Valutare il componente del modello
Questo articolo descrive un componente nella finestra di progettazione di Azure Machine Learning.
Usare questo componente per misurare l'accuratezza di un modello sottoposto a training. Si fornisce un set di dati contenente i punteggi generati da un modello e il componente Evaluate Model calcola un set di metriche di valutazione standard del settore.
Le metriche restituite da Evaluate Model dipendono dal tipo di modello da valutare:
- Modelli di classificazione
- Modelli di regressione
- Modelli di clustering
Suggerimento
Se non si ha familiarità con la valutazione del modello, è consigliabile usare la serie video di Stephen Elston, come parte del corso di Machine Learning di EdX.
Come usare Evaluate Model
Connettere l'output Scored dataset del modulo Score Model o l'output Result dataset del modulo Assign Data to Clusters alla porta di input sinistra di Evaluate Model.
Nota
Se si usano componenti come "Seleziona colonne nel set di dati" per selezionare parte del set di dati di input, assicurarsi che la colonna Etichetta effettiva (usata nel training), la colonna "Scored Probabilities" e la colonna "Scored Labels" esistano per calcolare metriche come AUC, Accuratezza per il rilevamento di anomalie/classificazione binaria. La colonna Actual label e la colonna 'Scored Labels' consentono di calcolare le metriche per la classificazione/regressione multiclasse. La colonna 'Assignments' e le colonne 'DistancesToClusterCenter no.X' (X è l'indice del centroide, che varia da 0 a numero di centroidi-1) consentono di calcolare le metriche per il clustering.
Importante
- Per valutare i risultati, il set di dati di output deve contenere nomi di colonna di punteggio specifici, che soddisfano i requisiti del componente Evaluate Model.
- La
Labelscolonna verrà considerata come etichette effettive. - Per l'attività di regressione, il set di dati da valutare deve avere una colonna denominata , che
Regression Scored Labelsrappresenta le etichette con punteggio. - Per l'attività di classificazione binaria, il set di dati da valutare deve avere due colonne, denominate
Binary Class Scored Labels,Binary Class Scored Probabilitiesche rappresentano rispettivamente etichette con punteggio e probabilità. - Per l'attività di classificazione multipla, il set di dati da valutare deve avere una colonna, denominata
Multi Class Scored Labels, che rappresenta le etichette con punteggio. Se gli output del componente upstream non dispongono di queste colonne, è necessario modificare in base ai requisiti precedenti.
[Facoltativo] Connettere l'output Scored dataset del modulo Score Model o l'output Result dataset del modulo Assign Data to Clusters per il secondo modello alla porta di input destra di Evaluate Model. È possibile confrontare facilmente i risultati di due modelli diversi sugli stessi dati. I due algoritmi di input devono essere dello stesso tipo. In alternativa, è possibile confrontare i punteggi di due esecuzioni diverse sugli stessi dati con parametri diversi.
Nota
Il tipo di algoritmo fa riferimento a 'classificazione a due classi', 'classificazione multiclasse', 'regressione', 'clustering' negli algoritmi di Machine Learning.
Inviare la pipeline per generare i punteggi di valutazione.
Risultati
Dopo aver eseguito Evaluate Model (Valuta modello), selezionare il componente per aprire il pannello di spostamento Evaluate Model (Valuta modello ) a destra. Quindi, scegliere la scheda Outputs + logs, in cui la sezione Data Outputs contiene diverse icone. L'icona Visualize presenta un'icona a forma di grafico a barre, che rappresenta il primo modo per vedere i risultati.
Per la classificazione binaria, dopo aver fatto clic sull'icona Visualizza , è possibile visualizzare la matrice di confusione binaria. Per la multi-classificazione, è possibile trovare il file del tracciato della matrice di confusione nella scheda Output e log , come indicato di seguito:
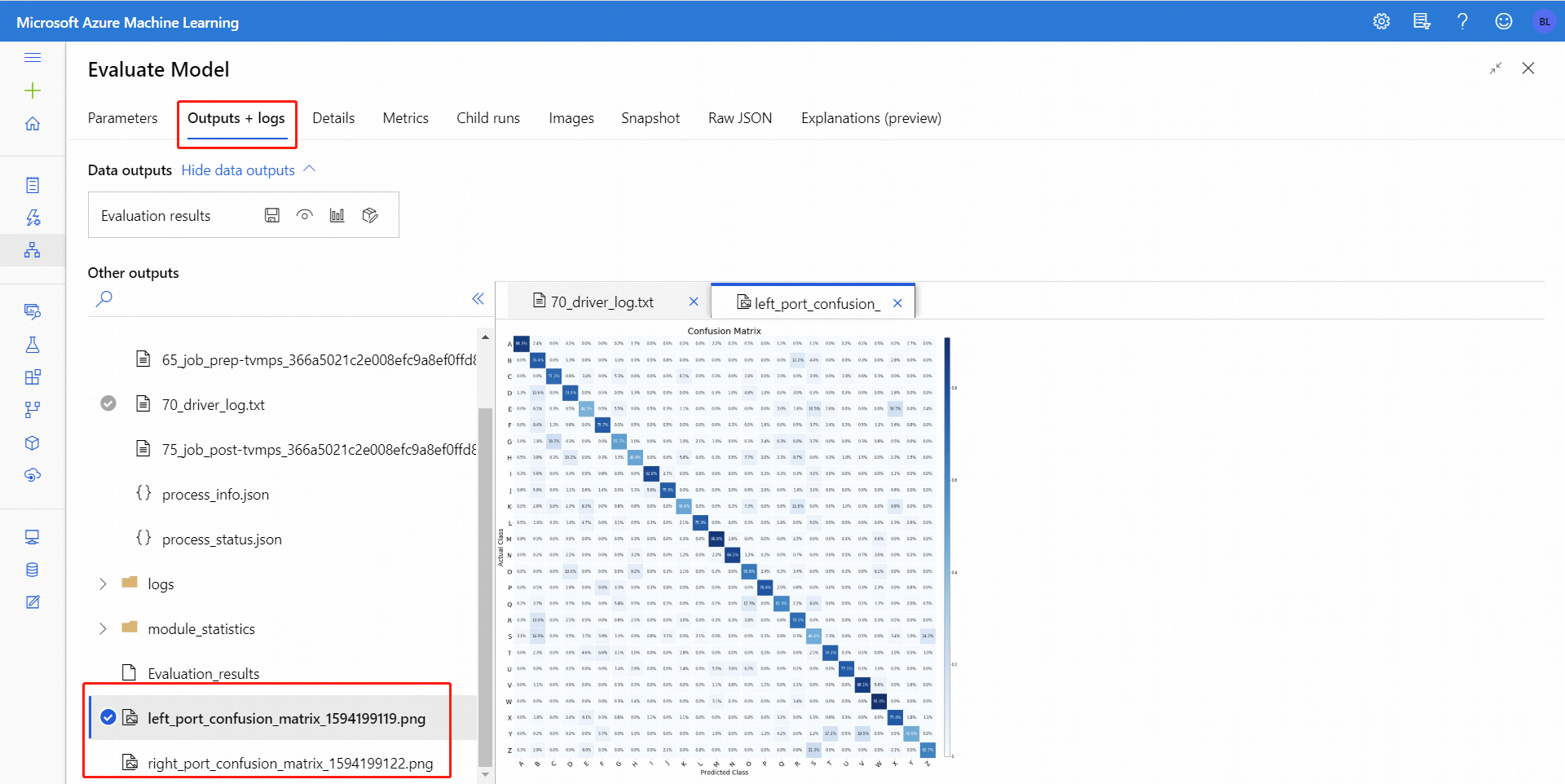
Se si connettono i set di dati a entrambi gli input di Evaluate Model, i risultati conterranno le metriche per entrambi i set di dati o per entrambi i modelli. Il modello o i dati collegati alla porta sinistra vengono presentati prima nel report, poi nelle metriche per il set di dati o il modello collegato alla porta destra.
Ad esempio, l'immagine seguente rappresenta un confronto dei risultati di due modelli di clustering basati sugli stessi dati, ma con parametri diversi.

Poiché si tratta di un modello di clustering, i risultati della valutazione sono diversi rispetto ai punteggi di due modelli di regressione oppure a quelli di due modelli di classificazione. Tuttavia, la presentazione complessiva è la stessa.
Metrica
Questa sezione descrive le metriche restituite per i tipi specifici di modelli supportati per l'uso con Evaluate Model:
Metriche per i modelli di classificazione
Le metriche seguenti vengono segnalate durante la valutazione dei modelli di classificazione binaria.
Accuratezza: misura la validità di un modello di classificazione come percentuale dei risultati effettivi rispetto al numero totale di casi.
Precisione: rappresenta la percentuale di risultati effettivi rispetto a tutti i risultati positivi. Precisione = TP/(TP+FP)
Il richiamo è la frazione della quantità totale di istanze rilevanti effettivamente recuperate. Richiamo = TP/(TP+FN)
Il punteggio F1 viene calcolato come media ponderata della precisione e richiamo tra 0 e 1, dove il valore del punteggio F1 ideale è 1.
Area sotto la curva: misura l'area sotto la curva tracciata con i veri positivi sull'asse Y e i falsi positivi sull'asse X. Questa metrica è utile perché fornisce un singolo numero che consente di confrontare modelli di tipi diversi. L'area di controllo dell'accesso alla rete è invariante per la classificazione.threshold-threshold-invariant. Misura la qualità delle stime del modello indipendentemente dalla soglia di classificazione scelta.
Metriche per i modelli di regressione
Le metriche restituite per i modelli di regressione sono progettate per stimare la quantità di errori. Un modello viene considerato adatto ai dati se la differenza tra i valori osservati e quelli previsti è minima. Tuttavia, l'analisi del modello dei residui (la differenza tra un punto previsto qualunque e il valore effettivo corrispondente) può fornire molte indicazioni sulla potenziale distorsione del modello.
Per la valutazione dei modelli di regressione lineare vengono segnalate le metriche seguenti. Altri modelli di regressione, ad esempio Fast Forest Quantile Regression , possono avere metriche diverse.
Errore assoluto medio (MAE): misura la distanza tra le previsioni e i risultati effettivi; pertanto un punteggio più basso è migliore.
Radice dell'errore quadratico medio (RMSE): crea un singolo valore che riepiloga l'errore nel modello. Grazie alla quadratura della differenza, la metrica ignora la differenza tra previsioni per eccesso e per difetto.
Errore assoluto relativo (RAE): è la differenza assoluta relativa tra i valori previsti e quelli effettivi; è relativo perché la differenza media viene divisa per la media aritmetica.
Errore quadratico relativo (RSE): analogamente normalizza l'errore quadratico totale dei valori previsti dividendolo per l'errore quadratico totale dei valori effettivi.
Coefficiente di determinazione: spesso definito R2, rappresenta la potenza predittiva del modello come valore compreso tra 0 e 1. Zero indica che il modello è casuale (non spiega niente); 1 indica una soluzione perfetta. Tuttavia, è consigliabile interpretare con cautela i valori di R2, in quanto i valori bassi possono essere perfettamente normali e i valori alti possono essere sospetti.
Metriche per i modelli di clustering
Poiché i modelli di clustering sono significativamente diversi dai modelli di classificazione e di regressione per molti aspetti, Evaluate Model restituisce anche un set di statistiche diverso per i modelli di clustering.
Le statistiche restituite per un modello di clustering descrivono il numero di punti dati assegnati a ogni cluster, il grado di separazione tra i cluster e il livello di aggregazione dei punti dati all'interno di ogni cluster.
Le statistiche per il modello di clustering vengono calcolate come media dell'intero set di dati, con righe aggiuntive contenenti le statiche per ogni cluster.
Per la valutazione dei modelli di clustering, vengono segnalate le metriche seguenti.
I punteggi della colonna Average Distance to Other Center rappresentano la distanza, in media, di ogni punto del cluster dai centroidi di tutti gli altri cluster.
I punteggi della colonna Average Distance to Cluster Center rappresentano la distanza di tutti i punti di un cluster dal centroide di tale cluster.
La colonna Number of Points indica il numero di punti dati assegnati a ogni cluster, oltre al numero complessivo totale di punti dati inclusi in qualsiasi cluster.
Se il numero di punti dati assegnati ai cluster è minore del numero totale di punti dati disponibili, significa che a un cluster non è stato possibile assegnare punti dati.
I punteggi nella colonna Maximal Distance to Cluster Center rappresentano il numero massimo di distanze tra ogni punto e il centroide del cluster di quel punto.
Se questo numero è elevato, può indicare che il cluster è ampiamente distribuito. Per determinare la distribuzione del cluster, è necessario esaminare questa statistica insieme al punteggio Average Distance to Cluster Center.
Il punteggio di valutazione combinata nella parte inferiore di ogni sezione dei risultati elenca i punteggi medi per i cluster creati in quel particolare modello.
Passaggi successivi
Vedere il set di componenti disponibili per Azure Machine Learning.