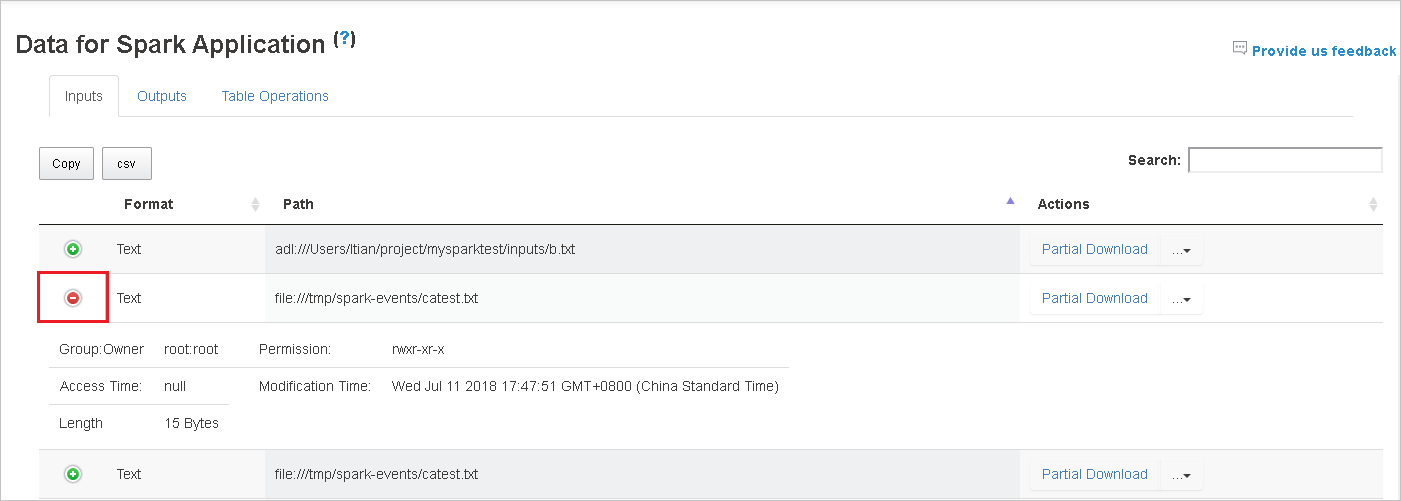
Scaricare un singolo file selezionando il pulsante Download parziale a destra. Il file selezionato verrà scaricato localmente. Se il file non esiste più, verrà aperta una nuova scheda per visualizzare i messaggi di errore.
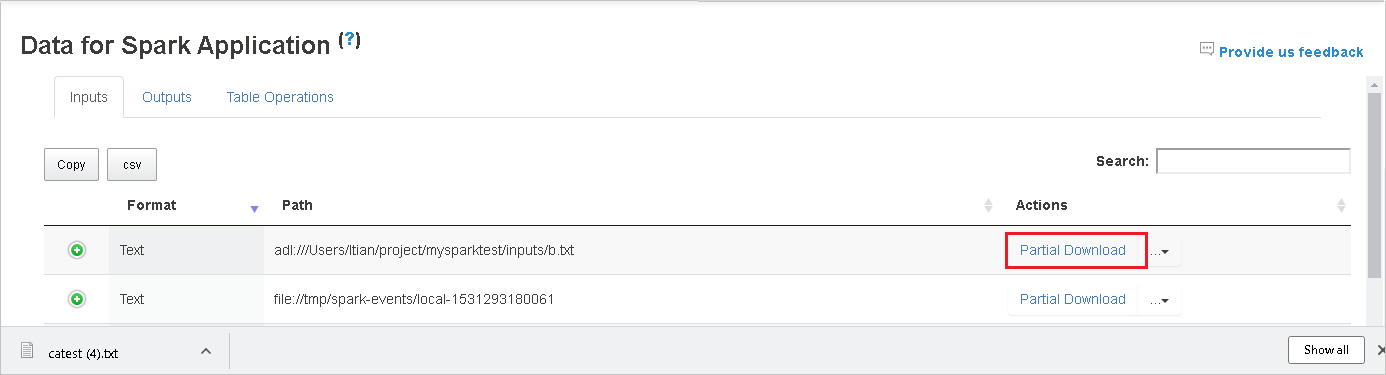
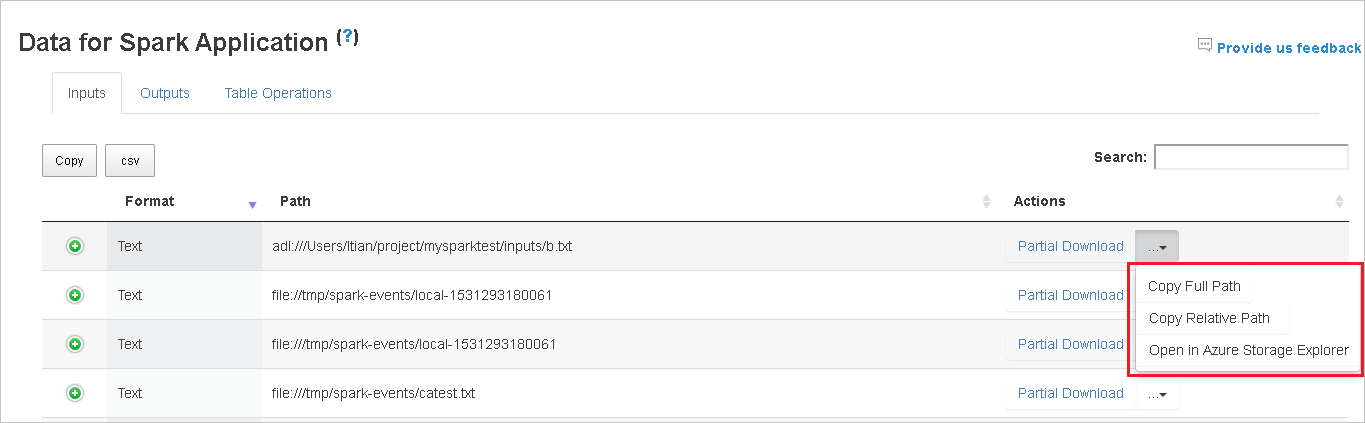
Copiare un percorso completo o un percorso relativo selezionando l'opzione Copia percorso completo o Copia percorso relativo, che si espande dal menu di download. Per i file di Archiviazione di Azure Data Lake, selezionare Apri in esplora Archiviazione di Azure per avviare Esplora Archiviazione di Azure e individuare la cartella dopo l'accesso.
Se sono presenti troppe righe da visualizzare in una singola pagina, selezionare i numeri di pagina nella parte inferiore della tabella da esplorare.

Per altre informazioni, passare il puntatore del mouse o selezionare il punto interrogativo accanto a Data for Spark Application (Dati per l'applicazione Spark) per visualizzare la descrizione comando.
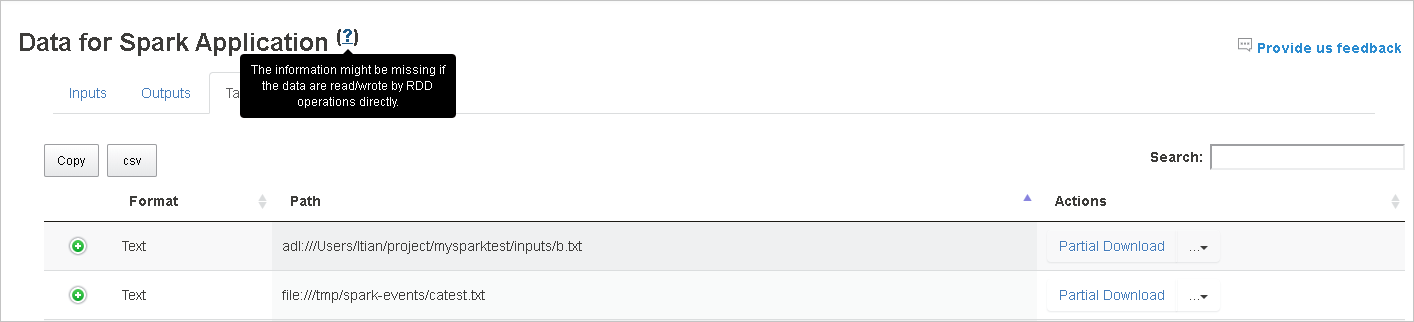
Per inviare commenti e suggerimenti sui problemi, selezionare Invia commenti e suggerimenti.
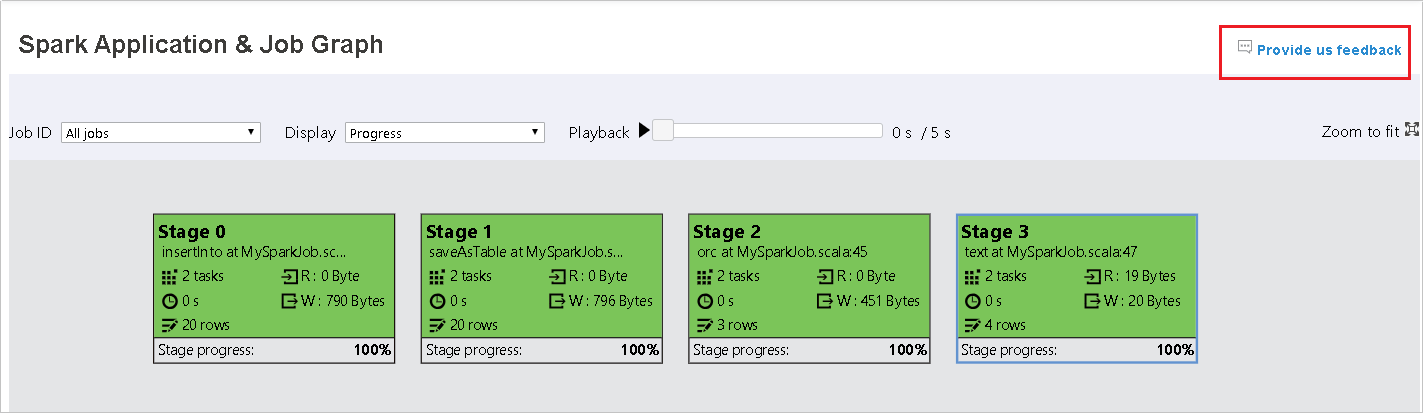
Usare la scheda Graph nel server cronologia Spark
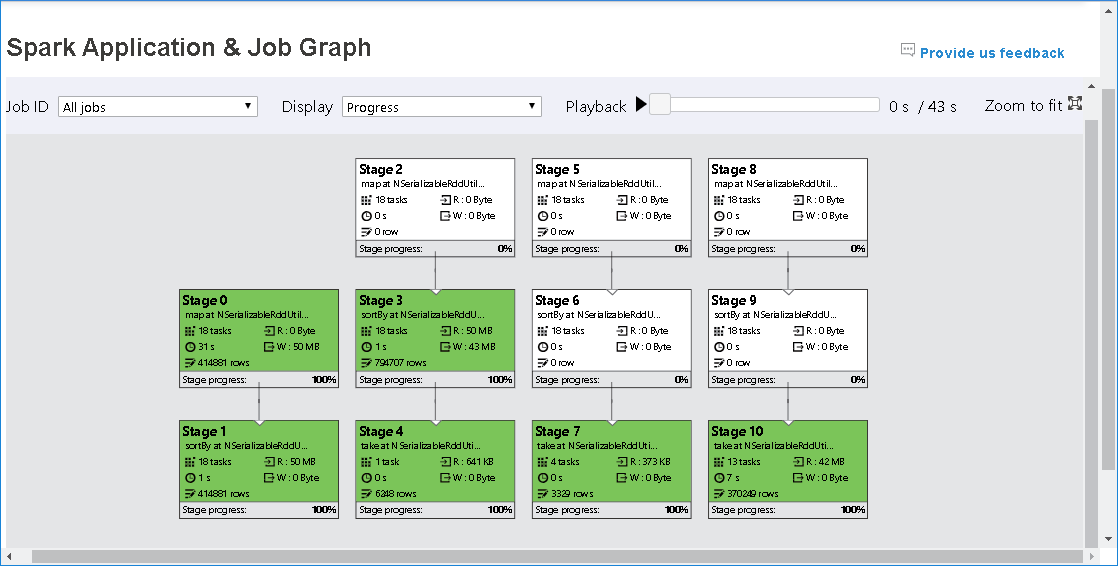
Selezionare l'ID processo e quindi selezionare Graph nel menu degli strumenti per visualizzare il grafico del processo. Per impostazione predefinita, il grafico mostrerà tutti i processi. Filtrare i risultati usando il menu a discesa ID processo.
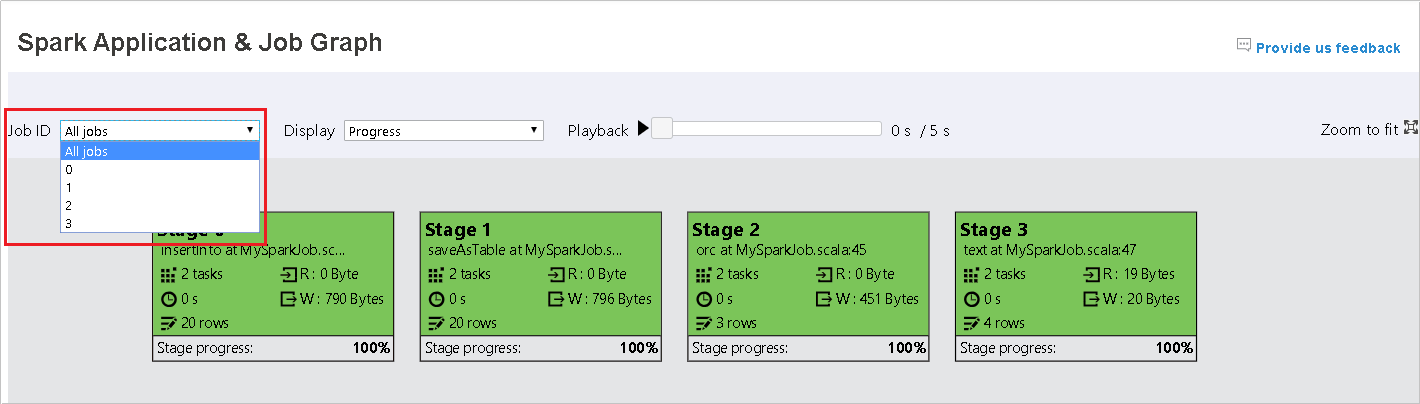
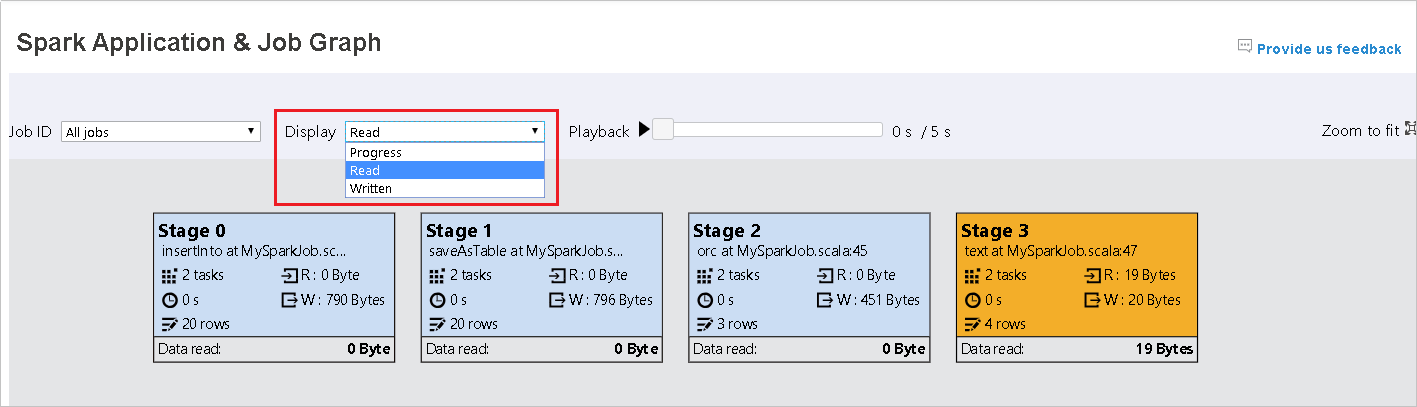
Lo stato di avanzamento è selezionato per impostazione predefinita. Controllare il flusso di dati selezionando Lettura o Scrittura nel menu a discesa Visualizza .
Il colore di sfondo di ogni attività corrisponde a una mappa termica.

Color Descrizione Verde il processo è stato completato correttamente. Orange L'attività non è riuscita, ma questo non influisce sul risultato finale del processo. Queste attività hanno istanze duplicate o di ripetizione dei tentativi che potrebbero avere esito positivo in un secondo momento. Blu l'attività è in esecuzione. Bianco l'attività è in attesa di esecuzione o la fase è stata ignorata. Rosso l'attività non è riuscita. 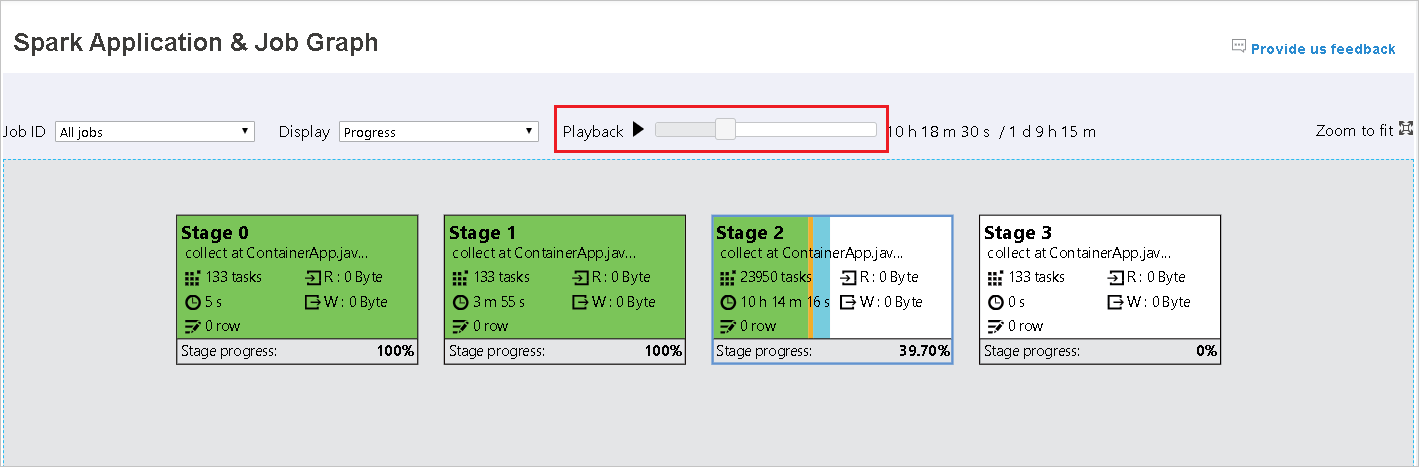
Le fasi ignorate vengono visualizzate in bianco.
Nota
La riproduzione è disponibile per i processi completati. Selezionare il pulsante Riproduzione per riprodurre il processo. Arrestare il processo in qualsiasi momento selezionando il pulsante Arresta. Quando un processo viene riprodotto, ogni attività visualizzerà lo stato in base al colore. La riproduzione non è supportata per i processi incompleti.
Scorrere per ingrandire o ridurre il grafico del processo oppure selezionare Zoom per adattarlo allo schermo.
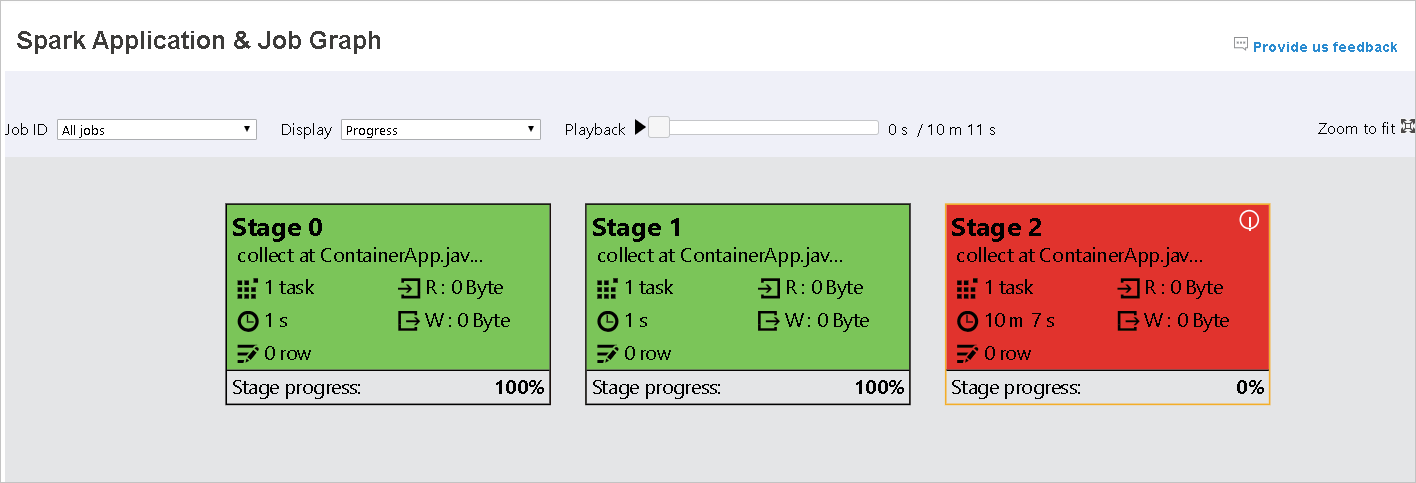
Quando le attività hanno esito negativo, passare il puntatore del mouse sul nodo del grafo per visualizzare la descrizione comando e quindi selezionare la fase per aprirla in una nuova pagina.
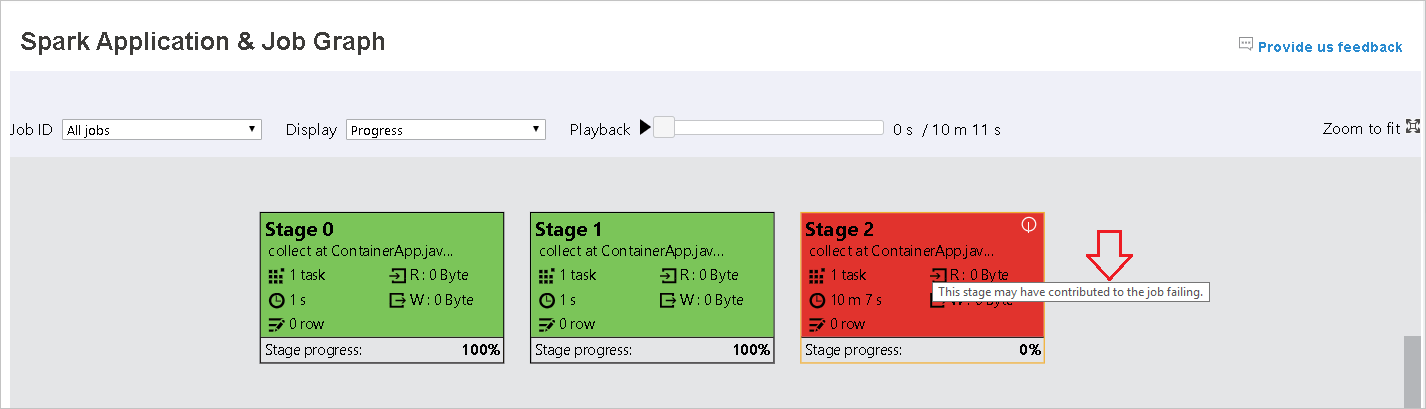
Nella pagina Grafico applicazioni e processi Spark le fasi visualizzeranno descrizioni comando e icone piccole se le attività soddisfano queste condizioni:
Asimmetria dei dati: dimensioni medie di lettura dei dati delle dimensioni > medie di tutte le attività all'interno di questa fase * 2 e dimensioni > di lettura dei dati 10 MB.
Differenza di tempo: tempo > medio di esecuzione di tutte le attività all'interno di questa fase * 2 e tempo > di esecuzione 2 minuti.
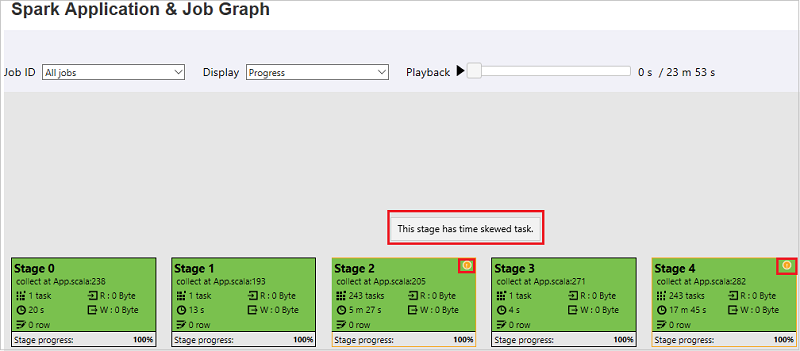
Il nodo del grafico del processo visualizzerà le informazioni seguenti su ogni fase:
ID
Nome o descrizione
Numero totale attività
Dati letti: la somma delle dimensioni di input e delle dimensioni di lettura casuali
Scrittura di dati: la somma delle dimensioni di output e delle dimensioni di scrittura casuali
Tempo di esecuzione: ora di inizio del primo tentativo e ora di completamento dell'ultimo tentativo
Conteggio righe: somma di record di input, record di output, record di lettura casuale e record di scrittura casuale
Avanzamento
Nota
Per impostazione predefinita, il nodo del grafico del processo visualizzerà le informazioni dell'ultimo tentativo di ogni fase ,ad eccezione del tempo di esecuzione della fase. Durante la riproduzione, tuttavia, il nodo del grafico del processo mostrerà informazioni su ogni tentativo.
Nota
Per le dimensioni di lettura e scrittura dei dati, si usano 1 MB = 1000 KB = 1000 * 1000 byte.
Inviare commenti e suggerimenti sui problemi selezionando Invia commenti e suggerimenti.
Usare la scheda Diagnosi nel server cronologia Spark
Selezionare l'ID processo e quindi selezionare Diagnosi nel menu degli strumenti per visualizzare la visualizzazione diagnosi del processo. La scheda Diagnosi include l'asimmetria dei dati, l'asimmetria temporale e l'analisi dell'utilizzo dell'executor.
Esaminare l'asimmetria dei dati, l'asimmetria temporale e l'analisi dell'utilizzo dell'executor selezionando le schede rispettivamente.

Asimmetria dei dati
Selezionare la scheda Asimmetria dati. Le attività asimmetriche corrispondenti vengono visualizzate in base ai parametri specificati.
Specificare i parametri
Nella sezione Specifica parametri vengono visualizzati i parametri usati per rilevare l'asimmetria dei dati. La regola predefinita è: i dati delle attività letti sono maggiori di tre volte della media dei dati delle attività letti e i dati delle attività letti sono superiori a 10 MB. Se si vuole definire una regola personalizzata per le attività asimmetriche, è possibile scegliere i parametri. Le sezioni Skewed Stage e Skew Chart verranno aggiornate di conseguenza.
Fase asimmetrica
Nella sezione Fase asimmetrica vengono visualizzate le fasi con attività asimmetrice che soddisfano i criteri specificati. Se in una fase sono presenti più attività asimmetrice, nella sezione Fase asimmetrica viene visualizzata solo l'attività più asimmetrica, ovvero i dati più grandi per l'asimmetria dei dati.
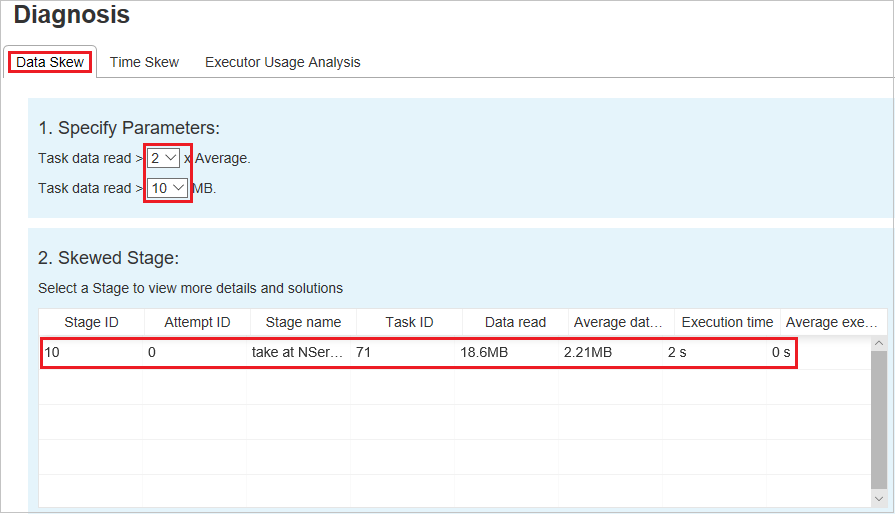
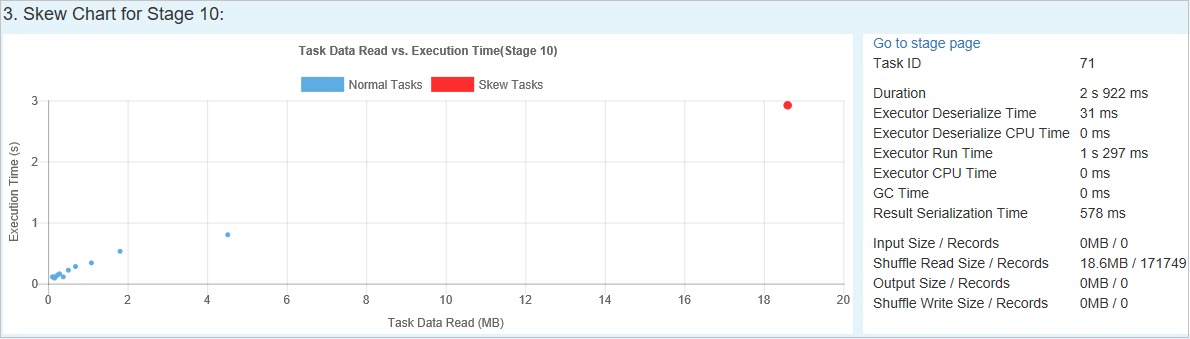
Grafico asimmetria
Quando si seleziona una riga nella tabella Fase asimmetria , il grafico asimmetria visualizza più dettagli di distribuzione delle attività in base al tempo di lettura e esecuzione dei dati. Le attività asimmetriche sono contrassegnate in rosso e le normali attività sono contrassegnate in blu. Per considerazioni sulle prestazioni, il grafico visualizza fino a 100 attività di esempio. I dettagli dell'attività vengono visualizzati nel pannello in basso a destra.
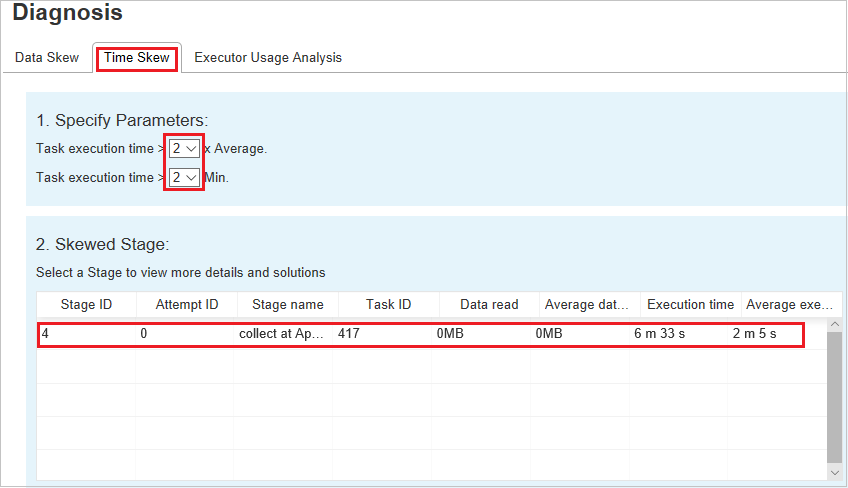
Sfasamento dell'ora
La scheda Sfasamento dell'ora visualizza le attività asimmetriche in base al tempo di esecuzione.
Specificare i parametri
Nella sezione Specifica parametri vengono visualizzati i parametri usati per rilevare l'asimmetria temporale. La regola predefinita è: il tempo di esecuzione dell'attività è maggiore di tre volte del tempo medio di esecuzione e il tempo di esecuzione dell'attività è maggiore di 30 secondi. È possibile modificare i parametri in base alle esigenze. La fase asimmetrica e il grafico asimmetria visualizzano le informazioni sulle fasi e sulle attività corrispondenti, proprio come nella scheda Asimmetria dei dati.
Quando si seleziona Sfasamento temporale, il risultato filtrato viene visualizzato nella sezione Fase asimmetrica, in base ai parametri impostati nella sezione Specifica parametri . Quando si seleziona un elemento nella sezione Fase asimmetrica, il grafico corrispondente viene disegnato nella terza sezione e i dettagli dell'attività vengono visualizzati nel pannello in basso a destra.
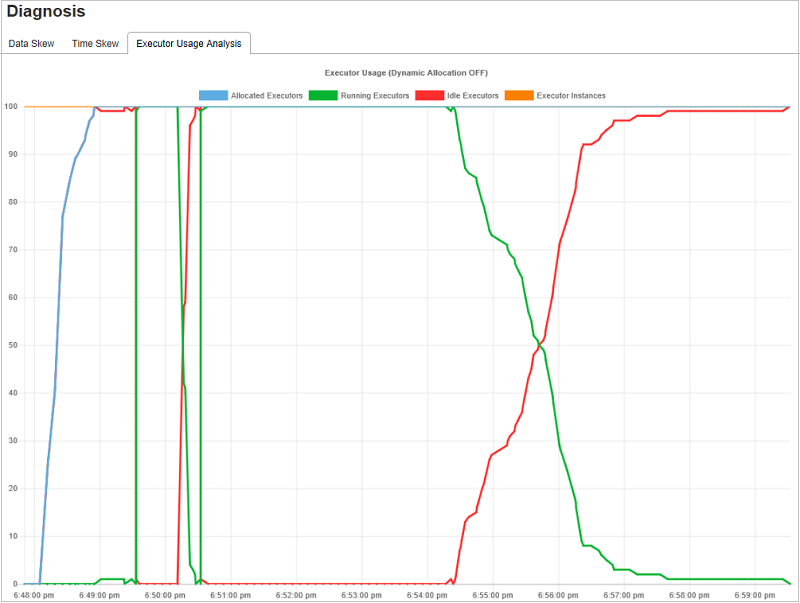
Grafici dell'analisi dell'utilizzo dell'executor
Il grafico utilizzo executor visualizza l'allocazione effettiva dell'executor e lo stato di esecuzione del processo.
Quando si seleziona Analisi utilizzo executor, vengono elaborate quattro curve diverse sull'utilizzo dell'executor: executor allocati, executor in esecuzione, executor inattivi e istanze max executor. Ogni executor aggiunto o executor rimosso evento aumenterà o ridurrà gli executor allocati. Per altri confronti, è possibile selezionare Sequenza temporale eventi nella scheda Processi .
Selezionare l'icona del colore per selezionare o deselezionare il contenuto corrispondente in tutte le bozze.
Domande frequenti
Ricerca per categorie ripristinare la versione della community?
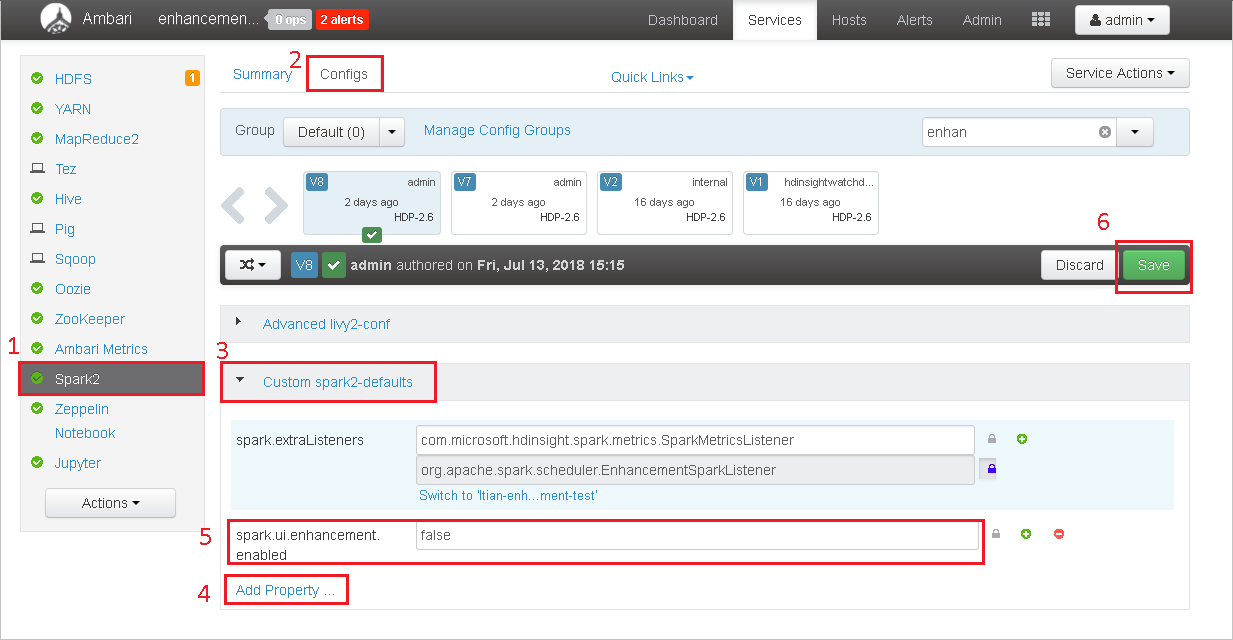
Per ripristinare la versione della community, seguire questa procedura.
Aprire il cluster in Ambari.
Passare a Configurazioni Spark2>.
Selezionare Custom spark2-defaults (Impostazioni predefinite spark2 personalizzate).
Selezionare Aggiungi proprietà ....
Aggiungere spark.ui.enhancement.enabled=false e quindi salvarlo.
La proprietà viene impostata su false.
Seleziona Salva per salvare la configurazione.
Selezionare Spark2 nel pannello sinistro. Quindi, nella scheda Riepilogo selezionare Server cronologia Spark2.
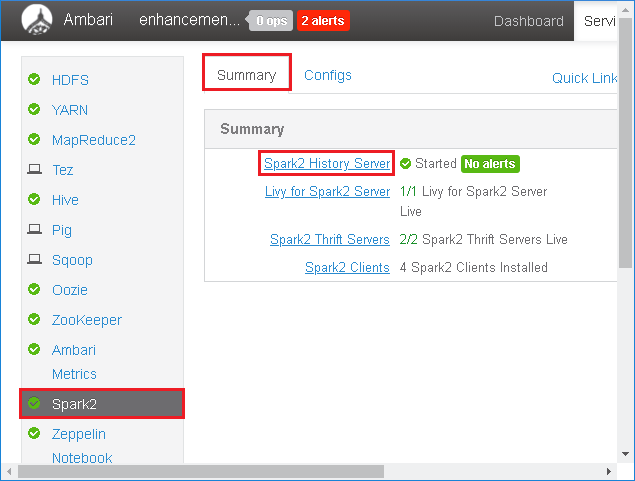
Per riavviare il server cronologia Spark, selezionare il pulsante Avviato a destra del server cronologia Spark2 e quindi selezionare Riavvia dal menu a discesa.
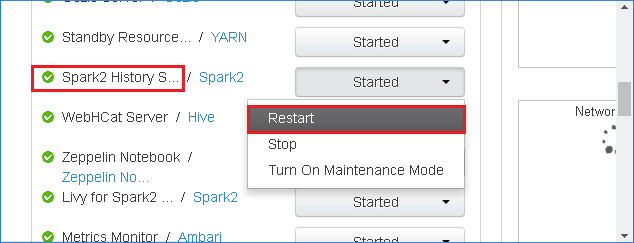
Aggiornare l'interfaccia utente Web del server cronologia Spark. Verrà ripristinata la versione della community.
Ricerca per categorie caricare un evento del server cronologia Spark per segnalarlo come problema?
Se si verifica un errore nel server cronologia Spark, seguire questa procedura per segnalare l'evento.
Scaricare l'evento selezionando Download nell'interfaccia utente Web del server cronologia Spark.
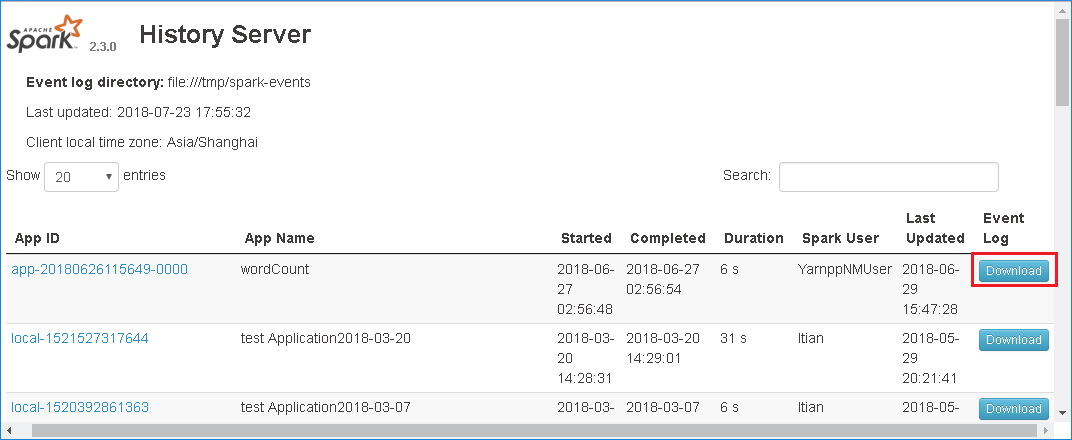
Selezionare Invia commenti e suggerimenti nella pagina Spark Application & Job Graph .
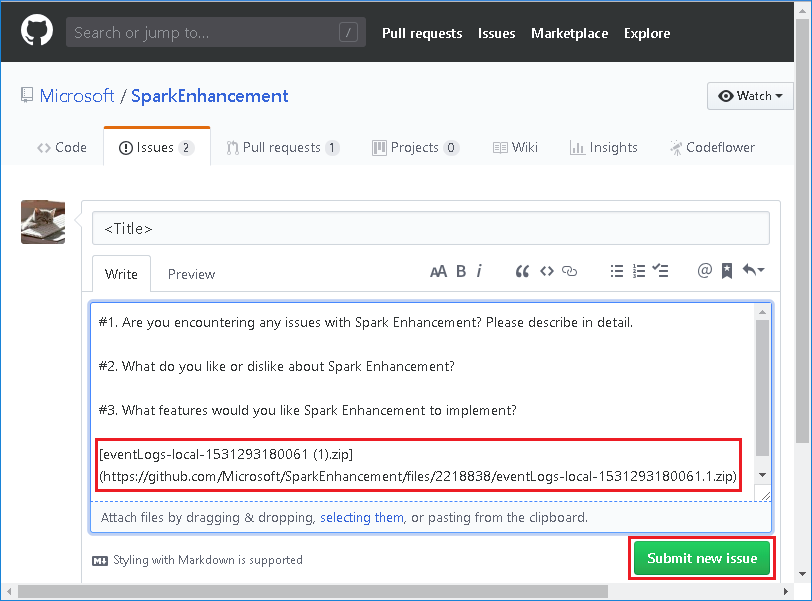
Specificare il titolo e una descrizione dell'errore. Trascinare quindi il file .zip nel campo di modifica e selezionare Invia nuovo problema.
Ricerca per categorie aggiornare un file di .jar in uno scenario di hotfix?
Se si vuole eseguire l'aggiornamento con un hotfix, usare lo script seguente, che aggiornerà spark-enhancement.jar*.
upgrade_spark_enhancement.sh:
#!/usr/bin/env bash
# Copyright (C) Microsoft Corporation. All rights reserved.
# Arguments:
# $1 Enhancement jar path
if [ "$#" -ne 1 ]; then
>&2 echo "Please provide the upgrade jar path."
exit 1
fi
install_jar() {
tmp_jar_path="/tmp/spark-enhancement-hotfix-$( date +%s )"
if wget -O "$tmp_jar_path" "$2"; then
for FILE in "$1"/spark-enhancement*.jar
do
back_up_path="$FILE.original.$( date +%s )"
echo "Back up $FILE to $back_up_path"
mv "$FILE" "$back_up_path"
echo "Copy the hotfix jar file from $tmp_jar_path to $FILE"
cp "$tmp_jar_path" "$FILE"
"Hotfix done."
break
done
else
>&2 echo "Download jar file failed."
exit 1
fi
}
jars_folder="/usr/hdp/current/spark2-client/jars"
jar_path=$1
if ls ${jars_folder}/spark-enhancement*.jar 1>/dev/null 2>&1; then
install_jar "$jars_folder" "$jar_path"
else
>&2 echo "There is no target jar on this node. Exit with no action."
exit 0
fi
Utilizzo
upgrade_spark_enhancement.sh https://${jar_path}
Esempio
upgrade_spark_enhancement.sh https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar
Usare il file bash dal portale di Azure
Avviare il portale di Azure e quindi selezionare il cluster.
Completare un'azione script con i parametri seguenti.
Proprietà valore Tipo di script - Personalizzato Nome UpgradeJar URI script Bash https://hdinsighttoolingstorage.blob.core.windows.net/shsscriptactions/upgrade_spark_enhancement.shTipo/i di nodo Head, Worker Parametri https://${account_name}.blob.core.windows.net/packages/jars/spark-enhancement-${version}.jar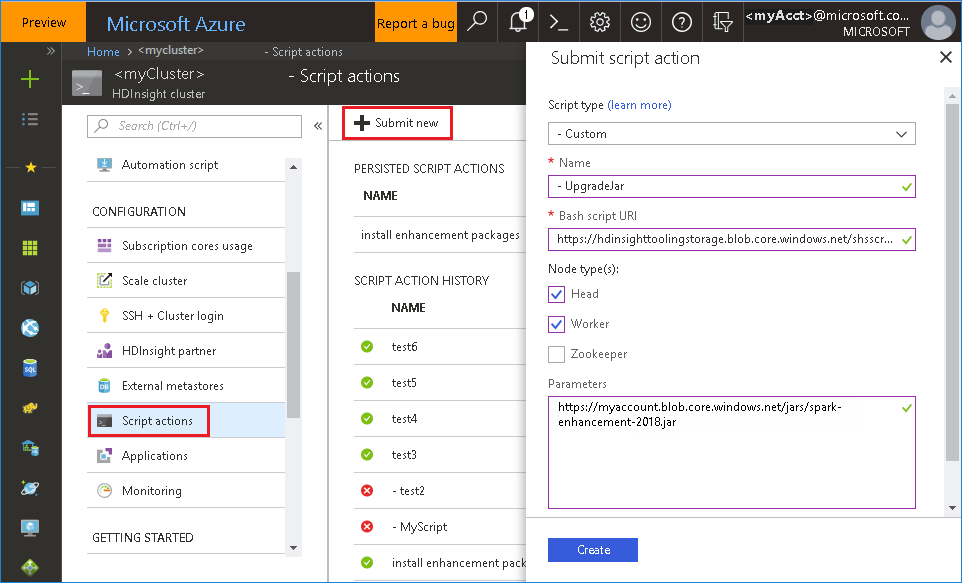
Problemi noti
Attualmente, il server cronologia Spark funziona solo per Spark 2.3 e 2.4.
I dati di input e output che usano RDD non verranno visualizzati nella scheda Dati .
Passaggi successivi
- Gestire le risorse di un cluster Apache Spark in HDInsight
- Configurare le impostazioni di Apache Spark
Suggerimenti
Se si hanno commenti e suggerimenti o si verificano problemi durante l'uso di questo strumento, inviare un messaggio di posta elettronica a (hdivstool@microsoft.com).