Gestire le risorse del cluster Apache Spark in Azure HDInsight
Informazioni su come accedere a interfacce associate al cluster Apache Spark, come l'interfaccia utente di Apache Ambari, l'interfaccia utente di Apache Hadoop YARN e Server cronologia Spark, e come modificare la configurazione del cluster per ottenere prestazioni ottimali.
Aprire il Server cronologia Spark
Server cronologia Spark è l'interfaccia utente Web per le applicazioni Spark completate e in esecuzione. Si tratta di un'estensione dell'interfaccia utente Web di Spark. Per informazioni complete, vedere Server cronologia Spark.
Aprire l'interfaccia utente di YARN
È possibile usare l'interfaccia utente di YARN per il monitoraggio delle applicazioni attualmente in esecuzione nel cluster Spark.
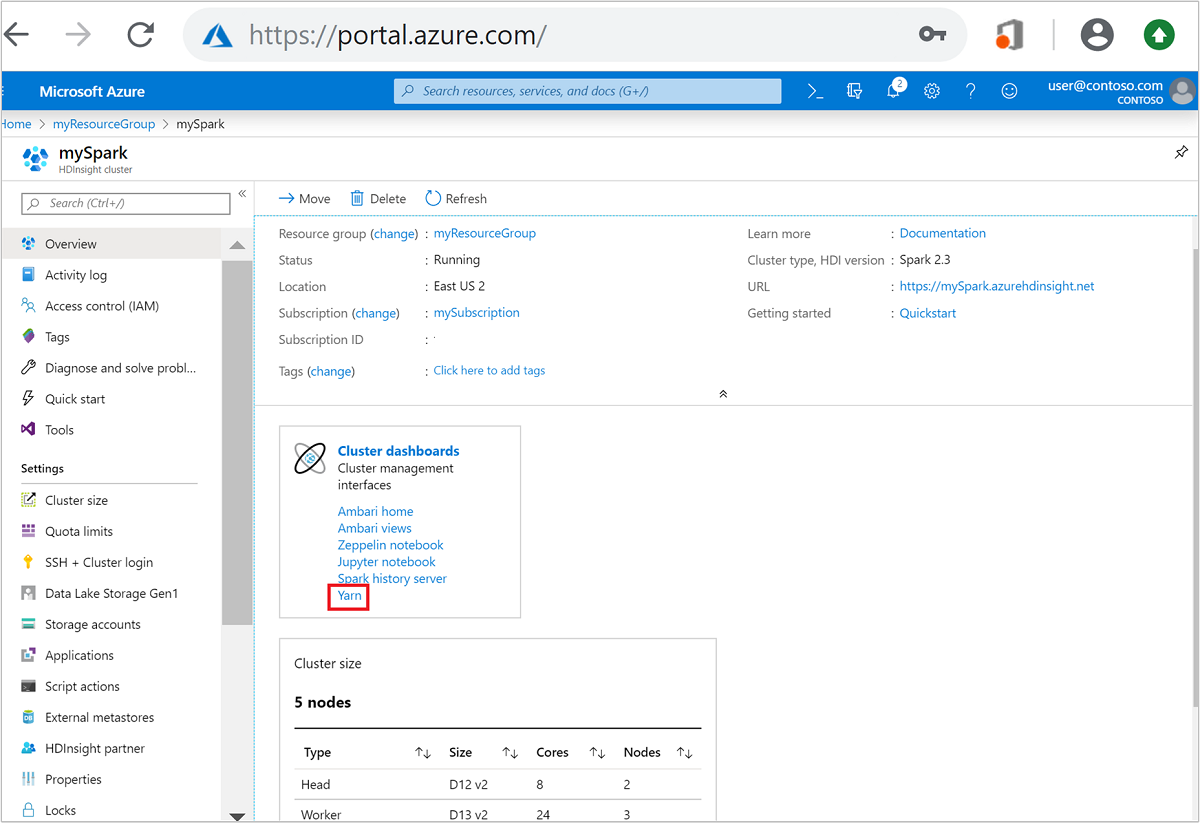
Nel portale di Azure aprire il cluster Spark. Per altre informazioni, vedere Elencare e visualizzare i cluster.
From dashboard del cluster, selezionare Yarn. Quando richiesto, immettere le credenziali di amministratore per il cluster di Spark.
Suggerimento
In alternativa, è anche possibile avviare l'interfaccia utente di YARN dall'interfaccia utente di Ambari. Dall'interfaccia utente di Ambari, passare a YARN>Collegamenti rapidi>Attivo>Interfaccia utente del gestore delle risorse.
Ottimizzare i cluster per le applicazioni Spark
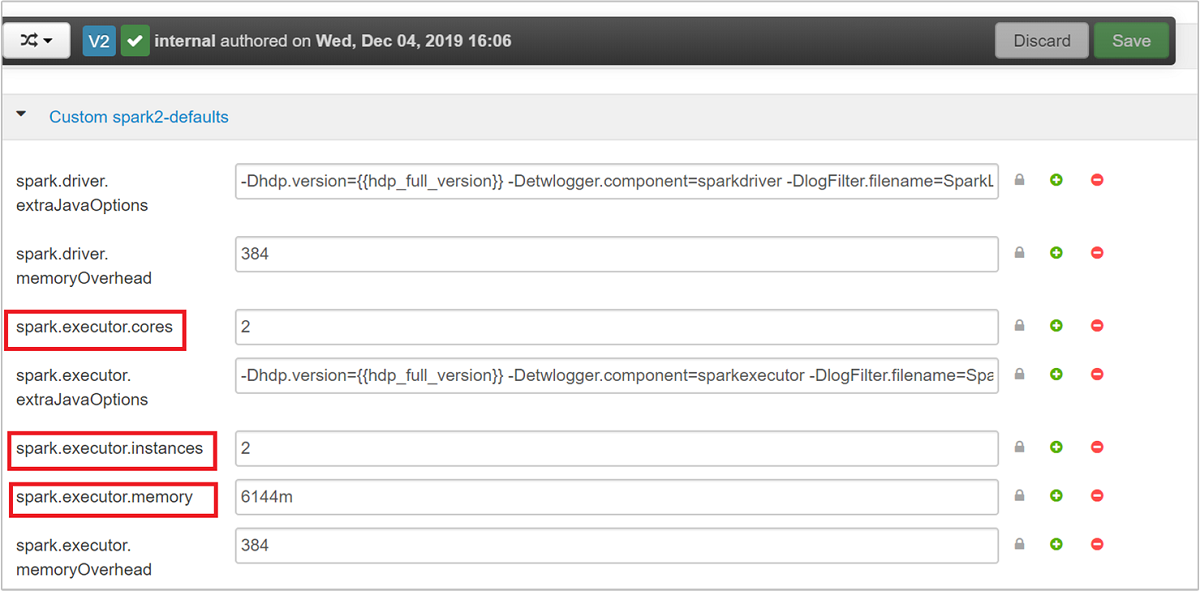
I tre parametri principali che possono essere usati per la configurazione di Spark, a seconda dei requisiti dell'applicazione, sono spark.executor.instances, spark.executor.cores e spark.executor.memory. Un Executor è un processo avviato per un'applicazione Spark. Viene eseguito sul nodo di lavoro e svolge le attività per l'applicazione. Il numero predefinito di executor e le relative dimensioni per ogni cluster vengono calcolati in base al numero di nodi di lavoro e alle relative dimensioni. Questi dati vengono archiviati in spark-defaults.conf nei nodi head del cluster.
I tre parametri di configurazione possono essere configurati a livello di cluster, per tutte le applicazioni in esecuzione nel cluster, o possono anche essere specificati per ogni singola applicazione.
Modificare i parametri con l'interfaccia utente di Ambari
Dall'interfaccia utente di Ambari, passare a Spark 2>Configurazioni>Impostazioni predefinite spark2 personalizzate.
I valori predefiniti sono appropriati per quattro applicazioni Spark in esecuzione contemporaneamente nel cluster. È possibile modificare questi valori nell'interfaccia utente, come illustrato nello screenshot seguente:
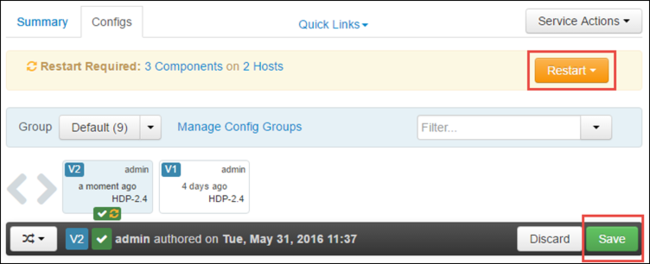
Per salvare la configurazione, selezionare Salva. Nella parte superiore della pagina verrà richiesto di riavviare tutti i servizi interessati. Seleziona Riavvia.
Modificare i parametri per un'applicazione in esecuzione in Jupyter Notebook
Per le applicazioni in esecuzione in Jupyter Notebook è possibile usare il magic %%configure per apportare le modifiche di configurazione. Idealmente, è necessario apportare le modifiche all'inizio dell'applicazione, prima di eseguire la prima cella di codice. Ciò garantisce che la configurazione venga applicata alla sessione Livy quando viene creata. Se si vuole modificare la configurazione in una fase successiva nell'applicazione, è necessario usare il parametro -f . Tuttavia, in questo modo tutte le operazioni eseguite nell'applicazione andranno perse.
Il frammento di codice seguente mostra come modificare la configurazione per un'applicazione in esecuzione in Jupyter.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
I parametri di configurazione devono essere passati come una stringa JSON e devono trovarsi nella riga successiva a magic, come illustrato nella colonna di esempio.
Modificare i parametri per un'applicazione inviata tramite spark-submit
Il comando seguente è un esempio di come modificare i parametri di configurazione per un'applicazione batch inviata tramite spark-submit.
spark-submit --class <the application class to execute> --executor-memory 3072M --executor-cores 4 –-num-executors 10 <location of application jar file> <application parameters>
Modificare i parametri per un'applicazione inviata tramite cURL
Il comando seguente è un esempio di come modificare i parametri di configurazione per un'applicazione batch inviata tramite cURL.
curl -k -v -H 'Content-Type: application/json' -X POST -d '{"file":"<location of application jar file>", "className":"<the application class to execute>", "args":[<application parameters>], "numExecutors":10, "executorMemory":"2G", "executorCores":5' localhost:8998/batches
Nota
Copiare il file JAR nell'account di archiviazione del cluster. Non copiare il file JAR direttamente sul nodo principale.
Modificare questi parametri nel server Spark Thrift
Il server Spark Thrift fornisce l'accesso JDBC/ODBC a un cluster Spark e viene usato per rispondere alle query di Spark SQL. Strumenti come Power BI, Tableau e così via, usano il protocollo ODBC per comunicare con il server Spark Thrift per eseguire query di Spark SQL come un'applicazione Spark. Quando si crea un cluster Spark, vengono avviate due istanze del server Spark Thrift, una in ogni nodo head. Ogni Thrift Spark Server è visibile come un'applicazione Spark nell'interfaccia utente di YARN.
Il server Spark Thrift usa l'allocazione di executor dinamica di Spark e quindi non viene usato spark.executor.instances. Il server Spark Thrift usa invece spark.dynamicAllocation.maxExecutors e spark.dynamicAllocation.minExecutors per specificare il numero di executor. Per modificare le dimensioni degli executor, si usano i parametri di configurazione spark.executor.cores e spark.executor.memory. È possibile modificare questi parametri come illustrato nella procedura seguente:
Espandere la categoria Advanced spark2-thrift-sparkconf per aggiornare i parametri
spark.dynamicAllocation.maxExecutorsespark.dynamicAllocation.minExecutors.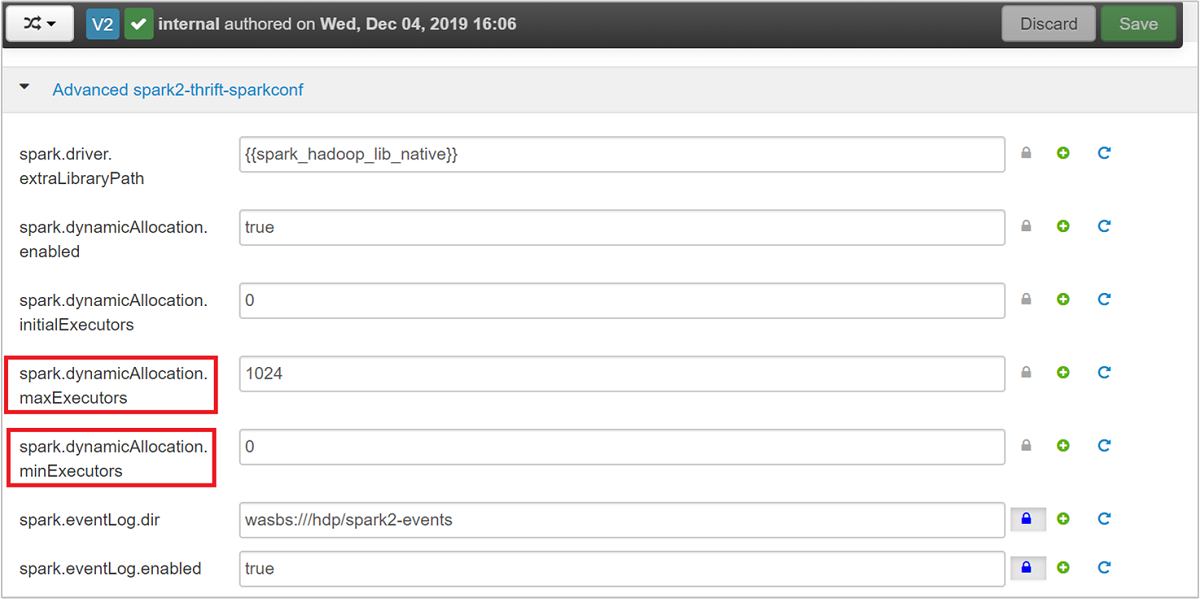
Espandere la categoria Custom spark2-thrift-sparkconf per aggiornare i parametri
spark.executor.coresespark.executor.memory.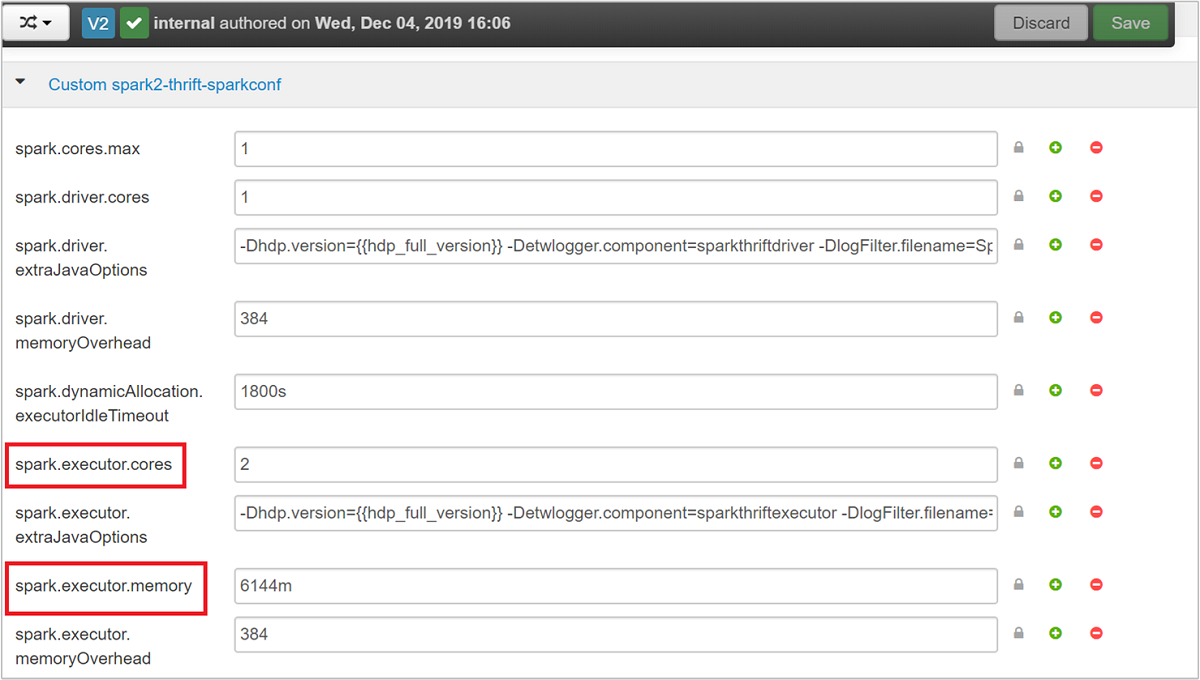
Modificare la memoria del driver del server Spark Thrift
La memoria del driver del server Spark Thrift è configurata al 25% delle dimensioni della RAM nodo head, a condizione che le dimensioni totali della RAM del nodo head siano maggiori di 14 GB. Per modificare la configurazione della memoria del driver, è possibile usare l'interfaccia utente di Ambari, come illustrato nello screenshot seguente:
Dall'interfaccia utente di Ambari, passare a Spark 2>Configurazioni>Spark2-env avanzato. Quindi fornire il valore per spark_thrift_cmd_opts.
Recuperare le risorse cluster di Spark
Grazie all'allocazione dinamica di Spark le uniche risorse usate dal server Thrift sono quelle per i due master applicazioni. Per recuperare tali risorse, è necessario arrestare i servizi del server Thrift in esecuzione nel cluster.
Nel riquadro sinistro dell'interfaccia utente di Ambari, selezionare Spark2.
Nella pagina successiva selezionare Spark 2 Thrift Servers.
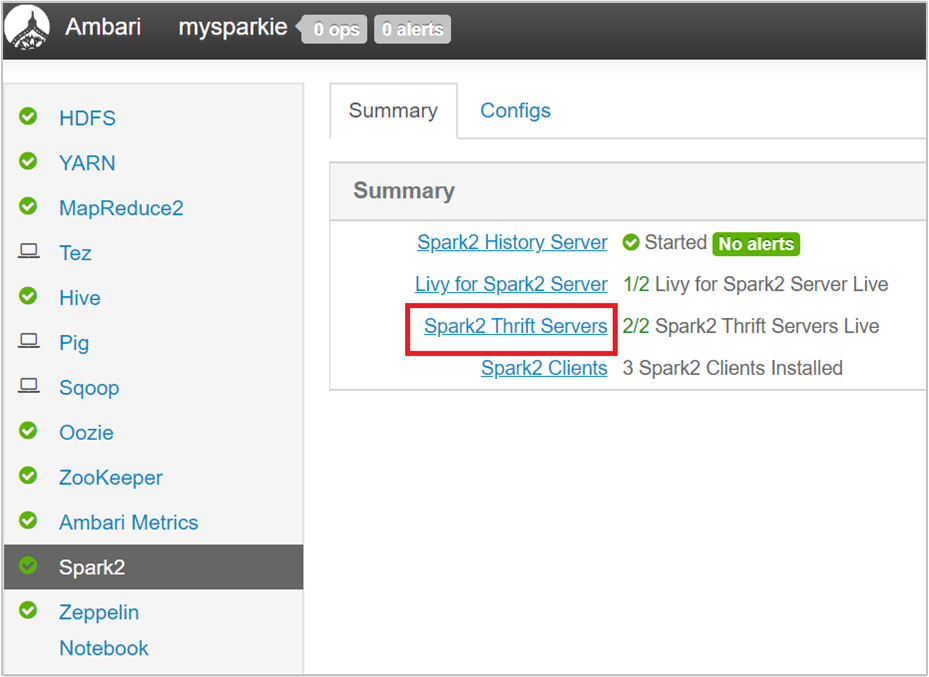
Verranno visualizzati due nodi head in cui è in esecuzione il server Spark 2 Thrift. Selezionare uno dei nodi head.
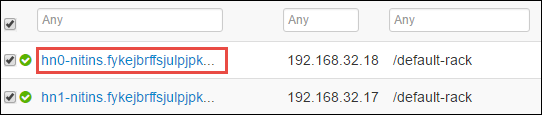
Nella pagina successiva sono elencati tutti i servizi in esecuzione in quel nodo head. Nell'elenco selezionare il pulsante dell'elenco a discesa accanto al server Spark 2 Thrift e quindi selezionare Stop.
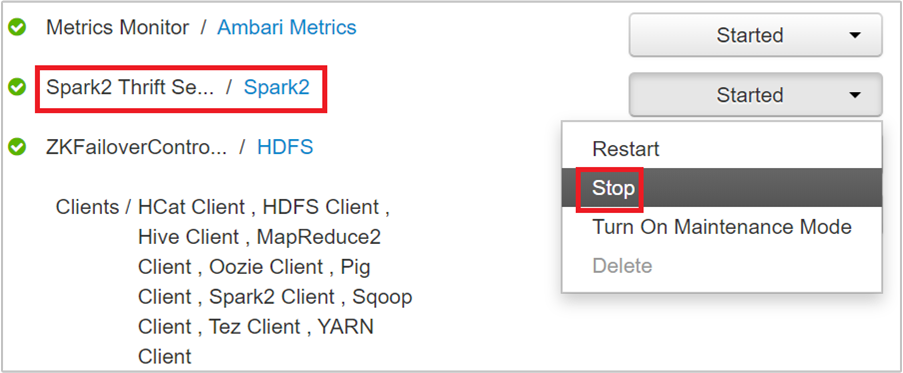
Ripetere questi passaggi anche per l'altro nodo head.
Riavviare il servizio Jupyter
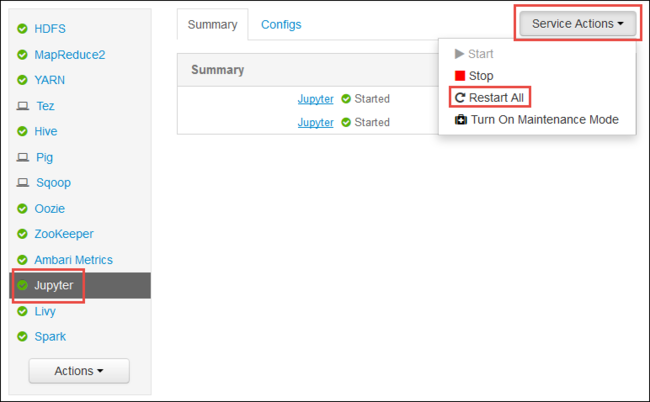
Avviare l'interfaccia utente Web di Ambari, come illustrato all'inizio dell'articolo. Dal riquadro di spostamento sinistro selezionare Jupyter, Azioni servizio e quindi Riavvia tutto. Verrà avviato il servizio Jupyter su tutti i nodi head.
Monitorare le risorse
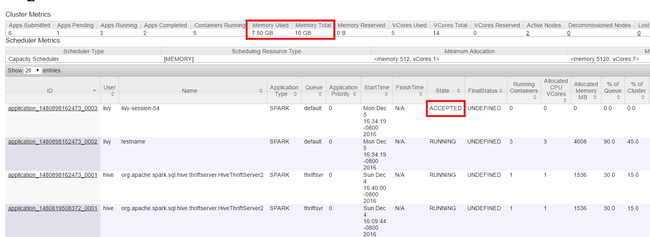
Avviare l'interfaccia utente di Yarn, come illustrato all'inizio dell'articolo. Nella tabella Cluster Metrics (Metriche cluster) nella parte superiore della schermata, verificare i valori delle colonne Memory Used (Memoria in uso) e Memory Total (Memoria totale). Se i due valori sono simili, potrebbero non esserci risorse sufficienti per avviare l'applicazione successiva. Lo stesso vale per le colonne VCores Used (VCore in uso) e VCores Total (VCore totali). Se nella visualizzazione principale è presente un'applicazione con stato ACCETTATO che non passa allo stato IN ESECUZIONE o NON RIUSCITO, ciò può anche indicare che l'applicazione non ha risorse sufficienti per l'avvio.
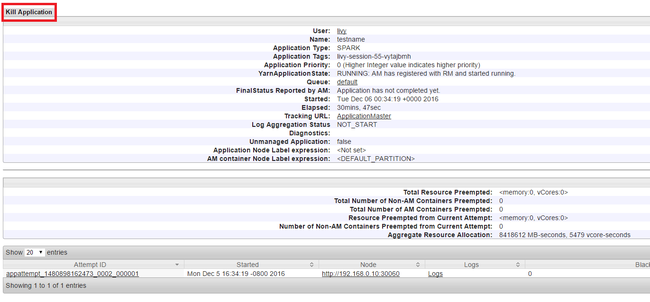
Terminare le applicazioni in esecuzione
Nell'interfaccia utente di Yarn, nel pannello a sinistra, selezionare In esecuzione. Dall'elenco delle applicazioni in esecuzione, determinare l'applicazione da terminare e selezionare l'ID.
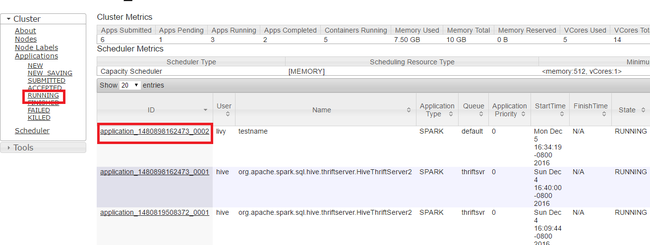
Selezionare Termina applicazione nella parte superiore destra, quindi selezionare OK.
Vedi anche
Per gli analisti dei dati
- Apache Spark con Machine Learning: utilizzare Spark in HDInsight per l'analisi della temperatura di compilazione utilizzando dati HVAC
- Apache Spark con Machine Learning: utilizzare Spark in HDInsight per prevedere i risultati di un controllo alimentare
- Analisi dei log del sito Web con Apache Spark in HDInsight
- Analisi dei dati di telemetria di Application Insights con Apache Spark in HDInsight
Per gli sviluppatori di Apache Spark
- Creare un'applicazione autonoma con Scala
- Eseguire processi in modalità remota in un cluster Apache Spark usando Apache Livy
- Usare il plug-in degli strumenti HDInsight per IntelliJ IDEA per creare e inviare applicazioni Spark in Scala
- Usare il plug-in Strumenti HDInsight per IntelliJ IDEA per eseguire il debug di applicazioni Apache Spark in remoto
- Usare i notebook di Apache Zeppelin con un cluster Apache Spark in HDInsight
- Kernel disponibili per Jupyter Notebook nel cluster Apache Spark per HDInsight
- Usare pacchetti esterni con Jupyter Notebook
- Installare Jupyter Notebook nel computer e connetterlo a un cluster HDInsight Spark