Panoramica di Apache Spark Structured Streaming
Apache Spark Structured Streaming permette di implementare applicazioni scalabili, a velocità effettiva elevata e a tolleranza di errore per l'elaborazione di flussi di dati. Structured Streaming è basato sul motore di Spark SQL ed è reso migliore attraverso i frame di dati e i set di dati di Spark SQL per permettere la scrittura di query di streaming allo stesso modo delle query in batch.
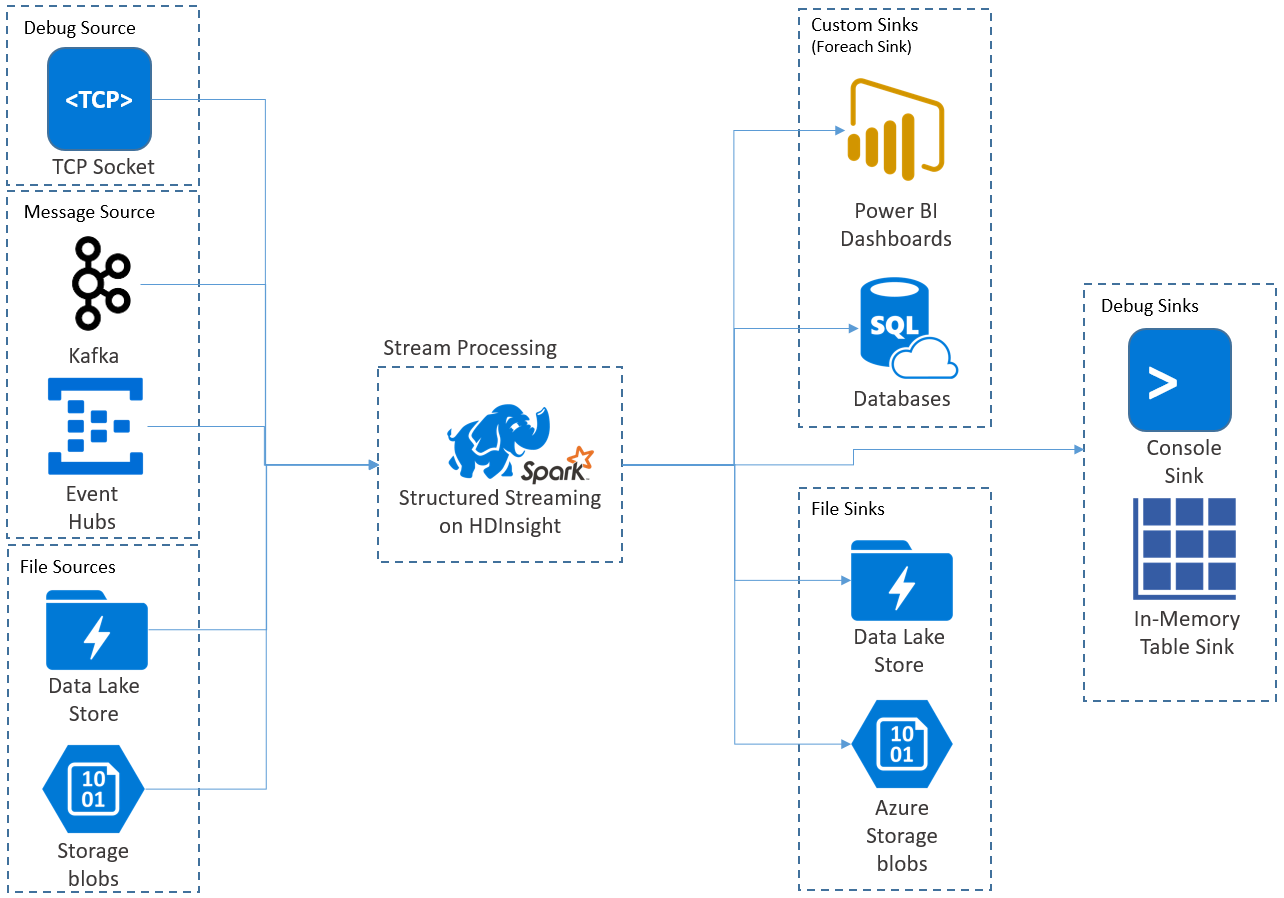
Le applicazioni Structured Streaming vengono eseguite in cluster HDInsight Spark e si connettono ai dati di streaming da Apache Kafka, un token TCP (per scopi di debug), Archiviazione di Azure o Azure Data Lake Storage. Le ultime due opzioni, basate su servizi di archiviazione esterna, permettono di individuare nuovi file aggiunti all'archiviazione e di elaborarne il contenuto analogamente a un'operazione di streaming.
Structured Streaming crea una query a esecuzione prolungata durante la quale è possibile applicare operazioni ai dati di input, tra cui la selezione, la proiezione, l'aggregazione, il windowing e l'aggiunta di DataFrame di riferimento al DataFrame di streaming. È quindi possibile restituire i risultati nell'archiviazione file (BLOB del servizio di archiviazione di Azure o Data Lake Storage) o in qualsiasi archivio dati usando codice personalizzato (come il database SQL o Power BI). Structured Streaming fornisce inoltre l'output alla console per il debug in locale e a una tabella in memoria per poter visualizzare i dati generati per il debug in HDInsight.
Nota
Spark Structured Streaming sostituisce Spark Streaming (flussi DStream). In futuro Structured Streaming riceverà miglioramenti e manutenzione, mentre i flussi DStream resteranno solo in modalità manutenzione. Structured Streaming attualmente non include funzionalità complete come i flussi DStream per origini e sink, supportate per impostazione predefinita, e di conseguenza è necessario valutare i propri requisiti per scegliere l'opzione di elaborazione di flussi Spark più appropriata.
Spark Structured Streaming rappresenta un flusso di dati come tabella senza limiti di profondità, ovvero la tabella continua ad aumentare con l'arrivo di nuovi dati. Questa tabella di input viene continuamente elaborata da una query a esecuzione prolungata e i risultati vengono inviati a una tabella di output:

In Structured Streaming i dati arrivano nel sistema e vengono immediatamente inseriti in una tabella di input. Si scriveranno query (usando le API DataFrame e Dataset) che eseguono operazioni su questa tabella di input. L'output della query produce un'altra tabella, denominata tabella dei risultati. La tabella dei risultati contiene i risultati della query, da cui è possibile ricavare i dati per un archivio dati esterno, come un database relazionale. Il periodo in cui i dati vengono elaborati dalla tabella di input viene controllato dall'intervallo di trigger. Per impostazione predefinita, l'intervallo di trigger è zero e di conseguenza Structured Streaming tenta di elaborare i dati non appena arrivano. In pratica, questo significa che non appena Structured Streaming ha completato l'elaborazione dell'esecuzione della query precedente, avvia un'altra elaborazione, eseguita su eventuali nuovi dati ricevuti. È possibile configurare il trigger per l'esecuzione in base a un intervallo specifico, in modo che i dati di streaming vengano elaborati in batch basati sul tempo.
I dati nella tabella dei risultati possono essere solo i nuovi dati dall'ultima elaborazione della query (modalità Append) oppure la tabella può essere aggiornata ogni volta che sono presenti nuovi dati, in modo da includere tutti i dati di output dall'inizio della query di streaming (modalità completa).
In modalità Append la tabella dei risultati contiene solo le righe aggiunte alla tabella dall'ultima esecuzione della query e tali righe vengono scritte nell'archiviazione esterna. Ad esempio, la query più semplice copia solo tutti i dati, inalterati, dalla tabella di input alla tabella dei risultati. Allo scadere di ogni intervallo di trigger, i nuovi dati vengono elaborati e le righe che rappresentano i nuovi dati vengono visualizzate nella tabella dei risultati.
Si consideri uno scenario in cui si elaborano dati di telemetria da sensori di temperatura, ad esempio un termostato. Si supponga che il primo trigger ha elaborato un evento alle 00.01 per il dispositivo 1 con un valore di temperatura di 95 gradi. Al primo trigger della query, nella tabella dei risultati viene visualizzata solo la riga con l'ora 00.01. All'ora 00.02, quando si verifica un altro evento, l'unica riga visualizzata è la riga con l'ora 00.02 e pertanto la tabella dei risultati conterrà solo tale riga.
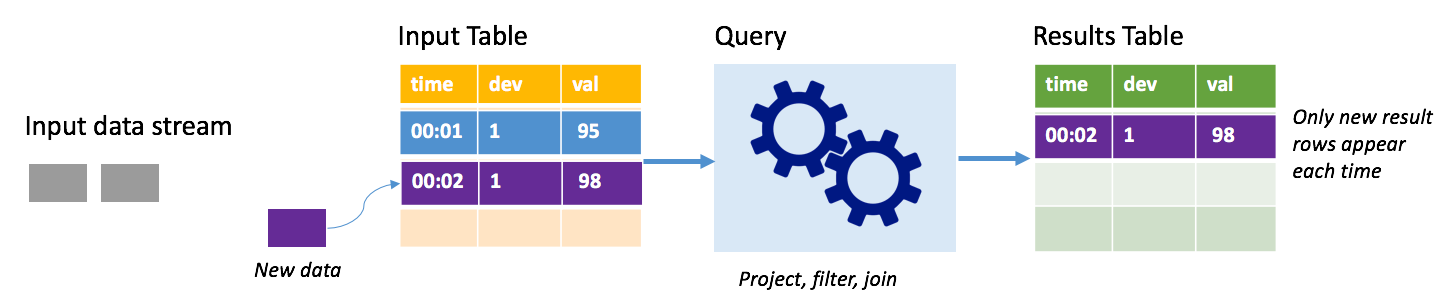
Quando si usa la modalità Append, la query applica proiezioni (selezionando le colonne rilevanti), filtra (selezionando solo le righe che corrispondono a determinate condizioni) o aggiunge (aumentando i dati con dati provenienti da un tabella di ricerca statica). La modalità Append semplifica il push nelle risorse di archiviazione esterne limitandolo ai soli nuovi punti dati rilevanti.
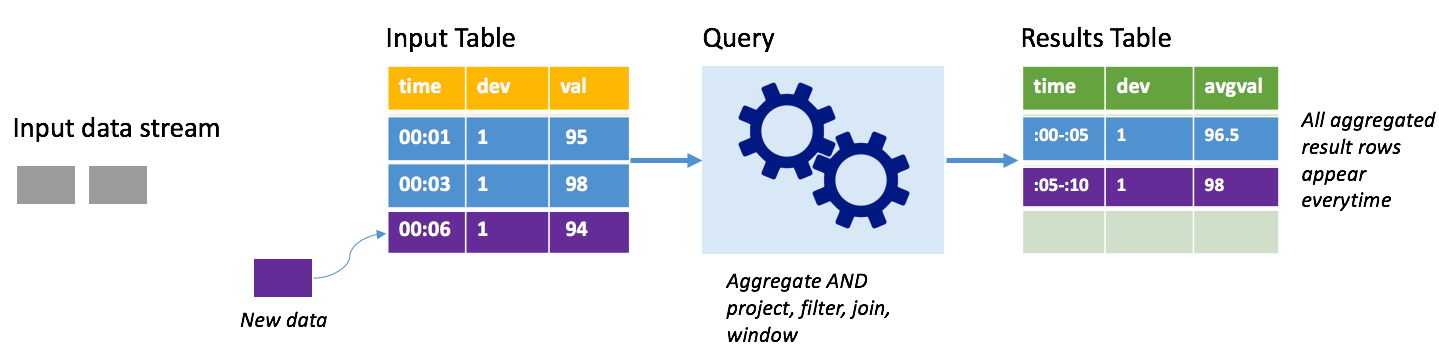
Si consideri lo stesso scenario nella modalità completa. In modalità completa l'intera tabella di output viene aggiornata a ogni trigger in modo da includere non solo i dati dall'esecuzione del trigger più recente, ma da tutte le esecuzioni. È possibile usare la modalità completa per copiare i dati inalterati dalla tabella di input alla tabella dei risultati. A ogni esecuzione attivata, le righe dei nuovi risultati vengono visualizzate insieme a tutte le righe precedenti. La tabella dei risultati di output finirà per archiviare tutti i dati raccolti dall'inizio della query e a un certo punto la memoria si esaurirà. La modalità completa è pensata per l'uso con query di aggregazione che restituiscono un riepilogo dei dati in ingresso. In questo modo, a ogni trigger, la tabella dei risultati viene aggiornata con un nuovo riepilogo.
Si supponga che finora siano stati elaborati i dati relativi a cinque secondi e che sia il momento di elaborare quelli relativi al sesto secondo. La tabella di input include eventi per l'ora 00.01 e l'ora 00.03. L'obiettivo di questa query di esempio è fornire la temperatura media del dispositivo ogni cinque secondi. L'implementazione di questa query applica un'aggregazione che, partendo da tutti i valori compresi in ogni finestra di cinque secondi, calcola la media della temperatura e produce una riga per la temperatura media nell'intervallo specifico. Alla fine della prima finestra di cinque secondi, sono presenti due tuple: (00.01, 1, 95) e (00.03, 1, 98). Di conseguenza, per la finestra 00.00-00.05 l'aggregazione produce una tupla con la temperatura media di 96,5 gradi. Nella successiva finestra di cinque secondi è presente un solo punto dati all'ora 00:06 e di conseguenza la temperatura media risultante è 98 gradi. Alle ore 00.10, se si usa la modalità completa, la tabella dei risultati include le righe per entrambe le finestre, 00.00-00.05 e 00.05-00.10, perché la query restituisce tutte le righe aggregate e non solo quelle nuove. Di conseguenza, la tabella dei risultati continua ad aumentare con l'aggiunta di nuove finestre.
Non tutte le query che usano la modalità completa provocano un aumento illimitato della tabella. Nell'esempio precedente si supponga che invece di calcolare la media della temperatura in base alla finestra di tempo, questa venga calcolata in base all'ID dispositivo. La tabella dei risultati contiene un numero fisso di righe (una per dispositivo), con la temperatura media per il dispositivo tra tutti i punti dati ricevuti dal dispositivo stesso. Man mano che vengono ricevute nuove temperature, la tabella dei risultati viene aggiornata in modo che le medie che contiene siano sempre aggiornate.
Una semplice query di esempio può restituire il riepilogo dei valori di temperatura in base a finestre della durata di un'ora. In questo caso, i dati vengono archiviati in file JSON in Archiviazione di Azure (servizio collegato come archiviazione predefinita per il cluster HDInsight):
{"time":1469501107,"temp":"95"}
{"time":1469501147,"temp":"95"}
{"time":1469501202,"temp":"95"}
{"time":1469501219,"temp":"95"}
{"time":1469501225,"temp":"95"}
Questi file JSON vengono archiviati nella sottocartella temps all'interno del contenitore del cluster HDInsight.
Configurare innanzitutto un frame di dati per descrivere l'origine dei dati e tutte le impostazioni richieste dall'origine. Questo esempio parte dai file JSON in Archiviazione di Azure e applica ai file uno schema in fase di lettura.
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
//Cluster-local path to the folder containing the JSON files
val inputPath = "/temps/"
//Define the schema of the JSON files as having the "time" of type TimeStamp and the "temp" field of type String
val jsonSchema = new StructType().add("time", TimestampType).add("temp", StringType)
//Create a Streaming DataFrame by calling readStream and configuring it with the schema and path
val streamingInputDF = spark.readStream.schema(jsonSchema).json(inputPath)
Applicare quindi una query che contiene le operazioni desiderate sul frame di dati di streaming. In questo caso, un'aggregazione raggruppa tutte le righe nelle finestre di un'ora e quindi calcola le temperature minima, media e massima nella finestra di un'ora.
val streamingAggDF = streamingInputDF.groupBy(window($"time", "1 hour")).agg(min($"temp"), avg($"temp"), max($"temp"))
Definire quindi la destinazione per le righe aggiunte alla tabella dei risultati all'interno di ogni intervallo di trigger. Questo esempio restituisce semplicemente tutte le righe in una tabella in memoria temps, su cui sarà successivamente possibile eseguire query con Spark SQL. La modalità di output completa garantisce che vengano restituite ogni volta tutte le righe per tutte le finestre.
val streamingOutDF = streamingAggDF.writeStream.format("memory").queryName("temps").outputMode("complete")
Avviare la query di streaming ed eseguirla finché non si riceve un segnale di arresto.
val query = streamingOutDF.start()
Durante l'esecuzione della query, nella stessa sessione di Spark è possibile eseguire una query Spark SQL sulla tabella temps in cui sono archiviati i risultati della query.
select * from temps
Questa query produce risultati simili ai seguenti:
| window | Min. (temp.) | Media (temp.) | Max (temp.) |
|---|---|---|---|
| {u'start': u'2016-07-26T02:00:00.000Z', u'end'... | 95 | 95,231579 | 99 |
| {u'start': u'2016-07-26T03:00:00.000Z', u'end'... | 95 | 96,023048 | 99 |
| {u'start': u'2016-07-26T04:00:00.000Z', u'end'... | 95 | 96,797133 | 99 |
| {u'start': u'2016-07-26T05:00:00.000Z', u'end'... | 95 | 96,984639 | 99 |
| {u'start': u'2016-07-26T06:00:00.000Z', u'end'... | 95 | 97,014749 | 99 |
| {u'start': u'2016-07-26T07:00:00.000Z', u'end'... | 95 | 96,980971 | 99 |
| {u'start': u'2016-07-26T08:00:00.000Z', u'end'... | 95 | 96,965997 | 99 |
Per informazioni dettagliate sull'API di Spark Structured Streaming, nonché su origini dei dati di input, operazioni e sink di output supportati, vedere Apache Spark Streaming Programming Guide (Guida ad Apache Spark Streaming per programmatori).
Per offrire resilienza e tolleranza di errore, Structured Streaming usa checkpoint per garantire che l'elaborazione di flussi possa continuare senza interruzioni, anche in caso di errori dei nodi. In HDInsight Spark crea checkpoint in una risorsa di archiviazione durevole, ovvero in Archiviazione di Azure o Data Lake Storage. Questi checkpoint archiviano le informazioni sullo stato della query di streaming. Inoltre, Structured Streaming usa un log write-ahead. Il log write-ahead acquisisce i dati inseriti che sono stati ricevuti ma non ancora elaborati da una query. Se si verifica un errore e l'elaborazione viene riavviata dal log write-ahead, tutti gli eventi ricevuti dall'origine non vanno persi.
In genere, un'applicazione Spark Streaming viene compilata in locale in un file JAR e quindi viene distribuita in Spark su HDInsight copiando il file JAR nella risorsa di archiviazione predefinita collegata al cluster HDInsight. È possibile avviare l'applicazione tramite le API REST Apache Livy disponibili dal cluster usando un'operazione POST. Il corpo dell'operazione POST include un documento JSON che fornisce il percorso del file JAR, il nome della classe il cui metodo principale definisce ed esegue l'applicazione di streaming e, facoltativamente, i requisiti relativi alle risorse del processo, ad esempio il numero di executor, la memoria e i core, e tutte le impostazioni di configurazione necessarie per il codice dell'applicazione.
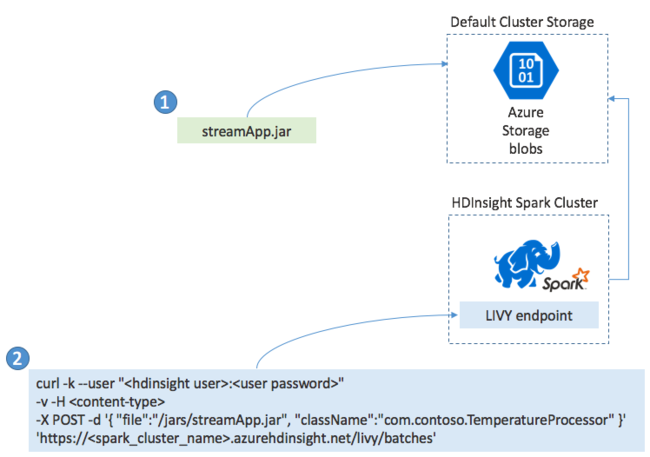
Lo stato di tutte le applicazioni può anche essere verificato con una richiesta GET su un endpoint LIVY. Infine, è possibile terminare un'applicazione in esecuzione eseguendo una richiesta DELETE sull'endpoint LIVY. Per informazioni dettagliate sull'API LIVY, vedere Processi remoti con Apache LIVY
- Creare un cluster Apache Spark in HDInsight
- Apache Spark Streaming Programming Guide (Guida ad Apache Spark Streaming per programmatori)
- Avviare processi Apache Spark in remoto con Apache LIVY