Eseguire il training del modello PyTorch
Questo articolo descrive come usare il componente Train PyTorch Model nella finestra di progettazione di Azure Machine Learning per eseguire il training di modelli PyTorch come DenseNet. Il training viene eseguito dopo aver definito un modello e impostato i relativi parametri e richiede dati etichettati.
Attualmente, il componente Train PyTorch Model supporta sia il training a nodo singolo che il training distribuito.
Come usare il training del modello PyTorch
Aggiungere il componente DenseNet o ResNet alla bozza di pipeline nella finestra di progettazione.
Aggiungere il componente Train PyTorch Model alla pipeline. È possibile trovare questo componente nella categoria Training modello . Espandere Train (Esegui training) e quindi trascinare il componente Train PyTorch Model (Esegui training modello PyTorch) nella pipeline.
Nota
Il training del componente del modello PyTorch è un'esecuzione migliore nel calcolo dei tipi di GPU per set di dati di grandi dimensioni. In caso contrario, la pipeline avrà esito negativo. È possibile selezionare calcolo per un componente specifico nel riquadro destro del componente impostando Usa altra destinazione di calcolo.
Nell'input sinistro collegare un modello non sottoposto a training. Collegare il set di dati di training e il set di dati di convalida all'input centrale e destro del modello Train PyTorch.
Per il modello non sottoposto a training, deve essere un modello PyTorch come DenseNet; in caso contrario, verrà generata un'eccezione 'InvalidModelDirectoryError'.
Per il set di dati, il set di dati di training deve essere una directory di immagini etichettata. Per informazioni su come ottenere una directory di immagini con etichetta, vedere Converti in directory di immagini. Se non viene etichettata, verrà generata un'eccezione 'NotLabeledDatasetError'.
Il set di dati di training e il set di dati di convalida hanno le stesse categorie di etichette. In caso contrario, verrà generata un'eccezione InvalidDatasetError.
Per Epochs specificare il numero di periodi di cui si vuole eseguire il training. L'intero set di dati verrà iterato in ogni periodo, per impostazione predefinita 5.
Per dimensioni batch, specificare il numero di istanze di cui eseguire il training in un batch, per impostazione predefinita 16.
Per Numero di passaggio warmup, specificare il numero di periodi che si desidera riscaldare il training, nel caso in cui la velocità di apprendimento iniziale sia leggermente troppo grande per iniziare a convergere, per impostazione predefinita 0.
Per Frequenza di apprendimento specificare un valore per la frequenza di apprendimento e il valore predefinito è 0,001. La frequenza di apprendimento controlla le dimensioni del passaggio usato in Optimizer come sgd ogni volta che il modello viene testato e corretto.
Impostando la velocità più piccola, si testa il modello più spesso, con il rischio che si possa rimanere bloccati in un plateau locale. Impostando la velocità maggiore, è possibile convergere più velocemente, con il rischio di superare il vero minimo.
Nota
Se la perdita di training diventa nan durante l'addestramento, che può essere causata da un tasso di apprendimento troppo elevato, la diminuzione del tasso di apprendimento può aiutare. Nel training distribuito, per mantenere stabile la discesa del gradiente, la velocità di apprendimento effettiva viene calcolata in
lr * torch.distributed.get_world_size()quanto le dimensioni batch del gruppo di processi sono le dimensioni del mondo rispetto a quella del singolo processo. Il decadimento della frequenza di apprendimento polinomiale viene applicato e può contribuire a ottenere un modello con prestazioni migliori.Per Valore di inizializzazione casuale, digitare facoltativamente un valore intero da usare come valore di inizializzazione. Se si vuole garantire la riproducibilità dell'esperimento tra processi, è consigliabile usare un valore di inizializzazione.
Per Pazienza, specificare il numero di periodi per interrompere il training in anticipo se la perdita di convalida non diminuisce consecutivamente. per impostazione predefinita 3.
Per Frequenza di stampa specificare la frequenza di stampa del log di training sulle iterazioni in ogni periodo, per impostazione predefinita 10.
Inviare la pipeline. Se il set di dati ha dimensioni maggiori, è consigliabile dedicare un po' di tempo e le risorse di calcolo GPU.
Training distribuito
Nel training distribuito, il carico di lavoro per eseguire il training di un modello viene suddiviso e condiviso tra più mini processori, denominati nodi di lavoro. Questi nodi di lavoro funzionano in parallelo per velocizzare il training del modello. Attualmente la finestra di progettazione supporta il training distribuito per il componente Train PyTorch Model .
Tempo di addestramento
Il training distribuito consente di eseguire il training su un set di dati di grandi dimensioni, ad esempio ImageNet (1000 classi, 1,2 milioni di immagini) in poche ore da Train PyTorch Model. La tabella seguente illustra il tempo di training e le prestazioni durante il training di 50 periodi di Resnet50 su ImageNet da zero in base a dispositivi diversi.
| Dispositivi | Tempo di training | Velocità effettiva del training | Accuratezza della convalida top-1 | Accuratezza della convalida top-5 |
|---|---|---|---|---|
| 16 GPU V100 | 6h22min | ~3200 immagini/sec | 68.83% | 88.84% |
| 8 GPU V100 | 12h21min | ~1670 immagini/sec | 68.84% | 88.74% |
Fare clic sulla scheda "Metriche" del componente e visualizzare grafici delle metriche di training, ad esempio "Eseguire il training delle immagini al secondo" e "Accuratezza primi 1".

Come abilitare il training distribuito
Per abilitare il training distribuito per il componente Train PyTorch Model , è possibile impostare in Impostazioni processo nel riquadro destro del componente. Per il training distribuito è supportato solo il cluster di calcolo AML.
Nota
Per attivare il training distribuito sono necessarie più GPU perché il componente train PyTorch model del back-end NCCL usa cuda.
Selezionare il componente e aprire il pannello destro. Espandere la sezione Impostazioni processo.
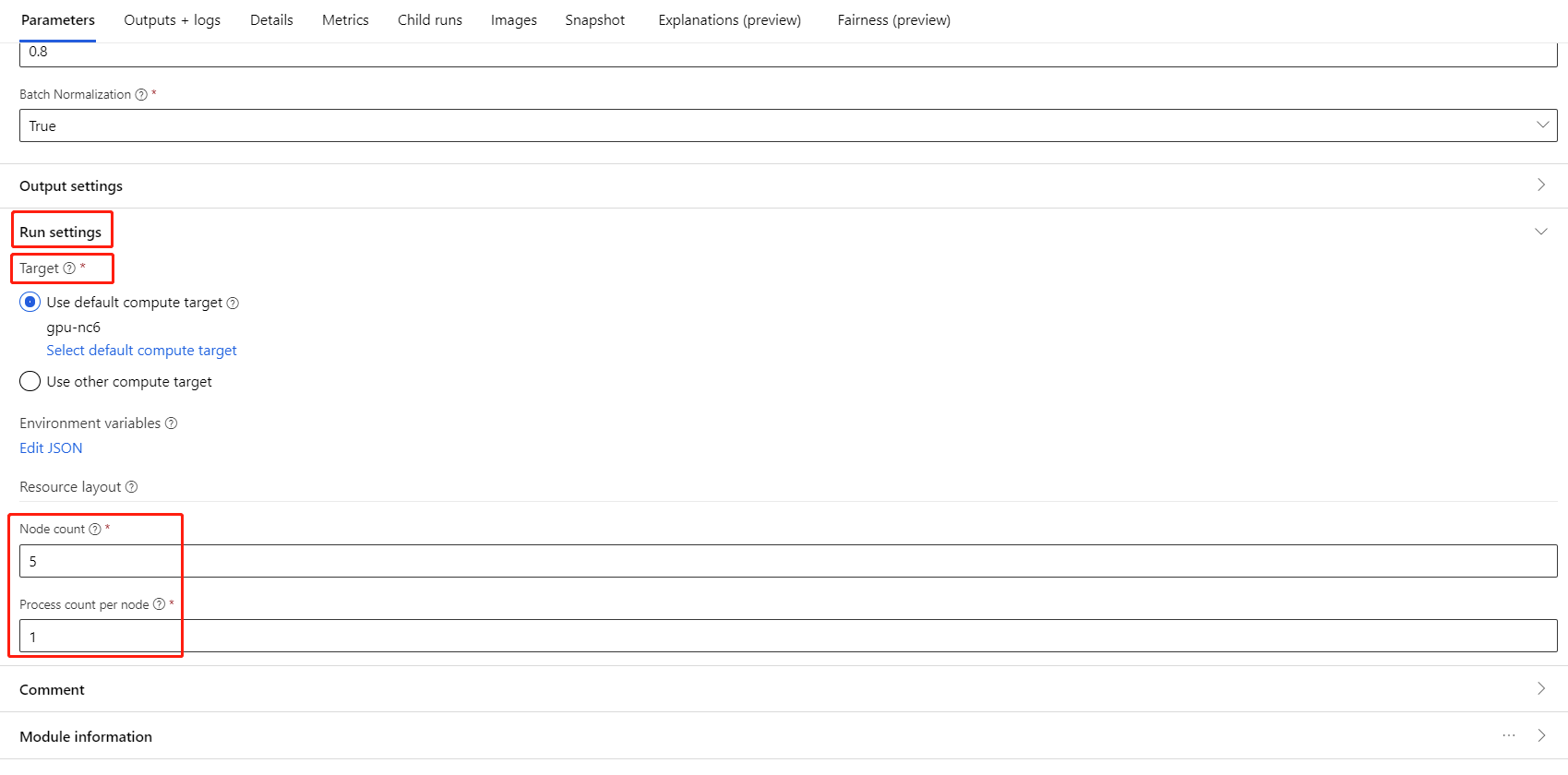
Assicurarsi di aver selezionato Calcolo AML per la destinazione di calcolo.
Nella sezione Layout risorse è necessario impostare i valori seguenti:
Numero di nodi: numero di nodi nella destinazione di calcolo usata per il training. Deve essere minore o uguale al numero massimo di nodi del cluster di calcolo. Per impostazione predefinita, è 1, il che significa processo a nodo singolo.
Numero di processi per nodo: numero di processi attivati per nodo. Deve essere minore o uguale all'unità di elaborazione dell'ambiente di calcolo. Per impostazione predefinita, è 1, ovvero un singolo processo di processo.
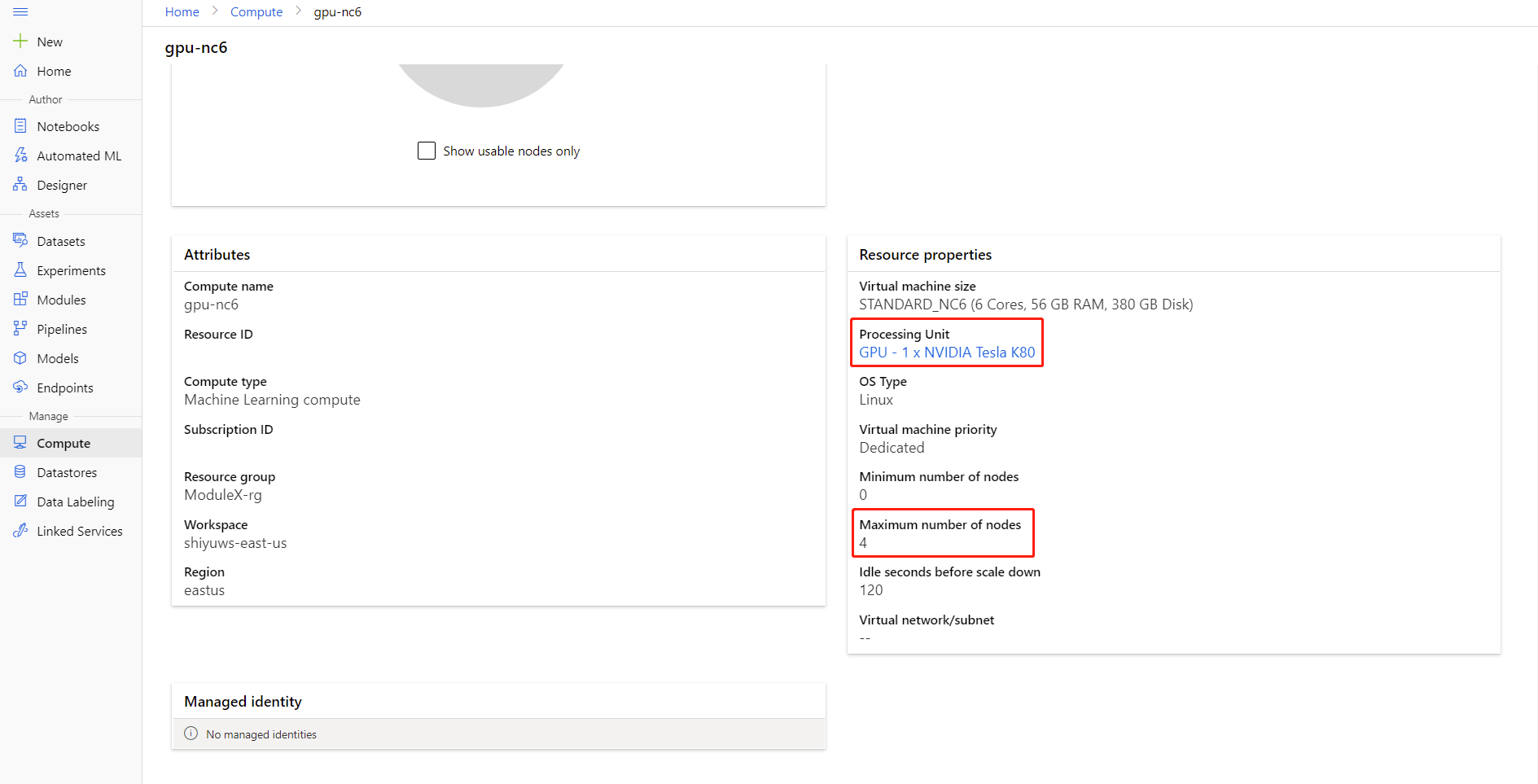
È possibile controllare il numero massimo di nodi e l'unità di elaborazione dell'ambiente di calcolo facendo clic sul nome del calcolo nella pagina dei dettagli di calcolo.


Altre informazioni sul training distribuito in Azure Machine Learning sono disponibili qui.
Risoluzione dei problemi per il training distribuito
Se si abilita il training distribuito per questo componente, verranno visualizzati i log dei driver per ogni processo. 70_driver_log_0 è per il processo master. È possibile controllare i log dei driver per i dettagli degli errori di ogni processo nella scheda Output e log nel riquadro destro.

Se il training distribuito abilitato per il componente ha esito negativo senza 70_driver alcun log, è possibile verificare 70_mpi_log i dettagli dell'errore.
L'esempio seguente mostra un errore comune, ovvero il numero di processi per nodo è maggiore dell'unità di elaborazione del calcolo.

Per altre informazioni sulla risoluzione dei problemi dei componenti, vedere questo articolo .
Risultati
Al termine del processo della pipeline, per usare il modello per l'assegnazione dei punteggi, connettere il modello Train PyTorch a Score Image Model per stimare i valori per i nuovi esempi di input.
Note tecniche
Input previsti
| Nome | Tipo | Descrizione |
|---|---|---|
| Modello senza training | UntrainedModelDirectory | Modello non sottoposto a training, richiedere PyTorch |
| Dataset di training | ImageDirectory | Dataset di training |
| Set di dati di convalida | ImageDirectory | Set di dati di convalida per la valutazione di ogni periodo |
Parametri del componente
| Nome | Intervallo | Type | Default | Descrizione |
|---|---|---|---|---|
| Epoche | >0 | Intero | 5 | Selezionare la colonna contenente l'etichetta o la colonna del risultato |
| Dimensioni del batch | >0 | Intero | 16 | Numero di istanze di cui eseguire il training in un batch |
| Numero di passaggio di riscaldamento | >=0 | Intero | 0 | Numero di periodi per il riscaldamento del training |
| Velocità di apprendimento | >=double. Epsilon | Float | 0,1 | Velocità di apprendimento iniziale per l'ottimizzatore di discesa del gradiente stocastico. |
| Random seed | Any | Intero | 1 | Valore di inizializzazione per il generatore di numeri casuali utilizzato dal modello. |
| Pazienza | >0 | Intero | 3 | Quante epoche arrestare il training in anticipo |
| Frequenza di stampa | >0 | Intero | 10 | Frequenza di stampa del log di training sulle iterazioni in ogni periodo |
Output
| Nome | Tipo | Descrizione |
|---|---|---|
| Modello sottoposto a training | ModelDirectory | Modello sottoposto a training |
Passaggi successivi
Vedere il set di componenti disponibili per Azure Machine Learning.