Train SVD Recommender (Training modulo di raccomandazione SVD)
Questo articolo descrive come usare il componente Train SVD Recommender nella finestra di progettazione di Azure Machine Learning. Usare questo componente per eseguire il training di un modello di raccomandazione basato sull'algoritmo SVD (Single Value Decomposition).
Il componente Train SVD Recommender legge un set di dati di triple di valutazione degli elementi utente. Restituisce un consigliatore SVD sottoposto a training. È quindi possibile usare il modello sottoposto a training per stimare le valutazioni o generare raccomandazioni connettendo il componente Score SVD Recommender .
Altre informazioni sui modelli di raccomandazione e sul consigliatore SVD
L'obiettivo principale di un sistema di raccomandazione è consigliare uno o più elementi agli utenti del sistema. Esempi di un elemento possono essere un film, un ristorante, un libro o una canzone. Un utente potrebbe essere una persona, un gruppo di persone o un'altra entità con preferenze di elemento.
Esistono due approcci principali per i sistemi di raccomandazione:
- Un approccio basato sul contenuto usa funzionalità sia per gli utenti che per gli elementi. Gli utenti possono essere descritti dalle proprietà, ad esempio età e sesso. Gli elementi possono essere descritti dalle proprietà, ad esempio autore e produttore. È possibile trovare esempi tipici di sistemi di raccomandazione basati sul contenuto sui siti di social matchmaking.
- Il filtro collaborativo usa solo gli identificatori degli utenti e degli elementi. Ottiene informazioni implicite su queste entità da una matrice (sparse) di valutazioni fornite dagli utenti agli elementi. È possibile ottenere informazioni su un utente dagli elementi che hanno valutato e da altri utenti che hanno valutato gli stessi elementi.
Il consigliatore SVD usa gli identificatori degli utenti e degli elementi e una matrice di valutazioni date dagli utenti agli elementi. Si tratta di un consigliatore collaborativo.
Per altre informazioni sul consigliatore SVD, vedere il documento di ricerca pertinente: Tecniche di fattorizzazione della matrice per i sistemi di raccomandazione.
Come configurare Train SVD Recommender
Preparazione dei dati
Prima di usare il componente, i dati di input devono essere nel formato previsto dal modello di raccomandazione. È necessario un set di dati di training di triple di valutazione degli elementi utente.
- La prima colonna contiene gli identificatori utente.
- La seconda colonna contiene identificatori di elemento.
- La terza colonna contiene la classificazione per la coppia di elementi utente. I valori di classificazione devono essere di tipo numerico.
Il set di dati Classificazioni film nella finestra di progettazione di Azure Machine Learning (selezionare Set di dati e quindi Esempi) illustra il formato previsto:
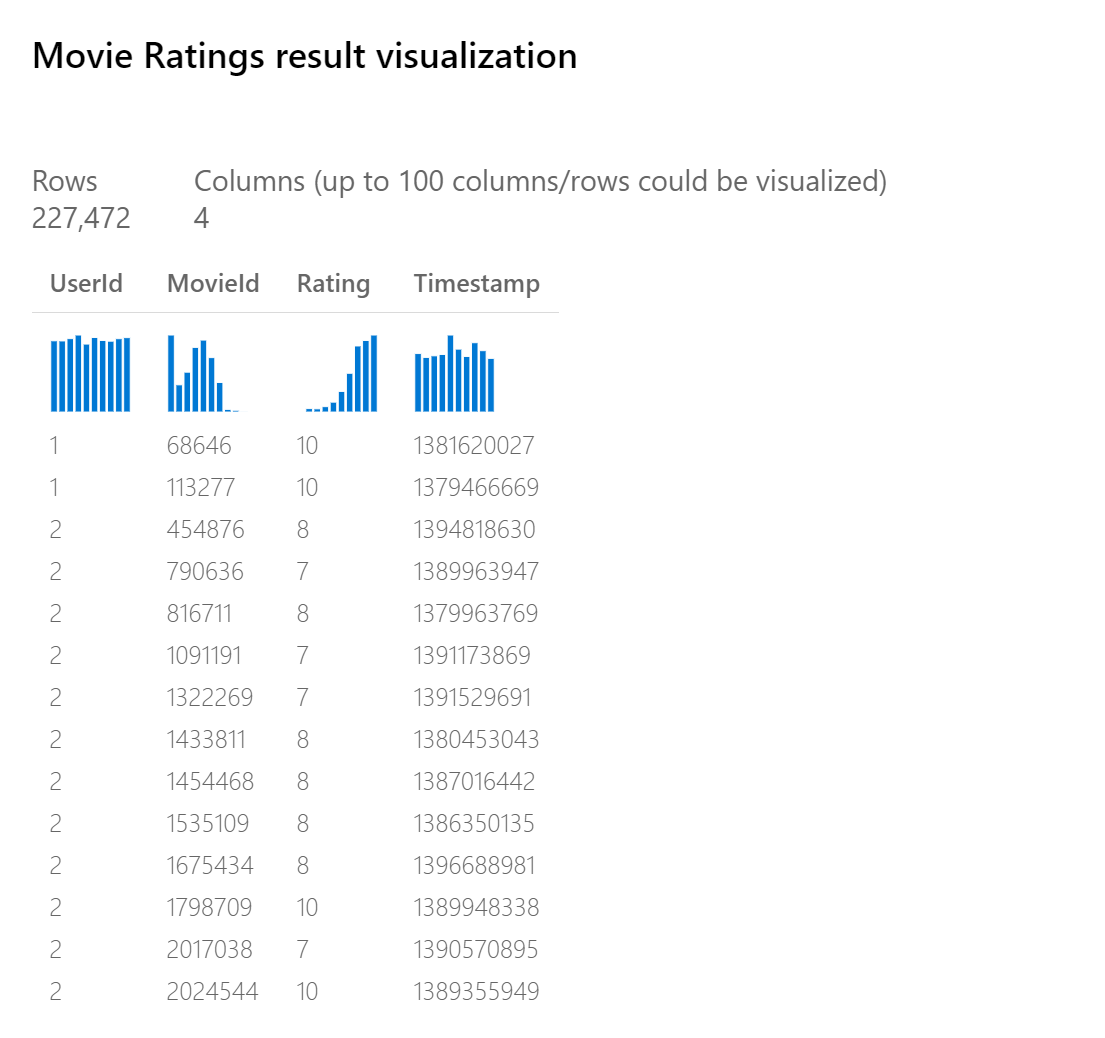
Da questo esempio è possibile notare che un singolo utente ha valutato diversi film.
Eseguire il training del modello
Aggiungere il componente Train SVD Recommender alla pipeline nella finestra di progettazione e connetterlo ai dati di training.
Per Numero di fattori, specificare il numero di fattori da usare con l'utilità di raccomandazione.
Ogni fattore misura la quantità di relazione dell'utente con l'elemento. Il numero di fattori è anche la dimensionalità dello spazio dei fattori latenti. Con l'aumento del numero di utenti ed elementi, è preferibile impostare un numero maggiore di fattori. Tuttavia, se il numero è troppo grande, le prestazioni potrebbero diminuire.
Il numero di iterazioni degli algoritmi di raccomandazione indica quante volte l'algoritmo deve elaborare i dati di input. Maggiore è questo numero, maggiore è la precisione delle stime. Tuttavia, un numero più elevato implica un training più lento. Il valore predefinito è 30.
Per Frequenza di apprendimento immettere un numero compreso tra 0,0 e 2,0 che definisce le dimensioni del passaggio per l'apprendimento.
La frequenza di apprendimento determina le dimensioni del passaggio in ogni iterazione. Se le dimensioni del passaggio sono troppo grandi, è possibile superare la soluzione ottimale. Se le dimensioni del passaggio sono troppo piccole, il training richiede più tempo per trovare la soluzione migliore.
Inviare la pipeline.
Risultati
Al termine del processo della pipeline, per usare il modello per l'assegnazione dei punteggi, connettere train SVD Recommender to Score SVD Recommender (Train SVD Recommender) per stimare i valori per i nuovi esempi di input.
Passaggi successivi
Vedere il set di componenti disponibili per Azure Machine Learning.