La deriva dei dati (anteprima) verrà ritirata e sostituita da Monitoraggio modelli
La deriva dei dati (anteprima) verrà ritirata il 01/09/2025 ed è possibile iniziare a usare Monitoraggio modelli per le attività di deriva dei dati. Controllare il contenuto seguente per comprendere la sostituzione, le lacune di funzionalità e i passaggi di modifica manuale.
SI APPLICA A: Python SDK azureml v1
Python SDK azureml v1
Informazioni su come monitorare la deriva dei dati e impostare avvisi quando la deriva è elevata.
Nota
Il monitoraggio dei modelli di Azure Machine Learning (v2) offre funzionalità migliorate per la deriva dei dati oltre a funzionalità aggiuntive per il monitoraggio dei segnali e delle metriche. Per altre informazioni sulle funzionalità di monitoraggio dei modelli in Azure Machine Learning (v2), vedere Monitoraggio dei modelli con Azure Machine Learning.
Con i monitoraggi di set di dati di Azure Machine Learning (anteprima), è possibile:
- Analizzare la deriva nei dati per comprendere come cambiano nel tempo.
- Monitorare i dati del modello per le differenze tra i set di dati di training e di servizio. Iniziare raccogliendo dati del modello dai modelli distribuiti.
- Monitorare i nuovi dati per le differenze tra un set di dati di base e uno di destinazione.
- Profilare le caratteristiche nei dati per tracciare come le proprietà statistiche cambiano nel tempo.
- Impostare avvisi sulla deriva dei dati per avvisi precoci su potenziali problemi.
- Creare una nuova versione del set di dati quando si determina che i dati presentano deriva eccessiva.
Un set di dati di Azure Machine Learning è utilizzato per creare il monitoraggio. Il set di dati deve includere una colonna con il timestamp.
È possibile visualizzare le metriche della deriva dei dati con SDK Python o nello studio di Azure Machine Learning. Altre metriche e informazioni dettagliate sono disponibili tramite la risorsa Azure Application Insights associata all'area di lavoro Azure Machine Learning.
Importante
Il rilevamento della deriva dei dati per i set di dati è attualmente in anteprima pubblica. La versione di anteprima viene messa a disposizione senza contratto di servizio e non è consigliata per i carichi di lavoro di produzione. Alcune funzionalità potrebbero non essere supportate o potrebbero presentare funzionalità limitate. Per altre informazioni, vedere le Condizioni supplementari per l'uso delle anteprime di Microsoft Azure.
Prerequisiti
Per creare e lavorare con i monitoraggi di set di dati, è necessario:
- Una sottoscrizione di Azure. Se non si ha una sottoscrizione di Azure, creare un account gratuito prima di iniziare. Provare la versione gratuita o a pagamento di Azure Machine Learning.
- Un'area di lavoro di Azure Machine Learning.
- Aver installato SDK di Azure Machine Learning per Python, che include il pacchetto azureml-datasets.
- Avere dati strutturati (tabellari) con un timestamp specificato nel percorso del file, nel nome del file o in una colonna dei dati.
Prerequisiti (migrazione a Monitoraggio modelli)
Quando si esegue la migrazione a Monitoraggio modelli, controllare i prerequisiti come indicato in questo articolo Prerequisiti del monitoraggio dei modelli di Azure Machine Learning.
Che cos'è la deriva dei dati?
L'accuratezza del modello degrada nel tempo, in gran parte a causa della deriva dei dati. Per i modelli di Machine Learning, la deriva dei dati è il cambiamento nei dati di input del modello che porta a una riduzione del livello delle prestazioni del modello. Monitorare la deriva dei dati aiuta a rilevare questi problemi di prestazione del modello.
Le cause della deriva dei dati includono:
- Cambiamenti nei processi a monte, come la sostituzione di un sensore che cambia le unità di misura da pollici a centimetri.
- Problemi di qualità dei dati, come un sensore interrotto che legge sempre 0.
- Deriva naturale nei dati, come il cambiamento della temperatura media con le stagioni.
- Cambiamento nella relazione tra caratteristiche, o spostamento covariato.
Azure Machine Learning semplifica il rilevamento della deriva calcolando una singola metrica che astrae la complessità dei set di dati confrontati. Questi set di dati possono avere centinaia di caratteristiche e decine di migliaia di righe. Una volta rilevata la deriva, è possibile eseguire il drill-down di quali caratteristiche stanno causando la deriva. Si esaminano quindi le metriche a livello di caratteristica per eseguire il debug e isolare la causa principale della deriva.
Questo approccio dall'alto verso il basso rende più semplice monitorare i dati rispetto alle tecniche tradizionali basate su regole. Le tecniche basate su regole, come l'intervallo di dati consentito o i valori univoci consentiti, possono essere dispendiose in termini di tempo e soggette a errori.
In Azure Machine Learning, si utilizzano i monitoraggi di set di dati per rilevare e avvisare in caso di deriva dei dati.
Monitoraggi del set di dati
Con un monitoraggio di set di dati è possibile:
- Rilevare e avvisare in caso di deriva dei dati su nuovi dati in un set di dati.
- Analizzare i dati cronologici per la deriva.
- Profilare i nuovi dati nel tempo.
L'algoritmo di deriva dei dati fornisce una misura generale del cambiamento nei dati e un'indicazione delle caratteristiche responsabili per ulteriori indagini. I monitoraggi di set di dati producono molte altre metriche profilando i nuovi dati nel set di dati timeseries.
È possibile impostare avvisi personalizzati su tutte le metriche generate dal monitoraggio tramite Azure Application Insights. I monitoraggi di set di dati possono essere utilizzati per individuare rapidamente problemi nei dati e ridurre il tempo necessario per risolvere il problema identificando le cause probabili.
Concettualmente, sono tre gli scenari principali per l'impostazione di monitoraggi di set di dati in Azure Machine Learning.
| Scenario | Descrizione |
|---|---|
| Monitorare i dati di servizio di un modello per la deriva dai dati di training | I risultati di questo scenario possono essere interpretati come il monitoraggio di un proxy per l'accuratezza del modello, poiché l'accuratezza del modello si degrada quando i dati di servizio derivano dai dati di training. |
| Monitorare un set di dati di serie temporale per la deriva da un periodo precedente. | Questo scenario è più generale e può essere utilizzato per monitorare set di dati coinvolti a monte o a valle della creazione del modello. Il set di dati di destinazione deve avere una colonna timestamp. Il set di dati di base può essere qualsiasi set di dati tabulari che ha caratteristiche in comune con il set di dati di destinazione. |
| Eseguire analisi sui dati passati. | Questo scenario può essere utilizzato per comprendere i dati cronologici e informare le decisioni nelle impostazioni dei monitoraggi di set di dati. |
I monitoraggi di set di dati dipendono dai seguenti servizi Azure.
| Servizio di Azure | Descrizione |
|---|---|
| Set di dati | La deriva utilizza i set di dati di Machine Learning per recuperare i dati di training e confrontare i dati per il training del modello. La generazione del profilo dei dati è utilizzata per generare alcune delle metriche riportate come minimo, massimo, valori distinti, conteggio dei valori distinti. |
| Pipeline e calcolo Azure Machine Learning | Il processo di calcolo della deriva è ospitato in una pipeline di Azure Machine Learning. Il processo è attivato su richiesta o secondo una pianificazione per essere eseguito su un calcolo configurato al momento della creazione del monitoraggio della deriva. |
| Application Insights | La deriva emette metriche ad Application Insights appartenenti all'area di lavoro di Machine Learning. |
| Archiviazione BLOB di Azure | La deriva emette metriche in formato json all'Archiviazione BLOB di Azure. |
Set di dati di base e set di dati di destinazione
Si monitorano i set di dati di Azure Machine Learning per la deriva dei dati. Quando si crea un monitoraggio di set di dati, si fa riferimento a:
- Set di dati di base, solitamente il set di dati di training per un modello.
- Set di dati di destinazione, solitamente i dati di input del modello, vengono confrontati nel tempo con il set di dati di base. Questo confronto significa che il set di dati di destinazione deve avere specificata una colonna timestamp.
Il monitoraggio confronta i set di dati di base e di destinazione.
Eseguire la migrazione a Monitoraggio modelli
In Monitoraggio modelli è possibile trovare i concetti corrispondenti come indicato di seguito ed è possibile trovare altri dettagli in questo articolo Configurare il monitoraggio dei modelli portando i dati di produzione in Azure Machine Learning:
- Set di dati di riferimento: simile al set di dati di base per il rilevamento della deriva dei dati, viene impostato come set di dati di inferenza di produzione recente.
- Dati di inferenza di produzione: analogamente al set di dati di destinazione nel rilevamento della deriva dei dati, i dati di inferenza di produzione possono essere raccolti automaticamente dai modelli distribuiti nell'ambiente di produzione. Possono anche essere dati di inferenza archiviati.
Creare il set di dati di destinazione
Il set di dati di destinazione necessita dell'impostazione della caratteristica timeseries specificando la colonna timestamp, sia da una colonna presente nei dati sia da una colonna virtuale derivata dal modello di percorso dei file. Creare il set di dati con un timestamp tramite il SDK Python o lo studio di Azure Machine Learning. È necessario specificare una colonna che rappresenti un timestamp per aggiungere la caratteristica timeseries al set di dati. Se i dati sono partizionati in una struttura di cartelle con informazioni temporali, come '{yyyy/MM/dd}', creare una colonna virtuale tramite l'impostazione del modello di percorso e impostarla come "timestamp di partizione" per abilitare la funzionalità dell'API di serie temporali.
SI APPLICA A:Python SDK azureml v1
Il metodo with_timestamp_columns() della classe Dataset definisce la colonna timestamp per il set di dati.
from azureml.core import Workspace, Dataset, Datastore
# get workspace object
ws = Workspace.from_config()
# get datastore object
dstore = Datastore.get(ws, 'your datastore name')
# specify datastore paths
dstore_paths = [(dstore, 'weather/*/*/*/*/data.parquet')]
# specify partition format
partition_format = 'weather/{state}/{date:yyyy/MM/dd}/data.parquet'
# create the Tabular dataset with 'state' and 'date' as virtual columns
dset = Dataset.Tabular.from_parquet_files(path=dstore_paths, partition_format=partition_format)
# assign the timestamp attribute to a real or virtual column in the dataset
dset = dset.with_timestamp_columns('date')
# register the dataset as the target dataset
dset = dset.register(ws, 'target')
Suggerimento
Per un esempio completo dell'utilizzo della caratteristica timeseries dei set di dati, consulta il notebook di esempio o la documentazione dell'SDK dei set di dati.

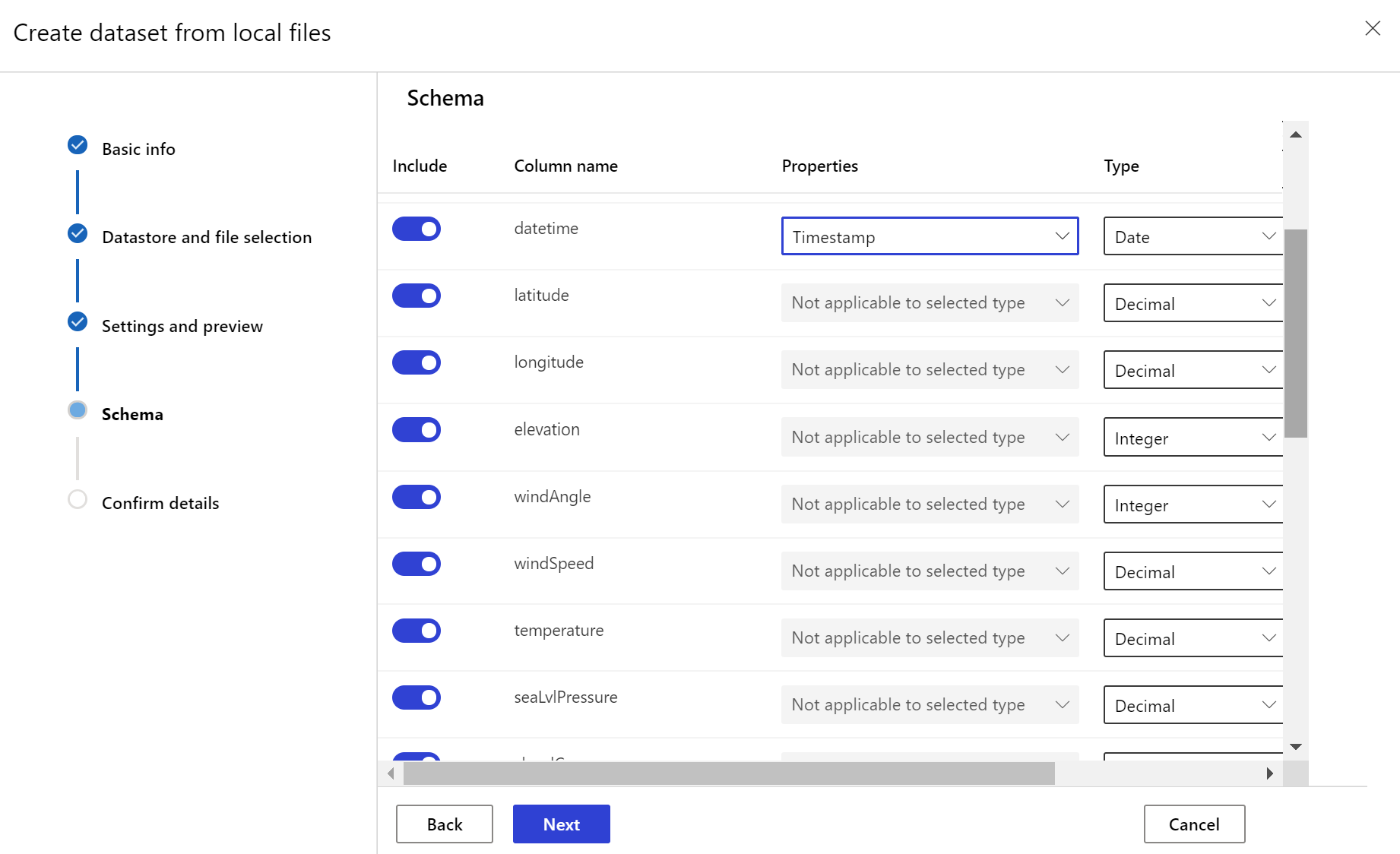
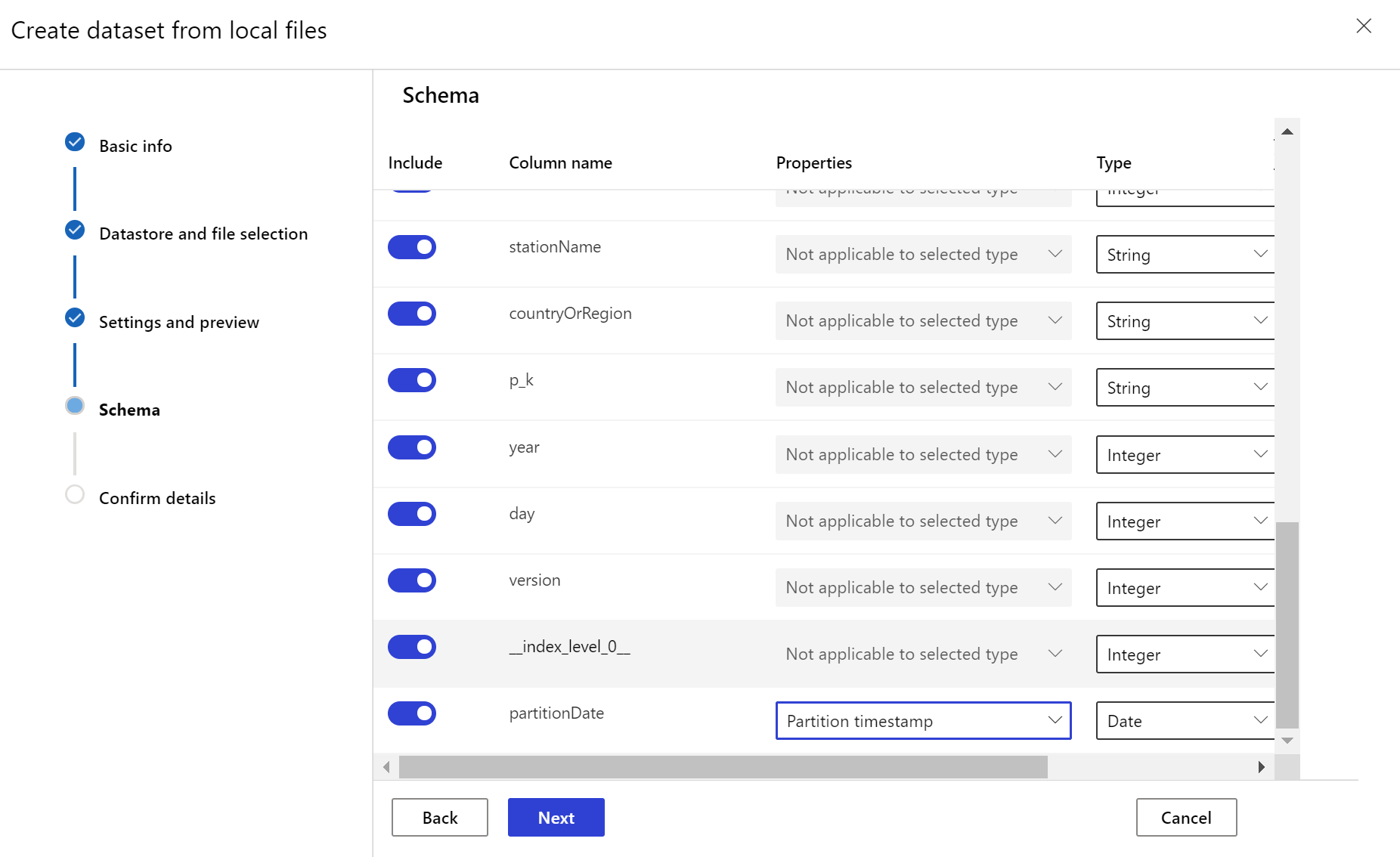
Creare il monitoraggio del set di dati
Creare un monitoraggio di set di dati per rilevare e segnalare la deriva dei dati su un nuovo set di dati. Utilizzare il SDK Python o lo studio di Azure Machine Learning.
Come descritto più avanti, un monitoraggio del set di dati viene eseguito a intervalli di frequenza (giornaliera, settimanale, mensile). Analizza i nuovi dati disponibili nel set di dati di destinazione dall'ultima esecuzione. In alcuni casi, tali analisi dei dati più recenti potrebbero non essere sufficienti:
- I nuovi dati dell'origine upstream sono stati ritardati a causa di una pipeline di dati interrotta e questi nuovi dati non erano disponibili durante l'esecuzione del monitoraggio del set di dati.
- Un set di dati della serie temporale disponeva solo di dati cronologici e si vuole analizzare i modelli di deriva nel set di dati nel tempo. Ad esempio: confrontare il traffico che passa a un sito Web, sia in inverno che in estate, per identificare i modelli stagionali.
- Non si ha familiarità con i monitoraggi dei set di dati. Si vuole valutare il funzionamento della funzionalità con i dati esistenti prima di configurarlo per monitorare i giorni futuri. In questi scenari, è possibile inviare un'esecuzione su richiesta, con un intervallo di date del set di dati di destinazione specifico, da confrontare con il set di dati di base.
La funzione back-fill esegue un processo di back-fill per un intervallo di date di inizio e di fine specificato. Un processo di back-fill riempie i punti dati mancanti previsti in un set di dati, in modo da garantire l'accuratezza e la completezza dei dati.
Nota
Il monitoraggio dei modelli di Azure Machine Learning non supporta la funzione back-fill manuale; se si vuole ripetere il monitoraggio dei modelli per un intervallo di tempo specifico, è possibile creare un altro monitoraggio del modello per tale intervallo di tempo specifico.
SI APPLICA A:Python SDK azureml v1
Consulta la documentazione di riferimento del SDK Python sulla deriva dei dati per tutti i dettagli.
L'esempio seguente mostra come creare un monitoraggio di set di dati usando l'SDK Python:
from azureml.core import Workspace, Dataset
from azureml.datadrift import DataDriftDetector
from datetime import datetime
# get the workspace object
ws = Workspace.from_config()
# get the target dataset
target = Dataset.get_by_name(ws, 'target')
# set the baseline dataset
baseline = target.time_before(datetime(2019, 2, 1))
# set up feature list
features = ['latitude', 'longitude', 'elevation', 'windAngle', 'windSpeed', 'temperature', 'snowDepth', 'stationName', 'countryOrRegion']
# set up data drift detector
monitor = DataDriftDetector.create_from_datasets(ws, 'drift-monitor', baseline, target,
compute_target='cpu-cluster',
frequency='Week',
feature_list=None,
drift_threshold=.6,
latency=24)
# get data drift detector by name
monitor = DataDriftDetector.get_by_name(ws, 'drift-monitor')
# update data drift detector
monitor = monitor.update(feature_list=features)
# run a backfill for January through May
backfill1 = monitor.backfill(datetime(2019, 1, 1), datetime(2019, 5, 1))
# run a backfill for May through today
backfill1 = monitor.backfill(datetime(2019, 5, 1), datetime.today())
# disable the pipeline schedule for the data drift detector
monitor = monitor.disable_schedule()
# enable the pipeline schedule for the data drift detector
monitor = monitor.enable_schedule()
Suggerimento
Per un esempio completo su come configurare un set di dati timeseries e un rilevatore di deriva dei dati, consulta il nostro notebook di esempio.
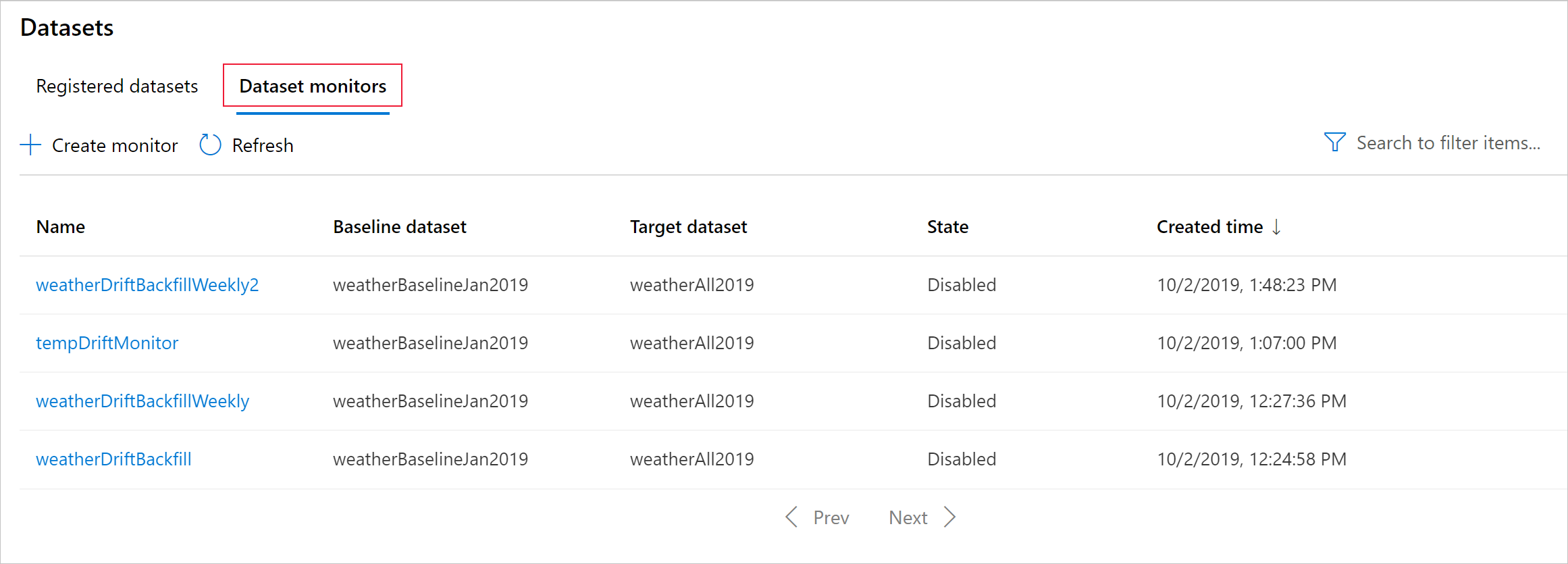
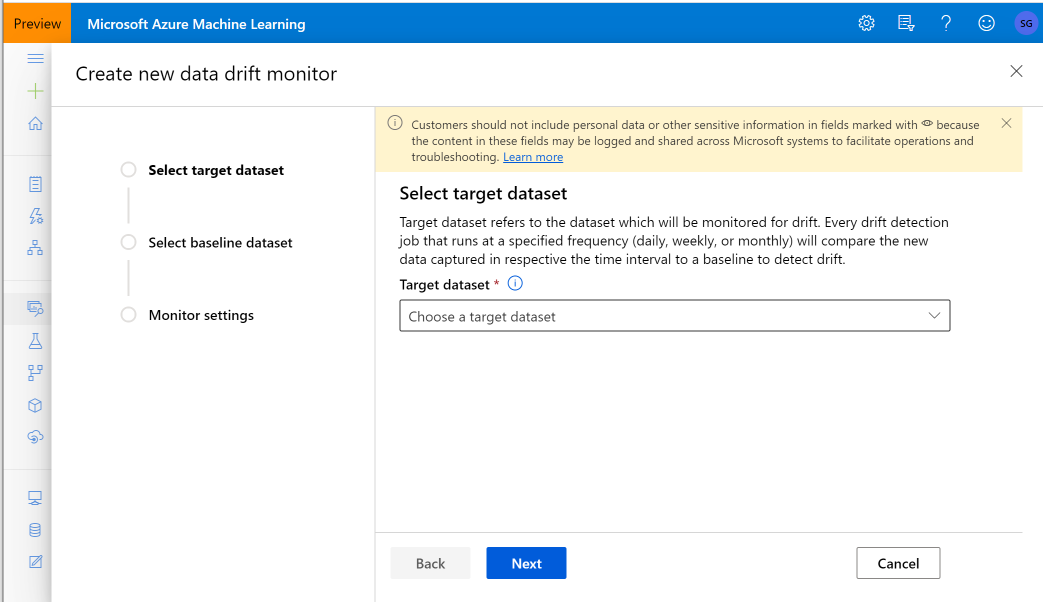
Creare Monitoraggio modelli (eseguire la migrazione a Monitoraggio modelli)
Quando si esegue la migrazione a Monitoraggio modelli, se il modello è stato distribuito nell'ambiente di produzione in un endpoint online di Azure Machine Learning e si è abilitata la raccolta dati in fase di distribuzione, Azure Machine Learning raccoglie i dati di inferenza di produzione e li archivia automaticamente in Archiviazione BLOB di Microsoft Azure. È quindi possibile usare il monitoraggio dei modelli di Azure Machine Learning per monitorare continuamente questi dati di inferenza di produzione ed è possibile scegliere direttamente il modello per creare il set di dati di destinazione (dati di inferenza di produzione in Monitoraggio modelli).
Quando si esegue la migrazione a Monitoraggio modelli, se il modello non è stato distribuito nell'ambiente di produzione in un endpoint online di Azure Machine Learning o non si vuole usare la raccolta dati, è anche possibile configurare il monitoraggio del modello con segnali e metriche personalizzati.
Le sezioni seguenti contengono altri dettagli su come eseguire la migrazione a Monitoraggio modelli.
Creare Monitoraggio modelli tramite i dati di produzione raccolti automaticamente (eseguire la migrazione a Monitoraggio modelli)
Se il modello è stato distribuito in produzione in un endpoint online di Azure Machine Learning e si è abilitata la raccolta dati al momento della distribuzione.
È possibile usare il seguente codice per configurare il monitoraggio dei modelli preconfigurato:
from azure.identity import DefaultAzureCredential
from azure.ai.ml import MLClient
from azure.ai.ml.entities import (
AlertNotification,
MonitoringTarget,
MonitorDefinition,
MonitorSchedule,
RecurrencePattern,
RecurrenceTrigger,
ServerlessSparkCompute
)
# get a handle to the workspace
ml_client = MLClient(
DefaultAzureCredential(),
subscription_id="subscription_id",
resource_group_name="resource_group_name",
workspace_name="workspace_name",
)
# create the compute
spark_compute = ServerlessSparkCompute(
instance_type="standard_e4s_v3",
runtime_version="3.3"
)
# specify your online endpoint deployment
monitoring_target = MonitoringTarget(
ml_task="classification",
endpoint_deployment_id="azureml:credit-default:main"
)
# create alert notification object
alert_notification = AlertNotification(
emails=['abc@example.com', 'def@example.com']
)
# create the monitor definition
monitor_definition = MonitorDefinition(
compute=spark_compute,
monitoring_target=monitoring_target,
alert_notification=alert_notification
)
# specify the schedule frequency
recurrence_trigger = RecurrenceTrigger(
frequency="day",
interval=1,
schedule=RecurrencePattern(hours=3, minutes=15)
)
# create the monitor
model_monitor = MonitorSchedule(
name="credit_default_monitor_basic",
trigger=recurrence_trigger,
create_monitor=monitor_definition
)
poller = ml_client.schedules.begin_create_or_update(model_monitor)
created_monitor = poller.result()


Creare Monitoraggio modelli tramite un componente di pre-elaborazione dati personalizzato (eseguire la migrazione a Monitoraggio modelli)
Quando si esegue la migrazione a Monitoraggio modelli, se il modello non è stato distribuito nell'ambiente di produzione in un endpoint online di Azure Machine Learning o non si vuole usare la raccolta dati, è anche possibile configurare il monitoraggio del modello con segnali e metriche personalizzati.
Se non si dispone di una distribuzione, ma si hanno dati di produzione, è possibile utilizzare i dati per eseguire un monitoraggio continuo dei modelli. Per monitorare questi modelli, è necessario essere in grado di:
- Raccogliere i dati di inferenza di produzione dai modelli distribuiti in produzione.
- Registrare i dati di inferenza di produzione come asset di dati di Azure Machine Learning e garantire aggiornamenti continui dei dati.
- Fornire un componente personalizzato di pre-elaborazione dei dati e registrarlo come componente di Azure Machine Learning.
È necessario fornire un componente personalizzato di pre-elaborazione dei dati se i dati non sono raccolti con l'agente di raccolta dati. Senza questo componente personalizzato di pre-elaborazione dei dati, il sistema di monitoraggio del modello di Azure Machine Learning non saprà come elaborare i dati in forma tabellare con supporto per la windowing temporale.
Il componente di pre-elaborazione personalizzato deve disporre di queste firme di input e output:
| Input/Output | Nome della firma | Tipo | Descrizione | Valore di esempio |
|---|---|---|---|---|
| input | data_window_start |
letterale, string | ora di inizio della finestra dati nel formato ISO8601. | 2023-05-01T04:31:57.012Z |
| input | data_window_end |
letterale, string | ora di fine della finestra dati nel formato ISO8601. | 2023-05-01T04:31:57.012Z |
| input | input_data |
uri_folder | I dati di inferenza produttivi raccolti, registrati come asset di dati di Azure Machine Learning. | azureml:myproduction_inference_data:1 |
| output | preprocessed_data |
mltable | Un dataset tabulare, che corrisponde a un sottoinsieme dello schema dei dati di riferimento. |
Per un esempio di un componente di pre-elaborazione dei dati personalizzato, vedere custom_preprocessing in the azuremml-examples GitHub repo.
Informazioni sui risultati della deriva dei dati
Questa sezione mostra i risultati del monitoraggio di un set di dati, reperibili nella pagina Set di dati / Monitoraggi di set di dati nello studio di Azure. È possibile aggiornare le impostazioni e analizzare i dati esistenti per un periodo di tempo specifico in questa pagina.
Iniziare con le informazioni dettagliate di primo livello sull'entità della deriva dei dati e una evidenziazione delle caratteristiche da indagare ulteriormente.
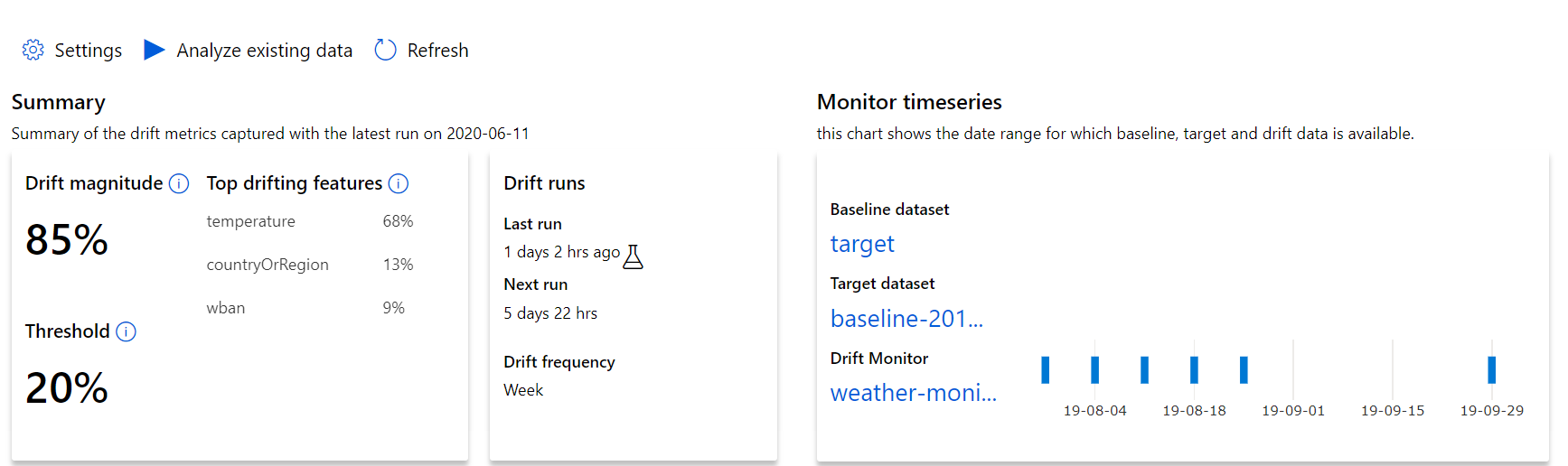
| Metrico | Descrizione |
|---|---|
| Grandezza della deriva dei dati | Una percentuale di deriva tra il set di dati di base e il set di dati di destinazione nel tempo. Questa percentuale varia da 0 a 100, dove 0 indica set di dati identici e 100 indica che il modello di deriva dei dati di Azure Machine Learning può distinguere completamente i due set di dati. Nelle tecniche di Machine Learning utilizzate per generare questa misurazione, è prevista una certa variabilità o imprecisione nel calcolo preciso della percentuale, a causa delle incertezze intrinseche. |
| Principali funzionalità con deriva | Mostra le funzionalità del set di dati con maggiore deriva e che quindi contribuiscono maggiormente alla metrica di grandezza della deriva. A causa dello spostamento covariato, la distribuzione sottostante di una caratteristica non deve necessariamente cambiare per avere un'importanza relativa della caratteristica piuttosto elevata. |
| Threshold | Una magnitudine della deriva dei dati oltre la soglia impostata attiva gli avvisi. Configurare il valore soglia nelle impostazioni di monitoraggio. |
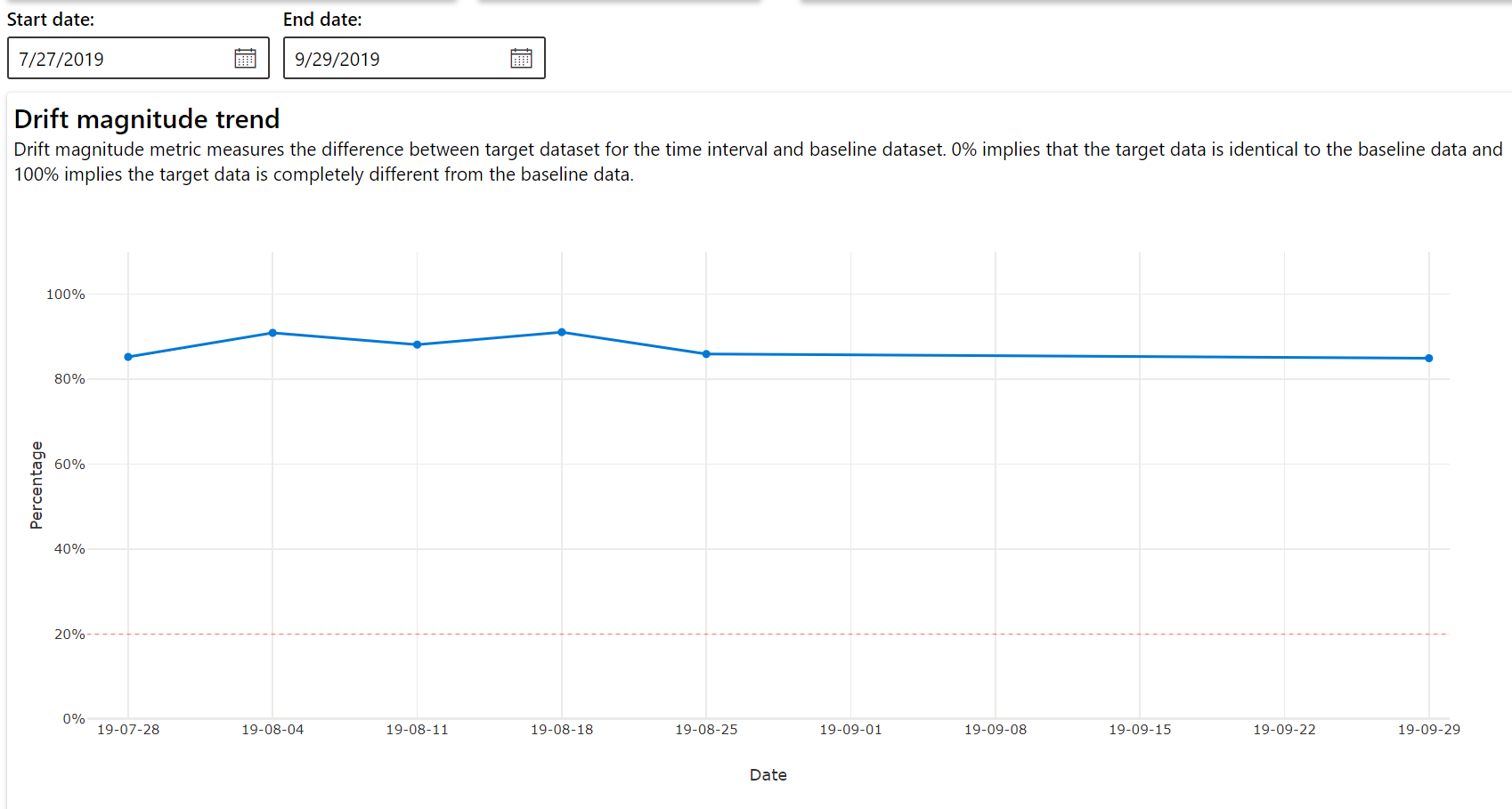
Tendenza della grandezza della deriva
Vedere come il set di dati si differenzia dal set di dati di destinazione nel periodo di tempo specificato. Più ci si avvicina al 100%, più i due set di dati differiscono.
Grandezza della deriva per funzionalità
Questa sezione contiene informazioni dettagliate a livello di caratteristica sul cambiamento nella distribuzione della caratteristica selezionata e altre statistiche, nel tempo.
Anche il set di dati di destinazione è profilato nel tempo. La distanza statistica tra la distribuzione di base di ogni caratteristica viene confrontata con quella del set di dati di destinazione nel tempo. Concettualmente, ciò assomiglia alla magnitudine della deriva dei dati. Tuttavia, questa distanza statistica è per una singola caratteristica piuttosto che per tutte le caratteristiche. Sono disponibili anche i valori minimo, massimo e medio.
Nello studio di Azure Machine Learning, selezionare una barra nel grafico per visualizzare i dettagli a livello di caratteristica per quella data. Per impostazione predefinita, si visualizza la distribuzione del set di dati di base e la distribuzione del lavoro più recente della stessa caratteristica.
Queste metriche possono essere anche recuperate nel Python SDK attraverso il metodo get_metrics() su un oggetto DataDriftDetector.
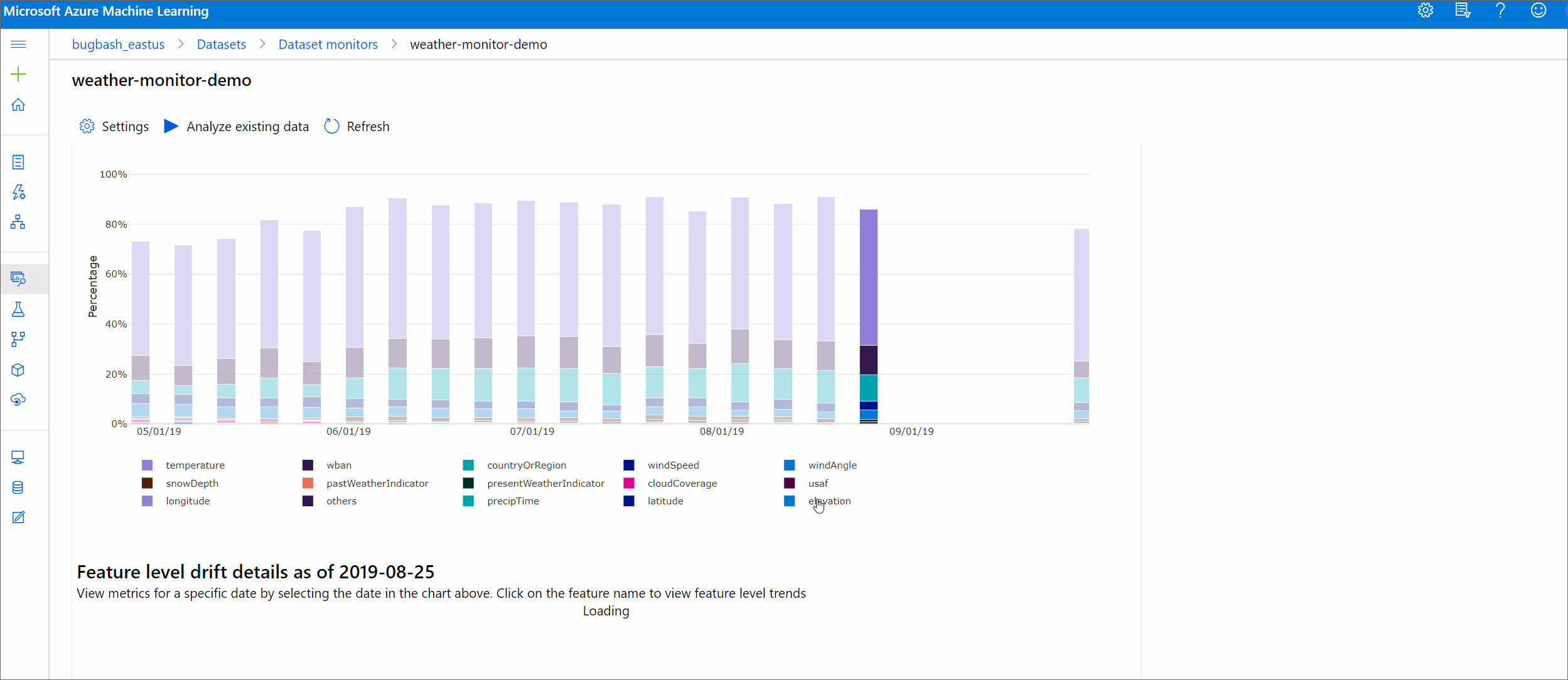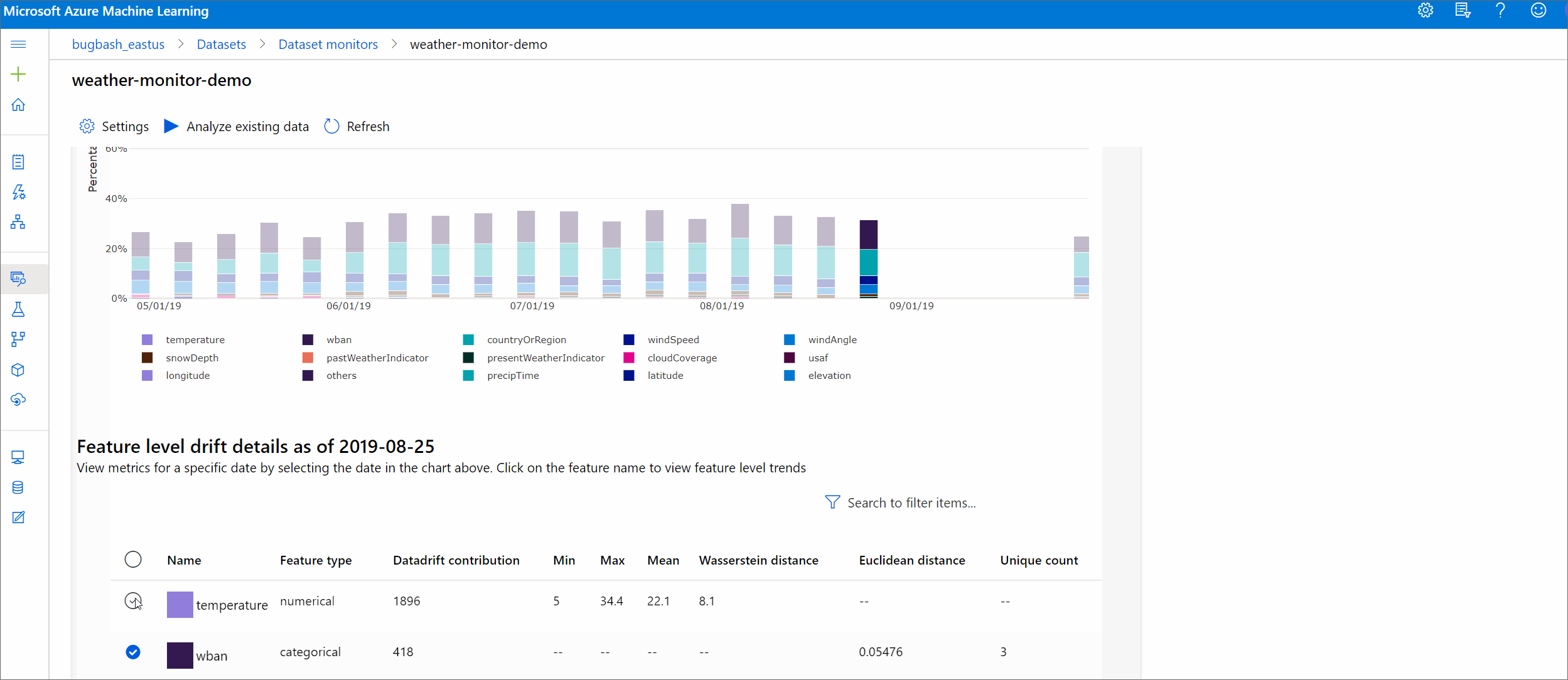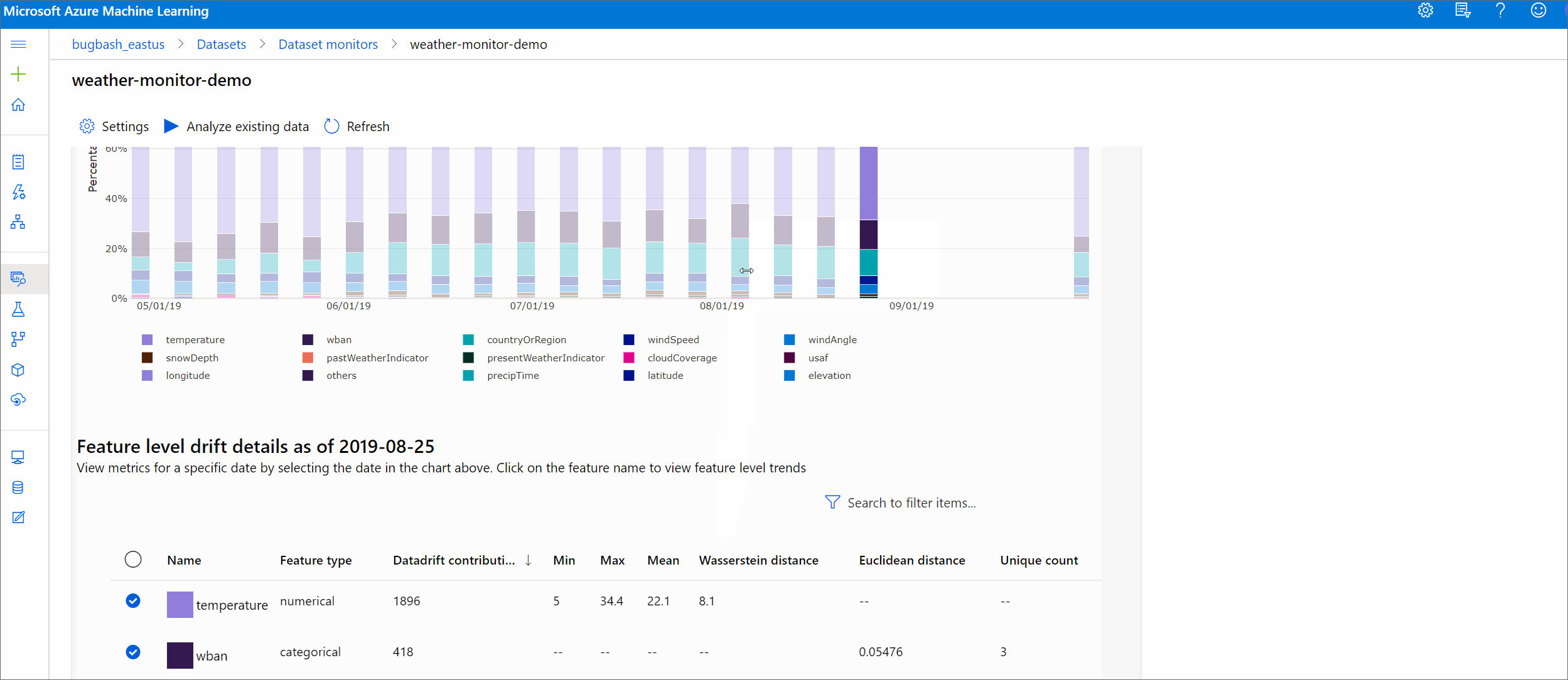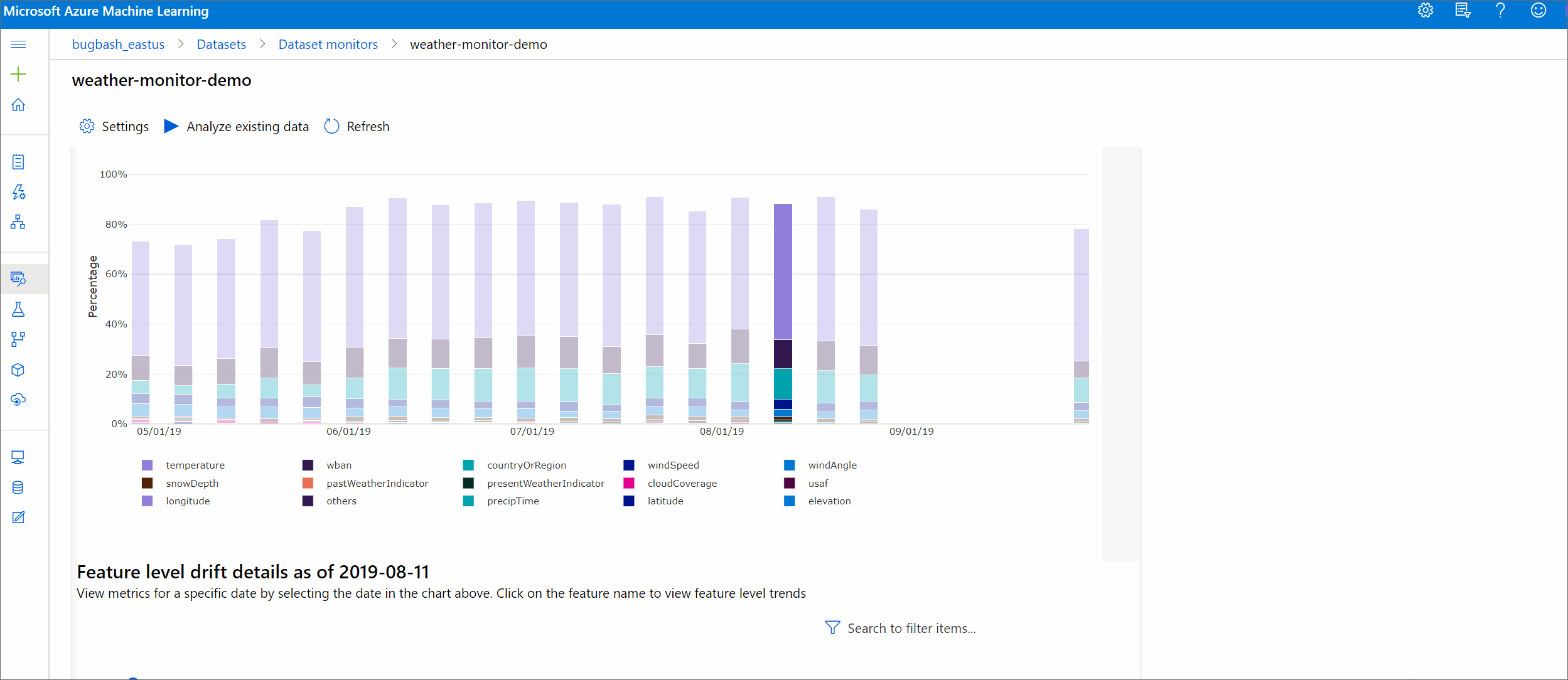
Dettagli sulla funzionalità
Infine, scorrere verso il basso per visualizzare i dettagli per ogni singola caratteristica. Utilizzare i menu a discesa sopra il grafico per selezionare la caratteristica e, in aggiunta, selezionare la metrica che si desidera visualizzare.
Le metriche nel grafico dipendono dal tipo di caratteristica.
Caratteristiche numeriche
Metrico Descrizione Distanza di Wasserstein La quantità minima di processi richiesta per trasformare la distribuzione di base nella distribuzione di destinazione. Valore medio Valore medio della caratteristica. Valore minimo Valore minimo della caratteristica. Valore massimo Valore massimo della caratteristica. Funzionalità categorie
Metrico Descrizione Distanza euclidea Calcolata per le colonne relative alle categorie. La distanza euclidea viene calcolata su due vettori, generati dalla distribuzione empirica della stessa colonna categorica dai due set di dati. 0 indica nessuna differenza nelle distribuzioni empiriche. Più si discosta da 0, più questa colonna è soggetta a deriva. Le tendenze possono essere osservate da un tracciato a serie temporali di questa metrica e possono essere utili per scoprire una caratteristica con deriva. Valori univoci Numero di valori univoci (cardinalità) della caratteristica.
In questo grafico, selezionare una singola data per confrontare la distribuzione della caratteristica tra la destinazione e questa data per la caratteristica visualizzata. Per le caratteristiche numeriche, vengono mostrate due distribuzioni di probabilità. Se la caratteristica è numerica, viene mostrato un grafico a barre.
Metriche, avvisi ed eventi
Le metriche possono essere interrogate nella risorsa Azure Application Insights associata all'area di lavoro di Machine Learning. Si ha accesso a tutte le funzionalità di Application Insights, inclusa la configurazione di regole di avviso personalizzate e gruppi di azione per attivare un'azione, come un'e-mail/SMS/Push/Voce o Funzione Azure. Per i dettagli, fare riferimento alla documentazione completa di Application Insights.
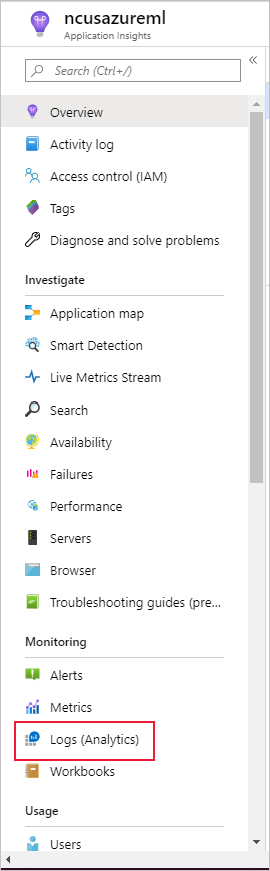
Per iniziare, navigare nel portale di Azure e selezionare la pagina Panoramica della propria area di lavoro. La risorsa Application Insights associata si trova sulla destra:

Selezionare Log (Analytics) sotto Monitoraggio nel riquadro a sinistra:
Le metriche del monitoraggio di set di dati sono archiviate come customMetrics. È possibile scrivere ed eseguire una query dopo aver configurato un monitoraggio di set di dati per visualizzarle:

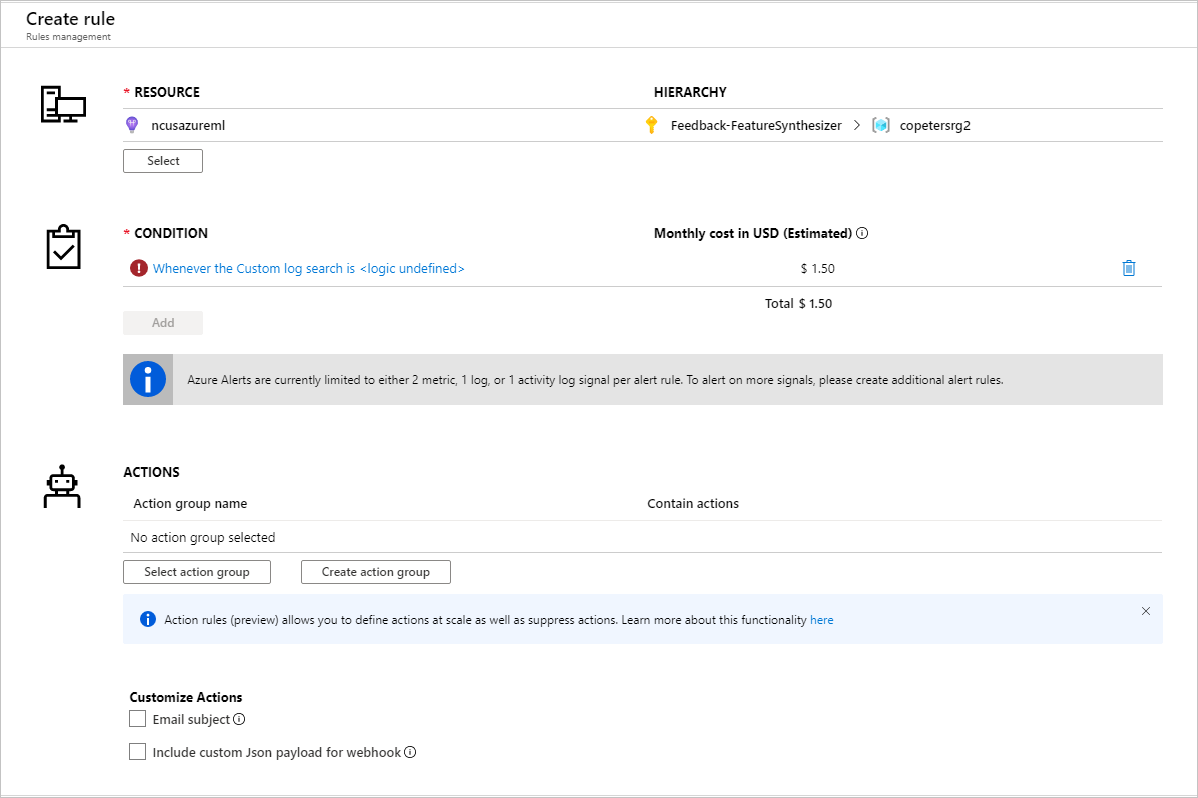
Dopo aver identificato le metriche per impostare le regole di avviso, creare una nuova regola di avviso:
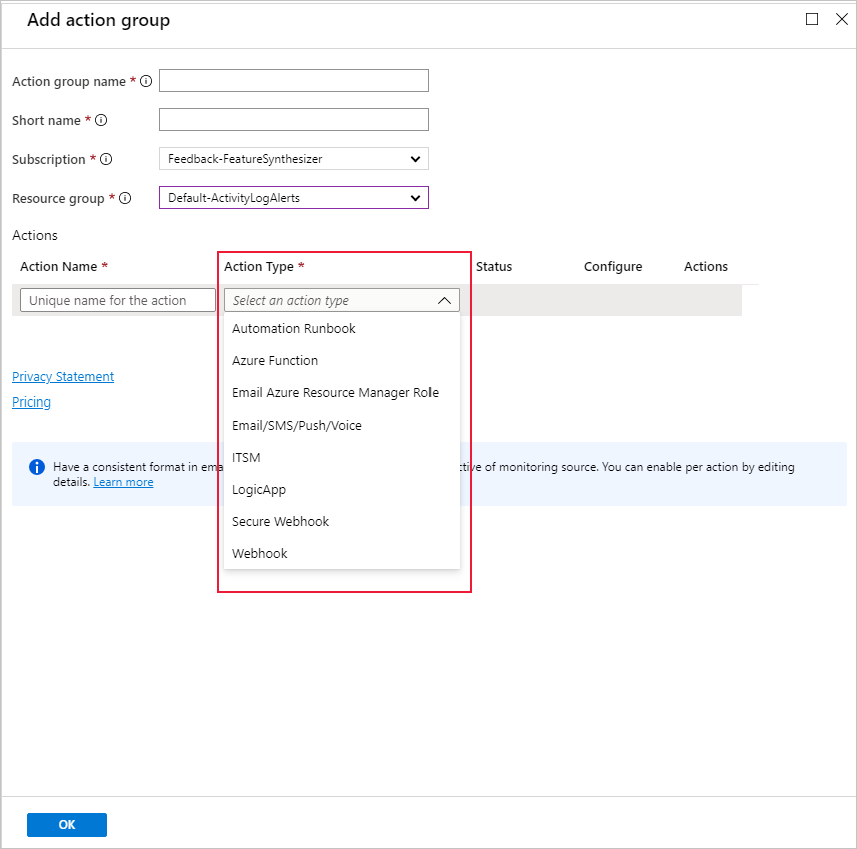
È possibile utilizzare un gruppo di azioni esistente o crearne uno nuovo per definire l'azione da intraprendere quando le condizioni impostate sono soddisfatte:
Risoluzione dei problemi
Limitazioni e problemi noti per il monitoraggio di deriva dei dati:
L'intervallo di tempo nell'analisi dei dati cronologici è limitato a 31 intervalli dell'impostazione di frequenza del monitoraggio.
Limite di 200 caratteristiche, a meno che non sia specificata un elenco di caratteristiche (utilizzate tutte le caratteristiche).
Le dimensioni di calcolo devono essere sufficientemente grandi da gestire i dati.
Assicurarsi che il set di dati abbia dati entro la data di inizio e fine per un dato processo del monitoraggio.
I monitoraggi del set di dati funzionano solo su set di dati che contengono 50 righe o più.
Le colonne, o le caratteristiche, nel set di dati sono classificate come categoriche o numeriche in base alle condizioni nella seguente tabella. Se la caratteristica non soddisfa queste condizioni, ad esempio, una colonna di tipo stringa con >100 valori unici - la caratteristica viene esclusa dall'algoritmo di deriva dei dati, ma viene comunque profilata.
Tipo di funzionalità Tipo di dati Condizione Limiti Categorie string Il numero di valori univoci nella caratteristica è inferiore a 100 e inferiore al 5% del numero di righe. Null viene trattato come una propria categoria. Numerico int, float I valori nella caratteristica sono di un tipo di dati numerico e non soddisfano la condizione per una caratteristica categorica. Caratteristica esclusa se >15% dei valori sono null. Quando si è creato un monitoraggio per la deriva dei dati ma non si visualizzano i dati nella pagina dei monitoraggi dei set di dati in studio di Azure Machine Learning, provare quanto segue.
- Verificare di aver selezionato l'intervallo di date corretto in cima alla pagina.
- Nella scheda Monitoraggi dei set di dati, selezionare il collegamento all'esperimento per controllare lo stato del processo. Questo collegamento si trova all'estrema destra della tabella.
- Se il processo è stato completato correttamente, controllare i log del driver per vedere quante metriche sono state generate o se sono presenti messaggi di avviso. Trovare i log del driver nella scheda Output + log dopo aver selezionato un esperimento.
Se la funzione
backfill()dell'SDK non genera l'output previsto, può essere dovuto a un problema di autenticazione. Quando si crea il calcolo da passare a questa funzione, non utilizzareRun.get_context().experiment.workspace.compute_targets. Invece, utilizzare l'autenticazione ServicePrincipalAuthentication come nel seguente esempio per creare il calcolo da passare a quella funzionebackfill():
Nota
Non impostare come hardcoded la password dell'entità servizio nel codice. Recuperarla invece dall'ambiente Python, dall'archivio di chiavi o da un altro metodo sicuro di accesso ai segreti.
auth = ServicePrincipalAuthentication(
tenant_id=tenant_id,
service_principal_id=app_id,
service_principal_password=client_secret
)
ws = Workspace.get("xxx", auth=auth, subscription_id="xxx", resource_group="xxx")
compute = ws.compute_targets.get("xxx")
Dall'Agente di raccolta dati del modello, possono essere necessari fino a 10 minuti affinché i dati arrivino nell'account di archiviazione BLOB. Tuttavia, in genere richiede meno tempo. In uno script o in un notebook attendere 10 minuti per assicurarsi che le celle seguenti vengano eseguite correttamente.
import time time.sleep(600)
Passaggi successivi
- Procedere allo studio di Azure Machine Learning o al Notebook Python per configurare un monitoraggio dei set di dati.
- Vedere come configurare la deriva dei dati su modelli distribuiti nel servizio Azure Kubernetes.
- Configurare i monitoraggi della deriva dei set di dati con Griglia di eventi di Azure.