Inserimento dati con Azure Data Factory
Questo articolo illustra le opzioni disponibili per la creazione di una pipeline di inserimento dati con Azure Data Factory. Si usa una pipeline di Azure Data Factory per inserire i dati da usare con Azure Machine Learning. Data Factory consente di estrarre, trasformare e caricare (ETL) facilmente i dati. Dopo aver trasformato e caricato i dati nella risorsa di archiviazione, è possibile usarli per eseguire il training dei modelli di Machine Learning in Azure Machine Learning.
Le trasformazioni dei dati più semplici possono essere gestite con attività native di Data Factory e strumenti come il flusso di dati. Per scenari più complessi, è possibile elaborare i dati con codice personalizzato. Ad esempio, codice Python o R.
Confrontare le pipeline di inserimento dati di Azure Data Factory
Esistono diverse tecniche comuni di utilizzo di Data Factory per trasformare i dati durante l'inserimento. Ogni tecnica presenta vantaggi e svantaggi che consentono di determinare se si tratta di una scelta adatta per un caso d'uso specifico:
| Tecnica | Vantaggi | Svantaggi |
|---|---|---|
| Data Factory e Funzioni di Azure | Valide solo per l'elaborazione a esecuzione breve | |
| Data Factory e componente personalizzato | ||
| Data Factory e notebook di Azure Databricks |
Azure Data Factory con Funzioni di Azure
Funzioni di Azure consente di eseguire piccoli frammenti di codice (funzioni) senza doversi preoccupare dell'infrastruttura dell'applicazione. In questa opzione i dati vengono elaborati con codice Python personalizzato racchiuso in una funzione di Azure.
La funzione viene richiamata con l'attività funzione di Azure di Azure Data Factory. Questo approccio è un'opzione valida per le trasformazioni dei dati leggere.
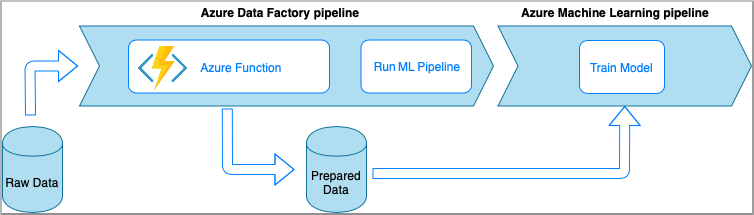
- Vantaggi:
- I dati vengono elaborati in un ambiente di calcolo serverless con una latenza relativamente bassa
- La pipeline di Data Factory può richiamare una funzione Azure Durable Function che può implementare un flusso di trasformazione dei dati sofisticato
- I dettagli della trasformazione dei dati vengono astratti dalla funzione di Azure che può essere riutilizzata e richiamata da altre posizioni
- Svantaggi:
- Le funzioni di Azure devono essere create prima dell'uso con Azure Data Factory
- Funzioni di Azure è utile solo per l'elaborazione dei dati a esecuzione breve
Azure Data Factory con attività componente personalizzato
In questa opzione i dati vengono elaborati con codice Python personalizzato racchiuso in un eseguibile. Viene richiamato con un'attività componente personalizzato di Azure Data Factory. Questo approccio è una soluzione per i dati di grandi dimensioni più adatta rispetto alla tecnica precedente.
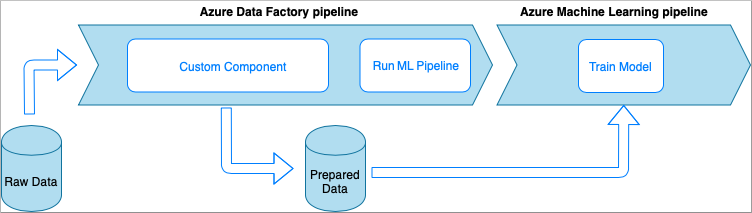
- Vantaggi:
- I dati vengono elaborati in pool di Azure Batch, che offre elaborazione parallela e a prestazioni elevate su larga scala
- Può essere usato per eseguire algoritmi complessi ed elaborare quantità significative di dati
- Svantaggi:
- Il pool di Azure Batch deve essere creato prima dell'uso con Data Factory
- Attività di progettazione aggiuntive relative al wrapping del codice Python in un eseguibile. Complessità della gestione delle dipendenze e dei parametri di I/O
Azure Data Factory con notebook Python di Azure Databricks
Azure Databricks è una piattaforma di analisi basata su Apache Spark nel cloud Microsoft.
In questa tecnica, la trasformazione dei dati viene eseguita da un notebook Python in esecuzione in un cluster Azure Databricks. Questo è probabilmente l'approccio più comune che usa la potenza completa di un servizio Azure Databricks. È progettato per l'elaborazione dei dati distribuiti su larga scala.
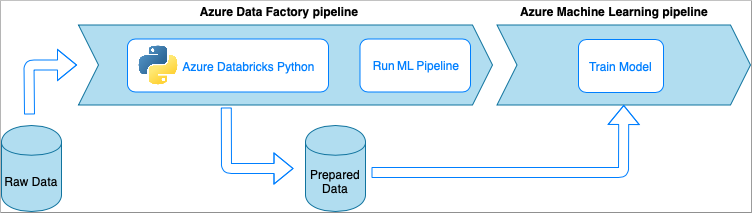
- Vantaggi:
- I dati vengono trasformati nel servizio di elaborazione dati di Azure più potente, supportato dall'ambiente Apache Spark
- Supporto nativo di Python insieme a framework e librerie di data science, tra cui TensorFlow, PyTorch e scikit-learn
- Non è necessario eseguire il wrapping del codice Python in funzioni o moduli eseguibili. Il codice funziona così com'è.
- Svantaggi:
- L'infrastruttura di Azure Databricks deve essere creata prima dell'uso con Data Factory
- Può essere una soluzione costosa a seconda della configurazione di Azure Databricks
- La riattivazione dei cluster di elaborazione dalla modalità "ad accesso saltuario" richiede tempo che comporta una latenza elevata per la soluzione
Utilizzare i dati in Azure Machine Learning
La pipeline di Data Factory salva i dati preparati nel servizio di archiviazione cloud, ad esempio BLOB di Azure o Azure Data Lake.
Utilizzare i dati preparati in Azure Machine Learning:
- Richiamando una pipeline di Azure Machine Learning dalla pipeline di Data Factory.
OPPURE - Creando un archivio dati di Azure Machine Learning.
Richiamare la pipeline di Azure Machine Learning da Data Factory
Questo metodo è consigliato per i flussi di lavoro di operazioni per l'apprendimento automatico (MLOps). Se non si vuole configurare una pipeline di Azure Machine Learning, vedere Eseguire la lettura dei dati direttamente dal servizio di archiviazione.
Ogni volta che viene eseguita la pipeline di Data Factory,
- i dati vengono salvati in una posizione diversa nel servizio di archiviazione.
- Per passare la posizione ad Azure Machine Learning, la pipeline di Data Factory chiama una pipeline di Azure Machine Learning. Quando la pipeline di Data Factory chiama la pipeline di Azure Machine Learning, il percorso dei dati e l'ID processo vengono inviati come parametri.
- La pipeline di Machine Learning può quindi creare un archivio dati e un set di dati di Azure Machine Learning con la posizione dei dati. Per altre informazioni, vedere Eseguire pipeline di Azure Machine Learning in Azure Data Factory.
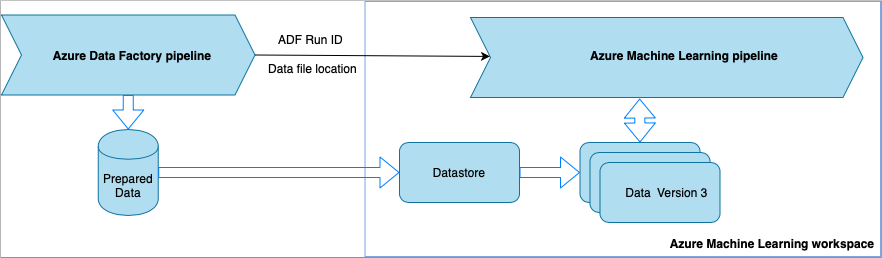
Suggerimento
I set di dati supportano il controllo delle versioni, per consentire alla pipeline di Machine Learning di registrare una nuova versione del set di dati che punta ai dati più recenti dalla pipeline di Azure Data Factory.
Quando i dati sono accessibili tramite un archivio dati o un set di dati, è possibile usarli per eseguire il training di un modello di Machine Learning. Il processo di training potrebbe far parte della stessa pipeline di Machine Learning chiamata da Azure Data Factory. Oppure potrebbe trattarsi di un processo separato, ad esempio la sperimentazione in un notebook di Jupyter.
Poiché i set di dati supportano il controllo delle versioni e ogni processo della pipeline crea una nuova versione, è facile comprendere quale versione dei dati è stata usata per eseguire il training di un modello.
Eseguire la lettura dei dati direttamente dal servizio di archiviazione
Se non si vuole creare una pipeline di Machine Learning, è possibile accedere ai dati direttamente dall'account di archiviazione in cui i dati preparati sono salvati con un archivio dati e un set di dati di Azure Machine Learning.
Il codice Python seguente illustra come creare un archivio dati che si connette al servizio Azure Data Lake Storage Gen2. Altre informazioni sugli archivi dati e su dove trovare le autorizzazioni dell'entità servizio.
SI APPLICA A:  SDK azureml per Pythonv1
SDK azureml per Pythonv1
ws = Workspace.from_config()
adlsgen2_datastore_name = '<ADLS gen2 storage account alias>' #set ADLS Gen2 storage account alias in Azure Machine Learning
subscription_id=os.getenv("ADL_SUBSCRIPTION", "<ADLS account subscription ID>") # subscription id of ADLS account
resource_group=os.getenv("ADL_RESOURCE_GROUP", "<ADLS account resource group>") # resource group of ADLS account
account_name=os.getenv("ADLSGEN2_ACCOUNTNAME", "<ADLS account name>") # ADLS Gen2 account name
tenant_id=os.getenv("ADLSGEN2_TENANT", "<tenant id of service principal>") # tenant id of service principal
client_id=os.getenv("ADLSGEN2_CLIENTID", "<client id of service principal>") # client id of service principal
client_secret=os.getenv("ADLSGEN2_CLIENT_SECRET", "<secret of service principal>") # the secret of service principal
adlsgen2_datastore = Datastore.register_azure_data_lake_gen2(
workspace=ws,
datastore_name=adlsgen2_datastore_name,
account_name=account_name, # ADLS Gen2 account name
filesystem='<filesystem name>', # ADLS Gen2 filesystem
tenant_id=tenant_id, # tenant id of service principal
client_id=client_id, # client id of service principal
Creare quindi un set di dati per fare riferimento ai file da usare nell'attività di apprendimento automatico.
Il codice seguente crea un set TabularDataset da un file CSV, prepared-data.csv. Altre informazioni sui tipi di set di dati e sui formati di file accettati.
SI APPLICA A: SDK azureml per Pythonv1
from azureml.core import Workspace, Datastore, Dataset
from azureml.core.experiment import Experiment
from azureml.train.automl import AutoMLConfig
# retrieve data via Azure Machine Learning datastore
datastore = Datastore.get(ws, adlsgen2_datastore)
datastore_path = [(datastore, '/data/prepared-data.csv')]
prepared_dataset = Dataset.Tabular.from_delimited_files(path=datastore_path)
Da qui usare prepared_dataset per fare riferimento ai dati preparati, ad esempio negli script di training. Informazioni su come eseguire il training di modelli con i set di dati in Azure Machine Learning.