Eseguire il training di modelli TensorFlow su larga scala con Azure Machine Learning
SI APPLICA A:  Python SDK azure-ai-ml v2 (corrente)
Python SDK azure-ai-ml v2 (corrente)
Questo articolo illustra come eseguire gli script di training TensorFlow su larga scala usando Azure Machine Learning Python SDK v2.
Il codice di esempio in questo articolo esegue il training di un modello TensorFlow per classificare le cifre scritte a mano usando una rete neurale profonda (DNN); registrare il modello; e distribuirlo in un endpoint online.
Indipendentemente dal fatto che si stia sviluppando un modello TensorFlow da zero o si stia portando un modello esistente nel cloud, è possibile usare Azure Machine Learning per aumentare il numero di processi di training open source usando risorse di calcolo cloud elastiche. Con Azure Machine Learning è possibile infatti creare, distribuire e monitorare modelli per ambienti di produzione, nonché controllarne la versione.
Prerequisiti
Per trarre vantaggio da questo articolo, è necessario:
- Accedere a una sottoscrizione di Azure. Se non se ne ha già una, creare un account gratuito.
- Eseguire il codice in questo articolo usando un'istanza di ambiente di calcolo di Azure Machine Learning o il Jupyter Notebook.
- Istanza di calcolo di Azure Machine Learning: nessun download o installazione necessaria
- Completare l'esercitazione Creare risorse per iniziare a creare un server notebook dedicato precaricato con l'SDK e il repository di esempio.
- Nella cartella di Deep Learning degli esempi nel server notebook, trovare un notebook completato ed espanso andando alla seguente directory: v2 > sdk > python > jobs > single-step > tensorflow > train-hyperparameter-tune-deploy-with-tensorflow.
- Il server Jupyter Notebook
- Istanza di calcolo di Azure Machine Learning: nessun download o installazione necessaria
- Scaricare i seguenti file:
- tf_mnist.py dello script di training
- score.pydello script di assegnazione punteggi
- sample-request.json del file di richiesta campione
È anche possibile trovare una versione completa di Jupyter Notebook di questa guida nella pagina degli esempi di GitHub.
Prima di poter eseguire il codice riportato in questo articolo per creare un cluster GPU, è necessario richiedere un aumento della quota per l'area di lavoro.
Configurare il processo
Questa sezione consente di configurare il processo di training caricando i pacchetti Python necessari, connettendosi a un'area di lavoro, creando una risorsa di calcolo per eseguire un processo di comando e creando un ambiente per eseguire il processo.
Connettersi all'area di lavoro
Prima di tutto, è necessario connettersi all' area di lavoro di Azure Machine Learning. L' Area di lavoro di Azure Machine Learning è la risorsa di primo livello per il servizio. Offre una posizione centralizzata per lavorare con tutti gli artefatti creati durante l’uso di Azure Machine Learning.
Si userà DefaultAzureCredential per ottenere l'accesso all'area di lavoro. Questa credenziale deve essere in grado di gestire la maggior parte degli scenari di autenticazione di Azure SDK.
Se DefaultAzureCredential non funziona per l'utente, vedere azure-identity reference documentation o Set up authentication per altre credenziali disponibili.
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()Se si preferisce usare un browser per accedere ed eseguire l'autenticazione, rimuovere il commento dal codice seguente e usarlo.
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
Ottenere quindi un handle per l'area di lavoro specificando l'ID sottoscrizione, il nome del gruppo di risorse e il nome dell'area di lavoro. Per trovare questi parametri:
- Cercare il nome dell'area di lavoro nell'angolo in alto a destra della barra degli strumenti di Studio di Azure Machine Learning.
- Selezionare il nome dell'area di lavoro per visualizzare il gruppo di risorse e l'ID sottoscrizione.
- Copiare i valori per il gruppo di risorse e l'ID sottoscrizione nel codice.
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)Il risultato dell'esecuzione di questo script è un handle dell'area di lavoro che viene usato per gestire altre risorse e processi.
Nota
- La creazione di
MLClientnon connetterà il client all'area di lavoro. L'inizializzazione del client è differita e attenderà la prima volta che sarà necessario effettuare una chiamata. In questo articolo, tale operazione verrà eseguita durante la creazione dell’ambiente di calcolo.
Creare una risorsa di calcolo
Azure Machine Learning richiede una risorsa di calcolo per eseguire un processo. La risorsa può essere un computer singolo o multinodo con sistema operativo Linux o Windows oppure un'infrastruttura di calcolo specifica come Spark.
Nello script di esempio seguente viene effettuato il provisioning di un compute cluster Linux. È possibile visualizzare la pagina Azure Machine Learning pricing per prendere visione dell'elenco completo delle dimensioni e dei prezzi delle VM. Poiché per questo esempio è necessario un cluster GPU, è possibile scegliere un modello di STANDARD_NC6 e creare un ambiente di calcolo di Azure Machine Learning.
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)Creare un ambiente di processo
Per eseguire un processo di Azure Machine Learning, è necessario un ambiente. Un ambiente di Azure Machine Learning incapsula le dipendenze (ad esempio il runtime del software e le librerie) necessarie per eseguire lo script di training di apprendimento automatico nella risorsa di calcolo. Questo ambiente è simile a un ambiente Python nel computer locale.
Azure Machine Learning consente di usare un ambiente curato (o pronto), utile per scenari di training e inferenza comuni, o di creare un ambiente personalizzato usando un'immagine Docker o una configurazione Conda.
In questo articolo verrà riutilizzato l'ambiente curato di Azure Machine Learning AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu. Viene usata la versione più recente di questo ambiente usando la direttiva @latest.
curated_env_name = "AzureML-tensorflow-2.12-cuda11@latest"Configurare e inviare un processo di training
Questa sezione introduce i dati per il training. Verrà quindi mostrato come eseguire un processo di training usando uno script di training fornito. Viene mostrato come compilare il processo di training configurando il comando per l'esecuzione dello script di training. Successivamente, il processo di training viene inviato per l'esecuzione in Azure Machine Learning.
Ottenere i dati di training
Si useranno i dati del database Modified National Institute of Standards and Technology (MNIST) di cifre scritte a mano. Tali dati provengono dal sito Web di Yan LeCun e sono archiviati in un account di archiviazione di Azure.
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"Per altre informazioni sul set di dati MNIST, visitare il sito Web di Yan LeCun.
Preparare lo script di training
In questo articolo è stato fornito lo script di training tf_mnist.py. In pratica, si dovrebbe essere in grado di eseguire in Azure Machine Learning qualsiasi script di training personalizzato così com'è, senza dover modificare il codice.
Lo script di training fornito esegue le operazioni seguenti:
- gestisce la pre-elaborazione dei dati, suddividendoli in dati di test e di training;
- esegue il training di un modello, usando i dati; e
- restituisce il modello di output.
Durante l'esecuzione della pipeline si usa MLFlow per registrare i parametri e le metriche. Per informazioni su come abilitare il rilevamento MLFlow, vedere Tenere traccia degli esperimenti e dei modelli di ML con MLflow.
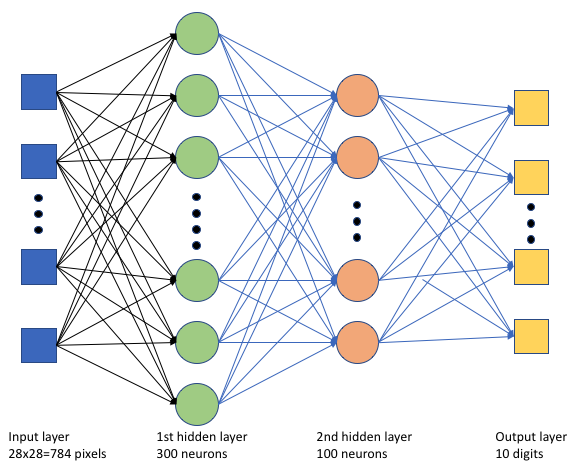
Nello script di training tf_mnist.py viene creata una rete neurale profonda (DNN) semplice. La DNN ha:
- Un livello di input con 28 * 28 = 784 neuroni. Ogni neurone rappresenta un pixel immagine.
- Due livelli nascosti. Il primo livello nascosto ha 300 neuroni, mentre il secondo ne ha 100 neuroni.
- Un livello di output con 10 neuroni. Ogni neurone rappresenta un'etichetta di destinazione da 0 a 9.
Compilare il processo di training
Ora che si dispone di tutti gli asset necessari per eseguire il processo, è possibile compilarlo usando Python SDK per Azure Machine Learning v2. Per questo esempio viene creato un command.
Azure Machine Learning command è una risorsa che specifica tutti i dettagli necessari per eseguire il codice di training nel cloud. Tali dettagli includono gli input e gli output, il tipo di hardware da usare, il software da installare e come eseguire il codice. command contiene informazioni per eseguire un singolo comando.
Configurare il comando
Si imposta l'utilizzo generico command per eseguire lo script di training e le attività desiderate. Creare un oggetto Command per specificare i dettagli di configurazione del processo di training.
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=64,
first_layer_neurons=256,
second_layer_neurons=128,
learning_rate=0.01,
),
compute=gpu_compute_target,
environment=curated_env_name,
code="./src/",
command="python tf_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="tf-dnn-image-classify",
display_name="tensorflow-classify-mnist-digit-images-with-dnn",
)Gli input per questo comando includono il percorso dei dati, le dimensioni del batch, il numero di neuroni nel primo e secondo livello e la frequenza di apprendimento. Si noti che il percorso Web è stato passato direttamente come input.
Per i valori dei parametri:
- specificare il cluster di elaborazione
gpu_compute_target = "gpu-cluster"creato per l'esecuzione di questo comando; - fornire l'ambiente curato
curated_env_namedichiarato in precedenza; - configurare l'azione della riga di comando, in questo caso, il comando è
python tf_mnist.py. È possibile accedere agli input e agli output nel comando tramite la notazione${{ ... }}; e - configurare metadati come il nome visualizzato e il nome dell'esperimento; dove un esperimento è un contenitore per tutte le iterazioni eseguite in un determinato progetto. Tutti i processi inviati con lo stesso nome dell'esperimento verranno elencati uno accanto all'altro in studio di Azure Machine Learning.
- specificare il cluster di elaborazione
In questo esempio si userà per
UserIdentityeseguire il comando. L'uso di un'identità utente significa che il comando userà l'identità per eseguire il processo e accedere ai dati dal BLOB.
Inviare il processo
È ora possibile inviare il processo per l'esecuzione in Azure Machine Learning. Questa volta si userà create_or_update in ml_client.jobs.
ml_client.jobs.create_or_update(job)Al termine, il processo registrerà un modello nell'area di lavoro (come risultato del training) e restituirà un collegamento per visualizzare il processo in studio di Azure Machine Learning.
Avviso
Azure Machine Learning esegue gli script di training copiando l'intera directory di origine. Se sono presenti dati sensibili che non si intende caricare, usare un file .ignore oppure non includerli nella directory di origine.
Ciò che accade durante l'esecuzione del processo
Il processo di esecuzione si articola nelle fasi seguenti:
Preparazione: viene creata un'immagine Docker in base all'ambiente definito. L'immagine viene caricata nel registro contenitori dell'area di lavoro e memorizzata nella cache per le esecuzioni successive. I log vengono inoltre trasmessi alla cronologia dei processi ed è possibile visualizzarli per monitorare lo stato di avanzamento. Se viene specificato un ambiente curato, verrà usata l'immagine memorizzata nella cache in cui è stato eseguito il backup dell'ambiente curato.
Ridimensionamento: il cluster prova ad aumentare laddove necessiti di più nodi di quelli attualmente disponibili per completare l'esecuzione.
Esecuzione: tutti gli script nella cartella degli script src vengono caricati nella destinazione di calcolo, gli archivi dati vengono montati o copiati e viene eseguito lo script. Gli output di stdout e la cartella ./logs vengono trasmessi alla cronologia dei processi e possono essere usati per monitorare il processo.
Ottimizza iperparametri del modello
Ora che si è visto come eseguire un training TensorFlow usando l'SDK, è possibile verificare se è possibile migliorare ulteriormente l'accuratezza del modello. È possibile affinare e ottimizzare gli iperparametri del modello usando le funzionalità di sweep Azure Machine Learning.
Per ottimizzare gli iperparametri del modello, definire lo spazio dei parametri in cui eseguire la ricerca durante il training. A tale scopo, sostituire alcuni dei parametri (batch_size, first_layer_neurons, second_layer_neuronse learning_rate) passati al processo di training con input speciali del pacchetto azure.ml.sweep.
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[32, 64, 128]),
first_layer_neurons=Choice(values=[16, 64, 128, 256, 512]),
second_layer_neurons=Choice(values=[16, 64, 256, 512]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)Si crea quindi una configurazione di sweep nel processo di comando usando alcuni parametri specifici di sweep, ad esempio la metrica primaria da controllare e l'algoritmo di campionamento da usare.
Nel codice seguente viene usato il campionamento casuale per provare diversi set di configurazioni di iperparametri nel tentativo di ottimizzare la metrica primaria validation_acc.
Si definiscono anche criteri di terminazione anticipata, ovvero BanditPolicy. Questo criterio funziona controllando il processo ogni due iterazioni. Se la metrica primaria validation_acc, non rientra nell'intervallo delle prime 10 percentuali, Azure Machine Learning termina il processo. In questo modo il modello continua a esplorare gli iperparametri che non mostrano alcuna promessa di contribuire a raggiungere la metrica di destinazione.
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="validation_acc",
goal="Maximize",
max_total_trials=8,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)È ora possibile inviare questo processo come indicato in precedenza. Questa volta si eseguirà un processo di sweep che esegue tale operazione sul processo di training.
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)È possibile monitorare il processo usando il collegamento all'interfaccia utente dello studio presentato durante l'esecuzione del processo.
Trovare e registrare il modello migliore
Al termine di tutte le esecuzioni è possibile trovare l'esecuzione che ha prodotto il modello con la massima accuratezza.
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "model"
path="azureml://jobs/{}/outputs/artifacts/paths/outputs/model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="custom_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)È quindi possibile registrare il modello.
registered_model = ml_client.models.create_or_update(model=model)Distribuire il modello come endpoint online
Dopo aver registrato il modello, è possibile distribuirlo come endpoint online, ovvero come servizio Web nel cloud di Azure.
Per distribuire un servizio di apprendimento automatico, in genere sono necessari:
- Gli asset del modello da distribuire. Questi asset includono il file e i metadati del modello già registrati nel processo di training.
- Codice da eseguire come un servizio. Il codice esegue il modello su una determinata richiesta di input (uno script di immissione). Lo script di immissione riceve i dati inviati a un servizio Web distribuito e li passa al modello. Dopo che il modello elabora i dati, lo script restituisce la risposta del modello al client. Lo script è specifico del modello e deve riconoscere i dati previsti e restituiti dal modello. Azure Machine Learning crea automaticamente questo script quando si usa un modello MLFlow.
Per altre informazioni sulla distribuzione, vedere Distribuire e assegnare punteggi a un modello di apprendimento automatico con un endpoint online gestito usando Python SDK v2.
Creare un nuovo endpoint online
Innanzitutto, per distribuire il modello è necessario creare un endpoint online. Il nome dell'endpoint deve essere univoco nell’intera area di Azure. In questo articolo si creerà un nome univoco usando un identificatore univoco universale (UUID).
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "tff-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using TensorFlow",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")Dopo aver creato l'endpoint, è possibile recuperarlo come indicato di seguito:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)Distribuire il modello nell'endpoint
Una volta creato l'endpoint, è possibile distribuire il modello con lo script di immissione. Un endpoint può avere più distribuzioni. Usando le regole l'endpoint può quindi indirizzare il traffico a queste distribuzioni.
In questo caso viene creata una singola distribuzione che gestisce tutto il traffico in ingresso. Per la distribuzione si utilizza un nome di colore arbitrario (tff-blue). È anche possibile usare un altro nome qualsiasi, ad esempio tff-green o tff-red, per la distribuzione. Il codice per distribuire il modello nell'endpoint esegue le operazioni seguenti:
- distribuisce la versione migliore del modello registrato in precedenza;
- assegna un punteggio al modello, usando il file
score.py; e - usa lo stesso ambiente curato (dichiarato in precedenza) per eseguire l'inferenza.
model = registered_model
from azure.ai.ml.entities import CodeConfiguration
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="tff-blue",
endpoint_name=online_endpoint_name,
model=model,
code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
environment=curated_env_name,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()Nota
L'esecuzione della distribuzione impiega un po' di tempo.
Testare la distribuzione con una query di esempio
Dopo aver distribuito il modello nell'endpoint, è possibile stimare l'output del modello distribuito usando il metodo invoke nell'endpoint. Per eseguire l'inferenza, usare il file di richiesta di esempio sample-request.json dalla cartella della richiesta.
# # predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request/sample-request.json",
deployment_name="tff-blue",
)È quindi possibile stampare le stime restituite e tracciarle insieme alle immagini di input. Usare un carattere rosso e un'immagine con colori invertiti (bianco su sfondo nero) per evidenziare gli esempi di classificazioni non corrette.
# compare actual value vs. the predicted values:
import matplotlib.pyplot as plt
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()Nota
Poiché l'accuratezza del modello è elevata, può essere necessario eseguire la cella più volte prima di poter vedere un esempio di classificazione non corretta.
Pulire le risorse
Se non si prevede di usare l'endpoint, eliminarlo per interrompere l'uso della risorsa. Prima di eliminare l'endpoint, assicurarsi che nessun'altra distribuzione lo stia usando.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)Nota
Il completamento di questa pulizia impiegherà un po' di tempo.
Passaggi successivi
In questo articolo è stato eseguito il training e la registrazione di un modello TensorFlow. Il modello è stato distribuito anche in un endpoint online. Per altre informazioni su Azure Machine Learning, vedere i seguenti altri articoli.